
© 1xpert, 123RF.com
Mit Klarheit im Inneren und einem Niedrigenergie-Ansatz nach außen schreibt die ARM-Architektur moderne Computergeschichte. Zeit für einen indiskreten Blick in britische Baupläne.
Die Anfänge der ARM-Architektur reichen zurück bis in die frühen 80er Jahre, als sich der britische Computerhersteller Acorn auf die Suche nach einem neuen Prozessor für seine Rechner machte. Der zuvor verwendete 6502 war nicht mehr leistungsfähig genug und alternative Architekturen schienen ungeeignet.
Daher entwickelte ein Team unter der Leitung von Steve Furber und Sophie Wilson eine eigene Architektur – die Acorn Risc Architecture, kurz ARM. Mitte der 80er Jahre kamen die ersten fertigen Produkte in Coprozessorkarten für Acorns BBC Micro zum Einsatz, ehe 1987 mit dem Acorn Archimedes der erste reine ARM-Rechner auf den Markt kam, dem in den nächsten Jahren weitere Geräte folgten.
Ende der 80er Jahre weckte Acorns Architektur das Interesse von Apple. Die Firma plante deren Einsatz in einem neuartigen mobilen Gerät. Acorn lagerte dafür die Entwicklung der Architektur in eine neue Firma (Advanced Risc Machines Ltd.) aus, die gemeinsam mit Apple die sechste Variante der ARM-Prozessoren entwickelte, die 1992 in Apples Stift-Handheld Newton zum Einsatz kam.
In den nächsten Jahren folgten weitere Lizenznehmer, während Acorns Rechnergeschäft immer mehr an Bedeutung verlor und die Firma um die Jahrtausendwende unterging. ARM Ltd. hingegen entwickelt bis heute die Architektur mit großem Erfolg weiter, was sowohl zu einer Entwicklung neuer Versionen der Architektur als auch zum Entwurf von Prozessorkernen und deren Anpassung an verschiedene Herstellungsverfahren führte.
Kerne versus Architektur
Die Versionen der ARM-Architektur werden mit ARMvX bezeichnet, wobei die Palette aktuell von ARMv1 bis ARMv8 reicht. Die Versionen ARMv1 (die von 1985 stammt) bis ARMv6 (die in den ersten iPhones und Androiden zum Einsatz kam) wurden dabei in den Kernen ARM1 bis ARM11 implementiert.
Mit dem Wechsel zu ARMv7 veränderten die Briten zugleich die Bezeichnungen der zugehörigen Kerne. Seitdem gibt es drei Reihen von Cortex-Kernen, deren Kürzel auch ihre Einsatzgebiete beschreiben: Cortex-Rx (Echtzeitanwendungen: geringe Latenz, Vorhersagbarkeit, geschützter Speicher), Cortex-Mx (Mikrocontroller: geringe Transistorenzahl, Vorhersagbarkeit) sowie Cortex-Ax (Anwendungsprozessoren: hohe Performance bei geringem Energieverbrauch, optimiert für Multitasking).
In Abhängigkeit vom vorgesehenen Einsatzzweck sind die Kerne sehr unterschiedlich realisiert. Von simplen In-Order-Kernen mit keiner oder einer nur sehr einfachen Pipeline in einfachen Mikrocontrollern bis hin zur komplexen Out-of-Order-Ausführung, Sprungvorhersage und spekulativer Ausführung in modernen Anwendungsprozessoren ist nahezu die gesamte Vielfalt von Beschleunigungstechniken, die auch x86-CPUs verwenden, anzutreffen.
Lizenzmodelle
Die Hardware, also konkrete Prozessoren mit diesen Kernen, fertigt und verkauft ARM Ltd. nicht selbst. Das Geschäftsmodell besteht vielmehr im Vertrieb geistigen Eigentums an Lizenznehmer [1]wie Samsung, Broadcom, Freescale oder Calxeda, wobei zwei Strategien zum Einsatz kommen: Zum einen lizenziert ARM Ltd. die Baupläne konkreter Prozessorkerne als so genannte IP Cores. Das erlaubt es Lizenznehmern, den Kern unverändert in das eigene Design eines System-on-Chip (SoC) zu integrieren. Beispiele dafür sind in sehr vielen Smartphones und Tablets zu finden. So enthält Samsungs Exynos-5-Dual-Chipsatz [2], der im Google Nexus 10 steckt, zwei Cortex-A15-Kerne. Zum anderen lässt sich auch die Architektur lizenzieren, was es ermöglicht, eigene Prozessorkerne zu entwickeln, die zur lizenzierten Version der Architektur kompatibel sind. Ein Beispiel sind die Krait-Kerne [3] von Qualcomm, die etwa Googles Nexus 4 antreiben.
ARM-Architektur
Wie die x86- wurde auch die ARM-Architektur im Laufe der Zeit erweitert, um neue Anforderungen zu erfüllen. Für jede Version der Architektur ist festgelegt, welche dieser Erweiterungen obligatorisch und welche optional sind. Die Vielfalt an Erweiterungen ist damit zwar geringer als bei x86, aber dennoch groß (Abbildung 1), weshalb der Artikel den Fokus auf die bislang meistgenutzten Architekturen ARMv4 bis ARMv7 legt. Erst ARMv8 weicht mit der Erweiterung auf 64 Bit deutlich von den Vorgängern ab – was der Artikel gegen Ende ebenfalls thematisiert.
