
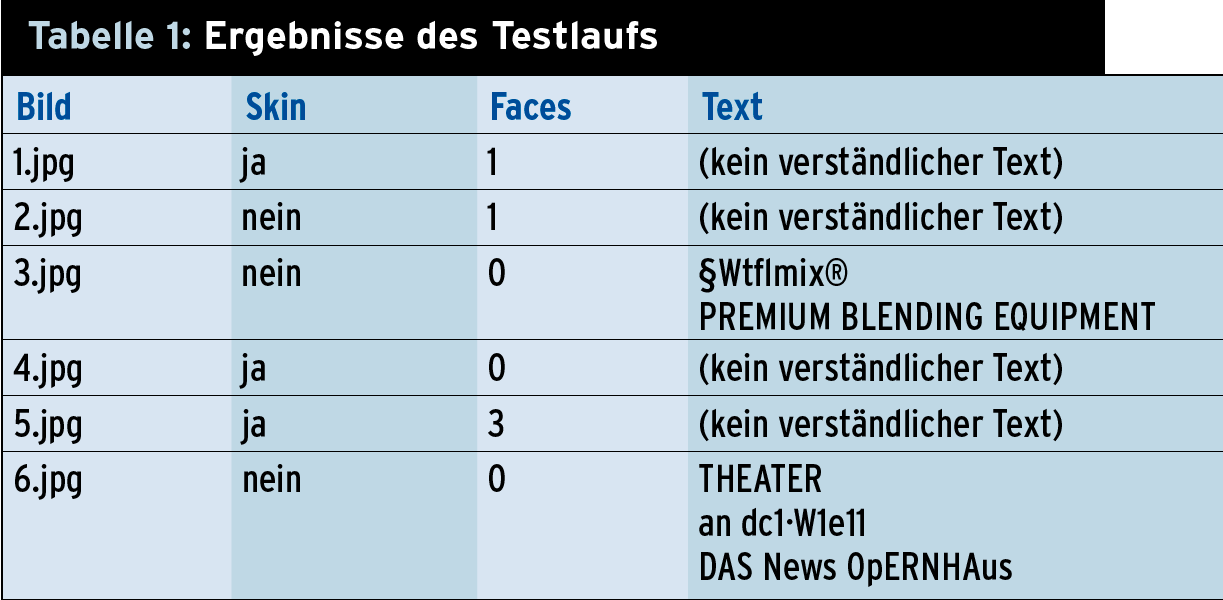
Abbildung 1: Die Versuchsbilder <custom name="code">1.jpg</custom> bis <custom name="code">6.jpg</custom> in der Übersicht: Fotos mit viel Haut, ein Schimpanse, die Gesichter der Autoren sowie Texte.
Wie soll man nur in einer Unmenge von Bilddateien gerade jene finden, die Gesichter oder Nackedeis oder Texte enthalten? Mit ein paar Python-Skripten, Programmierbibliotheken wie Open CV und der OCR-Software Tesseract geht das automatisch.
Die auf aktuellen Computern speicherbare Datenmenge nimmt kontinuierlich zu, so ist beispielsweise die Forensik mit Mengen von Multimedia-Dateien konfrontiert, die sich von Hand nicht mehr bewältigen lassen. Wie dieser Artikel aber zeigt, lässt sich zumindest die Verarbeitung von Bilddateien mit wenigen Zeilen Python-Code automatisieren. Kurze Beispiele erklären die Erkennung von Hautpartien, Gesichtern und Text.
Python aufrüsten
Die Installation der erforderlichen Programmierbibliotheken und Programme erfolgt auf Debian-basierten Distributionen mittels Paketmanager:
aptitude install python-imagingpython-opencv tesseract-ocrtesseract-ocr-deu
Auf diesem Weg ist sichergestellt, dass das System die von den Python-Bindings geforderten Voraussetzungen erkennt und mit installiert. Aufgrund der verwendeten Bibliotheken kommt Python 2 für das Programm zum Einsatz (siehe Kasten “Versions-Wirrwarr”).
Beim Paket »python-imaging« handelt es sich um die Python Imaging Library (PIL, [1]), sie liest in der eingesetzten Version 1.1.17 eine Vielzahl von Bildformaten. Daneben bietet sie diverse Bildbearbeitungsoperationen sowie Zugriff auf die Farbwerte einzelner Pixel. Beides zusammen eignet sich gut, um die Hautanteile in einem Bild zu bestimmen.
