
© ftlaudgirl, 123RF
Markow-Ketten modellieren Systeme, die mit vorgegebenen Wahrscheinlichkeiten von Zustand zu Zustand hüpfen. Aber können sie nach einer Analyse bisher geschriebener Artikel ein KI-System erzeugen, das neue Kolumnen wie diese schreibt?
Da meine Kolumne mit dieser Ausgabe sage und schreibe zwanzig Jahre voll hat (die erste Folge erschien im September 1997) und da künstliche Intelligenz immer mehr Arbeitsplätze verdrängt, stellt sich die Frage, ob es einmal ein KI-System schaffen könnte, das Manuskript zum bassen Staunen der sonst zum Unzeitpunkt Redaktionsschluss rufenden Redakteure fürderhin pünktlich abzuliefern und es dem Autor stattdessen erlaubt, möglichst dauerhaft seinem Surfhobby an diversen Pazifikstränden nachzugehen (Abbildung 1).

Abbildung 1: Ziel: Der Autor surft auf Hawaii, während ein KI-System seine Kolumne schreibt.
Launisch wie das Wetter
Als Algorithmus böte sich eine so genannte Markow-Kette an, benannt nach dem russischen Mathematiker Andrei Markow (englisch: Markov). Dabei handelt es sich um stochastische Prozesse mit verschiedenen Zuständen, die entsprechend vorgegebener Wahrscheinlichkeiten wechseln.
Das in Abbildung 2 dargestellte Modell zur Wettervorhersage besagt zum Beispiel, dass auf den Zustand “Sonne” mit 65-prozentiger Wahrscheinlichkeit wieder ein Sonnentag folgt. Zu 30 Prozent wechselt das Wetter zu “Bewölkt” und zu 5 Prozent sogar direkt zu “Regen”. Die angegebenen Wahrscheinlichkeiten beziehen sich nur auf den aktuellen Zustand, ein Wechsel in den nächsten erfordert keine Kenntnis der vorherigen, ist also höchst einfach auszurechnen.
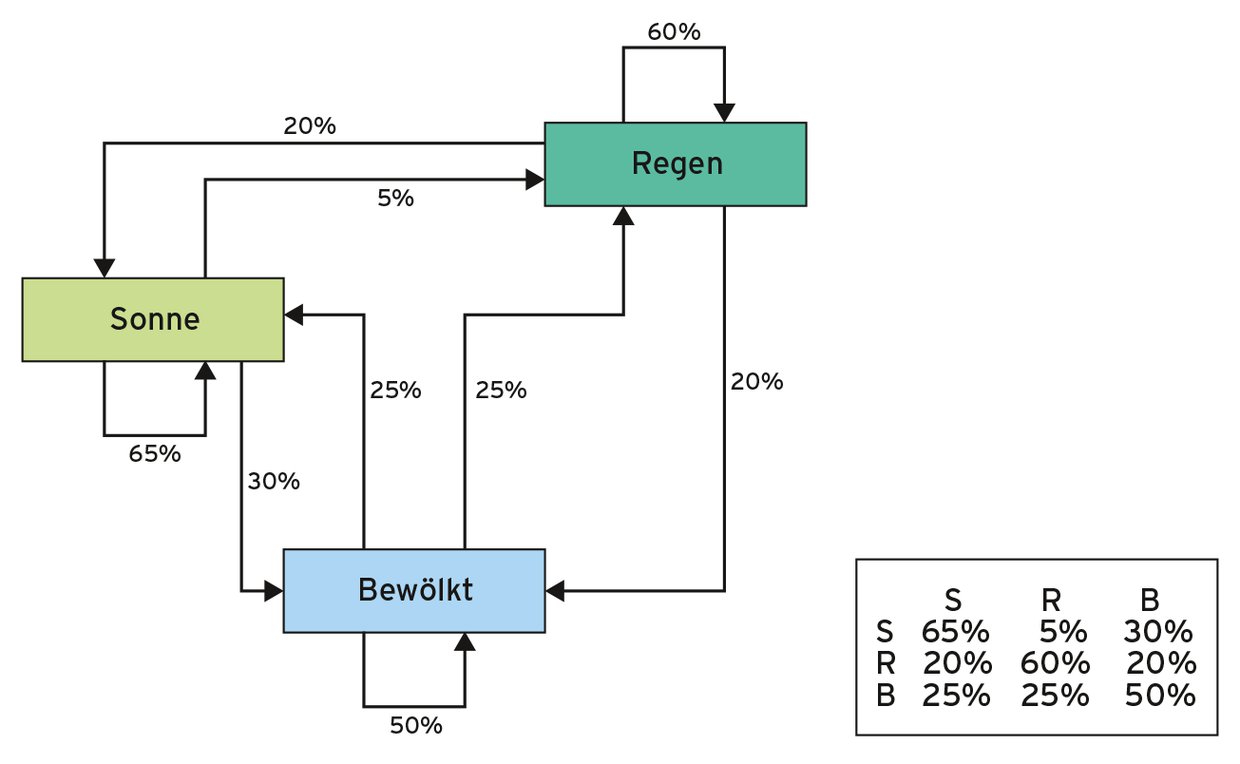
Abbildung 2: Markow-Diagramm zur Wettervorhersage.
