
© Martin, Fotolia.com
In großen Netzen mit vielen Hosts und Admins stößt die klassische Nagios-Konfiguration an Grenzen. Das universelle Client-Agent-Plugin Check_mk benötigt für beliebig viele Checks nur eine Abfrage pro Client und kann die auf dem Host zu überwachenden Services automatisch erkennen.
Nagios hängt in den Seilen. Das weltweite Netzwerk des Chemiekonzerns erfordert eine fünfstellige Anzahl von Checks pro Minute, eine schier unmögliche Aufgabe für den Monitoring-Server [1]. Experten gehen davon aus, dass heutige Maschinen etwa zwei- bis dreitausend Checks pro Minute schaffen, mehr gilt als schwierig. Spätestens wenn die Überwachung eine heterogene Landschaft aus Windows-, Linux- und Unix-Servern sowie diversen Appliances umfasst, stoßen auch der Nagios Remote Plugin Executor (NRPE, [2]) und die klassischen Nagios-Strukturen an ihre Grenzen.
Pflegebedürftig
Damit nicht genug: Das Monitoring für ein derart großes Netzwerk zu konfigurieren und zu pflegen bedeutet eine Menge Aufwand. Bei Änderungen muss der Admin sowohl am Client als auch am Nagios-Server die Konfiguration von Hand aktualisieren. Sind an verschiedenen Standorten mehrere Admins im Spiel, kommt einiges an Kommunikation und Organisation hinzu, um die Einträge immer auf dem aktuellen Stand zu halten. Aufwand und Kosten steigen exponentiell mit der Anzahl der Niederlassungen, Hosts und Admins.
Deshalb fing der Münchner Mathias Kettner 2008 an, für einen Kunden ein neuartiges Nagios-Plugin zu entwickeln, das all diese Probleme auf einen Schlag lösen soll. Seit April 2009 ist seine Arbeit als Check_mk [3] unter der GPL frei verfügbar. An Dokumentation und Entwicklern fehlt es zwar eindeutig noch, doch die “gute Akzeptanz” in der Community stimmt ihn optimistisch.
Zusammengefasst
Sein Konzept ist denkbar simpel: Wie beim Nagios-Plugin Check_multi [4] tritt als Client-Agent an die Stelle zahlreicher einzelner Nagios-Checks ein einfaches Shellskript, das seine Ergebnisse per Passive Check an den Server übergibt. Pollt sein Gegenpart auf dem Nagios-Server den Client, spuckt dieser alle Ergebnisse auf einen Schlag an den Server aus (Abbildungen 1 und 2). Zusätzlich erkennt der Agent auf Wunsch selbst, welche Services auf dem Host laufen, eine Konfiguration ist nicht nötig.
Die Rechnung ist einfach: Anstelle einer Verbindung pro Check kann dieses System Hunderte von Checks mit einer Verbindung erledigen. Und weil Check_mk auf dem Nagios-Server auf Wunsch automatisch für jeden Client maßgeschneiderte, vorkompilierte Python-Programme erstellt, ergibt sich laut Entwickler ein Performance-Boost um das Drei- bis Vierfache im Vergleich zum normalen Nagios-Setup, bei dem der Server auf Dauer immer länger werdende Konfigurationen parsen muss.
