
© Andrei Rancz / 123RF.com
Die einen halten Data Science für den “sexiest job” des 21. Jahrhunderts, die anderen sehen darin nur neuen Wein in alten (Statistik-)Schläuchen. Die Wahrheit liegt wie so oft irgendwo dazwischen.
Daten sind das neue Öl, so steht es seit Jahren auf den Folien der Unternehmensberater, und Data Science soll die neue Form der Raffinerie sein. Tatsächlich werden immer mehr Daten erhoben, zum Beispiel durch Sensoren, und stehen den Datenwissenschaftlern zur Verfügung. Deren Aufgabe besteht darin, neue Erkenntnisse aus diesen Daten zu gewinnen und dabei Prozesse zu automatisieren sowie Menschen bei Entscheidungen zu unterstützen [1].
Mehr als nur Modellierung
Obwohl die Bezeichnung Data Scientist zunächst die Assoziation eines Mathe-Nerds hervorruft, besteht Data Science aus viel mehr als dem Bauen und Optimieren von Modellen. Sie umfasst zunächst vor allem das Verständnis des Problems und seines Kontexts.
Ein Beispiel: Eine Bank will mithilfe eines Algorithmus prognostizieren, mit welcher Wahrscheinlichkeit ein Kreditnehmer sein Darlehen bedienen kann. Hier wird ein Data Scientist zunächst verstehen wollen, wie die Kreditvergabe bisher funktionierte, welche Daten dafür erhoben wurden und ob diese auch tatsächlich zur Verfügung stehen, etwa mit Hinblick auf Datenschutzvorgaben. Zudem müssen Data Scientists ihre Erkenntnisse kommunizieren können. Story Telling ist hier sinnvoller als eine Vorstellung endloser Zahlenreihen, denn das Publikum besteht häufig aus Nicht-Mathematikern. Das stellt die weniger extrovertierten Exemplare der Zunft nicht selten vor eine Herausforderung.
Vorbereitung der Daten
Was in der Theorie einfach klingt, erfordert häufig eine zeitaufwendige Reinigung und Transformation der Daten. Nicht immer liegen sie so vor, wie man sie benötigt. Zum Beispiel setzen viele Algorithmen numerische Daten voraus, die aus nicht numerischen Daten gewonnen werden müssen.
Dazu bildet der Data Scientist zum Beispiel Kategorien, die sich entweder mit numerischen Abständen voneinander trennen lassen oder mit sogenannten Dummy-Variablen, bei denen jedes Vorkommen einer Merkmalsausprägung (etwa männlich, weiblich und divers) zu einer eigenen Variable wird. Dabei kann man in der Regel eine Variable weglassen: So kann jemand nur männlich sein, wenn er weder weiblich noch divers ist. Durch fehlerhafte Nutzereingaben ergeben sich allerdings häufig Datenpunkte, die einen Algorithmus auf die falsche Fährte bringen könnten. Sie gilt es zu identifizieren und zu bereinigen.
Zudem sucht der Data Scientist nun nach den Variablen, die für das Modell tatsächlich relevant sind. Hier kommen die Informationen ins Spiel, die er während der Verständnisphase gesammelt hat. In einer explorativen Datenanalyse, häufig in einem Jupyter Notebook oder Ähnlichem, generiert und dokumentiert er die Erkenntnisse, sodass er sie mit Kollegen teilen kann (oder zumindest selbst nachvollziehen).
Das geeignete Modell auswählen
Die Auswahl eines Algorithmus hängt zunächst einmal von der Aufgabenstellung ab. Stehen Daten zur Verfügung, anhand derer sich ein Algorithmus trainieren lässt, spricht man von einem Supervised Learning. Das wäre in unserem Beispiel der Fall, wenn historische Daten über Kreditausfälle existieren, anhand derer eine Maschine lernen kann vorherzusagen, ob zukünftige Kreditnehmer ihre Darlehen zurückzahlen werden. Die Variable, nach der trainiert wird, nennt man häufig Zielvariable – in unserem Beispiel, ob ein Kredit zurückgezahlt wurde. Andere Beispiele wären Klassifikationen, ob ein Muttermal auf Hautkrebs hindeuten könnte oder ob ein Kunde ein Betrüger ist.