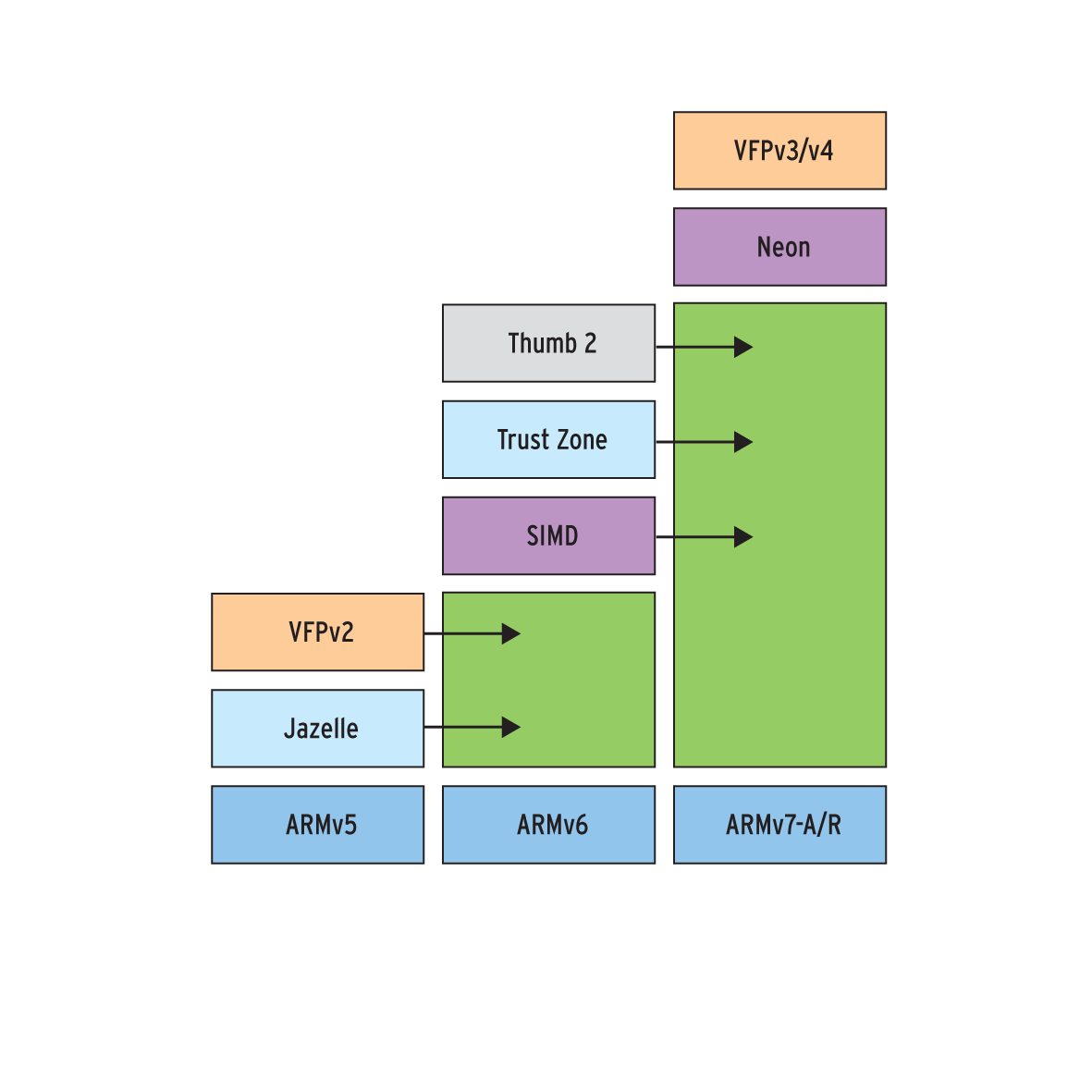
Abbildung 1: Die Evolution der Befehlssatzerweiterungen im Überblick. Die Erweiterungen sind teils obligatorisch, teils optional (Quelle: http://arm.com).
32 Bit für alles
Die ARM-Architektur wurde von Beginn an als 32-Bit-Architektur konzipiert, was sich insbesondere in der Verarbeitungsbreite von 32 Bit und der Adressierung mit 32 Bit (ab ARMv3, davor 26 Bit) ausdrückt. Daher adressiert ein ARM-Kern maximal 4 GByte Speicher, wobei die meisten Implementierungen nur einen Teil davon tatsächlich verwenden. Erst der Cortex-A15 überspringt diese Grenze mit einigen Tricks.
Wie bei anderen Prozessorarchitekturen gibt es mehrere Prozessormodi. Während ARM im User-Modus gewöhnliche Programme ausführt, kümmert sich der System-Modus um privilegierten Betriebssystemcode. Daneben existieren Modi, die zum Beispiel Ausnahmen behandeln sowie (ab ARMv7) für eine Hardware-unterstützte Virtualisierung sorgen. Eine Besonderheit der ARM-Architektur besteht darin, dass jeder Modus über spezifische Register verfügt, die das System bei einem Moduswechsel automatisch umblendet. So setzen ARM-Systeme Interrupts sehr effizient um.
Die meisten Implementierungen verfügen zudem über eine MMU (Memory Management Unit) für die Speichervirtualisierung und den Speicherschutz, manche aber nur über eine MPU (Memory Protection Unit) für die Realisierung des Speicherschutzes. Einige sehr einfache Mikrocontroller müssen ohne beides auskommen.
Der wesentliche Unterschied zu x86 besteht darin, dass ARM eine Risc-Architektur (siehe Kasten “Risc”) ist, während es sich bei x86 um einen Vertreter des Cisc-Ansatzes (Complex Instruction Set Computer) handelt. ARM setzt das Risc-Konzept sehr konsequent um, ist also eine Load-Store-Architektur mit verhältnismäßig vielen Registern und einer recht geringen Anzahl von Befehlen.
