
© marinini, 123RF
Politisch aufgeladene Diskussionen wie die ums Asyl brauchen belastbare Zahlen. Dank des Informationsfreiheitsgesetzes sind diese direkt bei den Behörden erhältlich. Die liefern allerdings oft nur schlecht geeignete Formate. Gefragt sind dann Tools, um sie aufzubereiten.
Wer Zahlenmaterial aus verschiedenen Quellen, verschieden formatiert und mit verschiedenen Größenordnungen verarbeiten muss, braucht die richtige Technik. Dieser Beitrag stellt einen bewährten Ansatz vor und nutzt als Beispiel ein Projekt, zu dem sich 2015 eine Gruppe von Menschen aus der IT zusammenfand, um öffentliche Daten zum Thema Asyl einzufordern und sichtbar zu machen: der Refugee Datathon Munich.
Die Gruppe trifft sich seitdem regelmäßig in ihrer Freizeit, um zu einem Fakten-basierten Verständnis der Flüchtlingssituation beizutragen. Die Autorin dieses Artikels gehört dieser Gruppe an. Wie sieht der Weg von den Behördendaten bis zum Erkenntnisgewinn aus?
Vom PDF zum CSV
Die wichtigste Datenquelle zum Thema Asylanträge und -entscheidungen ist das Bundesamt für Migration und Flüchtlinge (BAMF). Seine Website bietet unter anderem eine Infothek [1]. Manche der dort abrufbaren Daten wurden allerdings erst online gestellt, nachdem sie mehrmals nachdrücklich unter Berufung auf das Informationsfreiheitsgesetz und teils mit Hilfe der Initiative Fragdenstaat.de [2] angefordert wurden.
Nun sind die Zahlen also verfügbar – allerdings gibt es sie in der Infothek des BAMF nur in Gestalt von PDF-Tabellen, die zu einem Teil auch noch mehrspaltige Überschriften haben. Für die Weiterverarbeitung ist das ein Problem.
