
© Vladimir Kolectic, 123RF.com
Admins, deren Telefonnummer nach dem Ausfall des Fileservers hundertmal in einer Minute gewählt wird, wissen: Verfügbarkeit ist mehr als nur eine theoretische Kenngröße. Die Wahl der richtigen Architektur, Clustersoftware und Filesysteme hilft das Schlimmste vermeiden.
In Zeiten des Cloud Computing gilt Hochverfügbarkeit als das K.o.-Kriterium für jede IT-Plattform. Wer mit unsauber umgesetzter Redundanz schlampt, macht sich unglaubwürdig. Das gilt für die permanente Verfügbarkeit von Anwendungen, aber noch viel mehr für die Verfügbarkeit von Daten.
Böse Zungen behaupten, Cloud sei nur ein Akronym für “Can’t Locate Our Users’ Data” – wer das als Admin vermeiden will, braucht HA-Funktionen und sinnvolle Management-Interfaces, damit zum einen erst gar nichts ausfällt, er andererseits bei gravierenderen Ereignissen schnell und einfach eingreifen kann.
Redundanz ist erste Pflicht!
Fast immer ist es zwingend, Daten mehrfach zu speichern, sodass sie beim Ausfall einer Systemkomponente trotzdem andernorts zur Verfügung stehen. Dass Admins bei Linux-Systemen aus einer ganzen Reihe Möglichkeiten wählen können, um ihre Dateien redundant zu halten, ist nicht selbstverständlich. Und manch einer der aktuellen Ansätze – Gluster und Ceph seien nur als Beispiele erwähnt (siehe den Artikel zu den Netzwerk-Dateisystemen in diesem Schwerpunkt) – ist noch gar nicht so alt.
Großes Vorbild: Storage Area Networks
Welchen Pfad der Administrator beschreitet, um seine Daten und somit auch die auf sie zugreifenden Applikationen gegen Ausfälle zu schützen, hängt maßgeblich vom Einsatzszenario ab. Dieser Artikel wirft ein Schlaglicht auf einige der Lösungen, die sich um die Redundanz von Daten bei Linux kümmern. Auffällig ist es schon: Nahezu alle Storage-Lösungen für Linux fußen auf der Idee, eine Konkurrenz zu den klassischen SAN-Storages darzustellen.
SANs (Storage Area Networks, [1]) sind so etwas wie die alten Hasen im Storage-Geschäft: Die Idee eines zentralen Datensilos fürs Rechenzentrum existiert in ihrer derzeit verbreiteten Form bereits seit den 1990er Jahren, SAN-Storages dürfen sich also zu Recht auf die Fahnen schreiben, eine erste brauchbare Alternative zu Servern mit lokalen Platten gewesen zu sein. Die Raid-Idee gibt es zwar schon seit Ende der 1980er Jahre, doch war die Technik zu jener Zeit lange nicht so ausgereift wie heute.
SAN-Storages sind gegenüber lokalen Platten in Servern in vielerlei Hinsicht besser ([2], [3]): Einerseits bieten sie einen zentralen Administrationspunkt, der die Storage-Verwaltung erheblich erleichtert. Darüber hinaus funktionierte es mit SAN-Storages auf Fibre-Channel-Grundlage, dass mehrere Server gleichzeitig auf unterschiedliche Segmente des Speichers zugreifen. Und auch in Sachen Redundanz waren SANs allen anderen Speicherlösungen lange Zeit überlegen: Redundante Netzteile, Hot- und Cold-Standby-Disks und redundante Netzwerkanschlüsse waren bei SANs schon früh Standard.
Vendor-Lock-in
Aber der Ansatz hat auch Nachteile: Wer sich SAN-Storage kauft, holt sich damit unweigerlich langfristig einige Probleme ins Haus, von denen das schlimmste der so genannte Vendor-Lock-in sein dürfte. Gemeint ist, dass sich in einen SAN-Storage nicht einfach beliebige Hardware einbauen lässt. Wer sein SAN erweitern möchte, ist auf den Hersteller der Lösung angewiesen – und der kann die Preise praktisch diktieren, in dem sicheren Wissen, dass Kunden ohnehin keine echte Alternative haben.
