
© Aliaksei Smalenski, 123RF
Die Pressure Stall Information, ein neuerdings im Linux-Kernel angesiedelter Messmechanismus, erlaubt eine bessere Sicht auf Ressourcenkonflikte, die den Produktivbetrieb stören.
CPU, Arbeitsspeicher und I/O sind die drei wichtigsten Ressourcen von Rechnern. Sind sie aufgebraucht, streiten sich die Prozesse darum, und es kommt zu Ressourcenkonflikten (Resource Contention). Daher empfiehlt es sich, den Ressourcenverbrauch von Anwendungen genau zu beobachten, um die Hardware-Anforderungen korrekt zu bemessen und vorhandene Hardware optimal auszulasten.
Auch Smartphones können davon profitieren: Sie beenden bei Ressourcenknappheit Programme im Hintergrund, um für die Anwendung im Vordergrund weiterhin genügend Ressourcen bereitzustellen und das Nutzererlebnis nicht zu beeinträchtigen.
Load Average
Die meisten Administratoren behalten den Lastdurchschnitt (Load Average) im Auge, um zu entscheiden, wie ausgelastet ein System ist. Die Kommandos »uptime« oder »top« zeigen ihn an (Listing 1), wofür sie die Datei »/proc/loadavg« auslesen. Sie enthält fünf Werte (Zeile 6), von denen der vierte die aktuell lauffähigen Kernel-Scheduling-Entities und deren Gesamtzahl angibt, der fünfte die zuletzt erstellte Prozess-ID.
Listing 1
Load Average auslesen
$ strace -e file uptime[...] openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 4 16:17:55 up 3 days, 3:27, 1 user, load average: 0,44, 0,78, 0,64 $ more /proc/loadavg 0.12 0.26 0.36 2/909 130726
Die ersten drei Werte geben den Lastdurchschnitt für die lauffähigen Prozesse an. Das sind solche mit dem Status R (Runnable), die auf CPU-Zeit warten, und dem Status D (Disk Sleep), die auf I/O warten. Die Werte geben das Lastmittel über eine Periode von 1, 5 und 15 Minuten wieder. Linux berechnet hier nicht nur die CPU-Auslastung, sondern bezieht auch I/O mit ein.
Es gibt nur wenige Admins, die diese Werte genau verstehen; auch die Kernel-Entwickler halten nicht unbedingt viel davon (Abbildung 1). Brendan Gregg [1] und Neil Gunther [2] geben in ihren Aufsätzen tiefere Einblicke in das Problemfeld.

Abbildung 1: Kommentar des Linux-Scheduler-Betreuers Peter Zijlstra zu »loadavg.c«.
Die Kurzform ihrer Erkenntnisse lautet: Der Load Average ist nicht zu gebrauchen, wenn es darum geht, die Systemauslastung zu beurteilen. Der Admin kann anhand der drei Werte höchstens einschätzen, ob ein mitgeteiltes Performance-Problem bereits behoben wurde, weil die Werte wieder kleiner werden. Mit der Load-Average-Berechnung ergeben sich aber noch weitere Nachteile:
- Der Admin muss die Werte relativ zur Anzahl der Threads und CPUs interpretieren. Ein Wert von 128 kann auf einem 128-Thread-System völlig akzeptabel sein. Auf einem 4-Thread-System geht hingegen vermutlich nichts mehr.
Der Wert verrät nicht, wie lange ein Prozess auf Ressourcen warten musste.
- CPU und I/O hängen zusammen. Das macht eine separate Untersuchung des CPU- und I/O-Bedarfs unmöglich.
- Weil die minimale Auflösung eine Minute beträgt, lässt sich die Last nicht in Echtzeit beobachten.
Damit eignet sich der Load Average nicht als Kennzahl für Admins, die schnell auf Performance-Ereignisse reagieren wollen.
PSI
Um Ressourcenkonflikte besser zu ermitteln und überlastete Systeme in den Rechenzentren von Facebook einfacher zu handhaben, entwickelte Facebooks Kernel-Team die Pressure Stall Information, kurz PSI. Laut der Webseite des Projekts [3] handelt es sich um einen kanonischen neuen Weg, über den Linux-Kernel Auslastungsmetriken für Speicher, CPUs und I/O zu erhalten.
Linus Torvalds veröffentlichte die Implementierung von Johannes Weiner 2018 mit Linux 4.20. Weiner ist auch als PSI-Betreuer eingetragen [4]. In Debian 10 “Buster” steckt diese Funktionalität noch nicht, aber in Ubuntu ab Version 19.04 mit einem Linux-Kernel ab Version 5.0 aufwärts ist sie zu finden. Als Schnittstelle zu PSI fungieren die drei Dateien »cpu«, »io« und »memory« im Verzeichnis »/proc/pressure/«.