Die Aktivisten kommen also nicht darum herum, die richtigen Daten im falschen Format zunächst umzuformen. Im ersten Schritt kommt dabei ein eher wenig bekanntes, aber sehr nützliches freies Programm zum Zuge: Tabula [3]. Diese Java-Applikation öffnet eine Weboberfläche, in die sich PDF-Tabellen importieren lassen. Aus ihnen erzeugt Tabula dann CSV-Dateien (Abbildung 1).
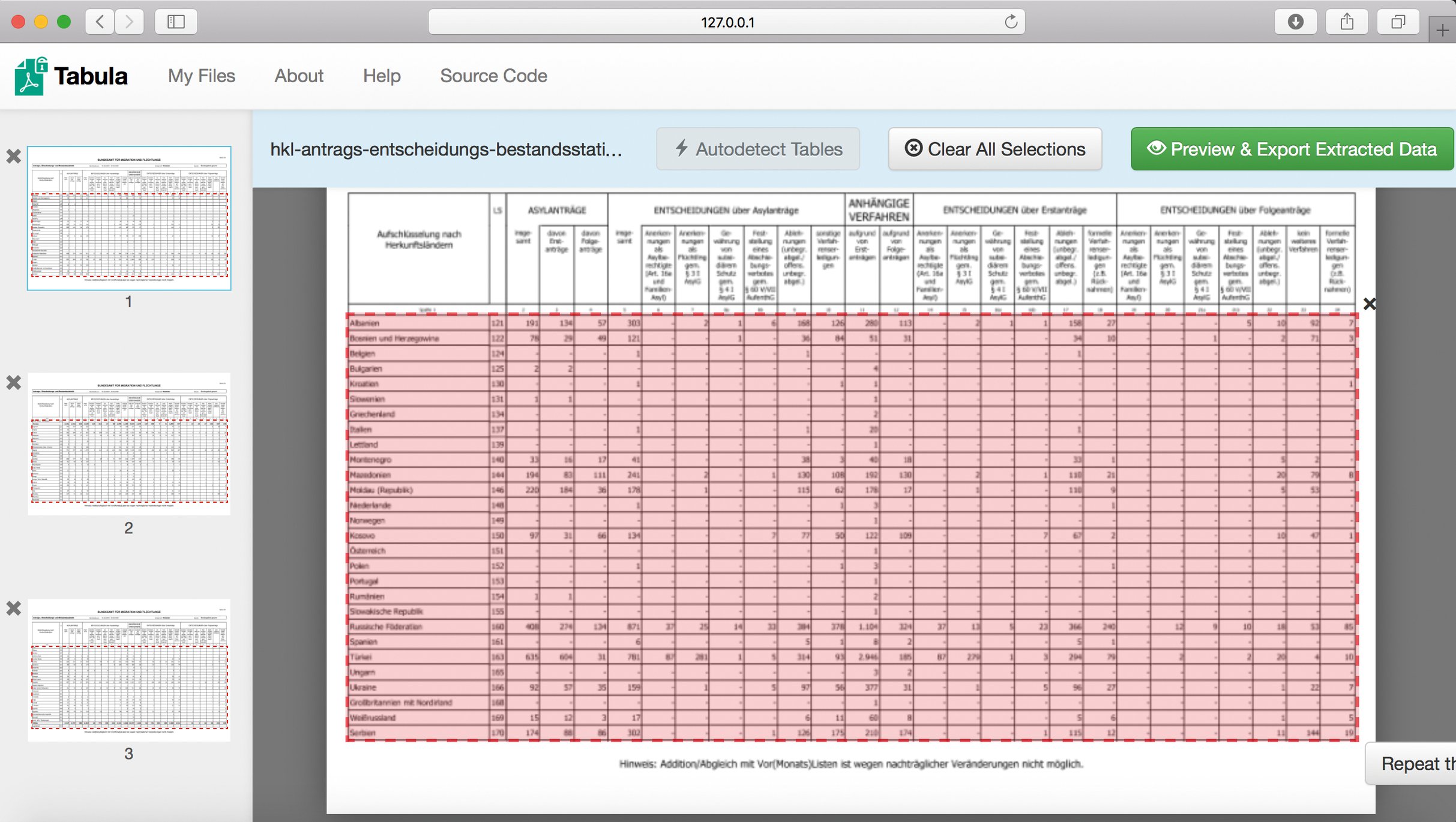
Abbildung 1: Das freie Programm Tabula extrahiert Daten aus einem markierten Aussschnitt einer PDF-Tabelle.
CSV ist dabei erst einmal nur ein Zwischenprodukt für die eigene Datenpipeline. Weil es aber das Andocken anderer Projekte erleichtert, eröffnen sich hier vielfältige Möglichkeiten: Nun lassen sich die Daten transformieren, in Datenbanken speichern oder direkt visualisieren. Dieser Artikel stellt etliche dieser Verfahren der Weiterverarbeitung vor.
CSV auch zum Publizieren
Außerdem bietet sich CSV an, um die Daten öffentlich verfügbar zu machen. Für kleine Datenmengen ist das auf Github möglich. Für Dateien ab 100 MByte käme beispielsweise die Git-Erweiterung Git Large File System in Frage, die Dateien bis 2 GByte abdeckt. Für noch größere Files könnte der Anwender auf eine Speichercloud wie Dropbox oder Amazon S3 zurückgreifen.
Wie bei der Veröffentlichung von Code gibt es auch bei der Veröffentlichung von Daten guten Stil. Dazu gehört es, mit den Daten ein File »datapackage.json« auszuliefern. Darin werden die Daten in einem definierten, aber flexiblen Format beschrieben [4]. Ein Beispiel für solch eine Datei »datapackage.json« für eine der aus BAMF-Daten generierten CSV-Tabellen des Refugee Datathon Munich zeigt Listing 1.