Die Bibliothek »python-opencv« (hier in der Version 2.1.0, [2]) ist eine ursprünglich von Intel veröffentlichte Bibliothek, die Algorithmen für maschinelles Sehen (Computer Vision) implementiert. Sie ist in C und C++ programmiert und steht unter der BSD-Lizenz.
Versions-Wirrwarr
Während für den Python-Interpreter in der Version 1 geschriebener Code auch auf Version 2 lauffähig war, ist dies beim Wechsel von Version 2 auf die im Dezember 2008 erschienene Version 3 nicht mehr ohne Weiteres möglich. Für einige der in diesem Artikel verwendeten Bibliotheken, zum Beispiel »python-openvc« , stehen oft nur Distributionspakete für Python 2, genauer gesagt 2.6, zur Verfügung. Daher verwenden die gezeigten Codebeispiele Python-2-Syntax.
Um Texte in Bildern mit Hilfe von OCR (Optical Character Recognition) zu erkennen, verwendet dieser Artikel die Pakete »tesseract-ocr« und »tesseract-ocr-deu« in den Versionen 2.04 und 2.00. Dabei handelt es um das Kommandozeilen-Programm der ursprünglich von Hewlett-Packard entwickelten Software Tesseract. Mittlerweile verwaltet Google das Programm und entwickelt es weiter ([3], [4]). Der von Samuel Hofstaetter entwickelte Wrapper Python-Tesseract [5] wandelt zu verarbeitende Bilder in das einzige von Tesseract verstandene Format Tiff um, ruft das Programm auf und reicht dessen Ausgaben an den Python-Interpreter weiter.
Python-Tesseract liegt derzeit nicht als Debian-Paket vor. Zur Verwendung mit den Python-Skripten dieses Artikels genügt es, das auf der Projekthomepage verfügbare Skript »tesseract.py« in deren Verzeichnis zu kopieren.
Hauptprogramm
Das Hauptprogramm »main.py« ruft die einzelnen Unterfunktionen und damit die Erkennung der jeweils gesuchten Objekte auf. Zu Beginn importiert es die nötigen Funktionen, wie in Listing 1 zu sehen ist. Das Programm lässt sich dann wie in Zeile 11 beschrieben aufrufen. Je nach Aufruf kommt eine andere Unterfunktion zum Zuge (Zeilen 14 bis 22). Den eingegebenen Pfad nimmt in Zeile 24 die Funktion »os.walk()« entgegen. Die »os« -Bibliothek bietet viele Betriebssystemfunktionen, »walk« durchsucht einen Verzeichnisbaum rekursiv und gibt ein Dreier-Tupel zurück. Aus diesem Tupel greift sich die folgende Zeile den Dateinamen heraus. Zeile 28 ruft die eigentliche Funktion auf.
Listing 1
Hauptprogramm main.py
01 #!/usr/bin/python
02 import os, sys
03
04 from faces import detectFaces
05 from skin import detectSkin
06 from ocr import extractText
07
08 def main():
09
10 if len(sys.argv) != 3:
11 print("Wrong number of arguments. Usage: python %s <faces|skin|text> <pPath>" % sys.argv[0])
12 sys.exit(-1)
13
14 if (sys.argv[1] == "faces"):
15 processFunc = detectFaces
16 elif (sys.argv[1] == "skin"):
17 processFunc = detectSkin
18 elif (sys.argv[1] == "text"):
19 processFunc = extractText
20 else:
21 print('Wrong parameter! Usage: python %s <faces|skin|text> <pPath>' % sys.argv[0])
22 sys.exit(-2)
23
24 for lRoot, lDirs, lFiles in os.walk(sys.argv[2]):
25 for lName in lFiles:
26 try:
27 pPath = lRoot + os.sep + lName
28 lResult = processFunc(pPath)
29 if lResult[0] == 0:
30 print("""Negative result for: %s
31 -------------------------------------------""" % pPath)
32 else:
33 print("""Positive result for: %s
34 -------------------------------------------""" % pPath)
35 except KeyboardInterrupt:
36 print("Cleaning up ...")
37 sys.exit(-1)
38 except IOError:
39 print("File \'"+ pPath + """\' is not supported or not a picture!
