
© sakkmesterke, 123RF
Einerseits müssen es nicht immer die großen und komplexen Monitoringsysteme sein, wenn nur ein paar Leistungs-Eckdaten zu bestimmen sind. Andererseits nutzen auch die Großen oft kleine Tools, Spezialisten für schnelle Messungen. Ein Blick in den Werkzeugkasten.
Spezielle Werkzeuge fürs Performance-Monitoring gibt es viele: Gemeinsam ist ihnen, dass sie auf einen bestimmten Anwendungszweck zugeschnitten sind und sich nicht mit den vielfältigen Aufgaben belasten, die große Monitoring-Suiten neben der Datensammlung noch im Pflichtenheft haben: Alarmierung und Eskalation etwa oder Visualisierung. Dafür folgen diese Tools oft dem Unix-Motto “Ein Kommando für einen Zweck” – hier das Messen eines oder mehrerer Parameter der Systemperformance. Die Weiterverarbeitung der Daten überlassen die Spezialisten dann Dritten.
Sysstat
Das Sysstat-Paket ([1], [2]) ist eine umfangreiche Toolsammlung, die zu allen Linux- und vielen Unix-Derivaten gehört. Es zeichnet sich nicht nur durch seinen Umfang aus, sondern vor allem auch durch die Fähigkeit, über längere Zeit automatisiert Daten sammeln und verdichten zu können. Um das Datensammeln zu aktivieren, braucht es Cronjobs für Root, die regelmäßig die Skripte »sa1« und »sa2« starten. Die steuern die tägliche Datensammlung und erzeugen eine Tageszusammenfassung.
Unter Debian (oder Ubuntu) richtet der Anwender die Jobs am einfachsten mittels »dpkg-reconfigure sysstat« ein, wonach er im Dialog eine entsprechende Frage mit »Yes« beantwortet. Wer die Cronjobs händisch einrichtet, muss zusätzlich in »/etc/default/sysstat« die Variable »ENABLED« auf »true« setzen.
Neben der Datenerfassung über längere Zeiträume kann »sar« auch ad hoc Daten liefern. Über Kommandozeilen-Parameter erfährt das Tool in diesem Fall nicht nur, welche Messwerte gewünscht sind, sondern auch mit welcher Frequenz es Proben nehmen soll. Beispielsweise liefert »sar -R 1 10« zehn Tabellenzeilen mit Memory-Statistiken im 1-Sekunden-Abstand. In dieser Weise gibt es Dutzende von Optionen für einzelne Messgrößen. Prinzipiell erteilt »sar« Auskunft über:
- I/O-Transferraten, wahlweise per Gerät, Partition, Prozess oder NFS-Volume
- CPU-Auslastung, wahlweise per CPU oder Prozess
- Arbeitsspeichernutzung inklusive Swapping und Paging
- Geschwindigkeit, mit der das System neue Prozesse erzeugt
- Interrupts nach Anzahl und Art
- Netzwerk-Interfaces
- Sockets
- NFS-Server und -Clients
- Runqueue (Load Average)
- Context Switches und interne Kernel-Tables
- TTY-Aktivitäten
Das Tool gibt die Daten tabellarisch auf der Konsole aus, von wo aus man sie bei Bedarf parsen und in andere Tools importieren kann.
Für die Visualisierung der Sar-Daten existiert schon ein fertiges Werkzeug: Ksar [3]. Das Java-Programm kann als Datenquelle sowohl lokal als auch entfernt laufende Sar-Kommandos wie auch die Files mit Tageswerten nutzen, die das Sar-Tool anlegt. In mehreren Unterfenstern lässt sich der Admin die Kurven verschiedener Messwerte darstellen. Dabei sind alle Zeitachsen automatisch synchronisiert, sodass sich leicht Wechselwirkungen zwischen den Parametern erkennen lassen (Abbildung 1).
