
© photocase.com
3, 4, 8, 11 – nur wer den dahintersteckenden Algorithmus errät, weiß die nächste Zahl. Doch neuronale Netze setzen Reihen auch fort, ohne den Rechenweg zu kennen – näherungsweise, quasi aus dem Bauch heraus. Sie gleichen damit dem menschlichen Gehirn, dessen Architektur ihr Vorbild ist.
Für viele scheinbar triviale Probleme lässt sich nur schwer ein mathematischer Lösungsweg finden. Wer eine Reiseroute durch vorgegebene Städte oder das Layout einer elektronischen Schaltung optimieren will, muss sich mit dem Durchprobieren und Bewerten von Alternativen behelfen. Da die Zahl der möglichen Lösungen für eine Route durch vorgegebene Punkte der Fakultät ihrer Anzahl entspricht, scheitert eine exakte Lösung trotz optimierter Algorithmen leicht am Aufwand.
Wesentlich schneller geht es mit Augenmaß. Wenn ein Mensch nach Gefühl eine Route in die Landkarte zeichnet, findet er eine gute Lösung (wenn auch nicht unbedingt die beste), auch ohne über Optimierungsalgorithmen nachzudenken oder auch nur die Länge der Teilstrecken zu summieren.
Neuronale Netze sind eine Möglichkeit, Digitalerchnern solche intuitiven Lösungen beizubringen. Künstliche neuronale Netze spielen ihre Vorteile gegenüber den Verfahren, die auf Formeln und Logik basieren, immer dann aus, wenn sich der systematische Zusammenhang zwischen Eingabe- und Ausgabewerten nur unzureichend mathematisch erfassen lässt.
Intuition gefragt
Eine typische Anwendung für neuronale Netze ist die Gesichtserkennung, bei der der Rechner aus farbigen Bildpunkten trotz Rauschen oder Verzerrungen Gesichter erkennen soll. Weitere Anwendungen sind die Texterkennung oder Vorhersagen in mathematisch schwer zu fassenden Systemen, etwa der Sonnenfleckenaktivität oder Börsentrends. Neuronale Netze haben den Ruf, das Bauchgefühl eines routinierten Börsianers besser nachzuahmen als rechnerische Verfahren. Das gilt auch für die Vorhersage von Sonnenflecken, die in 22-jährigen, aber nicht vollständig regelmäßigen Zyklen auf der Sonnenoberfläche zu sehen sind. Neuronetzte sagen ihre Häufigkeit besser vorher als Berechnungen, die die Komplexität der Gasdynamik nicht vollständig erfassen können.
Dieser Artikel trainiert ein neuronales Netz für die Vorhersage der Sonnenfleckenaktivität aus den Daten der letzten 30 Jahre. Für die Implementierung des Netzes nutzt er die leistungsfähige Libfann [1]. Von praktischem Wert ist eine solche Vorhersage, weil Sonnenfleckenaktivitäten Störungen bei Funk- und Satellitenübertragungen auslösen können.
Natürliches Vorbild
Künstliche neuronale Netze (Artificial Neural Networks, kurz ANNs) simulieren die Struktur des Gehirns von Menschen und Tieren. Wie ihr natürliches Vorbild bestehen sie aus künstlichen Nervenknoten (Neuronen), die sich in ihrem Zustand über eine Vielzahl von Verbindungen gegenseitig beeinflussen. Aus der unterschiedlichen Gewichtung der Neuronenverbindungen, die den Nervenfasern im Gehirn entsprechen, ergibt sich für ein Muster an den Eingangsneuronen eines Netzes ein bestimmter Ausgangswert.
Durch ein Training, das sich in der Stärke der Neuronenverbindungen niederschlägt, lernen es neuronale Netze, Eingangsmuster mit Ausgabewerten zu assoziieren. Dabei genügt es, dem Netz einen Ausschnitt aus der Ergebnismenge zu präsentieren. Ohne dass ein konkreter Rechenweg bekannt ist, findet das künstliche Gehirn nach einer Trainingsphase dann auch Lösungen, die nicht Teil des Trainings waren.
Abbildung 1 zeigt eine Nervenzelle. Sie besteht aus dem Zellkern und vielen verästelten Ausläufern. Die so genannten Dendriten empfangen Signale von anderen Nervenzellen und leiten die elektrischen Impulse an den Zellkörper weiter. Übersteigt deren Summe einen bestimmten Schwellenwert, wird das Neuron aktiv und sendet über das Axon einen elektrischen Impuls an die mit ihm verbunden Zellen.