Risc
Risc (Reduced Instruction Set Computer) verfolgt die Philosophie, den Befehlssatz so einfach wie nur möglich zu gestalten und darauf zu verzichten, jeden Befehl mit vielen Adressierungsvarianten auszustatten. Der Addierbefehl einer Cisc-Maschine ist in der Lage, sowohl Register als auch Speicherinhalte direkt oder indirekt für die Operanden und das Ergebnis zu verwenden – daraus ergibt sich eine Vielzahl möglicher Kombinationen.
Risc-Maschinen verzichten auf diese Vielfalt: Arithmetische und logische Instruktionen arbeiten ausschließlich auf Registern, während der Zugriff auf den Speicher über spezielle Befehle (Load/Store) erfolgt. Das macht Programme umfangreicher, vereinfacht aber die Architektur des Prozessors deutlich. Der zusätzliche Aufwand durch das Laden in die Register besteht nur scheinbar, denn auch eine Cisc-Maschine muss zwei Speicherworte vor dem Addieren erst laden, was jedoch intern geschieht, vor dem Programmierer verborgen. In der Konsequenz haben Risc-Maschinen meist mehr frei benutzbare Register als vergleichbare Cisc-Rechner.
Für eine fiktive Maschine könnte die Addition der Speicherinhalte M1 und M2 mit Ablage des Ergebnisses in M3 wie in Listing 1 aussehen.
Listing 1
Cisc- und Risc-Addition
01 ;Cisc-Addition 02 ADD M3 M1 M2 ; M1 + M2 -> M3 03 04 ;Risc-Addition 05 LD R1 M1 ; M1 -> R1 06 LD R2 M2 ; M2 -> R2 07 ADD R3 R1 R2 ; R1 + R2 -> R3 08 ST M3 R3 ; R3 -> M3
Zusammen mit den eingeschränkten Adressierungsmodi erlaubt dies, alle Befehle mit genau 32 Bit (also einem Wort) zu kodieren und an Wortgrenzen auszurichten. Der Instruktionsdekoder lässt sich somit sehr einfach konstruieren, da es ausreicht, für jeden Befehl ein Wort aus dem Speicher zu lesen und dieses dann zu dekodieren.
Bei x86 ist der Aufwand ungleich höher, denn hier verfügen Befehle über eine Länge von 1 Byte bis hin zu 15 Byte (bei einigen Befehlssatz-Erweiterungen sind es sogar mehr), sodass der Prozessor in Abhängigkeit vom Anfang eines Befehls entscheiden muss, wie lang der Befehl wird – eine Ausrichtung an Wortgrenzen ist hier nicht möglich.
Aktuelle x86-Implementierungen lösen diese Problem, indem sie die komplexen x86-Instruktionen in einfache Risc-Instruktionen (so genannte Mikrooperationen) zerlegen und diese dann ausführen. Bei einem ARM-Prozessor entfallen solche Schritte, was sowohl den Aufwand für die Hardware als auch den Energieverbrauch senkt.
Konditionale Instruktionen
Die modusspezifischen Register treiben die Gesamtzahl der Register in die Höhe (es handelt sich etwa um 40), jedoch lassen sich in jedem Modus nur 16 Register (R0 bis R15) direkt ansprechen (Abbildung 2). Während der Programmierer die Register R0 bis R12 frei verwenden darf, dient R13 in den meisten Fällen als Stackpointer. R14 kommt als Linkregister für das Speichern der Rücksprungadresse bei Prozeduraufrufen zum Einsatz, und R15 ist der Programmzähler, auf den der Prozessor, wie auf jedes andere Register, auch direkt zugreifen kann.

Abbildung 2: Die zahlreichen ARM-Register und ihre verfügbaren Prozessor-Modi.
Der Befehlssatz selbst enthält unter Verzicht auf Redundanz die üblichen Instruktionen für arithmetische und logische Operationen, für den Zugriff auf den Speicher, für die Steuerung des Programmflusses, zur Behandlung von Ausnahmen sowie zur Steuerung der verschiedenen Modi und den Zugriff auf Coprozessoren. Die Instruktionen selbst unterscheiden sich nicht von denen anderer Architekturen, sodass der Artikel hier nur einige Besonderheiten hervorhebt.
Im Gegensatz zu den meisten anderen Architekturen, bei denen lediglich Verzweigungsbefehle eine Ausführung in Abhängigkeit von Bedingungen zulassen, ist bei ARM nahezu jede Instruktion konditional. Dazu spezifiziert der Befehlscode über eine 4-Bit-Maske, welche Bedingungen (Negativ, Null, Übertrag, Überlauf) für die Ausführung erfüllt sein müssen. Damit lässt sich sehr kompakter Code unter Vermeidung von Sprüngen implementieren (Listing 2).
Listing 2
Bedingte Ausführung
01 // C-Code
02 if (a == 0)
03 {
04 b = 23;
05 }
06 else
07 {
08 b = 42;
09 c = a;
10 }
11
12 // x86
13
14 TEST EAX, EAX
15 JNE _else
16 MOV EBX, 23
17 JMP _done
18 _else: MOV EBX, 42
19 MOV ECX, EAX
20 _done:
21
22 // ARM
23
24 TEQ R0, #0
25 MOVEQ R1, #23
26 MOVNE R1, #42
27 MOVNE R2, R0
Neben den Load-Store-Instruktionen, die den Transfer jeweils eines Speicherworts zwischen Speicher und Register erlauben, gibt es Load-Store-Multiple-Instruktionen, die den Transfer zwischen einer Reihe aufeinanderfolgender Speicherworte und einer Menge von Registern ermöglichen. Damit kann der Prozessor ein kleines Variablenfeld mit einem Befehl in die Register laden, ebenso lässt sich auf diese Weise sehr effizient mit dem Stack arbeiten, da dieser mehrere Register auf einmal ablegt oder liest. Das ist insbesondere bei der Programmierung von Interrupt-Handlern oder Kontextwechseln in einem Betriebssystem interessant, da sich mit nur zwei Befehlen der gesamte Registersatz austauschen lässt.