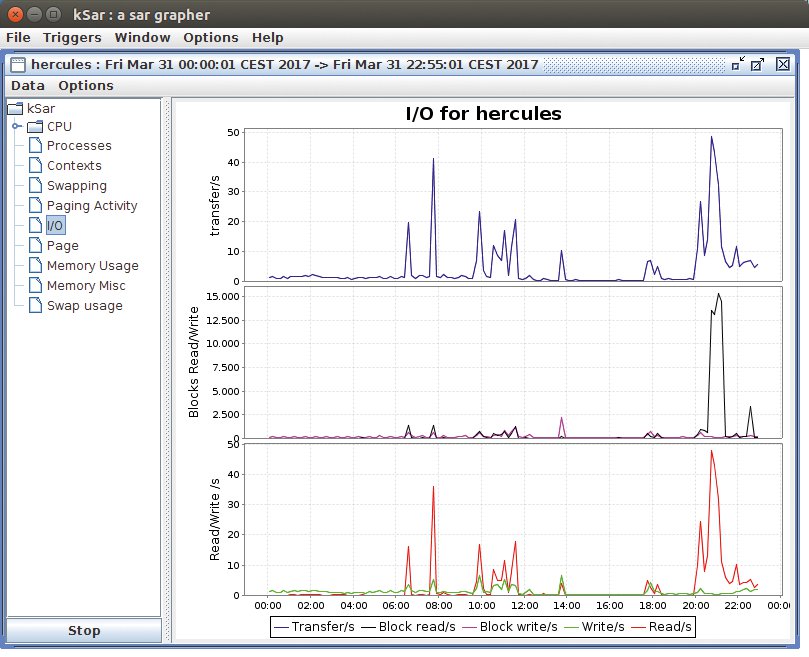
Abbildung 1: Eine beispielhafte Visualisierung von Messdaten mit Ksar.
Neben Sar enthält das Sysstat-Paket noch die Tools Pidstat, Iostat und Mp-stat. Pidstat überwacht alle oder einzelne Tasks, die der Linux-Kernel verwaltet, und gibt pro Prozess Statistiken aus wie I/Os, CPU-Last, Scheduling, Memory-Inanspruchnahme, Stack-Auslastung oder Task-Switching-Aktivitäten. Iostat sorgt für I/O-Statistiken pro Platte oder Partition. Mpstat liefert Werte für die Auslastung einzelner CPUs in einem Mehrprozessorsystem.
Nmon
Ein weiterer Alleskönner ist Nmon ([4], [5]). Ihn zeichnet besonders aus, dass er keine privilegierten Benutzer braucht und dennoch eine Unmenge nützlicher Informationen liefert. Besonders ist außerdem, dass Nmon für Linux auf vielen Plattformen zu Hause ist: auf Power, x86, x86_64, ARM (Raspberry Pi) und auf Mainframes. Und noch etwas hat das Tool der Konkurrenz voraus: Es integriert Grafiken in Form von Ascii-Balkendiagrammen in die Terminalausgabe, sodass man auch von einem Kommandozeilen-Werkzeug einen visuellen Eindruck erhält(Abbildung 2).
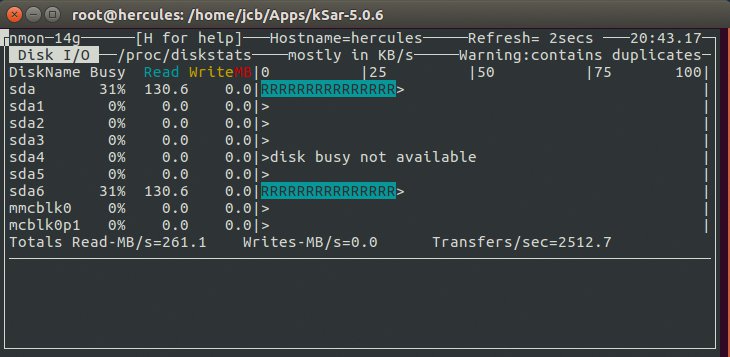
Abbildung 2: Nmon beherrscht einfache Säulendiagramme aus Ascii-Zeichen.
Nmon lässt sich interaktiv bedienen, indem der Nutzer aus einem Hauptmenü des Startbildschirms via Hotkey einzelne Statistiken anfordert. Verfügbar sind Daten über:
- CPU
- Memory und Virtual Memory
- Disks
- Betriebssystem-Details
- Kernel (Runqueue, Context Switches, Forks, Interrupts)
- Filesysteme
- Netzwerk
- NFS
- Prozesse
Nmon ist darüber hinaus auch in der Lage, die Messwerte in einem einfachen kommaseparierten Textfile zu speichern, von wo aus man sie später etwa in eine Tabellenkalkulation importieren kann. Es existieren auch Tools, um Nmon-Daten in einer Zeitreihen-Datenbank wie RRD abzulegen und daraus Diagramme zu erzeugen [6].
