
© Inara Prusakova, 123RF
Grafana bereitet Messdaten aus verschiedenen Quellen optisch auf und bietet dem Admin eine gute Übersicht. Welche Backends unterstützt es? Eine Übersicht.
Admins haftet der Ruf an, sie fühlten sich mit textbasierten Terminals wohler als bei der Arbeit mit grafischen Werkzeugen. Für klassische Admin-Aufgaben ist die Kommandozeile oft tatsächlich besser geeignet als ein GUI – weil sie Scripting erlaubt und direkte Eingaben.
Bei anderen Aufgaben des Admin verkehrt sich diese Einschätzung allerdings ins Gegenteil: Wenn es um die visuelle Aufbereitung von Messdaten und Statistiken geht, sind grafische Tools der Kommandozeile klar überlegen. Gerade wo es um Monitoring, Alerting und Trending (MAT) geht, fallen diverse Daten aus vielen Quellen an, die nur visualisiert sinnvoll nutzbar sind.
Praktisch jede große Umgebung, ganz gleich ob Container-Plattform oder Public-Cloud-Umgebung, ist auf MAT dringend angewiesen. Nur daraus ergeben sich für den Admin zuverlässige Anhaltspunkte über den Zustand und die Auslastung der Plattform. Und nur eben diese Anhaltspunkte verraten ihm, dass er bald neue Hardware anschaffen muss, weil seine Plattform aktuell fast voll ist.
Grafana als Matchwinner
An diese Admins mit Analysebedarf richtet sich Grafana [1]. Der Clou: Das Programm kann mit unterschiedlichen Backends umgehen und die anzuzeigenden Daten aus vielen Quellen beziehen. Seine Entwickler bezeichnen das als Data-Driven Architecture. An die Stelle klassischen Event-Monitorings tritt ein auf Zeitserien basierendes Prinzip, bei dem das Monitoring ein Abfallprodukt der kontinuierlichen Erhebung diverser Messwerte ist. Etwa bei Datenbanken: Wer auf Basis von Galera einen Multi-Knoten-Cluster für MySQL betreibt, erwartet, dass die anliegende Last auf allen Datenbank-Backends vergleichbar hoch ist. Fällt für eines der Backends die gemessene Systemlast plötzlich ab, ist das ein sicherer Indikator dafür, dass etwas nicht stimmt.
Anders als das typische Incident-Monitoring im Sinne von Nagios entsteht die Erkenntnis bei dieser Art des Monitorings also durch einen Rückschluss aus Performancedaten. Zwar geht es bei Grafana nicht primär um Monitoring – aber es hilft dabei, die Zeitreihen entsprechender Monitoringsysteme leicht interpretierbar aufzubereiten. Dieser Artikel beleuchtet im Folgenden zunächst die wichtigsten Features von Grafana und stellt danach die wichtigsten Backends vor, aus denen es seine Informationen beziehen kann.
Umbruch beim Monitoring
Um die Motivation hinter Grafana zu verstehen, ist ein kleiner Ausflug in die Welt des Monitorings nötig. Dort hat sich in den vergangenen Jahren ein fundamentaler Wandel vollzogen, der seinerseits eng mit dem Thema Cloud und den sich daraus ergebenden Veränderungen zusammenhängt. Denn das Monitoring für Clouds funktioniert anders als jenes für herkömmliche IT-Plattformen. Die waren ja bis zu einem bestimmten Grad statisch: Nach dem Setup der Umgebung hat diese sich bloß noch in Details verändert. Die Standardtools in Sachen Monitoring sind gestandenen Admins hinlänglich bekannt: Nagios, Icinga, Check Mk und diverse andere Lösungen gleicher Bauart geben den Ton an.
Das Monitoring konventioneller IT-Umgebungen beruht auf Ereignissen. Wenn etwa ein Dienst auf einem Server nicht mehr läuft, merkt das Monitoringsystem das und schlägt Alarm. Trending spielt in diesem klassischen Szenario eine untergeordnete Rolle, weil die Workload eines solchen Setups meist gleichmäßig wächst. Daher hat der Admin genug Zeit, um sich auf die Anschaffung neuer Hardware vorzubereiten. Ganz ohne Trending kommen auch die konventionellen Monitoring-Lösungen nicht aus: Für Nagios existiert etwa PNP4Nagios [2], das über seine Checks auch Performancedaten sammelt und diese dann als Grafik direkt im Nagios-Webinterface anzeigt.