CPU
In der Datei »/proc/pressure/cpu« finden sich die vier Werte »avg10«, »avg60«, »avg300« und »total« (Listing 2, Zeile 2). Die mit »avg*« beginnenden Werte stehen für den prozentualen Anteil, den Prozesse in den letzten 10, 60 und 300 Sekunden auf CPU-Ressourcen warten mussten.
Listing 2
cpu messen
$ more /proc/pressure/cpu some avg10=0.02 avg60=0.05 avg300=0.02 total=3990454056 [...] $ watch -n ,1 grep -R . /proc/pressure/cpu Alle 0,1s: grep -R . /proc/pressure/cpu maschine: Mon Jun 8 17:54:34 2020 some avg10=0.00 avg60=0.00 avg300=1.07 total=2684388193
Angenommen, zwei Prozesse belegen jeweils 100 Prozent eines Threads und laufen fünf Minuten lang auf einem System mit zwei Threads, auf dem sonst nichts weiter läuft. In diesem Fall liegen alle drei Durchschnittswerte bei null – klar, denn die Prozesse mussten nicht warten.
Bis auf die Unabhängigkeit von der CPU-Anzahl gibt es aber noch keinen großen Unterschied zum Load Average. Die Genauigkeit von 10 Sekunden hilft dem Admin aber bereits weiter, da er nun 50 Sekunden früher reagieren kann als beim Load Average.
Der letzte Wert, »total«, macht jedoch den Unterschied: Er gibt die Gesamtzeit in Mikrosekunden an, in denen Prozessen keine CPU-Ressourcen zur Verfügung standen. Diesen Wert kann der Admin zu beliebigen Zeiten auslesen, etwa alle 500 Millisekunden. Die Differenz zweier aufeinanderfolgender Werte ergibt dann die Anzahl von Mikrosekunden in diesem Zeitabstand, in denen Prozesse auf CPU-Ressourcen warten mussten.
Eine solche feine Auflösung gab es bisher noch nicht im Linux-Kernel. Über »watch« lässt sich anzeigen, wie sich der Wert in Echtzeit erhöht (Listing 2, Zeile 4 bis 6). Somit überwacht der Admin Ressourcenknappheit fast in Echtzeit und beendet gegebenenfalls unwichtige Prozesse oder migriert sie auf andere Systeme.
RAM und I/O
Die zwei weiteren Indikatoren »memory« und »io« geben sogar jeweils zwei Zeilen zurück. Die erste beginnt mit »some«, die zweite mit »full«. Die »some«-Werte gelten für mindestens einen Prozess, die »full«-Werte für alle. Listing 3 zeigt ein Beispiel für einen 2-Sockel-Rechenknoten mit AMD EPYC 7551 und insgesamt 128 Threads.
Listing 3
memory und io messen
$ grep -R . /proc/pressure/ /proc/pressure/io:some avg10=0.00 avg60=0.00 avg300=0.00 total=10587199096 /proc/pressure/io:full avg10=0.00 avg60=0.00 avg300=0.00 total=10072568253 /proc/pressure/cpu:some avg10=30.27 avg60=29.97 avg300=18.80 total=1620253162 /proc/pressure/memory:some avg10=0.00 avg60=0.00 avg300=0.00 total=15411 /proc/pressure/memory:full avg10=0.00 avg60=0.00 avg300=0.00 total=12389 $ uptime 07:24:59 up 2 days, 16:15, 1 user, load average: 150.58, 118.00, 76.42
Große »full«-Werte in »memory« können zum Beispiel bedeuten, dass das System in dieser Zeit keinen einzigen lauffähigen Prozess abarbeiten konnte und die CPU wahrscheinlich mit Paging beschäftigt war. Der Backup-Server in Listing 4 zeigt das recht illustrativ, er ist laut PSI überlastet. In der Tat dauerte eine Anmeldung auf dem System über SSH eine Minute. Der Load Average spiegelt das auf dem 24-Thread-System hingegen nicht wieder.
Listing 4
Überlasteter Backup-Server
$ grep -R . /proc/pressure/
/proc/pressure/io:some avg10=15.60 avg60=11.13 avg300=7.98 total=94192093351
/proc/pressure/io:full avg10=15.60 avg60=11.13 avg300=7.97 total=93713900789
/proc/pressure/cpu:some avg10=0.00 avg60=0.00 avg300=0.00 total=1159442298
/proc/pressure/memory:some avg10=67.79 avg60=67.80 avg300=72.51 total=618948360599
/proc/pressure/memory:full avg10=67.60 avg60=67.58 avg300=72.18 total=613900281165
Polling
Die Linux-PSI-Schnittstelle erlaubt zudem das Erzeugen von Ereignisbenachrichtigungen (Triggern), indem der Admin in die Dateien schreibt und sie dann mit »poll()« ausliest. Listing 5 schlüsselt die Syntax dazu auf, wobei die Angaben für die Werte »Stall_Amount« und »Time_Window« in Mikrosekunden erfolgen.