Vmstat
Von »iostat« war schon die Rede, im selben Stil steuert Linux noch das Kommando »vmstat« bei. Vmstat [7] gibt einen guten ersten Überblick über die Befindlichkeit des Systems. Die ersten beiden Spalten zeigen, wie viele Prozesse auf die Zuteilung von CPU-Zeit warten (»r«) beziehungsweise wie viele Prozesse im Moment blockiert sind (»b«). Ist die Anzahl der Prozesse in der so genannten Run Queue der CPU dauerhaft höher als die Anzahl der CPU-Kerne im System, deutet dies auf eine Überlastung der CPU-Ressourcen hin.
Die Prozesse in der Spalte »b« ruhen, während sie auf ein Event warten. Meist handelt es sich um eine noch nicht abgeschlossene I/O-Operation. Auch hier weist eine hohe Anzahl auf ein Performanceproblem hin. Generell sollten die Zahlen in den ersten beiden Spalten möglichst niedrig sein.
Die nächsten vier Spalten unter der gemeinsamen Überschrift »memory« spiegeln die Speicherverwaltung wider. Sie geben an, wie viel Swapspace in Benutzung ist, wie viel Speicher frei ist und wie viel RAM Buffer und Cache verwenden. Was das Swappen angeht, sind die folgenden beiden Spalten »si« und »so« besonders wichtig, die belegen, wie viel Memory das System auf Platten auslagert (»so«, Swap out) beziehungsweise aus dem Swap wieder einliest (»si«, Swap in). Diese Spalten sollten über längere Zeit nur den Wert null anzeigen, denn andauerndes Swappen bremst.
Die nächsten beiden Spalten »bi« und »bo« stehen für die Aktivität der Blockgeräte, also im Wesentlichen der Festplatten oder SSDs. Tauchen hier für längere Zeit hohe Werte auf, ist die Workload I/O-lastig. Es folgen die Spalten »in« und »cs«, was für Interrupts und Context Switches steht. Ergeben sich hier auffällige Werte, sollte der Admin deren Ursache zu ergründen versuchen. Bei den Interrupts hilft da beispielsweise »sar -I XALL«. Auch die Anzahl der Context Switches kann einen Performance-Engpass anzeigen. In vielen Fällen erhöht sich diese Anzahl, wenn mehrere Prozesse versuchen auf die gleiche Ressource zuzugreifen (Locking-Problem).
Die nächsten vier Spalten »us«, »sy«, »id« und »wa« sind Indikatoren dafür, wie viel Zeit die CPU jeweils für Applikationen im Userland, im Kernel, im Leerlauf und mit Warten auf I/O zugebracht hat.
Top in allen Spielarten
Das kleine Utility Top (Table of Processes) ist der Klassiker der Systemüberwachung schlechthin. Es bietet eine in Echtzeit sortierte und alle paar Sekunden aktualisierte Prozessliste mit Angaben über CPU- und Speicherverbrauch pro Prozess und global, zuzüglich Uptime, Anzahl eingeloggter User, Load Average und Task-Anzahl. So ergibt sich ein schneller Überblick über die momentan größten Konsumenten von Speicher- und CPU-Ressourcen.
Das Prinzip war so erfolgreich, dass es viele Nachahmer fand, die eigene Spielarten von Top kreierten [8]. Darunter ist etwa »atop«[9], das besonders die Informationen neben der Prozessliste ausgebaut hat und hier zusätzlich Netzwerkstatistiken, Werte für Lese- und Schreiboperationen auf die Platten sowie die Anzahl der Context Switches und Interrupts anzeigt. Nicht immer hat das Sinn, so addiert das Tool etwa die Idle-Werte in Prozent aller Kerne einer CPU zu einer unsinnigen Summe.
Daneben kann »atop« im laufenden Betrieb die Sortierung und Darstellung der Prozessliste ändern und wahlweise CPU-, Netzwerk-, Speicher-, I/O- oder Scheduling-Details pro Prozess anbieten. Auch Statistiken pro User sind möglich. Nicht zuletzt kann Atop seine Werte auch in einfache Ascii-Files schreiben, wobei es von allein merkt, ob seine Ausgabe im Terminal erfolgt oder in eine Datei umgeleitet wurde. In letzterem Fall spart es sich die Screen Control Codes, zum Beispiel für invertierte oder gefettete Darstellung. Mit all dem ist es deutlich flexibler als sein klassisches Vorbild.
