
© Kalenkov, 123RF
Mit Network Namespaces, die der Linux-Kernel schon lange bereitstellt und ohne die Containerlösungen aufgeschmissen wären, kann der Admin allein mit Bordmittel innerhalb eines laufenden Linux’ sehr anspruchsvolle und zugleich Ressourcen-schonende Setups auf die Beine stellen.
Linux-Namespaces erlauben es, mehrere virtuelle Instanzen der Ressourcen eines Hosts und eines Kernels (!) zu definieren und getrennt zu nutzen – kein Wunder, dass gerade Linux Containers (LXC, [1]) und Docker [2], aber auch SDN-Lösungen (Software Defined Networking, [3]) davon ausgiebig Gebrauch machen.
Im Unterschied zu Virtualisierung mit Hypervisoren wie KVM oder Xen legen Container keine vollwertige Betriebssysteminstanz an, sondern nutzen den Kernel des Gastgebers und Teile des Betriebssystems. Ressourcen, die dem Container zugewiesen sind, sind isoliert und abstrahiert; Prozesse, Geräte und Interfaces darin definiert der Admin im Rahmen eines Namespace, sie haben scheinbar eigene, ebenfalls isolierte Instanzen dieser Ressourcen im Zugriff. Die Linux-Namespaces umfassen derzeit IPC, Netzwerk, Mounts, PID, User und UTS.
Seit Linux 2.4.19
Spuren der Namensräume finden sich bereits im Linux-Kernel 2.4.19 [4], seit dem Kernel 2.6.24 liegen die Network Namespaces produktionsreif im Werkzeugkasten des Admin. Sie erlauben beispielsweise einzelnen Containern exklusiven Zugriff auf virtuelle Netzwerkressourcen. Der Admin weist damit jedem Container einen separaten Netzwerkstack zu. Was viele nicht wissen: Network Namespaces zu benutzen macht auch unabhängig von Containern eine Menge Sinn.
Vom Gerät bis zum Socket
Die Netzwerk-Namespaces erlauben es dem Admin, Netzwerkgeräte, IPv4- und IPv6-Protokollstacks, Routingtabellen, ARP-Tabellen, Firewalls, aber auch »/proc/net« , »/sys/class/net/« , QoS-Policies, Portnummern oder Sockets einzeln so zu virtualisieren, dass auch ohne Container einzelne Anwendungen ein besonderes Netzwerksetup vorfinden. Damit können sich auf ein und demselben System mehrere Dienste konfliktfrei an denselben Port binden. Jeder von ihnen darf gar seine eigene Routingtabelle vorhalten.
Ein typischer Anwendungsfall besteht darin, asymmetrisches Routing zu vermeiden. Wenn beispielsweise Admins einen Server in einem separaten Admin-Netzwerk über ein separates Interface verwalten, weil sie administrativen Traffic vom produktiven Netzwerk fernhalten wollen (Abbildung 1). Will ein Client das Admin-Interface eines Servers ansprechen, wird er – korrekt – über den Router geleitet, was mit klassischen Routingtabellen für den Antworttraffic kaum umzusetzen ist. Einfacher geht das, wenn das Admin-Interface nur in seinem eigenen, abgeschlossenen Netzwerk-Namespace existiert und seine eigenen Routingtabellen unterhält.
Ganz typisch für Network Namespaces sind in der Praxis virtuelle Netzwerkgeräte »vethX« . Während ein physikalisches Device nur in einem Netzwerk-Namespace existieren kann, lässt sich ein Paar virtueller Devices als Bridge verschalten oder wie eine Pipe bedienen; der Admin baut damit eine Art Tunnel zwischen den Namensräumen, die er auf seinem Host schaffen hat.
