
© Konstantin Shaklein, 123RF
Ein Beispielprojekt mit Apache StreamPipes berechnet den Vorbeiflug der Internationalen Raumstation ISS mit einem Microservices-Ansatz aus öffentlich zugänglichen Datenströmen.
Eine Vielzahl von Datenquellen, egal ob physische Sensoren, Ereignisse aus Geschäftsanwendungen oder auch sozialen Medien, produzieren heute große Mengen Daten in Quasi-Echtzeit. Daraus resultieren kontinuierliche Datenströme, die aus einer vernetzten Welt nicht mehr wegzudenken sind. Systeme, die sich auf das Verarbeiten solcher Datenströme spezialisieren, können viele Vorteile ausspielen und das riesige Potenzial sogenannter reaktiver Anwendungen erschließen.
Im Allgemeinen folgen solche Systeme einer Architektur, bei der sogenannte Ereignisse einzelne Komponenten steuern. Oft lösen kontinuierliche Datenquellen (Produzenten) wie etwa Sensoren die Ereignisse aus, unterschiedliche Komponenten (Konsumenten) der Architektur verarbeiten sie. Die Entkopplung von Produzenten und Konsumenten erfolgt über eine Middleware-Schicht, die die Verteilung der Daten übernimmt, in der Regel in Gestalt eines Message-Brokers. Ein solches Architekturmuster reduziert die Schnittstellenkomplexität, da beliebig viele Dienste quasi gleichzeitig eingehende Datenströme empfangen und weiterverarbeiten können.
Durch diese flexible Verarbeitung lassen sich schneller Mehrwertdienste bereitstellen, die auf einer standardisierten Infrastruktur für das Erfassen und Verteilen von Daten beruhen. Dazu gibt es heute eine Vielzahl produktiv einsetzbarer Open-Source-Technologien unter dem Dach großer Open-Source-Organisationen wie der Eclipse Foundation oder der Apache Software Foundation. Populäre Beispiele findet man zum Beispiel mit Eclipse Mosquitto, einem leichtgewichtigen Message-Broker auf Basis des Protokolls MQTT, Apache Kafka, einem verteilten Broker für Streaming-Anwendungen, der auch höchsten Skalierungsansprüchen gerecht wird, oder Apache Flink, einem Framework zur parallelisierten Verarbeiten von Datenströmen.
Um neue Anwendungsfälle mit wenig Zeitaufwand umzusetzen (oder auch zunächst prototypisch zu entwickeln), haben sich sogenannte Self-Service-Lösungen etabliert. Sie statten Anwender mit geringen Kenntnissen der Umsetzung von Stream-Processing-Anwendungen mit einfach nutzbaren Werkzeugen aus, um Mehrwert aus den verfügbaren Datenströmen zu generieren. Ein Beispiel für eine solche Lösung ist das Open-Source-Framework Apache StreamPipes [1].
Das ursprünglich in Karlsruhe am FZI (Forschungszentrum Informatik) entwickelte Tool ist seit November 2019 ein Incubating-Projekt der Apache Software Foundation und dort Teil einer wachsenden Anzahl an Lösungen für das Internet der Dinge (IoT). StreamPipes richtet sich mit seiner Toolbox [2] an Fachanwender mit geringen technischen Kenntnissen. Das Hauptziel besteht darin, Stream-Processing-Technologien auch für Laien zugänglich zu machen. Dafür stehen verschiedene Module bereit, um IoT-Datenströme von einer Vielzahl an Quellen anzubinden, auf diesen Datenströmen Analysen zu erstellen sowie Live-Daten oder auch historische Daten zu untersuchen.
Mit einer Vielzahl von Konnektoren und Algorithmen zur Analyse industrieller Daten bedient StreamPipes in erster Linie das sogenannte Industrial IoT, das insbesondere Daten aus dem Produktions- und Automatisierungsumfeld integriert. Aber auch Nutzer ohne Zugang zu einer eigenen Produktionsstraße können von der Lösung profitieren: Beispielsweise lassen sich Echtzeitdaten von öffentlich verfügbaren APIs sowie weitverbreitete Protokolle wie MQTT nutzen, um bestehende Datenquellen anzubinden.
Einen wichtigen Kernbaustein der Lösung bildet der Pipeline-Editor. Hier können Nutzer mithilfe grafischer, datenflussorientierter Modellierung eigenständig Verarbeitungspipelines erzeugen, die die zugrundeliegende Stream-Processing-Infrastruktur dann automatisiert ausführt. Auf der Anwendungsseite bedient StreamPipes typische Stream-Processing-Anwendungen wie kontinuierliches Monitoring (zum Beispiel Condition Monitoring), die Erkennung zeitkritischer Situationen, die Live-Berechnung von Kennzahlen (zum Beispiel Key Performance Indicators) bis hin zur Integration von Machine-Learning-Modellen.
Abbildung 1 liefert einen groben Überblick zu StreamPipes, von der Datenanbindung über Verarbeitung und Analyse bis hin zum Deployment zur Realisierung der eigenen Anwendungsfälle.
