
© ridoa, 123RF
Datensicherungen sind bei vielen Anwendern und auch manchen Administratoren unbeliebt und gelten als lästige Pflicht. Die Bitparade hat sich daher einige Backupprogramme für die Kommandozeile angesehen, die ohne jedes Zutun automatische Sicherungen durchführen.
Für Linux gibt es zahllose Backuptools. Gern per SSH arbeitende Admins wissen zu schätzen, dass sich selbst Server jeder Größe und Beschaffenheit auch mit Kommandozeilen-Programmen sichern lassen. Doch die Funktionsunterschiede sind beträchtlich. Nicht jedes Programm eignet sich für jedes Anwendungsszenario. Die Bitparade hat sich angesehen, welche Tools sich in welchen Umgebungen wohlfühlen.
Server versus Desktop
Heimanwender speichern inzwischen auf ihren Computern häufig größere Datenbestände, als sie auf Servern in kleinen Unternehmen oder Abteilungen zu finden sind. Vor allem hochauflösende Videosammlungen, aber auch verlustfrei gespeicherte Audiodateien und Ordner mit Fotodateien sind wahre Speicherfresser. Häufig kommen dort neue Daten hinzu, wogegen sich die einmal gespeicherten kaum noch ändern.
Auf Serversystemen dagegen finden sich oft kleine Dateien wie Korrespondenzen, Tabellen oder auch Präsentationen und Datenbanken. Diese Datenbestände ändern sich permanent durch Modifikationen, etwa neu angelegte Datensätze oder hinzugefügte Schriftstücke. Dementsprechend müssen Backupstrategien den vorhandenen Datenbeständen und ihrer Entwicklung Rechnung tragen, um im Falle eines Datenverlusts eine schnelle Rekonstruktion gewährleisten zu können.
Differenziell versus inkrementell
Grundsätzlich unterscheidet der Administrator zwischen drei Backupstrategien: der Vollsicherung, dem differenziellen und dem inkrementellen Backup. Die Vollsicherung steht stets als erster Sicherungslauf bei der Anlage einer Datenkopie auf der Agenda – später kommen Folgesicherungen als differenzielles oder inkrementelles Backup hinzu. Während das differenzielle Backup dabei immer Veränderungen zur Vollsicherung speichert, sichert das inkrementelle Backup nur Modifikationen im Verhältnis zum letzten Sicherungslauf.
Das differenzielle Sicherungsverfahren benötigt stets mehr Speicherplatz für die einzelnen Backups, kann allerdings im Ernstfall nur mit der Vollsicherung und dem letzten Backup den gesamten Datenbestand wiederherstellen. Bei der inkrementellen Methode wird zwar weniger Speicherplatz verbraucht, dafür sind bei einer Rekonstruktion alle inkrementellen Backups bis zur Vollsicherung in der korrekten Reihenfolge wieder einzuspielen. Fehlt hier auch nur eine noch so kleine Sicherung, ist der Datenbestand nicht mehr rekonstruierbar.
Es empfiehlt sich für den Admin, vor der Auswahl einer Backupsoftware zunächst eine genaue Datenbestands- und Datenentwicklungs-Analyse anzustellen, um nicht versehentlich ein Programm auszuwählen, das sich für seine konkrete IT-Umgebung nicht eignet.
Differenzielle Sicherungsstrategien kommen eher in Bereichen zum Zuge, in denen Datenbestände mit relativ wenigen großen Dateien und moderaten regelmäßigen Modifikationen vorherrschen, während sich die inkrementellen Sicherungen besser für die typischen Office-Umgebungen eignen. Dabei sollte der Admin jedoch stets darauf achten, dass er mindestens wöchentlich eine neue Vollsicherung anstößt.
Desktopanwender, die ihre eigenen Datenbestände ohne Rootrechte sichern wollen, sind mit Sicherungssoftware für die Kommandozeile, die Kenntnisse der Befehlssyntax voraussetzt, schlechter bedient. Für sie kommt es darauf an, möglichst reibungslos und zuverlässig ein Backup laufen lassen zu können. Nur wenn die Software einfach und schnell zu bedienen ist, wird sie der Endanwendern akzeptieren und das Backup wirklich durchführen.
In einer gemischten Umgebung mit einem Backupserver und zusätzlicher Sicherung der Desktops durch Anwender, verwendet man idealerweise in beiden Fällen dasselbe Programm. Der Administrator erspart sich in diesem Fall die Arbeit, die Syntax von zwei Programmen kennen zu müssen – und vermeidet damit einhergehende mögliche Fehlerquellen.
Attic
Das in Python geschriebene Backup-programm Attic befindet sich bei einigen Linux-Distributionen wie Mageia, Open Suse, Rosa oder Slackware-Linux bereits in den Repositories und lässt sich dort bequem mit Hilfe der jeweiligen Paketverwaltung installieren. Die Projektseite bietet darüber hinaus den Quellcode zum Download an. Eine ausführliche Dokumentation steht auch bereit [1].
Attic benötigt als zwingende Voraussetzungen Python in Version 3.2 oder darüber und Open SSL in einer Variante höher als 1.0.0. Da die Software außerdem das Mounten eines Backupsets im Userspace ermöglicht, ist zu dieser Funktion das Paket »llfuse« aus dem Python-Fundus zu installieren.
Nach erfolgreicher Installation muss der Anwender zunächst ein Repository initialisieren. Das gelingt mit dem Befehl:
attic init /Repository-Pfad/Repository-Name.attic
Anschließend lassen sich mehrere Verzeichnisse in einem eigens anzulegenden Archiv in diesem Repository sichern. Attic schaltet dabei per Default keine Verschlüsselung ein. Die Namen für die anzulegenden Archive sind frei wählbar. Die Verzeichnisse sichert der Befehl:
attic create /Repository-Pfad/Repository-Name.attic::Archivname/Quellverzeichnis 1[...] /Quellverzeichnis n
Sind die Daten verschlüsselt zu speichern, so ist dem Befehl der Parameter »–encryption=Passphrase | Schlüssel« hinzuzufügen.