40 -------------------------------------------""")
41
42 if __name__ == "__main__":
43 main()
Ein Besonderheit von Python ist, dass eine Funktion mehrere Rückgabewerte besitzen kann. In diesem Fall ist das neben 0 oder 1(je nach Erfolg) zusätzlich der Pfad der Datei (Zeilen 29 bis 34). Die Catch-Blöcke fangen die verschiedenen möglichen Fehler ab: Es handelt sich entweder nicht um eine Bilddatei, die Datei wird nicht unterstützt oder das Programm wird mit [Strg]+[C] beendet. Die Zeilen 42 und 43 machen das Skript zu einem ausführbaren Programm.
Hautfarben-Erkennung
Die Funktion »detectSkin()« in Listing 2 liest die einzelnen Pixel eines Bildes aus und vergleicht sie mit Richtwerten. Die globale Variable in Zeile 3 ist der Schwellenwert. Wird dieser Wert überschritten, im Beispiel um 10 Prozent, gibt die Funktion eine positive Rückmeldung, denn das aktuelle Bild zeigt mehr Haut, als erwünscht ist. Nach dem Öffnen des Bildes ermittelt das Skript dessen Breite und Höhe. Beide Werte benötigt es für die folgenden For-Schleifen. In diesen spricht die Funktion »getpixel()« das jeweilige Pixel an und wertet es aus (Zeilen 14 und 15). Der Rückgabewert ist ein Tupel mit drei Werten, in diesem Fall den Farbwerten für Rot, Grün und Blau.
Listing 2
Hautfarben-Erkennung skin.py
01 from PIL import Image 02 03 gSkinThreshold = 10 04 05 def detectSkin(pPath): 06 07 lIm = Image.open(pPath) 08 09 lImageW = lIm.size[0] 10 lImageH = lIm.size[1] 11 lIndication = 0 12 13 if (lIm.mode == "RGB"): 14 for lY in range(0, lImageH): 15 for lX in range(0, lImageW): 16 lXY = (lX, lY) 17 lRGB = lIm.getpixel(lXY) 18 19 if ( ((lRGB[0] > 225) and (lRGB[0] < 255)) and ((lRGB[1] > 170) and (lRGB[1] < 230)) and ((lRGB[2] > 180) and (lRGB[2] < 235))): 20 #light caucasian 21 lIndication += 1 22 elif ( ((lRGB[0] > 220) and (lRGB[0] < 255)) and ((lRGB[1] > 150) and (lRGB[1] < 210)) and ((lRGB[2] > 145) and (lRGB[2] < 200))): 23 #caucasian 24 lIndication += 1 25 elif ( ((lRGB[0] > 190) and (lRGB[0] < 235)) and ((lRGB[1] > 100) and (lRGB[1] < 150)) and ((lRGB[2] > 90) and (lRGB[2] < 125))): 26 #dark caucasian 27 lIndication += 1 28 elif ( ((lRGB[0] > 215) and (lRGB[0] < 255)) and ((lRGB[1] > 150) and (lRGB[1] < 200)) and ((lRGB[2] > 110) and (lRGB[2] < 155))): 29 #asian 30 lIndication += 1 31 elif ( ((lRGB[0] > 170) and (lRGB[0] < 220)) and ((lRGB[1] > 85) and (lRGB[1] < 135)) and ((lRGB[2] > 50) and (lRGB[2] < 100))): 32 #light african 33 lIndication += 1 34 elif ( ((lRGB[0] > 45) and (lRGB[0] < 95)) and ((lRGB[1] > 20) and (lRGB[1] < 65)) and ((lRGB[2] > 5) and (lRGB[2] < 60))): 35 #dark african 36 lIndication += 1 37 38 lResult = (((lIndication*100)/(lImageW*lImageH))) 39 if (lResult > gSkinThreshold): 40 return 1, pPath 41 else: 42 return 0, pPath
Jedes der ausgelesenen Pixel durchläuft anschließend die Zeilen 19 bis 36. Die If-Abfrage erhöht eine Zählervariable, wenn alle drei Werte in einen bestimmten Bereich passen. Die Autoren haben die Farbwerte aus diversen Listen übernommen und angepasst. Sie haben die Werte eher großzügig ausgewählt, damit sich Haut auch bei schlechteren Lichtverhältnissen erkennen lässt.
Nach dem Durchlaufen der If-Abfragen errechnet der Code aus dem Zähler einen Prozentsatz und vergleicht ihn mit dem Schwellenwert. Liegt das Ergebnis darüber, gibt die Funktion 1 und den entsprechenden Pfad zurück (Zeile 40).