Existieren zwar Daten, die aber keine Zielvariablen enthalten, dann geht es häufig darum, ein Muster in den Daten zu finden, um zum Beispiel Kunden in Segmente einzuordnen. Diese Art von Machine Learning bezeichnet man als Unsupervised Learning.
Unsupervised Learning
Einer der populärsten Algorithmen im Unsupervised Learning, sofern man das nach der Anzahl entsprechender Tutorials beurteilen kann, ist k-Means. Mit diesem Algorithmus werden Daten geclustert, also in Segmente eingeteilt. Grob beschrieben setzt man bei diesem Verfahren zunächst sogenannte Centroiden in die Datenpunkte und berechnet dann die Abstände der Datenpunkte zu diesen Centroiden.
Aus den Datenpunkten, die jeweils einem der Centroiden am nächsten liegen, ergeben sich die ersten Cluster. Für diese Cluster berechnet man dann deren tatsächlichen Mittelpunkt. So ergeben sich neue Abstände der einzelnen Datenpunkte zu den jeweiligen Mittelpunkten. Auf dieser Grundlage sortieren sich die Cluster wieder neu. Man wiederholt den Vorgang so lange, bis sich die Zentren nicht mehr verändern.
Abbildung 1 stellt diesen Ansatz dar. Die Anzahl der Segmente bestimmt der Wert k, der vorgegeben werden muss. Hier stellt sich die Frage nach der angemessenen Anzahl; die Antwort darauf liefert der sogenannte Ellbogentest. Er führt k-Means mit verschiedenen Cluster-Größen aus und zeigt danach an, wie stark die Varianz innerhalb der Cluster bei den verschiedenen Größen ausfällt. In der Regel entsteht beim Visualisieren dieser Varianzen ein Knick in der Kurve, der Ellbogen, an dem man den optimalen Wert für k ablesen kann.
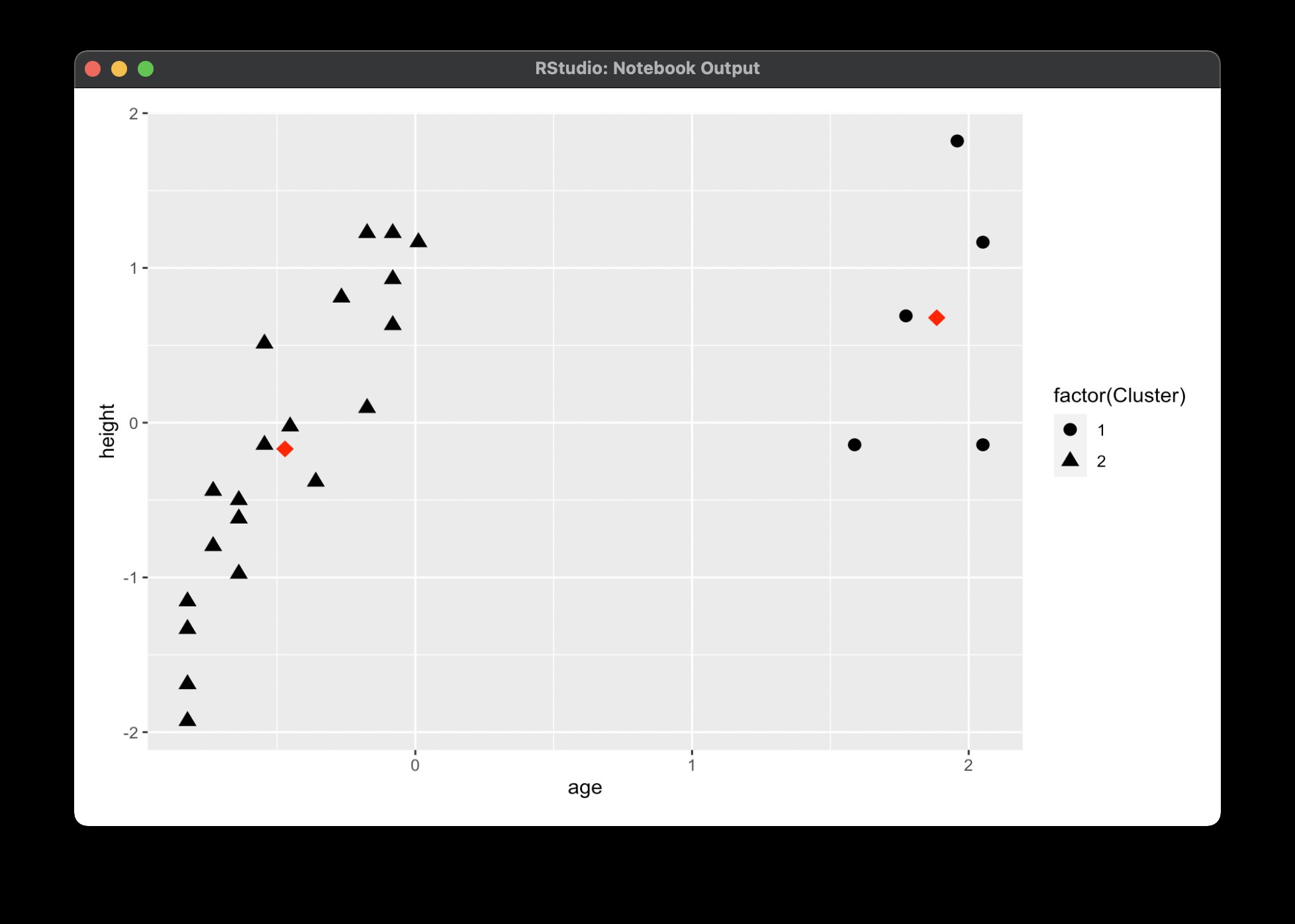
Abbildung 1: Die Visualisierung eines k-Means-Clusterings. Für die schwarzen Datenpunkte berechnet man die roten Mittenwerte. Danach verteilt man die Punkte abhängig vom Abstand zur jeweiligen Mitte gegebenenfalls neu auf die entstehenden Cluster.