Es empfiehlt sich, bei regelmäßigen Sicherungen der gleichen Verzeichnisse als Archivname Wochentage zu benutzen. So ergibt sich bei einer Wiederherstellung sehr schnell die korrekte Reihenfolge der Backups. Während die erste Sicherung in einem Repository bei größeren Datenmengen längere Zeit beanspruchen kann, sind Folgesicherungen wesentlich schneller abgeschlossen, da Attic sie inkrementell sichert, also stets nur modifizierte oder neu hinzugekommene Daten in das Backup integriert.
Möchte der Administrator den Sicherungslauf überwachen, so lässt er sich mit dem Parameter »–stats« die wichtigsten Daten zum gesicherten Archiv anzeigen. Attic listet hier nicht nur die Verzeichnisse und den benötigten Zeitaufwand für den Sicherungslauf, sondern auch die Anzahl der gesicherten Dateien und die Datenmenge. Dabei zeigt es sowohl das ursprüngliche als auch das nach Komprimierung gesicherte Datenvolumen an, sodass der Admin verfolgen kann, wie effizient die Datenkomprimierung ist (Abbildung 1).
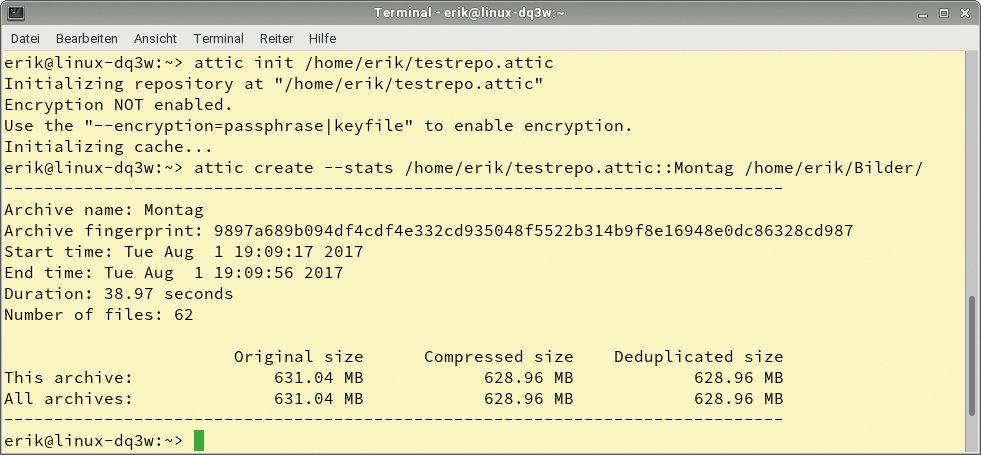
Abbildung 1: Attic liefert klare Daten zum letzten Backup.
Attic bietet im Gegensatz zu vielen anderen Backuptools eine komfortable Möglichkeit, den Inhalt von Archiven aufzulisten. Dazu gibt der Administrator am Prompt den Befehl
attic list -v /Repository-Pfad/Repository-Name.attic::Archivname
ein. Die Software listet daraufhin alle Inhalte inklusive der Dateigrößen, Eigentümer und Dateirechte auf. Unterverzeichnisse sind dabei automatisch mit eingeschlossen. Außerdem zeigt sie die absoluten Pfade an.
Archiv verifizieren
Auf die gleiche einfache Art und Weise kann der Admin bei Attic die Datenintegrität überprüfen. Der Befehl
attic check /Repository-Pfad/Repository-Name.attic
prüft das aufgeführte Repository und sämtliche darin befindlichen Archive. In einer Kurzmeldung wird sodann der Zustand ausgegeben (Abbildung 2). Tauchen hierbei Inkonsistenzen auf, so kann der Administrator durch Wiederholung des Befehls mit dem zusätzlich hinzugefügten Parameter »–repair« eine Reparatur vornehmen.
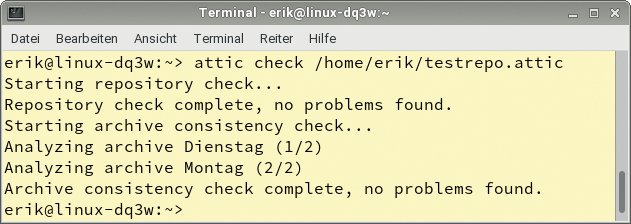
Abbildung 2: Auf einen Blick ist zu sehen, ob alle Daten korrekt gespeichert sind.
Das Restore
Um ein Archiv zu restaurieren, verwendet der Administrator die Option »extract«. Er gibt den Befehl
attic extract /Repository-Pfad/Repository-Name.attic::Archivname
ein und startet damit die Wiederherstellung des gesamten Archivinhalts im ursprünglichen Speicherpfad. Die Software listet dabei die einzelnen Dateien auf. Durch eine zusätzliche Pfadangabe ist der Zielpfad änderbar. Außerdem kann der Anwender Teile des Archivs von der Restauration ausnehmen.
Attic kann selbstverständlich auch Backups auf einem entfernten Server ablegen und von diesem zur Wiederherstellung beziehen. Dabei erwartet es die gleiche Syntax wie bei der lokalen Sicherung, wobei der Server mit »Nutzername@Servername:Repository-Name.attic« angesprochen wird.
Es empfiehlt sich allerdings, bei der Anlage von Repositories auf Serversystemen die Verschlüsselung einzuschalten. Attic nutzt zur Verschlüsselung 256-Bit-AES und zur Verifikation HMAC-SHA256. Attic verschlüsselt die Daten vor der Ablage im Archiv.
