
© alphaspirit, 123RF
Auch in einem kleinen Büro trudeln täglich zahllose Briefe, E-Mails und PDFs ein. Um nicht in der Flut an Dokumenten zu ertrinken, macht sich der Einsatz von Dokumentenmanagement-Systemen bezahlt.
Seit mehr als zehn Jahren proklamiert die Industrie mittlerweile das papierlose Büro, helfen dabei sollen unter anderem spezielle Dokumentenmanagement-Systeme (DMS). Diese versprechen, beliebige Schriftstücke ohne meterlange Aktenregale zu verwalten, arbeiten meist als Client-Server-Anwendungen und ihre Nutzer greifen mit Hilfe eines Datenbank-Backends darauf zu.
Doch die meisten dieser DMS-Applikationen sind in mittleren und großen Unternehmen zu Hause und für den Einsatz in kleinen Heimbüros hoffnungslos überdimensioniert. Noch schwieriger wird es, wenn Linux-Support auf der Anforderungsliste steht. Dennoch macht sich die aktuelle Bitparade auf die Suche nach DMS-Systemen für Linux-Arbeitsplätze, die ohne zeitaufwändige Einarbeitung und permanente Wartung auch das Ein-Mann-Büro entlasten.
Anforderungen
Im Idealfall soll das DMS-System den Weg eines Dokuments von seiner Entstehung über seinen gesamten Lebenszyklus bis hin zur Vernichtung abbilden. Dabei geht es längst nicht mehr nur um gedruckte Dokumente, sondern ebenso um Dateien, die in unterschiedlichen Formaten elektronisch vorliegen, also beispielsweise als E-Mails.
Das DMS-System dient dabei nicht nur als Archivierungssystem, das mit Hilfe von Schlagwörtern oder auch über Datumsstempel oder anderer Attribute den schnellen Zugriff auf die Archive ermöglicht. Es soll auch den Informationsfluss in Organisationen optimieren, indem es Verteilungsmechanismen für berechtigte Empfänger einführt, Dokumente verknüpft oder Zugriffe überwacht.
Nicht getestet
Als fünfter Kandidat für den Test war das in Spanien entwickelte Open KM [16] vorgesehen. Das gibt es ebenfalls in einer Linux-Variante und es verfügt neben kommerziellen und Cloudpaketen über eine Community-Version. Im Test erwies sich die Software jedoch als extrem störrisch: So fehlen für Kleinbüros und weniger versierte Admins brauchbare Installationsroutinen, auch gibt es keine aktuelle Dokumentation. Vielmehr muss der Admin die benötigten Pakete (unter anderem einen Tomcat-Applikationsserver, eine MySQL-Datenbank und Anwendungen wie Imagemagick oder Ghostscript) alle einzeln und gesondert manuell installieren. Dann muss er teils komplexe Konfigurationsdateien händisch anpassen.
Zwar stellt der Hersteller Hilfe-Dokumente bereit, die sind jedoch hoffnungslos veraltet und lassen die Installation auf aktuellen Linux-Distributionen scheitern. Die geforderten Pakete bieten aktuelle Linux-Versionen zudem teilweise nicht mehr an. Für Fedora und Red Hat Linux verweist die Doku etwa auf das Open-Office-Paket 3.1.1, das vom 31. August 2009 stammt und inzwischen unzählige neue Releases gesehen hat.
Auch die für Debian und Ubuntu vorhandene Dokumentation ist überholt: Sie beschreibt die Konfigurationen für das inzwischen längst abgelöste Sys-V-Initsystem, spart aber den Umgang mit den Service-Units des aktuellen Systemd-Sitzungsmanagers aus. Auch die Apache-Webserver-Konfiguration funktioniert nicht mehr so, wie einst beschrieben. Gründe genug also, von einer Open-KM-Aufnahme in den Test abzusehen.
Ein modularer Aufbau soll zudem das problemlose Weiterverarbeiten von Dokumenten in Anwendungen Dritter ermöglichen, zu denen etwa gängige Office-Suiten oder ECM-Systeme (Enterprise Content Management) gehören.
Immer wichtiger wird zudem die Multiplattform-Fähigkeit, die den Einsatz der Clients auf mobilen Geräten wie Tablets gestattet. Dazu zählen heute auch Cloud-Anbindungen, um unabhängig von einer stationären IT auf die Dokumente im DMS zuzugreifen. Nicht zuletzt sind in Deutschland, Österreich und der Schweiz außerdem gesetzliche Vorgaben zur Archivierung zu erfüllen.
Im Kleinbüro
Kleine Büros benötigen in der Regel keine großen DMS-Systeme. Die sind meist schwierig zu installieren und zu konfigurieren und bedürfen obendrein regelmäßiger Wartung. Doch auch Alternativen für kleine Büros sollen Eingangsquellen wie etwa gedruckte Dokumente, Dateien verschiedener Formate und gespeicherte E-Mails problemlos verarbeiten. Dazu bringen sie im Idealfall auch ein Scanmodul mit, welches das Einlesen und die Texterkennung von gedruckten Vorlagen ermöglicht. Das Verschlagworten und andere Ablagefunktionen gehören ebenso zur Domäne von DMS-Systemen. Ergänzend sollte es Schnittstellen für die wichtigsten Office-Suiten geben (siehe auch Tabelle 1).
