
(c) Galyna Andrushko, 123rf.com
Die meisten Entwickler verbinden Python mit dem objektorientierten Programmierstil. Doch die Sprache beschreitet vermehrt auch die Pfade der funktionalen Programmierung. Dieser Artikel zeigt, was Python in Sachen Closures, List Comprehension und Funktionen höherer Ordnung zu bieten hat .
Python nennt sich eine objektorientierte Programmiersprache. Das ist aber nur die halbe Wahrheit, denn als Multiparadigmen-Programmiersprache unterstützt sie insbesondere auch die funktionale Programmierung, und dies in immer mächtigerer Art und Weise. Nachdem sich die erste Folge dieser Reihe mit den Grundzügen der funktionale Programmierung beschäftigte, wird sich dieser Artikel den Techniken, Built-in-Funktionen und Bibliotheken rund ums funktionale Programmieren in Python widmen.
Python, zwar nicht als funktionale Sprache entworfen, nimmt doch immer mehr funktionale Charakteristiken an. Waren es anfangs nur First Class Functions, so fanden immer wieder neue funktionale Features Eingang in die Sprache:
- Closures
- anonyme Funktionen (Lambda-Funktionen)
- Generatoren und Generator-Ausdrücke.
- die klassischen Funktionen höherer Ordnung “map”, “filter” und “reduce” Python
- List Comprehension
Closures
Closures oder innere Funktionen sind Funktionen, die beim Aufruf ihren Aufrufkontext konservieren. Diese spezielle Funktionen mit Gedächtnis sind eine beliebte Technik, um Dekoratoren in Python zu implementieren (siehe Rainer Grimm, “Dekoratoren in Python”: Linux-Magazin 06/09, S. 96). Insbesondere ermöglichen Closures, Funktionen zu definieren, die innere Funktionen auf Anfrage zurückgeben. Für diese inneren Funktionen werden in Python gerne Lambda-Funktionen verwendet, denn durch sie können Closures sehr kompakt umgesetzt werden.
Ein klassischer Anwendungsfall für Closures und Lambda-Funktionen zugleich ist die Funktion “makefilter” aus Listing 1, die bei jedem Aufruf einen neuen Filter erzeugt. Vor dem Verständnis der Funktion “makefilter” steht zuerst das Verständnis der zwei funktionalen Komponenten Closures und Lambda-Funktionen.
Das kleine Beispiel “addWith” (Abbildung 1) zeigt, wie der Wert “first” beim Aufruf von “addWith” im Scope der Funktion gebunden wird, sodass auf ihn lesend aus der inneren Funktion “innerFunction” zugegriffen werden kann.
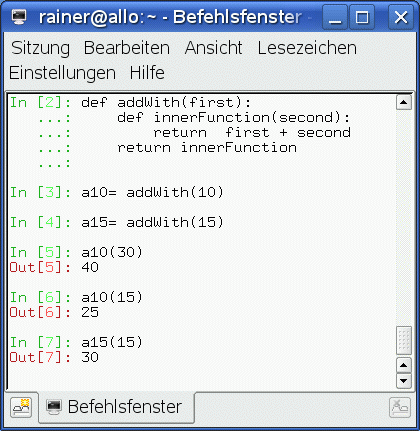
Abbildung 1: Lesender Zugriff auf den äußeren Scope.
Leider ist die Umsetzung von Closures unter Python 2 sehr eingeschränkt, da sich der umgebene Scope aus der inneren Funktion nur lesend referenzieren lässt (Abbildung 1).
Den schreibenden Zugriff auf eine Variable “start” aus der inneren Funktion “memorizeCount” quittiert der Interpreter mit einer schwer verständlichen Fehlermeldung (Abbildung 2). Durch den schreibenden Zugriff auf die Variable “start” in dem Ausdruck “start+=1” wird eine neue Variable in deren Scope angelegt. Bevor die Variable “start” einen Wert besitzt, wird aber versucht, diesen zu lesen. Dieser Zugriff muss scheitern.
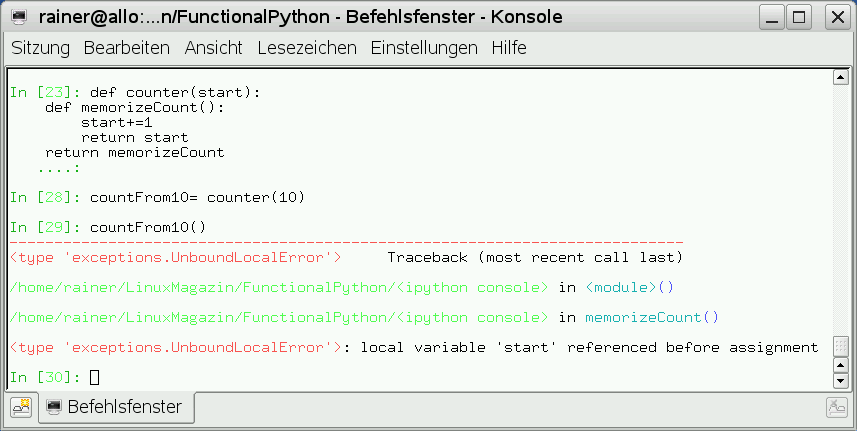
Abbildung 2: Der schreibende Zugriff auf den äußeren Scope scheitert in Python 2.*
Mit dem neuen Schlüsselwort “nonlocal” erlaubt Python 3.0 auf den äußeren, nicht lokalen Scope schreibend zuzugreifen. Damit ist ein Zähler schnell implementiert.