Automatisiert
Die Software beherrscht von Cronjobs gesteuerte, automatisierte Backupläufe. Um dabei die Anzahl der vorhandenen Repositories auf längere Sicht nicht ausufern zu lassen, bietet Attic mit dem Parameter »prune« eine Möglichkeit, die Speicherdauer älterer Repositories festzulegen. Die Option bestimmt eine maximale Anzahl an Archiven, die im Repository zu erhalten sind. Dabei definiert der Administrator, ob es sich um stündlich, täglich, wöchentlich oder monatlich angelegte Archive handelt. Die müssen allerdings zuvor mit dem »date«-Parameter erzeugt worden sein.
Bup
Das bereits seit sieben Jahren entwickelte und gepflegte Programm Bup (abgeleitet von “Backup”, [2]) hat sich in kleinen IT-Umgebungen wegen seiner Geschwindigkeit und Effizienz etabliert. Die Software steht bei vielen größeren Linux-Distributionen in den jeweiligen Repositories zur direkten Installation bereit.
Bup unterscheidet sich von anderen Backuptools bereits dadurch, dass es das Git-Packfile-Format verwendet anstelle herkömmlicher Tar- oder Zip-Archive. Auch in der Handhabung ist die Software sehr flexibel: So lassen sich Bup-Archive beispielsweise als eigenes Dateisystem im Userspace mounten. Auch das Backup ganzer ISO-Abbilder, die oftmals mehrere GByte umfassen, stellt für die Software kein Problem dar. Das Git-Packfile-Format setzt allerdings auch die Einrichtung eines Repository voraus.
Um einen ersten Überblick über die zahlreichen Befehlsparameter der Software zu erhalten, ruft der Anwender das Programm am Prompt ohne jegliche Option auf. Bup listet sodann die wichtigsten Parameter in Kurzform auf. Eine ausführliche Dokumentation findet sich auf der Projektseite [3]. Für lokale Backups auf dem Desktop verfügt das Programm zusätzlich über GTK-3- und Qt-basierte grafische Frontends, die auch für Ungeübte das Backup erleichtern. Diese sind über verlinkte Seiten von der Homepage des Bup-Projekts aus erhältlich.
Verwendung
Um ein Backup anzulegen, muss der Administrator zunächst das Backupverzeichnis initialisieren mit der Befehlssequenz:
BUP_DIR=/Backup-Setbup init
Danach indexiert er das zu sichernde Verzeichnis mit dem Befehl:
bup index -ux /Verzeichnis
Ist keine entsprechende Verzeichnisvariable definiert, ist zusätzlich der Parameter »-d« mit dem Pfad für das Backupset anzugeben. Ansonsten sichert Bup das Backupset im versteckten Unterordner ».bup« im Homeverzeichnis des Anwenders. Nach der Indexierung führt der Admin das eigentliche Backup mit
bup save -n Set-Bezeichnung /Originalverzeichnis
durch. Hier ist im Falle einer fehlenden Verzeichnisvariablen ebenfalls der Pfad zum Backupset mit vorangestelltem Parameter »-d« anzugeben. Die Set-Bezeichnung ist ein wahlfrei zu definierender Name und dient dazu, im Falle mehrerer Backups auf dem gleichen Zielmedium für die Wiederherstellung das korrekte Set zu identifizieren.
Beim ersten Backuplauf führt Bup eine Vollsicherung durch, was je nach Größe der originalen Daten einige Zeit beanspruchen kann. Die Folgeläufe fertigen nur noch inkrementelle Backups an, was wesentlich schneller geht.
Zu beachten ist, dass der Admin nach jeder Änderung der originalen Inhalte vor einem zusätzlichen Backuplauf erneut indexieren muss, damit die Software die Änderungen erfasst.
Soll das Backup auf einem entfernten Server landen, so gibt der Admin im einfachsten Fall die folgende Befehlssequenz ein:
bup save -r Username@Server-IP Verzeichnisname -n Setname /Originalverzeichnis
Auch in diesem Fall wird beim ersten Durchlauf eine Vollsicherung durchgeführt, während die anschließenden Backups inkrementelle Sicherungen sind. (Abbildung 3).
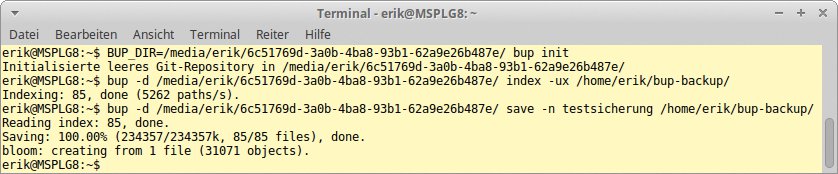
Abbildung 3: Auch mit Bup werden Daten in wenigen Schritten gesichert.
Bup beherrscht zudem das Backup einer entfernten Maschine auf eine lokale. Hierzu wird der Befehl »bup on« eingegeben, gefolgt von der Serveradresse und dem Zielverzeichnis auf dem lokalen System. Auch dabei ist zuvor ein Indexierungslauf durchzuführen.
Um vorhandene Backupsets zu überprüfen, kann der Anwender mit Hilfe des Befehls »bup ls« die einzelnen Dateien auflisten lassen. Spalten stellen diese übersichtlich dar (Abbildung 4).
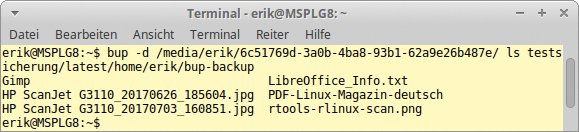
Abbildung 4: Eine einfache Anzeige der gesicherten Daten erleichtert dem Administrator die Prüfung.
Rückwärtsgang
Die Wiederherstellung von Backups nimmt der Anwender genauso einfach vor: Hierzu wird nach Angabe des Pfads zum Backupset der Parameter »restore« anstelle von »save« verwendet, gefolgt von der Set-Bezeichnung und deren Pfadangabe. Dabei besteht zusätzlich die Möglichkeit, einzelne Unterverzeichnisse aus dem Set wiederherzustellen.