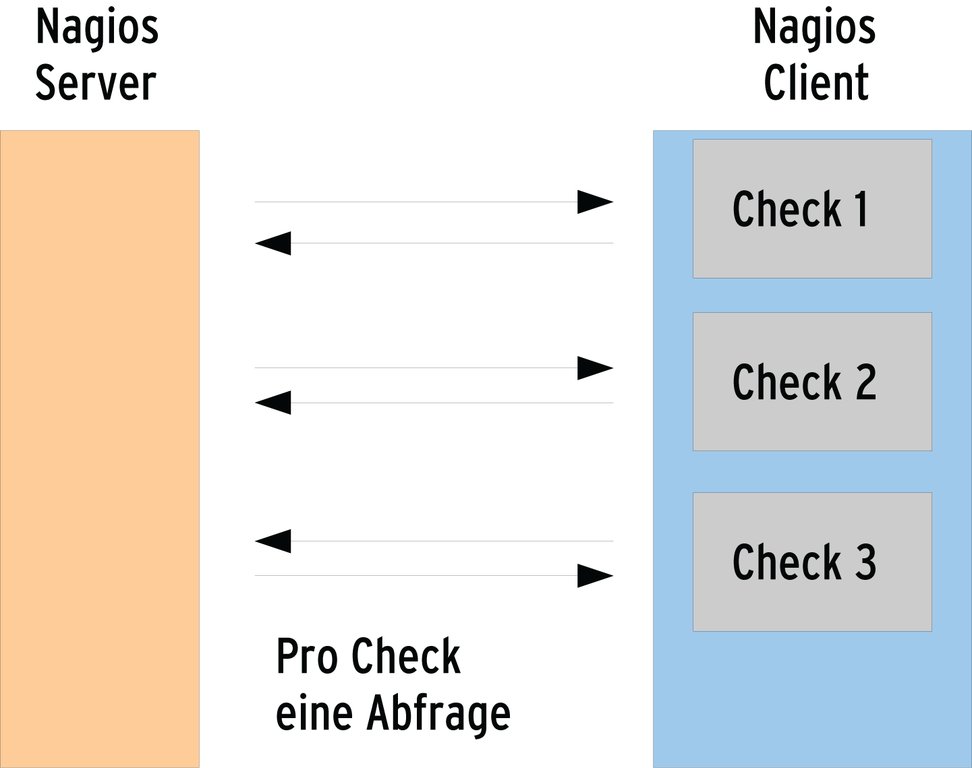
Abbildung 1: Wenn Nagios seine Hosts abklappert, ist pro Check eine Verbindung notwendig.
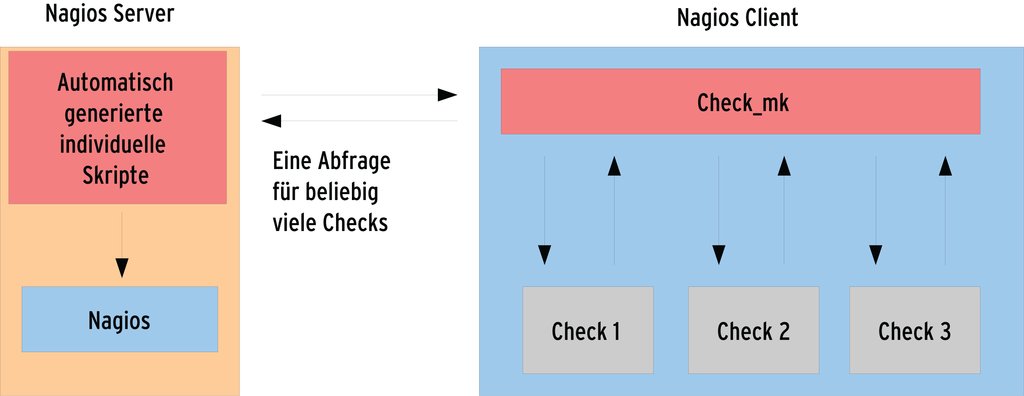
Abbildung 2: Der Check_mk-Agent übermittelt Hunderte Ergebnisse auf einmal, auf dem Server erledigt für jeden Host ein individuelles Python-Programm die Auswertung und übergibt die gesammelten Daten.
Agenten-Schule
Die Idee für den eigenen Agenten erhielt auch Anschub durch diverse Probleme mit Clients. Unter Windows erwies sich immer wieder die begrenzte Skriptfähigkeit als Hemmschuh, der Standard-Client »nsclient.exe« ist unter anderem deshalb ein fest kompiliertes Programm.
Bei NRPE muss der Admin auch auf dem Client in zwei Konfigurationsdateien (»services.cfg« und »checkcommands.cfg«) die zu prüfenden Checks eintragen. Außerdem gibt es laut Entwickler mit diversen Unix-Plattformen immer wieder Probleme. Mit Check_mk dagegen kann der Admin die Nagios-Plugins »check_by_ssh« und »check_snmp« ablösen und beliebige lokale Checks [5] auf den Clients integrieren, wenn er eine individuelle Konfiguration doch wünscht.
