
© Chris Baker, 123RF.com
Während Linux-Magazin-Autor und Modellbahn-Fan Tobias Eggendorfer die Website eines Ausflugsziels hackt, macht sich der Informatikprofessor Gedanken über die Vorhersagbarkeit von Zufällen, PHP-Funktionen und Kreditkartennummern.
Die liebevoll gestaltete Modelleisenbahn-Landschaft “Miniatur Wunderland” [1] in Hamburg erfreut ihre Besucher so sehr, dass es Tage gibt, an denen diese stundenlang auf Einlass warten müssen. Wer das nicht riskieren will, reserviert vorher über die Webseite eine Uhrzeit (Abbildung 1), zu der er über eine Fast-Lane direkt zur Kasse vordringen darf. Klar, dass gute Termine ruck, zuck ausgebucht sind. Eines Abends überlegte ich mit einem Gast, am nächsten Tag ins Miniatur Wunderland zu gehen. Doch die Wartezeitprognose betrug gruselige zwei Stunden, und auf der Webseite waren die für uns nützlichen Timeslots rot.
Ein paar Klicks auf Links mit grünen Zeiten zeigten mir jedoch, dass die URL neben dem Wunschdatum auch ein Feld »time« übergibt, das augenscheinlich keine Uhrzeit ist (Abbildung 2). Meine erste Vermutung war, dass »time« einfach ein Index in der Liste der Timeslots ist. Also probiere ich einen nicht legitimen Link für die Zeit 13 bis 14 Uhr zu erzeugen, obwohl die Auswahlseite den Slot rot und nicht mehr reservierungsfähig anzeigt. Tatsächlich: Anders als die Auswahlseite prüft die Reservierungsseite die Verfügbarkeit eines Slots nicht. Errate ich also den Index, kann ich für jede Zeit – grüne wie rote – reservieren.
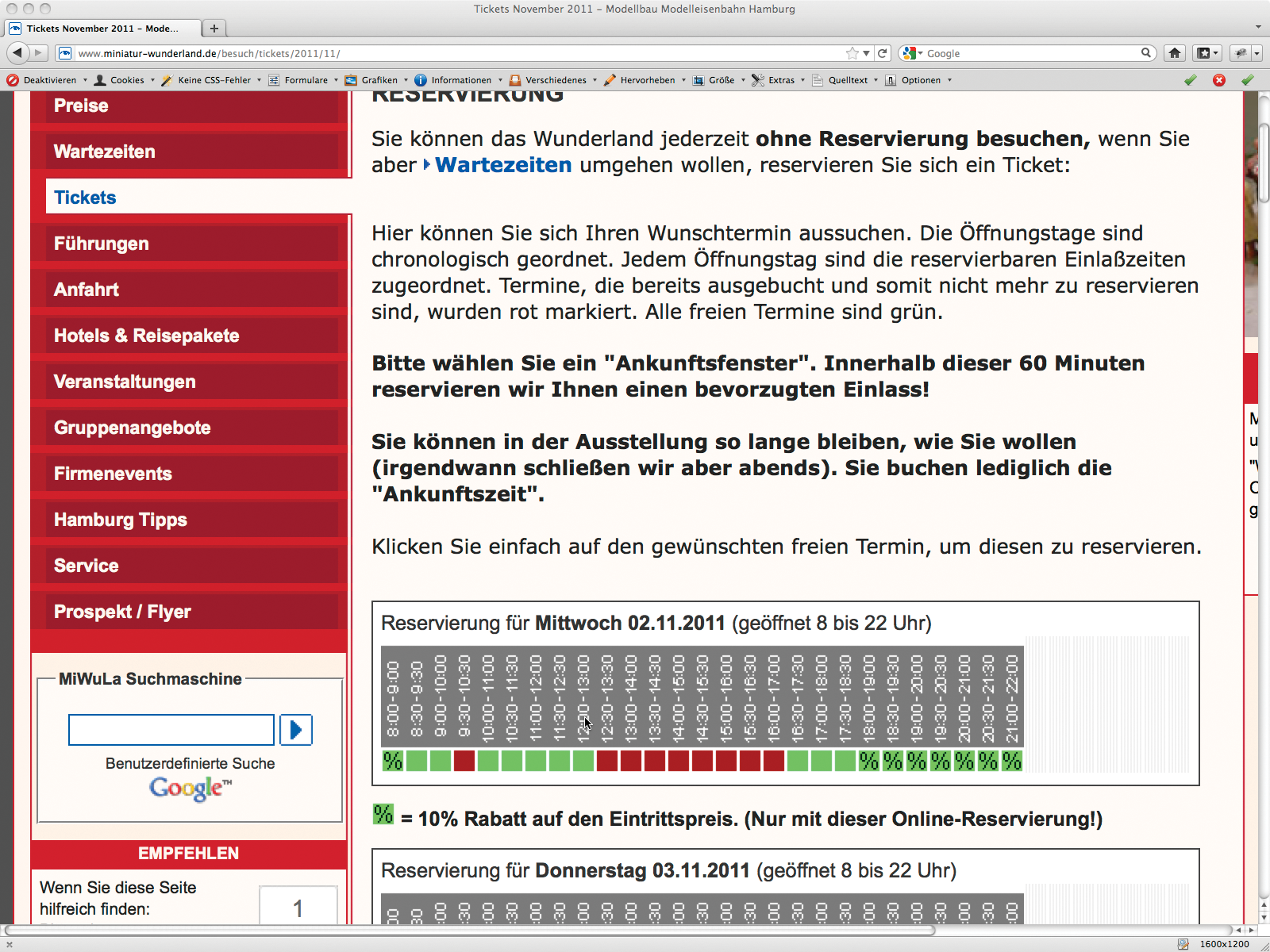
Abbildung 1: Wer vor dem Wunderland nicht warten will, reserviert sich seine Einlasszeit im Vorhinein.
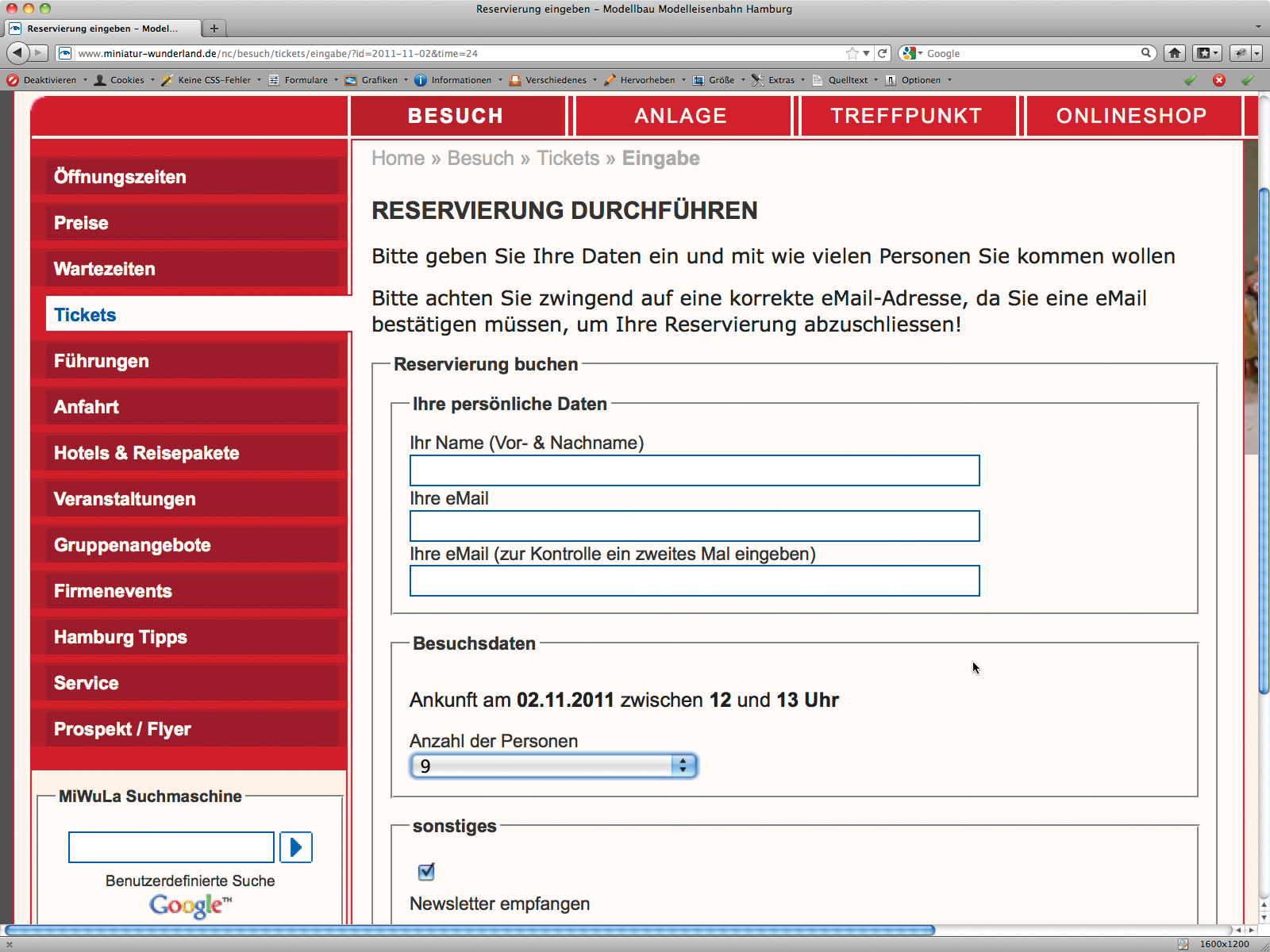
Abbildung 2: Gute Zeiten, schlechte Zeiten: Wer sich an die Regeln hält, klickt in der PHP-Applikation einen Link an und kann einen Platz für die Fast-Lane reservieren.