Listing 1
Beispiel eines datapackage.json
01 {
02 "contributors" : [
03 {
04 "role" : "author",
05 "title" : "refugee datathon munich"
06 }
07 ],
08 "homepage" : "https://refugee-datathon-muc.org",
09 "title" : "BAMF decision data",
10 "description" : "CSV created from PDF published by the German BAMF; columns on ENTSCHEIDUNGEN über Erstanträge",
11 "sources" : [
12 {
13 "path" : "http://www.bamf.de/DE/Infothek/Statistiken/Asylzahlen/Asylgesch%C3%A4ftsstatistik/asylgeschaeftsstatistik-node.html",
14 "name" : "German Migration Ministry BAMF"
15 }
16 ],
17 "resources" : [
18 {
19 "path" : "https://github.com/muc-fluechtlingsrat/bamf-asylgeschaeftsstatistik/blob/master/cooked/Gambia_cut.csv",
20 "schema" : {
21 "fields" : [
22 {
23 "type" : "yearmonth",
24 "format" : "default",
25 "name" : "YEAR_MONTH"
26 },
27 {
28 "type" : "integer",
29 "format" : "default",
30 "description" : "Anerkennungen als Asylberechtigte (Art. 16a und Familien-Asyl)",
31 "name" : "Asylberechtigt"
32 },
33 {
34 "name" : "Fluechtling",
35 "description" : "Anerkennungen als Flüchtling gem. § 3 I AsylG",
36 "format" : "default",
37 "type" : "integer"
38 },
39 {
40 "description" : "Gewährung von subsidiärem Schutz gem. § 4 I AsylG",
41 "name" : "subs. Schutz",
42 "type" : "integer",
43 "format" : "default"
44 },
45 {
46 "format" : "default",
47 "type" : "integer",
48 "description" : "Feststellung eines Abschiebungsverbotes gem. § 60 V/VII AufenthG\n",
49 "name" : "Abschiebungsverbot"
50 },
51 {
52 "format" : "default",
53 "type" : "integer",
54 "description" : "Ablehnungen (unbegr. abgel./ offens. unbegr. abgel.)\n",
55 "name" : "Abgelehnt"
56 },
57 {
58 "type" : "integer",
59 "format" : "default",
60 "name" : "sonstige Verfahrenserledigungen",
61 "description" : "formelle Verfahrenserledigungen (z.B. Rücknahmen)\n"
62 }
63 ]
64 },
65 "profile" : "tabular-data-resource",
66 "name" : "gambia_cut.csv"
67 }
68 ],
69 "licenses" : [
70 {
71 "title" : "Open Data Commons Public Domain Dedication and License v1.0",
72 "path" : "http://opendatacommons.org/licenses/pddl/",
73 "name" : "ODC-PDDL-1.0"
74 }
75 ],
76 "profile" : "tabular-data-package",
77 "name" : "refugee-datathon-bamf-country",
78 "keywords" : [
79 "BAMF",
80 "Asyl",
81 "refugee"
82 ]
83 }
Bereinigen und reduzieren
Der nächste Schritt sind Bereinigung, Transformation und Reduktion der Daten. Daten, die Fragen beantworten sollen, müssen nicht nur nach formalen, sondern auch nach inhaltlichen Kriterien richtig formatiert sein. Im vorliegenden Beispiel liefert das BAMF die Daten pro Monat, sortiert nach Herkunftsländern. Die Anwender interessieren sich aber für die nach Herkunftsland sortierten Daten und erst in zweiter Linie für deren Entwicklung im Lauf der Monate.
Wer versucht, diese Umformung naiv anzugehen, etwa mit einfachen Shellbefehlen, der stolpert schnell über Tücken wie Kommas in Ländernamen. Eine geeignete Toolsammlung für die Transformation von CSV-Dateien ist dagegen CSVkit (Abbildung 2, [5]). Sie ist in Python programmiert und bietet Befehlszeilenkommandos an. Man kann sie daher wie gewöhnliche Unix-Tools nutzen. Beispielsweise prüft »csvclean«, ob eine Datei sauberes CSV enthält. Mit »csvcut« lassen sich Spalten auswählen, wie Listing 2 zeigt.
Listing 2
Anwendungsbeispiel für csvcut
01 $ cat /tmp/csv 02 Irak,438,1.415,1.279,136,1.230,-,234,32,65,452,447,6.195,431,-,232,31,58,440,325,-,2,1,7,12,80,42 03 "Iran, Islamische Republik",439,862,774,88,719,19,95,7,5,268,325,2.522,271,19,94,7,3,260,286,-,1,-,2,8,30,9 04 05 $ cat /tmp/csv | csvcut -c 1,3,8,9,11 06 Irak,1.415,234,32,452 07 "Iran, Islamische Republik",862,95,7,268
Abbildung 2: Daten im CSV-Format eignen sich zur Weiterverarbeitung in einer Datenpipeline.
