
© luckybusiness / 123RF.com
Auch etliche Jahre nach dem Docker-Schock ebbt das Container-Thema nicht ab, im Gegenteil: Kubernetes und Co. sind präsenter denn je. Während sich die großen Unternehmen auf die neue Technik stürzen, fragen sich KMUs, ob sie auch vom Hype profitieren können.
Hypes sind in der IT keine Besonderheit, und jedem Hype schlägt anfangs das natürliche Misstrauen von Admins entgegen, die sich mit dem neumodischen Kram eher nicht befassen wollen. Das war beim Cloud Computing so, das viele für eine Eintagsfliege hielten, und auch während des Siegeszugs des Flottenorchestrierers Kubernetes, den so mancher Beobachter a priori kategorisch ausschloss.
Im Jahre 2022 ist klar: Kubernetes und Container sind gekommen, um zu bleiben. Vielerorts sind die Vorteile der Lösung so groß, dass Admins schnell vom Container-Skeptikern zum Container-Enthusiasten mutierten. Das gilt besonders für große Firmen und Corporate-Umgebungen: Einer Studie von Suse [1] zufolge beschäftigen sich Unternehmen, deren IT-Budget über 10 Millionen Euro pro Jahr liegt, zu über 60 Prozent mit Cloud-native-Anwendungen, während das Thema bei kleineren Firmen unter ferner liefen rangiert.
Schnell entsteht der Eindruck, Container böten für kleinere Unternehmen nur wenig oder gar keinen Mehrwert. Aber stimmt das tatsächlich? Haben Firmen wirklich nichts von Kubernetes, wenn ihr IT-Fuhrpark kleiner ist und keine Server-Flotte von Tausenden Geräten zur Verfügung steht? Dieser Artikel geht dieser Frage auf den Grund und zeigt, wie auch kleinere Firmen von Kubernetes durchaus profitieren.
Begriffe abgrenzen
Um die Vorzüge moderner Technologien auch für kleinere Unternehmen zu erkennen, ist es hilfreich, Begrifflichkeiten scharf zu trennen. Zwar werden gerade im öffentlichen Diskurs Begriffe wie Container, Kubernetes, Cloud-native und Microarchitecture kunterbunt vermischt und zum Teil synonym benutzt, mit der Realität hat das aber nur wenig zu tun. Klar ist: Container und Kubernetes sind nicht dasselbe, und die Nutzung von Containern erzwingt auch nicht die Verwendung moderner Anwendungen, die dem Mikroarchitekturansatz folgen.
Es ergibt deshalb Sinn, Container einerseits und ihr Flottenmanageent andererseits getrennt voneinander zu betrachten, um die Sweet Spots für KMUs zu identifizieren. Zunächst geht es deshalb nur und ausschließlich um Container. Ein Container ist ja per Definition erst einmal nur das Dateisystem eines (minimalen) Linux-Systems in Kombination mit einer darin installierten Anwendung. Je nach genutzter Container-Technik gibt es auch die Option, Volumes als persistenten Speicher an einen Container anzuschließen. Das sorgt dafür, dass sich auch herkömmliche Anwendungen wie Datenbanken sinnvoll in Containern betreiben lassen.
Das klassische Setup
Um den praktischen Nutzen von Containern im Alltag zu erörtern, hilft ein Blick in das klassische IT-Setup der Nullerjahre, das unverändert bis heute vielerorts im Einsatz ist. Und das hat mit der modernen Container-Welt nicht viel zu tun.
Zunächst gilt: In diesen typischen Setups hat jedes System eine feste, ihm zugewiesene Aufgabe. Weil selbst Virtualisierung in vielen Fällen keine Rolle spielt, gibt es eine statische Bindung zwischen einem System und der Anwendung, die darauf läuft. Die Basis eines solchen Systems bildet fast immer eine der klassischen Linux-Distributionen, etwa AlmaLinux oder Ubuntu.
Obwohl viele Firmen von sich behaupten, einen hohen Grad in Sachen Automation zu erreichen, sind solche Systeme oft genug mühsam von Hand gepäppelte Einzelinstallationen. Weil jede moderne Distribution mit einem Paketmanager wie Rpm oder Dpkg (Abbildung 1) daherkommt, machen Unternehmen davon bis heute vielerorts ausgiebigen Gebrauch. Die benötigte Userland-Software kommt deshalb als Paket auf das System, und die Konfiguration hinterlegt der Admin entweder per Hand oder aus seiner Automation heraus. So weit, so bekannt.
