
© Karsten Neglia, 123RF
Zu den größten Risiken für Unternehmen und öffentliche Einrichtungen zählen kriminelle Angriffe auf die IT-Infrastruktur. Wer sich über deren Abwehr informiert, stößt häufig auf das Buzzword maschinelles Lernen. Dieser Artikel untersucht, was das mit Cybersecurity zu tun hat.
Zwar wird bei den Anwendungen des maschinellen Lernens immer ein großer Aufwand in die Vorverarbeitung der Daten gesteckt, doch können die Algorithmen auch selbsttätig Strukturen erkennen. Gerade bei dieser Feature Extraction gab es weitere Fortschritte durch das sogenannte Deep Learning. Das macht Machine-Learning-Algorithmen gerade für Cybersecurity-Aufgaben noch interessanter.
In der IT-Sicherheit liegen oft sehr viele Daten vor, deren Interpretation extrem viel Aufwand verursacht, sei es aufgrund ihrer Menge oder ihrer Komplexität. So verwundert es nicht, dass die Hersteller von Cybersecurity-Produkten spezielle Machine-Learning-Toolkits anbieten wie Splunk [1] oder scheinbar fast komplett auf Machine Learning setzen wie Darktrace [2].
Zwar hat Machine Learning (ML) die Cybersecurity-Welt nicht plötzlich komplett umgedreht (auch wenn manche Produktanbieter das glauben), doch sollte man sich zu den folgenden Aspekten schlau machen – und sei es nur, um auf dem Laufenden zu bleiben:
- Welche Machine-Learning-Prinzipien greifen in Bereich der Cybersecurity?
- Wie sehen typische Szenarien für Verteidigung und Angriff aus?
- Welche Trends sind im Bereich der Kombination von Machine Learning und Cybersecurity zu erwarten?
Diese Fragen versucht der Artikel im Folgenden zu beantworten, ohne dabei einen Anspruch auf Vollständigkeit zu erheben.
![]()
Mehr zur Cybersecurity sowie vielen weiteren Themen bieten die Frankfurter IT-Tage, die in diesem Jahr Corona-bedingt virtuell vom 7. bis 10. Dezember stattfinden. In 13 Subkonferenzen stehen 220 Sessions zur Auswahl, die ein breites Themenspektrum abdecken und sowohl Entwickler und Admins als auch IT-Architekten, Manager, Consultants und Datenbank-Administratoren ansprechen. Alle Vorträge bleiben nach der Konferenz weiter verfügbar, sodass der Teilnehmer auch bei zeitlicher Überschneidung nichts verpasst. Tickets gibt es unter https://www.ittage.informatik-aktuell.de/tickets/anmeldung.html.
ML im Überblick
Jedes Machine-Learning-System (Abbildung 1) besitzt einen Eingang (x), über den es (hoffentlich) relevante Informationen erhält. Anhand dieser Eingangsdaten nimmt es typischerweise eine Klassifikation (y) vor. Im Bereich der Cybersecurity wäre das zum Beispiel das Auslösen eines Alarms oder die Feststellung, dass alles in Ordnung ist.

Abbildung 1: Der prinzipielle Aufbau eines Machine-Learning-Systems.
Zur Adaption (Learning) des Systems M dient ein Zielvektor (t, Target) oder ein Belohnungssignal (r, Reward). Beim unüberwachten Lernen gibt es diese Rückmeldung nicht. Dort nutzt das Verfahren die statistischen Eigenschaften der Eingangssignale, etwa die Häufung ähnlicher Eingangsmuster. Grundsätzlich unterscheidet man im Bereich des Machine Learning zwischen Unsupervised Learning, Supervised Learning und Reinforcement Learning.
Beim unüberwachten Lernen soll das System selbstständig Muster in den Eingangsdaten erkennen. Auf diese Weise identifiziert es ungewöhnliche Muster, etwa wenn ein Benutzer plötzlich viele Daten per E-Mail an eine Adresse außerhalb der Organisation schickt. Als Ausgangsdaten dienen zum Beispiel Server-Logs oder ein direkter Stream von Netzwerkdaten. Bei Auffälligkeiten führt das System nach Vorgabe sogenannter Playbooks Aktionen aus. So informiert es etwa ein Cybersecurity-Team, das dann prüft, ob tatsächlich ein Problem vorliegt oder vielleicht ein Mitarbeiter wegen legitimer Aufgaben ungewöhnliche Aktionen ausführen musste.