Vom CSV zur Visualisierung
Nach der Umwandlung ins CSV-Format ist die Visualisierung der nächste Schritt. Es gibt viele Möglichkeiten. Wo ansprechende, responsive Darstellungen wichtig sind, ist Datawrapper [6] eine gute Wahl. Diese Anwendung ist für den Datenjournalismus gemacht und sehr einfach bedienbar (Abbildung 3).
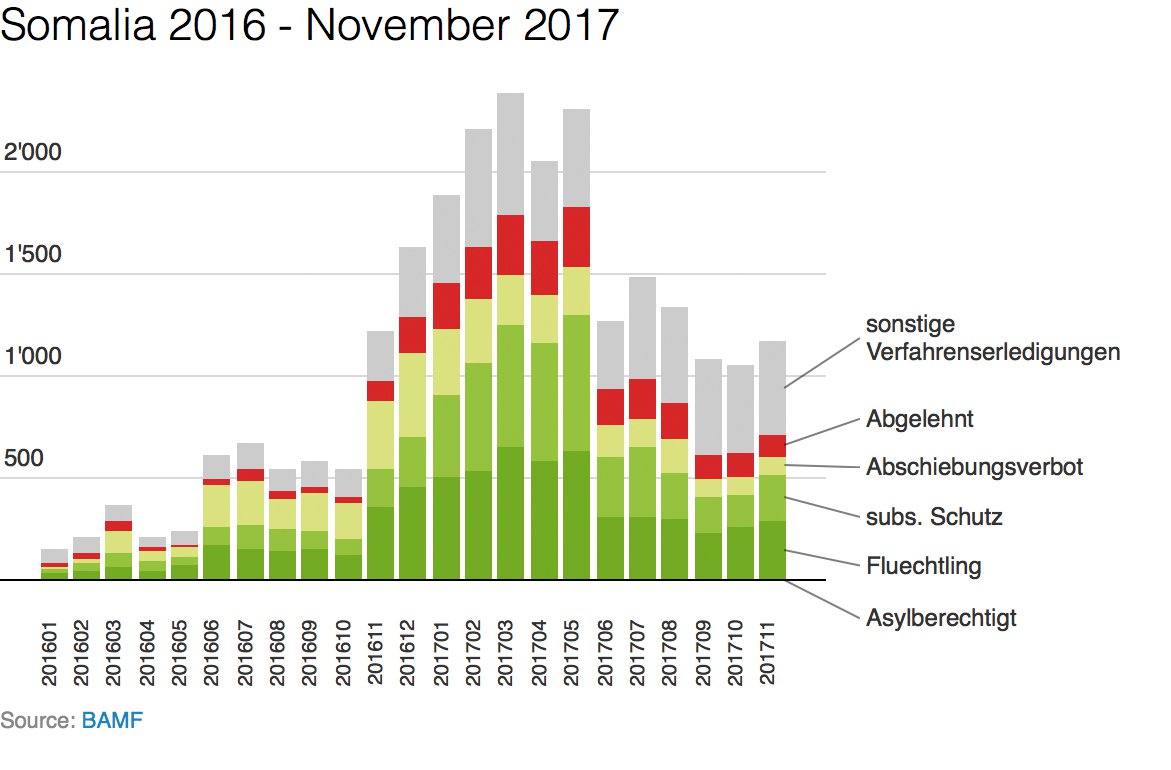
Abbildung 3: Ein solches Histogramm erzeugt Datawrapper.
Idealerweise bettet man die Visualisierungen dynamisch in eine Webseite ein. Das lässt aber nicht jeder Webhoster zu, zum Beispiel nicht WordPress.com, mit dem es die Anwender im vorliegenden Beispiel zu tun haben. Dann ist es ein gangbarer Ausweg, zuerst statische PNG-Files zu erzeugen und diese dann in die Webseite einzubinden.
Für einzelne Visualisierungen ist das eine gute Lösung. Wo aber eine ergiebige Datenbasis auf verschiedene Fragen hin zu untersuchen ist, kommt man schnell an den Punkt, an dem Hunderte statische Visualisierungen zu erstellen wären. In diesem Beispiel sind für jedes Herkunftsland drei Histogramme wichtig: die Anzahl der Anträge, die Entscheide in absoluten Zahlen und der prozentuale Anteil positiver Entscheide. Es gibt über 100 Herkunftsländer, das ergäbe über 300 Histogramme.
