© Stephen Kirschenmann, 123RF
Websiten-Releases finden heute nicht selten mehrmals am Tag statt. Terraform hilft dabei, virtuelle Maschinen im eigenen Rechenzentrum oder in der Cloud automatisiert auszurollen. Dafür schreibt der Admin lediglich eine Anleitung und passt diese bei Änderungen an.
Vorbei sind vielerorts die Zeiten, in denen sich Admins die Nächte um die Ohren schlugen, um die eigene Infrastruktur auf neue Software-Releases vorzubereiten. Die Entwicklungszyklen werden immer kürzer, die Entwicklerteams arbeiten immer agiler. Um den neuen Anforderungen Rechnung zu tragen, müssen auch Admins gezwungenermaßen mehr über Automatisierung nachdenken.
Eine Möglichkeit, dies umzusetzen, liefert das Konfigurationsmanagement. Hier genügt es zum Beispiel, nur die Konfiguration virtueller Maschinen zu beschreiben, um sie später nach diesem Bauplan auszuliefern und zu aktualisieren.
Die Idee nutzt Terraform [1] von Hashicorp, um auch Infrastruktur zu provisionieren oder anzupassen. Vom Anbieter stammt zudem Vagrant, das sich um Deployments von Entwicklungsumgebungen kümmert. Terraform ermöglicht nicht nur ein reines Provisionieren von Infrastruktur, sondern erlaubt es auch, bereits provisionierte Umgebungen zu verändern. Die Konfigurationsdateien erwartet Terraform als Textdateien, die schlicht Konfigurationen heißen und die Datei-Endung ».tf« tragen. Sie lassen sich mit Tools wie Git oder SVN versionieren.
Als Format wählt der Admin zwischen HCL (Hashicorp Configuration Language) und Json, wobei sich HCL an Json anlehnt, jedoch zugleich auch Kommentare und einige andere Erweiterungen unterstützt, die das Coden vereinfachen sollen. Die im Artikel gezeigten Codebeispiele verwenden daher das HCL-Format.
Bauplan
Terraform erledigt nahezu alle Arbeiten, die beim Deployment von virtueller Infrastruktur anfallen. Das beginnt beim Bereitstellen virtueller Maschinen mit VMware und Open Stack im eigenen Rechenzentrum, aber auch bei Cloudprovidern von Amazon oder Oracles Public Cloud und reicht bis hin zu Anpassungen am DNS- oder Monitoringserver. Für diesen Zweck verwendet Terraform unterschiedliche Provider [2], die für die entsprechenden Plattformen Ressourcen bereitstellen, die wiederum in die Konfigurationen einziehen.
Der Artikel spielt das exemplarisch am Beispiel von Digital Ocean [3] durch. Er gibt einen Einblick, wie Terraform arbeitet, und zeigt an einem Beispiel, dass das Paradigma “Infrastructure as Code” gar keine so große Hürde darstellen muss.
Fundament
Zuerst braucht der Admin Accounts für Digital Ocean und für Cloudflare, wozu auch gültige API-Keys gehören. Außerdem muss er bei Cloudflare eine eigene Domain konfigurieren.
Terraform installieren erweist sich als recht simple Prozedur. Hat der Admin das passende Zip-Archiv von [4] heruntergeladen, muss er nur das Binary darin entpacken und an einen Ort im Dateisystem kopieren, den auch die »$PATH«-Variable abdeckt. Hierfür bietet sich »/usr/local/bin« an. Anschließend genügt es, den Befehl »terraform« auszuführen.
Ziel der Übung ist es, beim Cloudprovider Digital Ocean ein Droplet zu platzieren. Dabei handelt es sich um nichts anderes als eine virtuelle Maschine, in diesem Fall mit vorinstallierter Applikation, einem Docker-Daemon. Auf diesem startet dann ein Container, der einen Webservice bereitstellt. Nach dem erfolgreichen Provisionieren bei Digital Ocean soll Terraform einen passenden DNS-Eintrag erzeugen, damit Dritte die Webapplikation automatisch per Domain und nicht nur über ihre IP-Adresse aufrufen können.
Der Plan erfordert zunächst einen Ordner, in dem alle weiteren Konfigurationen landen. Wichtigste Datei ist die »variables.tf« (Listing 1), die sämtliche verwendeten Variablen deklariert. Dabei kann es sich um Default-Werte, Typen oder eine Beschreibung für den Variablenwert handeln.