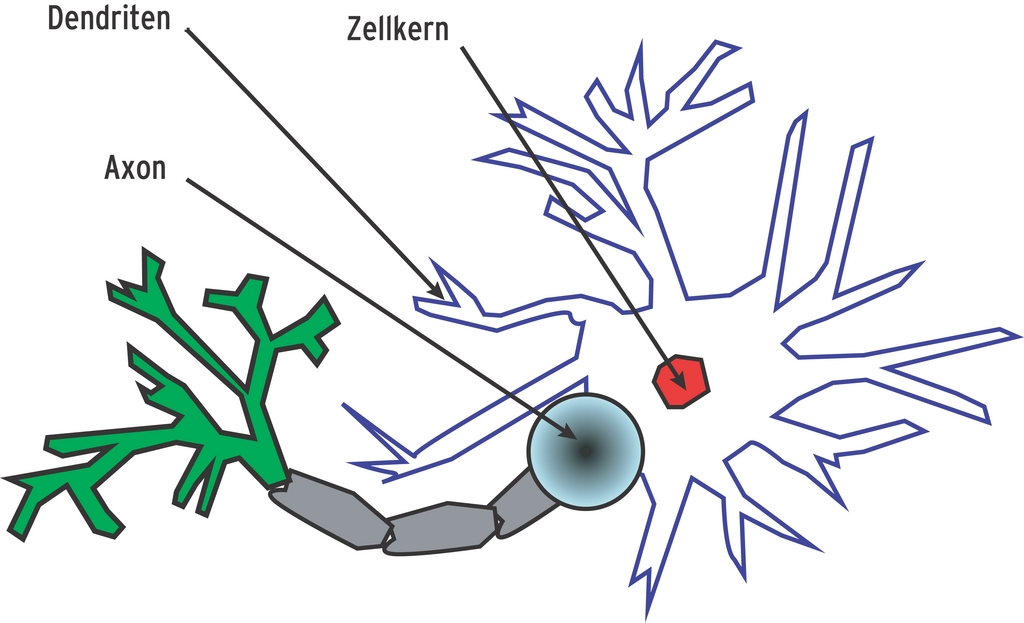
Abbildung 1: In der vielfältigen Verästelung der Nervenzellen sehen Neuro-Wissenschaftler die Basis für die Leistungsfähigkeit des Gehirns in Disziplinen wie Mustererkennung oder der Vorhersage schwer zu errechnender Systemzustände.
Ein künstliches Neuron simuliert die wichtigsten Eigenschaften einer Nervenzelle. Es summiert alle Potenziale seiner Dendriten, wendet auf diese Summe eine festgelegte Aktivierungsfunktion an und leitet das Ergebnis an alle verknüpften Zellen weiter (Abbildung 2). Jede Verbindung zu anderen Neuronen hat ein bestimmtes Gewicht und dämpft oder verstärkt das Signal auf dem Weg.
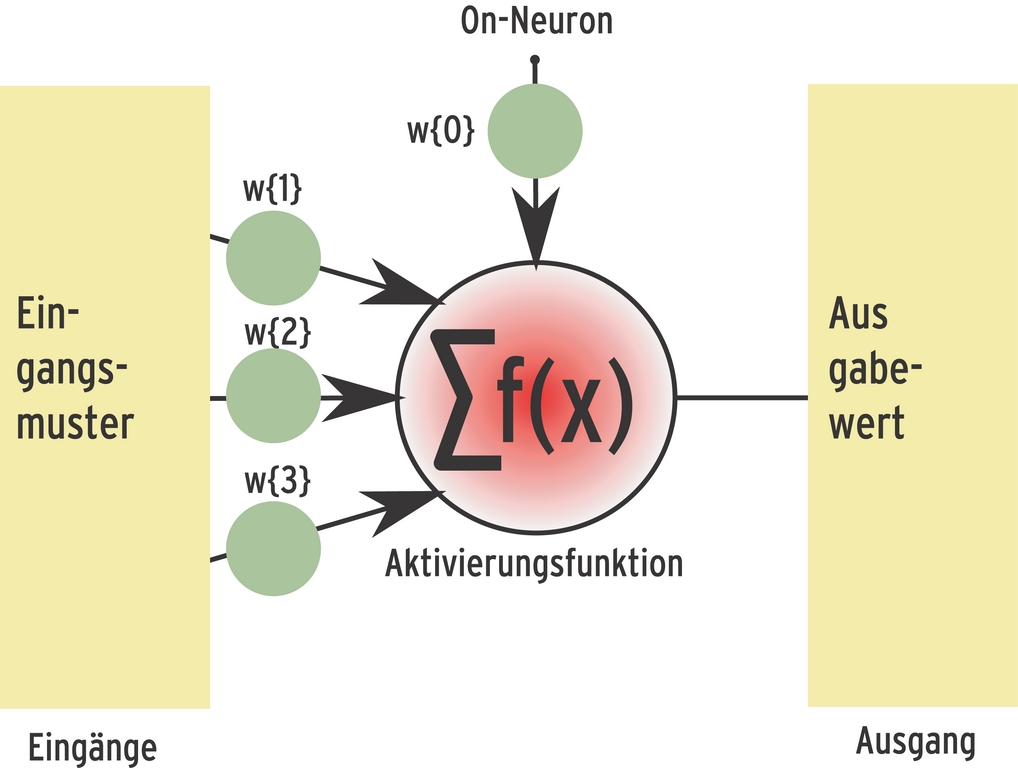
Abbildung 2: Künstliche Neuronen summieren die Reizpotenziale aller Verknüpfungen und leiten sie über gewichtete Verbindungen weiter. Die Anpassung der Verknüpfungsfaktoren verändert das Verhalten des Netzes.
Die Aktivierungsfunktion, die entscheidet, ab welchem Potenzial das Neuron aktiv wird, besteht im einfachsten Fall aus einer Schwellenwertfunktion, die eine Eins liefert, wenn die Summe aller Eingänge über einem bestimmten Wert liegt. Es ist üblich, die Aktivierungsschwelle als Neuron, das so genannte On-Neuron, darzustellen. Wie den Verknüpfungen zwischen den Neuronen lässt sich ihr eine Gewichtung zuweisen.
Schaltbild
Bestimmte Arten der Neuronen-Verschaltung ergeben Netzwerke mit unterschiedlichen Eigenschaften. Eine der einfachsten und in ihrem Verhalten am besten erforschten Netztopologien ist die des so genannten Feed-Forward Multilayer-Perceptron (MLP). Neuronale Netze von diesem Typ sind in Schichten unterteilt. Es gibt außerdem keine Feedback-Schleifen, das heißt, Aktionspotenziale pflanzen sich nur in direkter Richtung vom Eingang zum Ausgang fort (Abbildung 3).

Abbildung 3: Multilayer-Perceptrons, die Potenziale ohne Feedback-Schleifen von den Eingängen zum Ausgang weiterleiten, sind die einfachste und am besten erforschte Struktur für künstliche neuronaler Netze.
Die Fähigkeiten eines neuronalen Netzes, etwa die Vorhersage von Werten, ergeben sich aus der inneren Struktur. Folgende Operationen verändern die Eigenschaften eines ANN:
- Hinzufügen neuer Verbindungen oder das Löschen von
Verbindungen - Anpassen der Gewichte der Verknüpfungen zwischen
Neuronen - Verändern der Schwellenwerte der einzelnen Neuronen
- Hinzufügen oder das Löschen von Neuronen
Ein Training sorgt für die richtigen Gewichtungen, um eine bestimmte Aufgabe zu lösen. Dabei liegen nacheinander Eingabewerte und die zugehörigen Lösungen an den Eingangs- und Ausgangsneuronen an. Bei der Texterkennung sind dies das Bitmap eines Textabschnitts und die zugehörigen Zeichencodes. Zum Training bei Vorhersageaufgaben dienen Werte aus der Vergangenheit, zum Beispiel historische Börsenkurse oder die Sonnenfleckenaktivität der letzten Jahre. Eine Lernfunktion vergleicht Eingabe und Zielwert und verändert die Gewichtung der Neuronenverknüpfungen so lange, bis die Reaktion des Netzes der Aufgabenstellung entspricht.
In den Schädel geblickt
Ein einfaches Beispiel zeigt, was sich beim Lernen in einem Neuronetz abspielt: Ein Netz aus vier Neuronen soll den Mittelwert aus zwei den Eingangsneuronen anliegenden Zahlen bilden. Alle Gewichte der Neuronenverbindungen haben zunächst zufällige Werte (Abbildung 4). Die Aktivierungsfunktion, die die Reaktion eines Neurons auf Input definiert, lautet »f(x)=x«. Leistungsfähige ANNs benötigen komplexere Funktionen, doch für das Verständnis des Prinzips ist dies ausreichend.
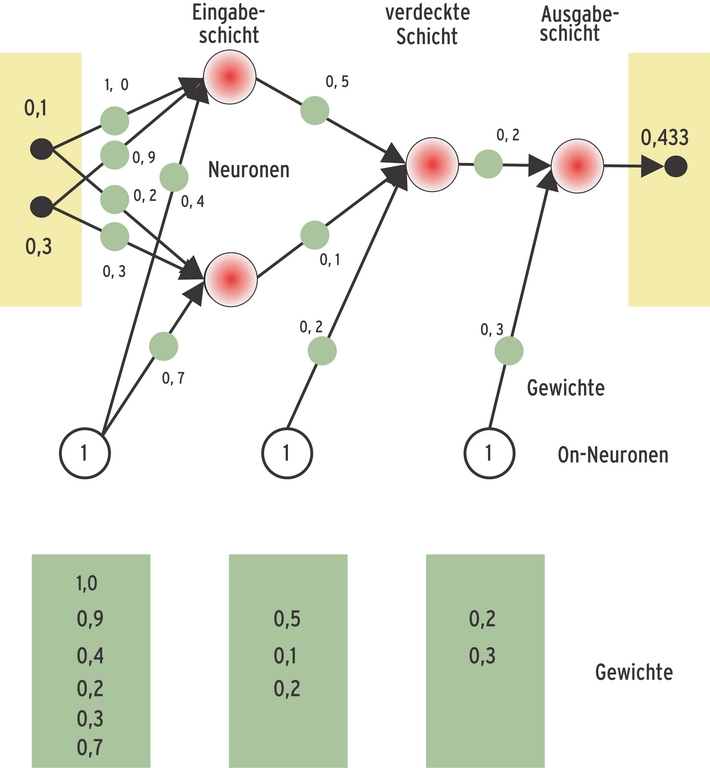
Abbildung 4: Das Verhalten eines neuronalen Netzes ergibt sich aus den Gewichtungen der Neuronen-Verknüpfungen und der On-Neuronen. Letztere entscheiden, ab welchem Reizniveau die Neuronen ihrerseits senden.
Liegen an den Eingangsneuronen die Werte 0,1 und 0,3 an, ergeben sich aus den Gewichten der Verbindungen für die Potenziale der beiden linken Neuronen folgende Werte: 0,1*1,0 + 0,3*0,9 + 1,0*0,4 = 0,77 für das erste Neuron, 0,1*0,2 + 0,3*0,3 + 1,0*0,7) = 0,81 für das zweite Neuron. Am Neuron zwischen Eingabe- und Ausgabschicht liegt der Wert 0,77*0,5 + 0,81*0,1 + 1,0*0,2 = 0,666 an. Das Ausgangsneuron liefert den Wert 0,666*0,2 + 1,0*0,3 = 0,433, der korrekte Mittelwert der Zahlen 0,1 und 0,3 wäre jedoch 0,2.
Damit das ANN richtig rechnet, sind also die Gewichtungen der Neuronenverknüpfen anzupassen. Aufschluss darüber, welches Gewicht zwischen welchen Neuronen zu korrigieren ist, liefert der so genannte Fehleranteil. Er ergibt sich aus dem Quadrat der erwarteten Ausgangswerte minus dem Quadrat der tatsächlich an den Ausgangsneuronen anliegenden Werte.
Rückwärtsgang
Zum Ermitteln des Lernfehlers bewegen sich die Daten vom Eingang zum Ausgang durch das Netz. Beim Backpropagation-Lernverfahren kehrt sich die Richtung um. Es verteilt den am Ausgang ermittelten Fehlerwert entsprechend der Gewichtung im Netz rückwärts in Richtung Eingang. Die über die Neuronen aufgeteilten Fehlerwerte bilden die Basis für die Anpassung ihrer Gewichte. Außer dem gut erforschten Backpropagation-Lernen gibt es weitere Verfahren, die für manche Anwendungen bessere Ergebnisse liefern ([2], [3], [7]).
Abbildung 5 veranschaulicht das Rückverfolgen des Fehleranteils. Das Potenzial des Ausgangsneurons entsteht aus der Summe seiner beiden Anschlüsse, der mit 0,3 gewichteten Verknüpfung zum On-Neuron und der mit 0,2 gewichteten zum Neuron aus der verdeckten Schicht. Entsprechend verteilt sich der Fehleranteil (0,433 – 0,2 = 0,233) am Ausgangsneuron auf die beiden Verknüpfungen: Auf die Leitung zum On-Neuron fallen 0,3/(0,2+0,3) = 60%, auf die Verknüpfung mit dem verdeckten Neuron 0,2/(0,2+0,3)= 40%. So lässt sich der Anteil am Gesamtfehler für jede Neuronenverknüpfung errechnen.
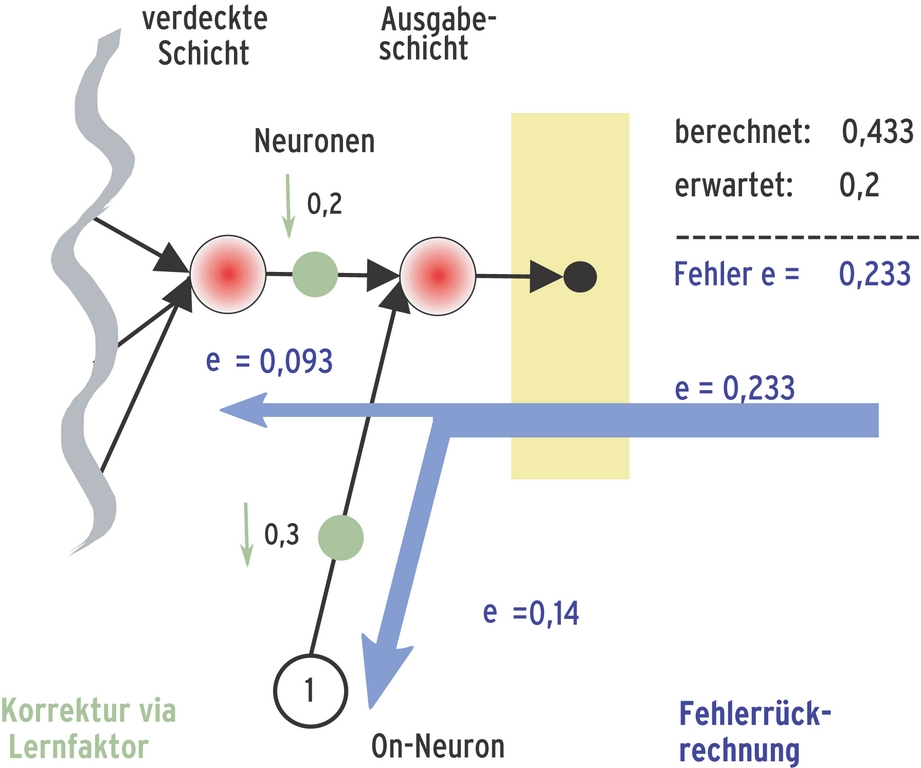
Abbildung 5: Selbstkritik: Neuronale Netze lernen, indem sie den Fehler, den sie beim Erraten eines bestimmten Wertes gemacht haben, über die gesamte Netzstruktur zurückverfolgen und je nach deren Anteil am Gesamtfehler die einzelnen Verknüpfungen der Neuronen neu gewichten. Dieser Vorgang heiß Backpropagation.
Ein Lernfaktor bestimmt schließlich, welche Veränderung an der Gewichtung der errechnete Fehleranteil bewirkt. Das Training eines ANN besteht aus vielen Feedforward- und Backpropagation-Zyklen, bei denen am Eingang und Ausgang für die zu trainierende Problemstellung zutreffende Wertepaare anliegen.
Trainingsplan
Aus der Arbeitsweise des Backpropagation-Lernens ergeben sich einige Voraussetzung für ein erfolgreiches Training. Offensichtlich dürfen Gewichte niemals null werden, da sich sonst Fehler nicht mehr zurückrechnen lassen. Negativ auf die Lernleistung wirkt es sich aus, wenn die Gewichtsverteilung zu gleichmäßig oder zu verschieden ist. Für effiziente Netze ist es am besten, wenn sich die Signale zwar durch das gesamte Netz verteilen, sich andererseits jedoch bestimmte Bereiche des Netzes bevorzugt um bestimmte Muster kümmern.
In der Praxis kommen für die Aktivierungsfunktion der Tangens Hyperbolicus oder die Sigmoid-Funktion zum Einsatz (Abbildung 6). Das steigert die Leistung des neuronalen Netzes, da diese Funktionen große Eingangswerte stetig auf Zahlen abbilden, die auch nach der Summenbildung im Netz nicht zu groß für die Weiterverarbeitung werden.
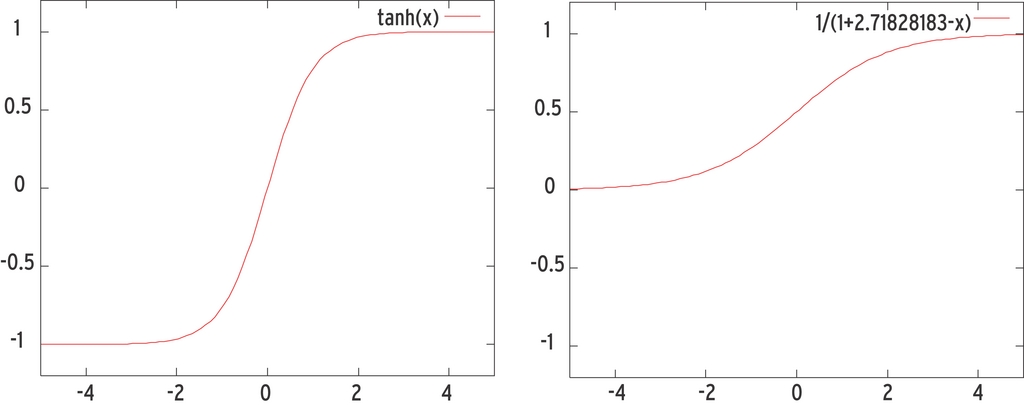
Abbildung 6: Die Funktionen »tanh(x)« und »1/(1+e-x)« eigenen sich besonders gut als Aktivierungsfunktionen für neuronale Netze, da sie bliebige Eingangswerte auf Werte mit einer absoluten Größe zwischen 0 und 1 komprimieren, die sich gut weiterverarbeiten lassen.
Voraussetzung für die Fehlerrückverfolgung ist dann allerdings eine Umkehrung der Aktivierungsfunktion [2]. Der Vorteil des Mehraufwands besteht darin, dass bereits dreischichtige Multilayer-Perceptrons beliebige Funktionen und Abbildungen erlernen können.
Berechenbare Sonne
Die NASA stellt Zeitserien für die Sonnenfleckenaktivitäten ab 1749 zur Verfügung [4]. Da die Aktivitätskurven eine Regelmäßigkeit aufweisen, die sich schwer in einer mathematischen Formel abbilden lässt, ist deren Kurzzeitvorhersage ein klassisches Anwendungsgebiet für neuronale Netze. Die Daten der NASA liegen im CSV-Format vor. Ein einfaches Perl-Skript [4] reicht aus, um sie in ein für die Libfann verständliches Format zu übertragen. Die Fast Artifical Library (Libfann, vergleiche Kasten “Die Fann-Bibliothek”) erwartet in der ersten Zeile die Anzahl der Datensätze, die Größe der Eingangsneuronen und die der Ausgangsneuronen.
|
Die Fann-Bibliothek |
|---|
|
Die Fast Artifical Neural Network Library ist eine freie und quelloffene Bibliothek, die eine C-Schnittstelle für die Implementierung von Multilayer-Perceptrons bereitstellt. Steffen Nissen hat die Bibliothek 2003 an der Universität von Kopenhagen im Rahmen seiner wissenschaftlichen Arbeit entworfen. Die Software wird aktiv weiterentwickelt. Sie stellt ein Framework für den einfachen Umgang mit Trainingsdaten bereit und läuft auf allen gängigen Plattformen. Die Libfann ist einfach einzusetzen und gut dokumentiert. Die Projekt-Homepage [1] enthält außerdem Praxisbeispiele, die den Einstieg erleichtern, und hilft bei häufig auftretenden Fragen und Problemen. Außer für C gibt es Bindings für alle gängigen Programmiersprachen. Gegenwärtig ist die Libfann eine der schnellsten Implementierungen für die Simulation neuronaler Netze. Die meisten Linux-Distributionen enthalten Libfann in Version 1.2. Das Kommando »aptitude install libfann1-dev« installiert die Bibliothek unter Debian. Die Quellen, die sich mit »configure; make; make install« bauen lassen, finden sich auf der Projekt-Homepage. |
Sie enthält für das Erzeugen, Trainieren und Nutzen eines neuronalen Netzes die Funktionen »fann_train()«, »fann_run()« und »fann_test()«. »fann_train()« erwartet als ersten Parameter eine Netzstruktur »struct fann * ann;«, die der Anwender mit dem Aufruf »ann=fann_create(connection_rate, learning_rate, num_layers,num_input, num_neurons_hidden, num_output);« erzeugt. Der richtige Wert für die Connectionrate ist normalerweise »1.0«.
Die Learningrate entspricht dem Lernfaktor und sollte zwischen »0.7« und »0.00001« liegen. Der Parameter »num_layers« sowie die folgenden Werte teilen der Libfann mit, aus wie viele Schichten das Netz besteht und wie viele Neuronen jede Schicht enthält. Für das Beispiel reicht ein dreischichtiges Netz mit 30:30:1 Neuronen (Abbildung 7). Das C-Programm unter [6] erzeugt das Neuronale Netz und trainiert es.
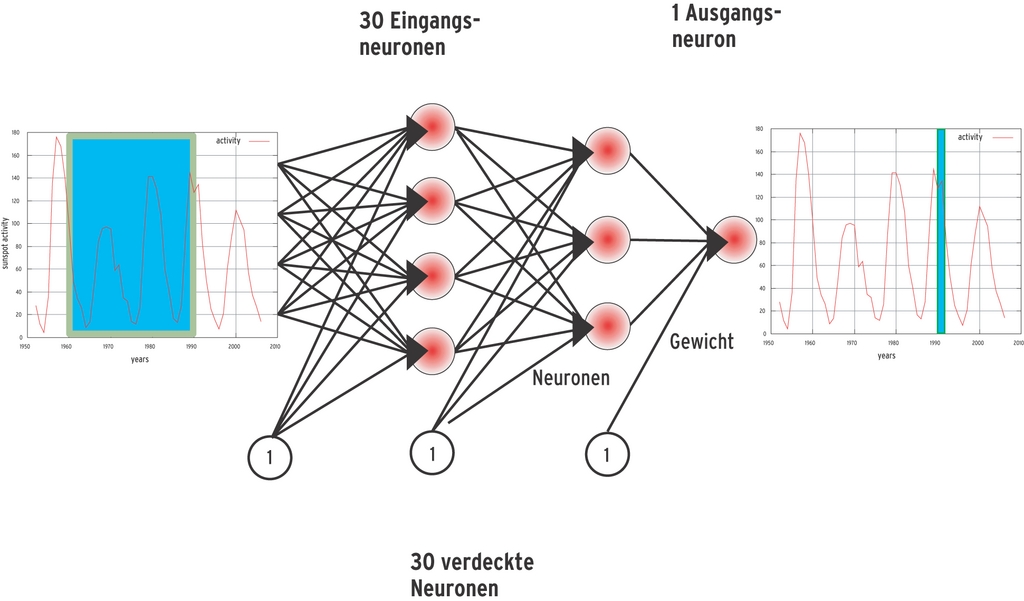
Abbildung 7: Ein neuronales Netz aus drei Schichten errechnet aus den Sonnenfleckenaktivitäts-Daten der letzen 30 Jahre, die an den Eingangsneuronen anliegen, die für das nächste Jahr zu erwartende Stärke.
Sehr menschlich
Um den Verlauf des Trainings zu verstehen und die Ursache für Probleme zu finden, sind bei neuronalen Netzen Parallelen zum menschlichen Denken hilfreich: Präsentiert das Training die Daten in chronologischer Reihenfolge, besteht die Gefahr eines Tunnelblicks. Mit anderen Worten, das ANN kodiert in seinen Neuronen lediglich die Struktur des ersten oder nur weniger Sonnenfleckenzyklen. Darunter leidet seine Fähigkeit, mit neuen Daten umzugehen. Eine Zufallsreihenfolge vermeidet diese vorschnelle Generalisierung. Das bereits erwähnte Perl-Skript [4] sorgt für eine zufällige Anordnung der Daten.
Um beurteilen zu können, wie gut das ANN beim gegenwärtigen Trainingsstatus abstrahiert, hilft ein Rückgriff auf Datenpaare, die beim Training noch nicht zum Einsatz kamen. Das Perl-Skript unterteilt die Daten daher in zwei Teilmengen. Der bei einem solchen Test auftretende Fehler heißt Generalisierungsfehler (Mean Squared Generalisation Error, MQGE). Zusammen mit dem mittleren Lernfehler (MQLE) gibt er Aufschluss darüber, ob das neuronale Netz bereits in der Lage ist, die Zukunft vorherzusagen, oder ob es noch weiteres Training benötigt. Die Libfann liefert beide Werte über die Funktionen »fanntest(ann, inputarray, expected_outputarray)« und »fann_get_MSE()«. Schließlich speichert »fann_save(ann, filename)« die Netzstruktur und die aktuellen Gewichte.
Strukturproblem
Außer von den Daten und ihrer Reihenfolge hängt der Erfolg des Trainings auch von einer für die Aufgabenstellung geeigneten Netzstruktur ab. Deren Aufbau beginnt mit der Wahl der richtigen Aktivierungsfunktion. Als Standardeinstellung bietet die Libfann die Sigmoid-Funktion an. Sie ist für die Vorhersage der Sonnenfleckenaktivität geeignet, da sie stets Werte größer oder gleich null ergibt. Für Börsenkurse und andere Zeitreihen dagegen, die negative Werte enthalten, wählt »fann_set_activation_function_output(ann, FANN_SIGMOID)« die Tangens-Hyperbolicus-Funktion.
Wenn bis dahin der Lernfehler nicht kontinuierlich sinkt, ist das Netz in einem lokalen Minimum stecken geblieben. Seine Leistung wird sich beim Training vermutlich nicht weiter verbessern. In diesem Fall sollte der Anwender das Training mit einem kleineren Lernfaktor neu starten und eventuell die Netzstruktur verändern. Ein Blick in die mit »fann_save« gespeicherte Datei kann Aufschluss über die Ursache geben, warum sich die Leistung eines Netzwerks im Training nicht weiter steigert: Einzelne Neuronen mit zu großer Gewichtung blockieren oft das Lernen.
Sobald der Fehler wie in Abbildung 8 stetig sinkt, wird es Zeit für einen Blick auf den Generalisierungsfehler. Weist dieser einen glatten Verlauf auf, steht es meist schlecht um die Vorhersageleistung. Das Netz hat dann sozusagen die trainierten Wertepaare auswendig gelernt und kommt mit unbekannten Eingabewerten nicht zurecht. Abhilfe schafft, die Zahl der versteckten Neuronen zu verringern. Bleibt der Generalisierungsfehler aber konstant hoch, ist die Zahl der versteckten Knoten zu klein oder das Training war noch nicht intensiv genug. Details liefert der Kasten “Training des Sonnenfleckenprädiktors”.
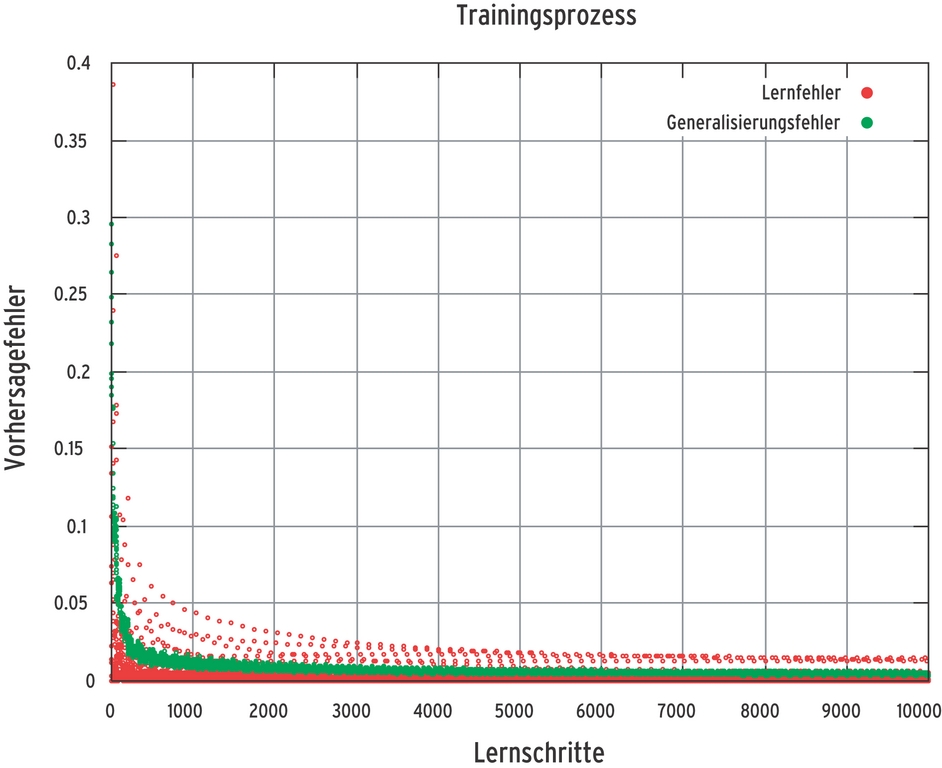
Abbildung 8: Bei einem erfolgreichen Training sinkt der Lernfehler (MQLE) stetig. Außerdem lernt das neuronale Netz immer besser, von einzelnen Werten zu abstrahieren, was sich im sinkenden Generalisierungsfehler (MQGE) niederschlägt.
|
Training des |
|---|
|
Das Multilayer-Perzeptron ist in erster Linie ein Musterlerner. Es lernt nur, wenn das Training ihm wechselnde Muster präsentiert. Würde ihm das Training statt der Sonnenfleckenaktivitäten der letzten 30 Jahre nur die Jahreszahl präsentierten, würde es so gut wie nichts lernen, da es im Dateninput keine Muster entdecken könnte. Wichtig für den Trainingserfolg ist die korrekte Skalierung der Eingangs- und Ausgangswerte. Ist die Größe der Eingangswerte ungünstig, lernt das Netz nur langsam bis gar nicht. Geeignete Werte dafür liegen erfahrungsgemäß zwischen -20 und +20, also für die 30 Eingangswerte im Netz für die Sonnenfleckenprädikation bei 20/30 = 0,66. Ausgangswerte müssen bei Verwendung der Sigmoid-Funktion im Bereich zwischen 0 und 1 liegen, für die Tangens-Hyperbolicus-Funktion zwischen -1 und +1, sonst bilden sich schnell zu hohe Gewichtungen, die den Lernvorgang blockieren. Das vorliegende Beispiel zeigt, dass für die Vorhersage der Sonnenfleckenaktivität 30 Neuronen in einer versteckten Zwischenschicht eine gute Wahl sind, 15 Neuronen erfassen nicht alle Feinheiten des Kurvenverlaufs. Netze mit einem versteckten Neuron können maximal eine einfache Sinusfunktion lernen. Der Lernvorgang startete mit einem Lernfaktor von 0,7. Der Generalisierungsfehler pendelte sich nach 1000 Schritten bei 0,03 ein, mit einem Lernfaktor von 0,07 sogar bei 0,02. Die folgenden optimalen Werte für das Training ergaben sich aus der Testphase: ein Lernfaktor von 0,07 sowie 30 verdeckte und 30 Eingangsneuronen, die Aktivierungsfunktion Tangens Hyperbolicus sowie eine Skalierung von 0,005. Nach etwa 10000 Lernschritten lag der Generalisierungsfehler bei 0,00371. |
»fann_load« lädt ein vorher mit »fann_save()« gesichertes Netz erneut, »fann_ run(ann, input)« gibt die Ausgabe des trainierten Netzes zurück. »train_net.c« [6] automatisiert den Test des Neuronenhirns. Abbildung 9 zeigt die Ausgabe eines erfolgreich trainierten Netzes, »run_net.c« [6] nutzt es zur Vorhersage.
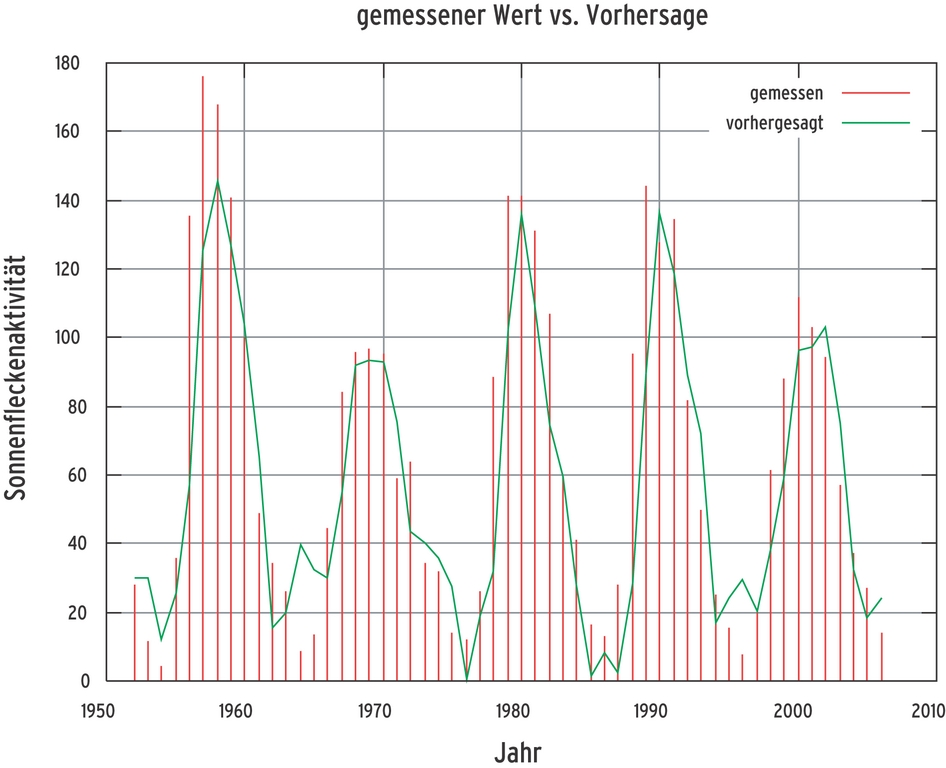
Abbildung 9: Die Zukunft im Griff: Nach einem erfolgreichen Training sagt das neuronale Netz aus den Daten der letzten 30 Jahre die für das nächste Jahr zu erwartende Sonnenfleckenaktivität mit zufrieden stellender Genauigkeit voraus.
Die Libfann in der Praxis
Die Libfann erleichtert es, ANNs aufzubauen, zu trainieren und zu nutzen. Um Details wie die Invertierung der Aktivierungsfunktion muss sich der Anwender nicht kümmern. Etwas Geduld und Erfahrung erfordert hingegen die Wahl von Parametern wie der Lernrate und der Anzahl der verdeckten Neuronen. Der Lernfehler, der Generalisierungsfehler sowie ein Blick auf die Sättigung der Neuronen liefern Hinweise, wenn das Training nicht erfolgreich verläuft.
Die aktuelle Libfann-Version 2.0 erweitert den Funktionsumfang: Viele neue Lernalgorithmen und Neuronentypen laden zum Experimentieren ein. Sehr interessant ist die Unterstützung von Cascaded Correlation Networks, die teilweise bessere Ergebnisse liefern als das klassische Multilayer-Perceptron.
Wer sich intensiver mit neuronalen Netzen beschäftigen will, findet unter [7] und [8] gute Einstiege. Bei Problemen, zum Beispiel beim Training, helfen die FAQs unter [9] weiter. Für eine intensivere Beschäftigung lohnt sich ein Blick in [2], [3] und [10]. (pkr)
|
Infos |
|---|
|
[1] Libfann: [http://fann.sourceforge.net] [2] Andreas Zell, “Simulation Neuronaler Netze”: R. Oldenbourg Verlag 1994 [3] Raul Rojas, “Theorie der neuronalen Netze: eine systematische Einführung”: Springer-Verlag 1996 [4] Perl-Skript zur Datenaufbereitung: [ftp://ftp.linux-magazin.de/pub/magazin/2007/07/neuronetz/cvs2fann.pl] [5] Sonnenflecken-Daten: http://solarscience.msfc.nasa.gov/greenwch/spot_num.txt [6] Im Artikel angeführte C-Programme für Training und Nutzung der Libfann: [ftp://ftp.linux-magazin.de/pub/magazin/2007/07/neuronetz/howto_compile.txt]] [7] Fabian Beck, Günther Daniel Rey, “Neuronale Netze – Eine Einführung”: [http://www.neuronalesnetz.de] [8] Robert Callan, “Neuronale Netze im Klartext”: Pearson Studium 2003 [9] Warren Sarle, Comp.ai.neural-nets FAQ: [http://www.faqs.org/faqs/ai-faq/neural-nets] [10] Stuart Russel, Peter Norvig, “Artificial Intelligence: A Modern Approach”: Prentice Hall, New Jersey, 1995 |
|
Der Autor |
|---|
|
Andreas Romeyke studierte Telekommunikationsinformatik und arbeitet als Software-Entwickler am Max-Planck-Institut für Neuro- und Kognitionswissenschaften in Leipzig. Er ist außerdem Gründungsmitglied der Leipziger Linux- Usergroup und der Gesellschaft für die Anwendung offener Systeme e.V. |