Extras
Bup bringt einige kleine Extras mit, um beispielsweise die Integrität von Backupsets zu prüfen. Eines der im Praxiseinsatz wohl wichtigsten Schmankerl dürfte die Option sein, ein Backup wie ein herkömmliches Laufwerk im Userspace einzubinden. Dazu ist das Paket »python-fuse« zu installieren und ein Mountverzeichnis anzulegen. Anschließend wird das Set mit dem Befehl
bup -d Pfad_zum_Backupset fuse Zielverzeichnis
in das bestehende System eingebunden. Der Administrator kann anschließend mit dem Zielverzeichnis und seinen Inhalten wie mit einem herkömmlichen Laufwerk verfahren.
Duplicity
Das für nahezu alle gängigen Linux-Distributionen als Binärpaket erhältliche Duplicity [4] zeigt sich bei den möglichen Speicherorten sehr flexibel. So kann der Administrator Backups nicht nur lokal abspeichern, sondern auch auf FTP- oder SSH-Servern im Intranet. Zusätzlich unterstützt Duplicity Windows-Freigaben und Webdav-Speicher.
Sind solche zentralen Speichermöglichkeiten nicht verfügbar, kann Duplicity die Backups auch in der Cloud ablegen. Dafür unterstützt es Amazons S3-Cloud und Cloudlösungen des US-Hosters Rackspace. Eines der Alleinstellungsmerkmale von Duplicity ist dabei die Verschlüsselung: Alle Dateien lassen sich per Gnu PG verschlüsseln und sicher in einer Cloud ablegen, ohne dass neugierige Zeitgenossen Einsicht nehmen können.
Die Software geht beim Anlegen der Backups professionell vor: Beim ersten Durchlauf führt sie eine Vollsicherung, durch, die sie in ein Tar-Archiv packt. Anschließend kommt das Programm mit inkrementellen Backups aus, was nicht nur Speicherplatz, sondern vor allem bei größeren Datenbeständen auch viel Zeit spart. Durch Signaturen wird dabei die Datenintegrität auch in unsicheren Umgebungen gewährleistet.
Duplicity benötigt aufgrund der sehr komplizierten Parametrierung [5] jedoch viel Einarbeitung; alternativ empfehlen sich besonders für kleinere Umgebungen oder Desktop-Backups grafische Frontends wie Déjà Dup [6], die den Funktionsumfang von Duplicity zwar bei Weitem nicht vollständig abbilden, jedoch sehr schnell nutzbar sind. Die Software kann zudem keine differenziellen Sicherungsläufe durchführen.
Duplicity eignet sich für das Sichern von einzelnen Ordnern, aber nicht für das Anlegen von kompletten Systemabbildern. (Hierzu sind Programme wie Clonezilla [7] besser geeignet.) Dabei speichert das Programm die gesicherten Daten in so genannten Volumes. Bei lokalen Backups muss der Anwender zudem die absoluten Pfade angeben, um die Daten in die korrekten Zielordner zu speichern.
Schlüsseldienst
Damit Duplicity seine Stärke – die Verschlüsselung der Backups – ausspielen kann, muss der Anwender zunächst einen GPG-Key generieren oder bereits im Besitz eines solchen sein. Die Eingabe von »gpg –gen-key« am Prompt erzeugt einen neuen Schlüssel in nur wenigen Schritten, wobei der Administrator auch die Schlüsselstärke definieren kann (Abbildung 5).
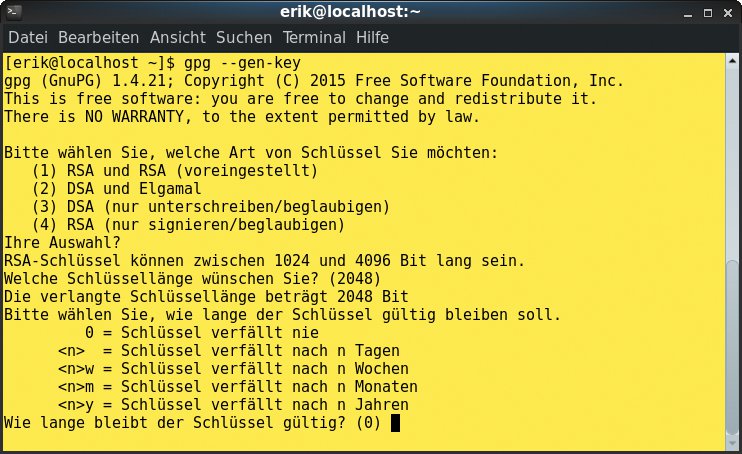
Abbildung 5: Ein Schlüssel lässt sich innerhalb weniger Minuten kreieren.
Die Passphrase, die der Anwender beim Generieren eines Schlüssels angibt, dient ebenfalls erhöhter Sicherheit: Kommt der Schlüssel abhanden, so können Dritte nicht einfach die Archive entschlüsseln, da die Passphrase bei der Restauration der Datenbestände abgefragt wird. Besonders paranoide Naturen können ihre Archive auch noch mit einer digitalen Signatur versehen, sodass sich die Datenintegrität der Backup-Volumes später ebenfalls jederzeit prüfen lässt.
Im einfachsten Fall gibt der Anwender für eine lokale Sicherung den Befehl
duplicity /Quellverzeichnis file://Zielverzeichnis
an. Nach zweimaliger Abfrage der Passphrase legt die Software das Backup im Zielverzeichnis an.
Um auf einem FTP-Server Daten zu sichern, ruft der Anwender die Software mit folgender Befehlszeile auf:
duplicity /Quellverzeichnis ftp://backupuser@Host.Name/Zielverzeichnis
Auch hier wird vor der Ablage die Passphrase abgefragt, wobei der Administrator dieses Procedere umgehen kann, indem er dem Backupbefehl die Sequenz »FTP_PASSWORD=Passwort« voranstellt. In beiden Fällen prüft Duplicity automatisch, ob dort bereits eine Vollsicherung vorhanden ist. Ist das nicht der Fall, legt es sie beim ersten Durchlauf automatisch an. Ab dem zweiten Durchlauf macht es ein inkrementelles Backup (Abbildung 6).