Listing 1
variables.tf
01 variable "site_name" {
02 description = "Beschreibung"
03 type = "string"
04 default = "DEMO-SITE"
05 }
06 variable "site_author" {
07 type = "string"
08 default = "Jon Doe"
09 }
10 variable "site_container" {}
11 variable "do_token" {
12 type = "string"
13 }
14 variable "key_path" {}
15 variable "ssh_priv_key" {}
16 variable "ssh_pub_key" {}
17 variable "cloudflare_email" {}
18 variable "cloudflare_token" {}
19 variable "cloudflare_domain" {}
Die nächste Datei setzt deklarierte Variablen. Bei ihr kommt es nicht nur auf die Datei-Endung, sondern auch auf den Dateinamen an: »terraform.tfvars« (Listing 2). Sie enthält unter anderem die API-Keys für Digital Ocean und Cloudflare. Hinweise dazu, wo der Admin solche API-Token findet, liefern [5] und [6].
Ressourcenplanung
Nun legt der Admin je eine Datei für alles an, was Digital Ocean und Cloudflare betrifft. Die Konfigurationen auf zwei Dateien zu verteilen ist an sich nicht erforderlich und auch keine Konvention, erleichtert jedoch die Übersicht, die Versionierung und die gemeinsame Arbeit an der Infrastruktur.
Listing 2
terraform.tfvars
01 do_token = "01189998819991197253" 02 ssh_priv_key = "/home/jon.doe/.ssh/id_rsa" 03 ssh_pub_key = "/home/jon.doe/.ssh/id_rsa.pub" 04 cloudflare_email = "jon.doe@example.com" 05 cloudflare_token = "01189998819991197253" 06 cloudflare_domain = "example.com" 07 site_name = "mysite.example.com" 08 site_author = "John Doe" 09 site_container = "dockersamples/static-site"
Terraform liest beim Ausführen selbstständig alle Dateien mit ».tf*«-Endung ein. Über die Datei »digitalocean.tf« (Listing 3) lädt es zuerst den Provider »digitalocean« und übergibt dann das API-Token aus der Variablen »do_token« aus der Datei »terraform.tfvars«. Über die Zeichenfolge »”${var.Variablenname}”« greift Terraform also auf Variablen zu. Im nächsten Schritt ruft Terraform die Ressource »digitalocean_ssh_key« mit dem Namen »jondoe« auf (Zeile 4). Sie liest aus einer Datei des lokalen Filesystems den öffentlichen Key aus und lädt ihn zu Digital Ocean hoch. Die virtuelle Maschine benötigt ihn später.
Listing 3
digitalocean.tf
01 provider "digitalocean" {
02 token = "${var.do_token}"
03 }
04 resource "digitalocean_ssh_key" "jondoe" {
05 name = "Key von Jon"
06 public_key = "${file("${var.ssh_pub_key}")}"
07 }
08 resource "digitalocean_droplet" "mywebapp" {
09 image = "docker-16-04"
10 name = "mydockerdroplet"
11 region = "fra1"
12 size = "512mb"
13 ssh_keys = ["${digitalocean_ssh_key.jondoe.id}"]
14 provisioner "remote-exec" {
15 inline = [
16 "docker run -p 80:80 --name ${var.site_name} -e AUTHOR=\"${var.site_author}\" -d -P ${var.site_container}",
17 ]
18 connection {
19 type = "ssh"
20 user = "root"
21 private_key = "${file("${var.ssh_priv_key}")}"
22 }
23 }
24 }
25 output "IP" {
26 value = "${digitalocean_droplet.mywebapp.ipv4_address}"
27 }
Die zweite Ressource »digitalocean_droplet« (Zeile 8) trägt den Namen »mywebapp« und erzeugt aus dem Image »docker-16-04«, das neben Ubuntu 16.04 auch einen vorinstallierten Docker-Daemon enthält, ein Droplet. Dank der Zeile 13, die mit »ssh_keys« beginnt, greift Terraform auf einen Wert »id« der Ressource »digitalocean_ssh_keys« und dem Namen »jondoe« zu. Das Attribut »id« speichert Terraform nach dem erfolgreichen Ausführen der Ressource »digitalocean_ssh_keys« und stellt es allen anderen Ressourcen bereit.