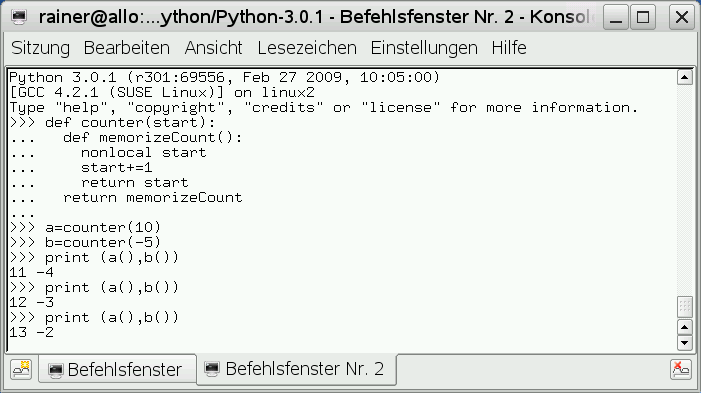
Abbildung 3: Schreibender Zugriff auf den äußeren Scope mit Python 3.*
Lambda-Funktionen
Das zweite Bausteinchen für das Verständnis der Filter-Funktion (Listing 1) fehlt noch. Was sind Lambda-Funktionen? Lambda-Funktionen oder auch anonyme Funktionen sind Funktionskörper ohne Namen. Diese nehmen in Python eine beliebige Anzahl von Argumenten an und führen einen Ausdruck aus – zugleich der Rückgabewert der Funktion.
Lambda-Funktionen werden gerne im Zusammenhang mit Funktionen höherer Ordnung verwendet. Die Funktion “makefilter” aus Listing 1 ist eine First Class Function, denn sie gibt eine Funktion zurück, genauer die Lambda-Funktion “lambda s,a=allchars,d=delchars: s.translate(a, d)”.
|
Listing 1: Filter-Funktion |
|---|
def makefilter(keep):
""" Return a function that takes a string and returns a copy of that
string consisting only of the characters in 'keep'.
"""
import string
# make a string of all chars, and one of all those NOT in 'keep'
allchars = string.maketrans('', '')
delchars = ''.join([c for c in allchars if c not in keep])
# return the function
return lambda s,a=allchars,d=delchars: s.translate(a,d)
|
Aber nun von Anfang an: Die Funktion “makefilter” erzeugt bei jedem Aufruf der Funktion einen Filter, der nur die Buchstaben aus “keep” passieren lässt. Der Schlüssel zum Verständnis dieses Filters ist die Funktion “translate” aus der String-Bibliothek. “s.translate(a,d)” übersetzt einerseits alle Zeichen des Strings “s” entsprechend der Übersetzungstabelle “a” und löscht andererseits die Zeichen, die sich in “d” befinden. Nun ist die Übersetzungstabelle “a” in diesem konkreten Fall “string.maketrans(”,”)” die Identität und “d” das Komplement zu “keep”. Das einzige fehlende Argument für die Lambda-Funktion “lambda s,a=allchars,d=delchars: s.translate(a,d)” ist der zu filternde String “s”. Dieser String ist das Argument für die Filter-Funktion (Abbildung 4).
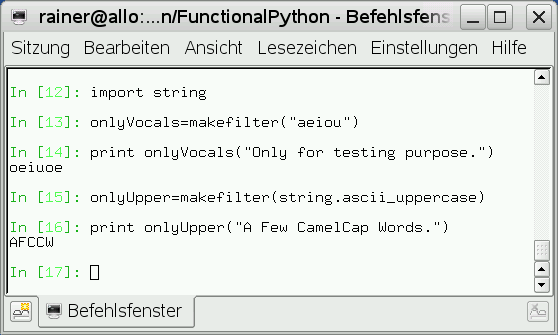
Abbildung 4: Die Filter-Funktion im Einsatz.
Generatoren
Charakteristisch für funktionale Programmiersprachen ist auch das Verarbeiten von (unendlichen) Listen. Generatoren lassen Listen leicht entstehen, da mit ihnen einfach Iteratoren über Listen erzeugt werden können. In Python ist ein Objekt dann ein Iterator, wenn er das Iteratorprotokoll umsetzt. Das Iteratorprotokoll setzt ein Objekt dann um, wenn es die Methoden “__iter__” und “next” anbietet. Während “__iter__” eine interne Methode ist, können mit “next” die Elemente des Iterators angefordert werden. Obwohl Python Generatoren seit Version 2.3 unterstützt, sind sie doch relativ unbekannt. Da Generatoren nicht nur Werte produzieren, sondern auch konsumieren können, lassen sich mit ihnen Koroutinen implementieren. Eine mächtige Verknüpfung von List Comprehension und Generatoren stellen Generator-Ausdrücke dar.
Aber nun erst einmal zu Generatoren als reine Produzenten. Der einfache Generator aus Abbildung 5 gibt auf Anfrage alle natürliche Zahlen aus.