|
Krystal DMS |
Logical Doc |
Paperwork |
Referencer |
|
|---|---|---|---|---|
|
Modular aufgebaut |
ja |
ja |
ja |
nein |
|
Deutsche Lokalisierung |
nein |
ja |
ja |
ja |
|
Client-Server-Architektur |
ja |
ja |
nein |
nein |
|
Webbasierte Oberfläche |
ja |
ja |
nein |
nein |
|
Scanmodul |
ja* |
ja* |
ja |
nein |
|
Mehrblattscan |
ja* |
ja* |
ja |
nein |
|
OCR-Modul |
ja (extern) |
ja (extern) |
ja |
nein |
|
Importfunktion |
ja |
ja |
ja |
ja |
|
Exportfunktion |
ja* |
ja |
ja |
ja (extern) |
|
Viewer |
ja |
ja |
ja |
nein |
|
Indexierung und Suche |
ja |
ja |
ja |
ja |
|
Versionshistorie |
ja |
ja |
nein |
nein |
|
Kommentare |
nein |
ja |
nein |
ja |
|
Cloudanbindung |
nein |
ja |
nein |
nein |
|
Mobile Apps |
ja |
ja |
nein |
nein |
|
Anbindung an CMS-Systeme |
nein |
ja |
nein |
nein |
|
* Nur in den kommerziellen Versionen verfügbar. |
Weniger relevant sind bei kleinen DMS-Lösungen hingegen ausgeklügelte Mechanismen zur Rechtevergabe und Module zur Interaktion mit ERP- und ECM-Boliden. Auch die Option, mit einer App von einem Mobilsystem wie einem Tablet oder Smartphone aus auf die DMS-Software zuzugreifen, ist in diesem Arbeitsumfeld nachrangig. Als wichtiger erweist sich im Leistungskatalog einer Lösung für kleine Büros und Einzelarbeitsplätze indes eine einfache Installation und Konfiguration der Software.
Problemfeld OCR
Nach wie vor problematisch gestaltet sich unter Linux die zuverlässige Texterkennung eingescannter Vorlagen. Mangels eigener Texterkennungs-Module in den DMS-Applikationen ist der Anwender in vielen Fällen gezwungen auf Drittlösungen zurückzugreifen. Im Test des Linux-Magazins entpuppte sich dabei das OCR-Duo aus Tesseract und G-Imagereader als technologisch ausgereift und daher gut brauchbar (siehe Kasten “Tesseract und G-Imagereader”).
Tesseract und G-Imagereader
Der US-amerikanische Computerhersteller Hewlett-Packard arbeitete zwischen 1985 und 1995 an der Erkennungs-Engine Tesseract [1]. Zehn Jahre lang lag die Entwicklung dann brach, weil HP das Marktsegment aufgegeben hatte. 2005 übernahm Google die Software und stellte diese nach einer Coderevision als freie Software unter der Apache-Lizenz der Entwicklergemeinde zur Verfügung. So verbreitete sich Tesseract im Linux-Universum und erkennt heute mit den entsprechenden Modulen sogar deutsche Frakturschriften. Dank des modularen Aufbaus ist es zudem multilingual. Auch Fremdsprachen mit vielen Sonderzeichen stellen die Software nicht vor unlösbare Probleme.
Da die Texterkennungs-Engines in aller Regel reine Kommandozeilen-Applikationen sind, entwickelten Dritte im Laufe der Jahre verschiedene grafische Oberflächen, um die Programme einfach bedienen zu können. Die GUI-Umgebungen decken dabei vielfach eine oder mehrere spezielle Engines ab.
Als relativ unbekanntes Frontend zur Texterkennung für Tesseract hat sich der G-Imagereader [2] etabliert. Er schreibt sich neben einer einfachen Bedienung vor allem ein schlankes Design auf die Fahnen und bringt daher keinen unnötigen Schnickschnack mit. Beide Softwarepakete stecken in den Software-Repositories aller größeren gängigen Linux-Distributionen. Sie lassen sich so bequem per Mausklick in das jeweilige System integrieren. Anschließend reicht es, das grafische Frontend aufzurufen, das die OCR-Engine im Hintergrund automatisch startet. Danach lesen User Vorlagen ein und lassen diese erkennen (Abbildung 1).

Abbildung 1: Für das Digitalisieren gedruckter Vorlagen eignet sich Tesseract am besten.
Krystal DMS
Die indische Firma Primeleaf Consulting vertreibt das von ihr entwickelte Krystal DMS [3] in vier kommerziellen Varianten. Daneben gibt es eine Community-Edition, die im Vergleich zu den kommerziellen Versionen funktionale Einschränkungen aufweist und für die die Firma auch keinen Support leistet.
Die Community-Variante verwaltet Dokumente bis zu einer Größe von 512 MByte und eignet sich eher als Testplattform. Die Client-Server-Applikation mit Datenbank-Backend lässt sich über ein Web-UI nutzen. Das Backend gehört zur Community-Variante, so brauchen User keine zusätzliche Datenbank.
Zwar ist Krystal DMS für das nicht mehr taufrische Red Hat Enterprise Linux in Version 5.x zertifiziert, arbeitet aber auch unter aktuellen Distributionen problemlos. Da es in Java geschrieben ist, muss der Anwender auf den Clients eine Java-Laufzeitumgebung installieren und einen Browser mit Java-Plugin verwenden. Der Download [4] der Community-Edition für Linux setzt eine Registrierung auf der Webseite des Herstellers voraus.
Vertriebsmodell
Bei den vier kommerziellen Varianten [5] richtet sich der Preis nach der Anzahl der jeweiligen Anwender. Allen Varianten gemeinsam ist das Subskriptionsmodell von jeweils einem Jahr Dauer, das kostenfreien E-Mail- und Telefonsupport beinhaltet. In diesem Zeitraum sind auch alle Updates kostenlos. Die Preise inklusive Mehrwertsteuer reichen dabei von etwa 340 Euro für einen Anwender der Xpress-Variante bis hin zu umgerechnet etwa 900 Euro für fünf Clients.
Die für mittlere und große Büros gedachte Enterprise-Variante schlägt bei fünf Anwendern mit rund 9800 Euro zu Buche und erreicht bei 100 Nutzern einen Subskriptionspreis von zirka 44800 Euro jährlich. Dabei handelt es sich durchweg um Preise für On-Premise-Installationen im Intranet des Anwenders.
Alternativ dazu bietet Primeleaf ab der Standard-Edition auch eine gehostete Cloudlösung an, die Büros auf monatlicher oder jährlicher Basis abrechnen, wobei sich die Preise ebenfalls an der Anzahl der Anwender orientieren.
Erster Eindruck
Nach dem Download und Entpacken des knapp 17 MByte umfassenden Tar.gz-Archivs wechselt der Nutzer in das neu angelegte Unterverzeichnis »krystalce«. Dort macht er das Skript »krystaldms.sh« mit Rootrechten und dem Befehl »chmod +x krystaldms.sh« ausführbar. Anschließend startet er das DMS-System einfach über »./krystaldms.sh«.