Teure Hardware
Insgesamt sind SAN-Storages also keine günstige Anschaffung; zu den hohen laufenden Kosten für eventuelle Reparaturen und Erweiterungen kommen die teils horrenden Anschaffungskosten. Außerdem stößt Redundanz bei SAN-Storages üblicherweise an Grenzen, wenn es darum geht, Daten an zwei unterschiedlichen Orten zu speichern.
In diesem Sinne sind auch SANs klassische Single-Points-of-Failure (SPoF): Muss die Feuerwehr den Strom in dem Teil eines Rechenzentrums abstellen, in dem ein SAN steht und in dem es gerade brennt, sind die Daten wenigstens offline. Abhilfe schafft nur das Spiegeln der Daten auf ein zweites SAN an einem anderen Ort, was den Preis für die gesamte Lösung aber endgültig in astronomische Höhen katapultiert.
Mit dem Einzug des Cloud Computing ergibt sich noch ein weiteres Problem, das sich nicht ohne Weiteres lösen lässt: Klassische SANs skalieren nicht in die Breite. Wer mehr Platz braucht, steckt entweder Platten hinzu, bis das Gehäuse voll ist, oder tauscht vorhandene Platten durch größere aus. So oder so ist das Ende der Fahnenstange irgendwann erreicht. Möglichkeiten, sich wohltuend von den SAN-Problemen abzusetzen, gibt es für Storage-Lösungen auf Linux-Basis aber mehr als genug.
Distributed Block Device
Als erster Ersatz für klassische SAN-Lösungen hat sich DRBD [4] etabliert und früh einen Namen gemacht. Die Idee ist eigentlich simpel: Anstelle eines SAN-Storage werkelt ein aus zwei Servern bestehender Cluster mit Linux [5]. Die installierte Distribution verwendet das DRBD-Kernelmodul auf beiden Knoten, was im Grunde eine Art Raid 1 über ein bestehendes Netz ermöglicht.
Besonders positiv bei DRBD ist, dass die Lösung unmittelbar im Block Storage Layer des Linux-Kernels beheimatet ist und damit für Applikationen von einer normalen Festplatte nicht zu unterscheiden. Praktisch verhält sich DRBD also nahezu völlig agnostisch hinsichtlich aller denkbaren Applikationen. Was auf einem normalen Dateisystem läuft, ist auch mit DRBD machbar, wenn auch nur im Verbund mit anderer Software.
DRBD braucht einen Clustermanager
Aber ein DRBD-Kerneltreiber allein macht noch nicht glücklich: Um echte Hochverfügbarkeit zu gewährleisten, braucht eine Speicherlösung mit DRBD zwingend einen Clustermanager wie etwa Pacemaker (siehe Abbildung 1, [6], [7]).
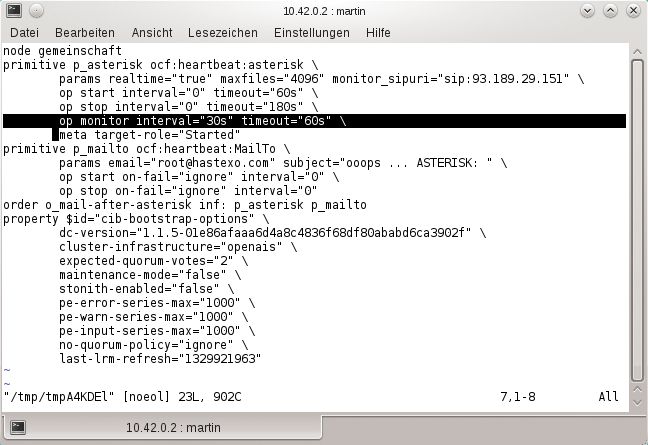
Abbildung 1: Die einfachste Form eines Netzwerk-Dateisystems ist und bleibt NFS – in Kombination mit DRBD auch redundant. Doch setzt dies den nicht ganz intuitiv zu bedienenden Clustermanager Pacemaker voraus.
Der kümmert sich darum, dass einerseits mindestens einer der beiden Netzwerkknoten tatsächlich auch den Zugriff auf die DRBD-Daten erlaubt, andererseits auch darum, dass die jeweilige Technik funktioniert, die die Daten im Netz erst nutzbar macht. Denn die Daten, die DRBD zwischen den beiden Knoten eines Speicherclusters hin- und herrepliziert, müssen ja auch irgendwie zu dem eigentlichen Adressaten gelangen.