Für eine Public Cloud funktioniert das so nicht mehr. Denn hier ist kaum vorhersagbar, wann die Plattform durch das Hinzufügen neuer Server in die Breite skalieren muss. Ein neuer Kunde mit riesiger Workload kann sich in einer typischen Public Cloud schließlich jederzeit einen Account anlegen und entsprechende Last erzeugen.
Trending wird wichtiger
Bei Plattformen neueren Typs spielt das Thema Trending deshalb eine größere Rolle als bei ihren konventionellen Vorgängern. PNP4Nagios oder vergleichbare Lösungen wirken hier eher wie ein Notnagel. Normalerweise legen sie ihre Messdaten im Hintergrund in einer gewöhnlichen Datenbank ab. Meist handelt es sich um MySQL, die sich für klassisches, Event-basiertes Monitoring problemlos geeignet: Vorfälle werden zu einem eigenen Eintrag in einer Tabelle. Weil für den Admin in diesem Szenario einzelne Ereignisse von Interesse sind und die Daten in MySQL genau so abgespeichert sind, entsteht weder beim Auslesen der Daten noch bei deren Verarbeitung ein Problem.
Trending ändert die Spielregeln. Denn beim Trending stehen nicht Ereignisse im Vordergrund, sondern die Entwicklung der Performancedaten eines bestimmten Checks im zeitlichen Zusammenhang. Der Admin will beim Trending nicht mehr wissen, ob ein bestimmter Dienst zu einem bestimmten Zeitpunkt funktionierte oder nicht. Viel eher interessiert ihn, ob zentrale Vitalwerte der Systeme wie die CPU-Last und die RAM-Nutzung über einen längeren Zeitraum so hoch sind, dass neue Hardware zur Lastverteilung notwendig ist.
Will ein Admin diese Information allerdings aus den einzelnen Ereignissen generieren, die in MySQL abgespeichert sind, verursacht das viele einzelne Datenbankabfragen und mithin eine entsprechend hohe Last. Außerdem dauert es recht lange, bis MySQL oder vergleichbare Datenbanken die Antworten auf entsprechende Queries liefern.
Anders speichern
An dieser Stelle treten Datenbanken für Zeitreihen auf den Plan – Time Series Databases. Die sind zwar wie MySQL Datenbanken, doch ihre internen Strukturen unterscheiden sich von SQL-Datenbanken deutlich: Zeitreihen-Datenbanken sind ab Werk darauf ausgelegt, Ereignisse in ihrem zeitlichen Ablauf abzuspeichern statt in Form einzelner Ereignisse. Sie sind deshalb in der Lage, die Anfrage “Wie hoch war die CPU-Last von System x im Zeitraum y” deutlich schneller zurückzuliefern als MySQL.
Der Clou: Bei einer Zeitreihe fällt das klassische, Event-basierte Monitoring quasi als eine Art Abfallprodukt nebenbei an, weil der definierte Zeitraum eben auch ein einziger Zeitpunkt sein kann (“vor genau 30 Sekunden”). MAT-Systeme auf Zeitreihen-Basis lassen sich deshalb sowohl für klassisches Monitoring als auch für umfassendes Trending nutzen. Genau das ist die aktuelle Entwiklungsrichtung: Alle Monitoringsysteme, die in den vergangenen Jahren entstanden sind, bauen im Hintergrund auf eine DB mit Zeitreihen-Struktur.
Wie funktioniert Grafana?
Nun kommt wieder Grafana ins Spiel: Den Grafana-Entwicklern ist nämlich aufgefallen, dass es am Markt mittlerweile zwar eine ganze Reihe Time-Series-Datenbanken gibt. Doch die schönsten Trendingdaten helfen dem Admin nicht, wenn er sie nicht irgendwie visualisieren und so verständlich machen kann. In genau diese Lücke stößt Grafana. Die Komponente selbst ist dabei gar nicht so komplex: Im Wesentlichen besteht Grafana aus einem Server, der HTTP(S) spricht und ein grafisches Webinterface exponiert.