Deshalb ist zu wünschen, dass die Anwender selbst auswählen können, was sie sehen wollen. Die Lösung hierfür ist ein interaktives Dashboard, und als dessen technische Basis bietet sich Kibana [7] an. Kibana ist eine Javascript-Applikation, die es ermöglicht, ohne Programmierkenntnisse in einer Weboberfläche Visualisierungen zu erzeugen: von Tortendiagrammen über Zeitreihen bis zu Karten. Sie sind interaktiv, mit einem Klick lässt sich die Darstellung anpassen. Im vorliegenden Fall wird ein Diagramm mit den Entscheidungen zu allen Herkunftsländern angeboten, und der Anwender kann auf das Land einschränken, das ihn interessiert. Die Visualisierungen ordnet das System in Dashboards.
Kibana braucht als Datenquelle Elasticsearch [8], einen NoSQL-Datenstore, der meist als Cluster betrieben wird. Das Aufsetzen eines Clusters ist unkompliziert. Wer sich für eine gehostete Lösung entscheidet, spart auch diese Arbeit, wird aber Ausgaben haben.
Wichtig ist, dass die Daten schon mit den richtigen Feldern in Elasticsearch ankommen. Für den Datenimport in Elasticsearch empfiehlt sich das Tool Logstash [9]. Eine Konfiguration mit CSV-Daten als Quelle findet sich in Listing 3. Dort liest es eine CSV-Datei ein.
Listing 3
Logstash-Konfigurationsdatei
01 input { file { path => "/tmp/201805.csv" start_position => "beginning" } }
02
03 filter {
04 csv {
05 separator => ","
06 columns => [ "Year_Month", "Herkunftsland", "Asylantraege", "Erstantraege", "Folgeantraege", "Entscheidungen", "Asylberechtigte", "Fluechtlingseigenschaft", "subsidiaerer_Schutz", "Abschiebungsverbot", "Ablehnungen", "sonstige_Erledigungen", "anhaengige_Erstantraege", "anhaengige_Folgeantraege" ]
07 add_field => { "document_key" => "%{Year_Month}_%{Herkunftsland}" }
08 convert => {
09 "Asylantraege" => "integer"
10 "Erstantraege" => "integer"
11 "Folgeantraege" => "integer"
12 "Entscheidungen" => "integer"
13 "Asylberechtigte" => "integer"
14 "Fluechtlingseigenschaft" => "integer"
15 "subsidiaerer_Schutz" => "integer"
16 "Abschiebungsverbot" => "integer"
17 "Ablehnungen" => "integer"
18 "sonstige_Erledigungen" => "integer"
19 "anhaengige_Erstantraege" => "integer"
20 "anhaengige_Folgeantraege" => "integer"
21 }
22 }
23 }
24
25 # for debugging
26 #output { file { path => "/tmp/elastic.out" } }
27
28 output {
29 elasticsearch {
30 hosts => ["your_elasticsearch_host:port"]
31 password => "your_password"
32 user => "your_user"
33 index => "your_index"
34 document_id => "%{[document_key]}"
35 }
36 }
Wenn das Datum im ISO-Format vorliegt, erkennt Elasticsearch es automatisch. Alternativ kann der Programmierer das Feld im Mapping von Elasticsearch als Datum definieren. Um Duplikate zu vermeiden, ist es ratsam, eine eindeutige Dokument-ID zu nutzen. Etwas ungewöhnlich ist hier, dass das Kibana-Dashboard direkt aus dem Internet zugänglich ist. In diesem Fall geht es nicht ohne ein Sicherheitsprodukt, das die Daten schützt. Naiv könnte man daran denken, einen Proxy einzurichten, der nur bestimmte Anfragen zulässt. Das ist bei der Komplexität der Anfragen aber unrealistisch.
Elastic, das Unternehmen hinter Elasticsearch, Logstash und Kibana, bietet eine in Elasticsearch integrierte Sicherheitslösung an: Elasticsearch Security [10]. Sie ist allerdings lizenzpflichtig. Damit kann der Admin Rollen für schreibenden und lesenden Zugriff anlegen und Visualisierungen und Dashboards vorbereiten. Im vorliegenden Fall übernimmt das der Refugee Datathon Munich. Die Besucher loggen sich mit einer Rolle ein, die nur Leserechte besitzt. Sie können die Ansicht für sich anpassen, aber weder die Daten noch die Ansicht für andere Benutzer ändern (Abbildung 4).