Face Detection
Ein Aufruf der Funktion »detectFaces()« startet die Gesichtserkennung. Listing 3 zeigt die darin enthaltene Logik: Zeile 13 lädt das zu untersuchende Bild durch den Aufruf der Funktion »cv.LoadImage()« . Diese erhält den Pfad zum Bild und gibt ein Objekt zurück, das die geladene Bilddatei repräsentiert. Zeile 15 generiert ein Bildobjekt und fordert dessen Speicherbereich an. Um Merkmale aus dem Gesicht zu extrahieren, konvertiert Zeile 16 das Bild in Graustufen.
Listing 3
Gesichtsklassifizierung faces.py
01 import sys, os
02 import cv
03
04 sCascade = cv.Load("./haarcascade_frontalface_default.xml")
05
06 def displayObject(pImage):
07 cv.NamedWindow("face", 1)
08 cv.ShowImage("face", pImage)
09 cv.WaitKey(0)
10 cv.DestroyWindow("face")
11
12 def detectFaces(pImage):
13 lImage = cv.LoadImage(pImage)
14
15 lGrayScale = cv.CreateImage((lImage.width,lImage.height), 8, 1)
16 cv.CvtColor(lImage, lGrayScale, cv.CV_BGR2GRAY)
17 lStorage = cv.CreateMemStorage(0)
18 cv.EqualizeHist(lGrayScale, lGrayScale)
19
20 lFaces = cv.HaarDetectObjects(lGrayScale, sCascade, lStorage, 1.15, 5)
21
22 if ((len(lFaces)) > 0):
23 print("The picture contains %(number)s face%(plural)s!" % {'number':len(lFaces),'plural':'s' if len(lFaces) > 1 else ''})
24 #for (x,y,w,h),n in lFaces:
25 # cv.Rectangle(lImage, (x,y), (x+w,y+h), 255)
26 #cv.SaveImage(os.path.join(os.path.dirname(pImage), "faces_" + os.path.basename(pImage)),lImage)
27 #displayObject(lImage)
28 return 1, pImage
29 else:
30 print ("The picture doesn't contain a face!")
31 return 0, pImage
Zur späteren Weiterbearbeitung reserviert der Code Speicher, den die eigentliche Gesichtserkennung benötigt. Dabei bedeutet der Parameter 0 des Aufrufs »CreateMemStorage(0)« , dass die Blockgröße dem Standardwert von 64 KByte entspricht. Zeile 18 überschreibt das Histogramm des Grau-skalierten Bildes und das bereits vorhandene Objekt mit dem neuen Inhalt.
Trainingsdaten
Die für den Haar-Classifier benötigte Datei »haarcascade_frontalface_default.xml« lädt das Python-Programm aus Optimierungsgründen außerhalb der Funktion »detectFaces()« in das Objekt »sCascade« (Zeile 4). Die XML-Datei befindet sich im selben Verzeichnis wie die Python-Quelltextdateien und enthält die Trainingsdaten des Haar-Klassifizierers. Sie stammt aus dem Downloadbereich des Jviolajones-Projekts [6].
Der Kasten “Haar Feature-based Cascade Classifiers” beschreibt im Schnelldurchlauf die Rolle der Klassifizierer bei der Gesichtserkennung. Der Aufruf der eigentlichen Gesichtserkennung erfolgt in Zeile 20. Die Funktion »HaarDetectObjects()« erhält neben dem Graustufenbild, den Trainingsdaten und dem zugewiesenen Speicherbereich für die Berechnungen den Wert »1.15« als »ScaleFactor« und »5« für »MinNeighbors« [7].
Haar Feature-based Cascade Classifiers
Bei der Implementierung von Objektklassifizierungs-Algorithmen gibt es mehrere Ansätze. Open CV bedient sich so genannter “Haar Feature-based Cascade Classifiers”, die auf dem von Paul Viola und Michael Jones entwickelten Viola-Jones-Detektor beruhen und die “Haar-like Features” ausmachen.
Damit so ein Detektor funktioniert, muss er im Vorfeld sowohl durch Positiv- als auch Negativ-Beispiele trainiert werden. Im ersten Fall enthält ein Beispiel das zu erkennende Objekt, im letzteren Fall nicht. Open CV verwaltet diese Trainingsdaten in einem XML-Format, das mit dem des Jviolajones-Projekts [6] kompatibel ist, und profitiert so von dessen Daten.