Die erfolgreiche Aktivierung meldet das Shellskript durch eine kurze Statusangabe im Terminal. Gleichzeitig aktiviert dieser Schritt das interne Datenbank-Backend und den eingebauten Webserver. Nun lässt sich das Dokumentenmanagement-Programm über jeden Java-fähigen Webbrowser im Intranet erreichen. Der User gibt dazu die URL »http://IP-Hostadresse:8080« ein und tippt ins sich öffnende Login-Fenster »ADMINISTRATOR« als Benutzername und als Passwort »admin«. Dann erscheint der Arbeitsbereich (Abbildung 2).
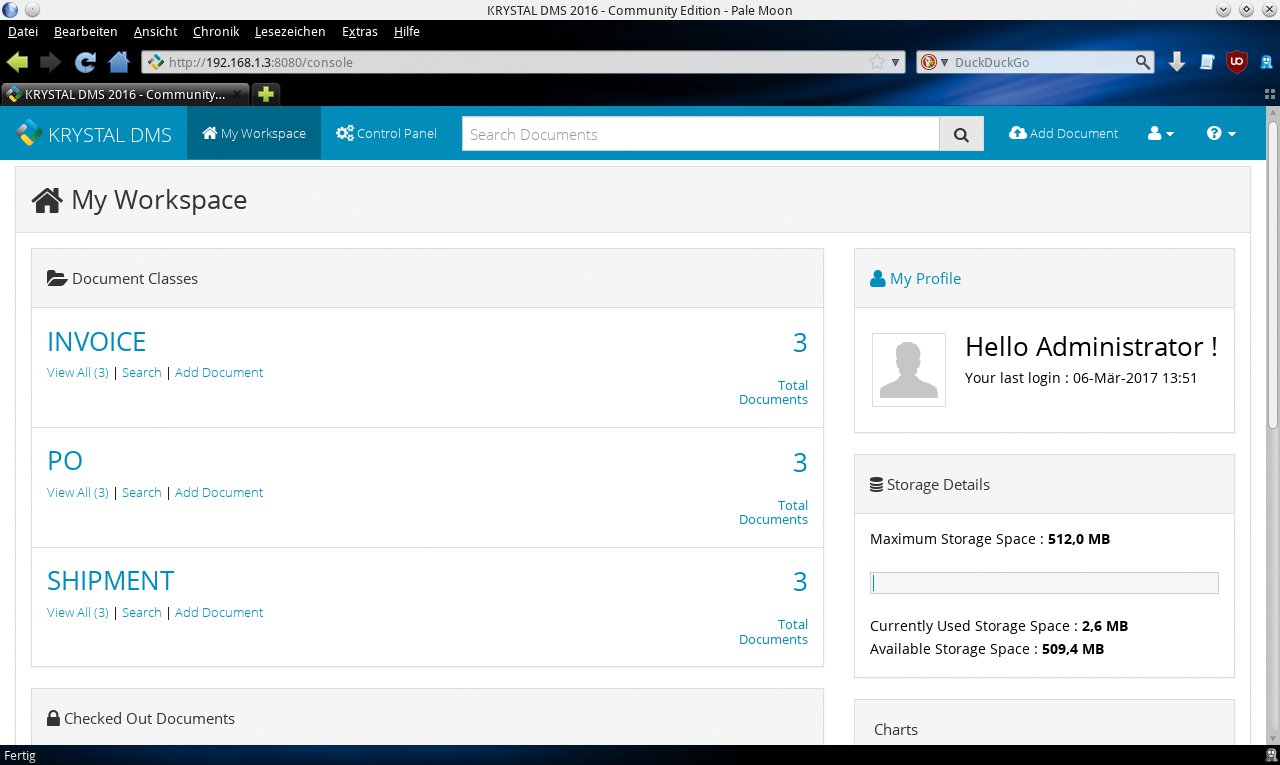
Abbildung 2: Die Weboberfläche von Krystal DMS wirkt übersichtlich.
Vor Beginn des produktiven Einsatzes sollte der Anwender zunächst einige Konfigurationen vornehmen. Da das indische DMS-System mit Beispieldaten im Gepäck kommt, veranschaulichen diese gut die Bedienung.
Über den Button »Control Panel« oben links im Browserfenster erreicht der Nutzer alle nötigen Einstelloptionen. Leider ist das Programm nicht in deutscher Sprache lokalisiert, was sich im Test aufgrund der einfachen Bedienung aber nicht als wirkliches Manko erwies.
Das Control Panel stellt in den Optionsfenstern »Manage Users« und »Manage Document Classes« die wichtigsten Einstellungen bereit. Während die Anlage eines oder mehrerer User obligatorisch ist und der Verwalter dies im Dialog »Add User« erledigt, bezeichnen »Document Classes« verschiedene Dokumentgruppen. Die lassen sich mit einzelnen Ordnern vergleichen, welche die Dokumente einer Gruppe zusammenfassen.
Die vorhandenen drei Dokumentklassen kann der Anwender löschen und durch eigene ersetzen. Neue Dokumentklassen fügt er mit Hilfe eines Dialogs hinzu, den er über die Schaltfläche »Add Document Class« öffnet.
Anschließend taucht die Klasse zwar im Control Panel auf, jedoch noch nicht auf der Arbeitsfläche. Dazu muss er über den Button »Manage Permissions« unter der Dokumentklasse im Control Panel Anwender-spezifische Rechte vergeben. Hat er diese per Klick auf »Submit« aktiviert, erscheint die neue Dokumentenklasse auch im Arbeitsbereich.
Über die Schaltfläche »Add Document« unterhalb der Klasse ergänzt der Anwender nun in einem übersichtlichen Dialog Dokumente. Die lassen sich anschließend im Arbeitsbereich über die entsprechende Dokumentenklasse aufrufen und tauchen in einer tabellarischen Übersicht auf.