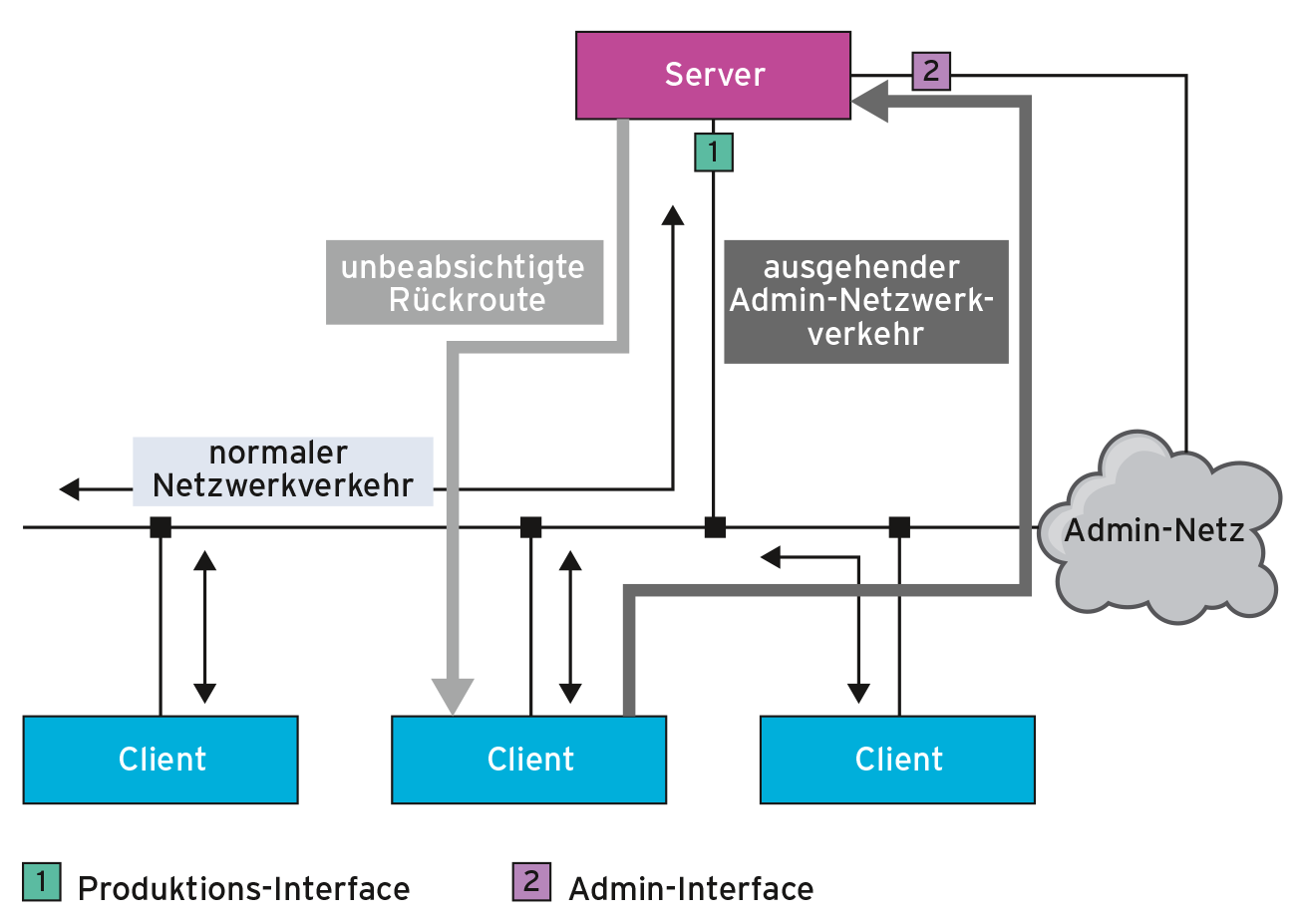
Abbildung 1: Asymmetrisches Routing wie hier lässt sich mit Namespaces relativ einfach vermeiden.
Das Namespaces-API
Damit die nun folgenden Beispiele funktionieren, muss der Kernel mit der Option »CONFIG_NET_NS=y« kompiliert sein. Der Befehl
cat /proc/config.gz | gunzip - | grep CONFIG_NET_NS
prüft dies (Abbildung 2). Das Namespaces-API besteht aus den drei Systemcalls »clone(2)« , »unshare(2)« und »setns(2)« sowie einigen »/proc« -Einträgen. Prozesse im Userspace öffnen Dateien unter »/proc/PID/ns/« und benutzen ihre Filedeskriptoren, um beim entsprechenden Namespace zu bleiben. Die beim Anlegen eines Namespace unter »/proc« erzeugten Inodes identifizieren die Namensräume.
Der Systemcall Clone erzeugt normalerweise einen neuen Prozess. Bekommt aber Clone das Flag »CLONE_NEWNET« als Argument mit auf den Weg, initiiert er neben dem Kindprozess einen neuen Netzwerk-Namespace, in dem der neue Prozess Mitglied wird. Unshare verschiebt den aufrufenden Prozess in einen neuen Namensraum, mit einem »CLONE_NEWNET« -Flag landet hierbei der aufrufende Prozess im neuen Namensraum. Setns erlaubt es dem aufrufenden Prozess, einem existierenden Namespace beizutreten.