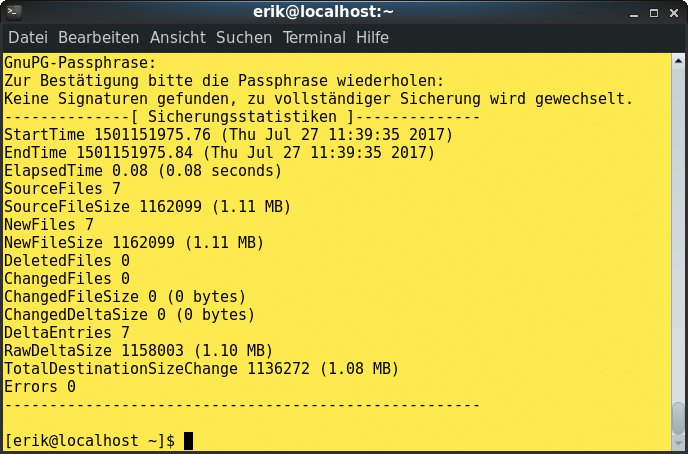
Abbildung 6: Duplicity liefert ebenfalls einige Infos zum Backup.
Manuell anstoßen
Da vor allem bei automatischen Backupläufen mit der Zeit immer mehr inkrementelle Sicherungen entstehen, die bei einer Datenrekonstruktion alle nacheinander bis zur letzten Vollsicherung wiederherzustellen sind, empfiehlt es sich, regelmäßig eine neue Vollsicherung auszuführen. Das hält die Zahl der inkrementell gesicherten Archive klein. Eine manuelle Vollsicherung lässt Duplicity dabei anlaufen, wenn es mit dem Parameter »full« startet. Der Parameter »incremental« bewirkt eine manuell gestartete inkrementelle Sicherung.
Sind bestimmte Verzeichnisse vom Backup auszunehmen, so gibt der Administrator diese mit dem Parameter »–exclude« an. Dabei lassen sich auch mehrere nicht zu sichernde Verzeichnisse aufzählen, wobei diese jeweils durch einen Leerschritt voneinander zu trennen sind. Der Ausschluss von einzelnen Verzeichnissen erscheint vor allem bei solchen Unterordnern sinnvoll, die beispielsweise temporäre, Cache- oder Log-Dateien enthalten.
Besondere Vorsicht ist jedoch geboten bei einem Backup des Root-Verzeichnisses: Hierbei ist das Verzeichnis »/proc« auszuschließen, da Duplicity ansonsten einfriert. Umgekehrt kann der Parameter »–include« auch zusätzliche Verzeichnisse in das Backup einschließen.
Wiederherstellung
Die Datenrekonstruktion ist genauso einfach möglich: Duplicity wird ohne weitere Parameter aktiviert, wobei lediglich Quell- und Zielpfad auszutauschen sind. Alternativ kann der Admin dabei selbstverständlich auch einen anderen Zielpfad angeben. Anschließend wird das Archiv erst nach Eingabe der Passphrase entpackt, sodass Unbefugte ohne Kenntnis des Passworts keinen Zugriff auf die Daten erhalten können.
Mit Hilfe der Parameter »verify« und »–compare-data« prüfen Administratoren auf einfache Weise die Integrität ihrer Backups. Diese Prüfung ist auch dann möglich, wenn die Volumes in einer Cloud liegen. Besonders zu Dokumentationszwecken empfiehlt es sich, den zusätzlichen Parameter »-vx« zu verwenden, wobei der Platzhalter x durch eine der Ziffern 4, 8 oder 9 zu ersetzen ist, um aussagekräftige Informationen zu erhalten. Diese Daten lassen sich sodann durch den Parameter »–log-file Dateiname« ebenfalls in der angegebenen Datei speichern.
Rdiff-Backup
Ein ebenfalls weitverbreitetes Tool zum Backup auf der Kommandozeile ist Rdiff-Backup [8]. Das Programm ist in die Repositories faktisch aller größeren Linux-Distributionen eingepflegt. Die Software lässt sich denkbar einfach nutzen: Um lokal ein Backup eines Verzeichnisses oder einer Verzeichnishierarchie anzufertigen, gibt der Anwender am Prompt den Befehl
rdiff-backup Quellverzeichnis Zielverzeichnis
ein. Auf diese Weise entsteht eine Vollsicherung, die der Admin so einfach wie in einer herkömmlichen Ordnerhierarchie ohne spezielle Tools, nur mit Bordmitteln von Linux wiederherstellen kann.
Rdiff-Backup legt bei Folgesicherungen Backups an, die gelöschte oder ältere Versionen der geänderten Dateien enthalten. Die neuesten Versionen der geänderten Files landen wie neue Dateien jeweils in der Vollsicherung, sodass diese stets den aktuellen Stand des Backups repräsentiert. Die regelmäßigen Sicherungen speichern lediglich ältere Varianten des Datenbestands. Diese als Reverse-Delta bezeichnete spezielle Form der inkrementellen Sicherung hat den Vorteil, dass der Admin sich zunächst nicht durch mehrere inkrementelle Backups nacheinander kämpfen muss, um einen kompletten Datenbestand wiederherzustellen.
Server
Mit Rdiff-Backup kann der Administrator auch Server im Intranet sichern. Hierbei ist zu beachten, dass die Applikation auch auf dem Server installiert sein muss. Um per SSH eine Sicherung durchzuführen, gibt der Administrator am Prompt des entfernten Clients den Befehl
rdiff-backup Username@Server-IP::Quellverzeichnis Backupverzeichnis
ein. Anschließend wird das Quellverzeichnis von dem Server auf dem lokalen Client gesichert. Soll die Sicherung auch Dateien in das Backup einbeziehen, auf die nur Root Zugriff hat, so muss sich der Admin mit entsprechenden Rechten einloggen.