Das überwachte Lernen (Abbildung 2) erfordert eine Zuordnung von Input und Output. Man präsentiert dem System etwa Beispiele für Log-Daten, die keinen Alarm auslösen sollen, und andere, die eine Alarmierung erfordern. So kann man beispielsweise in einer Sandbox eine Malware ausführen und deren Aktionen tracken – zum Beispiel, welche Registry-Einträge sie vornimmt. Die entsprechenden Log-Daten dienen dann als Exempel für die Klasse Malware-Alarm. Andere, normale Log-Einträge ordnet man der Klasse Kein_Alarm zu. Typischerweise kippt man die Logs jedoch nicht direkt als Input ein, sondern bereinigt die Daten zunächst und extrahiert Merkmale, etwa die Häufigkeit bestimmter Wörter. Erst damit gelingt eine effiziente Klassifizierung.

Abbildung 2: Verarbeitungsschritte beim überwachten Lernen.
Die Besonderheit des Reinforcement Learning liegt im Feedback, das das System erhält. In diesem Zusammenhang spricht man auch von der Belohnung (Reward), die erst nach einer Anzahl von Aktionen erfolgt. Deshalb nennt man sie auch verzögerte Belohnung (Delayed Reinforcement). Die Idee hinter dem Reinforcement Learning: Das System agiert, ähnlich wie ein Lebewesen, quasi als Agent mit der Umwelt (Abbildung 3). Der Agent muss seine Umwelt erforschen und erfährt typischerweise erst nach einer gewissen Anzahl von Aktionen, ob er erfolgreich war und eine Belohnung bekommt.
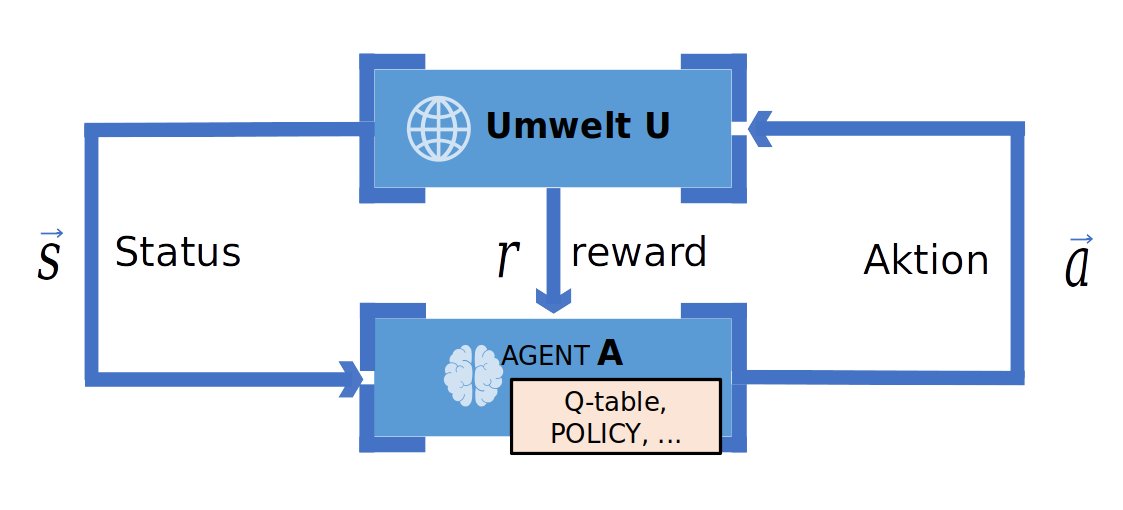
Abbildung 3: Der Ansatz des Reinforcement Learning: Ein Agenten (A) interagiert mit der Umwelt (U), wobei er auf Basis des Status und von bereits Erlerntem (Q-Table) Aktionen ausführt. Durch eine Kombination von Probieren und dem Nutzen von Erfahrungen wird die Q-Table immer weiter optimiert.
Cybersecurity und Machine Learning
Der Einsatz von Machine Learning in der Cybersecurity basiert darauf, das Security-Problem in ein ML- oder noch allgemeiner in ein Data-Science-Problem zu transformieren. Ein Ansatz kann zum Beispiel sein, dass man einerseits von einer Malware und andererseits von einem harmlosen Programm generierte Daten dazu nutzt, beide Fälle zu unterscheiden. Dafür richtet man eine identifizierte Malware in einer separierten virtuellen Maschine ein und verfolgt, welche Log-Dateien sie generiert. Analog sammelt man Log-Dateien von harmlosen Programmen. Auf diese Weise kann man dann per überwachtem Lernen dem System beibringen, “gute” von “schlechten” Log-Daten zu unterscheiden.
