
© Evgeny Atamanenko, 123RF
Wer eine Virtualisierungsumgebung mit Gluster als Storage-Backend aufzieht, genießt alle Vorteile eines verteilten Fileservers. Gerät der aber aus dem Tritt, ist kluges Handeln angesagt.
Das verteilte Dateisystem Gluster eignet sich hervorragend als fehlertolerantes Storage-Backend für einen Hypervisor wie O-Virt. Damit wirken sich aber auch Probleme und Ausfälle in Gluster besonders auf den Betrieb aus. Ein mit sich selbst beschäftigtes Gluster in inkonsistentem Zustand beeinträchtigt zumeist massiv die Performance der darauf laufenden VMs. Admins stehen dann unter starkem Druck und fragen sich, was zu tun ist. Der Artikel gibt Hilfestellung und Orientierung für den Notfall.
Positiv ist: Die Lernkurve für den Umgang mit Gluster ist nicht so steil wie bei Ceph. Der Admin muss anfangs nur wenige Konzepte und Begriffe kennen:
- Die Teilnehmer eines Gluster-Clusters bilden einen Trusted Server Pool (TSP) und heißen Host, Node oder Peer.
- Die in Gluster eingebundenen Disks mit ihren Partitionen und Dateisystemen bezeichnen Admins als Bricks.
- Bricks lassen sich lokal oder idealerweise über das Netzwerk mit je eigenem TCP-Port einbinden.
- Zwei oder mehr Bricks fasst der Admin zu einem Gluster-Volume zusammen.
- Über die Bricks kann Gluster dann Daten n-fach repliziert verteilt ablegen und lesen.
Da Gluster also bestehende Dateisysteme zu einem oder mehreren Volumes kombiniert, ist es eigentlich kein Dateisystem – auch wenn das FS in Gluster-FS etwas anderes vermuten lässt.
Listing 1
Gluster installieren
01 yum install centos-release-gluster 02 yum install glusterfs-server 03 systemctl enable glusterd 04 systemctl start glusterd
Seit April 2019 ist Gluster 6 ab Centos 6 und höher verfügbar und lässt sich auf Centos 7 wie in Listing 1 installieren. O-Virt 4 setzt dabei noch auf Gluster 3.12 und seine Vorgänger. Weil diese Versionen inzwischen aber keine Updates mehr erhalten, beziehen Admins sie über die O-Virt-Repositories. Ein Volume namens »data« mit drei Disks, die jeweils auf einem Host liegen – mit dreifacher Redundanz und ohne weitere Optimierungen –, ist auch schnell eingerichtet. Die Befehle für »host1« zeigt Listing 2.
Listing 2
host1
01 gluster peer probe host2 02 gluster peer probe host3 03 04 gluster volume create data replica 3 \ 05 host1:/gluster/brick/data \ 06 host2:/gluster/brick/data \ 07 host3:/gluster/brick/data 08 gluster volume start data
Hausaufgaben
Wer Gluster verteilt betreibt, kommt um zwei Voraussetzungen nicht herum: Er braucht korrekte DNS-Einträge für die Gluster-Nodes (Forward und Reverse) sowie ein zuverlässiges NTP-Setup. Für den Fall, dass die DNS-Infrastruktur nicht verfügbar ist, sollte der Admin vorsichtshalber alle beteiligten Gluster-Nodes in der Datei »/etc/hosts« aller Nodes eintragen.
Kontra-intuitiv: Host-Firewalls abschalten
Host-Firewalls sind super – außer wenn sie stören. Da die Gluster-Nodes meist in einer vertrauenswürdigen Umgebung laufen, sollte der Admin lokale Firewalls abschalten. Was sich im ersten Moment widersinnig anhört, hat einen handfesten Grund: Storageserver sollen Daten schnell und vor allem zuverlässig verarbeiten. Erreichen sie dank versehentlich aktivierter und falsch konfigurierter Host-Firewalls die Bricks nicht auf ihren Netzwerk-Ports (Abbildung 1), sorgt das womöglich für Inkonsistenzen. Im Worst Case fällt das Storagesystem aus.

Abbildung 1: Netzwerk-Ports auf einem Gluster-Node mit vier aktiven Bricks.