Ansichtssache
Krystal DMS bietet es auch an, Dokumente anzusehen. Dazu ist ein Viewer in die Software integriert. Klickt der Anwender rechts in der tabellarischen Ansicht auf »View Document«, erscheint das Dokument in einem gesonderten Fenster. Leider taugt die Formatunterstützung des Viewers wenig: Die Community-Variante zeigt lediglich PDF-Dokumente und einige Bildformate, etwa PNG-Dateien, an. Einfache Textdateien oder gar Dokumente im ODF- oder einem der Microsoft-Formate präsentiert der Viewer in der Community- und den preiswerteren Krystal-Versionen nicht.
Will der Anwender ein solches Dokument betrachten, wirft das DMS-System eine Fehlermeldung und er muss die betreffende Datei erst herunterladen. Dateien, die im ODF-Format (Libre Office, Open Office) vorliegen, öffnet erst die Premium-Edition von Krystal im integrierten Viewer (Abbildung 3).

Abbildung 3: Der Viewer in der freien Krystal-DMS-Version unterstützt nur sehr wenige Formate.
Workflow
Krystal DMS bietet beeindruckende Möglichkeiten, die weit über das Management kleinerer Dokumentenbestände hinausgehen: Es indiziert Dokumente und erfasst sie automatisch mit einem Scanner. Ein Texterkennungs-Modul ist eingebaut, auch Fremdsprachen unterstützt das Programm, und Dokumente lassen sich mit Verfallsdaten versehen, die manuelles Entfernen aus Datenbanken überflüssig machen. Diese Funktionen, ebenso wie ein Kalender und eine Aufgabenliste, stehen aber nur in den beiden Varianten Premium und Enterprise zur Wahl.
Die Community-Variante bringt jedoch essenzielle Funktionen wie die Verschlagwortung mit entsprechender Suche und das Hinterlegen von Notizen zu einzelnen Dokumenten mit. Diese nimmt der Nutzer in der Dokumentanzeige über die Reiter »Bookmark Document«, »Edit Indexes« und »Notes« vor. Daneben implementiert die Community-Variante eine Historie zu jedem Dokument, die über die letzten Arbeitsschritte an einer spezifischen Datei informiert.
Logical Doc
Als eines der am weitesten verbreiteten DMS-Systeme ist Logical Doc [6] fest am Markt etabliert. Die Software existiert als Client-Server-Anwendung in mehreren Varianten: Neben einer quelloffenen Community-Edition [7] sind eine Cloud- sowie eine Enterprise- und eine Business-Version als lokal zu installierende Pakete zu haben. Logical Doc setzt eine Java-Laufzeitumgebung voraus sowie ein Datenbank-Backend, wobei die Empfehlungen für Linux sowohl MySQL als auch PostgreSQL lauten.
Eine Testversion mit 30 Tagen Laufzeit und Support bietet die Webseite des Herstellers an. Der und seine Vertriebspartner veröffentlichen allerdings weder Preise noch Konditionen für den Kauf des Pakets. Subskriptionsmodelle mit eingeschlossenem Support und Updates richten sich jedoch wie in der Branche üblich nach der Anzahl der Anwender und gelten in der Regel für ein Jahr.
Installation
Logical Doc steht als Zip-Archiv bereit. Der Anwender erhält das derzeit rund 525 MByte große Archiv nach einer Registrierung auf der Webseite des Herstellers als Link zu einer Download-Seite. Hier sind auch Pakete für virtuelle Umgebungen erhältlich sowie verschiedene Add-ons für Dateibetrachter, Cloud-Uploads, Backuptools und die Integration eines FTP- oder Cifs-Servers.
Linux-Nutzer müssen im Vorfeld prüfen, ob ihre Installation auch eine Java-Umgebung ab Version 8 anbietet. Dies klappt unabhängig von der Distribution über den Kommandozeilenbefehl »java -version«. Logical Doc kooperiert sowohl mit der Open-JDK-Umgebung als auch mit dem Original-Java-Paket von Oracle. Zudem sollte auf dem System bereits ein aktiver MySQL-Server laufen.
Ubuntu-Nutzer müssen zudem darauf achten, das Logical-Doc-Paket mit Rootrechten zu installieren, was über die Eingabe des Befehls »sudo su« in einem Terminal gelingt. Danach rufen sie den Installer mit
java -jar logicaldoc-installer.jar
auf. Die Routine packt nun in 13 Schritten das Paket auf den Massenspeicher (Abbildung 4).
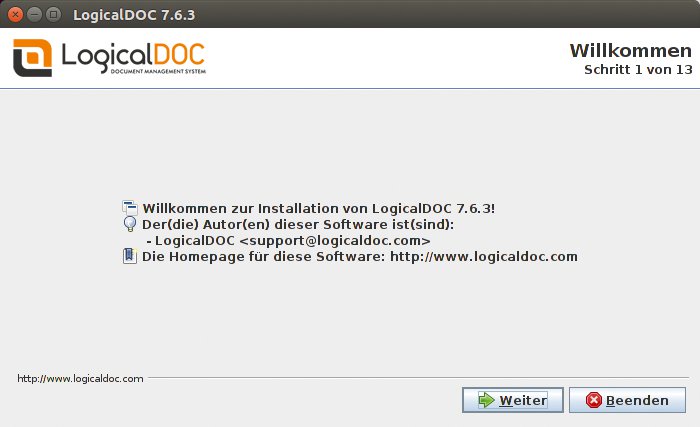
Abbildung 4: Der Installationsdialog von Logical Doc lässt sich trotz etlicher Schritte relativ schnell durchlaufen.
Auffallend ist, dass die Installationsroutine auch die Pfade zu Drittanwendungen abfragt, die als externe Programme Dokumente darstellen, Texte einlesen und Dateien konvertieren. Bei den hier verwendeten Applikationen handelt es sich ausschließlich um freie Software. Bei den meisten aktuellen Linux-Distributionen muss der Benutzer nur den Pfad zur Office-Suite anpassen, da Logical Doc hier noch Open Office erwartet und den Standard-Installationspfad zum Aufruf der Software anbietet.