Das besondere Bit
Eine weitere Besonderheit ist das so genannte S-Bit im Befehlssatz, das mehreren Zwecken dient. Zum einen hilft es beim feineren Steuern der bedingten Ausführung. Normalerweise ändert der Prozessor bei jedem Befehl die Bedingungsflags – wenn etwa eine Rechnung das Ergebnis Null liefert, setzt er das Zero-Flag. Bei ARM geschieht dies nur, wenn das S-Bit gesetzt ist, sodass der Zustand der Bedingungsflags unabhängig von aktuellen Rechnungen erhalten bleibt.
Zum anderen lässt sich das S-Bit zum Steuern der Prozessormodi und deren spezifischer Register verwenden. Ein gesetztes S-Bit ermöglicht es so, auf die Register des User-Modus durchzugreifen. Schreibt ein Programm bei gesetztem S-Bit auf den Programmzähler, wechselt der Prozessor automatisch in den vorherigen Modus. In Kombination mit einem Load-Multiple kann ein Programmierer damit auf sehr elegante Weise den Rücksprung aus einem Interrupt umsetzen.
Neon, Thumb, Jazelle
Das ARM-Design gestattet einfache Erweiterungen durch das Hinzufügen von bis zu 16 Coprozessoren, die ARM über spezielle Coprozessor-Instruktionen steuert – das erlaubt zum Beispiel Fließkomma-Berechnungen. Reagiert kein Coprozessor auf eine solche Anweisung, gibt es eine Ausnahme, die eine einfache Emulation in Software ermöglicht. Weitere nennenswerte und üblicherweise eingesetzte Erweiterungen sind eine Speicherverwaltungseinheit und eine Einheit zum Media Processing, Neon genannt.
Neben dem eigentlichen ARM-Befehlssatz unterstützen die meisten ARM-Prozessoren noch bis zu drei weitere Befehlssätze: Zunächst gibt es den Thumb-Modus in mittlerweile zwei Varianten. Er erlaubt durch den Einsatz von 16-Bit-Instruktionen eine höhere Codedichte.
Konnte die erste Version von Thumb nur auf die Hälfte der Register zugreifen und musste sie zum Behandeln von Ausnahmen auf den ARM-Befehlssatz zurückschalten, erlaubt ihr Nachfolger Thumb 2 Instruktionen von 16 und 32 Bit Länge und hebt damit die meisten Einschränkungen auf, sodass die höhere Codedichte dennoch eine vergleichbare Leistung zum ARM-Modus ermöglicht. Daneben bietet der Jazelle-Befehlssatz auch Hardwarebeschleunigung für Java-Bytecode an, allerdings hat ARM den Umfang der Unterstützung in neueren Versionen reduziert [4].
Multicore
Beim Erhöhen der Taktrate wächst der Energieverbrauch überproportional zur Rechengeschwindigkeit. Also nimmt die Energieeffizienz mit steigendem Takt ab, was insbesondere bei mobilen Geräten ein Problem darstellt. Der Einsatz mehrerer Kerne löst das Problem zum Teil, da sie die gleiche Anzahl von Rechenoperationen pro Zeiteinheit bei einer geringeren und somit energieeffizienteren Taktrate erreichen. Multicore-CPUs sind also auch für die ARM-Architektur interessant.
Es gibt dazu eine Vielzahl verschiedener Lösungen sowohl von ARM selbst – zu nennen wäre hier MP Core mit bis zu vier Kernen – als auch von Inhabern einer Architekturlizenz. Zwei der größten Herausforderungen beim Design von Multicore-CPUs bestehen in der Cache-Kohärenz und der Interrupt-Verteilung. ARM bietet für ARM11 lediglich einen IP-Block an, der sowohl die Kerne als auch die Logik für Cache-Kohärenz und Interrupt-Verteilung enthält.
Seit dem Cortex-A9 vertreibt ARM diese Komponenten als separate IP-Blöcke, was SoC-Designern mehr Freiheit beim Design lässt. Für Inhaber einer Architekturlizenz vergrößert sich dieser Spielraum erneut, jedoch sind die Details meist kaum oder gar nicht öffentlich dokumentiert.
Big-Little
Da mobile ähnlich wie Desktop-Geräte nur selten die volle Rechenleistung benötigen, gibt es einige Stromsparmechanismen, die in einfacher Form auch in x86-CPUs stecken. Sie regeln die Taktraten der CPUs, um energieeffizienter zu arbeiten, und schalten einzelne Kerne bei Untätigkeit ab. Da der Energieverbrauch bei kleinen Mobilgeräten eine größere Rolle spielt als bei PCs und Notebooks, bieten sowohl ARM als auch die SoC-Hersteller weitere Möglichkeiten an.
Die von ARM entwickelte Lösung Big-Little basiert auf der Tatsache, dass ARM CPU-Kerne verschiedener Leistungsklassen anbietet, die jeweils den gleichen Befehlssatz unterstützen. Big-Little bildet in der CPU Blöcke aus Kernen mit hoher Rechenleistung, aber geringerer Energieeffizienz, sowie Blöcke aus CPU-Kernen mit niedriger Rechenleistung bei höherer Energieeffizienz (Abbildung 3). Das Modell nimmt an, dass die meisten mobilen Geräte nur sehr selten die maximale Leistung des Prozessors anfordern. Somit bedeutet die zeitweise ausschließliche Nutzung langsamer, aber energieeffizienter Kerne eine signifikante Einsparung und führt zu längeren Akkulaufzeiten.