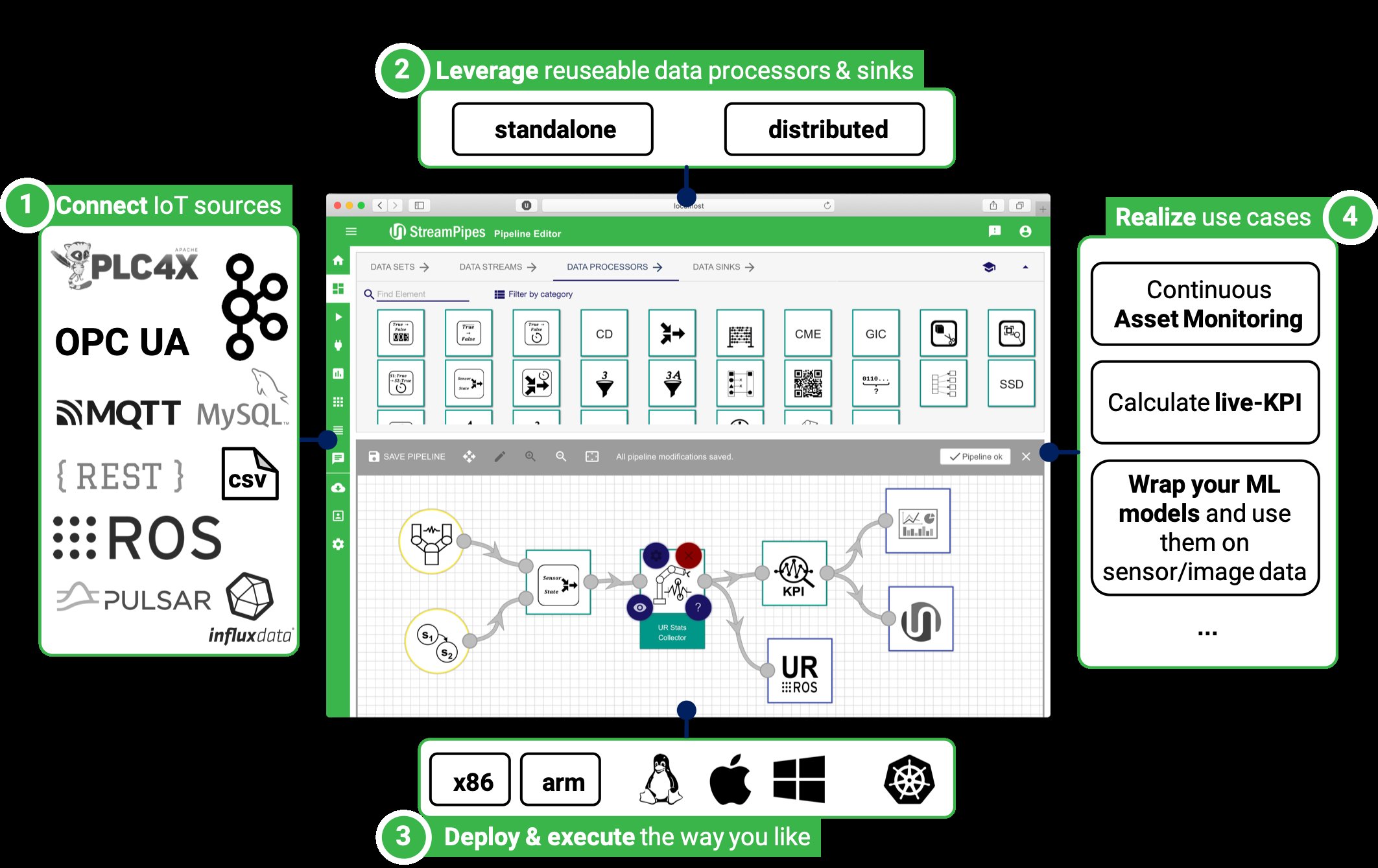
Abbildung 1: Ein Überblick über die einzelnen StreamPipes-Komponenten.
Stream Processing leicht gemacht
Bevor wir einen praktischen Anwendungsfall mit StreamPipes umsetzen, werfen wir einen groben Blick auf die technische Architektur. Abbildung 2 zeigt die verschiedenen Schichten des Systems.
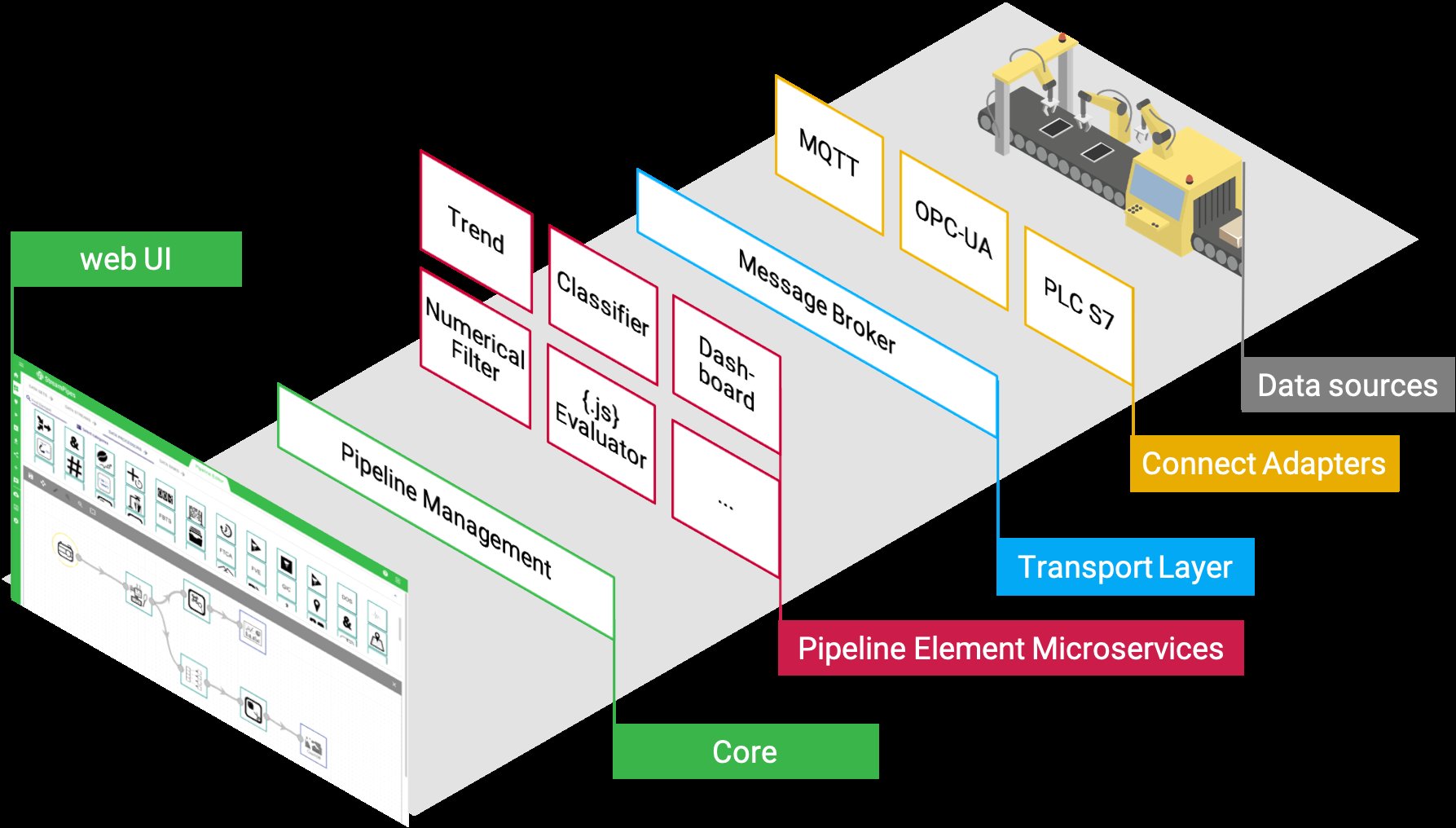
Abbildung 2: Eine StreamPipes-Anwendung besteht aus diversen Schichten.