Unter der Haube verfügt der Dienst über eine Plug-in-Schnittstelle für verschiedene Backends, sprich zwischen Grafana und diversen Zeitreihen-Datenbanken. Im Webinterface legt der Admin fest, welche Informationen aus den jeweiligen Backends er in Grafana sehen möchte. Grafana eilt nun los und sammelt die gewünschten Informationen ein, um anschließend Bilder aus ihnen zu generieren. Der Admin erhält eine einheitliche Oberfläche, die ihm die wichtigsten Infos aus verschiedenen Time Series Databases auf einen Blick präsentiert. Und weil Grafana viel Wert auf Flexibilität legt, richtet der Admin sich sein GUI, also sein Dashboard oder Kontrollzentrum, so ein, wie es ihm gefällt.
Erfreulich ist auch, dass Grafana leicht zu installieren und zu nutzen ist. Auf ihrer Website erklären die Entwickler, wie sie ihr Werkzeug auf Red Hat Enterprise Linux, Core OS, Debian oder Ubuntu installieren und konfigurieren. Auch auf Windows-Servern und Macs lässt sich Grafana betreiben. Wer es ganz einfach haben will, findet zudem einen Docker-Container mit vorinstalliertem Grafana, der in jeder Docker-Umgebung ad hoc startbar ist. Innerhalb weniger Minuten hat er dann Zugriff auf ein laufendes Grafana, bei dem bloß noch die Datenquellen zu definieren sind.
Grafana zeigt sich auch hier großzügig: Der Support reicht von gängigen Zeitreihen-Datenbanken wie Open TSDB und Influx DB über Prometheus bis hin zu exotischen Lösungen wie Open Stack Gnocchi. Mittlerweile unterstützt Grafana sogar Datenbanken, die gar keine echten Time Series Databases sind: Beispielhaft erwähnt sei Elasticsearch.
Im Folgenden stellt der Artikel die wichtigsten Backends vor und zeigt, wie sich Grafana mit der jeweiligen Datenbank verwenden lässt.
Graphite
Den Anfang im Schaulaufen der Grafana-Backends macht Graphite [3]. Schon aus der phonetischen Ähnlichkeit lässt sich herleiten, dass die beiden Lösungen zumindest eine gemeinsame Schnittmenge in Sachen Funktion haben: Wie Grafana bietet auch Graphite die Möglichkeit, Metrikdaten optisch visualisiert darzustellen. Anders als Grafana sieht Graphite darin aber nicht seine Hauptaufgabe. Stattdessen handelt es sich bei Graphite in erster Linie um eine Zeitreihen-Datenbank mit angeklebtem GUI.
Im Kern besteht Graphite aus drei Komponenten: Carbon fungiert als eine Art Broker und wartet darauf, von externen Stellen Metrikdaten geliefert zu bekommen. Die speichert es dann in Whisper, dem Kern der Software. Whisper ist die Time Series Database.
Interessanterweise kommt Graphite selbst ebenfalls mit einem Webinterface: Das Werkzeug, das auf den wenig originellen Namen »graphite-web« hört, kann die aus Whisper bezogenen Daten problemlos visuell darstellen. Zu Recht stellt sich mancher Admin deshalb die Frage, wieso Grafana dann die Möglichkeit bietet, an Graphite anzudocken.
Im Grunde genügt ein kurzer Blick auf beide Lösungen, denn in Sachen Optik und damit verbundener Funktionalität unterscheiden sich Graphite und Grafana erheblich. Grafana ist deutlich umfangreicher als das Webinterface von Graphite (Abbildung 1). Es wirkt auch moderner, wobei das freilich auch eine Geschmacksfrage ist. Unstrittig ist, dass Grafana deutliche Vorteile gegenüber Graphite besonders dann bietet, wenn der Admin Daten aus mehreren Quellen unter einer zentralen Oberfläche darstellen will.