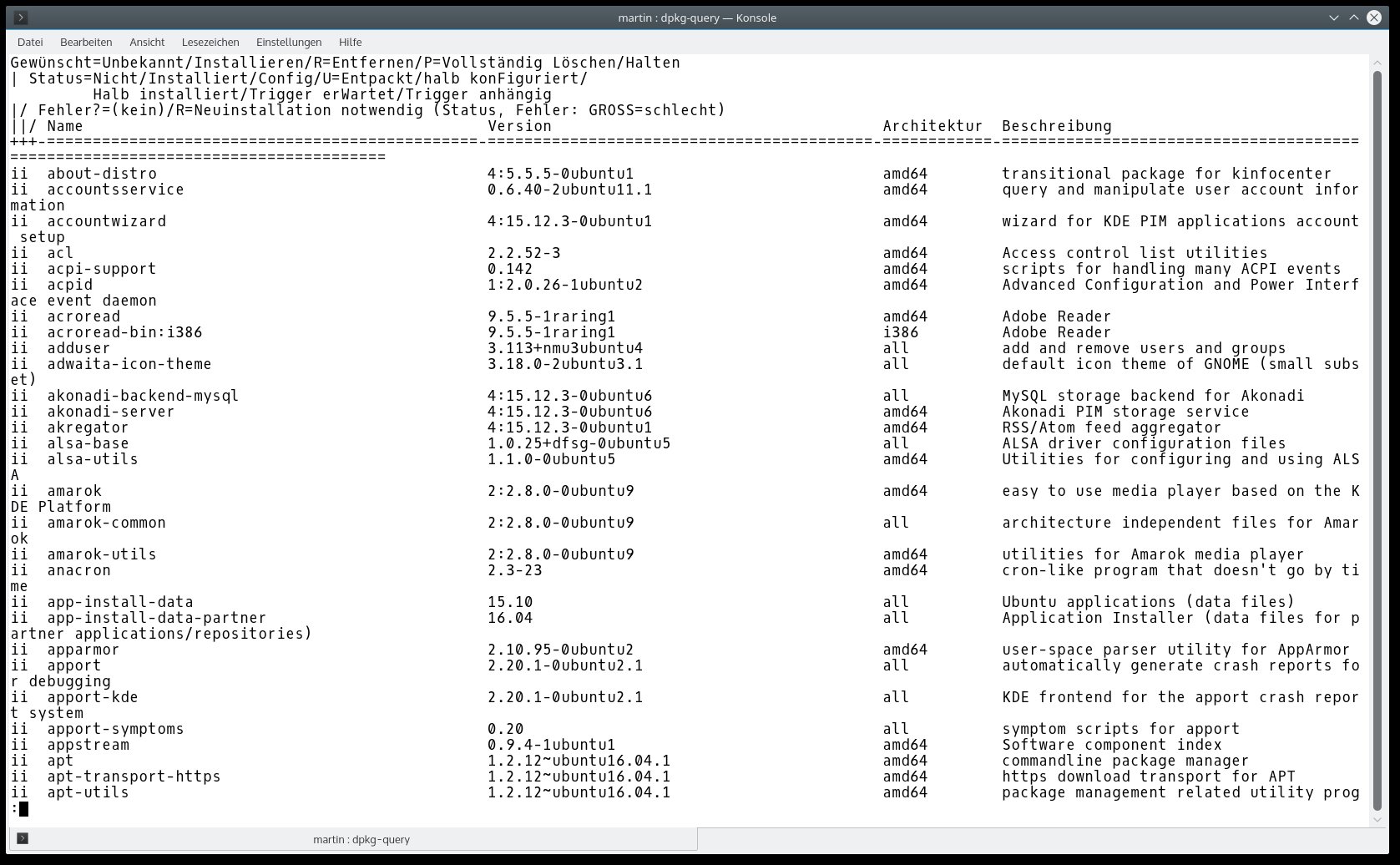
Abbildung 1: In klassischen Umgebungen ist die Verwaltung von Software die Aufgabe des Paketmanagers. Das führt nicht selten in die gefürchtete Abhängigkeitshölle, weil Pakete aus verschiedenen Quellen aufeinandertreffen.
Wohl jeder Admin mit etwas Berufserfahrung hat schon einmal vom Begriff der Abhängigkeitshölle gehört. Gemeint ist ein Problem, das auf Linux-Systemen vor allem dann gern auftritt, wenn der Admin sich mit dem Paketfundus der eigenen Distribution nicht zufrieden geben kann oder will und externe Softwareverzeichnisse einbindet. In vielen Fällen ist das gar nicht zu vermeiden.
Wer auch auf älteren Distributionen noch aktuelle Software haben will, bekommt diese oft ausschließlich über das Repository des jeweiligen Herstellers. Und wenn der dann noch beschließt, dass der Paketumfang beispielsweise von CentOS 7 nicht ausreicht, sondern auch noch das EPEL-Verzeichnis für CentOS 7 benötigt wird, kann der Admin sich warm anziehen. Spätestens bei einem Update auf eine neuere Version der Linux-Distribution fliegen dem Systemverwalter solche Systeme nicht selten um die Ohren. Die beteiligten Parteien – CentOS, EPEL und der jeweilige Hersteller – legen dann in der Regel die Hände in den Schoß und erklären sich für nicht zuständig. Dem Admin bringt das wenig, wenn er ohne funktionierende Rechner dasteht.
Die Linux-Distributoren haben dieses Problem bereits vor mehreren Jahren erkannt und begegnen ihm aktiv mit Containern. Der große Vorteil eines Containers: Er hat sein gesamtes Userland im Schlepptau. Ein fertiges Container-Abbild lässt sich auf jedem System ohne Probleme ausführen, das eine Runtime für Container hat – und zwar auch dann, wenn darauf mit Ausnahme der Grundkomponenten und der Container-Umgebung keine zusätzliche Software vorhanden ist.