Die meisten Nutzer möchten im ersten Schritt bestehende Datenströme anbinden. Dafür liefert StreamPipes mit dem Modul StreamPipes Connect eine Bibliothek, um Daten auf Basis von Standardprotokollen oder bestimmten, von StreamPipes bereits unterstützten Spezialsystemen anzubinden. Sogenannte Connect-Adapter, die sich auch auf leichtgewichtigen Edge-Geräten wie einem Raspberry Pi installieren lassen, übernehmen das Erfassen und Weiterleiten der Datenströme an den internen Message Broker – hier kommt unter der Haube Apache Kafka zum Einsatz. Bereits in den Connect-Adaptern können Nutzer eigenständig Transformationsregeln definieren, um beispielsweise eine Umrechnung von Werteinheiten vorzunehmen.
Eine Ebene über der Transportschicht existieren wiederverwendbare Algorithmen (zum Beispiel zur Erkennung von statistischen Trends, zur Vorverarbeitung von Daten oder zur Bildverarbeitung), die jeweils eine bestimmte Funktion kapseln und als Event-getriebene Microservices zur Verfügung stehen. Neben Algorithmen stellt StreamPipes auch Datensenken auf diesem Weg bereit wie zum Beispiel Konnektoren für Datenbanken oder Dashboards.
Jeder einzelne Microservice liefert dabei neben der Funktionalität auch eine maschinenlesbare Beschreibung der Anforderungen des Algorithmus. So lassen sich beispielsweise bestimmte benötigte Datentypen oder Messeinheiten spezifizieren, die der Datenstrom bereitstellen muss, um die Komponente zu initialisieren. Der Algorithmenbaukasten lässt sich zur Laufzeit mithilfe eines Software Development Kits erweitern, sodass der Anwender bei neuen Anforderungen ohne Neustart der Anwendung jederzeit zusätzliche Algorithmen installieren kann.
Nutzer interagieren anschließend mit dem webbasierten Frontend, das es leicht macht, Pipelines durch das Verknüpfen von Datenströmen mit Algorithmen und Datensenken aufzubauen. Im Unterschied zu anderen grafischen Tools zur Modellierung von Datenflüssen kommt hier eine im StreamPipes-Kern integrierte Matching-Komponente zum Einsatz. Sie überprüft während des Aufbaus des Modells fortlaufend die Konsistenz von Verarbeitungspipelines und verhindert durch eine semantische Prüfung, dass fehlerhafte Verbindungen modelliert werden.
Von Daten zur Applikation in wenigen Klicks
Aufbauend auf den Grundlagen soll nun demonstriert werden, wie eine Anwendung mit StreamPipes aussehen kann. Das Beispiel bedient sich Daten der Internationalen Raumstation ISS. Dazu verwendet es eine offene API, um die aktuelle Position der ISS in ihrem Orbit um die Erde zu ermitteln, darauf aufbauend einige Kennzahlen zu berechnen und die Ergebnisse in einem Live-Dashboard anzuzeigen.
Zunächst gilt es, StreamPipes zu installieren. Das gelingt am einfachsten mit einer Docker-basierten Installation (Listing 1), die alle benötigten Komponenten herunterlädt und startet. Dazu müssen sowohl Docker als auch Docker Compose auf dem System vorliegen; Docker sollten 2 bis 3 GByte RAM zugewiesen sein.
Listing 1
StreamPipes installieren und starten
$ wget https://s.apache.org/streampipes-installer $ unzip apache-streampipes-installer-0.67.0-incubating-source-release.zip $ cd incubator-streampipes-installer/compose $ docker-compose up -d
Bei der Erstinstallation werden die zugehörigen Docker-Images für StreamPipes sowie im Hintergrund genutzte weitere Images (zum Beispiel Apache Kafka) geladen. Sobald das System gestartet ist, lässt sich das Setup über den Webbrowser abschließen. Standardmäßig lässt sich das Interface auf Port 80 erreichen. Nach einem Login mit den gewählten Benutzerdaten (die ausschließlich lokal gespeichert werden) erscheint die Startseite von StreamPipes (Abbildung 3).
Abbildung 3: Die Startseite von StreamPipes nach der Erstinstallation.
Einfache IoT-Datenanbindung mit Connect
Im ersten Schritt soll die Anwendung nun die Positionsdaten der ISS als kontinuierlichen Datenstrom beziehen. Dazu wechseln wir in das Modul Connect. Der nun sichtbare Datenmarktplatz zeigt vorhandene Adapter an, die sich jeweils einzeln konfigurieren lassen (Abbildung 4). So existieren generische Adapter zum Beispiel für MQTT, SPS-Steuerungen, Kafka oder Datenbanken sowie einige spezifische Adapter für Quellsysteme wie Slack. Für unsere ISS-Anwendung verwenden wir den vorkonfigurierten Adapter ISS Location.