Anzeigen
Rdiff-Backup verfügt ähnlich wie alle anderen Probanden über eine Sammlung von Parametern, um die Backups zu verwalten. Um sich den Inhalt einer Sicherung anzeigen zu lassen, ist am Prompt »rdiff-backup -l Backupname« einzugeben.
Da die Software während der Sicherungsläufe keine Statusmeldungen ausgibt, empfiehlt es sich, den Parameter »-v6« mit einzugeben, um so den höchsten Verbose-Level einzuschalten. Anschließend gibt die Software alle verarbeiteten Dateien aus. Zusätzlich erscheinen nach dem Start des Backups diverse Statusmeldungen zu aktivierten und ausgeschalteten Parametern (Abbildung 7).
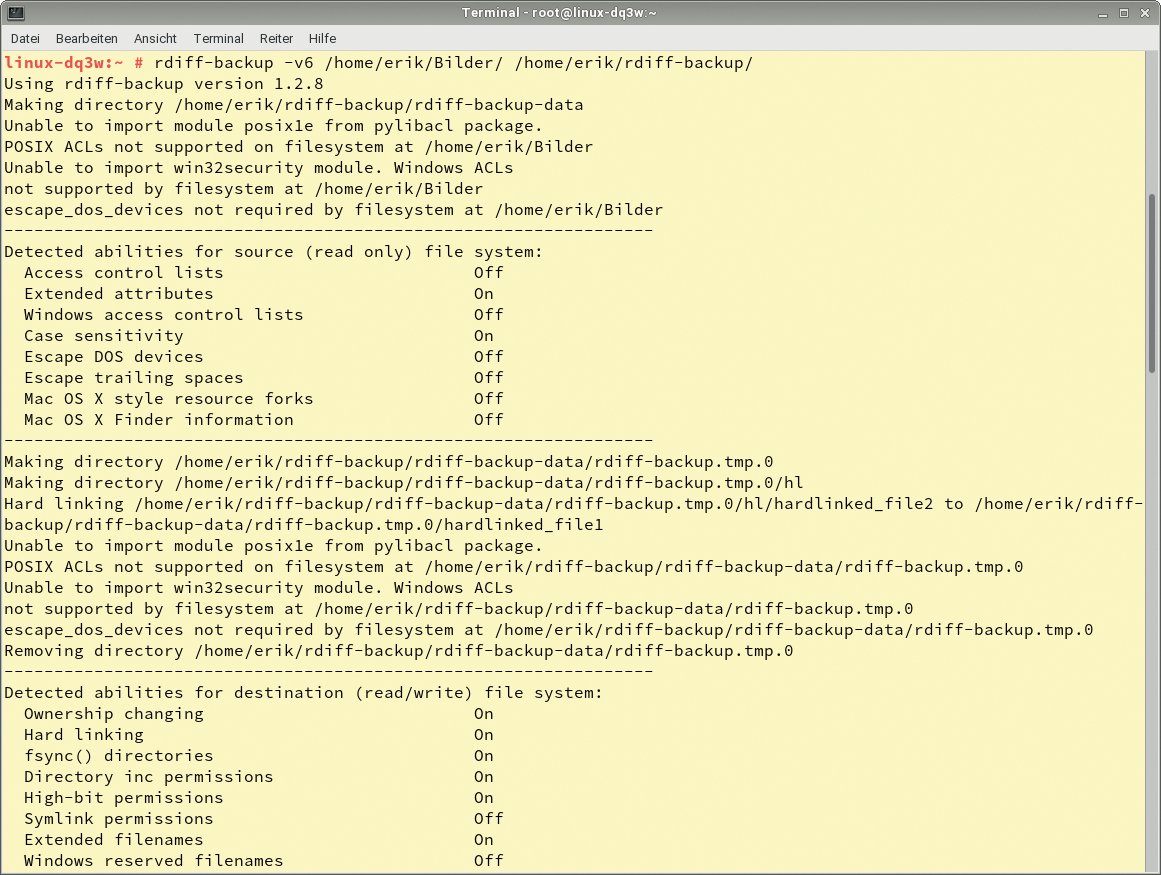
Abbildung 7: Rdiff-Backup gibt wesentlich mehr Informationen preis als andere Backupprogramme – sofern man es dazu veranlasst.
Die Parameter »–compare« und »–list-increments« geben über die veränderten Dateien und die unterschiedlichen Sicherungspunkte Auskunft. Mit dem Befehl »rdiff-backup-statistics Backup-Verzeichnis« kann der Administrator zusätzlich noch Auskunft über die statistischen Daten des Sicherungsverzeichnisses erhalten (Abbildung 8).
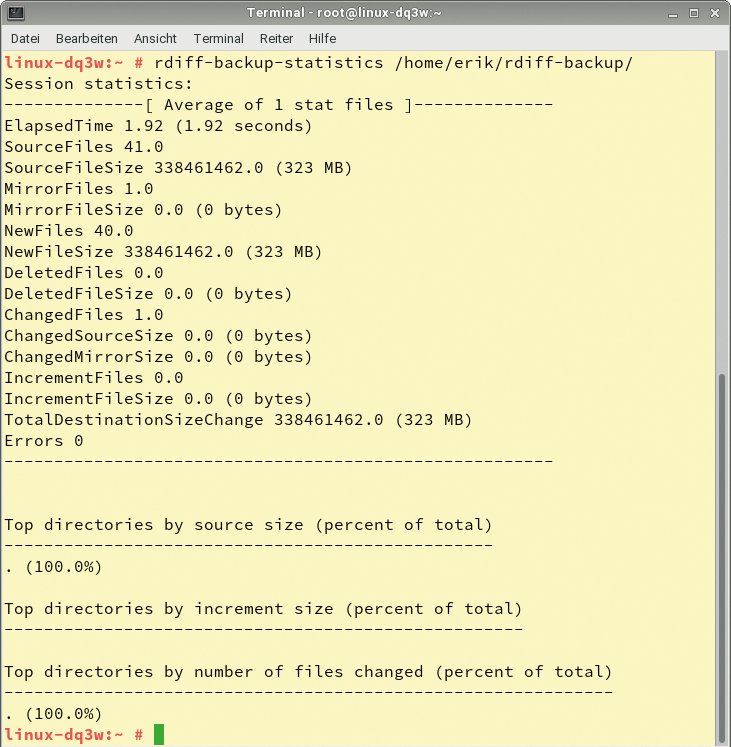
Abbildung 8: Eine der diversen Anzeigen statistischer Daten erleichtert dem Admin die Prüfung der Backups.
