
© Vitaliy Vodolazskyy / 123RF.com
OpenStack gilt in der Industrie als Standard für den Bau privater Clouds. Doch noch immer ist die Lösung für viele Einsatzzwecke viel zu komplex und zu schwierig in Wartung und Betrieb. Woran scheitern OpenStack-Projekte, und welche Alternativen haben Administratoren?
OpenStack – der Begriff löst bei manchem heute vielleicht bereits nostalgische Gefühle aus, andere haben das Projekt schon wieder vergessen, und wenige glauben sogar, OpenStack sei mittlerweile in die ewigen Jagdgründe eingegangen. Vor zehn Jahren wäre das völlig undenkbar gewesen, denn vor dem Kubernetes-Hype kam der OpenStack-Hype. OpenStack galt damals in der Szene eine ganze Weile lang als Wunderlösung für die meisten Probleme.
Amazon hatte 2007 mit AWS das Thema Cloud auf die Tagesordnung gesetzt und damit quasi im Vorbeigehen eine Industrie umfassend revolutioniert. Vielen wurde das erst im Lauf der nächsten Dekade völlig klar. Zwar war Cloud Computing 2007 noch weit entfernt von seinem heutigen Umfang, doch Schritt für Schritt erweiterte AWS das Konzept.
“The Cloud is just somebody else’s computer” trifft deshalb schon lange nicht mehr zu. Heute ist Cloud eben auch Infrastrukturautomation, Infrastructure as Code (IaC), Immutable Underlay, Mikroarchitektur und so weiter. Dass man in der F/LOSS-Community den gesamten Kuchen nicht der privaten Wirtschaft überlassen wollte, lag auf der Hand, zumal das Prinzip der Cloud schnell auch als Alternative zu etablierten Ansätzen wie den Produkten von VMware galt. Nicht wenige Admins versprachen sich davon neben erhöhter Flexibilität vor allem eine massive Senkung der eigenen Kosten.
Aus Sicht des Jahres 2022 lässt sich festhalten, dass sich viele, wenn nicht die meisten der mit OpenStack (Abbildung 1) einst verbundenen Hoffnungen für den Großteil der Anwender nicht erfüllt haben. Im Kubernetes-Zeitalter ist OpenStack als Projekt erheblich geschrumpft. Längst sind nicht mehr so viele Entwickler aktiv involviert wie seinerzeit. Ebenso haben viele einst prominente und fast schon militante OpenStack-Befürworter ihr OpenStack-Engagement reduziert oder praktisch beendet.
Allerdings hat diese Entwicklung auch ihr Gutes. Im Laufe der vergangenen Dekade scheiterten etliche OpenStack-Großprojekte auch deshalb, weil Erwartungen und Anforderungen im Vorfeld kaum sinnvoll abgesteckt waren. Zudem war teilweise nicht klar, was OpenStack ist und leisten kann und was eben nicht. Oft genug fiel bei Projekten die Wahl auf OpenStack, die mit diesem Tool mehr schlecht als recht oder gar nicht zu implementieren waren.
Hinzu kommt, dass auch der Ausfall vieler Hersteller beim Projekt heute gar nicht mehr unbedingt als großes Pech der Projektgeschichte betrachtet wird. Beispielsweise bedeutet die volle Unterstützung sämtlicher Speicheranbieter wie HP, Dell-EMC, Sandisk & Co. zwar viel Hardwareunterstützung für zahlreiche Geräte. Es heißt aber auch, dass all die großen Anbieter möglichst viel Personal in die Schlacht schicken, um die Geschicke des Projekts zu bestimmen. Aus diesem Würgegriff hat OpenStack sich inzwischen weitgehend wieder befreit.
Abbildung 1: OpenStack gilt als das Nonplusultra bei privater Cloud-Software, doch übersteigt die Komplexität der Umgebung oft das, was Unternehmen realistisch leisten können. Quelle: OpenStack Foundation
Woran OpenStack scheitert
Die Entwicklung innerhalb der Szene ist nicht zu Ende, nicht zuletzt deshalb, weil gerade in Deutschland bis heute viele Administratoren eher skeptisch sind, wenn es darum geht, die eigenen Daten bei AWS & Co. zu lagern. In dieser Situation stehen Admins vor einem Dilemma: Public Cloud geht nicht, weil man Angst um die Daten hat, aber in Sachen privater Cloud denken noch immer viele Administratoren an OpenStack und bekommen es intuitiv mit der Angst zu tun. Es erscheint daher sinnvoll, zunächst kurz auf die Gründe einzugehen, die OpenStack-Projekte scheitern lassen, denn nur so versetzt der Admin sich in die Lage, realistisch zu bewerten, ob OpenStack für seinen Einsatzzweck taugt oder nicht. Lautet die Antwort auf die Frage nach der Eignung “nein”, stellt dieser Artikel im weiteren Verlauf mögliche Alternativen vor.