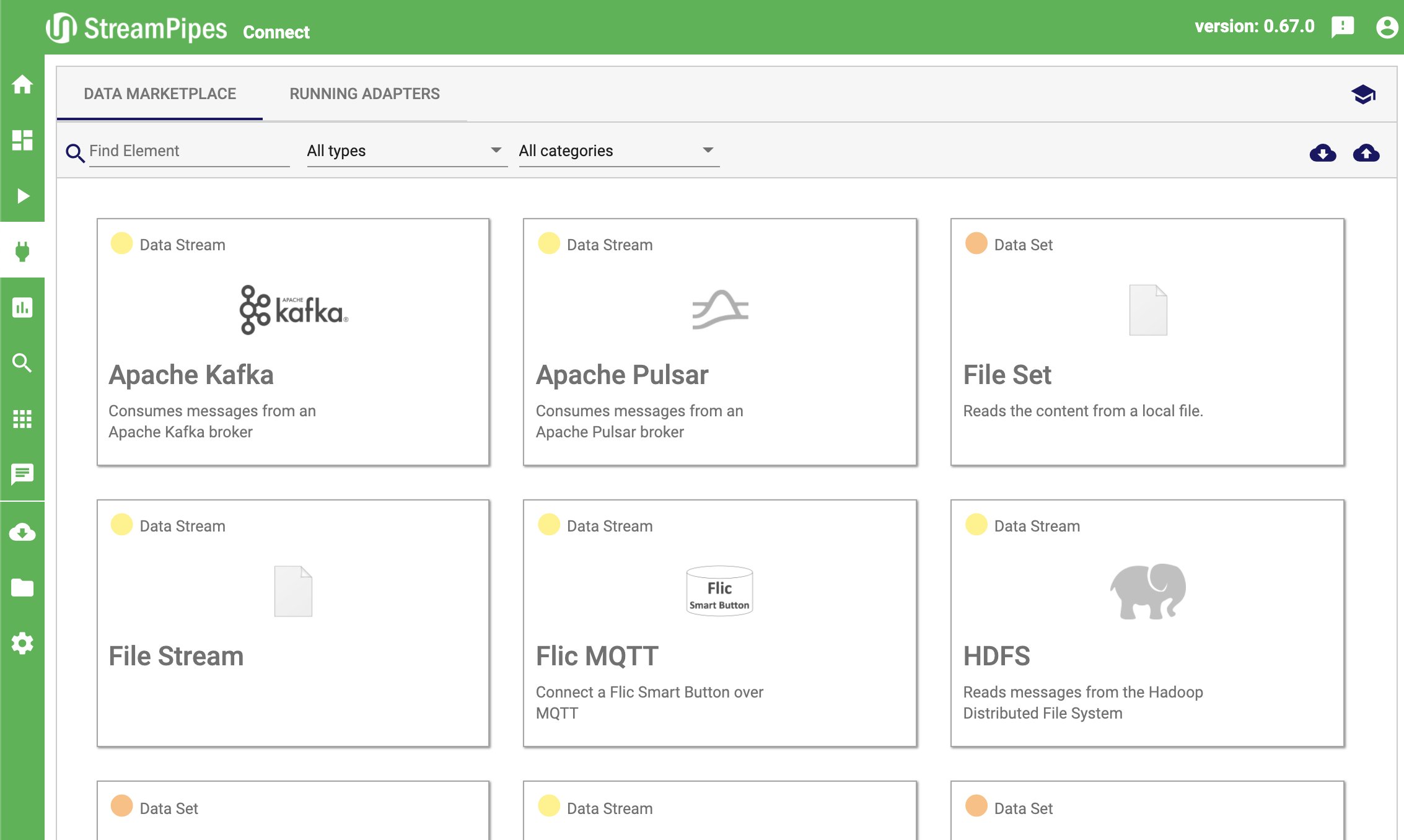
Abbildung 4: Der Datenmarktplatz innerhalb des Connnect-Moduls.
Für jeden Adapter gibt es einen Assistenten zur Konfiguration der erforderlichen Parameter. Hier lassen sich neben dem Format des Events auch weitere Eigenschaften anpassen wie das Umrechnen von Messwerten. In unserem Fall erzeugt der entsprechende Adapter ein Event mit lediglich drei Parametern, einem Zeitstempel sowie den Koordinaten des aktuellen ISS-Standorts (Latitude und Longitude im WGS84-Format).
Am Ende des Prozesses geben wir dem neuen Adapter einen Namen (hier ISS-Location) und starten den Prozess. Von nun an kommen regelmäßige Updates der ISS-Position in der zugrundeliegenden Apache-Kafka-Infrastruktur an. Ein Blick in den Pipeline-Editor zeigt ein neues Symbol im Reiter Data Streams.
Pipelines bauen
Nach der Implementierung des Adapters können wir nun damit beginnen, eine Pipeline zu erstellen, um einige interessante Daten zur ISS zu berechnen. Der Pipeline-Editor funktioniert nach dem Drag-and-Drop-Prinzip: Datenströme, Datenprozessoren und Datensenken lassen sich in den Bearbeitungsbereich ziehen und dort miteinander verknüpfen.
Zunächst transformieren wir die geografischen Koordinaten mittels eines Reverse-Geocoding-Verfahrens, um den der aktuellen Koordinate nächstgelegenen Ort zu ermitteln. Wir nutzen hier eine integrierte Komponente, die eine Auswahl von rund 5000 Städten weltweit abdeckt. Außerdem kommt ein Speed Calculator zum Einsatz, der auf Basis mehrerer aufeinanderfolgender Ortsangaben eine durchschnittliche Geschwindigkeit ermittelt. Am Ende soll die Verarbeitungspipeline eine Benachrichtigung erzeugen, sobald die ISS in einen definierten Radius um einen bestimmten Ort herum eintritt.
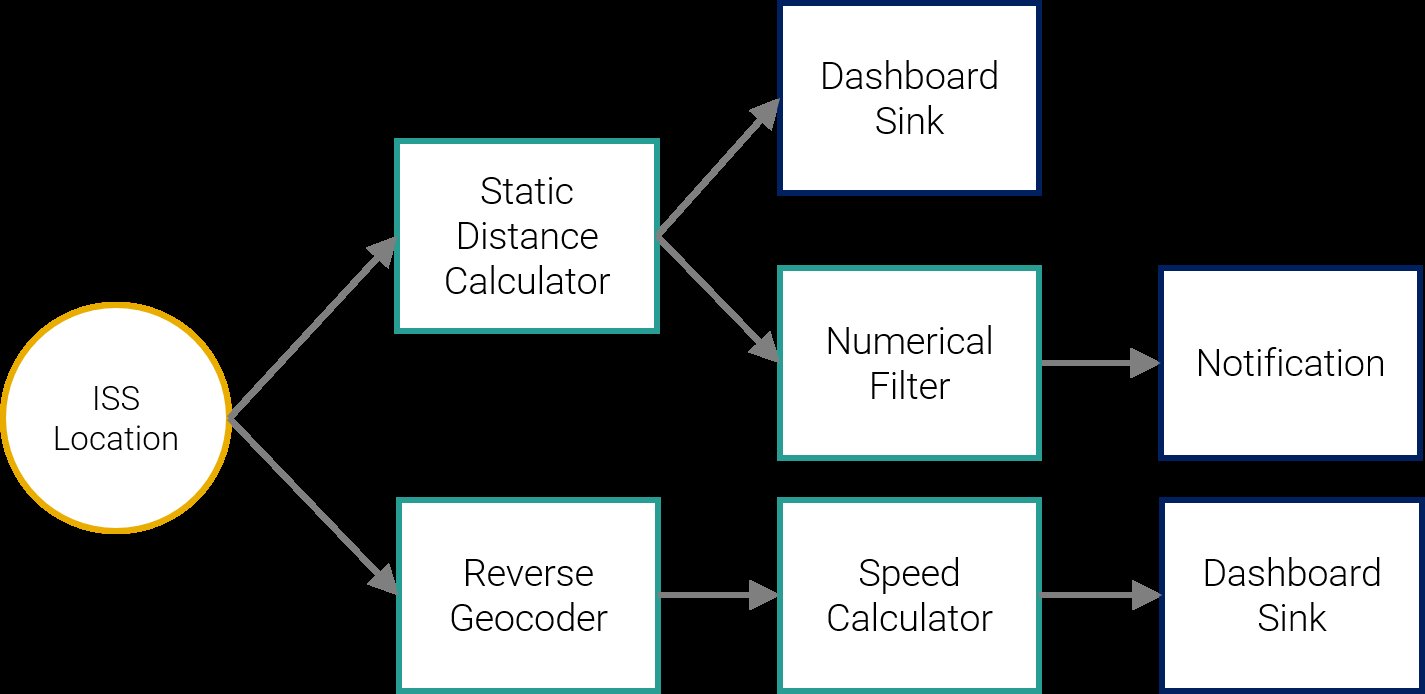
Abbildung 5: Schematische Darstellung der aufzubauenden Pipeline.