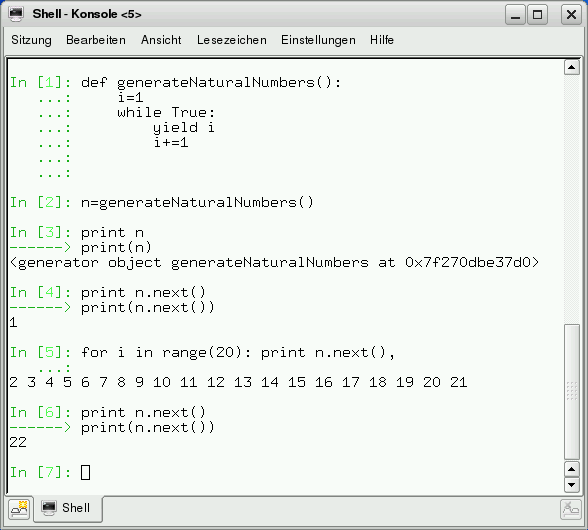
Abbildung 5: Generator für die natürlichen Zahlen.
Von der Praxis zur Theorie: Durch das Schlüsselwort “yield” wird die Funktion zu einem Generator. Die Werte des Generators lassen sich implizit durch eine Iteration über den Generator oder explizit mit der Funktion “next” anfordern. Wird beim Prozessieren der Funktion die Anweisung “yield” erreicht, wird die Ausführung der Generators einerseits eingefroren und andererseits der Wert von “yield” zurückgegeben. Die Iteration über die Werte des Generators ist mit der Abarbeitung des Funktionskörpers oder einer expliziten Return-Anweisung beendet.
In Abbildung 6 ist schön zu sehen, dass ein Generator auch endlich viele Werte erzeugen kann und dass die “next”-Funktion in Iteratorkontexten wie “for i in generatePython(): print i,” implizit aufgerufen wird.
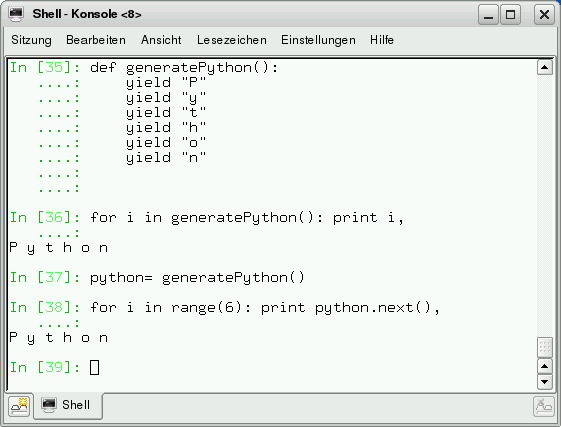
Abbildung 6: Ein endlicher Generator.
Ab Python 2.5 können Generatoren nicht nur Werte produzieren, sondern auch konsumieren. Der Generator besitzt das folgende Interface:
- next: produziere einen Wert
- send: konsumiere einen Wert
- close: schliesse den Generator
Der Generator wird zur Koroutine, denn er kann an einer beliebigen Stelle aufgerufen, verlassen oder beendet werden. Die Koroutine (Abbildung 7) unterscheidet sich nur unwesentlich zum Generator für die natürlichen Zahlen aus Abbildung 5. Durch “val= (yield i)” nimmt er Werte an, die mittels “send” an ihn geschickt werden. Falls der Generator einen neuen Wert erhält, wird in “if (val): i=val” der Rückgabewert des Generators neu gesetzt. “n.close” schliesst den Generator.
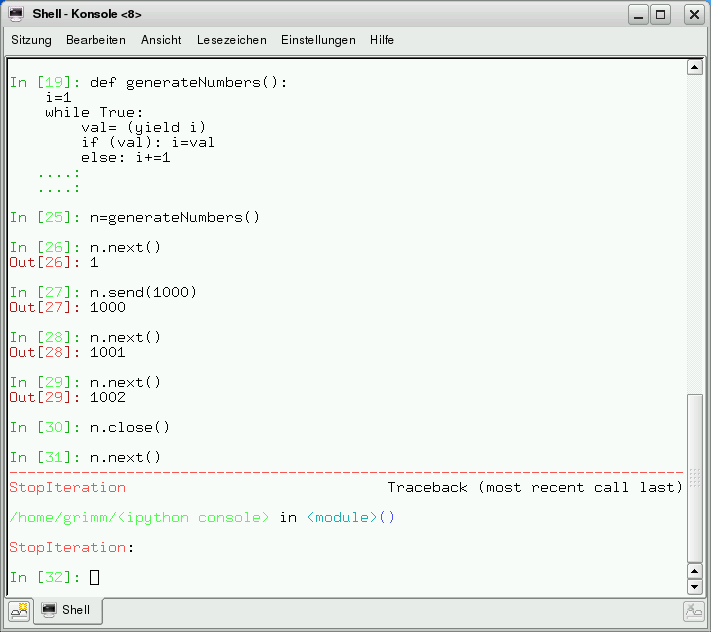
Abbildung 7: Der Generator wird zur Koroutine.
David Beazley zeigt in seinen englischsprachigen Präsentation “A Curious Course on Coroutines and Concurrency“, dass sich Generatoren sogar zum Implementieren eines Multitasking-Betriebssystems einsetzen lassen.