Applikationsabhängig: Die DRBD-Architektur
Welche Applikation das ganz konkret ist, hängt vom jeweiligen Setup ab. Im einfachsten Falle liegt auf dem DRBD-Device nur ein normales Dateisystem, auf das dann die jeweilige Applikation zugreift. Häufig kommt diese Art von Setup zum Einsatz, um eine MySQL-Datenbank einfach und unkompliziert hochverfügbar zu halten.
Falls andere Server im Netz ebenfalls unmittelbaren Zugriff auf das DRBD-Device erhalten sollen, ist eine Lösung auf NFS-Grundlage denkbar: Der NFS-Server exportiert dann das Dateisystem, das auf der DRBD-Ressource liegt, und erlaubt auf diese Weise jedem NFS-Client im Netz den gleichzeitigen Zugriff.
I-SCSI
Falls ein solcher DRBD-Cluster als SAN-Ersatz dienen soll, bietet sich überdies I-SCSI an (Abbildung 2, [8], [9]): Auf dem gerade aktiven Knoten des Clusters läuft ein I-SCSI-Target, das das DRBD-Blockdevice hin zu einem anderen Client im Netz exportiert.
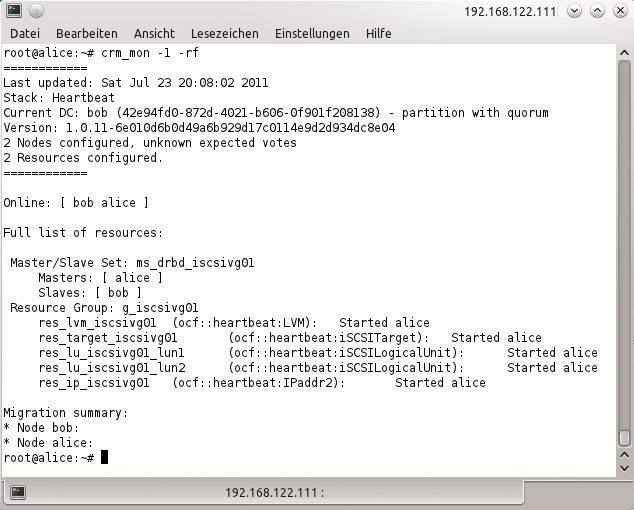
Abbildung 2: Ein DRBD-Cluster kann klassischen SAN-Storage ersetzen und ist für KMUs eine günstige Alternative – hier für I-SCSI-Exporte.
Auch mehrere I-SCSI-Targets für verschiedene DRBD-Ressourcen sind möglich. Diese Konstruktion reicht am ehesten an klassische SANs heran und lässt sich oft sogar als Drop-in-Replacement für sie installieren. DRBD-Cluster dieser Art gehören zu den zuverlässigsten Lösungen, um Daten hochverfügbar zu machen. DRBD selbst hat sich im Produktivumfeld bewährt und ist Bestandteil vieler Distributionen, Admins treffen an dieser Stelle auf erprobte Software.
Doch die Medaille hat auch eine Kehrseite, etwa den nötigen Clustermanager. Praktisch kommt dafür nur der sehr komplexe Pacemaker in Frage, der vielen Admins zu kompliziert ist. Selbst für ein einfaches Zwei-Knoten-Setup entsteht beträchtlicher Lernaufwand, wenn das Verständnis der Lösung über bloße Grundkenntnisse hinausgehen soll.
Graue Haare wachsen Admins regelmäßig, wenn es ans Erweitern der Lösung geht: Wie klassische SAN-Storages leiden auch DRBD-Cluster unter dem Problem, dass sie nicht in die Breite skalieren, sondern nur in die Höhe. Sind alle Plattenslots belegt, ist Schluss mit mehr Platz.