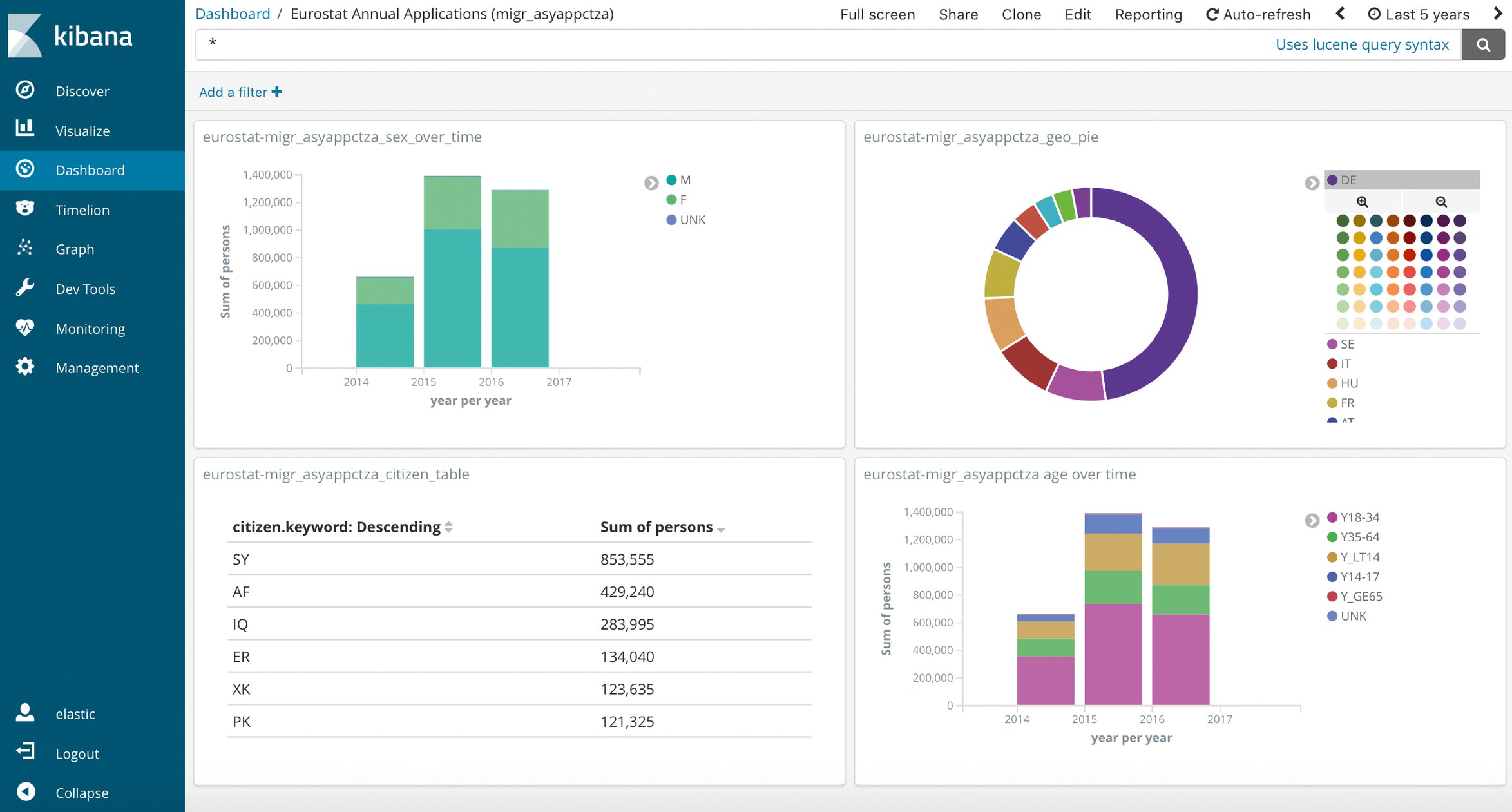
Abbildung 4: Ein frei zugängliches, interaktives Dashboard im Netz.