Abbildung 3: Die Kurve zeigt schematisch den Energieverbrauch von Big-Little in Relation zur Leistung. Die ARM-Technologie teilt die CPU-Kerne in Blöcke auf (Quelle: http://arm.com).
Energieeffizienz
Diese energieeffiziente Nutzung des Designs setzt eine Software-Unterstützung voraus, die grundsätzlich drei Ansätze kennt. Der erste nutzt die Virtualisierungsfunktion des System-on-Chip. Hierbei kommt ein Hypervisor zum Zuge, der bei Änderung der Last sämtliche Berechnungen von einem Block zum anderen migriert und den nicht genutzten Block komplett ausschaltet.
Dieser Weg erfordert keine Anpassung des Betriebssystems und funktioniert problemlos auf Android-Systemen. Doch nicht immer ist es sinnvoll, alle laufenden Programme von den kleineren auf die größeren Kerne und umgekehrt zu migrieren, da nicht selten ein gewisser Teil der Prozesse nur eine geringe Last erzeugt oder es sich um wenig zeitkritische Hintergrundprozesse handelt, was den höheren Energieverbrauch der größeren Kerne nicht rechtfertigt.
Daher wandern beim zweiten Ansatz nur die Anwendungen zwischen einzelnen Kernpaaren hin und her. Hierbei nutzt Linux die bereits bestehende Frequenzskalierung (Stichwort »cpufreq« ), indem es die Frequenzbereiche des kleinen und des großen Kerns in Bereiche virtueller Frequenzen zusammenfasst. Niedrige virtuelle Frequenzen werden in der Folge auf dem kleinen Kern abgebildet, hohe auf dem großen. Das Betriebssystem migriert nun eine Anwendung automatisch auf den Kern, in dessen Bereich die gewählte Frequenz liegt.
Dieser Ansatz hat ebenfalls Nachteile. Zum einen nutzt das System so in Höchstlast-Situationen nicht alle physisch verfügbaren Kerne, zum anderen ist der Ansatz (so wie der zuerst vorgestellte) nur bei einer identischen Anzahl von kleinen und großen Kernen sinnvoll.
Letzteres muss nicht zwingend der Fall sein, wie der Entwicklungsprototyp für Big-Little von ARM beweist, der drei Cortex-A7- und zwei Cortex-A15-Kerne besitzt (Abbildung 4). In diesem Fall ist der dritte Ansatz sinnvoll, der dem Nutzer alle Kerne zugleich zugänglich macht, womit das Big-Little-SoC schlicht als Multicore-Prozessor funktioniert.
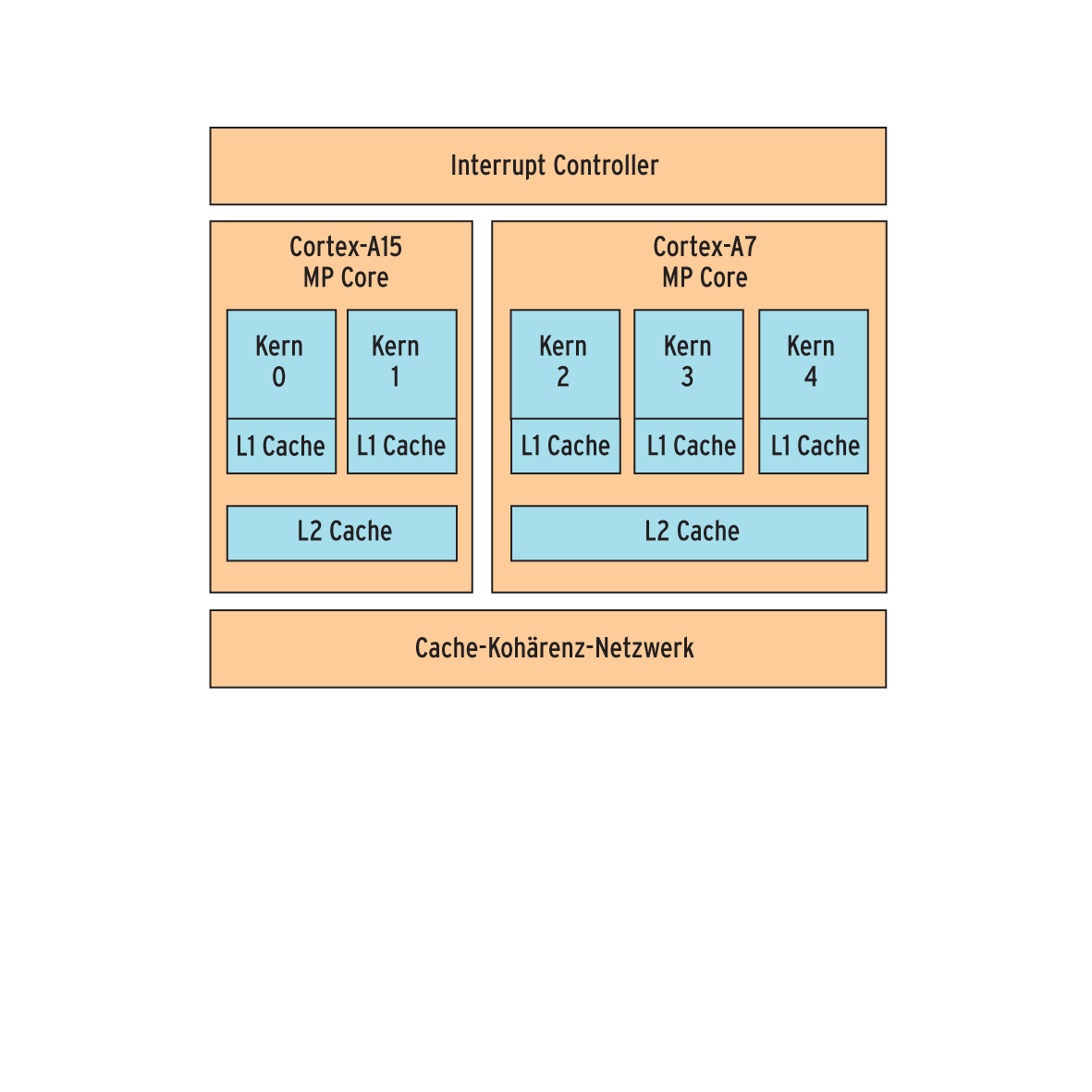
Abbildung 4: Die Architektur des Big-Little-Testprototyps mit drei Cortex-A7- und zwei Cortex-A15-Kernen.