It’s »time« to say hello!
Am nächsten Tag, pünktlich 13 Uhr im Miniatur Wunderland, durften mein Gast und ich tatsächlich die Fast-Lane passieren – freie Bahn im Hacker-Wunderland. Nach unserer Rückkehr überkam mich abermals die Neugier. Denn der Index wies einen seltsamen Offset auf, außerdem wollte ich das Error-Handling noch etwas auf die Probe stellen. Also wählte ich einen Index, der sicher nicht vorgesehen ist: 100 (Abbildung 3).
Dabei zeigt sich, dass der Wert gar kein Index ist, sondern einfach das Doppelte der Anfangszeit des Timeslots. Für ungerade Werte ergibt sich der Einlass zur halben Stunde. Nach einem bisschen Experimentieren erkenne ich, dass die Anwendung »time« als Signed-64-Bit-Integer ablegt. Denn bei “Zeiten” größer als etwa 9 Trillionen (263) und für negative Werte erscheint die kuriose Fehlermeldung »Hacking attempt, script execution stoped!« . Die Anwendung checkt offenbar auch das Datum nicht, weil ich für längst vergangene Tage reservieren darf.
Was haben die Programmierer falsch gemacht? Wirksam wäre, wenn ihre Bestätigungsseite den Timeslot und das Datum abermals prüfen würde. Wenn sie das nicht wollen oder können, müssten sie zumindest verhindern, dass der Link für Dritte vorhersagbar ist. Dafür sollten die Entwickler jedem Zeitslot eine für die jeweilige Sitzung zufällige, aber eindeutige ID zuordnen. Der Aufwand, diese ID auf der Zielseite zu überprüfen, gleicht aber wohl dem, die Verfügbarkeit des Timeslots erneut zu prüfen.