Wir beginnen den Zusammenbau der Pipeline, indem wir als Erstes den gerade erzeugten Datenstrom ISS-Location in den Bearbeitungsbereich ziehen und aus dem Tab Data Processors die Komponente Reverse Geocoding auswählen. Beide Komponenten werden nun verknüpft. Anschließend prüft der StreamPipes-Kern die Kompatibilität – in diesem Fall benötigt der Geocoder ein Eingangsereignis mit einem Koordinatenpaar aus Latitude und Longitude, die der ISS-Datenstrom auch liefert.
Anschließend öffnet sich ein Konfigurationsdialog, der bei vielen Algorithmen eine Parametrisierung ermöglicht, zum Beispiel die Angabe von konfigurierbaren Schwellenwerten. Für den Geocoder sind die einzig möglichen Konfigurationen bereits vorausgewählt. Nach einem Klick auf Save fügen wir das nächste Pipeline-Element an – in diesem Fall die Komponente Speed Calculator – und konfigurieren es. Zur Visualisierung des Ergebnisses klicken wir im Reiter Data Sinks den Punkt Dashboard Sink an. Dadurch lässt sich später im Live-Dashboard eine entsprechende Visualisierung einrichten.
Nun fehlt noch die Benachrichtung, dass sich die Raumstation nähert: Dazu verknüpfen wir die Komponente Static Distance Calculator durch einen weiteren Ausgang mit dem ISS-Datenstrom. Sie benötigt zwei Eingaben. Bei der ersten handelt es sich um ein Koordinatenpaar für den Ort, zu dem die aktuelle Distanz berechnet werden soll – in unserem Fall Karlsruhe (Latitude 49.006889, Longitude 8.403653).
Diese Komponente ergänzen wir dann noch um einen Numerical Filter, mit dem Wert »distance« für Field to Filter, »<« für FilterOperation und zum Beispiel »200« als Threshold. Die eigentliche Benachrichtigung erzeugt dann die Komponente Notification, die wir mit einem Titel und einem Zusatztext konfigurieren. Abschließend fügen wir noch eine weitere Dashboard-Senke an den Distance Calculator an, um die Distanz später live zu visualisieren.
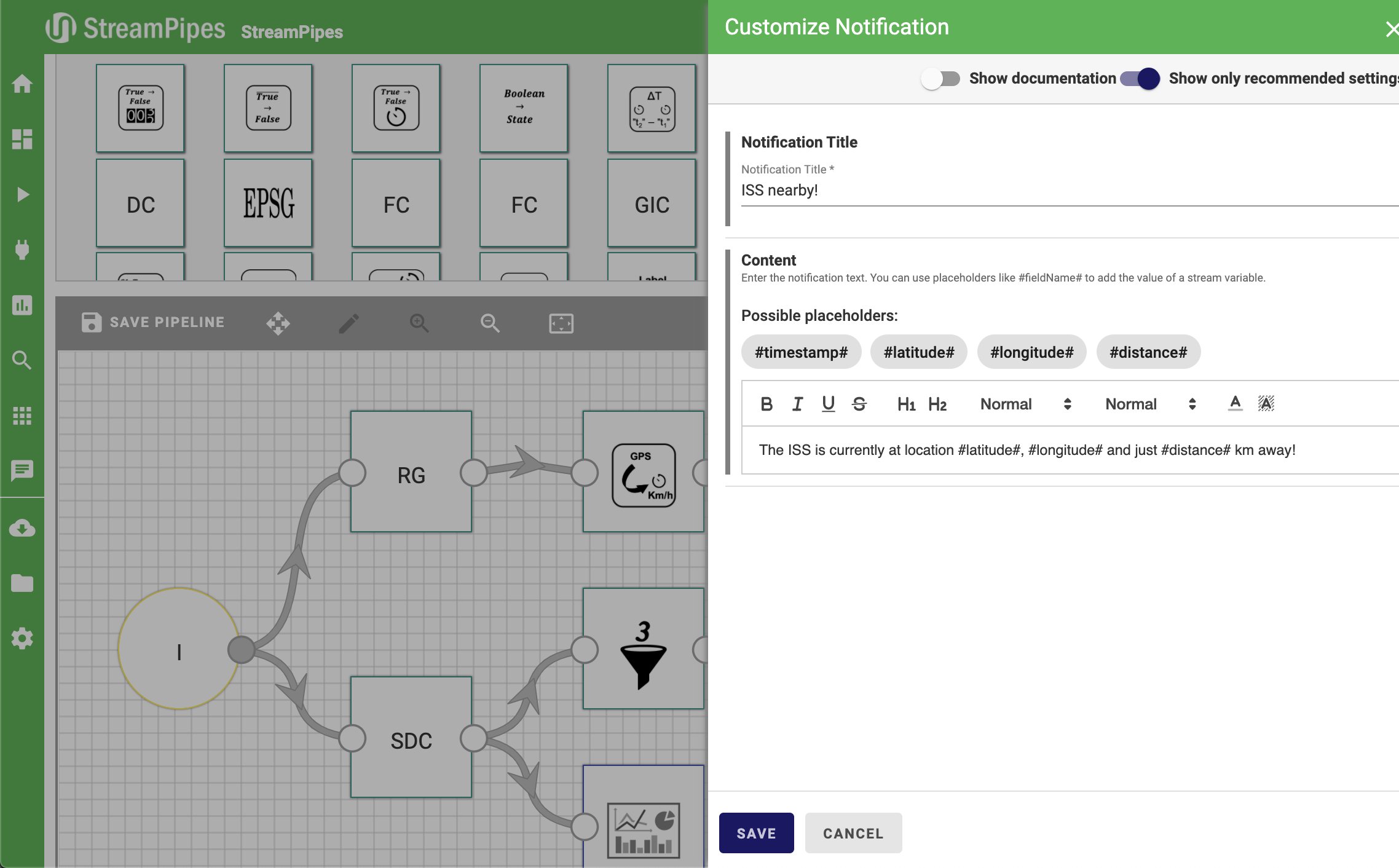
Abbildung 6: Die Konfiguration der Benachrichtigung.