Zugleich definiert die Datei eine Abhängigkeit: Terraform führt »digitalocean_droplet« erst aus, wenn es den Wert aus »digitalocean_ssh_key.jondoe.id« kennt. Greift es auf Attribute von Ressourcen zu, baut Terraform automatisch diese Abhängigkeiten auf und ruft die Ressourcen entsprechend in der richtigen Reihenfolge auf. Welche Attribute bereitstehen, geht aus der Ressourcen-Dokumentation [7] hervor. Bestehen weitere Abhängigkeiten, die Terraform nicht automatisch erkennt, weil sie keine Attribute anderer Ressourcen verwenden, muss der Admin diese explizit setzen [8].
Ab Zeile 25 definiert Listing 3 schließlich eine Output-Variable und deklariert diese mit einem Attribut. Diese Variable, die hier den Namen »IP« trägt, gibt Terraform explizit auf der Konsole aus, wenn das Programm seine Aufgabe erfolgreich abgeschlossen hat.
Erreichbarkeit
Innerhalb von Ressourcen darf der Admin Provisioner einsetzen. Diese führt Terraform wahlweise lokal aus oder – mit den entsprechenden Verbindungsdaten – remote über SSH oder Win RM. Hat der Admin etwa eine VM angelegt, kann er die öffentliche IP in einer lokalen Datei auf der eigenen Workstation ablegen oder sie, wie in diesem Beispiel, dem Provisioner »remote-exec« übergeben, der einen Befehl auf dem erstellten Droplet ausführt und dadurch einen Docker-Container startet.
Bevor Terraform die Cloudflare-Konfiguration erstellt, sollte der Admin die bisherige Konfiguration testen. Hierfür muss er zunächst mittels »terraform init« (Abbildung 1) einen Initialisierungsprozess in Gang setzen. Der durchsucht alle ».tf«-Dateien nach Providern, prüft, ob die zugehörigen Providerdefinitionen bereits vorhanden sind, und lädt sie gegebenenfalls aus dem Internet herunter. Den Befehl muss er stets ausführen, wenn neue Provider zum Zuge kommen.
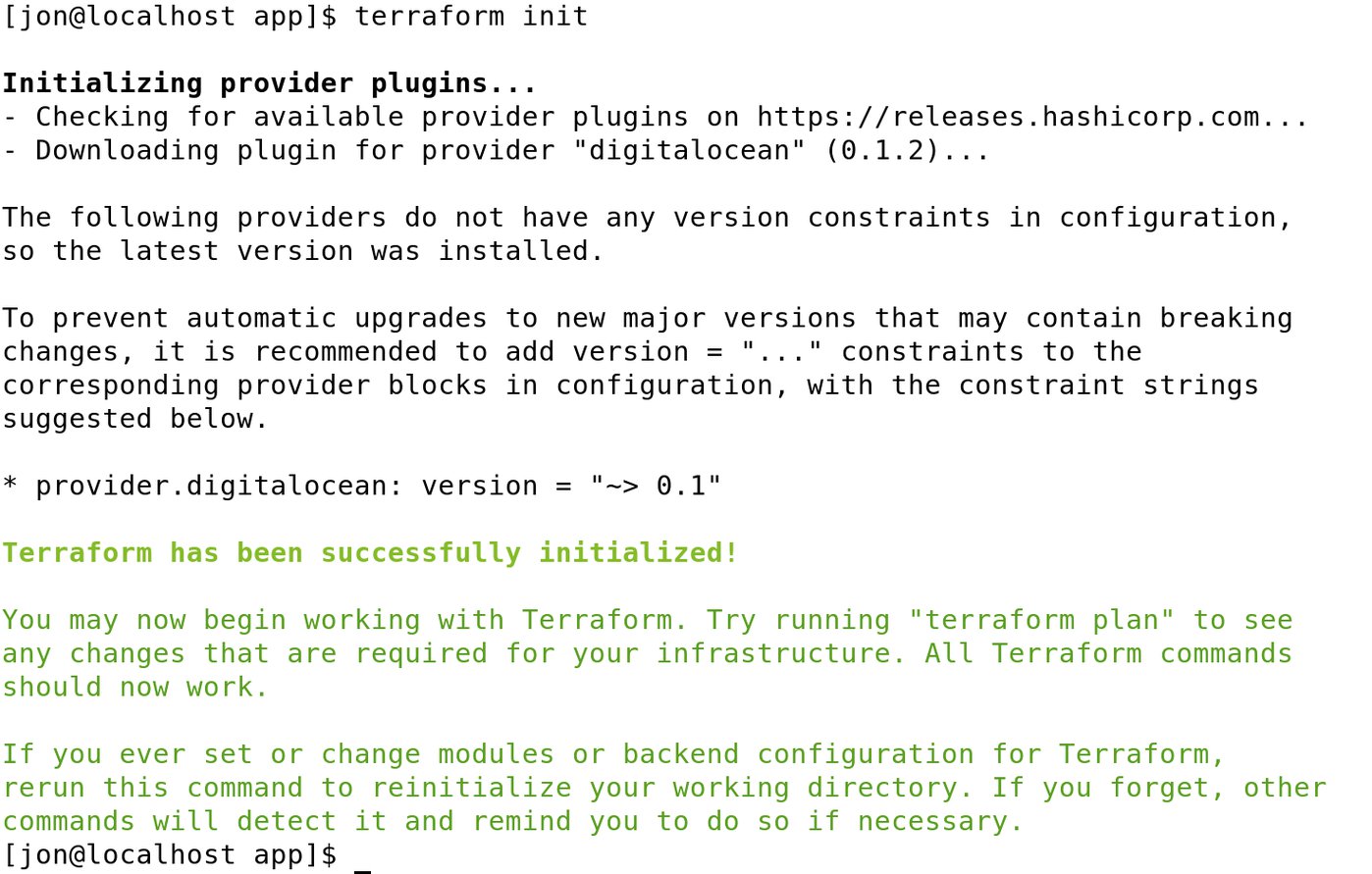