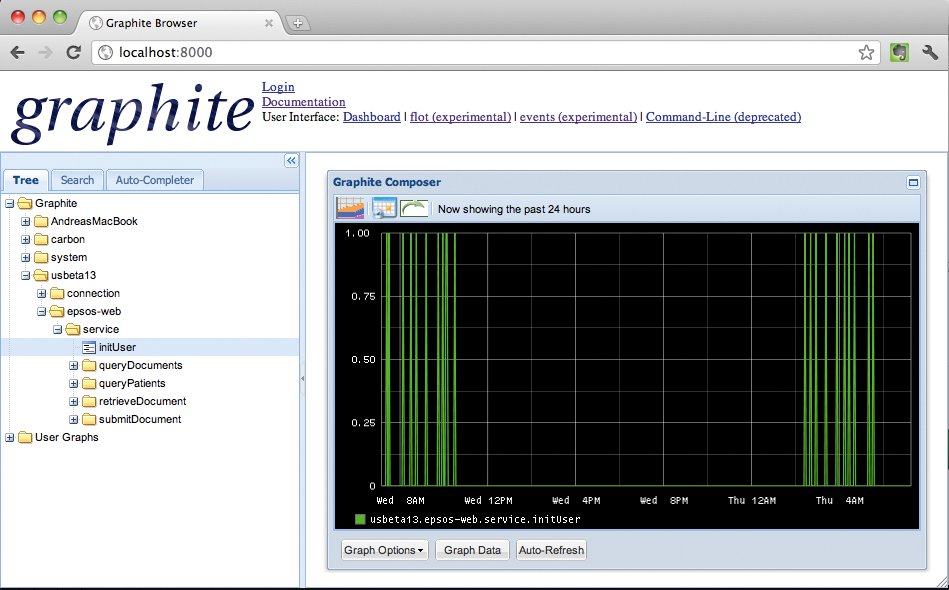
Abbildung 1: Die optische Erscheinung von Graphite ist der von Grafana unterlegen.
Grafana bietet diese Möglichkeit, indem der Admin einfach mehrere Datenquellen konfiguriert und entsprechende Dashboards baut. Graphite hingegen kann nur die Liste der Werte ausgeben, die es in der eigenen Whisper-Datenbank findet. Eigene Queries oder das Definieren spezieller Views sind in Graphite gleichfalls nicht möglich. De facto ist Grafana also nicht nur ein Drop-in-Ersatz für das Webinterface von Graphite. Es bietet deutlich mehr Funktionen und ist universeller nutzbar.
Graphite selbst ist ohne eine angeschlossene Monitoringlösung, die Daten liefert, ziemlich nutzlos: In der Regel kombinieren Admins deshalb Grafana mit Sensu ([4], Abbildung 2). Sensu ist eine komplette Monitoringumgebung neuer Spielart, die Graphite als Ablageort für die eigenen Nutzdaten verwendet. Wer auf der Suche nach einer modernen Nagios-Alternative ist, landet oft auch deshalb bei Sensu, weil es die von Nagios bekannten Checks wiederverwenden kann – es ist mit Nagios kompatibel.
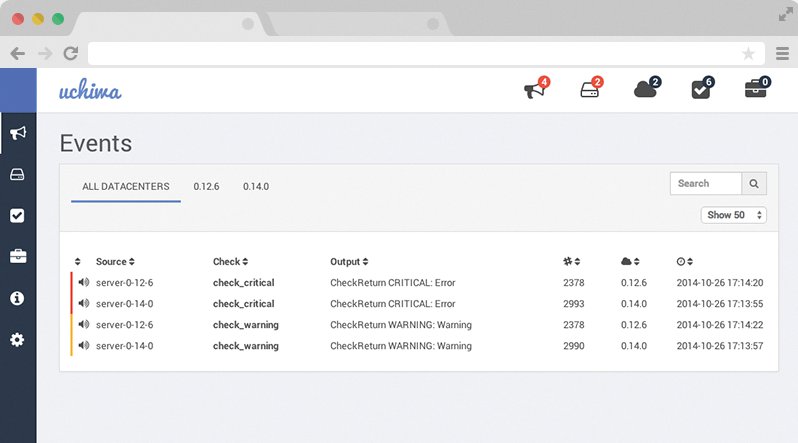
Abbildung 2: Sensu, hier mit seinem grafischen Frontend Uchiwa, setzt auf einer Zeitreihen-Datenbank wie Graphite oder Influx DB auf und bietet Monitoring .
In der Kombination mit Grafana sowie Sensu kommt Graphite im Wesentlichen die Aufgabe des Datenspeichers zu. Für diese Aufgabe ist es geeignet – auf das Graphite-Webinterface ließe sich beim Einsatz von Grafana (Abbildung 3) genauso gut verzichten.

Abbildung 3: Grafana ermöglicht es dem Admin, sich sein Dashboard so zusammenzustellen, wie er es wünscht.
Influx DB
Wer genau dies tun möchte – nämlich auf Graphite verzichten – findet in Form von Influx DB eine mögliche Alternative. Sie ist ebenfalls eine echte Time Series Database, die im Hinblick auf sehr ähnliche Anforderungen wie bei Graphite entwickelt worden ist. Die Produkte sind dennoch eigenständig und haben, von einzelnen Designprinzipien abgesehen, wenig miteinander gemein. Es ist im Grunde müßig, die Vor- und Nachteile der beiden Lösungen gegeneinander aufzuwiegen: Naturgemäß behaupten beide Probanden, dass sie das eine Quäntchen Performance mehr liefern, als die jeweils andere Lösung.