Dieser Ansatz scheint zunächst viel einfacher als die ersten beiden, weist jedoch ein Problem auf, das die Umsetzung erheblich erschwert: Wenn ein Betriebssystem seine Anwendungen auf die Kerne verteilt, geht es – in diesem Fall fälschlich – davon aus, dass alle Kerne die gleiche Rechenleistung besitzen. Das kann dazu führen, dass das System einer unwichtigen Hintergrundanwendung einen schnellen Kern zuordnet und einer wichtigen Vordergrundanwendung einen langsamen. Die Unterstützung solch asymmetrischer Prozessor-Architekturen in Betriebssystemen ist kein triviales Problem, weshalb es zurzeit noch keine marktreife Lösung für Linux gibt [5].
Pläne für Big-Little
Eine Reihe von SoC-Herstellern haben zwar Implementierungen der Big-Little-Architektur angekündigt, konkrete Pläne gibt es aber momentan nur von Renesas Mobile und Samsung. Die erste Firma will im Verlauf des Jahres einen SoC mit zwei Cortex-A7- und zwei Cortex-A15-Kernen auf den Markt bringen. Von Samsung gibt es das Exynos-5-Octa-Chipset, das in einigen Regionen der Welt das neue Galaxy-S4-Smartphone antreibt. Der Name suggeriert einen Achtkern-Prozessor, was technisch betrachtet korrekt ist, da er je vier Cortex-A7- und Cortex-A15-Kerne besitzt. Aus den oben genannten Gründen lassen sich derzeit aber jeweils nur vier Kerne zugleich nutzen.
Einen anderen Weg geht Nvidia mit seinem SoC Tegra 3, in dem vier Cortex-A9 stecken, sowie dem Tegra 4 mit vier Cortex-A15-Chips. Beide SoCs besitzen neben den vier genannten Kernen jeweils noch einen weiteren Cortex-A9- beziehungsweise Cortex-A15-Kern. Dieser, von Nvidia als Companion Core bezeichnet, besteht aus einer anderen Art von Transistoren, die wesentlich weniger Energie pro Schaltvorgang benötigen.
Zugleich zieht dies aber eine Limitierung der maximalen Taktrate des Companion Core nach sich, die weit unterhalb der Taktrate anderer Kerne liegt. Im Betrieb werden, ähnlich wie beim Big-Little-Ansatz, die Anwendungen zum Companion Core migriert, sobald nur noch ein Hauptkern aktiv ist, dessen Last einen gewissen Schwellenwert unterschreitet.
Welcher Stromsparmechanismus besser ist, lässt sich nicht pauschal sagen, da dies von Faktoren wie dem Anwendungsbereich, der Architektur des restlichen Systems und von der effizienten Unterstützung durch das Betriebssystem abhängt. Insbesondere Letztere steckt noch in den Kinderschuhen. Insgesamt führen solche Mechanismen zusammen mit der energieeffizienten Architektur dazu, dass moderne ARM-SoCs sparsamer sind als die meisten x86-Prozessoren ähnlicher Leistung.
Die Zukunft: 64 Bit
Geschichte neigt gelegentlich dazu, sich zu wiederholen: In den 90er Jahren stießen die Hersteller großer Unix-Server an die Grenze von 4 GByte, die eine 32-Bit-Maschine direkt adressieren kann. In der Folge wurden 64-Bit-Architekturen wie Ultra-Sparc von Sun entwickelt. Kurz nach der Jahrtausendwende zeichnete sich das gleiche Problem bei den x86-Rechnern ab, was zur Entwicklung von x86-64 führte.
Als AMD x86-64 startete, war dies eine echte Erweiterung der bestehenden 32-Bit-Architektur, die wiederum auf einer 16-Bit-Architektur fußte – die jeweils älteren Versionen sind Teilmengen der neueren. Dieser Ansatz ermöglicht zwar die problemlose Weiterverwendung bestehenden Wissens und Codes, schließt allerdings tiefgreifende architektonische Veränderungen aus.
ARM-Systemen geht es nun ähnlich: Zum einen erhalten auch kleine Geräte immer mehr Speicher, was Anwendungen anzieht, die davon profitieren, zum anderen wird die ARM-Architektur zunehmend für Server attraktiv, wie es auch der Artikel ab Seite 36 beschreibt. Beides lässt die Grenze von 4 GByte immer mehr zu einem Hindernis werden.