Der Handle für die Network Namespaces ist »/proc/PID/ns/net« , seit Kernel 3.8 sind das symbolische Links. Deren Name besteht aus einem String mit dem Namespace-Typ und der Inode-Nummer:
$ readlink /proc/$$/ns/net net:[4026531956]
Bind-Mounts (»mount –bind« ) halten den Netzwerk-Namespace am Leben, auch wenn alle Prozesse innerhalb dieses Namensraums beendet sind. Wer das File öffnet (oder eines, das darauf gemountet ist), erhält einen Filehandle für den entsprechenden Namespace geliefert. Mit Setns könnte er dann den Namensraum wechseln.
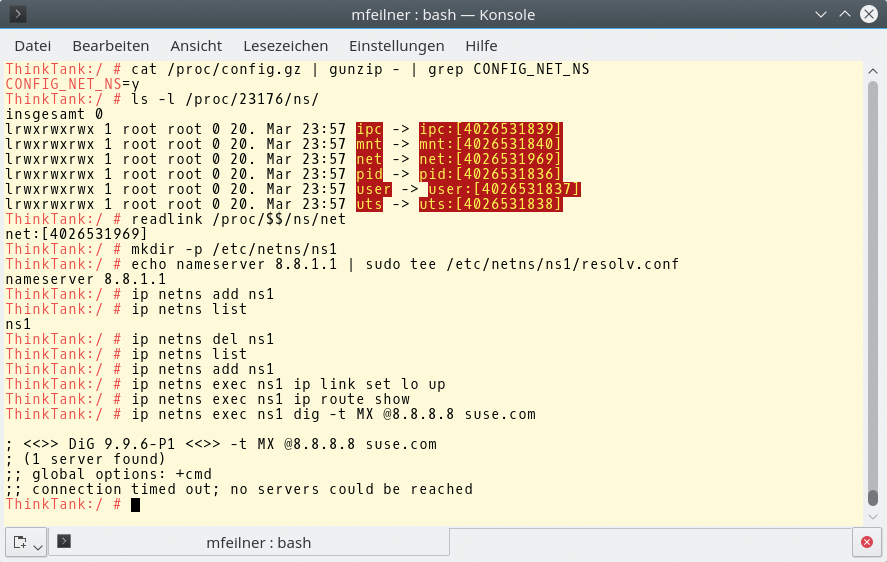
Abbildung 2: Der Kernelparameter »CONFIG_NET_NS« muss angeschaltet sein, damit das Proc-System Informationen über Namespaces transportiert.
Namespace konfigurieren und ein erstes Beispiel
Linux-Anwendungen, die von sich aus mit Namespaces umzugehen wissen, suchen nach globalen Konfigurationsdateien unter »/etc/netns/Namespace« und erst danach unter »/etc« . Zahlreiche Userspace-Pakete beherrschen den Umgang mit Network Namespaces: Ethtool, Iproute2 – das auch das »ip« -Managementtool mitbringt –, »iw« für Wireless-Verbindungen sowie Util-linux.
Namespaces zu verwenden ist einfach: Eine sehr simple, isolierte DNS-Resolver-Konfiguration in einem separaten Netzwerk-Namespace namens »ns1« beispielsweise richtet
sudo mkdir -p /etc/netns/ns1 echo nameserver 8.8.1.1 | sudo tee /etc/netns/ns1/resolv.conf
ein. Das Angebot lässt sich auch für Anwendungen erweitern, die keine Namespace-Fähigkeiten mitbringen. Hier erzeugt der Admin einfach einen Mount-Namespace und hinterlegt alle für den Netzwerk-Namespace relevanten Dateien in diesem Namespace an ihren gewohnten Orten, in der Regel unter »/etc« . So kollidiert nichts mit anderen Prozessen, was einiges an Flexibilität bringt.
“ip netns” als Dreh- und Angelpunkt
Nur selten braucht der Admin jedoch tief in die Details hinabsteigen, weil das Kommando »ip netns« das Handling einfach macht. Es kommt mit dem Paket Iproute2 und verwaltet das Anlegen und Löschen von Netzwerk-Namespaces sowie das Verteilen von Ressourcen zwischen ihnen. Dafür sind selbstverständlich Rootrechte notwendig; alle im Folgenden beschriebenen Kommandos funktionieren nur als Administrator richtig.
Die Syntax des Tools ist simpel und schmiegt sich an die klassische »ip« -Logik: »ip netns add ns1« fügt den Namespace »ns1« hinzu, »ip netns list« zeigt bestehende Namespaces an, »ip netns del ns1« löscht »ns1« (Abbildung 2). An das Ip-Kommando schließt sich optional die Konfiguration der Netzwerke in einem Namespace an, so wie das auf einem Single-Namespace-Gerät auch stattfände. Nur das »exec Namespace« -Kommando trennt die beiden Teile.