Nachdem der Klassifizierer trainiert wurde, lässt er sich auf beliebige Bereiche eines Bildes anwenden. Das Suchfenster kann bei diesem inkrementellen Prozess zwischen den Durchläufen vergrößert werden. Diesen Faktor legt »ScaleFactor« fest. Außerdem besteht ein solcher Klassifizierer aus mehreren einfacheren Subklassifizierern, die der Reihe nach anzuwenden sind – der so genannten Kaskade. Die Anzahl der Subklassifizierer definiert der Parameter »MinNeighbors« .
Damit werden die zu untersuchenden Bereiche während der Durchläufe um jeweils 15 Prozent skaliert und die Anzahl der Nachbar-Rechtecke, die ein Objekt ausmachen, auf 5 festgelegt. Die Zeilen 28 und 31 geben je nach Vorgabe des Hauptprogramms den Erfolgsfall sowie den Pfad zum Bild zurück.
Die auskommentierten Zeilen 24 bis 27 zeigen eine mögliche Erweiterung des Skripts zum Anzeigen der Bildobjekte. In den Zeilen 6 bis 10 ist die Anzeigefunktion »displayObject()« mit Hilfe der Open-CV-Bibliothek ausprogrammiert.
Bevor Tesseract Bilder analysieren kann, müssen sie in einer Form vorliegen, die die OCR-Engine versteht. Das erledigt der Wrapper Python-Tesseract. Damit das Python-Skript (Listing 4) aus dem übergebenen Pfad ein Objekt erstellen kann, importiert es die Python Image Library (PIL) in Zeile 1. Der Import des Tesseract-Moduls erfolgt in Zeile 2 des Skripts.
Listing 4
Text-Extraktion mit OCR ocr.py
01 import Image 02 import tesseract 03 04 def extractText(pPath): 05 lImage = Image.open(pPath) 06 lResult = tesseract.image_to_string(lImage, lang="deu") 07 print (lResult) 08 if (lResult != None): 09 return 1, pPath 10 else: 11 return 0, pPath
Die Funktion »extractText()« wird mit dem übergebenen Pfad aufgerufen, »Image.open()« lädt das Bild in ein Objekt (Zeile 5). Die Funktion »image_to_string()« gibt den erkannten Text als String zurück (Zeile 6). Die Tesseract-Bibliothek ist mehrsprachig, die gewünschte Sprache bestimmt der Parameter »lang« , ansonsten geht die Software von Englisch aus. Die folgende If-Abfrage (Zeilen 8 bis 11) überprüft, ob ein Text extrahierbar war. Den Namen der bearbeiteten Datei gibt das Skript samt Erfolgsmeldung an das Hauptprogramm zurück.





Abbildung 1: Die Versuchsbilder »1.jpg« bis »6.jpg« in der Übersicht: Fotos mit viel Haut, ein Schimpanse, die Gesichter der Autoren sowie Texte.
Probelauf
Nachdem die vorausgesetzten Pakete installiert und alle Skripte im selben Verzeichnis abgelegt sind, soll ein Test die Anwendbarkeit der vorgestellten Skripte belegen. Als Testmaterial dienen Bilder, die sich unter freien Lizenzen im Internet finden oder von Bekannten der Autoren stammen. Abbildung 1 zeigt die Versuchsbilder in der Übersicht. Aus Platzgründen analysiert der Test nur sechs Bilder.
Abbildung 2 zeigt den Aufruf und die Ausgaben des Hauptprogramms. Letztere lassen sich durch Anwendung des Dreiecksoperators in eine Datei umleiten und so etwa per Mail versenden.
Der Testlauf bringt mehrere Ergebnisse: So erkennt der Code Gesichter mit Ausnahme der Abbildung »4.jpg« richtig. Das liegt einerseits an der Sonnenbrille, andererseits daran, dass das Gesicht nicht frontal abgebildet ist. Offenbar weist aber das Gesicht des Affen Konturen auf, die Open CV nicht von denen eines Menschen unterscheiden kann. Die Hauterkennung fällt bei Bild 1, Bild 4 und Bild 5 positiv aus.

Abbildung 2: Start des Hauptprogramms auf der Kommandozeile: Enthalten die Testbilder Gesichter?