Ein weiteres populäres Beispiel für Unsupervised Learning bieten Assoziationsregeln, wie man sie in Shops einsetzt, um verwandte Produkte anbieten zu können. “Kunden, die X gekauft haben, sehen sich oft auch Y an” wäre eine typische Anwendungsmöglichkeit von Assoziationsregeln. Hier untersucht man sogenannte Items, zum Beispiel eine Ware in einem Shop, im Kontext von Transaktionen, die man auch als Warenkörbe oder Kassenbons verstehen kann. Der Apriori-Algorithmus ist in diesem Bereich populär, weil er weniger Rechenaufwand erfordert. Er ignoriert seltene Items und auch die Transaktionen, in denen sie auftauchen, sodass er viel weniger Daten durcharbeiten muss.
Aus den verbleibenden Transaktionen entstehen je nach Parametern Regeln mit verschiedenen Kennwerten: Der Support zeigt an, wie häufig ein Warenkorb im Vergleich zu allen Warenkörben vorkommt, wobei auch andere Items darin vorhanden sein dürfen. Die Konfidenz sagt aus, wie häufig ein Item auftaucht, wenn ein bestimmtes anderes Item vorhanden ist. Der Lift gibt an, wie viel häufiger eine Kombination vorkommt als voneinander unabhängige Items. Von Interesse sind Regeln, die einen hohen Lift aufweisen und gleichzeitig häufig genug auftauchen, um auch von Nutzern gesehen zu werden.
Supervised Learning
Eines der einfachsten Machine-Learning-Modelle ist die bereits im 19. Jahrhundert verwendete lineare Regression, sozusagen das “Hello World” des Machine Learnings. Abbildung 2 zeigt Auslösungen und Preise gebrauchter Spiegelreflexkameras eines bestimmten Kameramodells. Je mehr Auslösungen, desto weniger sollte eine gebrauchte Kamera kosten, wie die Datenpunkte auch schon erkennen lassen. Wie kann man nun aber einen fairen Preis ermitteln?