Zunächst sieht das komplette Kommando etwas schwierig aus, doch die Logik dahinter ist einfach und erlaubt es Anwendungen, die nur innerhalb eines Namespace agieren können, ohne Umwege zum Ziel zu gelangen. Der Eintrag
ip netns exec ns1 ip link set lo up
legt ein Loopback-Interface im Namespace »ns1« an. Das Kommando
ip netns exec ns1 ip route show
zeigt die Routingtabellen im Namespace. Die sind allerdings im Moment noch leer, weshalb auch der Aufruf einer DNS-Abfrage mit
ip netns exec ns1 dig -t MX @8.8.8.8 suse.com
noch kein Ergebnis zeitigt (Abbildung 2). Die Abbildung 3 zeigt, dass im vorliegenden Betriebssystem viele Netzwerkgeräte existieren, innerhalb des Namespace »ns1« dagegen nur ein Loopback-Device. Mit einem »exit« verlässt der Admin den Namensraum und befindet sich wieder in der vorherigen Umgebung.
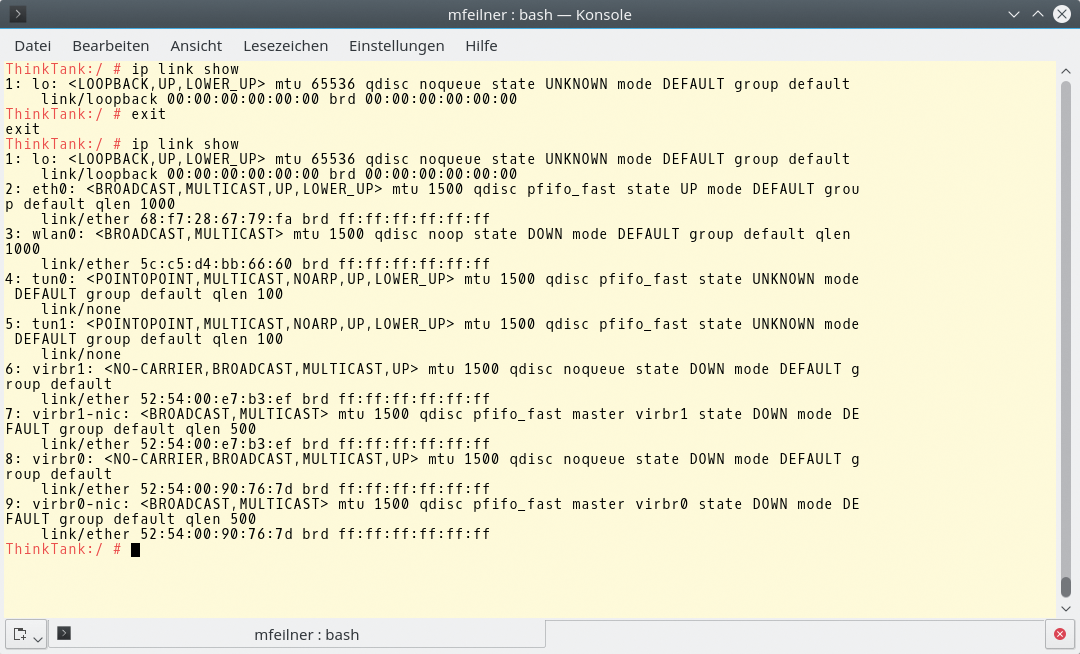
Abbildung 3: Der Admin hat eine Shell im Namespace »ns1« gestartet. Dort existiert nur das vorher angelegte Loopback-Interface.
Angesichts der etwas umfangreicheren Konfigurationsaufgaben, die jetzt vor dem Admin liegen, bietet es sich an, mit »ip« eine Shell zu öffnen, um mehrere Kommandos, jene aus Listing 1, nacheinander im Namespace abzusetzen.