Das jedoch dürfte nicht zuletzt auch vom Usecase abhängen: Wer es denn wirklich wissen will, der sollte beide Produkte im direkten Vergleich gegeneinander antreten zu lassen und dabei realistische Testszenarien durchspielen. An dieser Stelle soll deshalb die Feststellung genügen, dass auch Influx DB nur in der Kombination mit Sensu sinnvoll funktioniert, weil Sensu auch dort als Lieferant für die begehrten Metrikdaten fungiert.
Die Anbindung an Influx DB bei Grafana ist qualitativ mit der Graphite-Anbindung absolut vergleichbar. Am Ende geht es also tatsächlich um den spezifischen Einzelfall und nicht zuletzt auch um die Vorlieben des Admin.
Elasticsearch
Ein wunderbares Beispiel, dass Grafana sich auch mit anderen Programmen als Monitoringtool verwenden lässt, ist die Anbindung an Elasticsearch. Was auf den ersten Blick etwas unsinnig wirkt, ergibt bei genauerem Hinsehen durchaus Sinn: Verschiedene Werkzeuge – besonders zur Performance-Messung – nutzen Elasticsearch nämlich, um ihre Ergebnisse zu speichern. Felix Barnsteiner, der die Java-Performance-Applikation Stagemonitor [5] verantwortet, hat folgerichtig die Integration von Grafana und Elasticsearch vorangetrieben: Stagemonitor legt seine Messwerte in Elasticsearch ab. Mit dem nun vorhandenen Interface von Grafana hin zu Elasticsearch lassen sich diese Werte gut grafisch darstellen. In diesem Sinne ist Elasticsearch dann eben doch eine Time Series Database.
Open TSDB
In einem Artikel, der sich (auch) um Zeitreihen-Datenbanken dreht, darf eine Lösung nicht fehlen: Open TSDB. Bei ihr geht es gar nicht so sehr um das Thema Monitoring wie etwa bei Graphite oder Influx DB. Open TSDB bezieht sich in der Selbstbeschreibung auch nicht explizit auf Trending. Eher sieht die Lösung sich als verteilten Datenspeicher, der mit besonders großen Mengen von Zeitreihen zurechtkommt. Den entsprechenden Use Case möge sich der jeweilige Admin bitte selbst ausdenken.
Dass der unter diesen Umständen bei Open TSDB landet, darf allerdings bezweifelt werden: Aus Nutzersicht ist die Lösung zwar einfach einzusetzen. Aus Admin-Sicht impliziert sie allerdings einen laufenden Hadoop-Cluster, weil Open TSDB Hadoop als Datenspeicher im Hintergrund nutzt. Mal eben lässt sich dieses Setup also nicht bauen. Wer allerdings einen laufenden Open-TSDB-Cluster mit entsprechenden Nutzdaten hat, kann Grafana über das entsprechende Plugin hinzufügen.
Amazons Cloudwatch
Amazon bietet für seine AWS-Umgebung einen eigenen Metrikdienst, der auch eine Time Series Database ist. Für Grafana existiert ein Plugin, das Daten aus Cloudwatch auslesen und optisch aufbereitet darstellen kann.
Damit zeigt Grafana, dass es auch für hybride Workloads geeignet ist: Mit einem Klick ist es dem Admin etwa möglich, aktuelle Lastdaten sowohl für eine private als auch für seinen Teil einer öffentlichen Cloud zu sehen.
Prometheus
Ein Paradebeispiel für die vollständige Integration einer MAT-Lösung in Grafana ist Prometheus. Der Feuerbringer war bereits Thema des Artikels eben und in einem früheren Linux-Magazin [6]. Zur Erinnerung: Prometheus ist eine Monitoringlösung, deren Kern eine Time Series Database ist. Das Projekt ist bei der Firma Soundcloud entstanden, um große und schnell wachsende Rechnerfarmen effektiv zu überwachen. Das umfasst sowohl die Möglichkeit, Ausfälle sehr schnell zu bemerken, als auch, das Setup und seine Skalierung langfristig zu planen.