Obgleich die OpenStack-Entwicklung an Geschwindigkeit verloren hat, ist und bleibt OpenStack ein komplexes Konstrukt. Die Software umfasst heute über 30 Einzelkomponenten, von denen zugegebenermaßen aber längst nicht jeder Admin jede wirklich braucht. Reduziert man die Anzahl der Tools auf das absolute Minimum, bleiben aber noch immer mindestens sechs Komponenten übrig. Die sollte der Administrator nicht nur kennen, sondern auch die grundlegende Funktionsweise von Werkzeugen wie Nova, Cinder oder Glance klar verstehen.
Bereits an dieser simplen Hürde sind viele OpenStack-Großprojekte in der Vergangenheit gescheitert. Oft führten Verständnisprobleme etwa dazu, dass Unternehmen OpenStack als Fortsetzung von VMware mit anderen Mitteln verstanden. In Sachen Komfort und Einfachheit der Administration konnte und wollte OpenStack es allerdings zu keiner Zeit mit VMware aufnehmen. Hinzu kommt, dass in klassischen VMware-Setups oft völlig andere Prämissen gelten – es fehlt etwa SDN als Kernkomponente auf der Netzwerkseite. Viele Unternehmen, die sich in der Hoffnung auf Kosteneinsparungen OpenStack zulegten, sahen sich plötzlich einer schier nicht mehr zu kontrollierenden Komplexität gegenüber und gaben irgendwann völlig frustriert auf. Das lag nicht zuletzt oft daran, dass das eigentliche Ziel des Betriebs einiger VMs in keinem Verhältnis zum bereits betriebenen Aufwand stand.
OpenStack ist komplex
Auf OpenStack-Summits finden bis heute regelmäßig Vorträge statt, in denen Unternehmen stolz von ihrem automatisierten OpenStack berichten und die Anzahl der Server pro Admin auf 2000 Stück und mehr beziffern. Tatsächlich lässt OpenStack sich so betreiben, doch bis Automation und Orchestrierung aufgesetzt, angepasst und in Betrieb sind, steht viel Arbeit an, und zwar durch Personal, das Ahnung von der Materie hat.
Dass ein Unternehmen ohne OpenStack-Erfahrung etwa zu einer Boxed-Lösung wie Red Hat OpenStack Platform (RHOP) greift und damit in Wochen eine Riesen-Cloud mit voller Automation hinstellt, ist praktisch ausgeschlossen. Nach allzu langer Entwicklungszeit ohne konkrete Ergebnisse geht nicht wenigen Firmen wahlweise die Geduld, das Geld oder beides aus, um sich weiter mit OpenStack zu beschäftigen. Genau das sind die berüchtigten OpenStack-Riesenprojekte, die dem Ruf der Software in der vergangenen Dekade massiv geschadet haben.
Zusammengefasst lauten die Gründe für das Scheitern von OpenStack bei vielen Firmen also: zu wenig Recherche im Voraus, unrealistische Einschätzung der hohen OpenStack-Komplexität, falsche Wahl von OpenStack in der Annahme, seine Features allesamt zu benötigen, sowie zu viel Aufwand, um das Produkt selbst automatisiert und mithin effizient zu betreiben.
Mögliche Alternativen
Das Schöne an der Analyse: Sie zeigt auch einen Ausweg aus der Misere auf, indem sie im Umkehrschluss die Parameter festlegt, die bei der Wahl einer Alternative zu OpenStack eine Rolle spielen sollten.
Viele Firmen etwa benötigen zwar Virtualisierung mit einer Funktion wie Hochverfügbarkeit, doch spielt oft die Mandantenfähigkeit keine Rolle. Die macht allerdings bereits einen erheblichen Teil der OpenStack-Komplexität aus, weil sie in der Konsequenz oft auch andere Features ins Boot holt wie Software Defined Networking.