Listing 1
eth1 einrichten
01 ip netns exec ns1 bash 02 ip link set eth1 up 03 ip addr add 192.168.1.123/24 dev eth1 04 ip -f inet addr show 05 exit
Mehr Beispiele
Abbildung 4 zeigt weitere simple Beispiele für die Verwendung von Namespaces. Einen weiteren Namespace anlegen, die Namespaces anzeigen und die Struktur unter »/var« anzeigen lassen – all das ist ein Kinderspiel:
$ ip netns add ns1$ ip netns add ns2$ ip netns list ns2 ns1$ tree /var/run/netns /var/run/netns/ |---ns1 |---ns2
Der Mount-Befehl veranschaulicht die neu eingehängten Mountpunkte:
$ mount |grep netns tmpfs on /run/netns type tmpfs (rw,nosuid,nodev,mode=755) proc on /run/netns/ns1 type proc (rw,nosuid,nodev,noexec,relatime) proc on /run/netns/ns1 type proc (rw,nosuid,nodev,noexec,relatime) proc on /run/netns/ns2 type proc (rw,nosuid,nodev,noexec,relatime) proc on /run/netns/ns2 type proc (rw,nosuid,nodev,noexec,relatime)
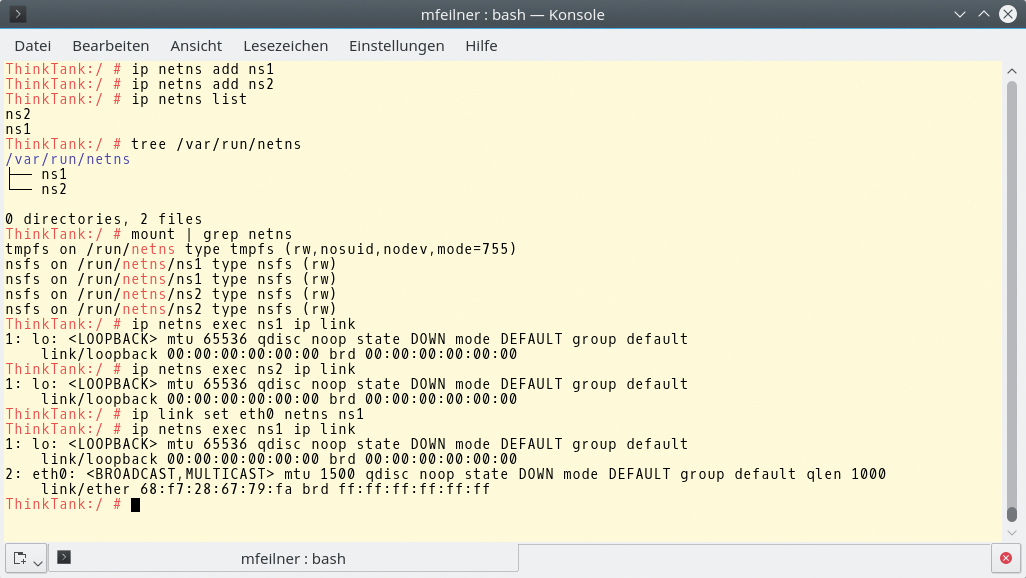
Abbildung 4: Das Handling der Namensräume fällt dem erfahrenen Linux-Admin leicht.
Wer den Bootvorgang seines Linux-Systems genau beobachtet, bemerkt, dass es bereits beim Hochfahren einen Namespace anlegt: »init_net« . Der bekommt dann das Loopback-Interface zugewiesen, dazu alle physischen Devices und die Sockets. Neu angelegte Namespaces beinhalten nur das Loopback-Device:
$ ip netns exec ns1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Der Befehl »set« fügt in einem Namespace ein im Hostsystem schon bestehendes Device hinzu. Weil es aber exklusiv ist, fehlt das Device fortan im Host-Namespace. Im Namespace »ns1« muss der Admin das Gerät anhand von Listing 2 zunächst konfigurieren. In diesem System gibt es zwei Netzwerkkarten, eine ist jetzt exklusiv »ns1« zugeordnet. Das Ganze funktioniert sehr stringent, wie ein Blick ins Sys-FS beweist:
$ tree /sys/class/net /sys/class/net |---eth0 -> ../../devices/pci0000:00/0000:00:03.0/net/eth0 |---lo -> ../../devices/virtual/net/lo
Im Default-Namespace ist das Gerät nicht mehr gelistet.
Listing 2
Devices konfigurieren
01 $ ip link set eth1 netns ns1 02 $ ip netns exec ns1 ip link 03 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default 04 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 05 3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 06 link/ether 52:54:00:02:e3:f1 brd ff:ff:ff:ff:ff:ff 07 $ ip link 08 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default 09 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 10 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 11 link/ether 52:54:00:01:b0:24 brd ff:ff:ff:ff:ff:ff
Das Beispiel mit dem asynchronen Routing ist in wenigen Schritten (Listing 3) fertig. Der Admin definiert hier Interfaces, Adressen und Routen, lässt sich die Ergebnisse anzeigen und testet das Ganze mit Ping. Die Routing-Tabelle, die er in Zeile 12 definiert, gilt nur im Namespace »ns1« . Ebenso kann er jetzt mit
$ mkdir -pv /etc/netns/ns1 mkdir: created directory ?/etc/netns? mkdir: created directory ?/etc/netns/ns1?$ echo 1.2.3.4\ mytest | tee /etc/netns/ns1/hosts$ ip netns exec ns1 getent hosts 1.2.3.4 mytest
unter »/etc/netns/ns1« eine eigene Konfigurationen hinterlegen.