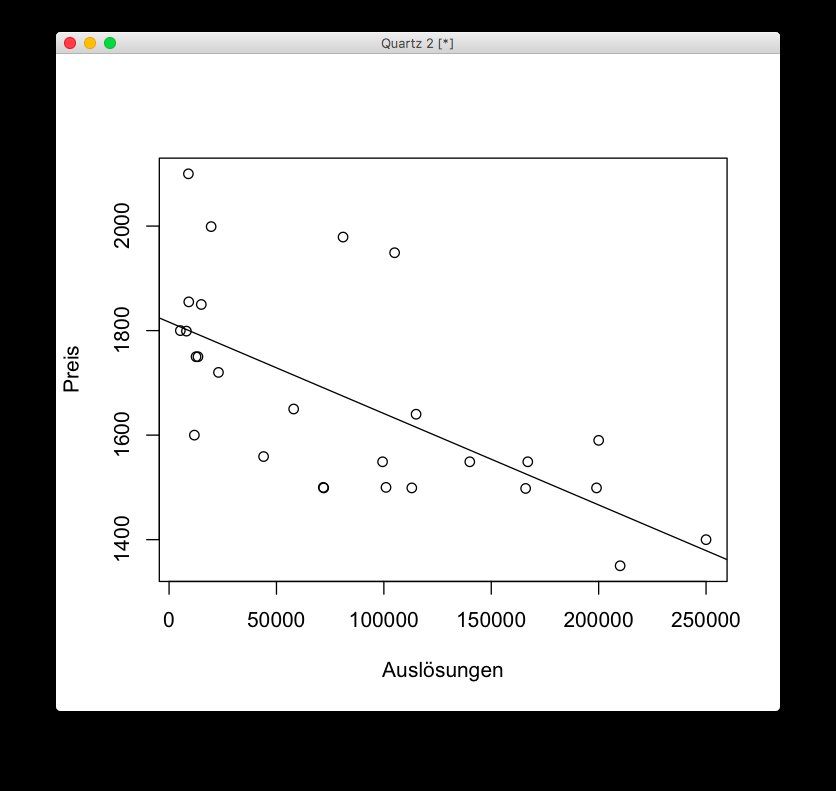
Abbildung 2: Visualisierung einer linearen Regression. Nach der Methode der kleinsten Quadrate ergibt sich die gezeigte Regressionsgerade.
In der linearen Regression legt man zunächst eine Linie in die Datenpunkte und misst dann die Abstände der Datenpunkte zu dieser Linie, die sogenannten Residuen. Sie quadriert man, um negative Vorzeichen loszuwerden, und summiert sie anschließend. Je besser die Linie zwischen die Datenpunkte passt, desto niedriger ist die Summe der quadrierten Abstände. Die Regression ist beendet, sobald man die Linie mit der geringsten Summe identifiziert hat. Anhand dieser Regressionslinie lässt sich nun ablesen, bei welcher Anzahl von Auslösungen welcher Preis für die gebrauchte Kamera angemessen ist.
Mit Abständen und Linien arbeiten auch Support Vector Machines (SVMs). Bereits in den 1930er- und 1950er-Jahren gab es Gedanken zu diesem Algorithmus, aber erst in den 1990ern gelang den Support Vector Machines der Durchbruch. Bei den SVMs geht es häufig um eine Klassifikation: Datenpunkte sollen voneinander in verschiedene Klassen getrennt werden. Wie bei der linearen Regression legt man dazu eine Linie zwischen die Datenpunkte. Allerdings arbeitet man nun nicht allein mit dieser Linie, sondern mit zwei Hilfslinien, den Support-Vektoren, die man parallel zur ersten Linie setzt. Nun gilt es, die Hauptlinie so zu positionieren, dass die Hilfslinien möglichst weit entfernt von ihr verlaufen, ohne dass Datenpunkte die Hilfslinien überschreiten. Abbildung 3 zeigt ein Beispiel dieses Verfahrens.