Wieder andere Unternehmen benötigen vielleicht ein ausgefeiltes virtuelles Netz, brauchen jedoch die Selbstbedienungsfähigkeiten von OpenStack nicht. Die spielen beim Projekt immer wieder eine erhebliche Rolle, weil On-Demand-Benutzung bei Clouds ein zentrales Wesensmerkmal ist.
Klassische Virtualisierung mit geringer Fluktuation der VMs hingegen kann auf bunte Webinterfaces oft verzichten, was wiederum erheblich zur Senkung der Komplexität beiträgt. Übrig bleibt ein kleiner, aber feiner Kreis weniger komplexer OpenStack-Alternativen, auf die dieser Artikel im Folgenden detailliert eingeht.
oVirt
Den Auftakt macht dabei oVirt (Abbildung 2). Manchem Administrator dürfte das Produkt unter dem Namen seiner kommerziellen Variante besser bekannt sein, denn oVirt ist die Open-Source-Grundlage von Red Hats Virtualisierungslösung RHEV (Abbildung 3).
Abbildung 2: oVirt ist Red Hats Virtualisierungsmanager und bietet so manche Funktion an, die auch bei OpenStack zu finden ist. Quelle: Red Hat
Abbildung 3: Wer eine Option mit Support braucht, setzt auf oVirts kommerzielle Distribution Red Hat Enterprise Virtualisation (RHEV).
Damit ist im Grunde auch klar, wo die Reise hingeht, denn Red Hat gehört zugleich weiterhin zu den aktivsten OpenStack-Entwicklern und mithin zu den wenigen Unternehmen, die eine kommerzielle OpenStack-Distribution – Red Hat OpenStack Platform – überhaupt noch im Portfolio führen. Stallintern wird RHOP seinem Geschwister RHEV aber kaum Konkurrenz machen, und so präsentiert sich oVirt an vielen Stellen als reine Virtualisierungslösung für kleine Umgebungen, wobei der Funktionsumfang grundsätzlich durchaus beachtlich ausfällt.
Dreh- und Angelpunkt des Produkts ist ein Controller-Knoten, auf dem sämtliche oVirt-Basisdienste laufen. Red-Hat-Fans sind hier klar im Vorteil, denn oVirt gibt es paketiert nur für RHEL 8 und CentOS Steam 8. Entsprechend läuft es jedoch auch auf AlmaLinux 8 und Rocky Linux 8. Nach der Installation der Basiskomponenten versorgt der Administrator die frische oVirt-Instanz zunächst mit Speicher, wobei ein Füllhorn an Optionen zur Auswahl steht. Dazu zählen NFS, GlusterFS, Fibre Channel sowie andere POSIX-kompatible Dateisysteme.
Auf der Website fehlt in der Liste mit den Storage-Treibern für oVirt interessanterweise Ceph. Das überrascht insofern, als sich Ceph als grundsolide Lösung für skalierbaren Speicher längst auch außerhalb von OpenStack etabliert hat. Anders als OpenStack ist Ceph schließlich in recht kurzer Zeit voll automatisiert aufgesetzt und betriebsbereit; anders als OpenStack verursacht es im administrativen Alltag eher geringen Aufwand und kümmert sich obendrein um die meisten seiner Probleme selbst.
Wühlt man ein wenig in der Dokumentation, kommt man allerdings dahinter, wie Red Hat sich die Ceph-Anbindung in oVirt vorstellt, und landet – wer hätte das gedacht? – bei einer OpenStack-Komponente. Der in OpenStack für Speicher zuständige Dienst heißt bekanntlich Cinder. Er lässt sich auch ohne den Rest der OpenStack-Komponenten ganz gut betreiben und kommuniziert dann im Wesentlichen mit den Storage-Backends im Hintergrund, um Volumes zu erzeugen. Deren Pfad gibt Cinder dann an anfragende Instanzen wie oVirt aus.
Wer oVirt und Ceph kombiniert, handelt sich also auch ein kleines Stück OpenStack ein, doch lässt sich der Aufwand bei der Verwendung des Cinderlib-Treibers in oVirt mit der Komplexität der Anbindung bei OpenStack selbst nicht einmal ansatzweise vergleichen.