Auf Windows kommt zwar auch Check_mk wegen der Entscheidung, das Win32-API zu nutzen, auch nicht um einen fest kompilierten Client herum, bleibt damit aber unabhängig von irgendwelchen Laufzeitumgebungen, Java oder Dotnet. Auf allen anderen Plattformen ist der Agent jedoch ein einfaches, anpassbares Shellskript, ganz getreu der typischen Unix-Tradition. Die wichtigsten erlaubten Optionen zeigt Tabelle 1.
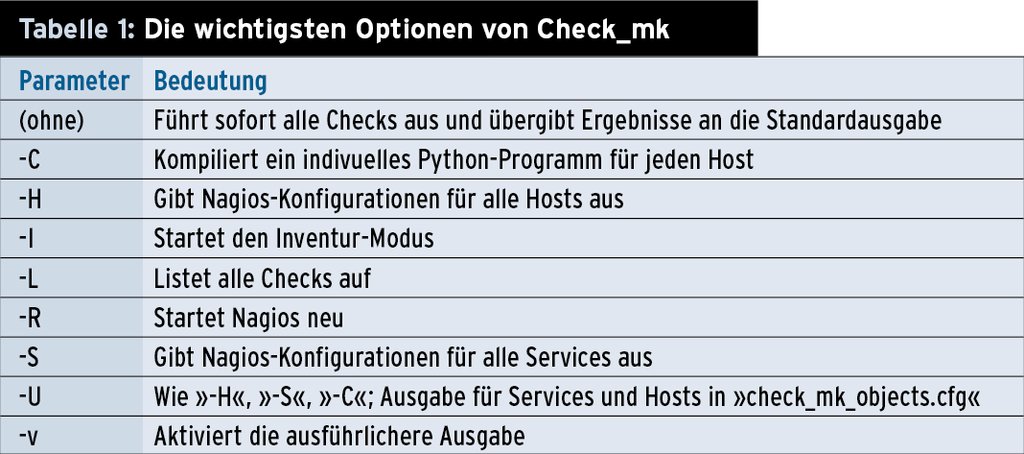
Die wichtigsten Optionen von Check_mk
Hürdenlauf Installation
Die Testinstallation gestaltete sich aber nicht so problemlos wie erwartet. Das Testsetup aus mehreren realen und virtuellen Linux-Maschinen, verteilt über verschiedene Hosts, wartete mit keiner topaktuellen Linux-Distribution auf und erforderte einiges an manueller Nacharbeit. Auf aktuellen Systemen soll das laut Doku besser laufen, aber auch der Versuch mit einem aktuellen Debian-System konnte das nicht bestätigen.
Pflichtgemäß erkannte das Autodetect-Feature bei der Testinstallation alle notwendigen Pfade. Allerdings meldete der Nagios-Server nach Abschluss der Installation und Restart des Dienstes einen Fehler. Der ließ sich nur manuell durch die Aufnahme der beiden Dateien »checkcommands.cfg« und »check_mk_templates.cfg« in die Plugin-Sektion der »nagios.cfg« beheben. Auch sollte Nagios die Datei »check_mk_objects.cfg« automatisch laden, was in der Testinstallation jedoch nicht der Fall war. Erst die folgenden Zeilen brachten die Lösung:
cfg_file=/usr/local/nagios/etc/checkcommands.cfg cfg_file=/usr/local/nagios/etc/check_mk_templates.cfg cfg_file=/usr/local/nagios/etc/check_mk_objects.cfg
Von den Testern des Linux-Magazins befragt, fixte der Entwickler dieses Problem sogleich, neue Versionen ab 1.0.35 prüfen jetzt automatisch, ob ein Konfigurationsverzeichnis vorhanden ist, und integrieren es. Viele Nagios-Anwender bevorzugen ohnehin die dafür nötige Direktive »cfg_dir« statt vieler einzelner »cfg_file«-Anweisungen.