Generator-Ausdrücke
Generator-Ausdrücke verbinden die Funktionalität von List Comprehension mit der Bedarfsauswertung von Generatoren. Ein Generator-Ausdruck unterscheidet sich von der List Comprehension syntaktisch dadurch, das er in runden Klammer definiert wird und semantisch dadurch von der List Comprehension, das er einen Generator zurückgibt. Dadurch wird gleichzeitig die Performance des Programms erhöht und Speicherplatz gespart, denn die Werte des Generator-Ausdrucks werden erst auf Anfrage erzeugt und im Speicher gehalten, und dies auch nur soweit wie nötig (Abbildung 8).
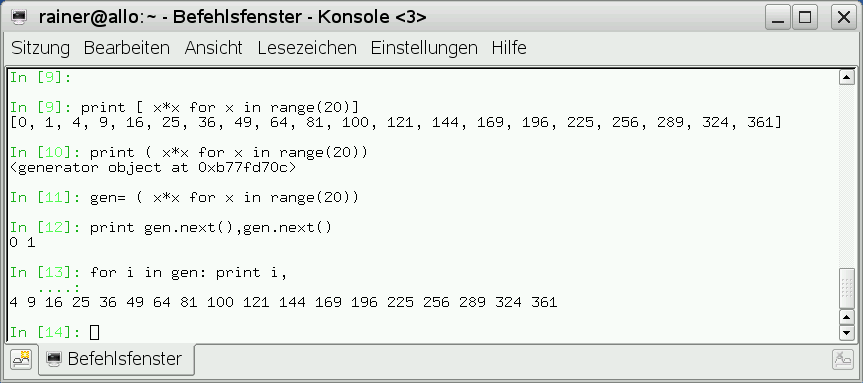
Abbildung 8: Die Werte des Generator-Ausdrucks werden erst auf Anfrage erzeugt.
Mit Generator-Ausdrücken lassen sich sehr mächtige Generatoren erzeugen, die Datenströme liefern – und das nur auf Anfrage. Dazu werden drei Komponenten benötigt: Die Funktion “generateOpenRange” (Listing 2) produziert natürliche Zahlen, beginnend mit “start” in “step”-Schritten. Ebenfalls notwendig ist ein Generatorausdruck, der die Daten aus “generateOpenRange” bearbeitet, und zuletzt noch die Funktion “takewhile” aus der Bibliothek “itertools”, die nur soviele Elemente aus dem Generator-Ausdruck ausliest, wie angefordert werden.
|
Listing 2: Unendlicher Datenstrom |
|---|
def generateOpenRange(start=1,step=1):
i=start
while True:
yield i
i+=step
|
Ein paar Beispiele in Abbildung 9 sollen dies verdeutlichen. Insbesondere zeigt das letzte Beispiel, wie sich mit “list” eine Bedarfsauswertung zur strikten Auswertung durch eine Liste transformieren lässt.
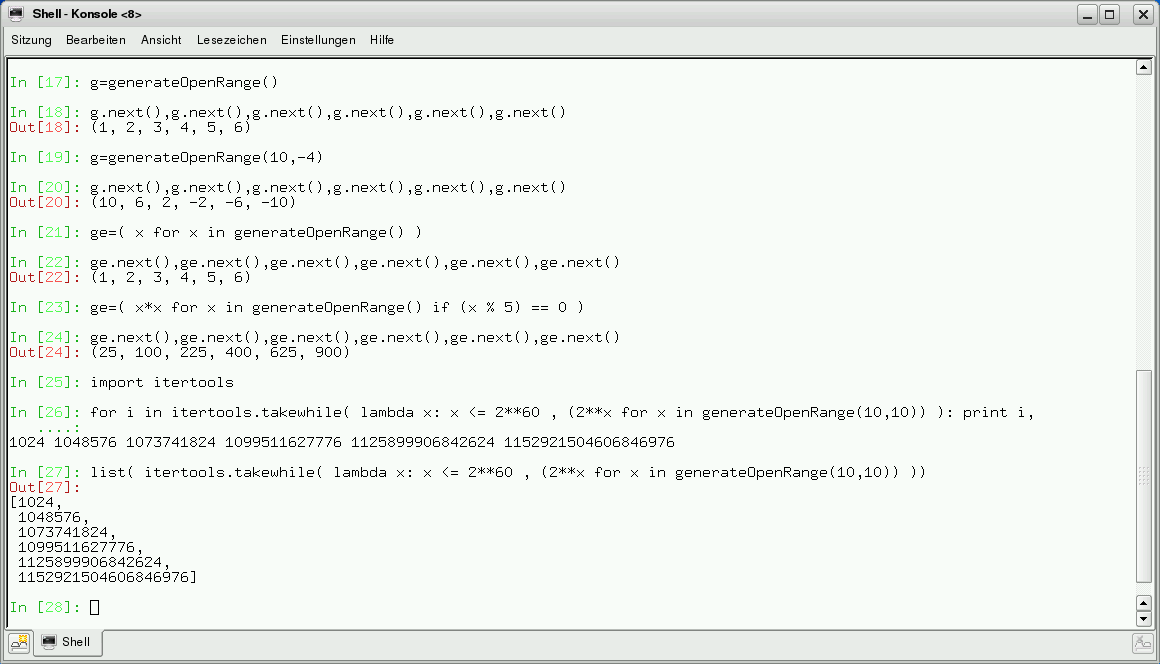
Abbildung 9: Datenströme.