Ein weiteres Top-Derivat heißt »htop«[10]. Eine seiner Spezialitäten ist das vertikale wie horizontale Scrollen. Das ermöglicht extrem lange Zeilen, wodurch das Tool die Prozesse mit vollem Pfad und allen Kommandozeilen-Optionen anzeigen kann. Kindprozesse kann Atop auf Wunsch auch hierarchisch darstellen. Darüber hinaus ist es in der Lage das Environment jedes Prozesses (Abbildung 3), die von ihm geöffneten Files und die von ihm benutzten Syscalls (via »strace«) auszugeben, was für die Fehlersuche sehr nützlich sein kann.
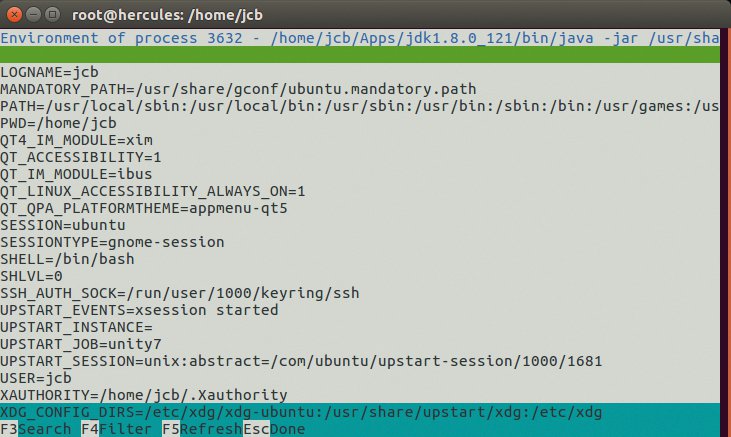
Abbildung 3: Als nützliches Extra kann Htop unter anderem das Environment jedes Prozesses anzeigen.
Interaktiv erlaubt Htop das Ändern der Prozesspriorität und das Senden von Signalen an einen Prozess, der in der Liste markiert wurde. Dabei, wie auch an einigen anderen Stellen, bietet es sehr bequeme Wertelisten an, aus denen Anwender das Passende auswählen. Die Optik der Anzeige aller Werte ist weitgehend frei konfigurierbar.
Ntopng [11] ist ein entfernterer Top-Verwandter, was nicht allein daran zu erkennen ist, dass sich das Tool ganz dem Netzwerkmonitoring verschrieben hat, sondern auch daran, dass es keine Terminalausgaben kennt. Stattdessen präsentiert es seine Ergebnisse über einen eingebauten Webserver in einem Browser. Dort kann Ntopng tabellarische Übersichten über die Hosts, Netzwerke, MAC-Adressen oder autonomen Systeme liefern, mit denen am meisten kommuniziert wurde. Für jede Kategorie ist das Verhältnis von empfangenen und gesendeten Paketen sowie die benutzte Bandbreite und der Gesamtumfang des Datenaustauschs ersichtlich.
Außerdem gibt es Bestenlisten zu Ländern und Betriebssystemen der Kommunikationspartner. Deren geografische Orte sind auf Wunsch in einer Karte darstellbar. Die Kommunikationsverbindungen (Flows) kann das Tool auch grafisch darstellen (Abbildung 4). Daneben sind Statistiken zu einzelnen Interfaces des Hosts möglich, auf dem Ntopng läuft.