Eine passable Lösung für zwei Knoten
Dennoch gilt: Wer lediglich einen Weg sucht, Daten innerhalb eines Zwei-Knoten-Clusters auf einfache Weise redundant zu halten und sie gleichzeitig mehreren Clients über das Netzwerk verfügbar zu machen, fährt mit einem DRBD-Cluster und einer klassischen NFS-Installation derzeit immer noch am besten. Zumindest dann, wenn Skalierbarkeit in die Breite für ihn kein Thema ist. Setups dieser Art sind tausendfach erprobt und im Netz finden sich unzählige Anleitungen für genau diesen Use-Case. Wer es in Sachen Netzwerk-FS also langsam angehen will, legt hier los.
Besser: Cluster-Dateisysteme
Weiter in die Richtung der SAN-Storages oder entsprechender Ersatzkonstruktionen stehen Cluster-Dateisysteme. Die Voraussetzung für ihren sinnvollen Einsatz ist ein Datensatz, der in identischer Form auf jeweils mehreren Storage-Devices zur Verfügung steht. In Frage kommen dafür beispielsweise DRBD-Ressourcen oder von replizierenden SANs gemountete Volumes. In einer normalen Konfiguration wäre der Zugriff bei solchen Szenarien nur auf jeweils einen der beiden Datensätze möglich, während im Hintergrund die Replikation dafür sorgt, dass der Datensatz auf dem anderen Gerät stets synchron bleibt.
Diese Lösung besitzt einige Nachteile: So ist der passive Clusterknoten zum Nichtstun verdammt, obwohl er ja im Grunde durchaus dazu beitragen könnte, eine erhöhte Last auf dem primären Storage auszugleichen. Cluster-Dateisysteme sollten genau diesen Engpass umgehen helfen: Sie bieten die Möglichkeit, diversen Clients gleichzeitig den Zugriff auf die verschiedenen Kopien eines Datensatzes einzuräumen.
Obendrein sollten Cluster-Dateisysteme vorrangig den Zugriff von mehreren Clients auf den gleichen Datensatz ermöglichen; beispielhafte Szenarios sind Session-Caches für Webumgebungen. Ihnen kommt dabei die Rolle eines Aufsehers zu: Wenn verschiedene Clients gleichzeitig auf exakt denselben Bereich des Dateisystems zugreifen wollen, sorgt das Cluster-Dateisystem dafür, dass es nicht zu konkurrierendem Zugriff kommt.
Klassische Filesysteme: Zwangsläufig korrupt
Konventionelle Dateisysteme sind für diese Aufgabe unbrauchbar, genau diese Form des konkurrierenden Schreibzugriffs würde sie zerstören. Denn ein normales Dateisystem unter Linux geht stets davon aus, dass Veränderungen am Dateisystem nur dort passieren, wo gerade der Mount aktiv ist. Im Cluster mit gleichzeitigem Zugriff von mehreren Clients auf die unterschiedlichen Backend-Devices würde das Dateisystem zwangsläufig korrupt, handelte es sich um ein normales Dateisystem wie XFS oder Ext 3.
Clustersysteme dagegen überspannen sämtliche Instanzen eines Storage und stellen sicher, dass konkurrierende Schreibzugriffe ausbleiben. Die bekanntesten Vertreter dieser Dateisystem-Kategorie sind sicherlich GFS2 [10] und OCFS2 [11].
Beide Lösungen [12] setzen auf den Distributed Locking Manager (DLM, [13]), den ursprünglich Red Hat entwickelt hat und der nunmehr Bestandteil des Linux-Kernels ist. Eine dritte Spielart eines solchen Setups bildet Clustered LVM [14], das den Zugriff auf die gleichen LVM-Daten über mehrere Server hinweg ermöglicht und ebenfalls den DLM im Linux-Kernel heranzieht.
Jedes Projekt kocht sein eigenes Süppchen
Was in der Theorie schön klingt, kämpft in der Praxis mit einigen Schwierigkeiten. In freier Wildbahn finden sich Cluster-Dateisysteme vorrangig in Replikationslösungen, bei denen der Admin DRBD im Dual-Primary-Modus nutzt und dann mit OCFS2 oder GFS2 kombiniert. Setups dieser Art sind komplex: Sie benötigen in jedem Fall einen Clustermanager, der den zugrunde liegenden Storage verwaltet und sich auch um die korrekte Funktion des Dateisystems im Betrieb kümmert. Ein Pacemaker nimmt hier eine sehr wichtige Rolle ein: Er muss in einem solchen Setup nicht nur DRBD die Stange halten, sondern auch dafür sorgen, dass der DLM wie erwartet funktioniert.