Abbildung 1: Vor dem Erstellen der Cloudflare-Konfiguration startet der Admin einen Init-Prozess.
Anschließend prüft »terraform plan -out digitalocean-plan«, wie weit die in den bisherigen Konfigurationen beschriebene Infrastruktur bereits provisioniert wurde (Listing 4). Da bislang noch keinerlei Infrastruktur existiert, erzeugt Terraform alle konfigurierten Ressourcen.
Listing 4
Infrastruktur testen
01 $ terraform plan -out digitalocean-plan 02 Refreshing Terraform state in-memory prior to plan... 03 [...] 04 An execution plan has been generated and is shown below. 05 Resource actions are indicated with the following symbols: 06 + create 07 Terraform will perform the following actions: 08 + digitalocean_droplet.mywebapp 09 id: <computed> 10 image: "docker-16-04" 11 [...] 12 + digitalocean_ssh_key.jondoe 13 id: <computed> 14 name: "Key von Jon" 15 [...] 16 Plan: 2 to add, 0 to change, 0 to destroy.
Der Parameter »-out« generiert dabei eine Art Plan, der garantiert, dass Terraform genau das tut, was die Ausgabe gerade anzeigt. Das ist vor allem in Produktivumgebungen wichtig, da sich zwischen der Eingabe des Kommandos »terraform plan« und der eigentlichen Ausführung an der Infrastruktur oder der Konfiguration etwas ändern kann. So stellt Terraform etwa sicher, dass ein Admin einen bestimmten Plan im Rahmen eines Change-Prozesses genehmigt und die Software wirklich nur die dort hinterlegten Änderungen ausführt.
Ein einfaches »terraform apply digitalocean-plan« (Abbildung 2, Auszug) lässt Terraform dann die im Plan »digitalocean-plan« festgehaltene Konfiguration ausführen. Der Schritt erzeugt die oben beschriebenen Komponenten beziehungsweise führt sie aus. In der letzten Zeile erscheint die vorhin konfigurierte IP-Adresse des Droplets (nicht im Bild). Sie dient dazu, im Browser zu überprüfen, ob die Außenwelt den Webserver im Container erreicht.