Listing 3
Netzwerk isolieren
01 $ ip netns exec ns1 ip link set lo up 02 $ ip netns exec ns1 ip link set eth1 up 03 $ ip netns exec ns1 ip addr add 192.168.1.123/24 dev eth1 04 $ ip netns exec ns1 ip -f inet addr show 05 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default 06 inet 127.0.0.1/8 scope host lo 07 valid_lft forever preferred_lft forever 08 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 09 inet 192.168.1.123/24 scope global eth1 10 valid_lft forever preferred_lft forever 11 12 $ ip netns exec ns1 ip route add default via 192.168.1.1 dev eth1 13 $ ip netns exec ns1 ping -c2 8.8.8.8 14 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 15 64 bytes from 8.8.8.8: icmp_seq=1 ttl=51 time=22.1 ms 16 64 bytes from 8.8.8.8: icmp_seq=2 ttl=51 time=20.1 ms
Namespaces im Dialog
Virtuelle Ethernet-Devices sind das Mittel, über das Ressourcen aus verschiedenen Namensräumen miteinander kommunizieren. Die kommen stets im Zweierpack und funktionieren wie eine Pipe: Alles, was das Betriebssystem an ein »veth« schickt, kommt bei dem anderen (dem Peer) wieder raus. Der in Listing 4 dokumentierte Prozess zeigt, wie das funktioniert.
Eingangs erzeugt der Admin zwei virtuelle Netzwerkdevices: »veth1« und »veth2« . In Zeile 2 überprüft er anhand der Ausgabe, ob sie wirklich im Namensraum angekommen sind. In Zeile 9 verschiebt er »veth2« in den richtigen Namensraum, nämlich »ns2« . Dieser zweite Namensraum wird das Loopback- und das Peer-Interface enthalten (Zeilen 10 und folgende).
Damit die Kommunikation zwischen den Peers funktioniert, brauchen beide natürlich IP-Adressen, wofür die Zeilen 16 und 17 sorgen. Jetzt darf der Admin die zwei Devices starten (ab Zeile 18) und die Konnektivität testen. Die Verbindung klappt offensichtlich. Wer die Namespaces mit einem physischen Interface verbunden hat, darf hier natürlich auch mit Bridges arbeiten.
Listing 4
Virtuelle Ethernet-Devices
01 $ ip netns exec ns1 ip link add name veth1 type veth peer name veth2 02 $ ip netns exec ns1 tree /sys/class/net 03 /sys/class/net 04 |---eth1 -> ../../devices/pci0000:00/0000:00:08.0/net/eth1 05 |---lo -> ../../devices/virtual/net/lo 06 |---veth1 -> ../../devices/virtual/net/veth1 07 |---veth2 -> ../../devices/virtual/net/veth2 08 09 $ ip netns exec ns1 ip link set dev veth2 netns ns2 10 $ ip netns exec ns2 ip link 11 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default 12 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 13 2: veth2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 14 link/ether 8e:1b:5d:87:62:db brd ff:ff:ff:ff:ff:ff 15 16 $ ip netns exec ns1 ip addr add 1.1.1.1/10 dev veth1 17 $ ip netns exec ns2 ip addr add 1.1.1.2/10 dev veth2 18 $ ip netns exec ns1 ip link set veth1 up 19 $ ip netns exec ns2 ip link set veth2 up 20 21 $ ip netns exec ns1 ping -c2 1.1.1.2 22 PING 1.1.1.2 (1.1.1.2) 56(84) bytes of data. 23 64 bytes from 1.1.1.2: icmp_seq=1 ttl=64 time=0.021 ms 24 64 bytes from 1.1.1.2: icmp_seq=2 ttl=64 time=0.022 ms
Der nächste Schritt soll zeigen, wie sich ein SSH-Server nur innerhalb dieses Namespace verfügbar machen lässt. Das Kommando
$ ip netns exec ns1 /usr/sbin/sshd -o PidFile=/run/sshd-ns1.pid -o ListenAddress=1.1.1.1
startet den Sshd im Namespace »ns1« und übergibt ihm ein PID-File und eine IP-Adresse, auf der er lauschen soll. Das PID-File ist nötig, um diesen SSH-Serverdienst von der ohnehin im globalen Namespace laufenden Instanz zu unterscheiden. Der zweite SSH-Server lauscht nun nur auf 1.1.1.1, der IP des Interface »veth1« , das es nur im Namespace »ns1« gibt:
$ ps -ef | grep $(cat /run/sshd-ns1.pid) root 7387 1 0 00:13 ? 00:00:00 /usr/sbin/sshd -o PidFile=/run/sshd-ns1.pid -o ListenAddress=1.1.1.1$ ip netns exec ns1 ss -ltn State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 1.1.1.1:22 *:*
Beim letzten Test, eine SSH-Session von »ns1« nach »ns2« , erweist sich eine Kleinigkeit als nützlich: Wegen der innerhalb der »ns1« -Sitzung laufenden Bash kann der Admin hier auch den Namensraum konfigurieren, ohne »ip netns exec« -Kommandos voranzustellen (Listing 5).