Weil dieses Vorgehen auch für die Linux-Distributoren und die Anbieter von Programmen große Vorteile bietet, hat sich das Container-basierte Vorgehen aktuell als faktischer Standard etabliert. Insbesondere Anbieter von Software haben mit Containern die Möglichkeit, ihre Lösungen exakt so zum Kunden zu liefern, wie sie es im eigenen Labor getestet haben. Sie bauen nur noch einen Container mit Laufzeitumgebung für sämtliche Linux-Distributionen, statt ein Paket für jede Version jeder Distribution, aufgeteilt in RPM- und DEB-Pakete (Abbildung 2).
Abbildung 2: In Umgebungen, die auf Containern basieren, laufen Anwendungen mit ihrem gesamten Userland darin. Abhängigkeiten spielen anders als bei der Paketverwaltung der eigenen Distribution keine Rolle mehr.
Vereinfachung und mehr Effizienz
Die vereinfachte Verwaltung einzelner Systeme ist für kleine Unternehmen realistisch betrachtet bereits ein Anreiz, sich mit der Technik von Containern genauer zu befassen. Denn gerade dann, wenn eine IT-Abteilung nicht sonderlich groß ist, ist sie ja auf ein hohes Maß an Effizienz zwingend angewiesen. Je weniger Aufwand laufende Systeme also im Alltag hervorrufen, desto besser ist das aus Sicht des Unternehmens. Container erfüllen diese Anforderung zunächst auf der Ebene der Anwendung. Denn wenn sich eine Anwendung ohne externe Abhängigkeiten in kürzester Zeit so ausrollen lässt, dass sie bloß noch eine Konfigurationsdatei und persistenten Speicher benötigt, verursacht das deutlich weniger Aufwand als die Installation per Paket.
Obendrein erlaubt dieses Prozedere auch deutlich leichtere Updates: Regelmäßig aktualisieren Administratoren ihre Container-Workloads, indem sie den alten Container stoppen, nachdem sie den neuen bereits heruntergeladen haben. Dann verbinden sie das bestehende persistente Volume mit einem neuen, auf Basis des frischen Images gestarteten Containers. Die meisten Anwendungen, die Daten verwalten, merken, wenn sie auf einen Datensatz einer Vorgängerversion treffen und aktualisieren ihn automatisch, wie etwa bei MariaDB zu beobachten. Unmittelbar danach steht die Datenbank in der neuen Version bereits zur Verfügung. Und nicht nur das: Geht beim Update etwas schief, ist es mit dem alten Image und einem Snapshot des persistenten Speichers relativ leicht, zum Zustand vor dem Update zurückzukehren.
Container bieten zudem auf der Systemebene eine Vereinfachung und Steigerung der Effizienz. Wenn die eigenen Systeme nur noch Container betreiben, fällt ein Großteil der Aufgaben der alltäglichen Wartung weg. Es muss dann etwa kein komplettes CentOS mehr sein, sondern es genügt auch ein CoreOS, also ein minimales Betriebssystem. Das kann außer dem Betrieb von Containern nicht viel, doch reicht genau das für die genannten Zwecke ja völlig aus.
Automation ist Trumpf
Für KMUs bietet die Verlagerung von Workloads in Container sogar die Möglichkeit, zum Sprungbrett in Sachen Automation zu werden. Wie bereits erwähnt überschätzen viele Admins den Grad der Automation im eigenen Umfeld gnadenlos.
Dafür gibt es eine Vielzahl von Gründen. Mal gehen Firmen (meist fälschlicherweise) davon aus, dass die Implementierung von Automation sich ohnehin nicht lohne, weil man viele Aufgaben bloß einmal ausführt. Mal sehen Unternehmen vor lauter Handarbeit gar keine Möglichkeit mehr, sich mit Automation zu befassen. Und mal verlaufen großspurig angekündigte Automationsprojekte im Sand, weil sich herausstellt, dass die Automation konventioneller Systeme in der Praxis viel komplizierter ist, als es in der Theorie den Anschein hat.
Betriebssystem-Container bieten hier einen Ausweg. Wer ein fertiges Container-Abbild vom Anbieter beziehen kann, erspart sich einen großen Teil der Verwaltung der App auf dem eigenen System. Mit Werkzeugen wie Ansible ist es relativ leicht, eine Konfigurationsdatei an der passenden Stelle im Betriebssystem zu hinterlegen und danach den Container mit den richtigen Parametern zu starten. Mithin machen Container auch die Implementierung von Automation wesentlich leichter.
Rumpfbetriebssysteme wie CoreOS haben zudem den Vorteil, dass ihre Automation nur ein einmaliger Vorgang ist, der sich danach beliebig oft reproduzieren lässt. Wer den Wald seiner Anwendungen erfolgreich vom Blech in den Container verlagert hat, sieht in der Schaffung einer AutoYaST- oder Kickstart-Konfiguration für seine lokale Umgebung eher keine große Herausforderung mehr. Quasi im Vorbeigehen lässt sich so allerdings auch ein Bare-Metal-Lifecycle-Management etablieren, das im Alltag weitere manuelle Arbeiten für immer eliminiert und so für mehr Effizienz sorgt. All das funktioniert weitgehend ohne den Zwang zu CI/CD-Systemen, die über manchem Container-Setup wie ein Damoklesschwert schweben – meist völlig unbegründet.