Mitunter passiert es, dass ein Mitarbeiter eine lokale Firewall aus Versehen aktiviert. Für diesen Fall kann der Admin vorsorgen und die Firewall so tolerant und auskunftsfreudig wie möglich konfigurieren (Listing 3).
Listing 3
Freundliche Firewall
01 firewall-cmd --set-log-denied=all 02 firewall-cmd --permanent --zone=public --add-source=192.168.100.0/24 03 firewall-cmd --permanent --zone=public --add-port=1-65535/tcp 04 firewall-cmd --permanent --zone=public --add-port=1-65535/udp 05 firewall-cmd --reload 06 firewall-cmd --list-all 07 systemctl stop firewalld 08 systemctl disable firewalld
Wer sich von diesem Schritt allerdings auch noch eine Entlastung der Nodes oder messbare Performancegewinne verspricht, wird enttäuscht.
Mein Name ist Bond
Falls die Kommunikation zwischen den Gluster-Nodes zickt oder die VMs auf dem Hypervisor nicht funktionieren, sollte der Admin prüfen, ob und in welcher Form das Netzwerk Bonding-Interfaces einsetzt, und falls ja, in welchem Modus das Bonding läuft. Dessen Relevanz hängt davon ab, ob Gluster allein auf dem Host zum Einsatz kommt oder ob es sich die Maschine mit einem Hypervisor wie Red Hat Enterprise Virtualization (RHEV) oder dessen Upstream-Pendant O-Virt teilen muss (Stichwort: Hyperconverged Infrastructure).
Das Gluster-Projekt empfiehlt für die Gluster-Nodes zunächst den Bonding-Mode 6 (Adaptive Load Balancing, »balance-alb«). Über ihn senden Clients die meisten Schreibanfragen parallel über alle verbundenen Netzwerk-Interfaces der Gluster-Nodes. Das Problem: Bonding-Mode 6 arbeitet nicht mit Bridges zusammen und ist daher nicht mit logischen Netzwerken in VMs kompatibel. Wer also eine Hyperconverged Infrastruktur betreibt, setzt bei O-Virt/RHEV auf den dort empfohlenen Bonding-Mode 4 (IEEE 802.3ad).
Auch schon vorgekommen: Ein Switch nahm fälschlicherweise an, dass sich die Interface-Geschwindigkeit von beispielsweise 10 auf 1 GBit/s geändert hat. Daher handelte er die Verbindung neu aus – um sich kurz darauf wieder neu zu entscheiden. Die Aktion hängte einen Node im stark ausgelasteten Gluster-Cluster zweimal kurz ab, was im Folgenden zu einer Synchronisation und noch stärkerer Auslastung führte. Admins sollten sich daher überlegen, auf dem Switch die Geschwindigkeit der Netzwerk-Interfaces fest auf den zu erwartenden Wert einzustellen.
Jumbo-Performance
Admins setzen Jumbo-Frames mit Vorliebe ein, um den Datendurchsatz im Netzwerk signifikant zu steigern. Wer mit Netzwerkproblemen zwischen den Gluster-Nodes kämpft, sollte daher prüfen, ob die Jumbo-Frames aktiviert sind und noch funktionieren.
Jumbo-Frames sind aktiv, wenn die Gluster-Nodes eine MTU größer als 1500 melden – meist 9000. Das findet der Admin leicht über ein »ip a | grep mtu« heraus. Allerdings müssen in solchen Fällen auch alle dazwischen liegenden Netzwerkkomponenten Jumbo-Frames unterstützen.
Das Senden überlanger Frames von einem Gluster-Node zum nächsten testet der Admin mit »ping -s 1600 -M do Gluster-Node-n«, wobei »-s« die Paketgröße ohne Header festlegt und »-M do« die Fragmentierung auf dem Weg zum Empfänger verhindert.
Update-Trouble
Aktualisiert der Admin auf einem Node das erste Mal über »yum update« die vorhandene Software, sorgt mitunter die Fehlermeldung »GPG key retrieval failed: [Errno 14] Could not open/read file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat -auxiliary« für Unbehagen. Wer sie aber getrost ignoriert, macht alles richtig: Beim zweiten Aufruf von »yum update« taucht die Meldung in der Regel nicht mehr auf.