Das Prinzip der Klassifikation der Log-Files klingt einfach, bedarf aber einer intensiven Vorverarbeitung. Für Klassifizierer wie neuronale Netze eignen sich nur numerische Werte als Eingangsgröße, am besten solche zwischen 0 und 1. Daher gilt es, zunächst die Textinformation aus dem Log numerisch zu kodieren.
Im Prinzip geht es um nichts anderes als um die Transformation des Security-Problems (Malware-Erkennung) in ein Texterkennungsproblem. Im Fall der Log-File-Klassifikation greift man dann auf entsprechend bewährte Algorithmen zurück, wie sie erprobte Bibliotheken zur Verfügung stellen. So lässt sich beispielsweise mithilfe der Python-Bibliothek Sklearn die Transformation des textuellen in ein numerisches Problem vornehmen. Die Log-File-Klassifikation ist aber nur ein Beispiel von vielen.
Abbildung 4 visualisiert grob den Ansatz des Machine-Learning-Anteils in der Cybersecurity. Die Aufgliederung soll dabei helfen, sich einen Überblick zu verschaffen, erhebt aber keinen Anspruch auf Allgemeingültigkeit.
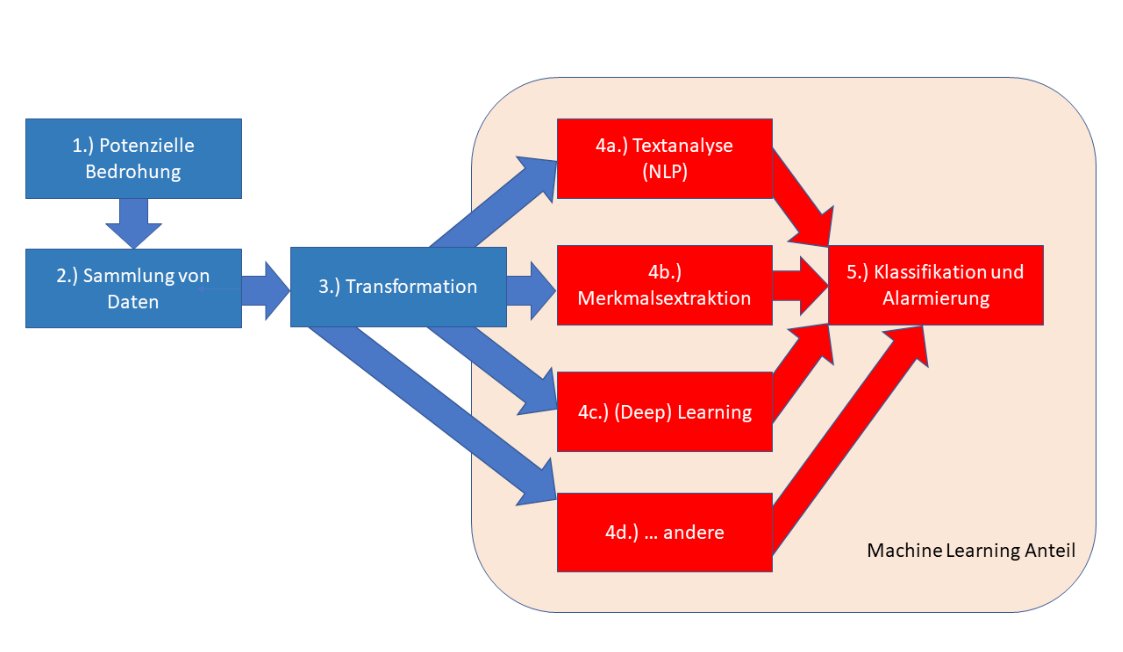
Abbildung 4: Der Machine-Learning-Anteil in der Cybersecurity.
Den Ausgangspunkt (1) bildet typischerweise eine manuell identifizierte Bedrohung, etwa Malware oder Phishing-Attacken. Um die Bedrohung zu erkennen, gilt es, entsprechende Daten zu sammeln (2), etwa aus Log-Files des Betriebssystems oder aus Anwendungen. Für die jeweiligen Bedrohungsszenarien bereitet man die gesammelten Daten dann auf (3), beispielsweise über Data-Science-Algorithmen.