Zwischenfazit
Ein erstes Zwischenfazit ist mithin klar: Das Verlagern von Anwendungen in Container liefert offensichtlichen Mehrwert auch und gerade im Hinblick auf Wartbarkeit und Automation, ohne dass das Prinzip Cloud-nativer Anwendungen oder Kubernetes auch nur irgendwie Teil der Gleichung sein müssen.
Wer im Unternehmen regelmäßig viel Zeit für die Durchführung der immer selben händischen Aufgaben investiert, findet in Containern in der Kombination mit einem Automatisierer wie Ansible einen guten Einstieg hin zu besserer Wartbarkeit und deutlich mehr Automation. Mini-Linux-Distributionen reduzieren den Aufwand der Wartung weiter und bieten die Chance, ein umfassendes Baremetal-Lifecycle-Management zu etablieren.
Deutlich weniger ausgeprägt ist dieser Effekt naturgemäß, wenn sich die zu betreibende Anwendung nicht als fertiger Container vom Anbieter beziehen lässt. Selbst in solchen Situationen zahlt es sich dennoch in den meisten Fällen aus, die Anwendung selbst in einen Container zu packen und zu betreiben. Wer sich bei Docker Hub bedient, achte auf die Nachvollziehbarkeit der Inhalte der Container.
Und Kubernetes?
Dass auch Kubernetes in kleineren Umgebungen durchaus eine Daseinsberechtigung haben kann, ergibt sich automatisch, wenn man das bis hierhin gestaltete Szenario weiterspinnt.
Angenommen, der Admin hat viel Arbeit investiert, um ein klassisches, konventionelles Setup in Container zu verpacken: Er wird bald merken, dass der Betrieb von Containern ganz ähnlich wie der Betrieb klassischer Anwendungen mit ein paar Herausforderungen einhergeht. Wer etwa eine Datenbank betreibt, braucht Hochverfügbarkeit. Daran hat sich in den letzten 20 Jahren praktisch nichts geändert. Geändert haben sich aber die Werkzeuge, die dem Admin für die Realisierung eines solchen Setups zur Verfügung stehen, was sich anhand eines einfachen Vergleichs gut beweisen lässt.
Bis zum Aufkommen des Cloud Computings und skalierbarer Umgebungen bestanden Setups von Datenbanken regelmäßig aus mehreren Komponenten. Die Grundlage waren zwei Server, zwischen denen der Admin mittels Cluster-Manager – in der Regel Pacemaker (Abbildung 3) – eine Verbindung schuf. Eine Shared-Storage-Lösung wie DRBD kümmerte sich darum, dass die Daten wahlweise auf dem einen oder dem anderen Knoten zur Verfügung stehen. Zusammen mit einer virtuellen IP-Adresse wanderte die Datenbank dann als Ressource in Pacemaker von Knoten A nach Knoten B oder in die andere Richtung, je nachdem, welcher Knoten gerade den Geist aufgegeben hatte.
Setups dieser Art sind allerdings nur bedingt vergnügungssteuerpflichtig: Auch wenn Andrew Beekhof in den vergangenen Jahren viel geleistet hat, um Pacemaker benutzerfreundlicher zu machen, ist die Software immer noch hochkomplex. Die meisten Admins werden ein Setup dieser Art vermeiden, wenn sie eine Möglichkeit dafür sehen.