Schlimmer wird es, wenn der Admin nach einem »yum update« die Bricks eines Host nicht mehr erreicht. Hier hilft eine schnelle Analyse der Logfiles (siehe Tabelle 1). So entfernten Updates früher schon mal Shared Object Libraries (».so«-Dateien), die je nach Konfiguration für den Betrieb von Gluster essenziell waren. Das schlägt sich in den Logdateien mit Meldungen wie »/usr/lib64/glusterfs/3.12.6/rpc-transport/rdma.so: cannot open shared object file: No such file or directory« nieder.
|
Komponente |
Logfile |
|---|---|
|
Gluster-Daemon |
»/var/log/gluster/glusterd.log« |
|
Gluster-Self-Heal-Daemon |
»/var/log/gluster/glustershd.log« |
|
Gluster-Bricks |
»/var/log/glusterfs/bricks/gluster-Brick-Name–Volume-Name.log« |
Wer in diesem Fall auf RDMA, also Speicherdirektzugriff über das Netzwerk, verzichten kann, deaktiviert RDMA in der Datei »/etc/glusterfs/glusterd.vol« und startet den Gluster-Daemon neu.
Hat er die Host-Firewall auf seinen Gluster-Nodes deaktiviert, sollte der Admin zudem nach einem Update und vor einem Reboot prüfen, ob sie immer noch deaktiviert ist. Mitunter starten nach Updates Dienste automatisch neu.
Selbstheilend
Der Gluster-Cluster befindet sich in einem inkonsistenten Zustand? Wer sich fragt, wann der Self-Heal-Daemon (»glustershd«) von Gluster endlich mit dem Selbstheilungsprozess beginnt, wirft am besten einen Blick in das Setting »gluster volume get Volume-Name cluster.heal-timeout«. Das Intervall steht standardmäßig auf 600 Sekunden. Das ist im Produktivbetrieb nach Meinung des Autors zu lang, denn in dieser Zeit laufen die Bricks zu stark auseinander.
Den Mechanismus kann der Admin aber von Hand anstoßen. Dazu genügt der Aufruf von »gluster volume heal Volume-Name«, den Fortschritt überwacht »gluster volume heal Volume-Name info«. Viele Volume-Settings darf man auch zur Laufzeit ändern, ohne die Daemons neu starten zu müssen. Ist das Self-Healing angestoßen, heißt es warten.
Restart des glusterd
Der Befehl »systemctl restart glusterd« hängt den Node und dessen Bricks kurzzeitig ab. Das System protokolliert ab sofort alle im Gluster-Cluster stattfindenden Schreibvorgänge und synchronisiert sie, sobald der Node wieder da und die Selbstheilung angestoßen ist. Das kann je nach Schreiblast und Infrastruktur Stunden in Anspruch nehmen. Startet der Admin »glusterd« auf jenem Host neu, mit dem das System per Fusemount verbunden ist, bricht kurz die Verbindung ab.
Ein Beispiel für Shards im inkonsistenten Zustand zeigt Abbildung 2. Je nach Grad der Replikation wirken sich ein inkonsistenter Zustand oder die Replikation nicht auf die Datenintegrität aus, wohl aber auf die Performance angeschlossener Clients oder VMs. Ähnlich wie ein klassisches Raid will Gluster die inhaltlich auseinandergelaufenen Bricks synchronisieren. Die Load geht dabei teilweise extrem hoch, limitierender Faktor ist in fast allen Fällen der Datendurchsatz von Laufwerken und/oder Netzwerk.
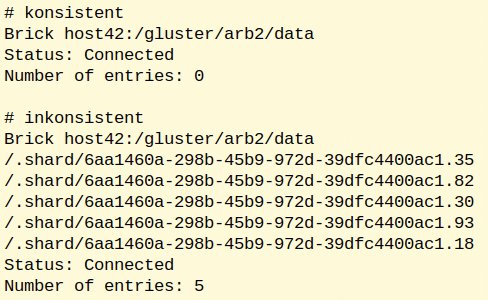
Abbildung 2: Gluster-Brick in zwei verschiedenen Zuständen.