In der Regel gilt es, an dieser Stelle den Pfad zum inzwischen bevorzugt verwendeten Libre Office einzutragen. Pakete wie Imagemagick, Tesseract, Ghostscript, Pdftohtml oder Open SSL installiert der Logical-Doc-Betreiber je nach Anwendungsszenario nach, um den vollen Funktionsumfang zu erhalten.
Oberflächliches
Auch Logical Doc nutzt den Webbrowser als Oberfläche. Zum Zugriff auf die Anwendung gibt der Nutzer in der Adresszeile »http://IP-Adresse-des-Servers:8080« ein, sofern er das DMS-System von einem anderen Rechner im Intranet aus aufruft. Am lokalen Rechner gelingt der Zugriff über »http://localhost:8080«.
Nach einem Warmstart des Rechners muss er hingegen zunächst den Logical-Doc-Server aktivieren, was im Terminal mit Rootrechten und dem Befehl »service logicaldoc start« geschieht. Im Login-Bildschirm des DMS-Systems authentifiziert sich der Benutzer beim ersten Mal über »admin:admin«. Außerdem legt er hier die Lokalisierung fest, Logical Doc spricht auch Deutsch. Anschließend öffnet sich ein übersichtliches Fenster mit drei großen Anzeigebereichen und zwei im linken Bereich horizontal angeordneten Reiterleisten.
Einstellungssache
Im nächsten Schritt legt der Admin Benutzer und Gruppen an. Dazu klickt er im Hauptfenster oben links auf den Reiter »Administration« und dann links auf den Button »Sicherheit«. Wählt er im Aufklappmenü die Schaltfläche »Benutzer« aus, erscheint rechts eine Liste der im System registrierten Anwender. Über den Button »Benutzer hinzufügen« legt er einen neuen User an (Abbildung 5). Diesem weist er zunächst die nötigen Rechte zu und steckt ihn dann in die passenden Gruppen.

Abbildung 5: Unter Logical Doc legt der Admin neue User in wenigen Schritten an.
Neue Gruppen legt der Administrator wiederum im gleichnamigen Menü an, wo er auch einzelne Anwender den Gruppen zuordnet. Welche Rechte die einzelnen Gruppen und Anwender besitzen, prüft und ändert er bei Bedarf, indem er links in der Baumansicht die aktuelle Dokumentengruppe anklickt und danach unten rechts den Reiter »Sicherheit« öffnet. In ihm setzt und entfernt er über Häkchen und sehr fein granuliert Gruppen- und Anwenderrechte. Die jeweils vergebenen Rechte vererbt der Anwender dabei ebenfalls, die Gruppenrechte gelten stets für alle Mitglieder einer Gruppe (Abbildung 6).
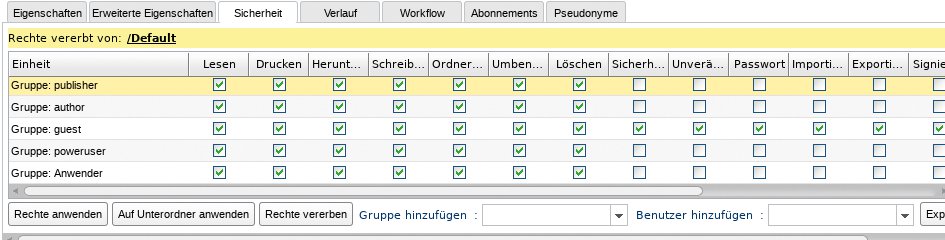
Abbildung 6: Logical Doc besitzt eine sehr fein justierbare Rechteverwaltung.
Danach lassen sich Dokumente importieren, einscannen und weiterverarbeiten. Dazu bietet das DMS-System im Reiter »Dokumente« in der oben mittig im Fenster angeordneten Buttonleiste Optionen. Auch komplette Ordner importiert der Nutzer hier.
Links im Fenster erscheinen in einer Baumansicht die Dokumentengruppen und darunter, hierarchisch geordnet, die ihnen bei Bedarf zugewiesenen Ordner. Klickt der Anwender mit der rechten Maustaste auf eine Dokumentengruppe oder einen Ordner, stehen ihm verschiedene Verwaltungsaufgaben zur Auswahl. Zum Beispiel legt er neue Ordner an. Zu diesen erscheint anschließend rechts im Bild eine leere Dokumententabelle, die sich nun füllen lässt. Dabei zeigen unten rechts mehrere Reiter unterschiedliche Eigenschaften zum momentan markierten Dokument an.
Wer suchet, der findet
Logical Doc bringt eine leistungsstarke Suchfunktion zum schnellen Auffinden von Dokumenten mit, die der Anwender über den Reiter »Suchen« links oben im Programmfenster verwendet. Eingelesene oder eingescannte Dokumente indiziert die Software dabei anhand interner Algorithmen automatisch.
Tippt der Logical-Doc-User in der Suchmaske links im Programmfenster einen Suchbegriff in das gleichnamige Eingabefeld ein und klickt dann auf das Lupensymbol rechts daneben, durchsucht das DMS-System den aktuellen Dokumentenbestand und listet tabellarisch die gefundenen Treffer auf. So genannte Scores zeigen als horizontale Balken auch die Relevanz des jeweiligen Dokuments für den Suchbegriff an.
Innerhalb der gefundenen Dokumente nimmt der Suchende auf Wunsch weitere Eingrenzungen vor. So stellt er eine tiefer gehende Suchanfrage, indem er die Option »Aktuelle Treffer durchsuchen« aktiviert und einen weiteren Suchbegriff eingibt. Rechts in der Tabelle zeigt das DMS-System dann nur noch jene Dokumente mit einem neuen Score-Balken an, auf die alle Suchbegriffe passen. Diese lassen sich per Rechtsklick in einem Kontextmenü betrachten oder weitergehend bearbeiten (Abbildung 7).

Abbildung 7: Die Suchfunktion von Logical Doc arbeitet dank ausgereifter Algorithmen sehr treffsicher.