Ausnahmen
Wie bei anderen Backupprogrammen auch, kann der Anwender Dateien oder Verzeichnisse vom Backup ausnehmen. Dies kann beispielsweise insbesondere dann von Vorteil sein, wenn sich im Backuppfad Verzeichnisse für temporäre Dateien befinden, die man nicht mitsichern will. In solchen Fällen kommt der Parameter »–exclude« zum Zuge, der einzelne Dateien ausschließt.
Sind komplette Verzeichnisse vom Sicherungslauf auszunehmen, so nutzt der Administrator hierzu den Parameter »–exclude-filelist«, wobei anschließend eine Datei anzugeben ist, welche die Pfade der auszuschließenden Dateien enthält. Diese ist zuvor manuell anzulegen.
Wiederherstellung
Um gesicherte Dateien aus den Archiven wiederherzustellen, ist es nicht nötig, erneut Rdiff-Backup aufzurufen: Gilt es, die Datenbestände aus dem aktuellen Archiv zu rekonstruieren, so kann der Administrator die Daten einfach aus dem Backupverzeichnis herauskopieren. Dazu dient der Linux-Befehl »cp«, den der Admin zusammen mit der Archive-Option verwenden sollte. Die einfachste Form dazu lautet:
cp -a /Backupverzeichnis/Dateiname /Restore-Verzeichnis/Dateiname
Um auf ältere Backupdateien zuzugreifen, bietet die Software zwei Optionen an: Entweder kann der Administrator über das Programm Rdiff-Backup selbst auf die inkrementellen Dateien zugreifen oder er bindet das Backuparchiv mit Hilfe von Rdiff-backup-fs, das als externes Paket gesondert zu installieren ist, wie ein herkömmliches Dateisystem in sein Betriebssystem ein.
Rdiff-Backup-fs [9] ist – teils unter leicht abgewandelter Paketbezeichnung – in einigen Software-Repositories großer Linux-Distributionen eingepflegt, ansonsten jedoch auch von der Webseite des Projekts zu beziehen. Beim direkten Zugriff wird der Parameter »-r« (Kurzform für “restore-as-of”) angewandt, gefolgt von einer Zeitangabe. Um beispielsweise ein zehn Tage altes Backup von einem Server in einem lokalen Verzeichnis auf dem Client zu rekonstruieren, ist folgende Befehlssequenz nötig:
rdiff-backup -r 10D Servername::/Quellverzeichnis /Restore-Verzeichnis
Die ausführliche Dokumentation [10] listet verschiedene Anwendungsszenarien auf, die die teils etwas ungewöhnliche Nomenklatur verständlich machen.
Rsnapshot
Rsnapshot ist – wie der Name bereits andeutet – ein Werkzeug, um komplette Snapshots eines Dateisystems anzulegen [11]. Dabei kann es sowohl lokale als auch – per SSH – Snapshots von entfernten Systemen kreieren. Das auf Rsync aufsetzende Tool legt Backups an, bei denen Hardlinks unveränderte Dateien ersetzen. Nur modifizierte Daten schreibt Rsnapshot tatsächlich in das Backup. Ein Cron-Daemon stößt die Backups regelmäßig an. Manuelle Sicherungsläufe sind nicht vorgesehen. Die Software bezieht alle Informationen komplett aus einer Konfigurationsdatei.
Weil Rsnapshot mit Hardlinks hantiert, müssen die Backups stets auf demselben Dateisystem landen. Andernfalls müsste das Tool wieder eine platzraubende Vollsicherung anlegen. Daher eignet sich Rsnapshot eher für Server in kleinen Intranets oder für lokale Arbeitsplatzrechner als für umfangreiche Storage-Setups. Das in Perl geschriebene Werkzeug speichert jedoch nur eine konfigurierbare Anzahl von Sicherungen, sodass selbst bei kleinen Backup-Intervallen der Speicherplatzbedarf im Rahmen bleibt.
Konfiguration
Das in praktisch allen größeren Linux-Distributionen in die Repositories eingepflegte Programm muss der Administrator nach erfolgreicher Installation zunächst konfigurieren. Dazu ruft er die Datei »/etc/rsnapshot.conf« auf. Diese Datei lässt sich bequem mit jedem gängigen Texteditor bearbeiten.
Da die recht zahlreichen Optionen dank ausführlicher Kommentare leicht zu erschließen sind, stellt die Konfiguration auch Ungeübte nicht vor unüberwindbare Probleme. Zu beachten ist, dass verschiedene Optionen durch Tabulatorschritte voneinander zu trennen sind. Außerdem sind Pfadangaben stets zwingend mit einem Slash abzuschließen.
Die Konfigurationsdatei erlaubt nicht nur die Angabe von Quell- und Zielverzeichnissen und die Aufzählung ein- oder auszuschließender Dateien, sondern enthält auch ein Zeitschema für einen Backupplan. Außerdem sind Einstellungen zur Sicherung eines entfernten Servers per SSH oder der Umgang mit einem LVM-Verbund definierbar. Wichtig sind zudem Einstellungen zur Aufbewahrungsdauer von Snapshots (Abbildung 9).
Abbildung 9: Rsnapshot wird mit einer Konfigurationsdatei vorbereitet.