Im Gegensatz zu den bereits vorgestellten Lösungen wie Graphite, Open TSDB oder Influx DB liegt bei Prometheus laut Aussage seiner Entwickler ein Schwerpunkt beim Thema Performance: Der Prometheus-Server selbst nutzt ein eigenes Format, um seine Daten auf der Platte abzulegen und indiziert die dort mittels des Level-DB-Formats.
In Summe soll Prometheus für eben diesen Einsatzzweck viel besser geeignet sein als seine Konkurrenten. Fakt ist, dass von den benannten Backends für Grafana Prometheus die einzige vollständige Monitoringlösung ist: In allen anderen Fällen ist die Time Series Database wie beschrieben nur das Backend, in dem eine andere Lösung wie Sensu ihre Daten ablegt.
In Sachen Funktionalität zeigt sich Prometheus auf der Höhe der Zeit: Seiner sehr modularen Architektur verdankt es eine große Flexibilität. Der Node Exporter ist dafür ein gutes Beispiel: Er läuft auf den einzelnen Hosts und führt dort Tests durch, deren Resultate er aufzeichnet. Anschließend holt sich der zentrale Prometheus-Server die Resultate der Node Exporter auf allen Hosts ab und speichert die Information entsprechend.
Dass Prometheus für große und sehr elastische Umgebungen konzipiert ist, wird an vielen Stellen deutlich. So hat Prometheus etwa eine direkte Schnittstelle zu Etcd, einem Daemon, der Buch über alle existierenden Knoten des Clusters führt. Sobald der