Funktionen höherer Ordnung
Will der Programmierer in Python Listen verarbeiten, stehen ihm die bekannten Funktionen höherer Ordnung “map”, “filter” und “reduce” zur Verfügung. Mit ihrer Hilfe lassen sich Funktionen auf Elemente einer Liste anwenden, Elemente aus der Liste herausfiltern und Listen auf ein Rückgabewert reduzieren, indem sukzessive eine Operation auf Paare der Liste angewandt wird. Werten diese Funktionen in Python 2.* noch strikt aus, so sind sie in Python 3.* “lazy”.
Die Funktion “reduce”, die der Haskell-Funktionsfamilie “fold*” entspricht, wird in Python deutlicher seltener verwendet als in rein funktionalen Programmiersprachen. Dies ist wohl der Grund dafür, dass sie mit Python 3.* keine Built-In-Funktion mehr darstellt, sondern in die “functools” Bibliothek wandert. Ein paar Beispiele sollen den Umgang mit den drei funktionalen Built-In-Funkionen in Python verdeutlichen (Abbildung 10). Durch Lambda-Funktionen und die Bibliothek “operator”, die einen reichen Satz an Operatoren zu Verfügung stellt, lassen sich kompakte Ausdrücke formulieren.
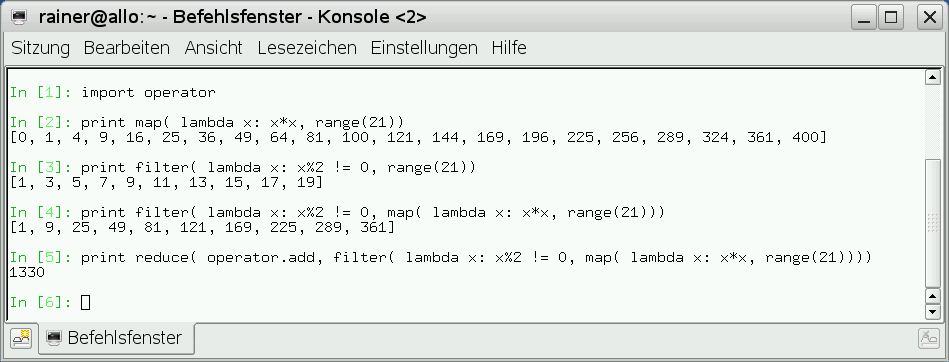
Abbildung 10: Map, Filter und Reduce in Aktion.
Ist es für eine funktionale Programmiersprache typisch, komplexe Funktionskompositionen aus elementaren Bausteinchen zu bauen, so leidet in Python die Lesbarkeit des Codes darunter, wie die Komposition der Funktionen “map”, “filter” und “reduce” zeigt. Typisch für Python Code ist es, solche Kompositionen durch List Comprehension “sum[ x*x for x in range(21) if x%2 != 0]” auszudrücken. Nun aber alles der Reihe nach.
List Comprehension
“map”- und “filter”-Ausdrücke werden in Python gerne durch List Comprehension implementiert. Eine List Comprehension besteht aus einer Menge von Sequenzen “sequence1 .. sequence2”, über die iteriert wird, einem Filter “if condition“, der die Elemente aus Menge von Sequenzen gegebenfalls passieren lässt und einem Ausdruck (“expression“), der auf die verbliebenen Elemente angewandt wird. Listing 3 enthält die allgemeine Form der List Comprehension.
|
Listing 3: List Comprehension |
|---|
[ expression for item1 in sequence1
for item2 in sequence2
...
for itemN in sequenceN
if condition ]
|
Zwar gilt List Comprehension als Syntactic Sugar zu den Funktionen “map” und “filter”, aber sie kann durchaus auch als Alternative zur Listenverarbeitung aufgefasst werden (Listing 4).
|
Listing 4: List Comprehension ausgeschrieben |
|---|
s=[]
for item1 in sequence1:
for item2 in sequence2:
...
for itemN in sequenceN:
if condition: s.append(expression)
|
Dass List Comprehension die Funktionalität von “map” und “filter” in eleganter Weise anbietet, illustrieren die nächsten Beispiele (Abbildung 11).
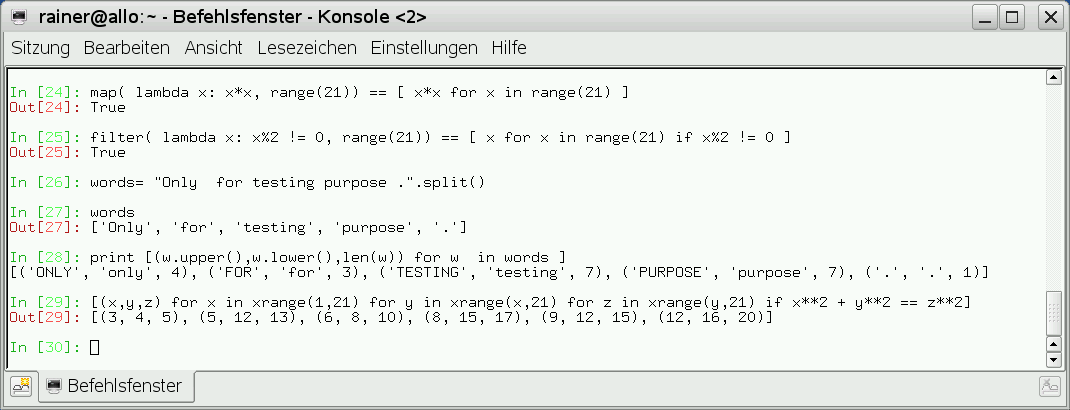
Abbildung 11: Map, Filter und List Comprehension im Vergleich.
