
© Fedor Selivanov, 123rf.com
Digitale Dokumente der Zeitgeschichte sind flüchtiger als Stein, Pergament oder Papier. Drei Archivierungstools helfen gegen das Vergessen und sichern Internetauftritte.
Das Internet vergisst nichts! Von wegen, die durchschnittliche Lebensdauer einer Webseite beträgt laut Internet Archive nur 77 Tage [1]. Die Flüchtigkeit digitaler Informationen bereitet vor allem den Archiven Kopfzerbrechen, die zunehmend mit Hilfe dynamischer Webanwendungen publizieren. Stadt-, Regional- und Kommunalarchive sind nach den Archivgesetzen der Länder verpflichtet ihre Daten zu speichern, aber auch Instituts- oder Unternehmensarchive möchten solche Inhalte aufbewahren. Es reicht längst nicht mehr aus, einfache Backups der Internetpräsenz auf zukunftssicheren Medien zu speichern – in nur 20 Jahren dürfte selbst ein geschickter Admin ein heute zeitgemäßes Contentmanagement-System kaum installieren können.
Viele Archive behelfen sich, indem sie einzelne relevante Seiten in Handarbeit als PDF-Dateien sichern [2]. Ein solches Vorgehen kann jedoch nicht mehr als eine Notlösung sein. Abhilfe versprechen auf Langzeitarchivierung spezialisierte Tools. Neben sehr teuren kommerziellen Lösungen werben auch einige Open-Source-Vertreter um die Gunst der Archivare. Httrack [3], die Netarchive Suite [4] und das Web Curator Tool [5] zeigen in dieser Bitparade unter Ubuntu 12.10 und auf einem Cloud-Linux (Amazon, basierend auf RHEL 5), wie sie digitale Informationen aufbewahren.
Die Tester ließen die Werkzeuge Daten von unterschiedlichen Contentmanagement-Systemen, Blog- und Forensoftware erheben. Sie wählten eigene Webseiten, um sicherzustellen, dass der jeweilige Crawler auf alle Inhalte zugreifen durfte.
Httrack
Den Auftakt macht das älteste Tool. Den unter der GPL veröffentlichten Offlinebrowser Httrack [3] gibt es bereits seit zehn Jahren. Er steht auf der Projektseite für Linux-, BSD- und Windows-Systeme zum Download bereit. Im Test trat die aktuelle Version 3.46 vom Juni 2012 an. Das in C programmierte Werkzeug benötigt für den Betrieb keine Datenbank. Linux-Anwender nutzen es entweder auf der Kommandozeile oder über ein Webinterface. Zusätzlich ist ein in Qt implementiertes GUI namens Httraqt [6] verfügbar.
Auf einem Standard-Linux-System ist Httrack schnell eingerichtet. Pakete für Debian, Ubuntu, Gentoo, Fedora, Red Hat und Mandriva bietet die Downloadseite. Auf einigen Distributionen, so auch auf dem Ubuntu-Testrechner, gibt es zwei Pakete – eins für das Kommandozeilentool (»httrack« ) und eins für das Webinterface (»webhttrack« ). Ersteres bietet zwei Betriebsarten: Entweder startet der Anwender über Eingabe von »httrack« den interaktiven Modus und beantwortet Fragen oder er gibt über Aufrufparameter seine Wünsche an. Die Manpage und der Befehl »httrack –help« listen die wichtigsten Optionen auf.
Wiedererkennungswert?
Das Webinterface fragt die gleichen Dinge ab wie das interaktive Shelltool. Zunächst möchte Httrack einen Projektnamen einrichten, danach ein Verzeichnis für das lokale Archiv. Benutzer geben nun die zu archivierende URL an und wählen aus, ob sie die Webseite mit oder ohne Hilfe des Assistenten spiegeln, nur die Zieldatei speichern, alle Links der URL spiegeln oder einfach nur die Links testen möchten. Um ein möglichst komplettes Archiv zu erhalten, empfiehlt sich die Arbeit mit dem Assistenten, der detaillierte Fragen stellt (siehe Abbildung 1).