Listing 5
Poll-Syntax
some|full Stall_Amount Time_Window
Listing 6 zeigt das Beispiel für ein Monitorprogramm aus der Linux-Dokumentation [5]. Es definiert ein Ereignis, um Nachrichten zu erhalten, sobald ein Prozess innerhalb von einer Sekunde mehr als 150 Millisekunden lang keine RAM-Ressourcen erhält. Wer die Datei zum Beispiel »psi_example.c« nennt, übersetzt sie einfach mit »make psi_example«, sofern die Build-Tools installiert sind.
Listing 6
psi_example.c
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <poll.h>
#include <string.h>
#include <unistd.h>
/*
* Monitor memory partial stall with 1s tracking
* window size and 150ms threshold.
*/
int main() {
const char trig[] = "some 150000 1000000";
struct pollfd fds;
int n;
fds.fd = open("/proc/pressure/memory",
O_RDWR | O_NONBLOCK);
if (fds.fd < 0) {
printf("/proc/pressure/memory open error: %s\n",
strerror(errno));
return 1;
}
fds.events = POLLPRI;
if (write(fds.fd, trig, strlen(trig) + 1) < 0) {
printf("/proc/pressure/memory write error: %s\n",
strerror(errno));
return 1;
}
printf("waiting for events...\n");
while (1) {
n = poll(&fds, 1, -1);
if (n < 0) {
printf("poll error: %s\n", strerror(errno));
return 1;
}
if (fds.revents & POLLERR) {
printf("got POLLERR, event source is gone\n");
return 0;
}
if (fds.revents & POLLPRI) {
printf("event triggered!\n");
} else {
printf("unknown event received: 0x%x\n",
fds.revents);
return 1;
}
}
return 0;
}
Ausblick
Die auf nur eine oder zwei Zeilen komprimierten PSI informieren den Admin über Ressourcenknappheiten [6]. Die dateibasierte Schnittstelle ermöglicht es, Skripte einfach zu integrieren, und hilft beim Aufbau von Monitoring-Systemen. Auch externe Systemüberwachungswerkzeug wie Atop integrieren die PSI bereits (Abbildung 2).
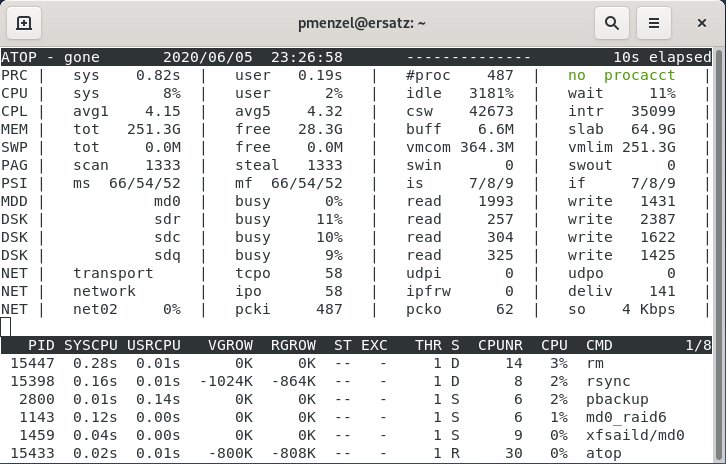
Abbildung 2: Seit Version 2.4.0 zeigt auch Atop die PSI mit an.
Dank der Integration der PSI in Cgroups erhält der Admin diese Informationen nicht nur systemweit, sondern auch fein abgestuft. Damit steht ihm neben dem bekannten Load Average eine leistungsfähigere Alternative zur Verfügung, um Ressourcenknappheiten besser zu überblicken. (kki/jlu)
Infos
-
“Solving the Mystery”: http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
-
Load Average: Dr. Neil Gunther, “Leistungsdiagnostik”, LM 08/2007, S. 84, https://www.lm-online.de/13548
-
Weiners Projektvorstellung: https://lkml.org/lkml/2018/8/28/816
-
PSI-Dokumentation: https://www.kernel.org/doc/html/latest/accounting/psi.html
-
Beispiele für den PSI-Einsatz: https://unixism.net/2019/08/linux-pressure-stall-information-psi-by-example/