Passend dazu lauten typische Kernel-Ring-Buffer-Meldungen wie »kernel:NMI watchdog: BUG: soft lockup – CPU#0 stuck for 22s!« oder »ata2.00: exception Emask 0x0 […] frozen«. Diese produzieren VMs, wenn sie auf hochausgelasteten Gluster-Systemen laufen, zum Beispiel in einem Hyperconverged-Setup.
Für die Ablage von VM-Disks konfiguriert der Admin Gluster in der Regel so, dass es Shards verwendet. Dazu lässt er die große VM-Disk in kleinere Häppchen fixer Größe aufteilen und gleichmäßig auf die Gluster-Nodes replizieren und verteilen. Die Gluster-Bricks sind damit in der Lage, nur die gerade angeforderten oder sich ändernden Bereiche einer VM-Disk sequenziell zu lesen oder zu schreiben, was die Geschwindigkeit erhöht.
Je nachdem, welcher Anleitung der Admin zu welchem Zeitpunkt folgt, verwendet er womöglich zu große Shards. Shards von beispielsweise 512 MByte Größe verringern zwar die Anzahl der zu verwaltenden Dateien im Gluster-Volume, führen aber dazu, dass Gluster bei der kleinsten Änderung in der VM-Disk jeweils 512 MByte liest, schreibt und repliziert, was den Heilungsprozess bremst.
Kleinere Shards
Das Gluster-Projekt empfiehlt, 64 MByte große Shards einzusetzen. Die für ein Volume gesetzte Shard-Größe lässt sich mit »gluster volume get Volume-Name features.shard-block-size« abfragen. Diesen Wert nachträglich zu ändern ist nicht möglich – dazu muss der Admin das Volume neu aufsetzen.
Wen das Gefühl beschleicht, dass der Heilungsprozess kein Ende nimmt, hält nach sich wiederholenden UUIDs (also Zeichenketten der Form »14fb48a6-c192-4c3f-a588-44c80cc36711«) im Gluster-Self-Heal-Daemon-Log sowie den Brick-Logs Ausschau. Shards erhalten eine UUID, wobei fortlaufende Nummern zusammenhängende Shards kennzeichnen. Die Datei ».shard/14fb48a6-c192-4c3f-a588-44c80cc36711.3599« ist der 3599ste Shard einer VM-Disk.
Tauchen immer wieder die gleichen Shard-UUIDs auf, dann schreibt nur eine VM, und Gluster kommt aufgrund von Last, limitierter Disk- oder Netzwerkbandbreite nicht mit der Synchronisation auf die anderen Nodes hinterher. Hier hilft es, die VM zu identifizieren und herunterzufahren.
Migration
Über »gluster replace-brick« verschiebt der Admin Bricks von einem Host zum anderen. Dabei kopiert oder verschiebt Gluster keinerlei Daten vom alten auf den neuen Brick, sondern macht es sich viel einfacher: Es hängt den alten Brick ab und repariert den neuen mit Hilfe des Self-Heal-Daemon. Es empfiehlt sich also, das Healing sofort nach »replace-brick« anzustoßen. Das Kommando lautet:
gluster volume replace-brick Volume-Name host1:/gluster/brick/data host4:/gluster/brick/data commit force
Wer VMs von einer Storage-Domain auf eine andere umziehen möchte, arbeitet am besten mit Bordmitteln seiner Virtualisierungslösung, etwa mit der Weboberfläche der O-Virt-Engine. Nach Möglichkeit sollten Admins nur ausgeschaltete VMs migrieren. Das ist deutlich schneller, weniger fehleranfällig und betrifft besonders Server, die irgendeine Form von Datenbanksystem fahren.
O-Virt erzeugt beim Umzug eingeschalteter VMs zunächst einen Snapshot der Maschine, verschiebt die Disk und führt am Ende die migrierte Disk und den Snapshot zusammen. Bei ausgeschalteter VM verschiebt O-Virt deren Disk dagegen einfach nur. Das Vorgehen hat zwar nichts mit Gluster an sich zu tun, funktioniert aber hier auch nicht besser oder schlechter als bei auf anderen Techniken basierenden Storage-Domains.