Ein Klick auf Save Pipeline startet nach Eingabe eines Namens die Pipeline und führt den Nutzer in die Übersicht. Im Hintergrund werden die vorhandenen Microservices mit den gewählten Konfigurationen instanziiert. Die Detailansicht zeigt das konfigurierte verteilte System; alle Komponenten tauschen nun Daten über automatisch erstellte Topics in Apache Kafka aus.
Neben dem hier zum Einsatz kommenden Standard-Wrapper, der direkt auf der Java Virtual Machine (JVM) ausgeführt wird und auch auf einem Raspberry Pi laufen kann, existieren weitere Wrapper für skalierbare Anwendungen auf Basis von Apache Flink oder Kafka Streams.
Datenexploration
Nun gilt es, die Ergebnisse noch zu visualisieren. Dafür stehen mit dem Live Dashboard sowie dem Data Explorer zwei Module zur Verfügung, um Live- oder historische Daten anzuzeigen. Für die ISS-Visualisierung ist das Live-Dashboard die richtige Wahl. Dazu muss man als Erstes ein neues Dashboard einrichten; anschließend übernehmen unterschiedliche Widgets die Anzeige der Live-Daten. Wir haben uns für die Anzeige der Geschwindigkeit, der am nächsten gelegenen Stadt und der Distanz zu Karlsruhe mittels eines Single-Value-Widgets sowie einer Kartendarstellung der aktuellen Position entschieden (Abbildung 7). Dashboards wie dieses lassen sich auch losgelöst von der eigentlichen StreamPipes-Webanwendung über generierte Links aufrufen.
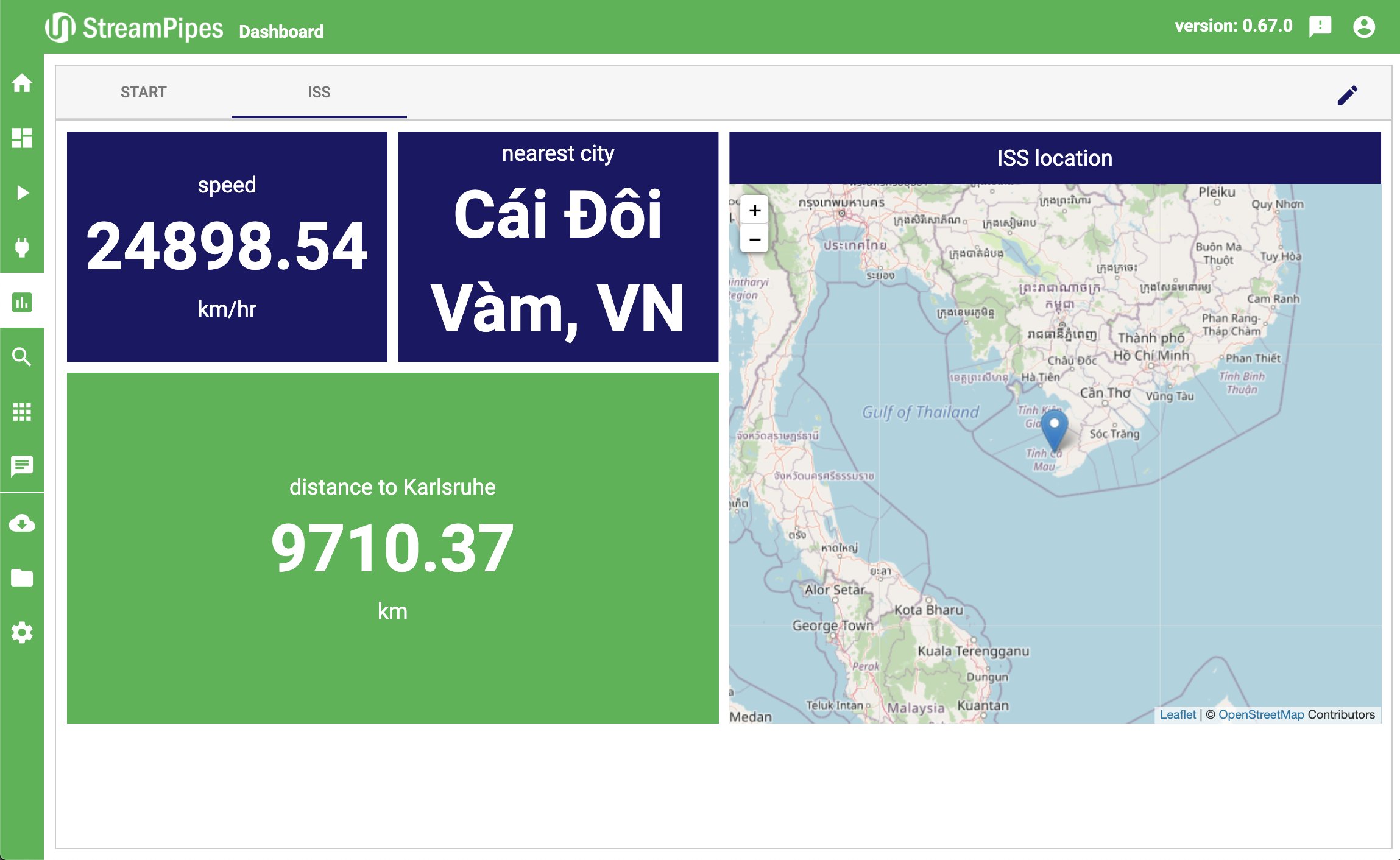
Abbildung 7: Das Dashboard visualisiert die ISS-Daten.
Mit wenigen Klicks ist hier eine Anwendung entstanden, die einen kontinuierlich eingehenden Datenstrom analysiert. Neben den hier gezeigten, auf geografische Operationen spezialisierten Algorithmen existieren viele weitere Module in der Bibliothek. Dazu zählen unter anderem solche zum Berechnen von Statistiken und Erkennen von Trends, zur Bildverarbeitung und zur Objekterkennung und zum Berechnen von Kennzahlen zu Datenströmen aus SPS-Steuerungen. Es gibt auch einen Javascript-Evaluator, der viel Flexibilität bei der Transformation von Datenströmen bereitstellt.
Erweiterung der Toolbox
No-Code-Lösungen für Datenstromanalysen umfassen zunächst nur einen begrenzten Fundus an Algorithmen oder Datensenken. Für Anwendungsfälle, die sich mit bestehenden Komponenten nicht abdecken lassen, sind daher Erweiterungen erforderlich.