SLES, RHEL, Debian
Im Augenblick erfordert das Ganze allerdings Bastelarbeit: SLES bietet die notwendigen Pakete, weil Suse eine uralte Version der DLM-Komponenten für Pacemaker bis zum gegenwärtigen Zeitpunkt auf eigene Faust pflegt. Auf Red-Hat-Systemen muss gar der Clustermanager Cman [15] zum Einsatz kommen, der Pacemaker anschließend huckepack nimmt, damit dieser den DLM sowie die Cluster-Dateisysteme in der Red-Hat-Ausführung nutzen kann.
Debian Squeeze setzt auf Uraltversionen der involvierten Software und Debian Wheezy unterstützt DLM vermutlich gar nicht mehr vernünftig. Zwischen den Ubuntu- und den Debian-Maintainern des Linux-HA-Stack gibt es eine Übereinkunft, den Support für DLM in absehbarer Zeit auch offiziell aus der Umgebung zu streichen.
Fencing wird notwendig
Hinzu kommt ein Faktor, den viele Admins vergessen: Für DLM ist funktionierendes Fencing [16] quasi obligatorisch. Ein Clusterknoten muss einen anderen aus dem Cluster rauswerfen können, wenn er ihn verdächtigt Daten zu korrumpieren. Die Fencing-Funktionen sind bei Pacemaker unter dem Oberbegriff Stonith abgehandelt, der Abkürzung für “Shoot the other node in the head”.
Um genau diese Stonith-Funktion machen die meisten Sysadmins aber einen großen Bogen – aus Angst vor Fehlalarmen, die möglicherweise unnötig Unruhe in die Umgebung bringen. Dem Autor dieses Artikels sind in den vergangenen Jahren diverse Cluster unter GFS2- oder OCFS2-Ägide begegnet, auf denen Stonith deaktiviert war. So wird aus einer eigentlich guten Idee ein kleiner Datenschredder, und die Betreiber solcher Systeme sind gut damit beraten, Backups zu haben (Abbildungen 3 und 4).
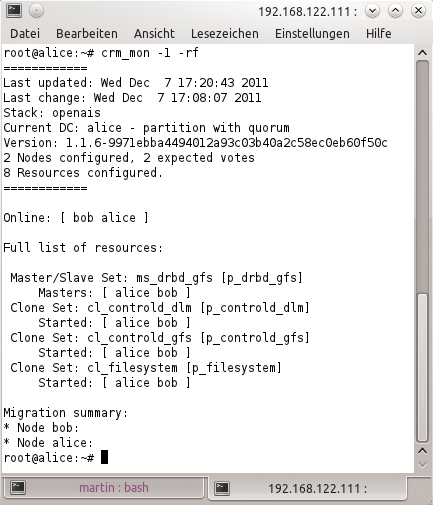
Abbildung 3: OCFS2 und GFS2 sind unnötig komplex. Hinzu kommt, dass die Konfiguration in diesem Beispiel kein Stonith verwendet.