Viele Funktionen
Zusätzlich zum Controller stellt der Administrator einer oVirt-Installation auch eine beliebige Anzahl von Virtualisierungs-Hosts zur Verfügung, also die eigentlichen Compute-Knoten. Die kommunizieren mit ihrem Controller mittels eines Controller-Agent-Verfahrens und wissen so, was sie zu tun haben. Der Mühe Lohn ist eine kleine, aber feine Virtualisierungslösung, die sich mittels LDAP-Anbindung sogar um eine rudimentäre Art von Selbstbedienung erweitern lässt. Komplexe virtuelle Netzwerk-Setups sieht oVirt allerdings nicht vor. Das erleichtert zum einen das Debugging und reduziert zum anderen die Zahl möglicher Fehlerquellen drastisch.
Eine Funktion, die viele Admins bei OpenStack schmerzlich vermissen, integriert oVirt zudem gleich ab Werk. Das Data Warehouse schreibt Metrikdaten mit Tausenden von Werten im Hintergrund mit und macht sie über Schnittstellen unmittelbar in oVirt verfügbar. Das erleichtert die Anbindung an Monitoring- oder Trending-Systeme erheblich. Es gibt auch einen oVirt-Exporter, der Daten aus oVirts Data Warehouse passend für Prometheus exportiert [1].
In Sachen alltäglicher Funktionalität lässt oVirt obendrein nur wenige Wünsche offen. So lassen sich fertige Betriebssystemabbilder definieren, und es besteht die Möglichkeit, Snapshots existierender VMs anzulegen. Das erleichtert Backups und Restore-Vorgänge erheblich. In Summe präsentiert oVirt sich als sehr leistungsfähige OpenStack-Alternative gerade für kleine Setups, die Admins mit Bedarf an Virtualisierung im Hinterkopf behalten sollten.
Der Eigenbau-Cluster
Möglicherweise ist es den nostalgischen Gefühlen des Autors geschuldet, dass auch die Urform eines Virtualisierungs-Clusters noch Erwähnung findet. Es könnte aber auch an dem Umstand liegen, dass ein Setup dieser Art die einfachste und schnellste Variante ist, möglichst flott ein paar hochverfügbare VMs an den Start zu bekommen.
Eingedenk der Komplexität von Lösungen wie OpenStack und sogar oVirt muss der Linux-HA-Stack heute zumindest nicht mehr als komplexestes Produkt unter der Sonne gelten. Zudem hat Red Hat in den vergangenen Jahren viel Arbeit investiert, die einstigen Schrecken von Heartbeat 2 und dessen Nachfolger Pacemaker in den Griff zu bekommen. Das Hacken irgendwelcher XML-Dateien kann man sich heute ebenso sparen wie das Auswendiglernen kryptischer Shell-Kommandos, um den Cluster mit zu verwaltenden Ressourcen zu füttern.
Gleichzeitig sind der Linux-HA-Stack und alle seine Komponenten praktisch ubiquitär verfügbar: Red Hat (RHEL) und Suse (SLES) vertreiben sie in Form eines Addons, die entsprechenden Pakete liegen auch Ubuntu und Debian bei. Anders gesagt: Wer drei Systeme mit einer gängigen Linux-Distribution hat, bringt einen Pacemaker-Cluster schnell zum Laufen. Wie das funktioniert, erklären zahllose Anleitungen im Netz mittlerweile bis ins kleinste Detail.
Zugleich gilt, dass Pacemaker in den vergangen 15 Jahren wohl für kaum eine Aufgabe so regelmäßig genutzt wurde wie für den Betrieb virtueller Instanzen. Der VirtualDomain Resource Agent hat sich seine Sporen längst verdient und gilt heute als zuverlässig und stabil. Die Anbindung externer Speicherdienste wie Ceph klappt in einem Setup dieser Art sogar fast einfacher als etwa bei oVirt: Hier genügt es, in die Libvirt-Definition der jeweiligen Instanz den Pfad zu ihrem RBD-Laufwerk einzutragen, und schon kann es losgehen.
Obendrein ist zumindest das grundlegende Ausbalancieren von Ressourcen per Pacemaker problemlos möglich. So lässt sich der Cluster etwa in einem 3-Knoten-Verbund dazu bringen, drei VMs gleichmäßig auf die drei Server zu verteilen. Auch ist es möglich, eine Instanz von Pacemaker abschalten zu lassen, sollte ein Server ausfallen. Das entspricht zwar noch nicht einer umfassenden Placement-Strategie, wie sie bei OpenStack oder oVirt existiert, genügt jedoch für kleine Umgebungen durchaus.