In einer Übergangsmatrix wie in Abbildung 2 unten rechts zu sehen, muss der Rechner nur die Reihe mit dem aktuellen Zustand heraussuchen, etwa Reihe 3 für den Zustand bewölkt (B), um herauszufinden, dass das Wetter zu 25 Prozent sonnig bleibt, zu 25 Prozent in Regen und zu 50 Prozent in Bewölkt umschlägt. Mit entsprechenden Zufallsgeneratoren ausgestattet springt das Modell zwischen den Zuständen hin und her, die spätere Auswertung des Monte-Carlo-Verfahrens erlaubt Rückschlüsse auf das wahrscheinlichste zukünftige Wetter.
Sätze vom Automaten
Mittels solcher “Random Walks” lassen sich auch Sätze mit einer fein dosierten Portion Zufall generieren. Hierzu analysiert ein Programm zunächst die Wortfolgen in einem umfangreichen Korpustext. Es merkt sich, welche Wörter in einem Satz aufeinander folgen, und stückelt aus gelernten Satzteilen einen neuen Text zusammen. Merkt es zum Beispiel, dass nach drei bestimmten Wörtern als viertes irgendwo im Korpus Wort A und einmal Wort B steht, wird es im generierten Text jedes Mal einen imaginären Würfel entscheiden lassen, welches zum jeweiligen Zeitpunkt zum Einsatz kommt.
Es zerlegt den Korpustext in Wörter (Tokens) und analysiert ihn schrittweise mit einem rollenden Fenster von n Wörtern. Die ersten n-1 Wörter des Fensters bestimmen den Zustand des Automaten an diesem Zeitpunkt, das letzte Wort ist der Wert, den der Automat beim Übergang in den nächsten Zustand annimmt.
Rollendes Fenster
Bei einer Fenstergröße von n=3 extrahiert der Algorithmus aus “Ene mene muh und raus bist du.” zum Beispiel die Fenster “Ene mene muh”, “mene muh und”, “muh und raus” und so weiter. Die ersten zwei Wörter bestimmen jeweils den Zustand des Automaten (“bist du”), das folgende Wort (oder im vorliegenden Fall das Sonderzeichen “.”) ist der Folgezustand. Stolpert der Algorithmus im zweiten Teil des Abzählreims (“raus bist du noch lange nicht”) ebenfalls wieder auf den Zustand “bist du”, dann folgt auf diesen aber kein Punkt, sondern das Wort “noch”. Jetzt hat der Algorithmus beim späteren Erstellen des Zufallstextes zwei Möglichkeiten: Er kann auf “bist du” entweder einen Punkt folgen lassen oder das Wort “noch”, und er wird dies auch entsprechend den kalkulierten Zufallswerten tun. Das Ergebnis ist ein Text, der leicht menschliche Qualitäten aufweist, weil er Wortfolgen kopiert, aber hin und wieder in andere Zusammenhänge springt, was entweder konfus oder lustig klingt.
Listing 1 holt sich den Sourcecode der bisher erschienenen Programmier-Snapshots seit 1997 und übergibt den Namen der sie enthaltenden Datei an die Funktion »generate_from()« in Zeile 68. Die Funktion »statemap_gen« ab Zeile 37 unterteilt die Datei mit »token_feed()« in Tokens und übergibt die daraus resultierende Liste der Funktion »window()« ab Zeile 26, die als Fensterbreite »n=4« entgegennimmt. Der Status der Markow-Kette besteht aus den drei letzten Wörtern, das vierte ist Teil des Folgezustands.