Neben der Volltextsuche unterstützt Logical Doc Suchende mit weiteren Merkmalen: Tags dienen ebenso wie verschiedene Dokumenten-spezifische Parameter, zu denen etwa die Spracheinstellung gehört, als Suchparameter. Im Auswahldialog »Ordner« wendet der Betreiber die Suchfunktion zudem auf Ordnerstrukturen an. Zusätzlich speichert er wahlweise alle Suchkriterien, um bei wiederholter Suche nicht sämtliche Optionen neu eingeben zu müssen.
Dashboard
Das Dashboard von Logical Doc heißt in der deutschen Lokalisierung »Übersicht«. Hier erhält der Anwender einen Überblick seiner Aktivitäten, Informationen zu den genutzten Dokumenten sowie zum Workflow. Letzterer bezieht dabei Interaktionen mit anderen Anwendern im Intranet ein und verfügt auch über eine Kalenderfunktion und eine Aufgabenverwaltung.
Paperwork
Das unter der GPLv3 veröffentlichte DMS-Programm Paperwork [8] gibt es ausnahmsweise nur in einer Variante. Die in Python geschriebene Applikation ist modular aufgebaut und besitzt sowohl eine Scanner- als auch eine OCR-Anbindung, wobei diese Module ebenfalls auf freier Software aufsetzen. Paperwork versteht sich als Komplettlösung für das Digitalisieren, Verschlagworten und Archivieren von Dokumenten. Als Voraussetzungen verlangt das für den Einsatz an Einzelarbeitsplätzen konzipierte System einen Scanner, der mit Sane [9] kooperiert, und die Texterkennung Tesseract mit den entsprechenden Sprachmodulen.
Installation
Paperwork besitzt keine integrierte Installationsroutine und benötigt eine stattliche Anzahl an Zusatzpaketen. Abhängig von der Linux-Distribution verlangt es dem Admin mitunter einiges an Aufwand ab, Paperwork einsatzbereit zu machen. Zwar stellen die Entwickler für mehrere Linux-Derivate kurze Installationsanleitungen auf Github bereit, die sind jedoch teils veraltet und daher nicht unbedingt aussagekräftig. Unter einem frisch aufgesetzten Ubuntu 16.04 brachte das Linux-Magazin die Software in mehreren Schritten zum Laufen (siehe Kasten “Paperwork installieren”).
Paperwork installieren
Zunächst integriert der Admin für die Installation diverse Python-Pakete in das System:
sudo apt install python3-pip python3-setuptools python3-dev python3-pil libenchant-dev
Anschließend holt er Paperwork mit Hilfe der für Python-Module vorgesehenen Paketverwaltung Pip auf den Massenspeicher:
sudo pip3 install paperwork
Im Anschluss prüft der Installateur mit der Papework Shell, ob das Programm alle Abhängigkeiten erfüllen kann. Dabei helfen ihm die Befehle:
paperwork-shell chkdeps paperwork_backend paperwork-shell chkdeps paperwork
Sie ziehen auch noch nicht aufgelöste Abhängigkeiten nach und legen, je nach Desktopumgebung, einen Starter für Paperwork in den Menüs an.
Fehlt am Ende der Installation ein Starter für die Software, aktiviert der Nutzer sie im Terminal über die Eingabe von »paperwork«. Das ruft zügig ein zweigeteiltes Fenster auf. Im rechten Segment erscheinen eingescannte und aus Datenbeständen geladene Dokumente, im linken zu jedem Dokument spezifische Attribute, etwa Schlagwörter. Zunächst sollte der User aber bei eingeschaltetem Scanner den Einstellungsdialog aufrufen, auch wenn der nur ein paar grundlegende Optionen bietet (Abbildung 8).

Abbildung 8: Einstellungen zum Scanner nimmt der Anwender in einem eher übersichtlichen Fenster vor.
Das betrifft insbesondere die Auflösung des Scanners: Befinden sich im Vorlagen-Fundus viele Dokumente mit sehr kleinen Druckschriften, empfiehlt es sich, den voreingestellten Wert von 300 dpi zu erhöhen. Unter Umständen sollten Nutzer auch die eingestellte Sprache für die Texterkennung Tesseract im entsprechenden Auswahlfeld ändern.
Bedienung
Paperwork gestattet einen sehr flexiblen Umgang mit Dokumenten: Beim Einscannen erfasst es mit Hilfe eines automatischen Einzugs auch komplette Vorlagenstapel. Dazu klickt der Anwender lediglich auf den »Scannen«-Button oben rechts im Programmfenster. Paperwork zeigt daraufhin jede Seite animiert im rechten Bereich des Fensters an. Im Hintergrund führt Tesseract da bereits die OCR-Erkennung aus – sofern der Nutzer diese zuvor aktiviert hat.
Der linke Fensterbereich zeigt verkleinerte Abbildungen der ersten Seite an. Im Unterverzeichnis »papers«, das die Software im Home des Anwenders anlegt, speichert sie die Textdateien ab, wobei sie mehrseitige Dokumente jeweils in einem einzigen Unterverzeichnis ablegt. Die Textdateien tragen die Endung ».words« und lassen sich als unformatierte Dateien in jedem herkömmlichen Editor weiterverarbeiten. Sie dienen jedoch vornehmlich zum Indexieren mit Schlüsselbegriffen.
Auch beim Einlesen bereits vorhandener Dateien führt Paperwork zunächst die Texterkennung aus. Zu beachten ist, dass die Software dabei keine Formate von Drittapplikationen wie Office-Suiten unterstützt. Eine Ausnahme bildet das weitverbreitete und universell einsetzbare PDF-Format. Integriert der Nutzer etwa Zeitschriften, die in diesem Format vorliegen, in das System, untersucht die OCR-Software diese Seite für Seite. Dann zeigt Paperwork im rechten Fensterbereich die einzelnen Seiten verkleinert in einer Listenansicht, die der User auf Wunsch vergrößert.
Bei Printmedien, die häufig auch viele Abbildungen und Werbeanzeigen enthalten, empfiehlt es sich, vor dem Einlesen die Texterkennung im Einstellungsmenü abzuschalten. Das spart nicht nur deutlich Zeit, sondern vermeidet auch unbrauchbare Ergebnisse, wie sie bei farbigen und mit unterschiedlichen Schriftgrößen hantierenden Vorlagen oft auftreten.