Admin einen neuen Server zum Cluster hinzufügt, erfährt über den Umweg Etcd auch Prometheus automatisch davon. Wenn die Automatisierung funktioniert und auf dem jeweiligen Server automatisch einen Node Exporter ausrollt, genügt so bereits die Installation des neuen Servers, um ihn in das vorhandene Monitoring zu integrieren.
Zu der Zeit, aus der der Prometheus-Artikel stammt, gab es für Prometheus noch eine eigene grafische Oberfläche direkt von dessen Entwicklern: Promdash (Abbildung 4). Promdash stand in vielerlei Hinsicht in Konkurrenz zu Grafana – war diesem aber in fast allen Belangen deutlich unterlegen. So kam, was kommen musste: Zunächst veröffentlichte Grafana noch ein Plugin für den Zugriff auf Prometheus-Daten, aber kurz darauf verkündete Prometheus bereits, dass man die Arbeit an Promdash einstellt (Abbildung 5).
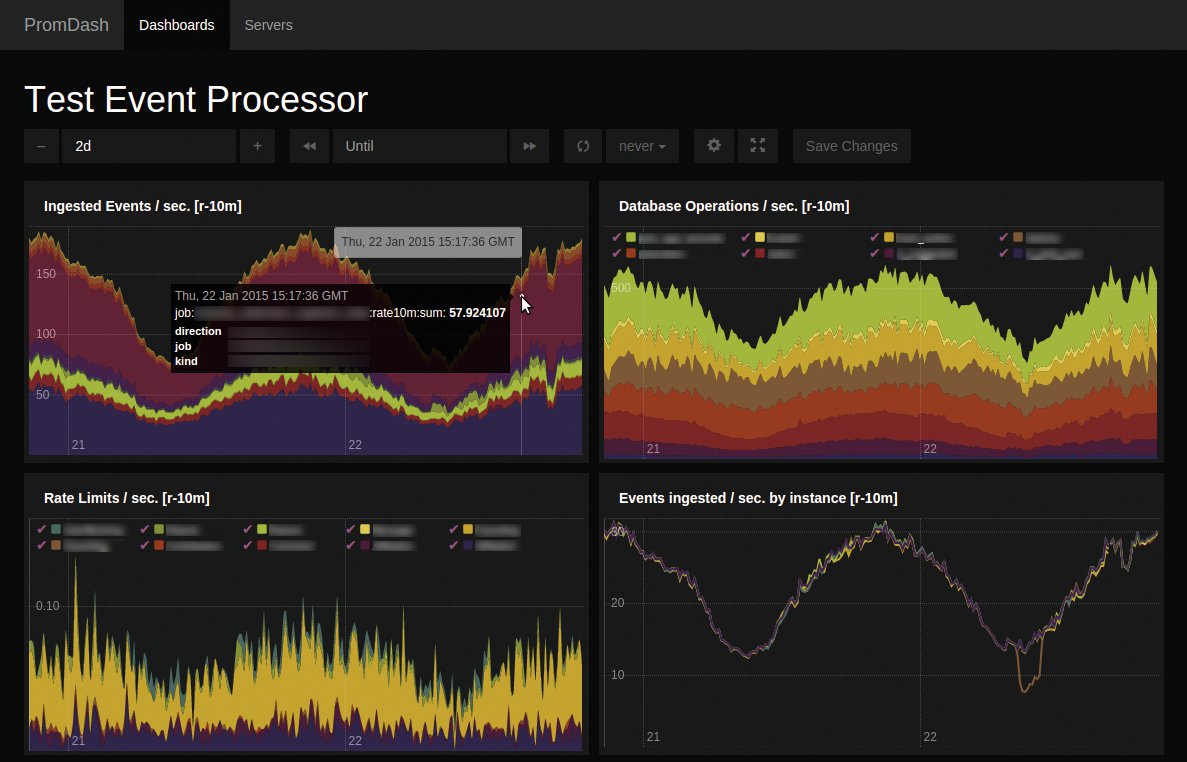
Abbildung 4: Ursprünglich entwickelte Soundcloud für Prometheus ein eigenes GUI namens Promdash. Damit ist nun Schluss, denn …
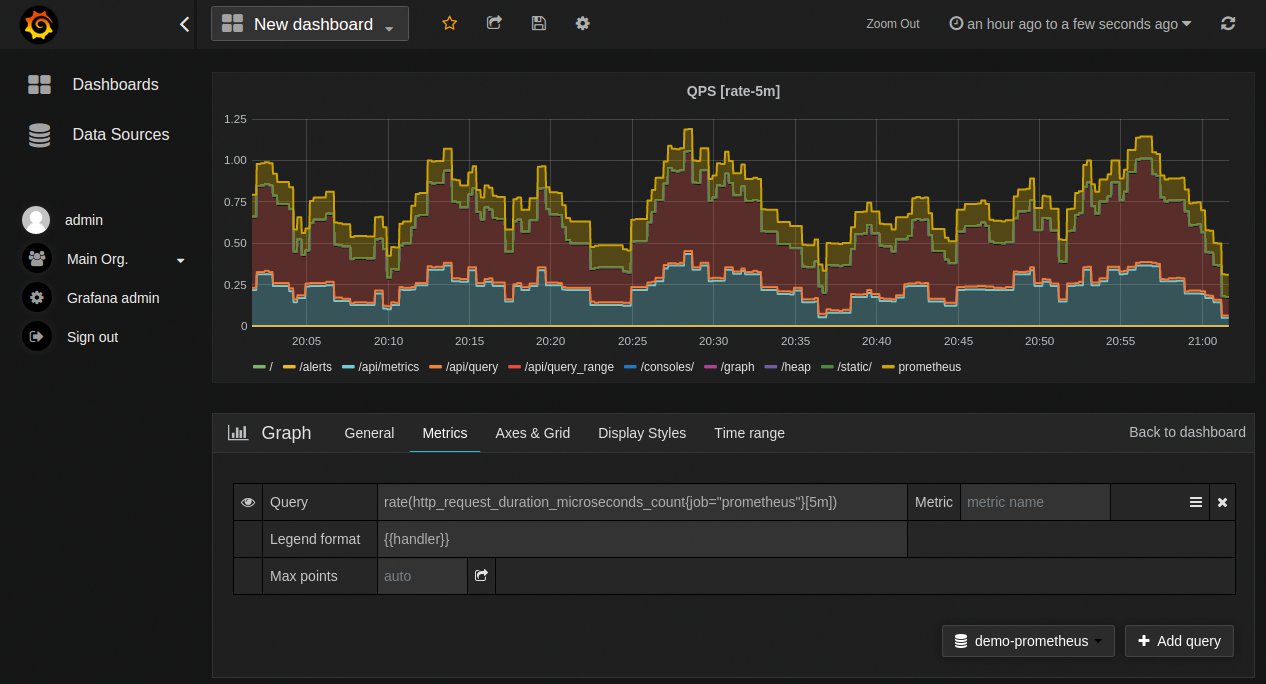
Abbildung 5: … mittlerweile ist Promdash offiziell tot und die Entwickler von Prometheus empfehlen, Grafana zu nutzen.
Weil die Grafana-Entwickler das Storage-Backend für ihre Metrikdaten von Grund auf neu geschrieben haben, haben sie auch die Gunst der Stunde für die Entwicklung einer eigenen Abfragesprache genutzt: Prom QL.