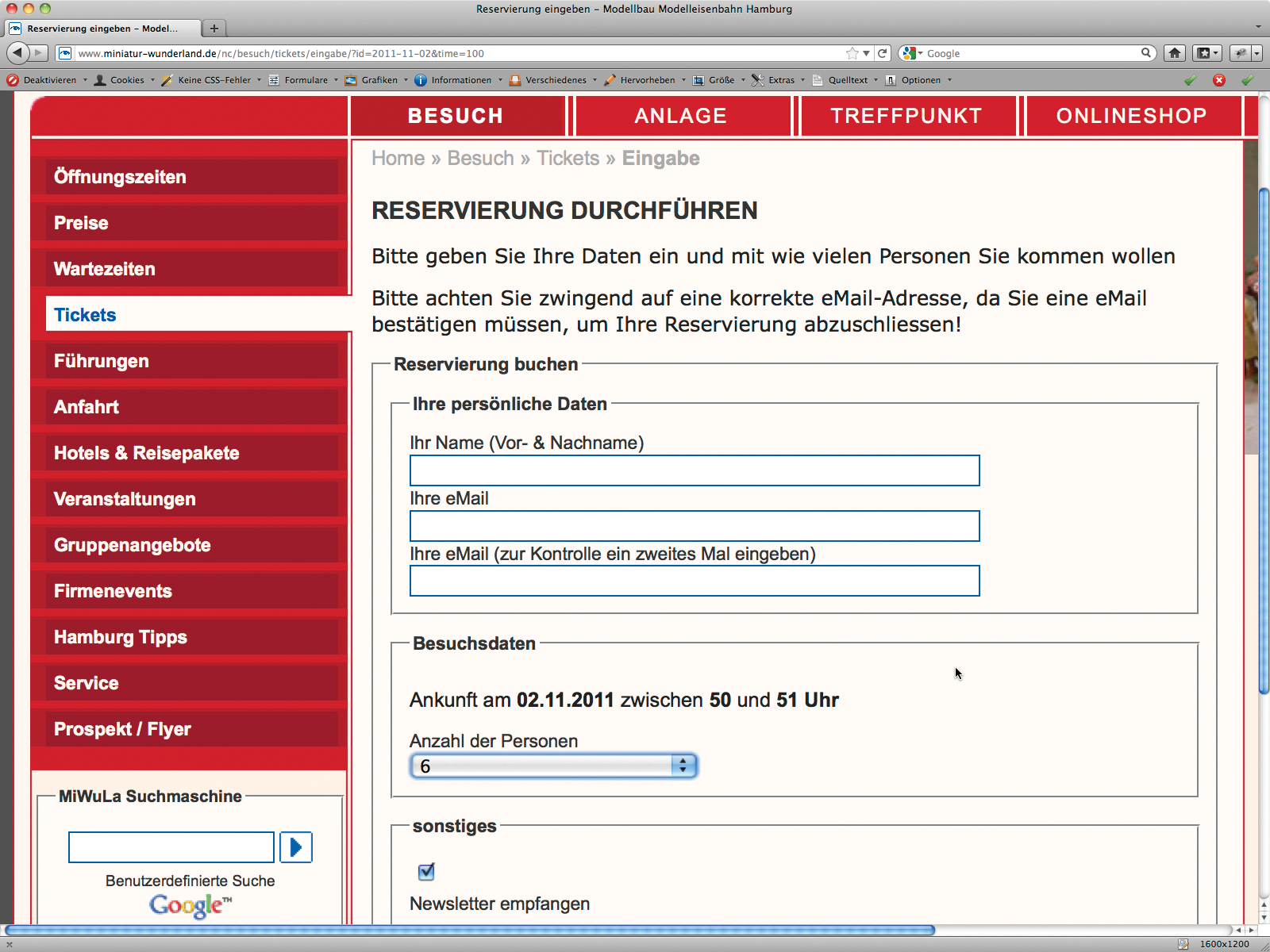
Abbildung 3: 50 bis 51 Uhr? Im Wunderland hat der Tag offenbar mehr als 24 Stunden.
PHP-Session-ID
Apropos Sitzung: Das Miniatur Wunderland vergibt eine PHP-Session-ID, wohl um das Surfverhalten der Nutzer zu verstehen. Im Hinblick auf den Datenschutz darf man das kritisch sehen, aber auch im Hinblick auf Vorhersagbarkeit liefern Session-IDs ein Beispiel – zumindest bis PHP 5.3.1, wie Samy Kamkar [2] auf der Blackhat 2010 [3] zeigte.
Miniatur Wunderland nutzt PHP 5.2.6, wie ich im HTTP-Header mit Firebug [4] herausfinde (Abbildung 4). Damit sind die Session-IDs vorhersagbar, auch wenn der dadurch anrichtbare Schaden überschaubar bleibt. Zum Demonstrieren des Angriffsprinzips eignet sich die Site allerdings schön: Jede Session bekommt eine zufällige, aber eindeutige ID zugewiesen. Ein Blick in die Funktion »php_session_create_id()« im PHP-API zeigt, dass die ID als Ausgangswert den aktuellen, Mikrosekunden-genauen Unix-Zeitstempel, die IP des Clients und einen Zufallswert beinhaltet. Das Konstrukt ist 148 Bit lang. Zum Tarnen wendet PHP auf diese Bitfolge eine Hashfunktion an, was auf die Zufälligkeit allerdings keine Auswirkung hat.
Die IP des entfernten Rechners ist leicht zu ermitteln, am einfachsten, indem man das Opfer über einen Linkverkürzer wie Tinyurl oder Bit.ly auf eine eigene Seite lotst und in die Zugriffslogs des Webservers schaut. Damit sind schon 4 Byte, also 32 Bit der ID bekannt.