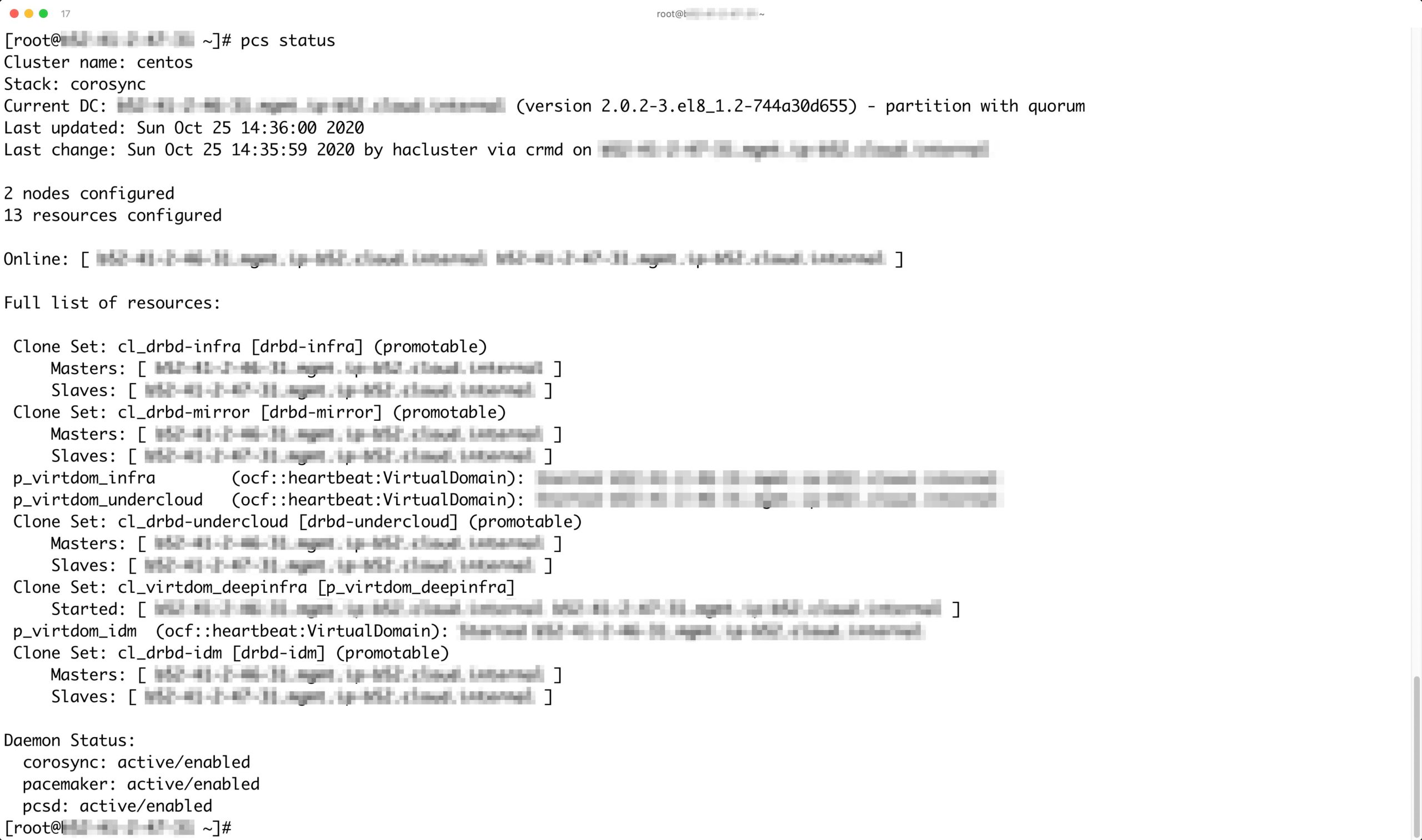
Abbildung 3: Ein Pacemaker-Setup aus der guten alten Zeit, im Bild allerdings für den Betrieb virtueller Maschinen und nicht für MariaDB. Komponenten wie Pacemaker lassen sich mit Kubernetes gut ersetzen, wenn es um den Betrieb bestimmter Dienste geht.
Kubernetes als Alternative
Mancher Systemverwalter wird nun mit Fug und Recht behaupten, dass die Antwort auf die überbordende Komplexität von Pacemaker ja wohl kaum Kubernetes sein könne, das selbst mit einer gehörigen Portion Komplexität daherkommt. Das Argument scheint nachvollziehbar, greift tatsächlich aber zu kurz. Kubernetes bietet heute zwar fraglos eine riesige Menge Funktionalität, doch ist diese für die allermeisten Setups gar nicht relevant.
Wie in den meisten Fällen, in denen eine Software klein und übersichtlich beginnt und dann durch einen Hype für immer mehr Einsatzbereiche erweitert wird, gilt auch für Kubernetes das Pareto-Prizip: 80 Prozent der Anwender lassen sich mit 20 Prozent der Kubernetes-Features problemlos zufriedenstellen, also mit den ganz grundlegenden Kubernetes-Funktionen.
Dass gerade im Beispiel der Datenbank Kubernetes eine echte Alternative sein kann, zeigt das oben beschriebene Beispiel aus der Kubernetes-Sicht. Hier braucht der Admin zwar nicht zwei Server, sondern vier, aber nicht alle müssen hochgezüchtete Monster mit viel CPU und RAM sein. Zentrale Komponenten wie jene, die zu Kubernetes gehören, lassen sich stattdessen problemlos auch in virtuelle Maschinen verpacken, die auf einem eventuell bereits vorhandenen Virtualisierungs-Cluster mitlaufen können. Faktisch gilt das auch für die Systeme, die später die Container betreiben sollen – hier sollte dann aber genug Kapazität in Form von vCPUs und vRAM zur Verfügung stehen.
Welches Kubernetes?
Im nächsten Schritt stellt sich die Frage, welche Kubernetes-Distribution der Admin für sein Setup auswählt. OpenShift von Red Hat (Abbildung 4), Rancher von Suse und etliche andere Varianten buhlen am Markt um die Gunst der Admins. Hier ist jedoch Vorsicht geboten, denn den Funktionsumfang von OpenShift wird ein einzelner Admin mit überschaubarem Setup eher selten benötigen. Im Gegenzug produziert ein ausgewachsenes OpenShift allerdings einiges an Wartungsaufwand, den zu leisten sich für KMUs in vielen Fällen nicht lohnen dürfte.