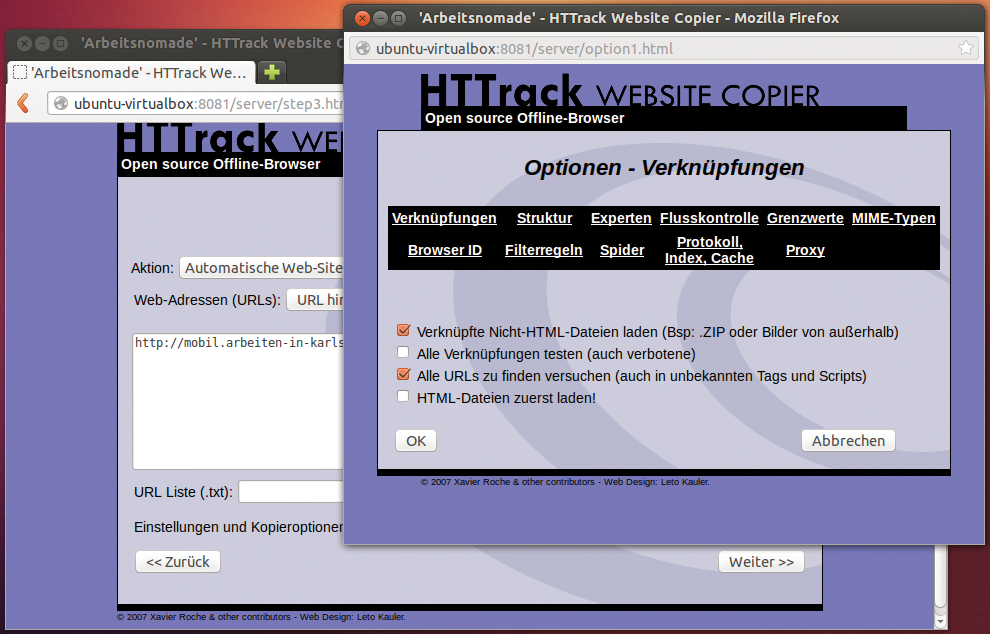
Abbildung 1: Anwender konfigurieren ihre Archivprojekte bequem über das Httrack-Webinterface. Hinter den Links verstecken sich die jeweiligen Einrichtungsoptionen.
Httrack erstellt keine vollständigen Archive. Webinhalte speichert dieser Testkandidat in den Quellformaten, zum Beispiel HTML, CSS, Text und Grafiken. Auf der Shell schreibt »-V« Tar- oder Zip-Archive. Einige wenige Metadaten, etwa Änderungsdaten einer Webseite, sichert das Tool optional. Dynamisch generierte Webseiten landen also als statische Kopie auf der Platte, auf die gesammelten Inhalte greifen Anwender danach mit einem Webbrowser zu.
Interne Links bleiben vollständig erhalten. Zusammengesetzten URLs mit Funktionsaufrufen und vom Anwender eingegebenen Variablen kann Httrack nicht folgen. Während das Tool Client-side Imagemaps, bei denen der Browser die Koordinaten des Mausklicks auswertet, problemlos mitnimmt, verweigert es bei Server-side Imagemaps, bei denen der Webserver für die Verarbeitung der Koordinaten zuständig ist, den Dienst. Solche Grafiken landen als statische Bilder ohne jegliche Funktion im Archiv.
Auf mehrere Server verteilte Inhalte stellen Httrack vor ähnliche Probleme wie Wget. Beauftragt der Anwender das Tool auch Domains zu besuchen, deren Content eingebettet ist, begibt er sich auf eine Gratwanderung. Entweder definiert er hier zu viele weitere Server, sodass Httrack verknüpften Links ohne Rücksicht auf Verluste folgt, oder er gibt zu wenige frei und das Archivtool überspringt eingelagerte Inhalte. Dennoch sollten Archivare Httrack den Vorzug vor Wget geben, denn das Werkzeug erfasst immerhin CSS-Styles und punktet mit einem hilfsbereiten Wizard.