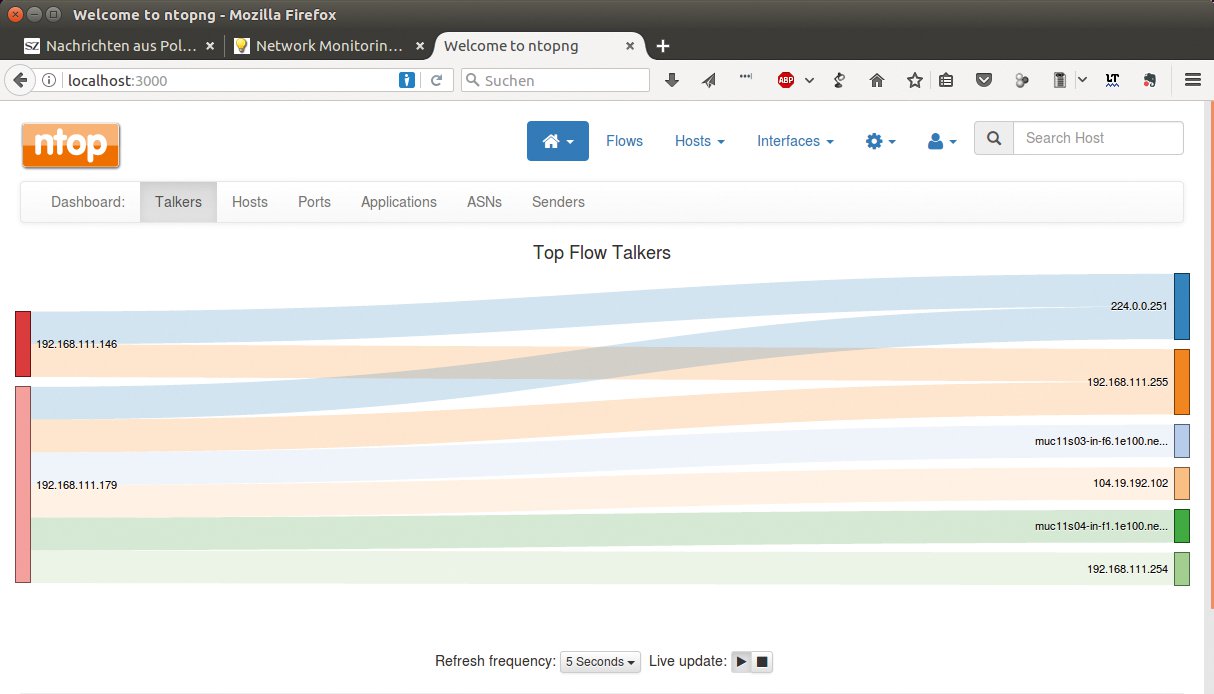
Abbildung 4: Ntop stellt den Umfang des Datenverkehrs auf Wunsch grafisch dar.
Ntopng kann auch längerfristige Statistiken zu einzelnen Parametern wie Durchsatz oder Applikationsprotokollen generieren und seine Daten dafür im RRD-Format speichern. Die Kommunikationsstatistiken können auch ins Detail gehen und etwa die Latenz von Netzwerk oder Applikation, die Round Trip Time, die Anzahl der Paketwiederholungen oder Paketverluste umfassen.
Fazit
Viele kleine Utilities helfen dabei, sich einen Überblick über die Systemperformance zu verschaffen. Die meisten Parameter sind auf verschiedenen Wegen zu erheben. Doch sind die Zahlen für sich genommen noch nicht allzu viel wert. Erstens sind in den meisten Fällen Vergleichswerte erforderlich, um einschätzen zu können, was für eine bestimmte Anwendung viel oder wenig, normal oder außergewöhnlich ist.
Zweitens sind ziellose Messungen sinnlos, nötig ist dagegen eine Hypothese, die sich systematisch mit Messwerten be- oder widerlegen lässt. Drittens wird man ein Problem über eine längere Zeit beobachten müssen, um nicht momentanen Extremwerten aufzusitzen, die vielleicht auffallend, aber insgesamt untypisch sind. Dabei helfen besonders Tools wie Sar, die kontinuierlich über längere Zeit messen und die Resultate automatisch protokollieren. Das ermöglicht es auch, im Nachhinein Beziehungen zwischen einzelnen Messgrößen zu erkennen.
Infos
-
Kames, Feilner, “Sar, Pidstat & Co.: Das Sysstat-Paket”: Linux-Magazin 09/08, S. 70
-
Charly Kühnast, “Nmon”: Linux-Magazin 06/10, S. 81
-
Nmon2web: https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/Power%20Systems/page/nmon2web
-
Spreitzer, Feilner, “Top-Tools”: Linux-Magazin 10/08, S. 50
-
Atop: http://www.atoptool.nl
-
Htop: http://hisham.hm/htop