Die Install-Guides erwiesen sich an vielen Stellen als unterschiedlich exakt und unvollständig. Den Erfahrungen der Tester am nächsten kommt der Turbo-Guide, der ganz nebenbei der kompakteste ist. Der Quickstart-Guide dagegen bietet außer zahlreichen redundanten Informationen wohl keinen zusätzlichen Nutzen. Das Problem Dokumentation ist bekannt, die vorhandenen Informationen sind im Rahmen des Projekts historisch gewachsen, gerade hier bedarf es noch des Inputs einer größeren Community.
Diskussionswürdig
Der Check_mk-Client kommuniziert mit dem Nagios-Server-Plugin über den TCP-Port 6556. Leider ist das Protokoll standardmäßig unverschlüsselt und ohne Authentifizierung. In der Konfiguration findet sich auch keine Option, um SSL zu aktivieren.
Damit entstehen verschiedene Angriffszenarien, zum Beispiel könnte sich ein Angreifer ins lokale Netz schmuggeln und einen falschen Status vortäuschen. Das Risiko hängt davon ab, was als Reaktion in Nagios konfiguriert ist: In manchen Umgebungen könnte ein automatischer Reboot des scheinbar ausgefallenen Servers eingestellt sein, vielleicht lässt sich so aber auch ein Switch lahmlegen.
Der Fairness halber sei vermerkt, dass auch die Standardtools hier nicht wirklich glänzen. Meist setzen Admins bei NRPE auf die schlichte Authentifizierung der Hosts über deren IP. Im NRPE-Security-Readme [6] schlägt Ethan Galstedt Stunnel vor, aber auch SSL- und Check_by_SSH-Konstrukte sind ebenso verbreitet. Besser scheinen da dedizierte Managementnetze oder gar OpenVPN.
SSH mit Public Key
Dass die Projekthomepage von Check_mk ebenfalls SSH vorschlägt, liegt nahe: Dann läuft auf der entfernten Shell »check_mk_agent«, seine Ausgabe landet über einer Pipe auf der lokalen Standardausgabe. Voraussetzung dafür ist jedoch eine funktionierende Public-Key-Authentifizierung. Aber ganz so “straight-forward” wie die Anleitung auf der Homepage [7] versichert, geht es in der Praxis nicht immer: Abhängig von der verwendeten Distribution sind noch entsprechende Anpassungen in »/etc/ssh/sshd_config« nötig.
Dass die Kommandozeile »ssh -l root 192.0.2.15 check_mk_agent« jedoch Root-Zugang via SSH auf dem entfernten System erfordert, ist Diskussionen wert. Viele sicherheitsbewusste Admins unterbinden den direkten Root-Access über SSH, zum Beispiel weil die Logins über den Umweg eines lokalen Users nachvollziehbarer sind. In vielen Fällen verbietet schon eine Security Policy im Unternehmen derartige Konstrukte.
Als kleinen Ausweg empfiehlt die Webseite die SSH mit Command-Restrictions zu konfigurieren. Dabei verknüpft der Admin einen Befehl mit einem SSH-Key, sodass nach dem Login nur das spezifizierte Kommando ausführbar ist. Auch hier ist die Online-Doku nicht vollständig, in den Beispielen für die Konfigurationsdateien fehlten teilweise einige Zeilen. Für den geübten Admin sind das kleine Hürden, die aber den Vorgang unnötig umständlich und die Fehlersuche lästig machen.
Tunnelbau
Technisch günstiger scheint es ohnehin, statt der entfernten Befehlsausführung über SSH einfach einen SSH-Tunnel zu graben, zum Beispiel mit »ssh -L 65015:192.0.2.15:6556 192.0.2.15 -l check_mk_user«. Dann kann Check_mk über »localhost:65015« auf den entfernten Rechner durch den SSH-Tunnel geschützt zugreifen. Dafür braucht es auch keine Root-Rechte, ein normaler User-Account ist völlig ausreichend.
Der Haken daran: Die Nagios-Status-Seite listet dann alle Systeme als 127.0.0.1. Das macht das Ganze wenig intuitiv und die Administration aufwändiger. Für eine übersichtliche Gestaltung müssten die Entwickler noch eine zusätzliche Identifikation des Client-Agenten einbauen.
Inetd
Ebenfalls wenig elegant erschien im Test, dass Check_mk für den Agenten einen installierten Inetd voraussetzt. Das mag Geschmackssache sein, aber nicht jeder Server hat Inetd installiert, schließlich sind die (Vor-)Urteile über den Metaserver geteilt: Manche Admins halten ihn für ein Sicherheitsproblem, andere sehen ihn als Sicherheitsvorteil. Schöner wäre auf jeden Fall, wenn der Agent auch selbst in der Lage wäre, sich an einen Port zu binden. Dann wäre allen Lagern gedient und viele User bräuchten nicht eigens Inetd nachzuinstallieren.
“Die Idee, den Inetd zu verwenden, entstand aus der Notwendigkeit heraus, viele verschiedene Unix-Systeme als Clients zu unterstützen”, so Mathias Kettner auf Anfrage des Linux-Magazins. “Da ist der Inetd ein Standard, der sich seit Jahren bewährt hat, und spart einiges an Aufwand. Als Umweg bot sich an, Check_mk ein beliebiges Remote-Programm ausführen zu lassen. Für einige – zugegeben uralte – VMS-Systeme mussten wir sogar noch RSH einbauen.”
Abschluss und Inventur
Die Tester des Linux-Magazins haben sowohl auf dem Nagios-Server als auch auf einigen Clients das Check_mk-Plugin eingerichtet. Nach erfolgreicher Installation passten sie die Datei »main.mk« an, und sofort erschienen die neuen Dienste im Nagios Webinterface mit dem Status Pending. Bis zum ersten Update dauerte es etwas, doch dann zeigte der Server die detaillierten Ergebnisse zu den automatisch gefundenen Diensten an (Abbildung 3). Das funktionierte auch zuverlässig und stabil, nur auf einem System nicht: Dort war Check_mk nach etwa 24 Stunden überhaupt nicht mehr Willens, Ergebnisse auszuliefern. Der Server stand im Nagios-Web-GUI auf »critical«, die Ursache blieb rätselhaft.
Wem die automatisch gefundenen Dienste des Agenten nicht reichen, der befasst sich tiefer mit der Inventory-Funktion von Check-mk [8]. Über einen Cronjob regelmäßig aufgerufen kann der Agent von selbst neue Dienste auf den Clients erkennen und einbinden. Eine Aktion des Admin ist dazu nicht nötig, eine neu eingebaute Netzwerkkarte oder Festplatte bemerkt der Agent automatisch.
Schade nur, dass er die laufenden Prozesse nicht überprüft, ein aktivierter Apache-Httpd bleibt unentdeckt, ihn muss der Admin von Hand einpflegen. Auf Wunsch ruft der Check_mk-Agent auch SNMP-Daten ab, allerdings braucht er die genaue OID. Das automatische Durchsuchen der kompletten MIB-Datenbank ist zwar möglich, erwies sich aber als sehr zeitaufwändig.
Zusammen mit den völlig frei definierbaren Local Checks [5] sollte somit fast alles möglich sein. Auch das schwierige Thema Logfile-Monitoring ist teilweise integriert. Der Windows-Agent liefert die Ereignisse automatisch weiter, während unter Linux mangels einer passenden Event-Klassifikation ein wenig händische Nacharbeit notwendig ist. Als Lohn winkt allerdings ein eigenes Webinterface namens »logwatch.php«, in dem der Admin Warnmeldungen überblickt und quittiert (Abbildung 4).
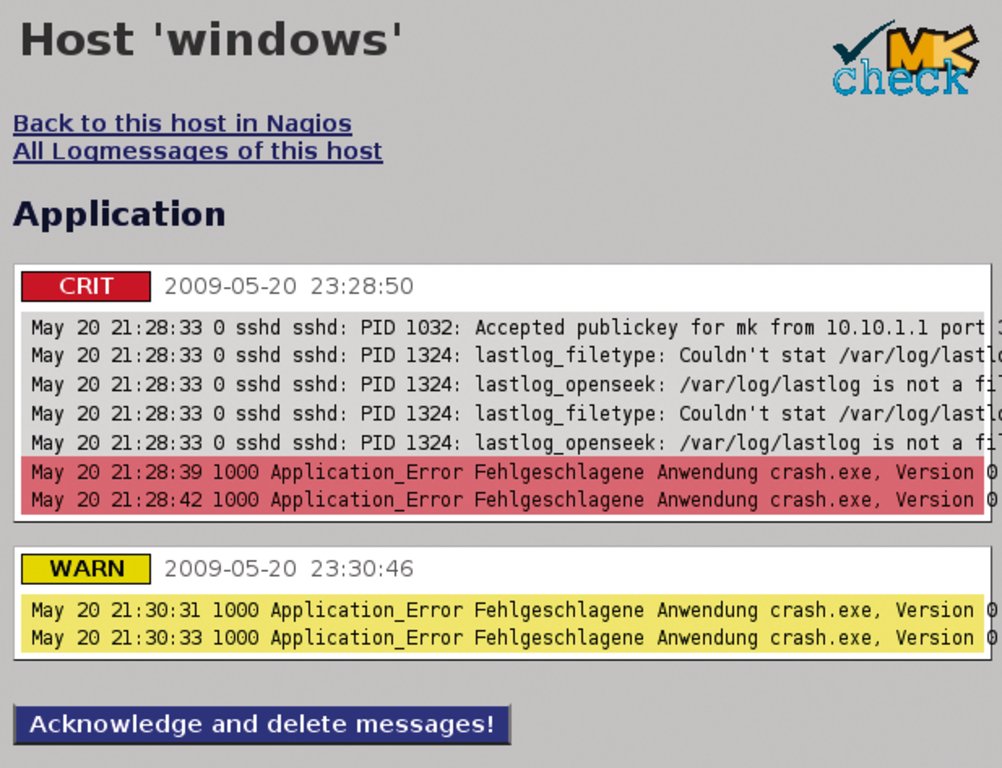
Abbildung 4: Der Windows-Agent überwacht automatisch auch Logfiles, auf Linux ist ein wenig Arbeit nötig. Zum Anzeigen und Quittieren gibt es Log_watch.php.
Jung, aber leistungsfähig
Das verbesserte Handling, vor allem mit der automatischen Inventur, dürfte dabei Check_mk auch für Admins in kleineren Netzen attraktiv machen, weil die Agents bereits in der Standardeinstellung viele Checks erledigen, für deren Konfiguration umfangreiches Know-how nötig ist.
Check_mk fehlt vor allem eine Entwickler-Community, die Ordnung in die Dokumentation bringt, beim Debuggen des jungen Projekts hilft und einige Einstiegshürden bei der Installation beseitigt. Bis dahin bleibt Check_mk erst mal ein – wenn auch sehr vielversprechendes – Ein-Mann-Projekt.
|
Infos |
|---|
|
[1] Nagios: [http://www.nagios.org] [2] NRPE: [http://www.nagios-wiki.de/nagios/howtos/nrpe] [3] Check_mk: [http://mathias-kettner.de/check_mk.html] [4] Check_multi: [http://my-plugin.de/wiki/de/projects/check_multi/start] [5] Lokale Checks: [http://mathias-kettner.de/checkmk_localchecks.html] [6] NRPE Security Readme: [http://www.ibr.cs.tu-bs.de/cgi-bin/dwww?type=file&location=/usr/share/doc/nagios-nrpe-doc/SECURITY] [7] Check_mk mit SSH:[http://mathias-kettner.de/lw_ssh_anmeldung_ohne_passwort.html] [8] Inventur: [http://mathias-kettner.de/checkmk_inventory.html] |
|
Die Autoren |
|---|
|
Dr. Tobias Eggendorfer ist in München als IT-Berater [http://www.eggendorfer.info] und Dozent tätig. Er lehrt an der Fernuniversität Hagen und forscht an der Universität der Bundeswehr in München im Bereich der IT-Sicherheit. Gerade bei seinen Testsystemen vergisst er gerne mal, Änderungen ans Nagios zu melden. Robert Koch forscht ebenfalls an der Universität der Bundeswehr an Sicherheitsfragen. Böse Zungen behaupten von ihm, dass er sogar im Schlaf seine Nagios-Konsole im Auge behält. Wenn er nicht gerade von Fehlermeldungen träumt, beschäftigt er sich mit künstlicher Intelligenz und Netzwerksicherheit. |