Verzichten muss der Administrator in diesem Szenario allerdings auf sämtliches Beiwerk. Weder gibt es hier Selbstbedienung per Web-UI noch virtuelles Netzwerk per SDN. Klickibunti-Assistenten für das Aufsetzen neuer Instanzen fehlen ebenfalls, nicht einmal eine Abbildverwaltung ist Teil des Pakets. Wer irgendeine dieser Funktionen benötigt, ist bei oVirt oder Proxmox zweifelsohne besser aufgehoben. Wer aber wirklich nur ein paar VMs virtualisieren möchte, kommt per Pacemaker schnell ans Ziel. Weil für Pacemaker mittlerweile sogar Automationsmodule wie etwa für Ansible existieren, geht das heute auch komplett automatisiert.
Der Veteran: Proxmox
Wem Pacemaker im Eigenbau zu viel Frickelei ist, der wird vermutlich mit Proxmox eher glücklich. Aus heutiger Sicht darf Proxmox fast schon als eine Art Veteran im Virtualisierungsgeschäft gelten, und was man sich in Wien in den vergangenen Jahren erarbeitet hat, spricht durchaus für sich. In vielerlei Hinsicht ist Proxmox nämlich sogar der Konkurrenz von VMware heute ebenbürtig – doch der Reihe nach.
So etwas wie die Proxmox-Keimzelle war der Wunsch, eine einfache Verwaltung von virtuellen Instanzen und ihren Storage-Bedürfnissen zu schaffen. Als die ersten Versionen von Proxmox das Licht der Welt erblickten, waren weder oVirt noch OpenStack so weit entwickelt wie heute, und insbesondere zwischen Proxmox und oVirt entstand eine Art offenes Rennen um die Gunst der Nutzer. Nach Stand der Dinge dürfte Proxmox es wohl gewonnen haben, denn vielerorts gilt das Produkt heute als logischer VMware-Ersatz und Nachfolger von oVirt.
In Sachen Funktionsumfang braucht Proxmox (Abbildung 4) sich tatsächlich nicht zu verstecken. Dreh- und Angelpunkt der Lösung ist eine eigene Management-Plane, die sich auf einem oder Dutzenden Systemen ausrollen lässt, wobei die Systeme die Koordination dabei untereinander selbst abwickeln. Eine große Stärke der Lösung ist ihr Webinterface, das auch weniger erfahrenen Benutzern Zugriff auf etliche Funktionen im Hintergrund bietet. Dank passender Rechteverwaltung und RBAC kann die Proxmox-UI auch für grundlegendes Self Servicing zum Einsatz kommen.