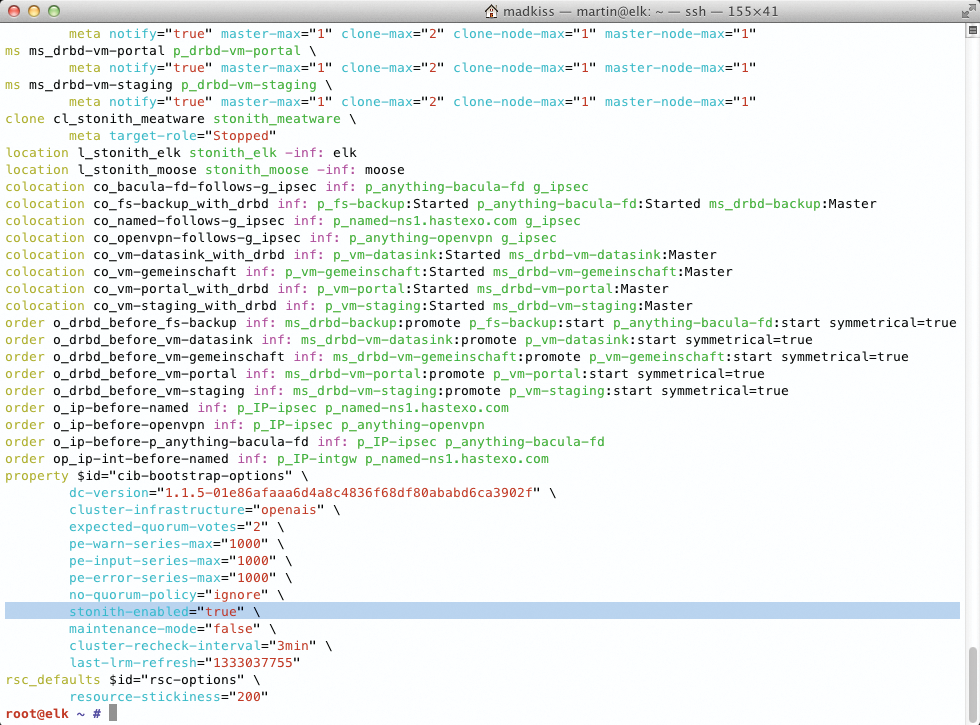
Abbildung 4: Besser geht es mit einer Stonith-Konfiguration wie in diesem Beispiel. Doch leider schalten viele Admins die Stonith-Funktionen im Betrieb aus.
Fakt ist also: Cluster-Dateisysteme bringen viel Komplexität und wenig Nutzen; in den meisten Fällen reicht ein klassisches NFS völlig aus, um die Anforderungen zu erfüllen, für die Cluster-Dateisysteme gern herangezogen werden. Bei NFS ist dann zwar die Performance unter erhöhter Last möglicherweise schlechter, doch dafür sind die Daten im Cluster deutlich sicherer. Ob DLM insgesamt eine Zukunft hat, steht eingedenk aufstrebender Lösungen wie Ceph und Gluster sowieso in den Sternen (Abbildung 5). Denn schließlich kommt Gluster-FS direkt von Red Hat, also der Firma, die einst der größte Befürworter von DLM war.
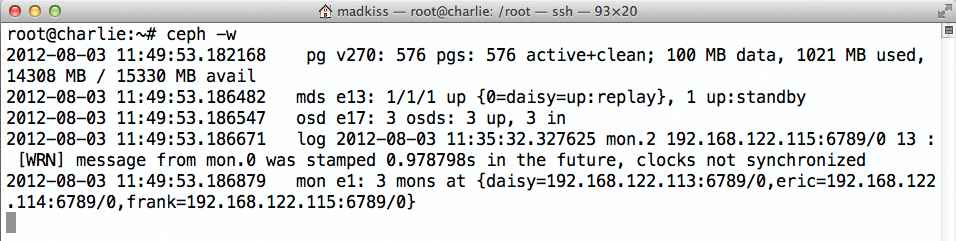
Abbildung 5: Bei verteilten Dateisystemen wie Gluster-FS oder Ceph und Ceph-FS ist Redundanz ab Werk eingebaut. Der Admin muss sich um das Thema im Grunde kaum mehr kümmern.
Die nächste Generation: Verteilte Dateisysteme
Gluster-FS [17] ist ein typischer Vertreter der verteilten Dateisysteme, die quasi eine neue Generation der Netzwerk-Dateisysteme darstellen. Anders als althergebrachte Lösungen hatte Gluster von Anfang an Gelegenheit, das Thema Hochverfügbarkeit ins Design zu integrieren. Denn als die Gluster-FS-Entwickler 2005 mit ihrer Arbeit anfingen, war das Thema HA bereits in aller Munde.
Replikation und Redundanz sind in Gluster-FS praktisch immanent. Nahezu jede Komponente eines Gluster-Clusters lässt sich problemlos in die Breite skalieren, und neu hinzugefügte Komponenten integriert die Umgebung automatisch in ihre HA-Funktionen. Beim Ausfall eines Servers in Gluster-FS tritt innerhalb des Speichers an die Stelle eines ausgefallenen Systems sofort ein adäquater Ersatz.