Abbildung 4: Zwar bieten große Kubernetes-Distributionen wie OpenShift enorm großen Funktionsumfang, doch in vielen Fällen ist der in KMUs gar nicht notwendig. Quelle: Red Hat
Es lohnt sich stattdessen, sich am Markt einmal nach Alternativen zu den großen Lösungen umzusehen. Ein guter Kandidat gerade für kleinere Umgebungen ist beispielsweise MicroK8s [2], das mit sehr wenig Schnickschnack daherkommt und von Canonical stammt. Ebenfalls eine Option kann K3s [3] sein, das sich zwar für eine IoT- und Edge-Variante von Kubernetes hält, aber dennoch eine vollständige Kubernetes-API und mithin alle relevanten Funktionen mitbringt. Sogar die Upstream-Version von Kubernetes kommt mit einer entsprechenden Distribution namens Minikube [4] daher, die lokal schnell einen einfachen Kubernetes-Cluster hochzieht.
Die Entscheidung, welches der Mini-Systeme infrage kommt, muss der Admin letztlich auch auf der Grundlage eigener Präferenzen selbst treffen.
HA-MySQL in kurzer Zeit
Zurück jedoch zum ursprünglichen MySQL-Beispiel. Ist ein Kubernetes-Cluster aus dem Boden gestampft, sind die verbliebenen Schritte bis hin zur hochverfügbaren Datenbank auf Basis von MariaDB oder MySQL schnell erledigt. Kubernetes bietet in seiner API alle hierfür benötigten Funktionen an, etwa Replica Sets oder Stateful Sets (Abbildung 5). Es fehlt also nur noch ein passendes Image mit der benötigten Software, im Beispiel Galera, doch das findet sich etwa auf Docker Hub in guter Qualität und mit nachvollziehbarer Herkunft.
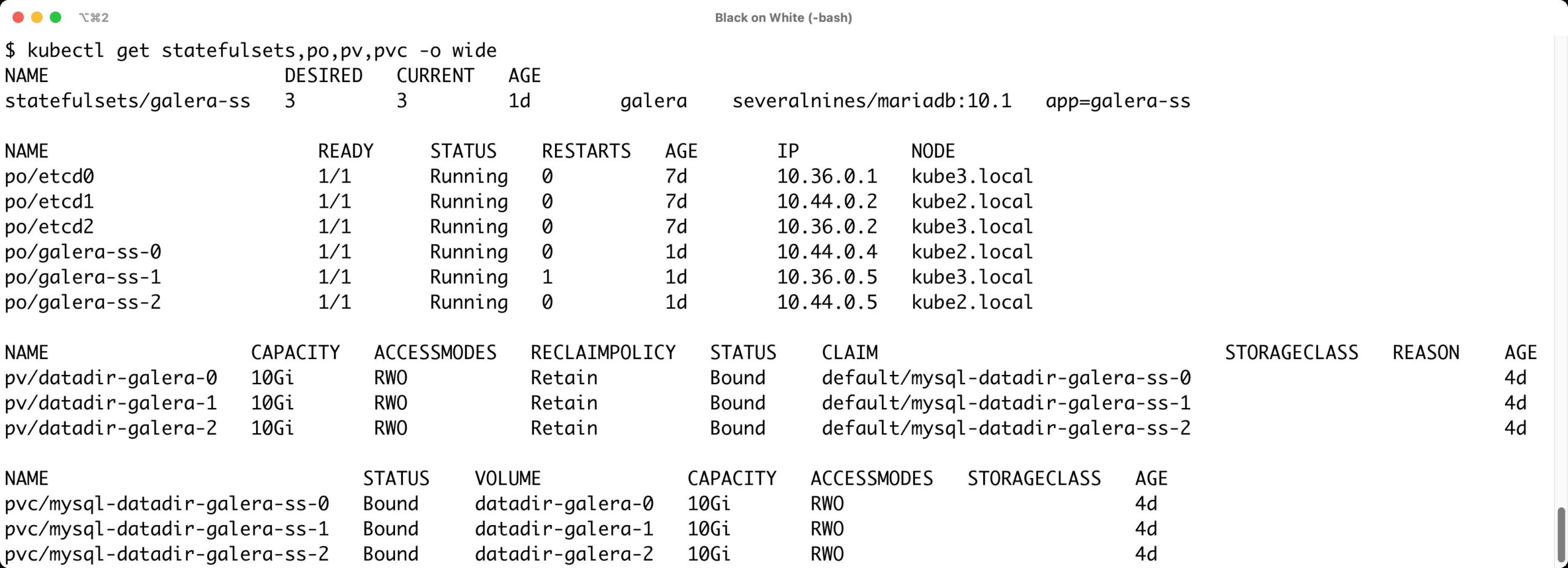
Abbildung 5: Mittels eines Stateful Sets lässt sich ein Galera in Kubernetes leicht und weitgehend automatisiert betreiben. Das birgt gegenüber dem klassischen Ansatz ganz erhebliche Vorteile.