Neuere ARMv7-Kerne wie der Cortex-A15 umgehen das Problem nur teilweise: Die Large Physical Address Extension (LPAE) erlaubt es (ähnlich wie PAE bei x86), bis zu 1 TByte physisch zu adressieren, was aber nicht die Beschränkung auf 4 GByte virtuellen Speicher pro Thread berührt. Der radikale Ausweg ist der Wechsel auf eine 64-Bit-Architektur.
ARMv8 definierte 2011 die zwei Architekturen Aarch64 und Aarch32, die wiederum A64 und A32 als Befehlssätze verwenden (sowie Thumb 2 als T32 für Aarch32). Aarch32 und A32 sind abwärtskompatibel zu ARMv7 (aber nicht umgekehrt), während Aarch64 mit A64 einen neuen Befehlssatz besitzt. Damit ist es – im Gegensatz zu x86 – nicht erforderlich, bestehende Lücken im alten Befehlssatz zu verwenden oder neue Befehle mit komplizierten Präfix-Konstruktionen zu basteln. Vielmehr konstruiert man so einen sauberen Befehlssatz.
Registerfragen
So lassen sich alle A64-Befehle in nur 32 Bit kodieren, obwohl sich die Anzahl der Register verdoppelt hat: X0 bis X29, dazu X30 als Linkregister sowie X31 als hart verdrahtetes Null-Register. Beim Programmzähler, der im A32-Befehlssatz als R15 auftritt, handelt es sich nun um ein spezielles Register, auf das man nur noch über angepasste Befehle zugreifen kann. Die Befehle selbst sind im Wesentlichen an ihre Pendants aus A32 angelehnt, Anpassungen erfordern aber die folgenden architektonischen Änderungen.
Prozessormodi erneuert
Die größte davon betrifft die Prozessormodi und die abhängigen Modus-spezifischen Register: Mit zuletzt acht Modi bei A32 kommt nur noch ein kleiner Teil der vielen Register zum Einsatz. Zudem ist der Umgang mit den verschiedenen Ausnahme-Modi umständlich. Mit A64 führt ARM ein stark vereinfachtes Modell mit vier Ausnahme-Ebenen (Abbildung 5) ein, das Ähnlichkeit mit den Ringen der x86-Architektur aufweist.
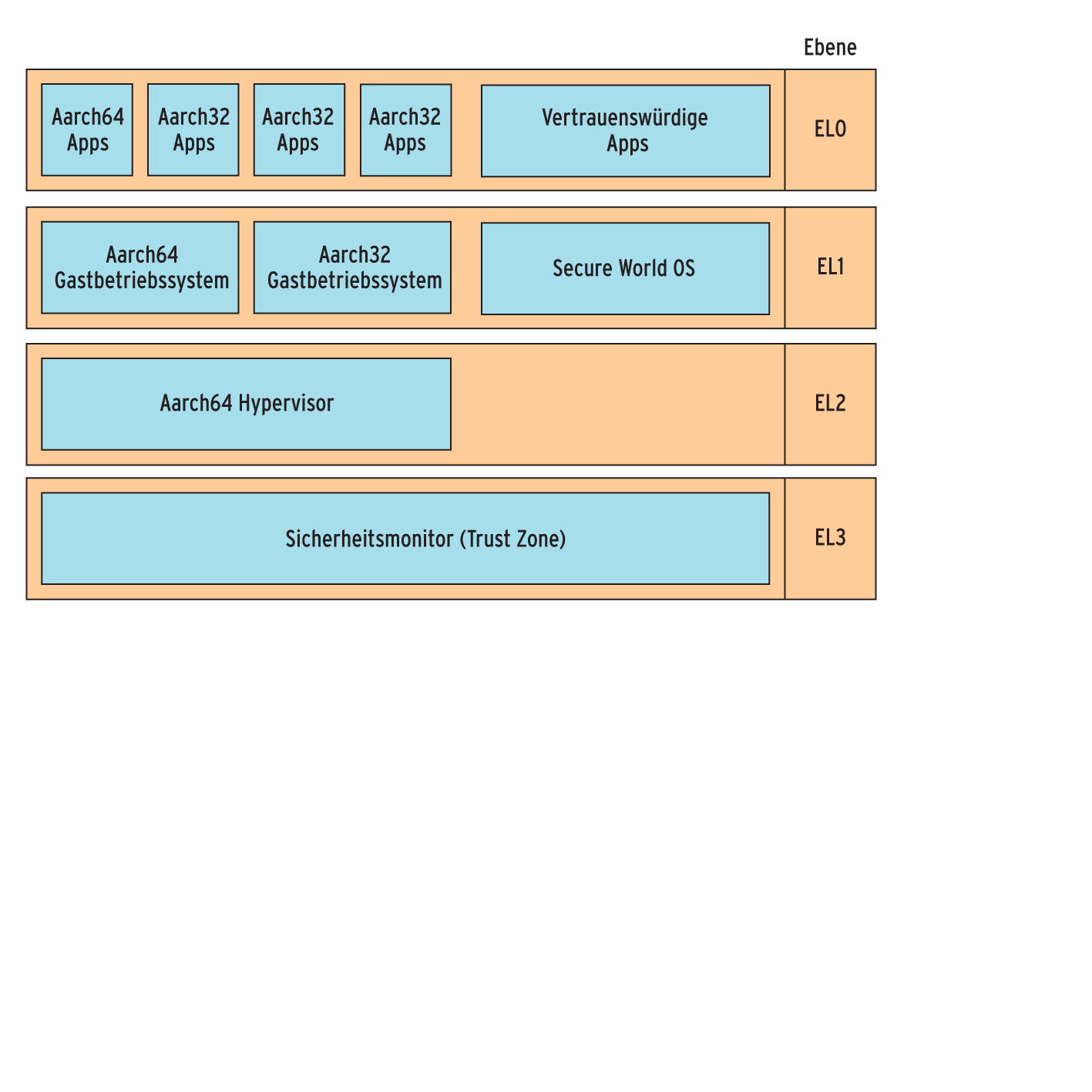
Abbildung 5: Die Prozessormodi von ARMv8 und ihre Kompatibilität zu 32-Bit-Software. Die Ausnahme-Ebenen erinnern stark an die Ringe von x86 (Quelle: http://arm.com).