Netarchive Suite
Zwei dänische Nationalarchive riefen dieses Projekt 2005 ins Leben, um vor allem heimische Webseiten zu bewahren. Seit 2008 beteiligen sich auch die französische und die österreichische Nationalbibliothek an der Weiterentwicklung. Die Netarchive Suite [4] steht unter der LGPL und setzt im Hintergrund auf den Webcrawler Heritrix [7] von Internet Archive. Die Tester schauten sich Version 4.0 vom Januar 2013 an.
Genau wie Heritrix selbst implementierten die Entwickler die Netarchive Suite in Java. Entsprechend benötigen Anwender eine vollständige Java-Umgebung auf dem System. Eventuell vorhandene »headless« -Varianten tauschen sie gegen ein “Java mit Köpfchen” aus.
Die Netarchive Suite arbeitet wahlweise mit einer Derby-, MySQL- oder PostgreSQL-Datenbank zusammen; die Macher empfehlen Derby. Zusätzlich verlangt die Netarchive Suite nach dem Java Messaging Service von Sun. Admins laden den Installer in Binärform von [8] herunter, entpacken die Zip-Datei, wechseln ins neue Verzeichnis und führen den Befehl »./installer« aus. Auf dem Rechner muss zwingend ein SSH-Dienst laufen.
Zur Installation der Suite folgen Benutzer am besten der Quickstart-Anleitung unter [9]. Leider gestaltet sich die Einrichtung auf dem eigenen System alles andere als angenehm. Es entsteht schon viel zusätzliche Arbeit dadurch, dass der Download nicht alle notwendigen Komponenten enthält. Offenbar gehen die Macher davon aus, dass Admins ein derart umfangreiches Tool selten mehr als einmal installieren. Auch die Einarbeitung in die Bedienung hat es in sich. Die Suite ist unübersichtlich und wenig intuitiv – ohne intensives Studium der Dokumentation gelingt hier wenig.
Vor der Archivierung sollten Anwender in den Browsereinstellungen einen Proxy einrichten. Ist die Netarchive Suite auf dem lokalen Rechner installiert, tragen sie »localhost« und Port 8070 ein und fügen den eigenen Rechner als Ausnahme hinzu. Danach greifen sie über die Adresse »http://localhost:8074/HarvestDefinition« auf das Netarchive-Webinterface zu und klicken auf den Link »Selektiver Harvest« . Sie vergeben einen Projektnamen, tragen die Ziel-URL ein, wählen die Frequenz der Sicherung aus und speichern das Ganze.
Soll das Tool auch Subdomains erfassen, definieren Anwender dies ebenfalls an dieser Stelle und legen jeweils einen eigenen Seed an. Ergebnisse können Nutzer über das Menü »Qualitätssicherung« unter »Viewerproxy Status« begutachten (siehe Abbildung 2).