In dem letzten Beispiel zum pythagoreischen Tripel findet eine Iteration über 3 Schleifen statt.
Der Quicksort-Algorithmus in Haskell aus dem Vorgänger dieses Artikels lässt sich auch in Python (Listing 5) elegant implementieren, vergleicht man dies mit imperativen Herangehensweisen in C++, C# oder auch Java im Algorithm-Wiki. Gleichzeitig stehen sich im Listing 6 die Implementierung des Sortierverfahrens mittels List Comprehension und “filter” gegenüber. Im Fall von List Comprehension wird das Prädikat “if lt < L[0]”, bzw. im Falle der builtin-in Funktion “filter” die Lambda Funktion “lambda lt: lt < L[0] ” verwendet, um die ursprüngliche Liste entsprechend dem Pivotelement L[0] zu sortieren. “L[1:]” ist die Liste ohne ihr erstes Element; in der funktionaler Ausdrucksweise als “tail” der Liste bezeichnet.
|
Listing 5: Quicksort mit List Comprehension und Filter |
|---|
def qsortListComprehension(L):
if len(L) <= 1: return L
return qsortListComprehension( [lt for lt in L[1:] if lt < L[0]] ) + L[0:1] + qsortListComprehension( [ge for ge in L[1:] if ge >= L[0]] )
def qsortFilter(L):
if len(L) <= 1: return L
return qsortFilter( filter(lambda lt: lt < L[0] , L[1:]) ) + L[0:1] + qsortFilter( filter(lambda gt: gt >= L[0] , L[1:]) )
|
Zip – der Reißverschluss
Ein häufiger Anwendungsfall besteht darin, eine Ausgabeliste durch Verknüpfung von Eingabelisten zu erzeugen. Dazu bietet sich die funktionale Built-In Funktion “zip” an. Sie erzeugt aus den Eingabelisten eine Ausgabeliste über Tupels, deren erste Tupel die ersten Elemente der Eingabelisten sind, deren zweites Tupel die zweiten Elemente der Eingabelisten sind und so fort. Ihre Länge entspricht der minimalen Länge der Eingabelisten.
Leider lässt sich “zip” nicht über eine Funktion parametrisieren. Hierzu kann man die Funktion “map” mit “None” als Abbildungsfunktion verwenden, aber die durch “map” erzeugte Liste besitzt die Eigenschaft, dass ihre Länge der maximalen Länge der Eingabeliste entspricht. Fehlende Elemente werden auf “None” gesetzt. Die Anwendung der anonymen-Funktion “lambda a,b,c: a+b+c” auf “None”-Argumente führt infolgedessen zu einem “TypeError” (Abbildung 12).
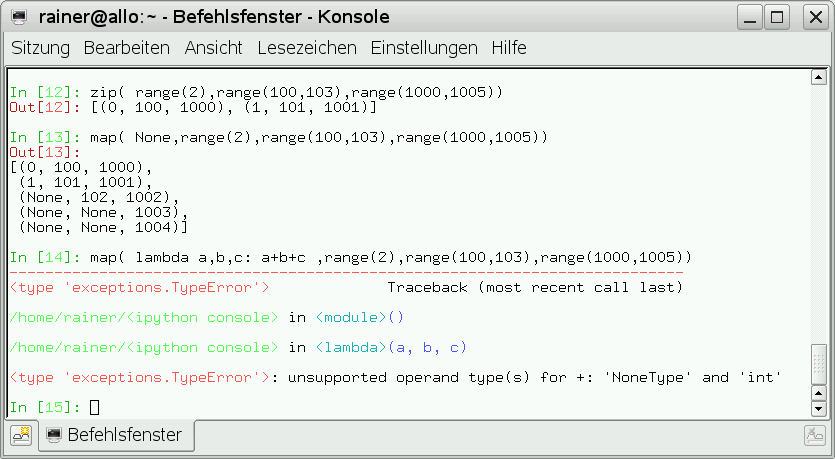
Abbildung 12: Verknüpfen von Eingabelisten mit “zip” und “map”.
Die Funktion “zipWith” (Listing 6), die die Abbildungsfunktionalität von “map” und die Verknüpfungseigenschaften von “zip” besitzt, ist schnell implementiert. Noch ein paar Worte zu der Funktion “zipWith”: Die minimale Länge über alle Listen wird durch den Ausdruck “min(map(len,args))” berechnet. Diese minimale Länge “minLength” wird in “map( lambda a : a[0:minLength],args )” verwendet, um neue Listen (“sliceArgs”), die diese Länge besitzen, zu erzeugen. Letztendlich wird die “map” Funktion über die verkürzten Eingabelisten angewandt.
|
Listing 6: Die Funktion zipWith |
|---|
def zipWith( func, *args): minLength= min(map(len,args)) sliceArgs= map( lambda a : a[0:minLength],args ) return map ( func, *sliceArgs ) |
Die Funktion “zipWith” ist wieder ein Beispiel dafür, wie aus einfachen funktionalen Bausteinen mächtige Funktionen (Abbildung 13) gebildet werden können.