Da die Konfigurationsdatei recht umfangreich ist, kann der Admin sie nach einer Modifikation validieren. Dazu gibt er mit Administratorrechten am Prompt den Befehl »rsnapshot configtest« ein. Die Ausgabe »Syntax OK« signalisiert eine konsistente Konfiguration. Mit einem Cron- oder Anachron-Job startet die Software dann automatisch. Eine vordefinierte Beispielanpassung findet sich daher auch bereits bei einigen Distributionen in der Datei »/etc/cron.d/rsnapshot«. Deren Daten lassen sich entsprechend den individuellen Bedürfnissen anpassen. Weitere Informationen bietet eine FAQ [12].
Rotationsprinzip hält Daten in Schranken
Dank des Rotationsprinzips kann der Anwender die Anzahl der Backups – seinen Erfordernissen gemäß – übersichtlich halten. Dazu definiert er in der Konfigurationsdatei, in welchen Intervallen Sicherungen anzulegen und wie viele Sicherungen jedes Intervalls vorzuhalten sind. Der Parameter »retain« in der Datei »/etc/rsnapshot.conf« bewerkstelligt durch Zeitangaben wie »daily« oder »hourly« und eine dahinter angegebene Zahl beides.
Beispielsweise bedeutet die Zeile »retain daily 5«, dass täglich ein Backup-Lauf startet und die fünf letzten täglichen Sicherungen aufzuheben sind. In weiteren Zeilen lassen sich auf dieselbe Weise zusätzliche Intervalle mit einer jeweils eigenen Anzahl aufzubewahrender Backups definieren, sodass Rsnapshot sehr flexibel einzusetzen ist.
Auf die Konfiguration folgt ein erster Testlauf durch Eingabe des Befehls:
rsnapshot -v Intervall
Mit dem Parameter »Intervall« ist hier das jeweils in der Konfigurationsdatei definierte Intervall anzugeben, also etwa »hourly« oder »daily«. Quell- und Zielverzeichnisse muss der Nutzer nicht angeben, denn diese Angaben entnimmt Rsnapshot der Konfigurationsdatei.
Da Rsnapshot seine Sicherungen nicht in Archiven oder eigenen Formaten ablegt, sind die Daten direkt zugänglich und dürfen für eine Restauration einfach zurückkopiert werden. Nach einem erfolgreichen Testlauf kann der Administrator die benötigten entsprechenden Cronjobs einrichten.
Fazit
Die besprochenen Backuplösungen arbeiten alle zuverlässig und stabil. Sie eignen sich durchgängig sowohl für eine Sicherung lokaler Systeme als auch von Servern. Gilt es, Sicherungsarchive jedoch in die Cloud auszulagern, scheitern die meisten Programme an der fehlenden Verschlüsselung. Zumindest in einer Public Cloud wird der Admin seine Backups allerdings nicht ohne Verschlüsselung ablegen wollen.
Zu bemängeln ist außerdem bei einigen Kandidaten eine schlechte bis schlichtweg katastrophale Dokumentation. Teils erläutert die vorhandene Beschreibung Funktionsparameter nicht und listet auch keine Anwendungsbeispiele auf, teils besteht die Manpage obendrein nur aus einem flotten Zehnzeiler. Als Konsequenz solcher Defizite dürfen die Entwickler in diesen Fällen nicht erwarten, dass ihr Programm bei Anwendern, deren Zeit und Geduld begrenzt ist, auf breite Akzeptanz stößt.
Die meist für Unix-ähnliche Betriebssysteme entwickelten Backuplösungen zeigen außerdem teilweise insofern konzeptionelle Schwächen, als sie in heterogenen Umgebungen nicht immer funktionieren können. So lassen sich Hardlinks unter längst nicht allen Plattformen und mit allen Dateisystemen verwenden. Bei einem Tool wie Rsnapshot schränkt dieser Umstand das Einsatzgebiet auf Linux und verwandte Systeme ein.
|
Attic |
Bup |
Duplicity |
Rdiff-Backup |
Rsnapshot |
|
|---|---|---|---|---|---|
|
Lokale Sicherung |
ja |
ja |
ja |
ja |
ja |
|
Sicherung per SSH |
ja |
ja |
ja |
ja |
ja |
|
Verifizierung |
ja |
ja |
ja |
ja |
ja (Logdatei) |
|
Verschlüsselung |
ja |
ja |
ja |
nein |
nein |
|
Clouddienste |
nein |
nein |
ja (Amazon, Rackspace) |
nein |
nein |
|
Include/exclude Verzeichn. |
ja |
ja |
ja |
ja |
ja |
|
Zeitgesteuert |
ja* |
ja* |
ja* |
ja* |
ja* |
|
Frontends verfügbar |
nein |
ja |
ja |
nein |
ja |
|
Inkrementelle Backups |
ja |
ja |
ja |
ja |
nein |
|
Differenzielle Backups |
nein |
nein |
nein |
nein |
nein |
|
Manuelle Vollsicherungen |
ja |
ja |
ja |
ja |
ja |
|
Fuse-Mount möglich |
ja |
ja |
nein |
ja |
nein |
|
* = zeitgesteuerte Sicherungsläufe mit Cron-Daemon |
Infos
-
Attic und Download-Option: https://attic-backup.org/installation.html#installation
-
Bup auf Github: https://github.com/bup/bup
-
Dokumentation von Bup: https://bup.github.io/man.html
-
Duplicity: http://duplicity.nongnu.org
-
Duplicity-Dokumentation: http://duplicity.nongnu.org/duplicity.1.html
-
GUI Deja-Dup: https://launchpad.net/deja-dup
-
Clonezilla-Webseite: http://clonezilla.org
-
Rdiff-Projektseite: http://www.nongnu.org/rdiff-backup/
-
Github-Seite von Rdiff-Backup-fs:https://github.com/rbrito/rdiff-backup-fs
-
Rdiff-Backup-Dokumentation: http://www.nongnu.org/rdiff-backup/examples.html
-
Rsnapshot-Projektseite: http://rsnapshot.org
-
FAQ zu Rsnapshot: http://rsnapshot.org/faq.html






das gute alte ‘rsync’ hat keine Berücksichtigung gefunden