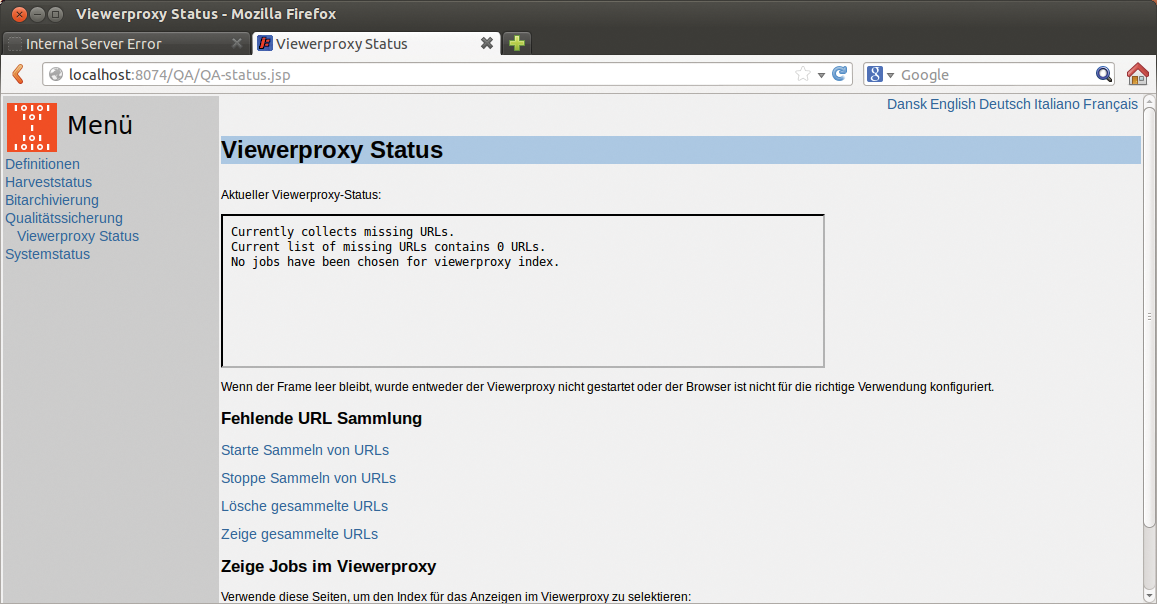
Abbildung 2: Im Bereich »Qualitätssicherung« erfahren Benutzer mehr zum aktuellen Status der Netarchive Suite. Außerdem überprüfen sie hier bereits archivierte Seiten.
Sammeln und bewahren
Für die Archive nutzt die Netarchive Suite das WARC-Format (siehe Kasten “Das Web Archive File Format”), welches das Internet Archive für Heritrix und die Wayback Machine entwickelt hat. Es handelt sich um Container, die unter anderem Indexsysteme und Metadaten enthalten. Letztere orientieren sich an Dublin Core, einer Sammlung einfacher Konventionen zur Beschreibung von Dokumenten und anderen Objekten im Internet [10]. Viele Archivierungstools setzen auf diesen Standard, um Autor, Herausgeber, Sprache oder Lizenz des Dokuments als Meta-Information festzuhalten und diese zur Indizierung zu verwenden.
Das Web Archive File Format
Um flüchtige Informationen aus dem Web möglichst lange für die Nachwelt zu erhalten, hat die Internationale Organisation für Normung (ISO) den Standard WARC verabschiedet. Das Web Archive File Format [12] ist der Nachfolger des vom Internet Archive entwickelten ARC File Format (ARC_IA, [13]) und in ISO 28500:2009 definiert [14]. WARC ist das Ergebnis aus Diskussionen und praktischen Erfahrungen, die das IIPC (International Internet Preservation Consortium, [15]) über die Jahre gesammelt hat. Mitglieder des Konsortiums sind das Internet Archive selbst sowie Organisationen, Archive und Bibliotheken aus über 25 Ländern.
Das verbesserte Format soll einen Standard bereitstellen, um Webquellen zu strukturieren, zu verwalten und aufzubewahren. Bei WARC handelt es sich um ein Containerformat, das neben dem eigentlichen Inhalt auch Informationen zu verwendeten Protokollen (zum Beispiel HTTP, FTP, NNTP und SMTP), zu eventuellen Duplikaten und zahlreiche andere Metadaten speichert. WARC-Dateien bestehen zu großen Teilen aus Text, ausgenommen die eingebundenen Bilder, Videos, Skripte und Ähnliches. Anwender können sie daher problemlos im Texteditor oder Pager öffnen und betrachten. In mehreren Blöcken (so genannten »record blocks« ) sind beschreibende Header und die zugehörigen Dokumente aneinandergereiht.
Derzeit sind acht solcher Blocktypen definiert: »warcinfo« (Dateiname, Erstellungsdatum, Crawler-Software, IP und Hostname des ausführenden Rechners), »response« (unter anderem Ziel-URI und -IP, Protokollname und -version), »resource« (Informationen zur Quelle, wenn keine Angaben zum Protokoll vorliegen), »request« (Methode, wie der Inhalt angefragt wurde inklusive Protokoll und User-Agent), »metadata« (beschreibende Infos zum Ziel mit Angaben, wenn eine andere Quelle darauf verweist, Zwischenschritte bis dahin und so weiter), »revisit« (für Inhalte, die in der Vergangenheit bereits archiviert wurden), »conversion« (alternative Version, wenn das Original beispielsweise zur Archivierung verändert wurde) und »continuation« (enthält Informationen zum Speicherort von Inhalten, die aus Platzgründen in mehreren WARC-Dateien untergebracht sind).