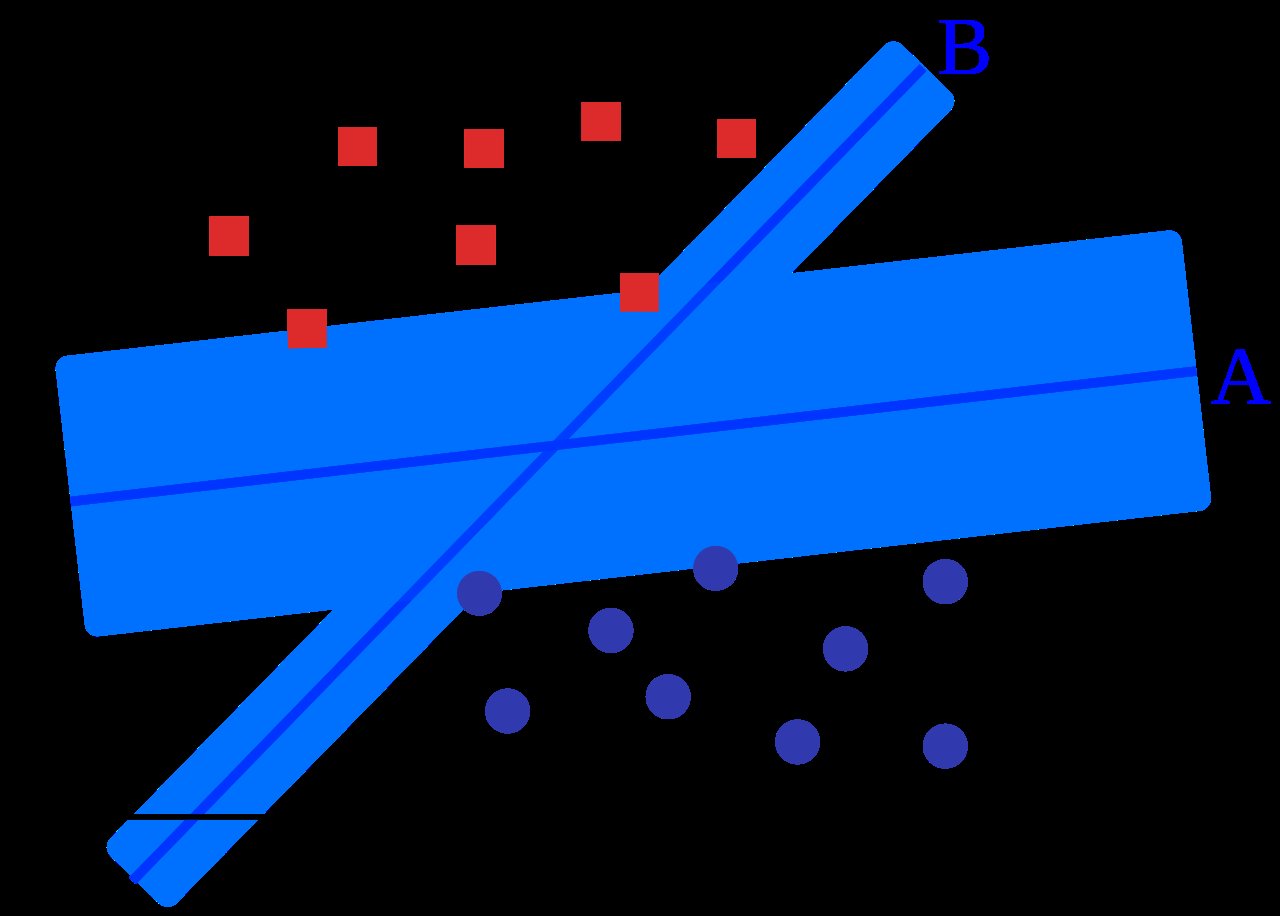
Abbildung 3: Visualisierung einer Support Vector Machine. Der Bereich um die Linien soll möglichst breit sein, ohne Datenpunkte einzuschließen. Dann sind die Punktgruppen optimal getrennt.