Ein interaktives Kibana-Dashboard im Netz – das klingt erst einmal nach einer guten Lösung, ist allerdings im Detail noch nicht benutzerfreundlich. So muss sich der Anwender ein wenig umständlich zunächst einloggen, um etwas zu sehen. Die Bedienung der Dashboards ist zwar einfach, aber dazulernen muss man doch. Für Mobilgeräte ist die Visualisierung völlig unbrauchbar. Wenn der Webhoster kein Einbetten von Kibana zulässt, müssen die Besucher weitergeleitet werden. Nur ernsthaft interessierte Nutzer nehmen all diese Hürden. Beim Refugee Datathon Munich sind das etwa Flüchtlingsunterstützer, die jemanden aus einem ungewöhnlichen Herkunftsland kennen und Informationen zur Anerkennungsquote suchen.
Mittelfristig ist Besserung in Sicht. Elastic arbeitet daran, das Login abschaltbar zu machen. Innerhalb von Unternehmen sind interaktive Dashboards etabliert und erreichen nicht nur technisch versierte User. Auch das Internet verändert sich in diese Richtung. Datenjournalismus reichert so manchen Artikel mit interaktiven Visualisierungen an, die den Besuchern sowohl mehr abverlangen als auch mehr bieten als bisher.
Big Data von der Europäischen Union
Neben dem BAMF gibt es eine weitere Datenquelle, bei der weniger das Format als die Menge der Daten Kopfzerbrechen bereitet: Eurostat. Das ist das statistische Amt der Europäischen Union. Dort finden sich Datenbanken zu den verschiedensten Themen. Eurostat bietet APIs zum Herunterladen von Daten an – ein Traum im Vergleich zu den PDFs des Bundesamts. Aber auch hier gibt es in der Praxis Stolperfallen.
Im hier vorgestellten Beispiel sind die jährlichen Asylantrag-Daten zu bearbeiten, sie tragen den schönen Namen »migr_asyappctza« und enthalten knapp vier Millionen Werte. Damit wäre ein bekanntes Bonmot erfüllt, wonach unter Big Data alles fällt, was Excel zum Absturz bringt.
Damit die Zahlen am Ende auch stimmen, muss der Anwender die Datenstruktur beachten. Die Eurostat-Daten haben totale und überlappende Altersklassen. Wer diese nicht ausschließt, zählt die Anträge mehrfach. Außerdem gibt es in diesen Daten Null-Values, also fehlende Werte, denn nicht alle Länder liefern zur gleichen Zeit. In den Visualisierungen haben sie denselben Effekt wie eine Null, was irreführend ist. Hierüber muss man die Anwender informieren.
Mit R zu statischen Diagrammen
Für die Statistiksprache R ist dieses Datenvolumen kein Problem, wenn die Maschine, auf der es zu verarbeiten ist, entsprechend mit CPU und Memory ausgestattet ist. Das hier vorliegende Codebeispiel (Listing 4) importiert zunächst benötigte Bibliotheken. Es gibt ein fertiges Paket zur Bearbeitung von Eurostat-Daten, »r-eurostat«. Die anderen beiden Bibliotheken kommen beim Erstellen der Diagramme zum Einsatz.
Listing 4
R-Skript
01 library(eurostat)
02 library(ggplot2)
03 library(scales)
04
05 migr_asyappctza=get_eurostat("migr_asyappctza")
06
07 de_sy_migr_asyappctza <- subset(migr_asyappctza, citizen == "SY" & geo == "DE" & asyl_app == "ASY_APP" & sex != "T" & age != "TOTAL" & age != "Y_LT18")[c(2,4,7:8)]
08
09 ggplot(de_sy_migr_asyappctza, aes(x=time, y=values, fill=sex)) + geom_bar(stat="identity", position="dodge") + scale_y_continuous(labels=comma) + scale_x_date() + ggtitle("Asylanträge von syrischen Staatsangehörigen", subtitle="In Deutschland, nach Geschlecht") + xlab("Jahr") + ylab("Anzahl Asylanträge") + scale_fill_discrete() + theme_light()
Zeile 5 lädt die Daten. Der Rest des Listings reduziert die Daten zeilenweise auf:
1. Anträge von Syrern,
2. gestellt in Deutschland,
3. vom Typ »ASY_APP«,
4. ohne die Totale über Alter und Geschlecht,
5. ohne eine Altersgruppe, die sich mit anderen überschneidet.
Außerdem bleiben lediglich die Spalten von Interesse. Die letzte Zeile erstellt das Histogramm.