Der zweite Testkandidat archiviert auch dynamische Webseiten und Foren ohne Probleme. Im »Viewerproxy Status« erreicht der Anwender Links, um Details zu den Jobs einzublenden. Über »Wähle diese Jobs zur Qualitätssicherung im Viewerproxy« beginnt die Suite die Indizierung der Seite, und »Starte Sammeln von URLs« aktiviert die automatische Überprüfung aller internen Links der archivierten Webseite.
Leider fehlt ein Menüpunkt, über den Anwender die archivierten Seiten aufrufen. Stattdessen tippen sie die Original-URL in die Adressleiste, und die Proxy-Einstellungen des Browsers biegen den Aufruf auf die lokale Kopie um. Nutzer können daher nicht erkennen, ob sie auf der echten Seite oder im eigenen Archiv unterwegs sind. Haben sie den Proxy deaktiviert und vergessen ihn wieder einzuschalten, freuen sie sich möglicherweise über das vollständige Archiv auf der Platte, surfen aber tatsächlich im Netz.
Ein vernünftiges Interface für die archivierten Inhalte bietet das Wayback-Plugin. Es erlaubt auch Netarchive-Suite-Anwendern sich durch verschiedene Revisionen zu klicken. Hinweise zur Installation dieser und anderer Erweiterungen bietet die Abteilung »Configuration Manual« der Dokumentation.
Web Curator Tool
Auch der dritte Kandidat entstand als Gemeinschaftsprojekt. Die British Library und die National Library of New Zealand arbeiten seit 2006 zusammen am Web Curator Tool (WCT, [5]) und veröffentlichen ihre Software unter der Apache Public Licence. Genau wie bei der Netarchive Suite werkelt im Hintergrund der Webcrawler Heritrix [7].
Das Web Curator Tool ist ebenfalls in Java implementiert und benötigt daher ein JDK (1.5 oder neuer). Beim Datenbank-Backend dürfen Anwender zwischen Oracle, MySQL oder PostgreSQL wählen. Die Tester entschieden sich für MySQL und installierten zusätzlich die Pakete »libmysql-java« und »libcommon-dbcp-java« . Das Archivtool setzt außerdem Apache Tomcat in Version 5.5.x oder neuer voraus. WCT 1.6 vom Dezember 2012 arbeitete auf dem Testsystem klaglos mit Tomcat 5.5.36 zusammen, hatte allerdings Probleme mit Version 6 und verweigerte den Dienst mit der neuesten 7er Variante gänzlich.
Wer auf der Projekthomepage nach einer Anleitung sucht, der findet dort nur Handbücher für ältere WCT-Versionen. Nach dem Entpacken der aktuellen Programmfassung 1.6 hilft daher ein Blick ins Unterverzeichnis »docs« weiter. Fraglich ist jedoch, ob die Entwickler die Installationsskripte für MySQL gründlich getestet haben, denn sogar die Kommentarzeichen verursachen ab und zu Fehler. Benutzer, die bei der Datenbankeinrichtung die Skript-Versionsangaben der WCT-Anleitung ignorieren und jeweils auf die neueste Skriptversion setzen, bewegen sich auf der sicheren Seite.
Nachdem sich der Anwender erfolgreich durch die Installation gekämpft hat, startet er Tomcat neu und öffnet die Adresse »http://localhost:8080/wct/« im Browser. Dort meldet er sich mit dem Benutzernamen »bootstrap« und dem Passwort »password« an. Nun zeigt sich der Kandidat von der besten Seite. Die Oberfläche von Web Curator Tool ist aufgeräumt und sogar ohne umfassende Kenntnisse über Archivarbeit verständlich (siehe Abbildung 3). Ein Blick in die beiliegende Quickstart-Anleitung schadet dennoch nicht.