Listing 5
SSH in den Namespace
01 $ ip netns exec ns2 ssh 1.1.1.1 02 $ ip -f inet addr show 03 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default 04 inet 127.0.0.1/8 scope host lo 05 valid_lft forever preferred_lft forever 06 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 07 inet 192.168.1.123/24 scope global eth1 08 valid_lft forever preferred_lft forever 09 4: veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 10 inet 1.1.1.1/10 scope global veth1 11 valid_lft forever preferred_lft forever 12 13 $ ss -etn 14 State Recv-Q Send-Q Local Address:Port Peer Address:Port 15 ESTAB 0 0 1.1.1.1:22 1.1.1.2:40412 timer:(keepalive,109min,0) ino:34868 sk:ffff880036f8b4c0 <->
Brücke bauen zur Realität
Neben den handlichen Tunnel durch Veth-Devices bieten die Bridges einige Vorteile für Admins, die Namespaces mit dem realen Netzwerk verbinden wollen. Listing 6 zeigt, wie sich ein virtuelles Device mit einem realen Ethernet-Device »eth0« verknüpfen lässt. Dazu löscht der Admin zunächst eines der bestehenden virtuellen Devices und legt es im Default-Namespace neu an. Weil die beiden Geräte durch die »Peer« -Direktive verknüpft sind, verschwindet auch das »veth1« automatisch.
Listing 6
Bridge bauen
01 $ ip netns exec ns1 ip link delete veth1 02 $ ip link add name veth1 type veth peer name veth2 03 $ ip link 04 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default 05 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 06 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 07 link/ether 52:54:00:01:b0:24 brd ff:ff:ff:ff:ff:ff 08 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 09 link/ether 52:54:00:02:e3:f1 brd ff:ff:ff:ff:ff:ff 10 7: veth2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 11 link/ether c6:27:2a:a8:06:ca brd ff:ff:ff:ff:ff:ff 12 8: veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 13 link/ether 26:3e:ce:c5:de:de brd ff:ff:ff:ff:ff:ff 14 15 $ ip -f inet addr show eth0 16 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 17 inet 192.168.56.130/24 brd 192.168.56.255 scope global eth0 18 valid_lft forever preferred_lft forever 19 20 $ ip addr del 192.168.56.130/24 dev eth0 21 $ brctl addbr br0 22 $ ip addr add 192.168.56.130/24 dev br0 23 $ ip link set br0 up 24 $ ip -f inet addr show br0 25 9: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default 26 inet 192.168.56.130/24 scope global br0 27 valid_lft forever preferred_lft forever 28 29 $ brctl addif br0 eth0 30 $ brctl addif br0 veth1 31 $ brctl show 32 bridge name bridge id STP enabled interfaces 33 br0 8000.263ecec5dede no eth0
Vor dem Errichten der Brücke wartet ein Abriss
Um eines der verbauten Ethernet-Devices im Host zu einer Brücke hinzuzufügen, muss der Admin zunächst seine IP-Adresse löschen und es entbinden. »ip -f inet addr show eth0« zeigt diese an, »ip addr del« löscht die Konfiguration. Der Befehl »brctl addbr br0« richtet in gewohnter Manier eine Brücke »br0« ein (Zeile 21), »ip link set br0 up« startet sie. Anschließend lassen sich mit »brctl addif« die virtuellen Devices mit der Bridge verknüpfen und das Ganze per »btctl show« verifizieren.