Indexierung und Suche
Sind alle Vorlagen fertig gescannt oder eingelesen, versieht sie der Anwender mit Schlagwörtern. Dazu klickt er auf die verkleinerte Dokumentenanzeige links im Programmfenster und dann auf das kleine Werkzeugsymbol im rechten Bereich. Nach einem Klick auf den »+«-Button definiert er verschiedene Labels – sprich Schlagwörter. Zur besseren Übersicht hinterlegt er die Labels wahlweise noch farbig (Abbildung 9).
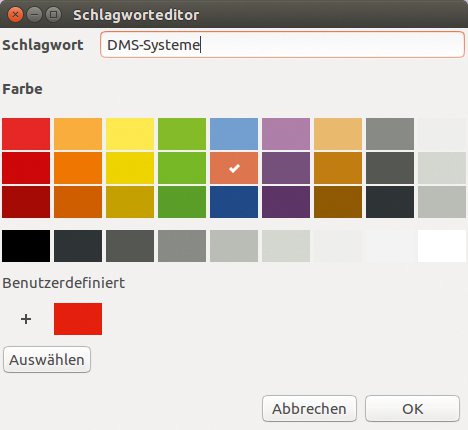
Abbildung 9: Manuell, aber farbenfroh geht die Verschlagwortung in Paperwork vonstatten.
Neu zu verschlagwortende Dokumente versieht Paperwork stets mit allen bereits eingegebenen Referenzbegriffen. Der Anwender kann nicht zutreffende Schlagwörter im jeweiligen Dokument deaktivieren, indem er Häkchen entfernt, und zugleich über das Eingabefeld »Additional keywords« neue eintragen. Sind alle Angaben getroffen, öffnet der User erneut die Listenanzeige, indem er auf den Pfeil »Zurück« in der »Properties«-Anzeige klickt. Nun erscheinen farbige Indexierungen zu jedem Dokument.
Um in umfangreichen Dokumentenbeständen nach bestimmten Daten zu suchen, klickt der Anwender oben links in der Dokumentenansicht auf den Button »Erweiterte Suche« und gibt dann in einem sehr schlicht gehaltenen Suchdialog seine Kriterien ein. Dabei kombiniert er die Gruppen »Datum«, »Schlagwort« und »Schlüsselwort(e)« wahlfrei miteinander. Ein Klick auf »Anwenden« aktualisiert die Anzeige und listet nur noch die zu allen Suchkriterien passenden Bestände auf (Abbildung 10).

Abbildung 10: Referenzierte Dokumente erscheinen in Paperwork mit farbig unterlegten Schlagwörtern.
Eine Exportfunktion versteckt sich oben rechts hinter dem Menü-Button. Sie exportiert aktuelle Dokumente oder Seiten in PNG-, Jpeg- oder PDF-Dateien, die der User in einem Verzeichnis seiner Wahl ablegt. Im selben Menü lässt sich das aktuelle Dokument über den entsprechenden Eintrag auch ausdrucken.
Referencer
Referencer [10] ist ein für den Gnome-Desktop entwickeltes kleines DMS-System – jedoch keine Client-Server-Anwendung – und eignet sich daher primär zum Verwalten kleinerer Dokumentenbestände auf Einzelplatzsystemen. Referencer braucht kein Datenbank-Backend, ist in den Repositories der meisten Linux-Distributionen enthalten und schnell per Mausklick installiert. Auch Nutzer anderer Desktops können den Gnome Referencer installieren und einsetzen – die Abhängigkeiten lösen die Paketverwaltungen automatisch auf. Für Distributionen, die das Programm nicht enthalten, liegt der Quellcode als Tar.gz-Archiv unter [11].
Nach der Installation wartet ein Starteintrag im Untermenü »Büro«. Ein Klick auf ihn öffnet ein simples Programmfenster mit lediglich einer Menü- und einer Buttonleiste am oberen Rand. Darunter erwartet den Anwender gähnende Leere, verpackt in zwei Fenstersegmente und einen weiteren Bereich darunter.
Die Software organisiert Dokumentenbestände in Bibliotheken. Um einen Bestand anzulegen, zieht der Nutzer Ordner oder mit der Maus markierte Dateien in das rechte Fenstersegment. Referencer bindet Dateien als Verknüpfungen ein, was den Vorteil hat, dass der Anwender das Dateiformat völlig frei wählen kann. Eine Bibliothek beheimatet daher auch verschiedene Dateiformate, darunter selbst Multimediadateien.
Nutzer sollten beachten, dass Referencer aufgrund der Verknüpfung zu den originalen Dokumenten in seinen Bibliotheken auch Pfade speichert. Es empfiehlt sich, vor dem Anlegen der Dokumentenbestände die Verzeichnishierarchien gut überlegt zu definieren, da Referencer Dokumente, die der Benutzer nachträglich in ein anderes Verzeichnis schiebt, nicht mehr findet.
Offenbar fehlt der Software nicht nur ein Dokumenten-Tracking, sie ignoriert beim Anlegen von Bibliotheken auch die Menü-Hierarchien und nimmt lediglich Dokumente aus der letzten Ebene einer Verzeichnisstruktur gemeinsam in einem Arbeitsgang auf.
Für das Einscannen gedruckter Vorlagen und die folgende Texterkennung braucht Referencer Drittprogramme, da der Software ein eigenes Scanmodul und eine OCR-Routine fehlen (Abbildung 11).