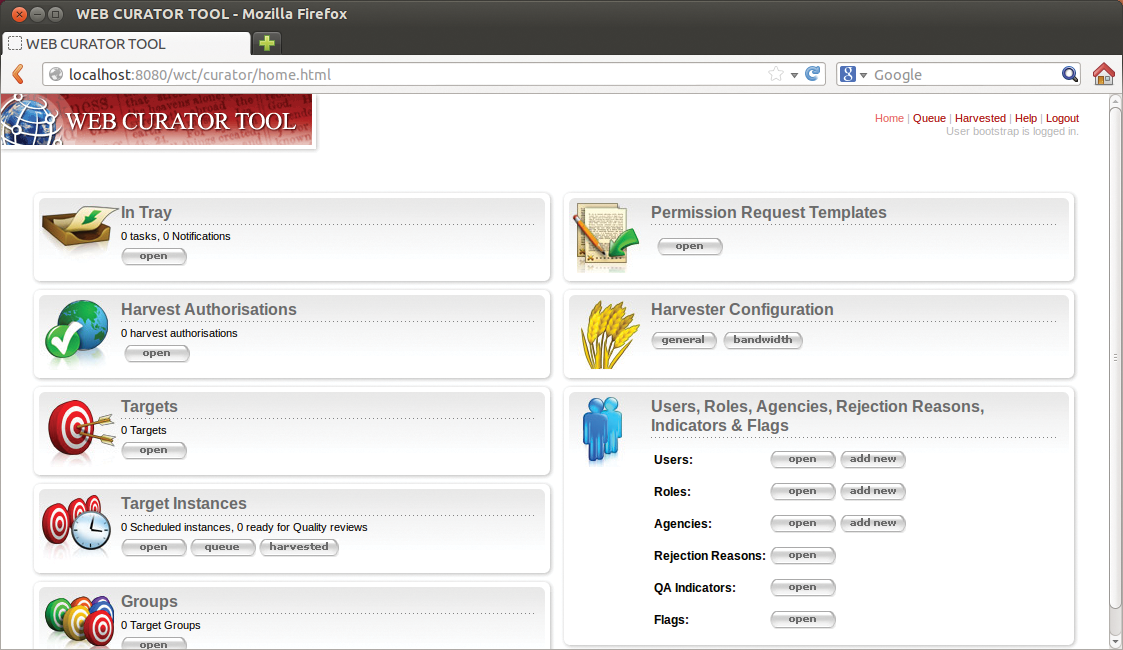
Abbildung 3: Das Web Curator Tool überzeugt mit seiner aufgeräumten Benutzeroberfläche. Auch ohne Vorkenntnisse finden sich Benutzer hier schnell zurecht und gelangen zu ihren Archiven.
In Verwahrung
Bevor der Nutzer mit dem Archivieren beginnt, sollte er im Hauptmenü eine neue Rolle anlegen. Diese kann er zum Beispiel »Admin« nennen und im nächsten Arbeitsschritt mit allen Rechten ausstatten. Danach erstellt er im gleichen Menü einen Account, den er der »Admin« -Rolle zuordnet. Nach dem Einloggen besucht er die Abteilung »Harvest Authorisations« und legt eine neue Berechtigung an. Diese dient intern als Nachweis, dass der Inhaber einer Webseite der Archivierung zugestimmt hat.
Im Bereich »Targets« richtet der Nutzer alle Webseiten ein, die er sichern möchte. Für jedes Ziel definiert er einen Namen, eine Beschreibung, einen Besitzer, den Status, eine oder mehrere URLs und einen Zeitplan. Auch wenn der Weg für einfache Archive recht aufwändig erscheint, ist das Vorgehen bei vielen Zielen angebracht. Das Web Curator Tool sorgt für Ordnung und Struktur.