Nicht immer kann man die Hilfslinien so setzen, dass alle Datenpunkte außerhalb liegen. In diesem Fall berechnet man für jeden hereinragenden Datenpunkt einen Fehler (basierend auf dem Abstand zur Hilfslinie), bildet die Summe der Fehler und sucht dann nach der Position der Linie, die den geringsten Fehler aufweist. Das Besondere an Support Vector Machines: Man kann Dimensionen hinzufügen, um die Daten besser zu trennen – der sogenannte Kernel Trick.
Bei Naive Bayes handelt es sich um einen Algorithmus, der nicht auf Distanzen basiert. Er fußt auf dem (1763 posthum veröffentlichten) Satz von Thomas Bayes und funktioniert mit bedingten Wahrscheinlichkeiten. Hier geht es darum, mit welcher Wahrscheinlichkeit ein Fall (zum Beispiel das Ausfallen eines Kredits) unter Berücksichtigung einer bestimmten Bedingung (der Schuldner hat eine negative Schufa-Auskunft) eintritt. Allerdings wird es noch ein wenig komplizierter, denn meist ist nicht nur eine Bedingung gegeben, sondern mehrere, zum Beispiel ob der Schuldner Immobilien besitzt, ein Konto bei einer Bank hat und viele weitere Features. Diese Wahrscheinlichkeiten setzt man jeweils in Bezug dazu, wie häufig die jeweiligen Fälle insgesamt auftreten, also wie häufig jemand beispielsweise Immobilien besitzt. Der Algorithmus funktioniert übrigens nicht nur mit Zahlen, sondern auch mit Sprache. So basieren einige Spam-Filter auch (aber nicht nur) auf dem Naive-Bayes-Algorithmus.
In den letzten Jahren hat vor allem ein Algorithmus für viel Aufsehen gesorgt, XG Boost. Er stammt aus der Familie der Grading-Algorithmen, daher auch sein Name, Extreme Grading. Er stammt vom Entscheidungsbaum ab, einem seit Jahrzehnten aufgrund seiner Nachvollziehbarkeit beliebten Machine-Learning-Algorithmus. Hier trennt man Datenpunkte zunächst nach dem Kriterium, in dem sie sich am stärksten unterscheiden. Durch Kombination mehrerer Bäume (eines Ensembles) und starker und schwacher Modelle (das Boosting) lernt jeder Baum aus den Fehlern des vorherigen Baums (das Grading).
Reinforcement Learning wird häufig außerhalb der Kategorien Supervised und Unsupervised gesehen, da es gewissermaßen beide Ansätze miteinander verbindet. Algorithmen dieser Kategorie suchen ihre eigenen Strategien um zu lernen, und werden dann durch Feedback belohnt. Ein Beispiel für Reinforcement Learning ist Googles AlphaGo.
Performance-Messung
Insbesondere bei Klassifikationsmethoden benötigt man eine Kennzahl dafür, wie gut ein Modell gearbeitet hat. Für die Einschätzung ist jedoch nicht allein wichtig, wie häufig ein Modell richtig prognostiziert.
Angenommen, ein Modell sagt bei jeder Kreditentscheidung nein, dann hätte es auf jeden Fall alle Kreditausfälle richtig prognostiziert (True Positives). Die True-Positive-Rate bezeichnet man auch als Sensitivität (bekannt durch Corona-Tests). Dummerweise hätte die Bank dann aber auch kein Geschäft mehr gemacht, da das Modell auch die guten Transaktionen verhindert hätte (False Positives). Würde es dagegen alle Anträge gestatten, dann hätte es neben den korrekten Entscheidungen (True Negatives, deren Rate man auch als Spezifität bezeichnet) auch alle inkorrekten Entscheidungen zugelassen (False Negatives).