Der Rest ist schnell erledigt: Wer Kubernetes etwa per Stateful Set um eine MariaDB-Instanz mit Galera erweitern möchte, legt die entsprechenden Pod-Definitionen in einer YAML-Datei an, spielt diese in den Cluster und hat wenige Sekunden später eine hochverfügbare, skalierbare Datenbank mit persistentem Speicher. Mehr noch: Kubernetes wird sich aktiv um den Betrieb der Datenbank kümmern und ausgefallene Pods durch neue ersetzen, falls mal ein Stück Hardware den Geist aufgibt.
In Summe ist solch ein Setup auf einer herkömmlichen Linux-Distribution mithin einfacher zu erstellen als ein konventionelles, doch bietet es im Nachgang mehr Funktionalität. Und das gilt nicht nur in Sachen MariaDB: Schließlich hätte der Admin auf einem einmal eingerichteten Kubernetes auch die Möglichkeit, andere Dienste zu betreiben, für die bis dahin eigene Hardware zum Einsatz kommt. Kubernetes erlaubt mithin auch KMUs eine echte Konsolidierung des eigenen Server-Parks. Weniger Blech, das es individuell zu pflegen gilt, ist grundsätzlich gut, weil es Zeit spart.
Cloud-native als Sahnehäubchen
Schließlich stellt sich die Frage, ob auch kleinere Unternehmen von der bunten Welt der Cloud-native-Anwendungen profitieren können. Zur Erinnerung: Cloud-native bzeichnet eine Art der Applikationsentwicklung, die ohne große Monolithen auskommt und stattdessen ein Geflecht aus Kleinstprogrammen darstellt, die über definierte Schnittstellen miteinander kommunizieren. Jede Mini-App hat dabei eine einzige, spezifische Aufgabe.
Das Modell hat in der Praxis viele Vorteile: Es ermöglicht zum Beispiel, die einzelnen Komponenten völlig unabhängig voneinander zu entwickeln, und erzwingt keinen gemeinsamen Release-Zyklus. Es sorgt so implizit auch dafür, dass die befürchteten Release Days ihren Schrecken verlieren, bei denen eine riesige, monolithische Anwendung nach Monaten der Entwicklung ihren Weg endlich in die Produktion findet. Oft genug finden Unternehmen erst zu diesem Zeitpunkt heraus, was alles nicht klappt, und treten hektisch den Rückzug an. Das Modell der Cloud-native-Entwicklung beugt diesem Problem vor.
Allerdings: In vielen KMUs finden sich gar keine selbstentwickelten Anwendungen, die diese Probleme hätten. Das gilt umso mehr, wenn das IT-Geschäft gar nicht im Fokus des eigenen Unternehmens steht, sondern die IT Mittel zum Zweck ist. Wer keine Anwendungen selbst entwickelt, profitiert vom Cloud-native-Prinzip folgerichtig erst einmal gar nicht. Wer hingegen bestehende Applikationen von altem Zuschnitt hat, kann aus der Migration hin zum Cloud-native-Ansatz durchaus profitieren. Viele Großunternehmen haben vorgemacht, wie das gehen kann: Hier hat man konsequent alte Zöpfe abgeschnitten und zum Teil Anwendungen, die man seit Jahrzehnten genutzt hat, verworfen und nach dem Cloud-native-Ansatz neu gebaut. Das setzt freilich den Luxus voraus, dafür die Zeit und die Ressourcen zu haben. In vielen KMUs dürfte genau das nicht der Fall sein.
Cloud-native-Komponenten können helfen
Trotzdem kann es sich aus Admin-Sicht durchaus lohnen, sich mit einigen Prinzipien des Cloud-native-Designs genauer auseinanderzusetzen. Auch wenn die eigene Anwendung ein im Container betriebener Monolith ist, hat der Cloud-native-Ansatz nämlich durchaus ein paar Änderungen eingeführt, die auch außerhalb nativer Cloud-Apps Sinn ergeben. Ein gutes Beispiel dafür bieten die sogenannten Sidecars, die sich in Kubernetes als Nebenanwendung zu den Containern mit den eigentlichen Anwendungen installieren lassen. Im Beispiel von oben mit MariaDB und Galera könnte ein solches Sidecar beispielsweise durchaus Mehrwert bieten.
Die Rede ist dabei von Istio (Abbildung 6). Bei Istio handelt es sich um ein Werkzeug, das eigentlich in Mikro-Apps die Verbindungen zwischen den einzelnen Komponenten steuert, verschlüsselt und als Load Balancer fungiert. Auch ein Galera-Cluster braucht aber einen Load Balancer, um sinnvoll für Clients erreichbar zu sein, denn den meisten Datenbank-Clients kann man nicht mehrere IP-Adressen mit auf den Weg geben. Obendrein wäre das auch nicht elegant, weil der Client sich im ungünstigsten Szenario dann mit einer Galera-Instanz verbinden könnte, die gerade nicht funktioniert.