Samy Kamkar möchte die Session-IDs in sozialen Netzen ausspähen. Er schlägt vor, sich einfach mit dem Adressaten des Angriffs virtuell zu befreunden, dann sähe man die Einlogzeit – den zweiten Bestandteil der Session-ID. Gangunterschiede zur lokalen Uhr lassen sich anhand des HTTP-Headers (Abbildung 4) erkennen. Dank der Zeit sind weitere 4 Byte der Session-ID bekannt – fehlen noch 84 Bit. Den größten Teil macht ein 64 Bit große Zufallswert aus, den die Funktion »php_combined_lcg()« liefert. Die prüft zunächst, ob der Zufallszahlengenerator schon initialisiert ist.

Abbildung 4: Wer nicht an der Konsole per Telnet HTTP tippen will, nutzt zum Beispiel das Analysetool Firebug, um dem fremden Server seine Versionsdaten abzuluchsen.
Pseudo ist eben nicht echt
Pseudozufallszahlen werden durch ein Berechnungsschema ermittelt, im Fall des hier verwendeten LCG-Algorithmus (linearer Kongruenzgenerator) handelt es sich um eine rekursiv definierte Folge Xn+1=(aXn+c) mod m. Jeder Zufallswert Xn+1 hängt also vom vorherigen Zufallswert Xn ab. Darum wird die Folge vorhersagbar, sobald ihr Startwert bekannt ist, denn die Parameter a (Faktor) und m (Modul) sind konstant.
Die Kunst ist es, einen nicht vorhersagbaren Startwert zu finden. In PHP erledigt dies »lcg_seed()« (Listing 1). Die Funktion setzt den 64 Bit langen Startwert aus zwei gleich langen Teilwerten »s1« und »s2« zusammen. »s2« bildet die Prozess-ID des Webservers ab, deren Wertebereich in der Praxis die theoretischen 32 Bit nicht mal annähernd ausnutzt. Der Standard-Linux-Kernel begrenzt ihn in »threads.h« auf 16 Bit. Viele Systeme vergeben die PIDs sogar aufsteigend, andere reservieren einen relativ kleinen Bereich. Lässt das Zielsystem gar eine PHP-Injection zu, würde »getmypid()« die Webserver-PID sogar genau ausgeben.
Auch »s1« nutzt nicht die vollen 32 Bit aus: Listing 1 verknüpft die Unix-Epoche (t1) mit den logisch negierten Mikrosekunden (t2) per XOR, also s1=t1 XOR (NOT t2). Doch ist t2 stets kleiner 1000 000. Damit ändern sich nur die niederwertigsten 20 Bits von t2, die anderen sind stets 0 (invertiert dann 1). Somit lassen sich die oberen 12 Bits direkt aus der Systemzeit ermitteln.
Der genaue Startzeitpunkt des Prozesses ist in einem Zeitfenster von 220 Sekunden (rund 12 Tage) unerheblich. Denn praktischerweise startet Apache Instanzen nach einer bestimmten Anzahl von Anfragen neu. Das bedeutet, dass mit einer ausreichend hohen Wahrscheinlichkeit ein solcher Neustart innerhalb der letzten zwölf Tage stattfand – t2 ist also nicht mehr signifikant.
Die niederwertigen 20 Bits von »s1« verbleiben als einzige Unbekannte. Das sind ausreichend wenig Werte, um sie durch einen Brute-Force-Angriff zu ermitteln. Samy Kamkar hat dafür ein kleines Beispielprogramm [5] geschrieben und ein Patch für PHP 5.3.1 eingereicht, das dann in PHP 5.3.2 eingeflossen ist und sogar nach 5.2.13 zurückportiert wurde.
Listing 1
lcd_seed() von PHP 5.3.1
01 /* Auszug aus ext/standard/lg.cm, gekürzt um einige IFDEFs */
02
03 static void lcg_seed(TSRMLS_D)
04 {
05 struct timeval tv;
06 if (gettimeofday(&tv, NULL) == 0) {
07 LCG(s1) = tv.tv_sec ^ (~tv.tv_usec);
08 } else {
09 LCG(s1) = 1;
10 }
11 LCG(s2) = (long) getpid();
12 LCG(seeded) = 1;
13 }
Die Alternative
Tatsächlich weist die neue Version in Listing 2 eine höhere Entropie auf: Zum einen verschiebt die Zeile 7 für »s1« die gelieferten Mikrosekunden um 11 Bit nach links, was genau den Teil der Epoche maskiert, der sich am wenigsten stark ändert. Auf diese Weise schließt sich das oben abgeschätzte Zwölf-Tage-Fenster. Zum anderen fragt Zeile 14 die Systemzeit ein zweites Mal ab, um die Mikrosekunden als Verschiebungsparameter für »s2« zu gewinnen.