Unnötig in Gluster-FS: Clustermanager
Aus der Sicht eines Sysadmin gibt es also wenig in Sachen HA, worüber er sich Gedanken machen müsste. Nicht mal ein Clustermanager ist nötig: Damit Gluster-FS funktioniert, müssen auf den beteiligten Hosts lediglich die Gluster-Daemons (»glusterd« ) laufen. Pacemaker könnte in so einem Setup höchstens noch den Überwacher spielen und auf Knoten, auf denen »glusterd« abgestürzt ist, diesen neu starten. Der gleiche Effekt lässt sich aber auch mit Upstart oder Systemd erzielen, die abgestürzte Dienste auf Wunsch des Admin ebenfalls automatisch neu starten.
Als Argument gegen Gluster-FS bleibt damit nur die Tatsache, dass das gesamte Konzept verhältnismäßig simpel strukturiert ist. Weil sich der ganze Ablauf bei Gluster-FS im Userland abspielt und auch das Mounten eines Dateisystems per Fuse passiert, traut mancher der Lösung nicht über den Weg. Und tatsächlich tut Gluster-FS sich mit einzelnen Setups schwer, beispielsweise wenn innerhalb eines Brick – so heißen die einzelnen Storagedevices in Gluster – viele kleine Files beheimatet sind. Das mindert die Performance deutlich.
Dennoch gilt: Wer sich ohne viel Aufwand dem Thema redundante Netzwerk-Dateisysteme nähern möchte, der fängt idealerweise mit Gluster-FS an – für kleine und mittelgroße Setups reicht die Lösung allemal.
Vielarmiger Newcomer: Ceph
Als absoluter Shootingstar in Sachen Netzwerk-Dateisysteme gilt im Augenblick das von Inktank [18] entwickelte Ceph [19]. Dabei ist Ceph im Grunde gar kein echtes Dateisystem: Das Herzstück der Lösung ist ein Object Store, also ein im Userspace implementierter Dienst, der Dateien von Clients per Netzwerk entgegennimmt, diese in binäre Objekte umwandelt und die Objekte anschließend in kleine Teile trennt.
Ganz am Ende dieses Vorgangs verteilt der Dienst die Teile dann auf die verfügbaren Storageserver nach einem komplizierten Algorithmus (Crush, Controllable Replication Under Scalable Hashing). Der Clou an der Sache ist, dass es verschiedene Frontends gibt, die den Zugriff auf diesen Object Store erlauben: In Form von Ceph-FS steht ein echter Linux-Dateisystemtreiber bereit, der Daten aus einem Ceph-Store lesen kann.
Mehrere Clients können auf den gleichen Ceph-Store gleichzeitig zugreifen – in dieser Spielart kommt Ceph mit Ceph-FS anderen verteilten Dateisystemen wie Gluster-FS oder Lustre näher. Von Lustre hat Ceph-FS die Idee eines zentralen Metadaten-Servers geerbt, der Posix-Kompatibilität gewährleistet. Bei Ceph-FS ist es im Gegensatz zu Lustre aber nicht so, dass der Ausfall des Metadaten-Servers zu stundenlangen Downtimes führt. Wer an Lustre bereits gescheitert ist, sollte Ceph trotzdem eine Chance geben.
Das Rados Block Device (RBD) bietet ein Blockdevice zum Zugriff auf Ceph. »radosgw« hat ein Restful-API im Gepäck, das über verschiedene APIs per HTTP zugreift. Hinsichtlich des Themas HA gilt für Ceph, was auch für Gluster gilt: Von Anfang an haben Sage Weil und sein Team in Ceph die Redundanz als inhärente Funktion behandelt, sodass diese allein durch das Design der Lösung gegeben ist. Fällt ein einzelnes Glied des gesamten Speichers aus, so beeinträchtigt das in keiner Weise die Funktion des ganzen Systems.
Nahtloses Skalieren
Ceph skaliert in die Breite perfekt: Jede Komponente einer Ceph-Installation – egal ob es sich um die Storage-Dienste (Object Storage Daemons, OSD), um die Monitoringserver (MON) oder um den erwähnten MDS handelt – von jeder Instanz können beliebig viele Inkarnationen Teil des Clusters sein. Ein Nadelöhr oder einen SPOF sucht man bei Ceph bei sinnvoller Anwendung, die mindestens drei Knoten beinhaltet, vergebens.