Idealerweise minimiert ein Modell also sowohl False Positives als auch False Negatives: Bei beiden Extremen geht die Bank pleite – entweder, weil sie gar kein Geschäft mehr macht, oder weil zu viele Kreditausfälle auftreten, die sich nicht mehr durch Krediteinnahmen kompensieren lassen. Die vier Werte der False und True Positives und Negatives bildet eine Confusion Matrix ab: Sie sagt genau, in welcher Kategorie der Positives und Negatives ein Algorithmus wie viele Fälle generiert. Damit lassen sich die Performance-Details zwar gut überblicken, doch der Vergleich mit anderen Modellvarianten fällt schwer, da die Performance nicht in Form einer Kennzahl vorliegt.
Eine Möglichkeit zum Erfassen einer solchen Kennzahl bietet die sogenannte ROC AUC. Das Kürzel steht für die sperrige Bezeichnung Receiver Operating Characteristics Area Under the Curve. Dahinter steckt der Ansatz, die Datenpunkte auf zwei Achsen zu plotten – eine für die Sensitivität, die andere für die Spezifität. Als Kennzahl verwendet man dann die Fläche unter der entstehenden Kurve (Abbildung 4). Bei einem Wert um die 0,5 wäre der Zufall genauso gut, unter 0,5 ist das Ergebnis schlechter als bei einer Zufallsentscheidung.
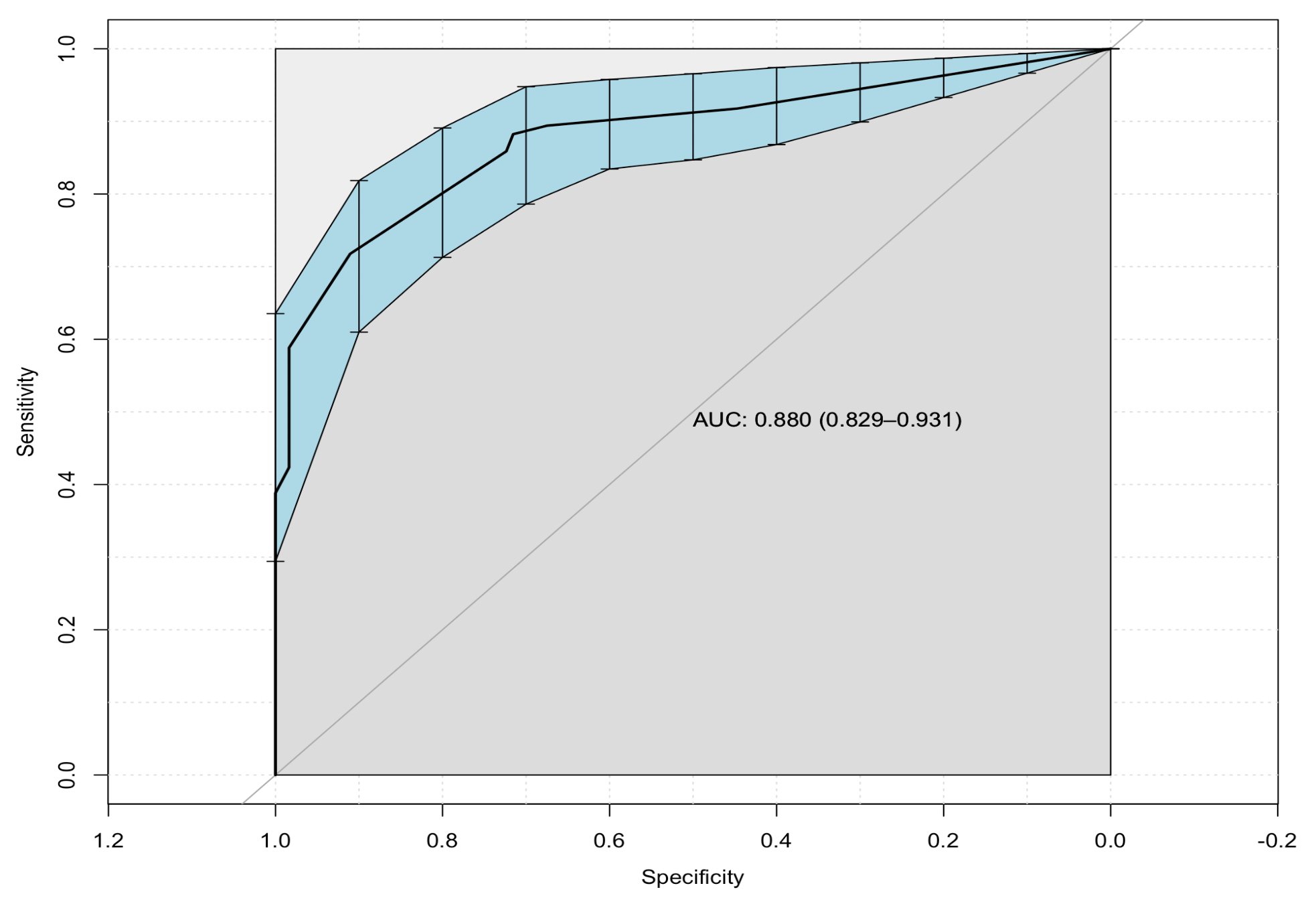
Abbildung 4: Visualisierung einer ROC AUC: Die Fläche unter der Kurve dient als Kennzahl für die Güte.
Eine andere Möglichkeit liefert die Precision Recall Curve: Die Precision ergibt sich hier aus dem Verhältnis der True Positives zur Summe der True und False Positives, der Recall ist dasselbe wie die Sensitivität.
All diese KPIs sagen allerdings nur bedingt etwas darüber aus, wie sich ein Modell nachher in der Wirklichkeit verhält. So ist es häufig sinnvoll, ein Modell gegen das bisherige Modell (oder gegebenenfalls manuelle Prozesse) in einem Split-Test laufen zu lassen. Um beim Beispiel der Bank zu bleiben: Hat das Modell für weniger Kreditausfälle gesorgt? Hinzu kommt, dass man ein Modell auch entwickeln und unterhalten muss, was Kosten verursacht. Rechnet sich dieser Aufwand?