Um die Entwicklung neuer Algorithmen für StreamPipes zu vereinfachen, steht ein Software Development Kit zur Verfügung. Aktuell existiert ein SDK für Java, Unterstützung für Javascript und Python ist in Vorbereitung. Für Java lässt sich über einen Maven-Archetype eine neue Komponente erzeugen. Der Befehl aus Listing 2 generiert ein neues Projekt mitsamt der erforderlichen Java-Klassen, um ein neues Pipeline-Element zu erstellen.
Listing 2
Projekt via Maven generieren
mvn archetype:generate \ -DarchetypeGroupId=org.apache.streampipes \ -DarchetypeArtifactId=streampipes-archetype-pe-processors-jvm \ -DarchetypeVersion=0.67.0
Die Anatomie eines Pipeline-Elements folgt dabei dem in Abbildung 8 gezeigten Schema. Ein (oder mehrere) Datenprozessoren in StreamPipes werden in einen eigenständigen Microservice gekapselt, der sich über eine API erreichen lässt. Die API bietet dem zentralen Pipeline-Management von StreamPipes eine Beschreibung der verfügbaren Prozessoren (oder Senken) an und wird von diesem aufgerufen, sobald eine Pipeline startet oder terminiert.
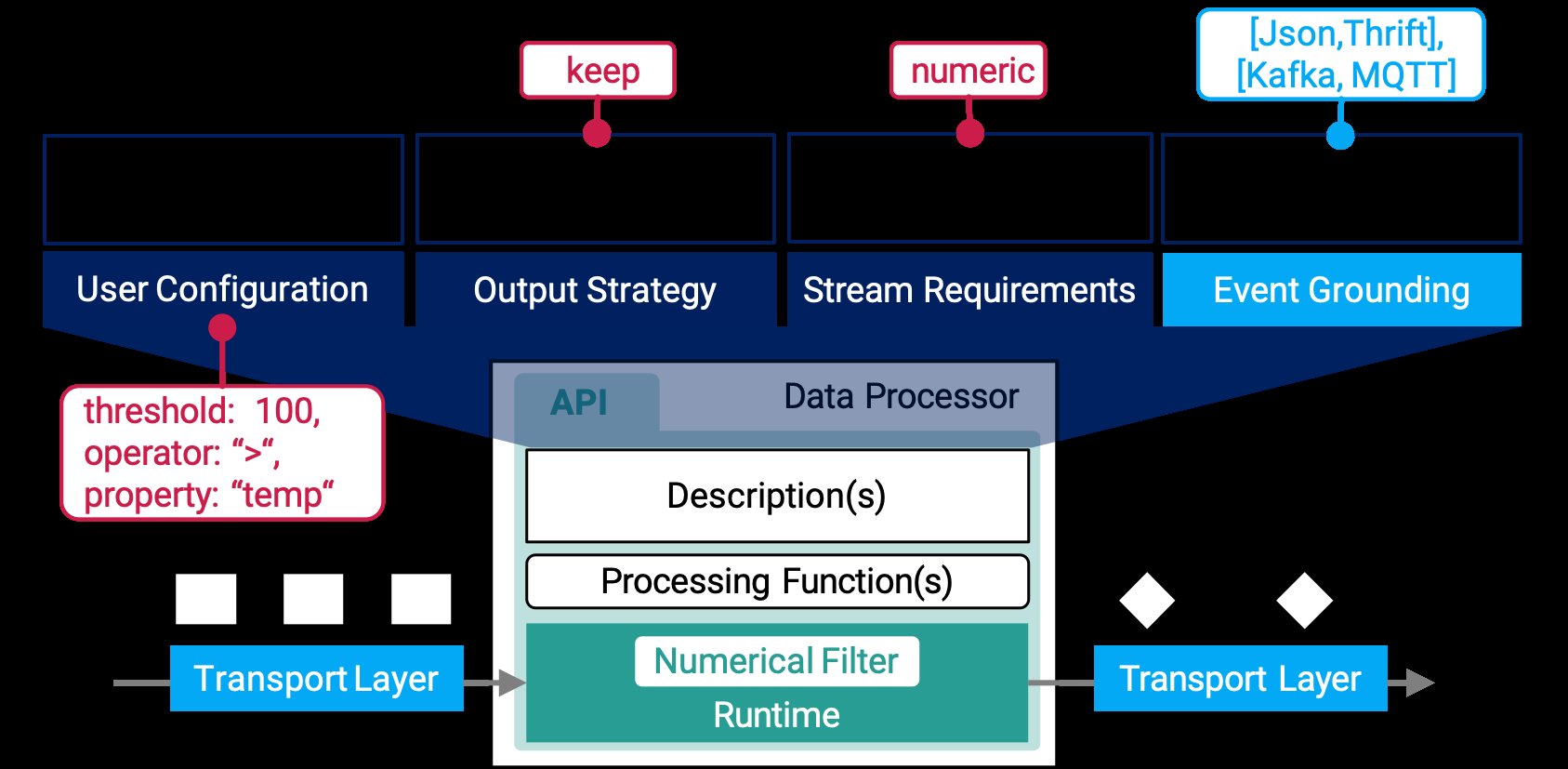
Abbildung 8: Die Anatomie eines neuen Pipeline-Elements.
Die Beschreibung enthält Informationen wie benötigte Nutzerkonfigurationen (zum Beispiel Eingabeparameter oder Auswahlmenüs), die die Weboberfläche anzeigt. Zusätzlich definiert sie Stream Requirements. Auf diese Weise kann der Pipeline-Element-Entwickler Anforderungen an den eingehenden Datenstrom definieren, etwa das Vorliegen eines numerischen Werts für einen entsprechenden Filter oder im beschriebenen Beispiel von Geokoordinaten (geografische Länge und Breite im WGS84-Format).
Eine Output Strategy legt das von der Komponente bereitgestellte Schema der ausgehenden Ereignisse fest. Sie beschreibt die Transformation der eingehenden Datenströme in einen ausgehenden Datenstrom. Beispielsweise lässt sich über »OutputStrategies.keep()« festlegen, dass der Ausgangsdatenstrom in der Struktur dem Eingangsdatenstrom entspricht. Schließlich definiert das Event Grounding von der Komponente unterstützte Nachrichtenformate zur Übermittlung. Hier kann es sich etwa um JSON handeln oder auch Binärformate wie Apache Thrift sowie diverse unterstützte Protokolle. Von Haus aus unterstützt StreamPipes dabei Kafka und JMS.