Im nächsten Schritt werden die Daten dann mithilfe von ML-Algorithmen weiterverarbeitet. Für ausgewählte Bedrohungsszenarien wählt man einen oder mehrere Algorithmen zur Vorbereitung der späteren Alarm- beziehungsweise Kein-Alarm-Entscheidung. Per Textanalyse (4a) lassen sich Log-File-Einträge zu Clustern zusammenfassen. Damit kennzeichnet man die Daten als einer Musterklasse zugehörig. Eine Merkmalsanalyse (4b) vermag weitere Muster in den Eingangsdaten zu erkennen, etwa zeitliche Abhängigkeiten.
Als weitere Variante eignet sich Deep Learning (4c). Neuronale Netze, deren innere Struktur mehr als eine sogenannte versteckte Lage enthält, bezeichnet man als “deep” (Abbildung 5). Diese Netze eignen sich besonders gut zur Merkmalsextraktion, sind aber aufwendiger zu trainieren und zu interpretieren. Als versteckte Lagen gelten Neuronen (als Kreise dargestellt), die nicht direkt mit dem Ausgang (Alarm/kein Alarm) oder den Eingangsdaten verbunden sind. Bei mehr als einer solchen Ebene spricht man von einem Deep Neuronal Network.
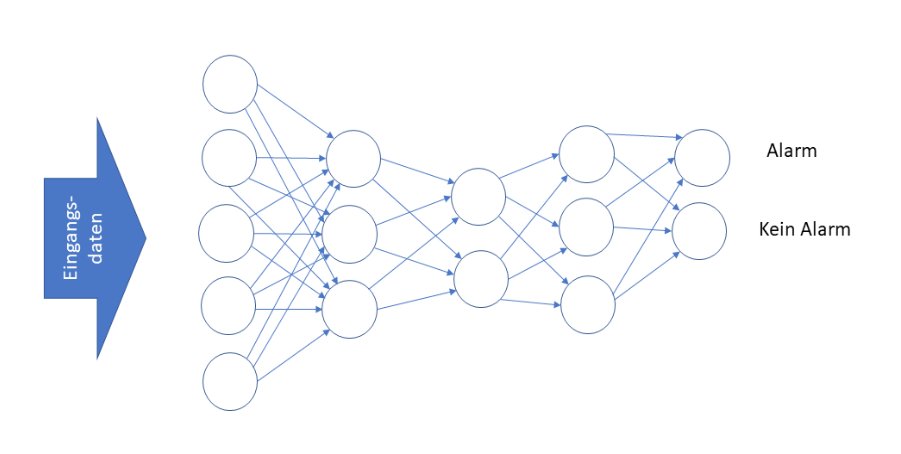
Abbildung 5: Ein Beispiel für ein Deep Neuronal Network.
Daneben lassen sich noch zahlreiche andere Verfahren nutzen (4d) wie zum Beispiel Entscheidungsbäume. Am Ende steht dann die Klassifikation (5): Soll ein Alarm ausgelöst werden?
Eigene Experimente
Als Alternative zum Programmieren eines eigenen neuronalen Netzes bietet es sich an, die Testversionen bekannter Werkzeuge zu installieren und anhand ihrer Toolkits die Möglichkeiten von Machine Learning zu erproben.
So kann man Splunk Enterprise und darauf basierend auch dessen Machine Learning Toolkit (Abbildung 6) für 60 Tage installieren. Die Software bietet eine Reihe von Beispielen für verschiedene Einsatzszenarien, darunter auch IT-Security. Bei der Installation werden auch gleich Beispieldaten mitgeladen, mit denen sich die verschiedenen Szenarien testen lassen.

Abbildung 6: Das ML-Toolkit von Splunk bietet diverse Showcases, mit denen man experimentieren kann.
Zum Testen von Algorithmen hat man nicht immer die geeigneten Daten zur Hand. Erzeugt man sie selbst, erhält man mehr Kontrolle darüber, wie stark man den Daten noch eine Zufälligkeit hinzufügen möchte. Als Beispiel sei hier das Erstellen einer Zeitreihe aufgeführt, die die Anzahl von Logins darstellt (Abbildung 7).

Abbildung 7: Eine simulierte normierte Zeitreihe, die die Anzahl von Logins darstellt.
Typischerweise fallen an Arbeitstagen sehr viele Logins an, am Wochenende dagegen deutlich weniger. Dabei gibt es mehr oder weniger starke Schwankungen. Listing 1 zeigt, wie sich eine solche Zeitreihe erzeugen lässt. Der Vorteil der simulierten Daten: Man kann einzelne Parameter gezielt beeinflussen wie hier mit dem Parameter »random_gain« den Zufallsanteil.