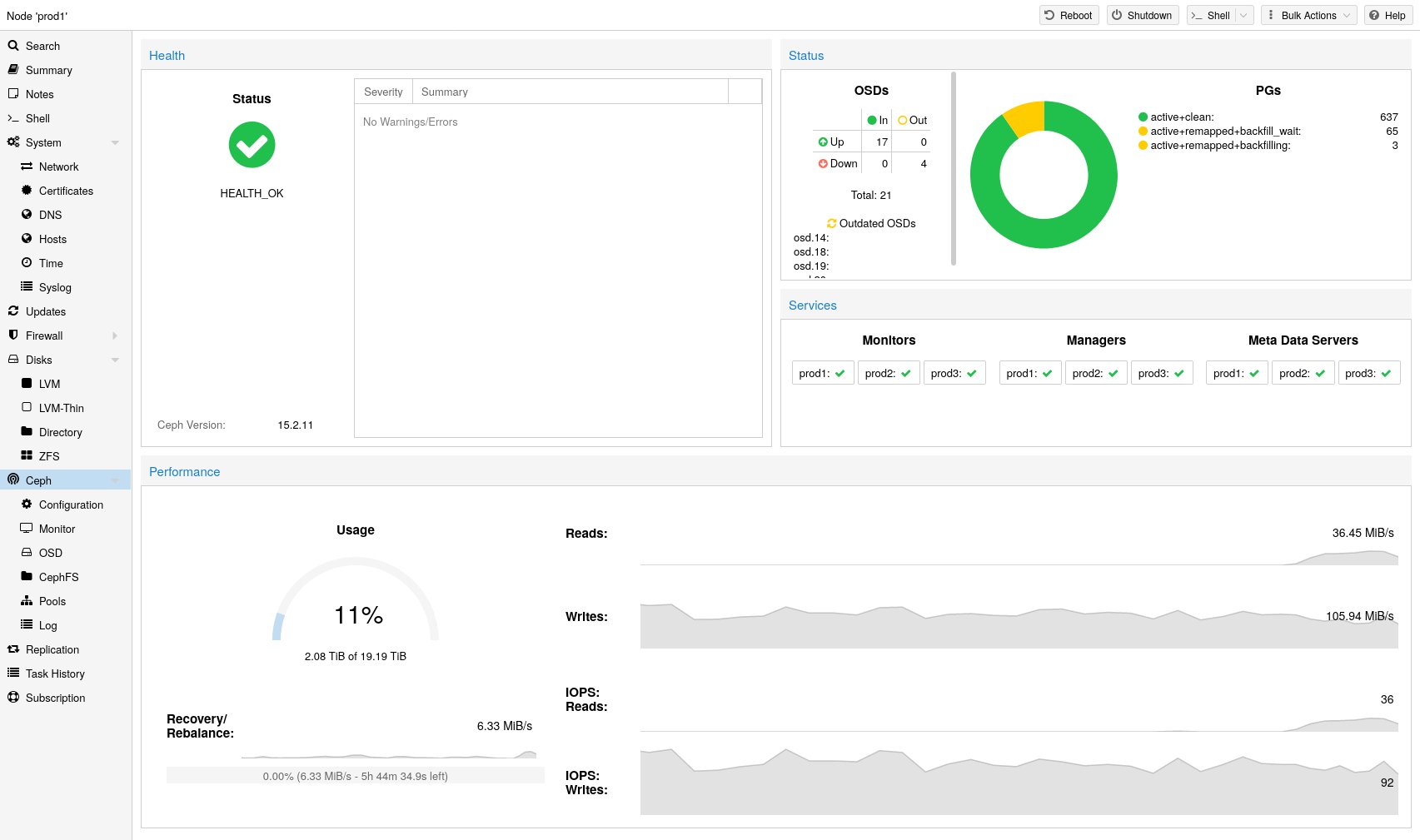
Abbildung 4: Proxmox ist ein echter Veteran in Sachen Virtualisierung, kommt heute aber auch gut mit Lösungen wie Ceph klar und rollt diese zum Teil sogar selbstständig aus. Quelle: Proxmox
Nutzer, denen die Bastelei in Sachen Pacemaker aus dem vorherigen Abschnitt zu viel war, bekommen bei Proxmox das komplette Pacemaker-Handling als Teil des Pakets. Hier lassen sich Compute-Knoten nämlich als HA-Knoten definieren, und Proxmox kümmert sich im Hintergrund um das Ausrollen und die Konfiguration der benötigten HA-Dienste auf den betroffenen Systemen.
Legendär ist bei Proxmox obendrein die Integration verschiedener Storage-Backends. Für HA etwa bot man bereits vor einer Dekade Support für die Replikationslösung DRBD an. Heute setzt man eher auf Ceph, das Proxmox auf Zuruf sogar automatisiert an den Start bringt. Das klappt freilich nur, falls entsprechende Hardware vorhanden ist. Dasselbe gilt für einen eigenen Storage-Replication-Stack auf Basis von ZFS, falls für Ceph keine Hardware zur Verfügung steht oder das Produkt nicht zum Einsatz kommen soll.
Darüber hinaus lässt Proxmox in Sachen Funktionalität nur wenige Wünsche offen. Templates virtueller Instanzen lassen sich hinterlegen. Neben KVM unterstützt der Dienst auch Container-Virtualisierung auf Basis von LXC. Dabei behandelt Proxmox Container wie VMs als gleichwertige virtuelle Instanzen. Zugänglich gibt es sich auch bei seinem eigenen Setup: Nicht zuletzt dank einer umfassenden Installationsanleitung auf der Projektseite ist die Lösung schnell am Start.
Die Verteilungspolitik des Anbieters sorgt allerdings bei so manchem Administrator für Stirnrunzeln – meist zu Unrecht: Proxmox VE steht unter einer freien Lizenz und lässt sich als Open-Source-Software aus den Github-Verzeichnissen des Anbieters völlig kostenfrei beziehen. Das Bauen von Paketen obliegt dann allerdings dem Benutzer, und gerade diesen Schritt wollen viele Unternehmen vermeiden.