Listing 1
randomtext.py
01 #!/usr/bin/python3
02 from nltk.tokenize import word_tokenize
03 from collections import deque
04 import re
05 import random
06
07 re_special=re.compile("^[,.:]$")
08 re_word=re.compile("^\w+$")
09
10 def token_feed(file):
11 string = open(file, 'r').read()
12
13 for i in word_tokenize(string):
14 if re_special.match(i) or \
15 re_word.match(i):
16 yield(i)
17
18 def tokens_to_text(tokens):
19 out=""
20 for word in tokens:
21 if(not re_special.match(word)):
22 out += " "
23 out += word
24 return out
25
26 def window(seq, n):
27 it = iter(seq)
28 win = deque(
29 (next(it, None) for _ in range(n)),
30 maxlen=n)
31 yield win
32 append = win.append
33 for e in it:
34 append(e)
35 yield win
36
37 def statemap_gen(file):
38 statemap={}
39 tokens=token_feed(file)
40 for state in window(tokens,4):
41 key = list(state)
42 value = key.pop()
43 key = tuple(key)
44
45 if key in statemap:
46 statemap[key].append(value)
47 else:
48 statemap[key] = [value]
49 return statemap
50
51 def generate_from(file):
52 statemap=statemap_gen(file)
53 key=list(
54 random.choice(list(statemap.keys())))
55 words_new=list(key)
56
57 for i in range(200):
58 if not tuple(key) in statemap:
59 continue
60 next_token = random.choice(
61 statemap[tuple(key)])
62 words_new.append(next_token)
63 key.append(next_token)
64 key.pop(0)
65
66 return tokens_to_text(words_new)
67
68 print(generate_from('test.txt'))
Damit der Tokenizer aus dem Paket »nltk« bereitsteht, muss ich es mit »pip3 install nltk« installieren und noch den Tokenizer-Datensatz »punkt« herunterladen (Abbildung 3). Satzzeichen wie Kommas oder Doppelpunkte (der reguläre Ausdruck in Zeile 7 definiert sie alle) interpretiert der Tokenizer als eigene Tokens, das erhöht später die Lesbarkeit des Zufallstextes.

Abbildung 3: Herunterladen der Daten für den Nltk-Tokenizer.
Abbildung 4 zeigt, wie der Algorithmus aus dem Abzählreim und der Fensterlänge n=3 eine Zustandsdatei der Markow-Kette erzeugt. Die Alternativen “.” und “noch” als mögliche Folgen der Wortkette “bist du” gibt dieser Eintrag vor:
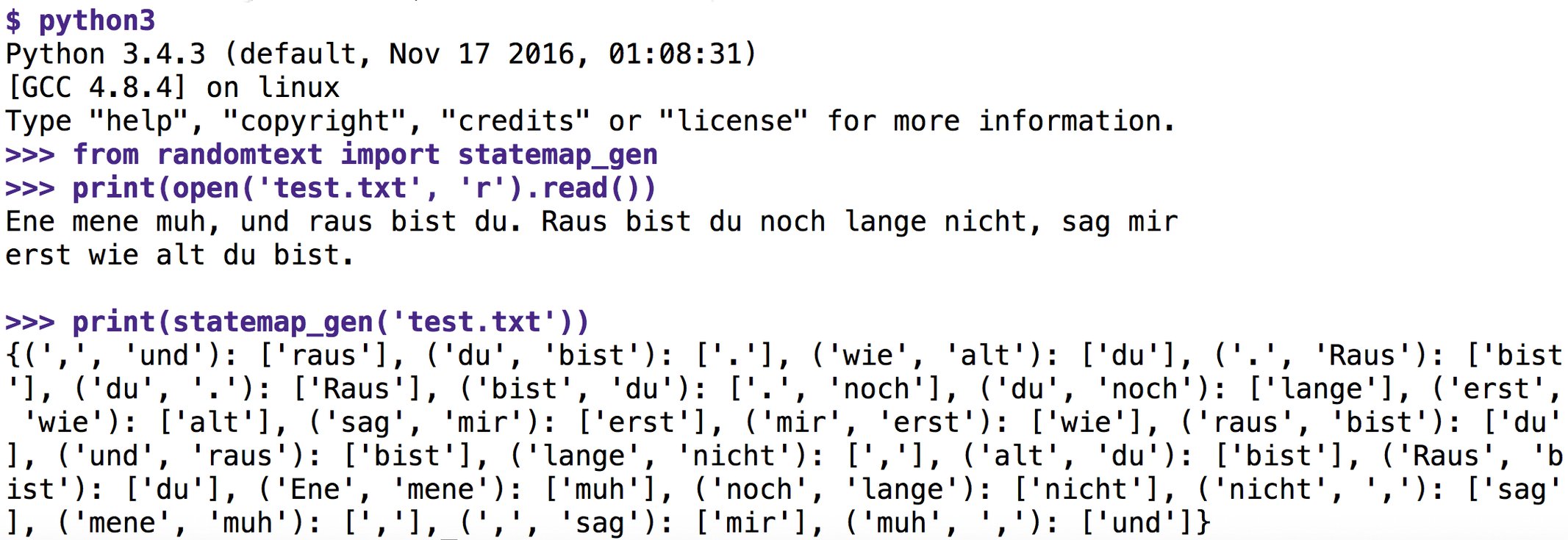
Abbildung 4: Zerteilen eines Textes in Tokens und Erstellen des Markow-Modells.
('bist', 'du'): ['.', 'noch']