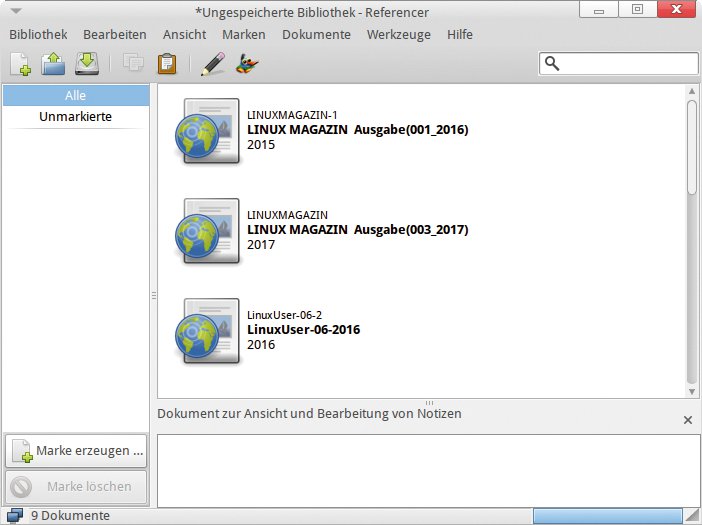
Abbildung 11: Die sehr einfach gehaltene Oberfläche des Referencer bringt keine eigenen Scan- und OCR-Routinen mit.
Schlagwörter
Stecken die gewünschten Dokumente in der neuen Bibliothek, beginnt das Referenzieren. Dazu erzeugt der Anwender über die Schaltfläche »Marke erzeugen« manuell so genannte Marken, die er mit jedem Dokument verknüpft. Referencer legt sie in einem gesonderten Fenster an und überträgt sie in das linke Segment. Dann markiert der User jene Dokumente, die er der aktuellen Marke zuordnen will, und ruft per Rechtsklick ein Kontextmenü auf. Ein Klick auf »Marken« öffnet die entsprechende Liste, aus der er dann die passende Marke auswählt.
Je nachdem, wie viele Dokumente er mit einer Marke verknüpft, ändert sich im linken Listenfenster die Schriftgröße des betreffenden Schlagworts. Die so referenzierten Dokumente lassen sich insbesondere bei größeren Beständen wesentlich leichter auffinden.
Im- und Export
Referencer importiert Metadaten aus dem kommerziellen DMS-System Endnote [12] wie auch aus der freien Bibtex-Literaturverwaltung [13]. Außerdem beherrscht das Werkzeug die Übernahme von Marken aus der Wissenschaftsdatenbank Arxiv.org [14], um so entsprechende Metadaten leichter mit Dokumenten in Referencer zu verknüpfen. Da sich diese Datenbanken jedoch primär auf wissenschaftliche Texte aus den Bereichen Mathematik, Physik, Biologie und Informatik fokussieren, ist der Nutzen im Kleinbüro begrenzt.
Beim Import von Dokumenten versucht Referencer, aus der Datenbank des Web-of-Knowledge-Service [15] Metadaten zu erhalten. Da dieses Angebot eine Registrierung voraussetzt und kostenpflichtig ist, erscheinen hier Fehlermeldungen. Über das Menü »Bibliothek« exportiert der Anwender Bibliotheken als Bibtex-Dateien, um sie anderweitig zu nutzen. Zudem kann er hier auch angelegte Notizen als HTML-Dateien exportieren.
Neben den Referenzen hinterlegt der Anwender zu jedem Dokument bei Bedarf noch einen Kommentar. In das Freitextfeld »Notizen:« – unten rechts im Fenster – lassen sich auch längere Anmerkungen eingeben und mit Hilfe der Speicherfunktion sichern.
Referencer setzt bei der Anzeige von Dokumenten ausschließlich auf externe Programme. Auf diese Weise unterstützt das Programm wesentlich mehr Formate als die internen Viewer und legt sogar Dateiarchive in einer Bibliothek ab. Die lässt sich dann mit einem Archivierungsprogramm ansehen und bei Bedarf auch entpacken. Um ein Dokument zu betrachten oder zu bearbeiten, klickt der Anwender zunächst auf die verkleinerte Ansicht der Datei und danach auf den »Play«-Knopf. Ein Klick auf »Öffnen« im nun erscheinenden Kontextmenü verbindet die Datei mit der passenden Anwendung für das Format. Über dasselbe Menü entfernen Nutzer auch einzelne Dateien aus der Bibliothek oder verknüpfen sie mit weiteren Schlagwörtern.
Fazit
Die getesteten DMS-Systeme konnten funktional alle überzeugen, peilen aber verschiedene Zielgruppen an: Während Referencer und Paperwork für das Kleinbüro und auch Privatanwender eine gute Lösung darstellen, bedient Krystal DMS eher mittelgroße bis große Unternehmen. Spitzenreiter in Sachen Funktionalität ist Logical Doc, das deshalb aber auch eine längere Einarbeitung erfordert.
Wichtig ist, dass sich Anwender vor dem Einführen eines kommerziell vertriebenen DMS-Systems genau überlegen, welche Funktionen sie benötigen und welche nicht. Die kommerziellen Pakete sind inzwischen derart modular aufgebaut, dass es mühsam ist, einen Überblick zu gewinnen. Bei passgenauer Auswahl eines DMS-Systems ist jedoch eine deutliche Arbeitserleichterung bei der Verwaltung und Nutzung von Dokumenten zu erwarten. So lohnt es sich in jedem Fall, eine solche Software einzuführen.
Infos
-
Tesseract: https://github.com/tesseract-ocr/tesseract
-
G-Imagereader: https://sourceforge.net/projects/gimagereader/
-
Krystal DMS: http://www.krystaldms.in
-
Download von Krystal DMS: http://www.krystaldms.in/resources/downloads/downloadForm.php?fileid=4
-
Krystal-Varianten: http://www.krystaldms.in/products.php
-
Webseite von Logical Doc: https://www.logicaldoc.com/de/
-
Community-Ausgabe von Logical Doc: https://sourceforge.net/projects/logicaldoc/files/sources/
-
Projektseite von Paperwork auf Github: https://github.com/jflesch/paperwork/
-
Sane-Projektseite: http://www.sane-project.org
-
Gnome Referencer: https://launchpad.net/referencer
-
Quellcodes des Referencer: http://icculus.org/referencer/
-
Endnote: http://www.adeptscience.de/products/refman/endnote/endnote.html
-
Bibtex: http://www.bibtex.org/de/
-
Arxiv.org: https://arxiv.org
-
Web of Knowledge: http://wokinfo.com
-
Open KM: https://www.openkm.com