Wer lediglich auf die Pakete spitz ist und keinen Support seitens des Herstellers wünscht, zahlt pro System mit vier CPU-Sockets 380 Euro Subskriptionsgebühr jährlich. Angesichts des erheblichen Funktionsumfangs von Proxmox und der einfachen Installation erscheint das jedenfalls nicht übertrieben viel.
OpenNebula
In einer Auflistung der OpenStack-Alternativen darf OpenNebula keinesfalls fehlen. Das Produkt geriert sich im Grunde von Anfang an als eine Art Anti-OpenStack. Viel weniger Komplexität, einfachere UIs, leichtere Bedienung und mehr Automation ab Werk sind nur einige der Versprechen, mit denen der gleichnamige Hersteller Kunden zu locken versucht. Die meisten seiner Versprechen hält OpenNebula tatsächlich.
Die automatisierte Installation von OpenNebula (Abbildung 5) mit allen benötigen Komponenten geht in kurzer Zeit leicht von der Hand – zumindest, wenn die Planung im Vorfeld stimmt. Das umfasst das für echtes Cloud Computing so wichtige Webinterface ebenso wie eventuell benötigte Software im Hintergrund, etwa für Ceph. Grundlegende SDN-Funktionalität mittels OpenDaylight oder OVN steht mittlerweile ebenso zur Verfügung wie die umfassende Handhabung von Storage Volumes. Das ganze garniert der Anbieter mit einer schmucken Verwaltung von VM-Templates und einer intuitiven Weboberfläche inklusive Mandantenfähigkeit. In Summe ist OpenNebula also gerade für kleinere Cloud-Setups eine echte Alternative.
Abbildung 5: OpenNebula vermarktet sich seit Jahren erfolgreich als eine Art Anti-OpenStack. Wer die überbordende OpenStack-Komplexität satthat, wird hier mit höchstwahrscheinlich fündig. Quelle: OpenNebula
Mancher mag sich gar fragen, warum OpenNebula dann OpenStack nicht gleich komplett ersetzen soll? Hier steckt der Teufel wie üblich im Detail. In gewisser Weise ist OpenNebula das, was viele Unternehmen sich von OpenStack einst erhofft hatten – eine nicht hyperkomplizierte Virtualisierungslösung mit grundlegender Cloud-Funktionalität, Automation und Selbstbedienung.
OpenStack konnte diesem Anspruch schon deshalb nie gerecht werden, weil viele große Telcos und andere Unternehmen die Geschicke des Projekts mitbestimmten und ihre eigenen Interessen zum Teil hemmungslos durchsetzten. Daraus erwuchs eine Komplexität, die die Fähigkeiten und Möglichkeiten kleinerer Setups praktisch a priori übersteigt. Für die meisten kleinen Umgebungen kann OpenStack einfach zu viel. OpenNebula bildet hier den angenehmen Kontrapunkt, der für kleine Umgebungen genug sinnvolle Funktionen bietet, ohne übermäßig komplex auszufallen.
Fazit
Wie dieser Artikel zeigt, muss es in den seltensten Fällen wirklich OpenStack sein. OpenStack hat seinen Sweet Spot bei Großkonzernen, die Plattformanbieter werden und dabei riesige Virtualisierungsumgebungen bieten müssen. Gerade das trifft auf die meisten kleineren Unternehmen allerdings nicht zu. Drum prüfe, wer sich langfristig bindet: Der erste Schritt bei der Einführung einer neuen Virtualisierungsumgebung sollte stets die genaue Dokumentation des eigenen Bedarfs sein.
Wenn man einen Großteil klassischer Cloud-Funktionalität gar nicht erst benötigt, ist die Eigenbaulösung mit Pacemaker, Libvirt und Qemu bis heute eine valide, weil gut überschaubare Option. Wird ein Nachfolger für VMware gesucht, sind Proxmox und oVirt die logischen ersten Kandidaten. Soll wirklich eine Art Cloud entstehen, jedoch ohne die überbordende OpenStack-Komplexität, ist OpenNebula mit einiger Wahrscheinlichkeit das Mittel der Wahl. Hier zeigt sich auch einmal mehr die Stärke der F/LOSS-Community, die für das Problem in jeder Größe eine fertige Lösung bereithält. (jcb)
Infos
- oVirt-Exporter für Prometheus: https://github.com/czerwonk/ovirt_exporter