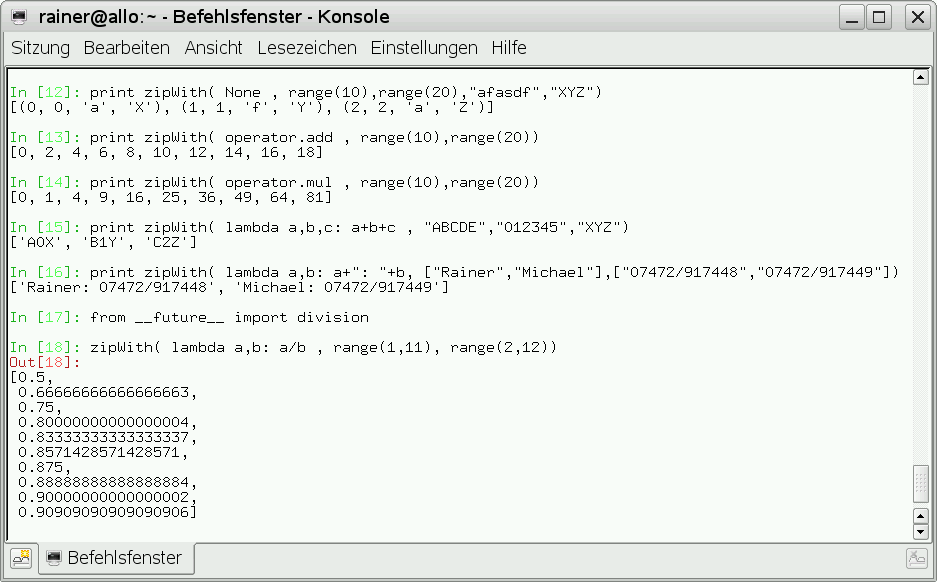
Abbildung 13: Die Funktion “zipWith” angewandt.
Bibliotheken für das funktionale Programmieren
Die Bibliotheken “operator“, “functools” und “itertools” runden das funktionale Programmieren in Python ab. “operator” enthält eine Menge von Funktionen als Operatoren, die das Verarbeiten von Sequenzen deutlich erleichtert. Die Operatoren werden dort gerne eingesetzt, wo normale oder auch anonyme Funktionen mehr Tipparbeit verlangen. Im folgenden Beispiel (Abbildung 14) werden zwei Listen zu einer neuen verknüpft. Da ein String in Python eine Sequenz von Zeichen (characters) darstellt, werden die Buchstabenpaare miteinander verglichen. Das Spektrum der “operator” Bibliothek reicht von Objektvergleichen über logische Operationen, mathematische Operationen und Sequenz-Operationen bis zu Typvergleichen. Wer es genauer wissen will, kann dies in der Operator-Dokumentation nachlesen.
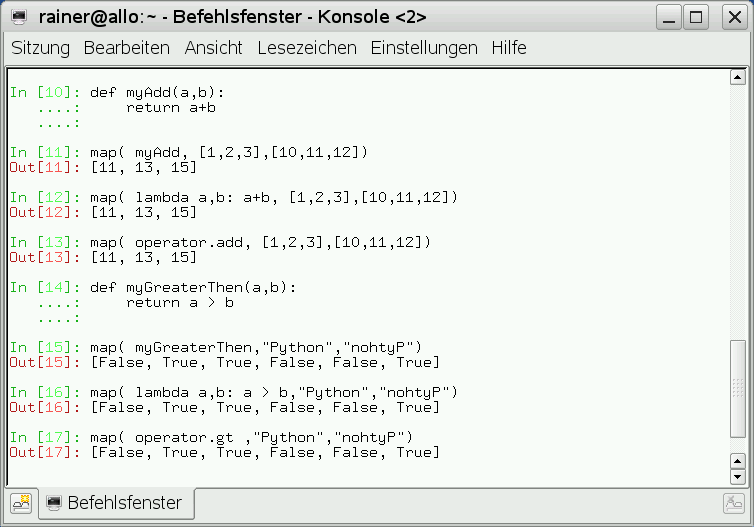
Abbildung 14: Reguläre und anonyme Funktionen sowie Operatoren.
Die “functools”-Bibliothek enthält die Funktion “partial”. Diese Funktion höherer Ordnung nimmt eine Funktion und optional deren Argumente an und gibt eine Funktion zurück, die diese Argumente bereits angewandt hat. Damit lässt sich die Funktion “myDivide” (Abbildung 15) über zwei Argumente, in zwei Funktionen über jeweils ein Argument transformieren. Der Aufruf “divide1By(3)” zeigt, das ein Aufrufargument explizit an das entsprechende Funktionsargument gebunden werden muss.