Auch bei Ceph sind keine Clustermanager nötig. Wer also einen wirklich großen Datenspeicher mit inhärenter HA sein Eigen nennen möchte, sollte Ceph an die Spitze seiner Evaluierungsliste stellen. Die Entwickler der Software verorten ihr Produkt sinnvollerweise bei Größenordnungen von mehreren Terabyte Speicherkapazität. Obwohl Inktank Ceph-FS noch nicht offiziell als “fertig” betrachtet, sind Testläufe mit Ceph und Ceph-FS bereits jetzt problemlos möglich.
Die Konfiguration ist zwar nicht ganz so komfortabel wie bei Gluster-FS, aber nicht unnötig kompliziert. Das dürfte auch die noch kurz vor Redaktionsschluss bekanntgegebene Kooperation mit Suse noch fördern.
Fazit
Wer sich mit Dateisystemen beschäftigt, die die Nutzung eines Netzwerks bedingen, sollte zunächst klar definieren, welche Bedingungen die Plattform erfüllen muss. Davon hängt ab, welche der Lösungen überhaupt in Frage kommen, denn deren HA-Fähigkeiten unterscheiden sich deutlich.
Wer lediglich mehreren Clients den Zugriff auf Daten zur selben Zeit anbieten möchte und wenn absehbar ist, dass die Summe an Daten eher gering bleibt, fährt mit einem klassischen Cluster aus zwei Knoten mit DRBD und NFS noch immer am besten. Viele Admins sind der irrigen Überzeugung, ein derartiges Setup sei nur mit GFS2 oder OCFS2 sinnvoll zu realisieren – groteskerweise verkomplizieren gerade Cluster-Dateisysteme das Thema Hochverfügbarkeit gewaltig. Von ihrem Einsatz in diesem Bereich ist daher generell abzuraten.
Wer eine Large-Scale-Lösung braucht, schaut sich indes bei Gluster-FS oder Ceph um. Hier ist Redundanz fester Teil des Gesamtkonzepts, der Admin muss sich nur noch die Frage stellen, wie anspruchsvoll die Redundanz ausgebaut sein soll – sowohl Ceph als auch Gluster erlauben die Konfiguration des »replica« -Werts, der beschreibt, wie oft eine einzelne Datei im Cluster vorhanden sein muss.
Infos
- Storage Area Networks: http://en.wikipedia.org/wiki/Storage_area_network
- Jens-Christoph Brendel, “Storage-Strategien”: Linux-Magazin 11/04, S. 48
- Michael Lorenz, “Canale Grande”: Linux-Magazin 05/09, S. 52
- DRBD: http://www.drbd.org
- Martin Loschwitz, “Storage für HA-Cluster”: Admin-Magazin 04/11, S. 80
- Martin Loschwitz, “Dabeibleiben ist alles”: Linux-Magazin 05/12, S. 40
- Michael Kromer, “Schrittmacherdienste”: Linux-Magazin 11/10, S. 86
- Thorsten Staerk, “Speicherriese”: Linux-Magazin 04/10, S. 86
- Kai-Thorsten Hambrecht, “Zielstrebig”: Linux-Magazin 05/11, S. 66
- GFS bei Red Hat: http://www.redhat.com/gfs/
- OCFS bei Oracle: https://oss.oracle.com/projects/ocfs2/
- Udo Seidel, “Server-Traube – GFS2 und OCFS2, zwei Cluster-Dateisysteme im Linux-Kernel”: https://www.linux-magazin.de/Online-Artikel/GFS2-und-OCFS2-zwei-Cluster-Dateisysteme-im-Linux-Kernel
- DLM: http://khawajahashim.files.wordpress.com/2010/11/white-paper-on-distributed-locking-manager1.pdf
- Clustered LVM: http://www.sourceware.org/cluster/clvm/
- Cman: http://sourceware.org/cluster/cman/
- Fencing: http://en.wikipedia.org/wiki/Fencing_(computing)
- Gluster: http://www.gluster.org
- Inktank: http://www.inktank.com
- Ceph: http://ceph.com
Der Autor

Martin Gerhard Loschwitz arbeitet zurzeit als Principal Consultant bei Hastexo. Er beschäftigt sich dort ganz Cloud-affin mit Hochverfügbarkeitslösungen, Open Stack sowie mit verteilten Dateisystemen.