Startet man nun die neu erstellte Komponente über die integrierte Init-Methode, meldet sie sich automatisch im Pipeline-Management von StreamPipes an und lässt sich über die Nutzeroberfläche installieren. Das erlaubt, das System zur Laufzeit um neue Funktionen zu erweitern. Der Maven-Archetype generiert neben den erforderlichen Codeklassen auch ein Dockerfile, was einen einfachen Übergang in das Produktivsystem gewährleistet. Die Online-Dokumentation enthält mehrere Tutorials, die das Erstellen neuer Komponenten für StreamPipes erklären.
Sobald der Nutzer eine Pipeline startet, wird über die API die Runtime und über diese die implementierte Funktion aufgerufen. Dabei gehen Nachrichten kontinuierlich über das gewählte Protokoll (hier Apache Kafka) ein, die berechneten Ergebnisse werden wieder zurück an den Broker geschickt.
Cluster-Betrieb
Der Microservice-Ansatz von StreamPipes umfasst neben der UI und dem StreamPipes-Kern zum Pipeline-Management auch sämtliche Erweiterungen wie Connect-Adapter und Pipeline-Elemente. Eine flexible Orchestrierung mittels Docker ergänzt ihn. Sie unterstützt neben den weitverbreiteten AMD-basierten Architekturen seit Neustem auch ARM-basierte Systeme.
So lassen sich beispielsweise für bestimmte Anwendungsfälle einzelne Algorithmen-Container auch auf kleinen Edge-Geräten wie einem Jetson Nano oder Raspberry Pi starten, während der Kern des Pipeline-Managements zentralisiert gehostet wird. Das gelingt mittels auf Dockerhub verfügbarer Multi-Architecture-Docker-Images. Sie sind über das Docker-Manifest-Feature annotiert, sodass der Anwender keine Anpassung der Image-Tags in den etwaigen Deployment-Beschreibungen vornehmen muss. Mit einer Kombination aus architekturspezifischen Image-Tags und einem damit verbundenen Docker-Manifest lässt sich so eine One-suits-it-all-Image-Beschreibung erzeugen, die agnostisch zur jeweiligen Systemarchitektur das richtige Image von Dockerhub zieht.
Erfahrungsgemäß lassen sich durch die Containerisierung der Dienste verschiedene Betriebsoptionen von einzelnen Server-Instanzen bis hin zum Clusterbetrieb realisieren. Für den Einsatz auf einem einzelnen Server kann man die StreamPipes-Umgebung schnell und bequem mittels Docker Compose starten, einem Werkzeug des Docker-Ökosystems zum Definieren und Ausführen von Multi-Container-Docker-Anwendungen. Die in einer YAML-Datei definierten StreamPipes-Dienste werden so konfiguriert und anschließend mit einem einzigen Befehl lokal gestartet.
Gerade in Anwendungsfällen, bei denen intern keine große Rechenressourcen zur Verfügung stehen oder aber die Cloud keine Option darstellt, kann auch ein Anwender ohne tiefgreifende Docker-Kenntnisse so in wenigen Minuten eine lauffähige StreamPipes-Instanz aufsetzen. Neben dem Server-Betrieb lassen sich so auch kleine, portable Mini-PC mit StreamPipes provisionieren, wodurch man das System für erste Machbarkeitstests zum Beispiel direkt auf dem Shopfloor in der Maschinenhalle in Betrieb nehmen kann.
Daneben kann man StreamPipes auch im verteilten Cluster nutzen. Dazu lassen sich die einzelnen Microservices in einer Kubernetes-Infrastruktur betreiben, wobei man zur Reduzierung der Komplexität und wegen der einfachen Anwendbarkeit auf Helm zurückgreift. Helm bietet als Paketmanager für Kubernetes-Applikationen die Möglichkeit, über sogenannte Helm Charts verhältnismäßig komplexe Kubernetes-YAML-Manifeste als einziges Paket zusammenzufassen. Die Installation des StreamPipes-eigenen Helm Charts in einem Kubernetes-Cluster lässt sich durch einen einzelnen Helm-Installationsbefehl sehr einfach realisieren (Listing 3).
Listing 3
StreamPipes-Helm-Chart installieren
$ helm install streampipes k8s
Hierdurch lassen sich auch Kubernetes-Cluster aus Edge-Knoten auf dem Shopfloor sowie auf zentralisierten Backend-Servern aufbauen. Das ermöglicht, direkt an der Maschine mit StreamPipes Connect die Daten frühzeitig anzubinden und gegebenenfalls Verarbeitungsalgorithmen zur Transformation, Filterung, Anreicherung und so weiter zu platzieren. Das stellt im Bedarfsfall sicher, dass man nicht zwangsläufig sämtliche Rohdaten übermitteln muss – oft ist das aufgrund von Restriktionen wie der erwarteten Latenz, der verfügbaren Bandbreite oder der Datenhoheit gar nicht umsetzbar.
Zu diesem Thema finden sich auch in einem Blogpost auf der StreamPipes-Webseite Detailinformationen zum Verwenden des StreamPipes-Helm-Charts in einem exemplarischen RasPi-4-Kubernetes-Cluster auf Basis der leichtgewichtigen K3s-Distribution von Rancher.
Fazit
Das noch relativ junge Incubating-Projekt Apache StreamPipes der Apache Software Foundation möchte die Zugänglichkeit datenstrombasierter Applikationen für Fachanwender verbessern. StreamPipes strebt mit dem zugrundeliegenden Microservice-Ansatz eine möglichst hohe Wiederverwendbarkeit der einzelnen Komponenten an. Hier gilt es allerdings letztlich, den Nutzen der Flexibilität einer solchen bausteinbasierten Lösung gegen den einer maßgeschneiderten, programmierten Anwendung abzuwägen. Letztere erfordert zwar einen erhöhten Programmieraufwand, bietet jedoch dafür in einigen Fällen auch mehr Konfigurationsoptionen.
Neben StreamPipes sowie den populären Tools Apache Flink und Apache Kafka gibt es in der Apache Software Foundation weitere Projekte, die in IoT-Einsatzszenarien Nutzen bringen. Das Top-Level-Projekt Apache PLC4X beispielsweise beschäftigt sich insbesondere mit der Anbindung von Maschinendaten im industriellen Kontext; bei Apache IoTDB handelt es sich um eine relativ neue, auf die Persistierung von Zeitreihen spezialisierte Datenbank. Die Apache Software Foundation pflegt dabei einen stark Community-getriebenen Entwicklungsansatz: Die Entwicklergemeinschaft freut sich über Beiträge aller Art und ermöglicht es dadurch jedem, das starke, auf Open-Source-Technologien beruhende IoT-Ökosystem auszubauen. (jcb)
Infos
-
Apache StreamPipes: https://streampipes.apache.org
-
StreamPipes auf Github: https://github.com/apache/incubator-streampipes