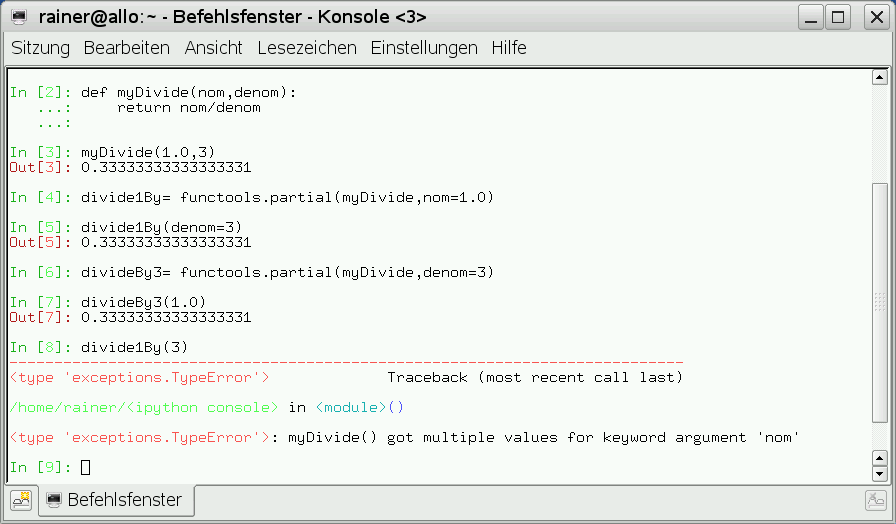
Abbildung 15: Partial Evaluation.
Die “itertools”-Bibliothek bietet einen reichen Satz an kleiner Helferlein an um aus einfachen Sequenzen mächtige Iteratoren zu bilden. Die Methoden “imap”, “izip” und “ifilter” dieser Bibliothek sind die Lazy-Pendants zu den Python 2.* built-in Funktionen “map”, “zip” und “filter” und ersetzen diese mit Python 3.*. Neben diesen Methoden, die die Elemente einer Sequenz verarbeiten, besitzt “itertools” viele Funktionen um Iteratoren über Sequenzen oder unendlichen Datenströmen zu erzeugen.
|
Iteratoren |
|
|---|---|
|
Funktion |
Beschreibung |
|
count(n=0) |
Datenstrom über die natürlichen Zahlen, beginnend bei n |
|
cycle(seq) |
unendliche Wiederholung der Sequenz |
|
chain(seq1,seq2,..) |
(endliche) Verkettung der Sequenzen |
|
islice(seq,[start],stop[,end]) |
endlicher Slice von seq |
|
tee(seq,n=2) |
Vervielfältigung der Sequenz seq |
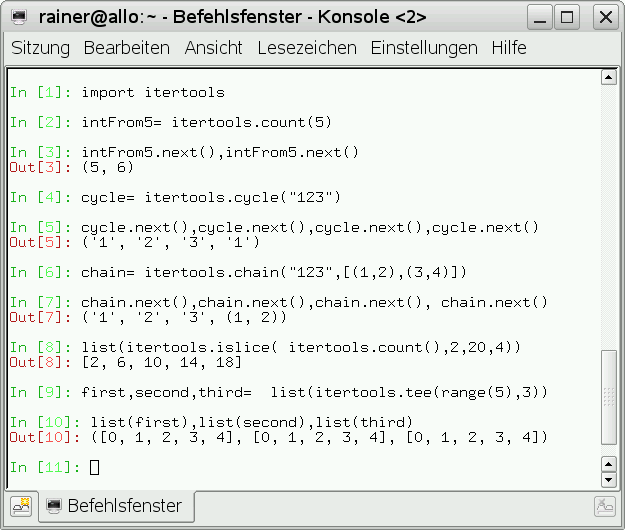
Abbildung 16: Erzeugen von Iteratoren mit Itertools.
Mit Python 2.6 bietet die “itertools” Bibliothek die drei weiteren Funktionen “product”, “permutations” und “combinations” an. Damit lassen sich bei vorgegebener Sequenz und k alle k-elementigen Teilmengen aus einer Sequenz bilden (Abbildung 17). Während “product” einen Iterator über alle k-elementigen Teilmengen erzeugt, erzeugt “permutations” nur Teilmengen, die sich nicht wiederholen. “combinations” stellt sicher, das die Teilmengen darüber hinaus sortiert sind.

Abbildung 17: Kombinationen über Sequenzen mit Itertools.
Die Dokumentation zur Itertools-Bibliothek enthält viele Rezepte rund um deren Anwendung.
Ausblick
Es bleibt spannend, wie sich die Multiparadigmen-Programmiersprache Python weiter entwickeln wird, welche funktionalen Feature von der Python Community angenommen werden. Der wohlwollende Diktator auf Lebenszeit, Guido van Rossum, stellt in dem Blogartikel “Origins of Python’s “Functional” Features” fest, dass es Python an bestimmten funktionalen Features wie endrekursiven Funktionen mangelt – stellt es fest, und stößt eine Diskussion darüber an. Es bleibt spannend.
Inspiriert durch die Funktionen höherer Ordnung “map” und “reduce” entwickelte Google 2003 das gleichnamige Framework. Die Grundidee von MapReduce ist es, das viele konkrete Probleme in den Funktionen “map” und “reduce” ausgedrückt werden können. Der Anwender definiert die Anwendungslogik in den beiden Funktionen, das Framework bietet ihm eine parallele und fehlertolerante Ablaufumgebung, die zudem auch noch für das Monitoring, die Daten-, Job- und Lastverteilung sorgt. Wie das MapReduce Framework funktioniert, für welche Anwendungen es geeignet ist und worin die Aufgaben des Anwenders bestehen, das sind insbesondere die Fragen, die in dem folgenden Artikel über MapReduce beantwortet werden. (mhu)
|
Der Autor |
|---|
|
Rainer Grimm arbeitet seit 1999 als Software-Entwickler bei der Science + Computing AG in Tübingen. Insbesondere hält er Schulungen für das hauseigene Produkt scVENUS. |