Tesseract liefert bei den Bildern 3 und 6 den enthaltenen Text mit einiger Genauigkeit zurück. Allerdings gibt es auch bei Bildern, die offensichtlich keinen Text enthalten, irgendwelche Zeichenketten aus. Tabelle 1 zeigt die Ergebnisse im Überblick.
Das Hauptprogramm eignet sich für Erweiterungen. Beispielsweise ließen sich Dateien je nach Ausgang des Klassifizierungsprozesses durch Funktionen des »shutil« -Moduls [8] behandeln. Das Verschieben von Dateien in ein beliebiges Verzeichnis gestaltet sich mit Hilfe der Funktion »shutil.move()« relativ einfach – denkbar wäre etwa das maschinenunterstützte Aussortieren der Urlaubsfotos nach gefundenem Hautanteil. Schließlich möchte nicht jeder die neueste Bademode am eigenen Körper der Internet-Öffentlichkeit präsentieren.
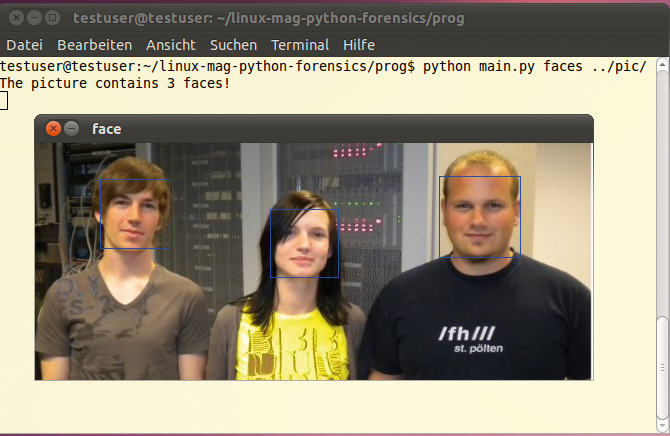
Abbildung 3: Die studentischen Autoren, eingerahmt: Das Skript zur Gesichtserkennung kann seine Befunde auch interaktiv dem Anwender vorlegen.
Weitere Szenarien wären das Archivieren fotografierter Visitenkarten in einem effizientem Textformat oder die Unterstützung bei der Digitalisierung analoger Fotografien. Das auf den Fotos abgedruckte Aufnahmedatum ließe sich mit Hilfe der Texterkennung in die Metadaten einfügen. Auch das Einlesen von Bilddaten von externen Quellen ist denkbar. Open CV erlaubt schon jetzt das Auslesen diverser Webcams über das Video4linux-API [9].
Forensik auf Python-Art
Die vielseitige Verwendung von Python in der Forensik hat auch das Sans Institute in einem Artikel dargestellt [10]. Der Autor T. J. O’Connor demonstriert anhand mehrerer Beispiele die praktische Eignung der Sprache für die Forensik: Python-Skripte durchsuchen das Dateisystem nach diversen verschlüsselten Daten (Rot 13, Cisco-VPN-Passwörter, DES) und entschlüsseln diese nach Möglichkeit. Außerdem extrahieren sie GPS-Koordinaten aus den Metadaten von Bildern, knacken Zip-Dateien und werten verschiedene betriebsystemspezifische Datenstrukturen aus. (mhu)
Infos
- Python Imaging Library: http://www.pythonware.com/products/pil/
- Open CV Python: http://opencv.willowgarage.com/wiki/PythonInterface
- Tesseract OCR: http://code.google.com/p/tesseract-ocr/
- Peter Kreußel, “Nachlese”: Linux-Magazin 03/09, S. 86: https://www.linux-magazin.de/Heft-Abo/Ausgaben/2009/03/Nachlese
- Python-Tesseract: https://github.com/hoffstaetter/python-tesseract/raw/master/tesseract.py
- Jviolajones: http://code.google.com/p/jviolajones/
- Cascade Classification: http://opencv.willowgarage.com/documentation/python/objdetect_cascade_classification.html
- Shutil-Bibliothek: http://docs.python.org/library/shutil.html
- Janne Parkkila, “Detecting Eyes With Python & OpenCV”: http://japskua.wordpress.com/2010/08/04/detecting-eyes-with-python-opencv/
- T. J. O’Connor, “Grow Your Own Forensic Tools”: http://www.sans.org/reading_room/whitepapers/forensics/
- Listings und Beispieldateien zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2011/07/python-objekterkennung/