Der Python-Code zeigt einige Schmankerl der Sprache, zum Beispiel den »yield()«-Operator in der Funktion »token_feed()« in Zeile 16: Damit Python mittels einer For-Schleife über die Komponenten eines Objekts iterieren kann, muss selbiges vom Typ »Iterable« sein. Diese spucken ihre Komponenten nicht in einem Rutsch aus, sondern reichen sie scheibchenweise bei jedem Aufruf durch.
Das hat den Vorteil, dass das Skript nicht alle in einem Konstrukt enthaltenen Daten im Arbeitsspeicher vorhalten muss, sondern sie erst bei Bedarf ausrechnen darf. So kann ein Objekt unendlich viele Komponenten enthalten, wenn sie nie alle gebraucht werden, bleibt die Illusion trotz begrenztem Arbeitsspeicher erhalten.
Python bietet auch eine Vielzahl von Datenstrukturen. Die so genannten Double Ended Queues, genannt »deque«, in der Funktion »window()« ab Zeile 26 lassen sich besonders performant umwandeln, indem Elemente zum Kopf oder Schwanz der Schlange hinzugefügt oder entfernt werden. Der einzige Schönheitsfehler ist, dass der Aufrufer der Funktion »window()« die von ihr zurückgegebene Deque nicht manipulieren darf, sonst gerät der Algorithmus durcheinander.
Aus diesem Grund kopiert Zeile 41 mit »key=list(state)« die Elemente des Deque-Objekts in eine Python-Liste, auf der die Funktion »statemap_gen()« nach Herzenslust herumorgeln darf. Sie interpretiert die ersten n-1 Elemente als Markow-Status und das letzte Element als möglichen Folgewert.
In »key« liegt nach Zeile 43 ein nicht mehr modifizierbarer Python-Tupel, der dem Eintrag unter dem Schlüssel in einem mehrdimensionalen Dictionary »statemap« den Folgewert zuweist. Später kann der Algorithmus also nachsehen, ob zu einer Folge von n-1 Wörtern schon ein oder mehrere Folgewerte existieren, und davon per »random.choice()« in Zeile 60 einen zufälligen auswählen. Das lenkt den Text in unberechenbare Bahnen und macht den Reiz des Verfahrens aus.
Das Ergebnis präsentiert Abbildung 5. Es zeigt allerdings, dass das angewandte Markow-Ketten-Verfahren nicht automatisch spannende neue Artikel liefert. Auch bei der Grammatik hapert es noch gewaltig. Der Snapshot wird wohl auf absehbare Zeit von Hand erstellt werden müssen.

Abbildung 5: Das KI-System schreibt den Snapshot aller Snapshots.
Online PLUS
Im Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/Ausgaben/2017/09/plus
Infos
-
Listings zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2017/09/snapshot/
Der Autor

Michael Schilli arbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