Grafana macht von Prometheus’ eigener Query-Sprache guten Gebrauch: Hat der Admin einen Prometheus-Server in Grafana erst mal als Datenquelle eingerichtet, kann er im Anschluss beliebige Prom-QL-Queries konfigurieren, um Grafiken in Grafana zu generieren. In Summe stellt sich das Gespann aus Grafana und Prometheus daher als äußerst potent heraus: Wer auf der Suche nach echtem MAT ist, sollte sich diese Kombination definitiv genauer ansehen.
Gnocchi
Auch für Open-Stack-Admins bietet Grafana echten Mehrwert: Gnocchi [7], die vom Open-Stack-Projekt selbst entwickelte Datenbank für dessen Metering-Dienst, ist in Grafana nämlich ebenfalls als Datenquelle konfigurierbar. Zur Erinnerung: Ceilometer, das in Open Stack eigentlich nur das Metering erledigen sollte, hat in Open Stack sehr lange eine stiefmütterliche Behandlung erfahren. Das hatte maßgeblich auch damit zu tun, dass die ersten Ceilometer-Versionen noch MySQL als Storage-Backend erwarteten. Metering-Daten aus Open Stack umfassen Werte wie die Zahl der laufenden VMs pro Kunde, die Zahl angelegter virtueller Netze oder den gesamten Speicherverbrauch aller Volumes eines Kunden. Für MySQL ist die Workload also gerade nicht geeignet. Entsprechend viele Ressourcen verleibte Ceilometer sich ein und entsprechend unbeliebt war es bei Admins im Open-Stack-Umfeld.
Gnocchi ist der Versuch, diese Probleme in den Griff zu kriegen: Es handelt sich um eine Time Series Database, die speziell für Daten aus dem Metering- und Billing-Kontext konzipiert ist. Gnocchi übernimmt in diesem Konstrukt die Rolle der Storage Engine und Ceilometer befüllt diese mit den ermittelten Nutzdaten. Das Ceilometer-Backend in Grafana erlaubt es, verschiedene Werte aus Gnocchi auszulesen und optisch aufbereitet anzuzeigen.
Nota bene: Grafana macht aus Ceilometer und Gnocchi keinesfalls eine komplette Billing-Lösung. Wer die Daten aus Gnocchi zu Verrechnungszwecken nutzen will, benötigt noch immer eine Integration von Gnocchi in sein Verrechnungssystem. Die Stärke der Kombination aus Grafana und Gnocchi liegt darin, dass die Workloads einzelner Projekte visualisierbar werden. Daraus lässt sich eine Prognose herleiten, wann die nächste Ausbaustufe ins Haus steht. Wenn entsprechende Daten von allen Projekten verfügbar sind, geht das noch besser.
Hinzu kommt im Open-Stack-Kontext, dass Grafana auch hier die einzige gute Möglichkeit schafft, die Daten aus Gnocchi überhaupt irgendwie optisch so darzustellen, dass sich aus ihnen schnell Rückschlüsse ziehen lassen. Admins von Open-Stack-Clouds sollten sich Grafana ruhig genauer anschauen. Schaden kann das jedenfalls nicht.
Fazit
Das Fazit zu Grafana und seinen Backends fällt kurz aus: Die Lösung lässt sich unkompliziert und schnell installieren, ist leicht zu warten und bietet im Alltag echten Mehrwert. Wer eine Time Series Database bereits betreibt oder das bald tun wird, sollte sich mit Grafana frühzeitig beschäftigen und die von der Software gebotenen Funktionen ausprobieren. Im Admin-Alltag und beim Umgang mit Zeitreihen ist Grafana jedenfalls ausgesprochen nützlich.
Infos
-
Grafana: https://grafana.com
-
PNP4Nagios: https://docs.pnp4nagios.org
-
Graphite: https://graphiteapp.org
-
Sensu: https://sensuapp.org
-
Stagemonitor: http://www.stagemonitor.org
-
Martin Loschwitz, “Prometheus für das Cloud Monitoring”: Linux-Magazin 03/16, S. 62, https://www.linux-magazin.de/Ausgaben/2016/03/Prometheus
Der Autor

Martin Gerhard Loschwitz ist Head of Cloud bei der Firma iNNOVO Cloud. Er beschäftigt sich dort bevorzugt mit den Themen Distributed Storage, Software Defined Networking und Open Stack.