Nach dem Harvester-Durchlauf legt WCT dem Benutzer das Ergebnis zur Qualitätskontrolle vor. In einer hierarchischen Übersicht entfernt er dann überflüssige Bestandteile des Archivs wie etwa Seiten mit HTTP-Statuscodes. Zugriff auf Logfiles, eine Liveansicht und Vergleichsmöglichkeiten für zuvor erstellte Archive sind ebenfalls vorhanden.
Das Web Curator Tool speichert die Daten genau wie die Netarchive Suite im WARC-Format. Auch beim Handling der Metadaten gibt’s keine Unterschiede: Dublin Core [10] ist als Standard mit von der Partie. Unter dem Menüpunkt »Harvested« finden Anwender die archivierten Webseiten. Vom Look&Feel her erinnert das Tool an die Wayback Machine [11]. Gesicherte Webseiten zeigt WCT mit allen Inhalten an, die das Tool erfassen konnte. Einschränkungen gibt es lediglich für Streamingmedien oder Javascript-Aufrufe von nicht erfassten Servern wie beispielsweise Social Widgets.
Was den Umgang mit verteilten Inhalten betrifft, hält sich das Web Curator Tool strikt an die Vorgaben des Benutzers und erfasst nur Seiten, für die er eine Freigabe eingerichtet hat. Liegen Inhalte auf Subdomains oder auf verschiedenen Servern verstreut, muss der Archivar diese zusätzlich als »URL Pattern« bei den »Harvest Authorisations« anlegen.
Auf immer und ewig
Httrack ist ein nützliches Werkzeug mit einer flachen Lernkurve. Benutzer, die einfach nur Inhalte aus einem Blog oder einem CMS herauslösen und in statische Webseiten umwandeln möchten, kommen auf ihre Kosten. Das Tool stößt allerdings schnell an seine Grenzen, vor allem wegen der fehlenden Verwaltung archivierter Webseiten beziehungsweise wegen der mangelnden Unterstützung für Dublin-Core-Metadaten [10]. Httrack empfiehlt sich somit eher für den Privatgebrauch oder als Überganglösung, bis ein besseres Archivierungsprogramm verfügbar ist.
Die Netarchive Suite hinterlässt keinen allzu guten Eindruck und wirkt wie ein Flickenteppich, dem eine einheitliche Oberfläche gut täte. Die Installation strapaziert die Nerven der Anwender und braucht viel Arbeitszeit. Ist das Tool einmal eingerichtet, überzeugen die fertigen Archive – vor allem wegen der zugrunde liegenden Heritrix-Technik.
Diesen Crawler nutzt auch der dritte Testkandidat, setzt oben drauf noch eine benutzerfreundliche Oberfläche und punktet bei der Bedienung. Das Web Curator Tool hat daher klar die Nase vorn und gewinnt diesen Test. Berechtigungen, Metadaten und Archivinhalte sind übersichtlich vereint und versöhnen mit den Hürden bei der Installation.
Infos
- Internet-Archive-FAQ: http://archive.org/about/faqs.php
- Empfehlung der Bundeskonferenz der Kommunalarchive: http://www.bundeskonferenz-kommunalarchive.de/empfehlungen/Empfehlung_Webarchivierung_Teil2_Technik.pdf
- Httrack: http://www.httrack.com
- Netarchive Suite: https://sbforge.org/display/NAS/NetarchiveSuite
- Web Curator Tool: http://webcurator.sourceforge.net
- Httraqt: http://httraqt.sourceforge.net
- Heritrix: http://crawler.archive.org
- JMS-Download: http://mq.java.net/downloads.html
- Netarchive-Quickstart: https://sbforge.org/display/NASDOC321/Installation+of+the+Quickstart+system
- Dublin Core: http://dublincore.org
- Wayback Machine: http://web.archive.org
- Web Archive File Format: http://www.digitalpreservation.gov/formats/fdd/fdd000236.shtml
- ARC File Format: http://www.digitalpreservation.gov/formats/fdd/fdd000235.shtml
- ISO 28500:2009 (WARC): http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=44717
- IIPC: http://www.netpreserve.org