Listing 1
Zeitreihen erzeugen
import numpy as np
import plotly.graph_objects as go
step = 1 / 1000 t = np.arange(0, 1, step) # time vector
periods = 30 # number of 'days'
# function to produce base sine data
# with a 7th of the base frequency overlap
def data_w_weekend(t):
if np.sin(periods / 7 * 2 * np.pi * t) > 0.5:
value = 0.001 * np.sin(periods * 2 * np.pi * t)
return max(value, 0.0)
else:
value = np.sin(periods * 2 * np.pi * t)
return max(value, 0.0)
# building the data vector
my_data = []
i = 0
while i < 1000:
my_data.append(data_w_weekend(i / 1000))
i += 1
# add some noise
random_gain = 0.1 # factor for the noise
i = 0
while i < 1000:
my_data[i] += np.random.rand() * random_gain
i += 1
my_data_max = np.amax(my_data)
print('max value is: ' + str(my_data_max))
# normalize the data to a range up to 1.0
my_norm_data = []
i = 0
while i < 1000:
my_norm_data.append(my_data[i]/my_data_max)
i += 1
# plot the data
trace0 = go.Scatter(
x = t,
y = my_norm_data,
name='Logons'
)
fig = go.Figure()
layout = go.Layout(title="Logins over time", xaxis={'title':'time'}, yaxis={'title':'occurences'})
fig = go.Figure(data=trace0, layout=layout)
fig.show()
Für den praktischen Einsatz gilt es, trotzdem mit realen Daten zu testen sowie Sonderfälle wie Feiertage gesondert zu behandeln. Will man stärker in die Zeitreihenvorhersage einsteigen, empfiehlt sich die Lektüre eines Papiers von Tensorflow [3]. Die Idee dabei: Liegen Daten vor, die das System nicht vorhersagen konnte, besteht Verdacht auf ein Sicherheitsproblem.
Wie Angreifer Machine Learning nutzen
Machine Learning lässt sich nicht nur nutzen, um sich gegen Angreifer zu wehren: Auch Hacker sind sich des Potenzials der Technik bewusst. So hat etwa die Gefährlichkeit von Phishing-Attacken zugenommen, da sich fingierte E-Mails immer weniger von authentischen Nachrichten unterscheiden. Machine Learning kann die Angriffsqualität weiter erhöhen, indem zum Beispiel unüberwachtes Lernen die Ähnlichkeiten automatisch aufzeigt. In Kombination mit Algorithmen des Natural Language Processing (NLP) lassen sich auf diese Weise zufällige Variationen in die E-Mails einbauen, sodass die einzelnen Exemplare sich lediglich ähneln, jedoch nicht identisch sind. Dadurch sind Phishing-Attacken weniger leicht zu erkennen.
Die Herausforderung beim Reinforcement Learning besteht darin, dass das System recht viele Versuche braucht, um das richtige Verhalten zu erlernen. Deshalb setzt man beim Entwickeln entsprechender Algorithmen auf simulierte Umgebungen – etwa auf Videospiele als Welt, mit der der Agent interagiert. Ein Hacker würde ähnlich vorgehen und nicht versuchen, seinen Agenten am potenziellen Opfer zu trainieren; das wäre allzu leicht zu entdecken. Stattdessen könnte er spezielle Trainingsumgebungen von Standardinstallationen aufbauen, mit denen sich dann Agenten optimieren lassen. Dabei können diese auch Angriffsstrategien entwickeln, die sich ein Mensch so nicht überlegt hätte.
Fazit
Sowohl das Machine Learning als auch die Cybersecurity haben bereits einen hohen Stellenwert für IT-Systeme und werden in Zukunft vermutlich noch weiter an Bedeutung gewinnen.
Dabei hat Machine Learning das Potenzial, Cybersecurity insofern zu vereinfachen, als es Verteidigungssysteme ermöglicht, die sich selbstständig anpassen. Hierzu muss das System wissen, was normal ist und was nicht. Letztendlich kann das lernende System auch aus den Aktionen eines Security-Mitarbeiters ableiten, was zu tun ist, und so zur Entlastung beitragen.
Mit hoher Wahrscheinlichkeit sehen wir zur Zeit nur die Spitze jenes Eisbergs, den die Kombination von Machine Learning und Cyber Security darstellt. Die Angreifer und Verteidiger werden sich weiter gegenseitig hochschaukeln, ihre Lösungen reifen dabei. Umso wichtiger ist es, hier auf dem Laufenden zu bleiben. (jcb/jlu)
Infos
-
Splunk: https://www.splunk.com
-
Darktrace: https://www.darktrace.com
-
Zeitreihen: https://www.tensorflow.org/tutorials/structured_data/time_series