Im letzten Schritt verschiebt »setns« das Device »veth2« noch in den Namensraum »ns1« , verpasst ihm eine IP-Adresse und startet die Devices:
$ ip link set veth2 netns ns1$ ip netns exec ns1 ip addr add 192.168.56.131/24 dev veth2$ ip netns exec ns1 ip link set lo up$ ip netns exec ns1 ip link set veth2 up
Bei den Tests zu diesem Artikel scheiterten die letzten Schritte auf manchen Systemen unerklärlicherweise – das »veth2« -Interface schien dann down zu sein und Pings kamen nicht an. Auf anderen System funktionierte dagegen alles klaglos; wer hierfür mit einer Erklärung aufwarten kann – die Autoren würden sich freuen.
Aufräumen per Neustart oder Stück für Stück
Die Netzwerk-Namespaces sind nicht persistent, das bedeutet: Wer sich beim Spielen und Testen heillos verkonfiguriert hat, macht einen Neustart und findet nach dem Reboot eine Tabula rasa vor. Andererseits bedeutet das auch, dass es eines Startskripts bedarf, damit benötigte Namespaces auf produktiven Systemen erhalten bleiben.
Doch auch ohne Reboot kann der Admin die Konfiguration bequem löschen, indem er die Geräte zurück an den Namespace »init_net« verweist:
$ ip netns exec ns1 ip link delete veth1$ ip netns exec ns1 ip link set eth1 netns 1$ ip netns del ns1$ ip netns del ns2
Mit dem Löschen eines Namespace entfernt der Admin automatisch auch die Einträge in »/var/run/netns« – das Betriebssystem unmountet sie und entfernt die Mountpunkte. Normalerweise bringt dies die echten Devices zurück in den Default-Namespace, aber es gibt Situationen, wo das nicht angebracht wäre. Denn wer einen Namespace löscht, bevor alle Prozesse darin beendet sind, handelt sich Ärger mit den Mountpunkten ein.
Normalerweise wird eine Fehlermeldung das verhindern (“Mountpoint in use”). Leider kommt die nicht immer, dann ist das Gerät verloren, das zu einem gelöschten Namespace gehört, und damit die dort beheimateten Prozesse.
Daher sollte der Admin immer die PIDs durchgehen und betroffene Prozesse händisch killen, wenn nötig. Dabei leistet das Programm »ip netns pids Namespace« gute Dienste. Es geht für den Admin durch das »/proc/« -Verzeichnis und findet alle Prozesse, die dem genannten Network Namespace angehören (Listing 7).
»ip netns pid ns1 | xargs kill« killt dann die Prozesse aus Namespace »ns1« , wobei der Admin aber auch »identify« verwenden könnte, um für jeden einzelnen Prozess den entsprechenden Namespace herauszufinden, einfach anhand der PID. Das Kommando »monitor« hilft nachzuvollziehen, was die Befehle denn für Änderungen vorgenommen haben – je umfangreicher die Umgebung, desto hilfreicher ist dieses Vorgehen.
Listing 7
ip net pid
01 $ ps auxww | grep $(ip netns pids ns1) 02 root 7811 0.0 0.0 46900 1024 ? Ss 01:05 0:00 /usr/sbin/sshd -o PidFile=/run/sshd-ns1.pid -o ListenAddress=1.1.1.1 03 04 $ ip netns pids ns1 | xargs kill 05 $ ip netns del ns1 06 $ ip netns identify 1445 07 ns1 08 $ ip netns monitor 09 add ns1 10 add ns2 11 delete ns2 12 delete ns1
Leichtgewichtig und leicht verständlich
Dass Containertechnologien wie Docker und LXC Namespaces ausgiebig benutzen, ist allgemein bekannt. Dass die schon lange vom Linux-Kernel bereitgestellte leichtgewichtige Isoliertechnik aber auch ohne turmhohe Cloudstacks für Admins interessante Setups zustande bringt, wissen nur wenige. Dabei gelingt die Einarbeitung in die nötigen Bordmittel recht zügig, wie der Artikel hoffentlich gezeigt hat.
Infos
- LXC: https://linuxcontainers.org
- Docker: http://www.docker.com
- SDN-Schwerpunkt “Software Defined Networking beendet das administrative Klein-Klein”: Linux-Magazin 04/14, ab. S. 28
- Eva-Katharina Kunst, Jürgen Quade, “Kern-Technik” – Folge 55: Linux-Magazin 02/11,S. 104, https://www.linux-magazin.de/Ausgaben/2011/02/Kern-Technik/(language)/ger-DE#






funktioniert nicht:
Obwohl es außerhalb des namespace existiert: