
Das Programmieren von normalen und Web-Applikationen gelingt mit Python gleichermaßen gut. Die Kombination mit der relativ einfachen Syntax von MySQL hat ihren eigenen Zauber.
Eine so einfache Datenbank wie MySQL mit recht simpler Syntax ist ein guter Einstieg in die Materie Datenbank-Programmierung mit Skriptsprachen. Dieser Artikel zeigt, dass in Kombination mit der mächtigen und doch klaren Sprache Python der Umgang mit MySQL und das Entwickeln von Applikationen mit angebundenen Datenbanken leicht ist. Ein weiterer Vorteil von Python gegenüber manch anderer Programmiersprache ist die Einfachheit, mit der der Entwickler höhere Applikationsschichten wie Zope ansprechen darf.
Der Artikel erwartet von seinen Lesern Grundkenntnisse in der Programmiersprache Python, erworben vielleicht mit der Python-Artikelreihe im Linux-Magazin[1]. Nützlich, aber nicht unabdingbar sind MySQL- oder SQL-Grundlagen, zum Beispiel aus[2].
Wie fast alles in Python, ist auch das Datenbank-Anbinden modulbasiert. Um das Wie des Datenbankzugriffs kümmert sich in der Python-Entwicklergemeinde eine von diversen Special Interest Groups (SIG)[3], die sich – wenig überraschend – DB-SIG nennt. Die Gruppe hat vor allem eine einheitliche Schnittstelle für den Zugriff von Python auf beliebige Datenbanken entworfen[4], das so genannte DB-API (Applikations-Programmierschnittstelle). An diese Spezifikation halten sich so ziemlich alle Python-Datenbankmodule.
Python und MySQL |
|
Den Zugriff auf Datenbanken regelt unter Python das DB-API. Damit steht eine einheitliche und relativ gut verständliche Form des Zugriffs zur Verfügung, die der Wiederverwendbarkeit des Quellcodes zugute kommt. Spezielle Lösungen abstrahieren den Umgang mit der Datenbank so weit, dass diese sich transparent in gewohnte Python-Datenstrukturen einpasst. |
Ein Modul für den Zugriff
Das verbreitetste dieser Module für den Zugriff auf die MySQL-Datenbank ist MySQLdb, das seit neuestem auch unter dem Namen MySQL-Python firmiert[5]. Wie bei Python-Modulen allgemein üblich, muss MySQLdb zunächst per »import MySQLdb« in den Python-Namensraum importiert werden. Das weitere Vorgehen ist durch das DB-API standardisiert:
connection = MySQLdb.connect(
host="mein.db.rech.ner",
db="datenbank",
user="fionn", passwd="geheim"
)
Falls danach die Verbindung zum Server mit der Datenbank namens »datenbank« unter der Benutzerkennung »fionn« und mit dem Passwort »geheim« korrekt aufgebaut werden konnte, haben wir mit »connection« nun ein Verbindungsobjekt. Dieses Objekt stellt eine ganze Reihe grundlegender Datenbankfunktionen zur Verfügung:
- »commit()«: Falls die MySQL-Datenbank Transaktionen unterstützt, wird hiermit eine Transaktion ausgeführt – andernfalls ist diese Funktion wirkungslos. Transaktionen sind ein Datenbankmechanismus, der mehrere Datenbankzugriffe zu einer so genannten Transaktion zusammenfasst und erst am Ende aller Zugriffe die Änderungen in einem Zug in die Datenbank überträgt.
- »rollback()« macht im Falle unterstützter Transaktionen die aktuelle Transaktion rückgängig. Andernfalls tritt ein Fehler auf.
- »cursor()« gibt dem Benutzer einen so genannten Cursor zurück, also ein Objekt, das die eigentlichen Zugriffe auf die Datenbank ermöglicht. Da MySQL (anders als viele größere SQL-Datenbanken) keine Cursors kennt, werden sie vom MySQLdb-Modul emuliert.
- »close()« beendet die Verbindung zur Datenbank.
Da nur spezielle MySQL-Tabellentypen Transaktionen unterstützen, ist hier nur die »cursor()«-Funktion interessant. »connection.cursor()« erzeugt ein solches Cursor-Objekt. Das wiederum stellt neue Methoden zur Interaktion mit der Datenbank bereit:
- »execute(anfrage)« führt eine Datenbankanfrage durch. Die Funktion gibt die Anzahl der von der Anfrage betroffenen Datensätze zurück.
- »fetchone()« liefert genau eine Zeile eines Anfrage-Ergebnisses.
- »fetchmany( n)« übergibt n Zeilen eines Anfrage-Ergebnisses. Fehlt n, liefert Fetchmany normalerweise 100 Zeilen. Diese Zahl ist durch das Attribut »cursor.arraysize« beeinflussbar, etwa mit »cursor.arraysize = 200«.
- »fetchall()« liefert alle Ergebnisse einer zuvor durchgeführten Datenbankanfrage.
- »info()« gibt Informationen über die zuletzt durchgeführte Datenbankanfrage zurück.
- »close()« schließt sozusagen den Cursor. Er kann nicht weiter verwendet werden.
Zuerst ist zu klären, wie so eine Anfrage an die MySQL-Datenbank aussehen muss. Angenommen die Datenbank enthält eine Tabelle namens »Adressen« für Adressen von wichtigen Mitbürgern. Wer die Beispiele nachvollziehen will, findet im Kasten “Beispieltabelle” Anweisungen für das Anlegen der Tabelle.
Eine primäre Arbeit an jeder Datenbank ist es, deren Tabelle(n) mit Daten zu füttern. Das MySQLdb-Modul unterstützt »INSERT«-Statements durch sehr geschickte Nutzung von Templates, wie das Listing 1 gezeigt.
Wie das Beispiel ebenfalls verdeutlicht, muss das Template nur einmal angegeben werden, es lässt sich anschließend automatisch auf eine beliebig lange Liste von einzufügenden Datensätzen anwenden. Auch um den Typ der anfallenden Daten muss sich der Programmierer keine Gedanken mehr machen: Ob String, Integer oder Fließkomma, die Konvertierung übernimmt stets das Datenbankmodul.
Listing 1: Einfügen von Daten
cursor.execute("""INSERT INTO Adressen (Name, Strasse, PLZ, Ort)
VALUES (%s, %s, %s, %s)""",
[ ('Dr. Hans Mustermann', 'Musterstraße 13', 50823, 'Köln'),
('Peter Lustig', 'Im Bauwagen 2', 50827, 'Porz'),
('Edmund Stoiber', 'Spendensumpf 1', 47011, 'Bimbesdorf'),
('Onkel Hotte', 'Im Siff 42', 57072, 'Siegen'),
('Gerhard Schröder', 'Großmaulweg 2', 11901, 'Worthülsen') ]
)
Abfragen der Datenbank per Python-Tupel
Um nun beispielsweise nach allen in der Datenbank gespeicherten Personen zu fragen, deren Postleitzahl mit einer 5 beginnt, programmiert man einfach :
anz = cursor.execute("SELECT * FROM
Adressen WHERE PLZ LIKE '5%'")
Oft werden im Programm Details wie der gesuchte Wert in Variablen gespeichert. Darum lässt der MySQLdb-Cursor analog zum oben gezeigten »INSERT« auch Template-Konstruktionen wie die folgende zu:
suchwert = "5%"
anz = cursor.execute("SELECT * FROM
Adressen WHERE PLZ LIKE %s",(suchwert, ) )
Durch diese Art der Anfrage überlässt der Anwender dem MySQLdb-Modul die Konvertierung des Suchwerts in einen SQL-konformen String. Die DP-API-Spezifikation verlangt für diese Fälle die Übergabe des Werts oder der Werte als Python-Tupel.
Nun speichert die Variable »anz« die Anzahl der gefundenen Adressen. Der »print anz«-Befehl liefert die Zahl »3«. Um die eigentlichen Ergebnisse zu bekommen, ist eine der drei oben genannten Fetch-Methoden des Cursor-Objekts verwendbar: »cursor.fetchone()« gibt das erste Ergebnis in Form eines Tupels zurück, das beispielsweise »(233, ‘Dr. Hans Mustermann’, ‘Musterstraße 13’, 50823, ‘Köln’)« lauten kann.
Wer kennt die Namen?
Zum Glück ist hier noch leicht zu erraten, welche Bedeutung die einzelnen Felder haben. Im anderen Fällen ist das schwieriger – wenn zum Beispiel noch Kontostand und Schuhgröße als Werte in der Datenbank auftauchen. Und was könnte wohl die »223« am Anfang bedeuten? Wichtig wäre es daher, die Namen der Felder zu erfahren. Wie, das beschreibt der Kasten “Tabellen- und Feldnamen”.
Tabellen- und Feldnamen |
|
Mit dieser Anfrage sind die Namen aller Tabellen einer MySQL-Datenbank in einer Python-Liste erhältlich:
cursor.execute("SHOW TABLES")
tab_namen = map(lambda c: "%s" % c, cursor.fetchall())
Die folgende Anfrage erzeugt je ein Python-Listenobjekt, in dem die Namen aller Felder und die (SQL-)Feldtypen einer Datenbanktabelle stehen:
from string import split
tabelle = "Adressen" # "Adressen" hier nur als Beispiel
cursor.execute("SHOW COLUMNS FROM %s" % tabelle)
feldnamen = map(lambda c: "%s" % c[0], cursor.fetchall())
feldtypen = map(lambda c: "%s" % split(c[1],"(")[0], cursor.fetchall())
|
In unserem Beispiel erhält die Liste »feldnamen« folgende Werte: »[‘ID_Nummer’, ‘Name’, ‘Strasse’, ‘PLZ’, ‘Ort’]«. Das erklärt auch, was es mit der »223« des ersten Datensatzes auf sich hat: Es ist ein so genannter Index, eine jedem Datensatz zugeordnete eindeutige Nummer oder Zeichenkette. Er dient der Unterscheidung einander gleichender Datensätze. Andernfalls wäre im Beispiel ein doppelt vorhandener Hans-Mustermann-Eintrag auch nur noch im Doppel zu löschen. Darum verfügt praktisch jede SQL-Tabelle über ein entsprechendes Indexfeld.
Zurück zu den Ergebnissen und zu der Frage, wie wir an die nächsten beiden Datensätze kommen. Dazu bieten sich entweder ein zweimaliger »cursor.fetchone()«-Aufruf an oder einfach »cursor. fetchmany(2)«. Letzterer liefert die beiden nächsten Ergebnisse als Tupel zurück, im Beispiel sind das »((296, ‘Peter Lustig’, ‘Im Bauwagen 2’, 50827, ‘Porz’), (676, ‘Onkel Hotte’, ‘Im Siff 42’, 57072, ‘Siegen’))«.
Um die restlichen Datensätze abzurufen, wäre letztlich auch die Funktion »cursor.fetchall()« durchaus verwendbar gewesen. Sie fällt durch die Besonderheit auf, dass sie entweder all jene Datensätze liefert, die die beiden anderen Fetch-Methoden bisher übrig gelassen haben, oder – wenn bereits alle Ergebnisse einmal abgerufen worden sind – erneut die gesamten Ergebnisse aus der letzten Anfrage.
Weniger SQL, mehr Abstraktion
Zweifelsfrei ist die Standardisierung des Datenbankzugriffs unter Python eine gute Sache, erleichtert sie doch das Verwenden des gleichen Quellcodes für unterschiedliche Datenbanken. Das enthebt den Programmierer aber nicht der Pflicht, sich über syntaktische Besonderheiten der verwendeten Datenbank zu informieren.
So funktionieren zum Beispiel die Befehle zum Auslesen der Tabellen- und Feldnamen im Kasten “Tabellen- und Feldnamen” nur mit MySQL-Datenbanken. Das PostgreSQL-Modul würde sie trotz DB-API mit einem Fehlermeldung quittieren.
Aus diesem Grund gibt es gerade für die einfache MySQL-Datenbank auch Lösungen, die – teilweise zu Lasten der Flexibilität – versuchen, den Datenbank-Zugriff stärker zu abstrahieren und möglichst weit an das in Python gewohnte Schema anzugleichen. Sie beruhen zumeist auf dem DB-API, benötigen also ihrerseits ein Modul wie MySQLdb.
Wie bei Python-Dictionaries – dank SQLDict
Ein allgemein auf dem DB-API aufsetzendes Modul ist SQLDict von Andy Dustman[6]. Der Name SQLDict deutet den Zweck schon an: den Umgang mit SQL-Datenbanken und Ergebnissen möglichst ähnlich dem Umgang mit Python-Dictionaries zu gestalten.
Die Experimente des Autors dieses Beitrags mit diesem Modul, das seit zwei Jahren nicht mehr aktualisiert wurde (laut Maintainer ist es “Perfect in every way”), endeten allerdings in vielen merkwürdigen Fehlermeldungen seitens MySQLdb. Außerdem scheinen viele Konstrukte noch komplizierter als das DB-API selbst zu sein. Also schrieb der Autor im vergangenen Jahr ein eigenes Modul, das inzwischen in vielen seiner Programme zuverlässig seinen Dienst tut – pSQL[7].
Die Datenbankabfrage aus dem obigen Beispiel sieht mit pSQL wie in Listing 2 aus. Wer die Befehle der Reihe nach in eine Shell eingibt, kann das Beispiel leicht nachvollziehen und selber damit experimentieren, dazu muss jedoch das pSQL-Modul aus der unten angegebenen Quelle[7] installiert sein. Das Selektieren von Einträgen aus der Datenbank passiert hier in gleicher Art und Weise, wie es bei Python-Dictionaries üblich ist. Als Platzhalter fungiert allerdings das SQL-gängige »%«.
Am Anfang erzeugt das Listing mit »beispiel« ein pSQL-Datenbank-Objekt, das dann mit »print beispiel« angezeigt wird. Um nun die Tabellen von »beispiel« aufzulisten eignen sich die Funktionen »beispiel.keys()« oder »beispiel.tables()«. Das Formulieren komplizierter Map/Lambda-Ausdrücke wie in Listing 1 übernimmt das pSQL-Modul.
Wie bei hierarchischen Datenstrukturen in Python gewohnt, ist zum Zugriff auf die »Adressen«-Tabellen jederzeit »beispiel.Adressen« oder auch »beispiel [‘Adressen’]« referenzierbar. Dadurch erhält man in der Variablen »adress« ein pSQL-Tabellenobjekt, das mit »print« angezeigt wird.
Listing 2: Datenbankabfrage mit pSQL
01 python
02 >> import MySQLdb # pSQL setzt auf MySQLdb auf
03 >> import pSQL
04
05 >> datenbank = "Beispiel"
06 >> connection = MySQLdb.connect("localhost", db=datenbank)
07 >> beispiel = pSQL.pSQL(connection, name=datenbank)
08 >> print beispiel
09 <pSQL database 'Beispiel' at '0x80efacc'>
10 >> print beispiel.keys()
11 ['Adressen']
12 >> adress = beispiel.Adressen
13 >> print adress
14 <pSQL table 'Adressen' of database 'Beispiel' at '0x8100414'>
15 >> ergebnis = adress.PLZ['5%']
16 >> len(ergebnis)
17 3
18 >> print ergebnis[0]
19 { 'ID_Nummer': 233, 'Name': 'Dr. Hans Mustermann',
20 'Strasse': 'Musterstraße 13', 'PLZ': 50823, 'Ort': 'Köln' }
Suchbegriff als Schlüsselwort für die Tabellenspalte
Das Suchergebnis entsteht – wie von Python-Dictionaries gewohnt – ganz einfach durch das Angeben des Suchbegriffs als Schlüsselwort für die zu durchsuchende Datenbankspalte. Die Suche erstreckt sich im Beispiel auf alle Einträge, deren Postleitzahl mit 5 beginnt: »adress.PLZ[“5%”]«. Das Ergebnis der Anfrage ist ein Array von Ergebnisobjekten, die je einen der gefundenen Datensätze repräsentieren.
Das erste gefundene pSQL-Ergebnisobjekt zeigt »print ergebnis[0]« an. Das Ergebnisobjekt präsentiert sich genau wie ein Python-Dictionary. Jede Änderung an den Daten dieses Dictionaries wird sofort auch in die MySQL-Datenbank übertragen. Beim Schreiben von »ergebnis[0].Strasse = ‘Musterstrasse 14’« erzeugt das pSQL-Modul direkt einen entsprechenden SQL-Datenbankbefehl, der die Daten dann aktualisiert.
Darüber hinaus wandelt das Gespann aus MySQLdb und pSQL alle Datumsfelder der Datenbank transparent in »python-mx.DateTime«-Datumsobjekte um, und umgekehrt. Das Modul ist so programmiert, dass die Datenbank mindestens ein eineindeutiges Indexfeld zur Unterscheidung der Daten enthalten sollte, und findet dieses selbsttätig. Enthält eine Datenbank einmal keinen Index, dann können mehrere identische Datensätze transparent von pSQL auch durch ein einziges Ergebnisobjekt repräsentiert werden.
Gelegentlich geht der Bedarf bei Datenbankabfragen auch über das reine “Suche alle Daten mit x=y” hinaus. Dann helfen andere pSQL-Methoden weiter. Wer zum Beispiel nach mehreren Kriterien sucht, speichert Feldnamen und Suchbegriffe in einem Dictionary. Beispiel: Die Suchanfrage nach allen Einträgen aus der Datenbank, in denen im Namen “Hans” vorkommt und der Ort “Köln” ist, wäre:
ergebnis = adress.select({'Name': '%Hans%',
'Ort': 'Köln'})
Ohne besonders tief greifende Kenntnisse über SQL kommt auch folgende Anfragevariante aus:
ergebnis = adress.sql_select("PLZ > 50800
AND PLZ < 50900")
Sortieren können SQL-Profis die Adressen per SQL-Befehl (Variante 1):
ergebnis = adress.sql_select("PLZ > 50800
ORDER BY Name")
SQL-Normalos nehmen dafür Python (Variante 2):
ergebnis = adress.sql_select("PLZ > 50800")
ergebnis.sort("Name")
Bei Performance-kritischen Anwendungen ist die erste Variante zu empfehlen, da sie weniger CPU-Zeit benötigt.
Ist für einen Anwendungsfall beispielsweise nur die Liste der Namen von Interesse, ist diese jederzeit per »ergebnis.column(‘Name’)« extrahierbar. Auch das Vergleichen zweier Ergebnisse wie etwa »if ergebnis[0] == ergebnis[1]: print “gleich”« ist problemlos möglich. Die einfache Anweisung »ergebnis[0].delete()« löscht den ersten Datensatz aus Liste und Datenbank.
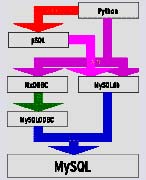
Abbildung 1: Hierarchie einiger Schnittstellen, die beim Zugriff von Python auf MySQL-Datenbanken eine Rolle spielen.
Gut für den Datenschutz – transparente Querverweise
Ein besonderes Plus von pSQL ist die transparente Behandlung von Querverweisen zwischen Tabellen. Beispiel: Eine Datenbanktabelle enthält die Personalliste eines Unternehmens. Darin ist (wie häufig in der Praxis anzutreffen) für jeden Angestellten statt der vollen Adresse nur ein Verweis auf das Indexfeld einer gesonderten Adresstabelle in der Datenbank gespeichert. Diese Verfahrensweise vermeidet eine doppelte Datenhaltung und trennt zusätzlich die sensiblen Personaldaten von den weniger sensiblen Adressdaten.
Angenommen »personal« ist das pSQL-Tabellenobjekt der Personaltabelle, entsprechend »adress« das der Adresstabelle. Hat man mit
personal.x_ref(adress, "Anschrift", "Adresse")
der pSQL-Tabelle die Verknüpfung zwischen dem »Anschrift«-Feld der Personaltabelle und der Adresstabelle bekannt gemacht, hat jedes Ergebnisobjekt aus der Personaltabelle ein neues, virtuelles Feld namens »Adresse«.
Statt die Adresse eines Angestellten mit einer aufwändigen und unübersichtlichen Konstruktion wie
>> ergebnis = personal.Gehalt[100000]
>> print ergebnis[0].Anschrift 233
>> anschrift = adress.ID_Adresse[103]
>> print anschrift [{ 'ID_Adresse': 233,
'Name': 'Dr. Hans Mustermann', 'Strasse':
'Musterstraße 13', 'PLZ': 50823, 'Ort':
'Köln' }]
zu ermitteln, reicht dank der Verknüpfung des »Anschrift«-Felds der Personaltabelle und der Adresstabelle zum virtuellen »Adresse«-Feld:
>> anschrift = personal.Gehalt [100000][0].Adresse
Noch eine ganze Menge anderer Ansätze bietet pSQL, die das Benutzen der SQL-Datenbank aus Sicht eines Python-Programmierers so intuitiv wie möglich gestalten, und es werden immer mehr. Trotzdem sollte es in stabilitätskritischen Umgebungen nur mit Bedacht und von gut informierten Programmierern verwendet werden.
Wer sich jedoch erst einmal an die bequeme Art der Datenmanipulation gewöhnt und sich mit den zwar nicht allzu drastischen, aber durchaus vorhandenen Einschränkungen in Sachen Geschwindigkeit und Flexibilität arrangiert hat, wird ein Werkzeug wie pSQL nicht mehr missen mögen.
Für jeden etwas
Darüber hinaus existieren spezielle Lösungen, die den Umgang mit der Datenbank so weit abstrahieren, dass kaum SQL-Kenntnisse mehr erforderlich sind und die Datenbank sich transparent in die gewohnten Python-Datenstrukturen einpassen lässt. Wie vielfältig die Ebenen sind, auf denen der Programmierer den Datenbankzugriff ansetzen kann, demonstriert das Diagramm in Abbildung 1. Damit steht dem Entwickler das Beste aus allen Datenbank-Welten zur Verfügung – schnell, professionell und flexibel. (jk)
Infos |
|
[1] “Schlangenkonserven” von Andreas Jung: Linux-Magazin 09/01 und folgende [2] “Ganz oder gar nicht” von Michael Kofler: Linux-Magazin 08/01 [3] DB-SIG: [http://www.python.org/sigs/ db-sig/] [4] DB-API: [http://www.python.org/topics/database/DatabaseAPI-2.0.html] [5] MySQLdb-Homepage: [http://sourceforge.net/projects/mysql-python] [6] SQLDict-Homepage: [http://dustman.net/andy/python/SQLDict/1.0.0] [7] pSQL-Homepage: [http://rtfm.n3.net/software/pSQL/] |
Der Autor |
|
Fionn Behrens lebt beruflich unter anderem vom Verkauf und vom Erstellen kundenspezifischer Datenbank-basierter oder -gestützter Web-Auftritte mit Python. |







Wenn ich die Beispiele so verwende bekomme ich immer eine Fehlermeldung “NameError: Name ‘cursor’ is not defined”