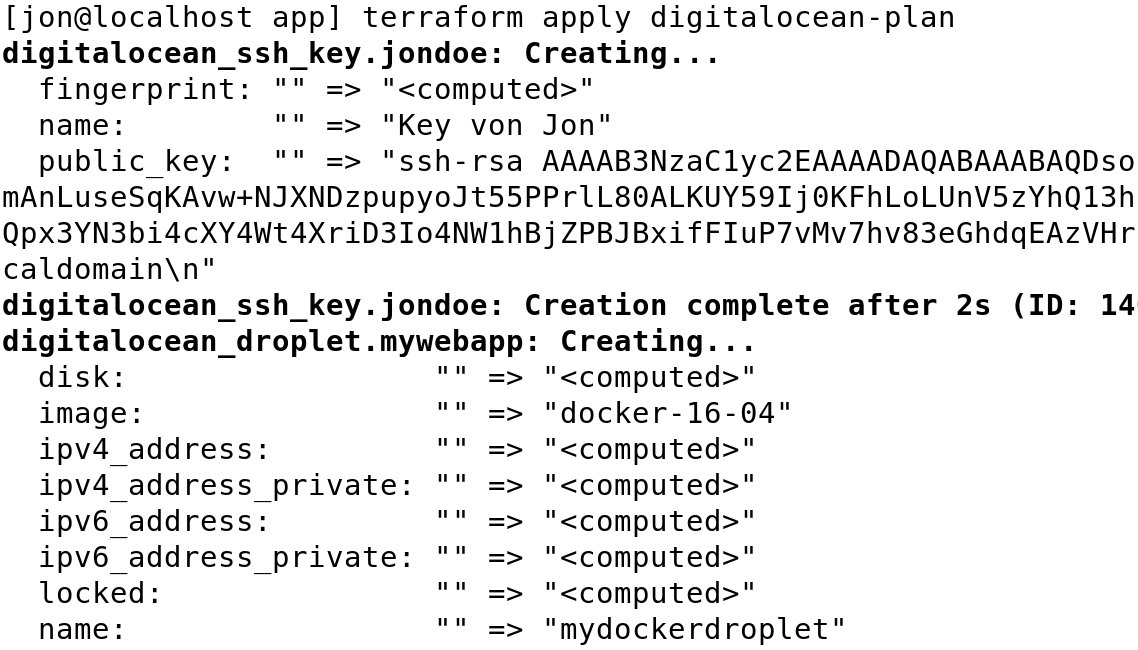
Abbildung 2: Terraform führt die zuvor konfigurierten Arbeitsschritte streng nach Plan aus (Auszug).
Ist das Docker-Droplet erzeugt, legt Terraform bei Cloudflare gleich auch eine neue Subdomain für die Webapplikation an und versieht diese mit der IP des Droplets. Hierfür benötigt Terraform aber zuerst die Datei »cloudflare.tf« (Listing 5), die den Cloudflare-Provider lädt. Anschließend lässt sich die Ressource »cloudflare_record« verwenden (Zeile 6), die dann die eigentliche Anpassung am DNS-Server bei Cloudflare vornimmt. Auch hier will Terraform auf eine Variable zugreifen, die erst existiert, nachdem die Software das Droplet bei Digital Ocean generiert hat.
Listing 5
cloudflare.tf
01 provider "cloudflare" {
02 email = "${var.cloudflare_email}"
03 token = "${var.cloudflare_token}"
04 }
05
06 resource "cloudflare_record" "mywebapp" {
07 domain = "${var.cloudflare_domain}"
08 name = "terraform"
09 value = "${digitalocean_droplet.mywebapp.ipv4_address}"
10 type = "A"
11 ttl = 120
12 proxied = true
13 provisioner "local-exec" {
14 command = "firefox ${cloudflare_record.mywebapp.hostname}"
15 }
16 }
17
18 output "Website:" {
19 value = "${cloudflare_record.mywebapp.hostname}"
20 }
Um einen DNS-Eintrag zu tätigen, braucht Terraform die öffentliche IP-Adresse, die im Attribut »digitalocean_droplet.mywebapp.ipv4_address« des Droplets steckt. Ist der »cloudflare_record« angelegt, startet Firefox über den »local-exec«-Provisioner und lädt eine Seite mit der konfigurierten URL.
Dank dieser Konfiguration sollte Terraform neben der IP-Adresse auch den Domainnamen der Webseite anzeigen, über den Anwender den Container erreichen. Ihn stellt der Wert in »cloudflare_record.mywebapp.hostname« bereit.
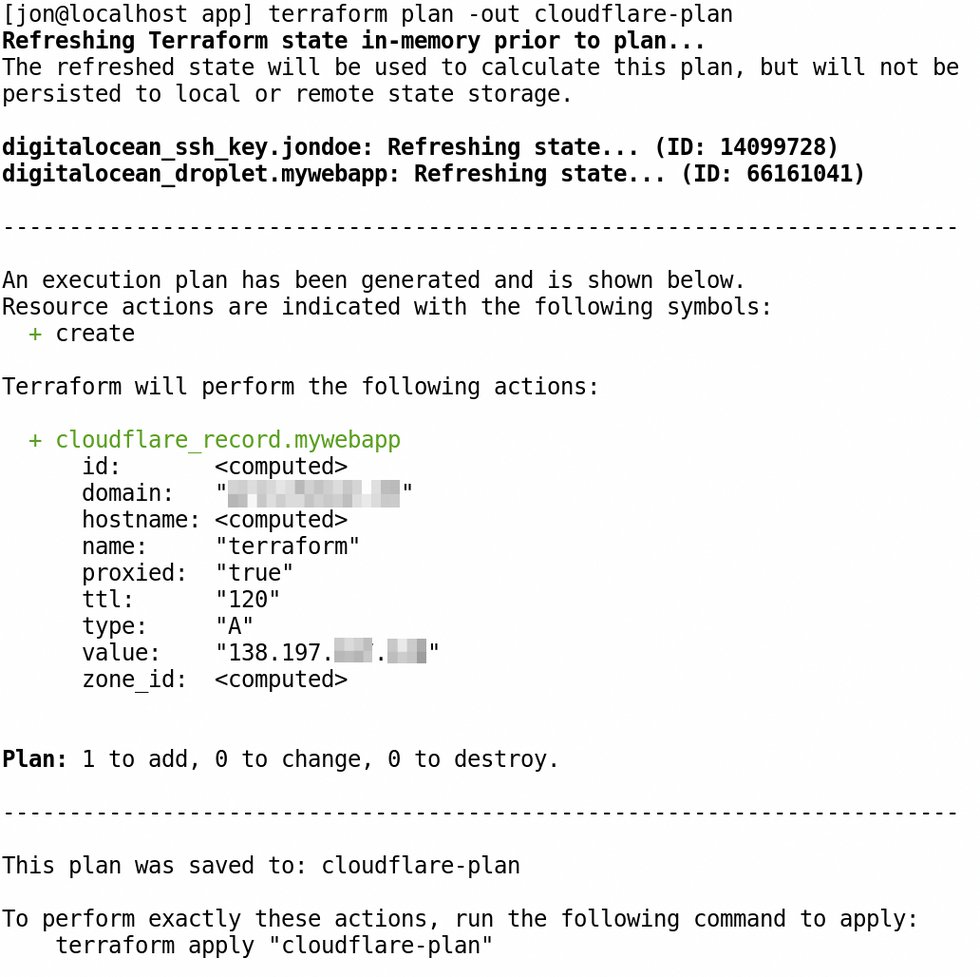
Abbildung 3: Terraform führt testweise den »cloudflare-plan« aus und gibt Rückmeldung darüber.
Zuerst sorgt der Admin wieder mittels »terraform init« dafür, dass Terraform alle Abhängigkeiten für den neu verwendeten Provider »cloudflare« (Listing 5, Zeile 1) vorfindet. Um mit dem Deployment fortzufahren, erzeugt »terraform plan -out cloudflare-plan« einen neuen Plan, der beschreibt, was Terraform tun würde (Abbildung 3). Wie sich zeigt, würde es hier lediglich die Cloudflare-Ressource bereitstellen. Die anderen Ressourcen ändert der Aufruf nicht, da sie bereits provisioniert wurden.
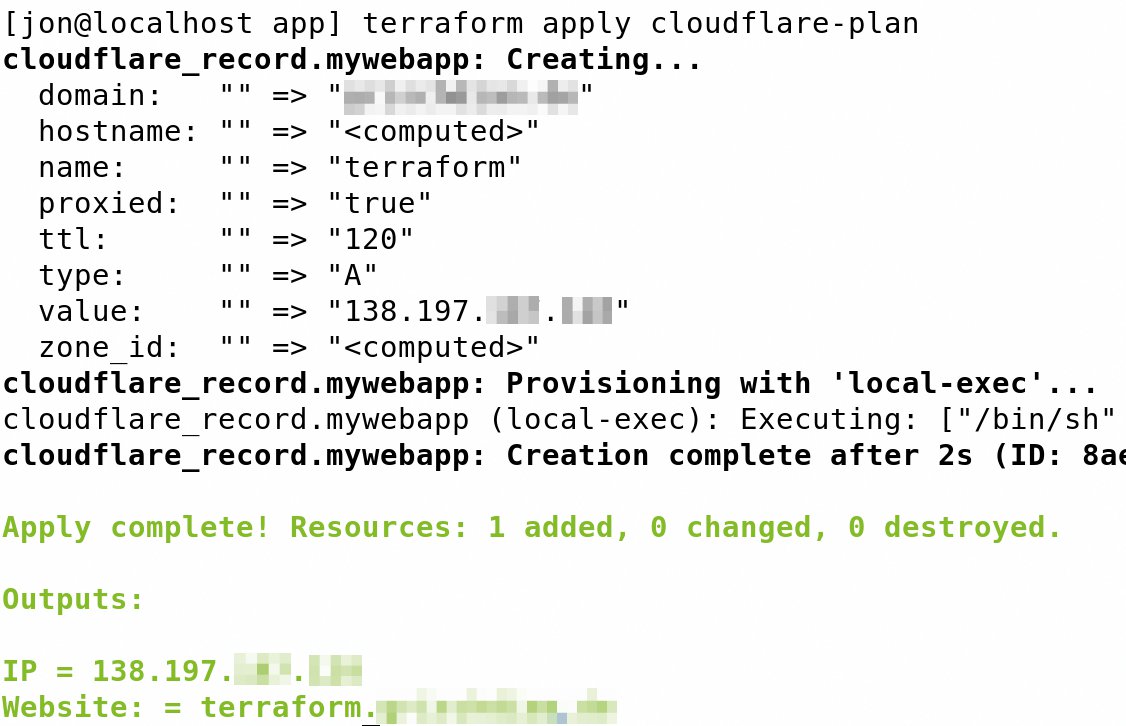
Abbildung 4: Neben der IP-Adresse erscheint auch der Domainname der neu angebotenen Webseite.
Der Befehl »terraform apply cloudflare-plan« (Abbildung 4) passt die Infrastruktur an beziehungsweise erweitert sie um die Cloudflare-Komponente. Im Anschluss erreicht der Admin die Website unter der nun konfigurierten Adresse, die auch in der Ausgabe des Befehls steht. Ein Blick im Browser auf die in »terraform.tfvars« spezifizierte URL genügt, um zu testen, ob die bekannte Website existiert.
Applikation zurückbauen
Um nicht jede einzelne Komponente wieder von Hand zu löschen, kann der Admin die provisionierte Infrastruktur mittels »terraform destroy« entfernen. Hier geht jedoch nichts ohne eine explizite Bestätigung mit »yes« im Dialog. Das ist auch gut so, schließlich soll die Infrastruktur nicht unüberlegt und aus Versehen verschwinden.
Fazit
Das Beispiel zeigt, wie es Terraform gelingt, Infrastruktur bereitzustellen und dynamisch zu erweitern. Geplante Änderungen zeigt das »plan«-Subkommando vorab an, was eine Review ermöglicht. Sollte der Admin zudem einmal einen DNS-Eintrag, etwa den von Cloudflare, löschen, erkennt Terraform diese Änderung und korrigiert sie über »apply«. Andere Ressourcen beeinflusst diese Bestätigung nicht. Weil viele Provider bereits existieren, gelingt der Einstieg in die Welt von Infrastructure as Code mit Terraform recht einfach.
Infos
- Terraform: https://www.terraform.io
- Provider: https://www.terraform.io/docs/providers/index.html
- Digital Ocean: https://digitalocean.com
- Download: https://www.terraform.io/downloads.html
- Digital-Ocean-API: https://www.digitalocean.com/community/tutorials/how-to-use-the-digitalocean-api-v2
- Cloudflare-API-Key einbinden: https://support.cloudflare.com/hc/en-us/articles/200167836-Where-do-I-find-my-Cloudflare-API-key-
- »ssh_key«: https://www.terraform.io/docs/providers/do/r/ssh_key.html
- Abhängigkeiten auflösen: https://www.terraform.io/intro/getting-started/dependencies.html