Die niedrigste Ebene – EL0 – ist für den Betrieb von Anwendungen gedacht (User-Modus), während EL1 dem bisherigen System-Modus entspricht und der Ausführung privilegierter Teile eines Betriebssystems dient. EL2 ist Hypervisoren zugeordnet und EL3 Teil von ARMs Sicherheitskonzept Trust Zone, also für den Betrieb von Sicherheitsmonitoren (siehe Kasten “Verschlüsselte ARM-Prozessoren”). Jeder dieser Modi hat nur noch drei private Register: ein Linkregister für Ausnahmen, den Stackpointer und das gesicherte Statusregister.
Verschlüsselte ARM-Prozessoren
Neben komplexen, auf Virtualisierung beruhenden Sicherheitskonzepten wie Trust Zone (Abbildung 5), gibt es seit einigen Jahren unter den leistungsstarken ARM-Prozessoren Versionen, die komplett verschlüsseltes Booten anbieten. In der Praxis stehen dafür im Prozessor so genannte OTP-Register (One Time Programmable) bereit, die einen Schlüssel verwalten können, der den Bootloader verschlüsselt oder signiert. Diese Maßnahme soll sicherstellen, dass das ausgeführte Programm tatsächlich vom Entwickler oder Hersteller stammt.
Freescale [7] bietet unter den Namen Vybrid beziehungsweise Imx28 Prozessoren mit den entsprechenden Features an. Schon länger auf dem Markt ist der LPC3143 von NXP [8]. Das Open-Source-Projekt Picosafe [9] bietet eine komplette Toolchain an, um einen vollständig verschlüsselten Bootprozess vom Bootloader bis zum Root-Dateisystem zu ermöglichen. (Benedikt Sauter)
Die konditionale Ausführung aller Befehle gibt es bei A64 nicht mehr. Sie erlaubt zwar sehr eleganten Code, erschwert aber die Implementierung einer Out-of-Order-Maschine stark. Auch deshalb müssen die Load-Store-Multiple-Instruktionen simpleren Instruktionen weichen, die nur noch das Laden oder Speichern von zwei Registern erlauben.
Kleinere Änderungen stammen aus den praktischen Erfahrungen mit der 32-Bit-Architektur. Es gibt zwei virtuelle Adressräume von jeweils 248 Byte (256 TByte) – einen für die Anwendungen ab der Adresse 0 und einen für den Betriebssystemkernel ab der Adresse 264 abwärts. Virtuelle Adressen werden je nach Seitengröße mit vierstufigen (4-KByte-Seiten) oder dreistufigen (64-KByte-Seiten) Seitentabellen in physische Adressen umgesetzt. Die Adressierung selbst folgt weiterhin dem Load-Store-Ansatz, doch wurden die Adressierungsmodi angepasst, um die Berechnung zu vereinfachen.
Wie bei x86-64, wo 32-Bit-Anwendungen auf einem 64-Bit-System laufen, sorgt auch ARMv8 für Kompatibilität. Beim Auftreten von Ausnahmen und dem Verlassen derselben kann der Prozessor zwischen Aarch64 und Aarch32 wechseln und die Register in Abhängigkeit vom Modus aufeinander abbilden; 32-Bit-Zugriffe betreffen nur die untere Hälfte des Registers (Abbildung 5). So ist es möglich, sowohl Aarch32-Anwendungen unter einem Aarch64-Betriebssystem laufen zu lassen als auch unter einem Aarch64-Hypervisor Gäste beider Architekturversionen nebeneinander auszuführen [6].
Linux und ARMv8
Obwohl ARMv8 bereits 2011 vorgestellt wurde und mit dem Cortex-A53 und Cortex-A57 bereits erste IP Cores im Angebot sind, existiert außer Simulatoren und FPGA-basierten Prototypen bislang noch keine Umsetzung. Jedoch haben einige Hersteller Produkte angekündigt, die wohl noch in diesem oder Anfang nächsten Jahres auf den Markt kommen. Dessen ungeachtet arbeiten Entwickler bereits sehr aktiv an Software für die neue Architektur: Die Codegenerierung für Aarch64 ist mit aktuellen GCC-Versionen problemlos möglich, und der Linux-Kernel unterstützt die Architektur ab Version 3.7. Wenn also die ersten 64-Bit-ARM-Rechner erscheinen, ist Linux schon für sie bereit.
Infos
- ARM-Lizenznehmer: http://www.arm.com/products/processors/licensees.php
- Samsungs Exynos 5 Dual: http://www.samsung.com/global/business/semiconductor/minisite/Exynos/products5dual.html
- Qualcomms Krait-Kerne: http://www.qualcomm.com/snapdragon/processors#CPU
- Steve Furber, “ARM System-on-Chip Architecture” (2nd Edition): Pearson
- Robin Randhawas Whitepaper zu Big-Little: http://arm.com/files/downloads/System_Software_for_b.L_Systems_Randhawa.pdf
- David Kanter, “ARM Goes 64-bit”: http://www.realworldtech.com/arm64/
- Vybrid und Imx28 von Freescale: http://www.freescale.com
- LPC3143 von NXP: http://www.nxp.com
- Picosafe: http://www.picosafe.de