Nicht mehr verwendete, angehaltene Volumes löscht der Admin über »gluster volume delete Volume-Name«. Die Daten auf den Bricks bleiben dabei erhalten.
Split Brain
Gluster ist kaum aus dem Tritt zu bringen: In seinen Replikationsmodi und mit seinen Self-Heal-Daemons läuft es bewundernswert stabil. Schlimm wird es, wenn der Aufruf von »gluster volume heal Volume-Name info« Meldungen wie
Brick host7:/gluster/brickf/data/.shard/40643186-66de-4e2d-900a-b2bdcc762cdc.1000 - Is in split-brain Brick host9:/gluster/arb2/data/.shard/40643186-66de-4e2d-900a-b2bdcc762cdc.1000 - Is in split-brain
hervorruft. Einfachstes Beispiel für Split Brain sind zwei sich replizierende Nodes, die voneinander getrennt sind, jedoch weiterlaufen und Schreibanfragen von außen beantworten. Führt der Admin die Nodes wieder zusammen, ist die Datenintegrität dahin.
Gluster repariert Split-Brain-Dateien zunächst einmal nicht selbstständig, hier muss der Admin ran. Ist eine VM betroffen, muss er diese erst herunterfahren (Power-off). Um Split-Brain-Probleme zu lösen, bleiben ihm drei Optionen: Die erste besteht darin, die Datei zu heilen, die Gluster zuletzt geändert hat. Welche das ist, erfährt der Admin über den folgenden Befehl:
gluster volume heal Volume-Name split-brain latest-mtime Dateiname
Der zweite Ansatz besteht darin, einfach die größere der beiden identischen Dateien auszuwählen:
gluster volume heal Volume-Name split-brain bigger-file Dateiname
Im dritten Fall bestimmt der Admin aus der Menge an Bricks, die diese Datei führen, einfach einen Brick, der dann als Quelle zur Wiederherstellung dient:
gluster volume heal Volume-Name split-brain source-brick Host:Brick-Name
Die Dateien untersucht der Admin dabei mit »stat Dateiname« auf den betroffenen Hosts, um Details zu erfahren.
Wer dagegen sicher ist, dass es beispielsweise immer auf die neueste Datei ankommt, kann Gluster auch zur automatischen Korrektur von Split Brains bewegen. Standardmäßig steht die Einstellung »cluster.favorite-child-policy« auf »none«, lässt sich aber analog zur obigen Aufzählung auf »mtime«, »ctime« oder »size« setzen. Die Policy »majority« verwendet die Dateiversion als Quelle, die mit identischer »mtime« und »size« auf mehr als der Hälfte aller Bricks vorkommt.
Gluster bietet jedoch wesentlich mehr als die klassische Logfile-Überwachung. Mit dem »gluster«-Befehl lässt sich der Admin unter anderem Statusinformationen zu Volumes, Bricks oder Self-Heal-Daemons anzeigen oder debuggt Volumes. Tabelle 2 listet hilfreiche »gluster«-Befehle auf.
|
Problemstellung |
Passendes Kommando |
|---|---|
|
Welche Volumes gibt es? |
»gluster volume list« |
|
Sind die Bricks der Volumes online, laufen die Self-Heal-Daemons? |
»gluster volume status all« |
|
Wie steht es um den Plattenplatz der Bricks, um freie Inodes und so weiter? |
»for volname in $(gluster volume list); do gluster volume status $volname detail; done« |
|
Wer greift auf das Volume zu? |
»gluster volume status Volume-Name clients« |
|
Wie fällt der Speicherverbrauch der Bricks aus? |
»gluster volume status Volume-Name mem« |
Fazit
Gluster lässt sich zwar ganz einfach installieren, doch bedarf es – wie bei jedem anderen Storagesystem auch – einer für den Einsatzzweck ausgelegten Konfiguration sowie einer laufenden Überwachung. Zudem sollte der Admin einige Stolpersteine kennen und in Teilen wissen, wie Gluster unter der Haube arbeitet. Geplante Arbeiten sowie Troubleshooting lassen sich an kleinen virtuellen Testsystemen üben. Das Wichtigste im Ernstfall ist aber, auch unter Druck Ruhe zu bewahren und besonnen die nächsten Schritte durchzuführen.