Ein weiteres Thema, das viele Tutorials ignorieren: Ein Modell kann zwar gut funktionieren, aber eventuell diskriminiert es einen Teil der Menschen, die hinter den Datenpunkten stehen. Diese Erfahrung musste zum Beispiel der Erfinder von Ruby on Rails, David Heinemeier Hansson, machen [2], als seine Ehefrau ein zwanzig Mal schlechteres Limit für die AppleCard erhielt als er. Die AppleCard ist eine Kreditkarte von Apple, die Goldman Sachs herausgibt und die es bisher nicht in Deutschland gibt. Seltsamerweise hatte Mrs. Hansson einen besseren Credit Score (ein Pendant zum in Deutschland populären Schufa-Score) als ihr Gatte und war steuerlich mit ihm gemeinsam veranlagt. Das legt die Vermutung nahe, dass dass allein ihr Geschlecht der Grund dafür war, ihr ein schlechteres Limit zu geben.
Neben den reinen Messungen zur Leistung eines Algorithmus gilt es also auch zu testen, ob ein Algorithmus diskriminiert. Dazu könnte man zum Beispiel bei einem Kreditantrag exakt dieselben Daten eingeben, bis auf das Geschlecht oder eine andere Variable, die auf keinen Fall zu einer Benachteiligung führen darf. (jcb/jlu)
Der Autor
Tom Alby ist Autor mehrerer Bücher, Lehrbeauftragter für alle Angelegenheiten rund um Daten an mehreren Hochschulen und hat bei Unternehmen wie Bertelsmann, Google und bbdo gearbeitet. Heute ist er Chief Digital Transformation Officer bei Allianz Trade.
Infos
- Tom Alby, “Data Science in der Praxis” (Rheinwerk, 2022): https://www.rheinwerk-verlag.de/data-science-in-der-praxis/
- Tweet zur AppleCard. https://twitter.com/dhh/status/1192540900393705474