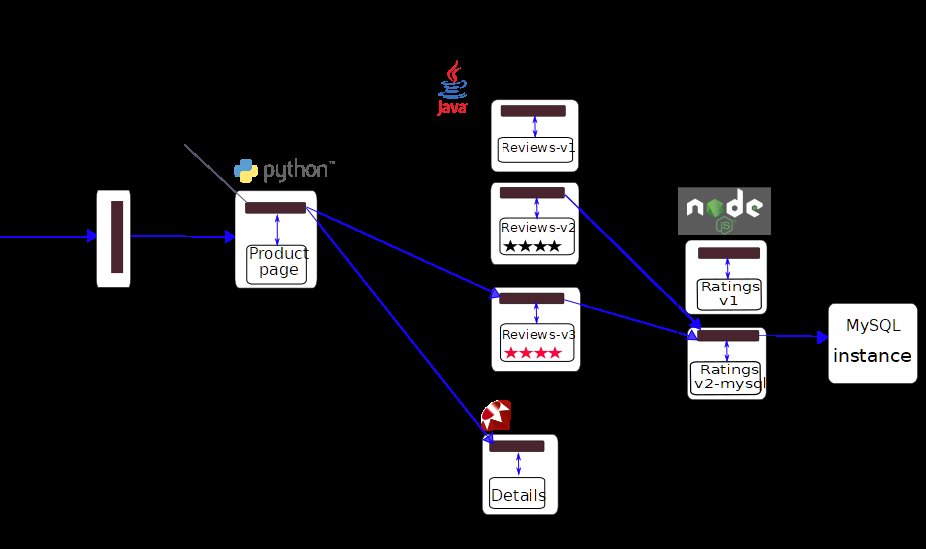
Abbildung 6: Istio ist zwar eigentlich für die Welt der “Cloud-native”-Anwendungen gemacht, doch lässt es sich auch mit konventionellen Diensten wie MySQL oder Galera gut verwenden. Quelle: Istio
Kubernetes stellt in Form der Service-IP nur einen einfachen Balancer zur Verfügung. Istio kann viel mehr und lässt sich als Sidecar zu Galera durchaus auch ausrollen. Und weil Istio in Kubernetes als hochverfügbare Komponente läuft, erspart der Admin sich auf diesem Weg sogar den Betrieb eines eigenen Load Balancers, ganz gleich, ob der Linux nutzt oder in Form einer Appliance daherkommt.
Warnende Worte
Bei aller Euphorie über Container-Orchestrierung und den Mehrwert, den Container auch für kleine Unternehmen zweifelsohne bringen, darf eine Warnung am Ende dieses Artikels nicht fehlen. Das Linux-Magazin hat diese Warnung bereits mehrfach publiziert, doch hat sich am Problem seither kaum etwas geändert.
Die Idee, eine Anwendung mitsamt dem zugehörigen Userland als Container zu verschiffen, hat viele Vorzüge. Unternehmen sollten von durch Anbietern bereitgestellten Abbildern aber nur Gebrauch machen, wenn sich zweifelsfrei nachvollziehen lässt, wie diese gebaut werden, und wenn sichergestellt ist, dass der Hersteller seine Abbilder regelmäßig pflegt.
Wenn das nicht der Fall ist, ist es in den meisten Fällen eine gute Idee, in den sauren Apfel zu beißen und die Anwendung auf eigene Faust in einen Container zu packen. Ein CI/CD-System dafür lässt sich, wie bereits beschrieben, auch ohne große Mengen an Enterprise-Hardware implementieren. Der Mühe Lohn ist die Gewissheit des Admins, auf Probleme wie sicherheitsrelevante Bugs schnell reagieren zu können, ohne am Fliegenfänger des Anbieters zu hängen.
Kunden von Unternehmen, die ihre Anwendung als Black-Box-Container zur Verfügung stellen, sollten dem Lieferant gegenüber zudem klar und deutlich artikulieren, dass das inakzeptabel ist. Schon im eigenen Interesse sollten Admins Container nur dann produktiv einsetzen, wenn sie deren Innenleben kennen und verstehen.
Fazit
Die im Text vorgetragenen Beispiel sind genau das – Beispiele, die nur einen winzigen Einblick in die Möglichkeiten von Containern und Kubernetes für KMUs bieten. Klar ist aber: Nicht nur riesige Unternehmen profitieren von Containerisierung, sondern durchaus auch KMUs. Kubernetes ist leichter zu betreiben und zu warten als konventionelle Setups, kommt mit vielen Automatismen daher und skaliert besser in die Breite als seine ursprünglichen Vorgänger.
Selbst wer sich mit Kubernetes nicht anfreunden möchte, findet im Trend hin zu Containerisierung viele gute Ansätze, die eigene Installation leichter zu warten und effizienter zu machen. Sowohl Container als auch Kubernetes unterstützten KMUs letztlich dabei, den Grad der Automation zu erhöhen. Und der ist in kleinen Unternehmen fast noch wichtiger als in großen Konzernen, eben weil IT hier oft nur ein Nebenkriegsschauplatz ist, für den chronisch zu wenig Personal zur Verfügung steht. Es gilt: Je mehr Automation, umso besser. Container und Kubernetes leisten dazu einen echten Beitrag.
Infos
- IDG-Studie zu Cloud-native Applications: https://www.suse.com/c/idg-study-cloud-native-2022-where-do-european-companies-stand-in-their-digital-transformation/
- Microk8s: https://microk8s.io
- K3s: https://k3s.io
- Minikube: https://kubernetes.io/de/docs/setup/minikube/