Noch mal Elastic-Tools
Was mit den überschaubaren Datensätzen des Bundesamts geschah, das geht auch mit den Eurostat-Daten: Eine CSV-Datei erzeugen und sie dann mit Logstash in Elasticsearch laden und in Kibana visualisieren. Die Datenmengen bereiten den besagten Tools keinerlei Probleme. Um an die Rohdaten zu kommen, kann man sie einfach herunterladen mit dem Kommando:
wget -O migr_asyappctza.tsv.gz http://ec.europa.eu/eurostat/estat-navtree-portlet-prod/BulkDownloadListing?file=data/migr_asyappctza.tsv.gz
Leider ist die resultierende Datei noch kein CSV, sondern eine Mischung aus Komma- und Tab-separierten Werten:
citizen,sex,unit,age,asyl_app,geo\time 2017 2016 2015 AD,F,PER,TOTAL,ASY_APP,AT 0 0 0 0 AD,F,PER,TOTAL,ASY_APP,BE 0 0 0 0 AD,F,PER,TOTAL,ASY_APP,BG 0 0 0 0
Um die Daten sauber in Elasticsearch einlesen zu können, braucht man sie in der Form:
Variable_1, ... , Variable_m, Observation_1 _var_1, ... , Observation_1_var_m ... Observation_n_var_1, ... , Observation_n_ Var_m
In der Welt von R heißt das Tidy Data. Das CSV-Tabulator-Mischformat lässt sich mit Hausmitteln in die gewünschte Form bringen, beispielsweise mit PHP (Listing 5). Sobald die CSV-Dateien sauber vorliegen, funktioniert alles ab dem Einlesen mit Logstash wie gehabt.
Listing 5
PHP bringt eine Tabelle in Form
01 <?php
02 //Defining the files
03 $valueWhenTheresNoData = "";
04 $in = file("migr_asyappctza.tsv");
05 $out = fopen("migr_asyappctza_unpivot.csv", "w+");
06
07 //header in output file
08 fwrite($out, "citizen,sex,unit,age,asyl_app,geo,time,ammount\n");
09
10 $in_array_line1 = explode("\t",$in[0]);
11 //The year comes in in a faulty format, so correct it to the right one
12 for ($i = 1; $i < count($in_array_line1); $i++) {
13 $year = "";
14 for ($j = 0; $j < 4; $j++) {
15 $year .= $in_array_line1[$i][$j];
16 }
17 $in_array_line1[$i] = $year;
18 }
19 for ($k = 1; $k < count($in); $k++) {
20 $in_array_lineK = explode("\t",trim($in[$k],"\n"));
21 for($i = 1; $i < count($in_array_line1); $i++){
22 $data_out = $in_array_lineK[0] . "," . $year . ",";
23 if ($in_array_lineK[$i] === ": " or $in_array_lineK[$i] === ": \n") {
24 $data_out .= $valueWhenTheresNoData;
25 } else {
26 $data_out .= trim($in_array_lineK[$i],"bcdefinprsuz"); //removes the flags and footnotes
27 }
28 $data_out .= "\n";
29 fwrite($out, $data_out);
30 }
31 }
32 fclose($out);
33 ?>
Fazit
Technisch ist der Weg von den Behördendaten zur Visualisierung kein Hexenwerk. Es hilft allerdings, die richtigen Tools zur Hand zu haben. In Eurostat und den Open-Data-Portalen von Städten, Ländern und Bund wartet noch viel auf seine Entdeckung, beispielsweise [11] oder [12]. Wer Interesse und das technische Know-how mitbringt, kann hier Schätze heben.
Infos
-
Infothek des BAMF: http://www.bamf.de/DE/Infothek/Statistiken/statistiken-node.html
-
Frag den Staat: https://fragdenstaat.de
-
Tabula: https://tabula.technology
-
Data Package: https://frictionlessdata.io/docs/data-package
-
Datawrapper: https://www.datawrapper.de
-
Elasticsearch: https://www.elastic.co/de/products/elasticsearch
-
Elasticsearch Security: https://www.elastic.co/de/products/stack/security
-
Open-Data-Portal München: https://www.opengov-muenchen.de
-
Transparenzportal Hamburg: http://transparenz.hamburg.de/open-data