Listing 2
lcd_seed() von PHP 5.3.8
01 /* Auszug aus ext/standard/lg.c, gekürzt um einige IFDEFs */
02
03 static void lcg_seed(TSRMLS_D)
04 {
05 struct timeval tv;
06 if (gettimeofday(&tv, NULL) == 0) {
07 LCG(s1) = tv.tv_sec ^ (tv.tv_usec<<11);
08 } else {
09 LCG(s1) = 1;
10 }
11 LCG(s2) = (long) getpid();
12
13 /* Add entropy to s2 by calling gettimeofday() again */
14 if (gettimeofday(&tv, NULL) == 0) {
15 LCG(s2) ^= (tv.tv_usec<<11);
16 }
17 LCG(seeded) = 1;
18 }
Zugleich versuchen die PHP-Macher mit dieser Maßnahme auch die Zufälligkeit von »s2« zu erhöhen. Das erscheint allerdings wenig weise, denn der Wert wird sich zwischen den beiden kurz aufeinanderfolgenden Aufrufen nicht wesentlich ändern, vermutlich nur in den niederwertigsten 4 bis 5 Bit.
Zwar shiftet Zeile 15 diese Mikrosekunden wieder um 11 Bit nach links, der Bereich ist aber maximal 16 Bit lang, auf Standardsystemen ohne Randomisierung der Prozess-ID eher 11 bis 12 Bit. Damit wird nur das oberste Bit der PID maskiert. »s2« ist nun immerhin nicht mehr zur Hälfte mit Nullen gefüllt, ähnelt dafür aber S1 ziemlich, was theoretisch Raum für neue Abschätzungen gibt. Sinnvoller wäre es, eine andere schwer vorhersagbare Zufallsquelle für »s2« heranzuziehen, statt ein zweites Mal die Systemzeit. Auf Linux-Systemen steht mit »/dev/random« bereits ein sehr guter Zufallsdatengenerator zur Verfügung.
GCC macht’s jetzt besser
Zufällig war der Zufall gerade erst Ende September 2011 bei GCC ein Thema, als Andi Kleen ein Patch [6] für den Compiler vorschlug, das das Seeding des GCC-Zufallszahlengenerators verbessert. Denn der initialisiert sich bis heute mit einer Mischung aus Prozess-ID und Systemzeit. Kleen fiel dieses Problem auf, als er in einer massiv parallelen Umgebung eine unzureichende Zufallszahlenqualität diagnostizierte.
Er schlägt als Verbesserung vor, »/dev/urandom« – sofern verfügbar – als Quelle für den Seed zu verwenden. Dabei bleibt jedoch ein kleines Zufalls-Restrisiko: Während »/dev/random« nur Zahlen liefert, solange sein Vorrat an durch Systemereignisse gefütterten Zufallsdaten ausreicht, emittiert »/dev/urandom« immer Zahlen. Deshalb könnte »/dev/random« blockieren und so den zugehörigen Prozess zum Stillstand bringen, bis wieder zufällige Ereignisse anfallen. Das ist für viele Anwendungen nicht tolerierbar, weshalb sich ein Ausweichen auf »/dev/urandom« empfiehlt. Damit sinkt zwar geringfügig die Zufälligkeit, allerdings ist das Eintreten des Effekts für den Angreifer nicht vorhersagbar.
Bind und Open SSL binnen eines Jahres im Visier
Ein Pseudozufallszahlen-Generator erwies sich 2008 auch als Ursache für DNS-Poisoning-Angriffe auf verschiedene BSD-Unixe, darunter Open BSD und Mac OS X [7]. Seit 1997 war bekannt, dass vorhersagbare, aufsteigende DNS-Anfragen-IDs ein Sicherheitsrisiko darstellen. Open BSD hatte darum damals schon einen Zufallszahlengenerator in seine Bind-Variante integriert, dabei aber – neben einem statischen UDP-Port – übersehen, wie stark der LCG-Algorithmus vom Startwert abhängt und wie wenig er sich für sichere Anwendungen eignet. Es gibt wesentlich bessere, kryptographisch sichere Zufallszahlengeneratoren.
Ebenfalls 2008 erwischte es die Open-SSL-Implementierung von Debian mit einer auf Zufallszahlen zurückzuführende Sicherheitslücke [8]. Durch ein Patch reduzierte sich der Startwert des Zufallszahlengenerators auf die Prozess-ID. Die maximal 16 Bit große Nummer vergab Debian aufsteigend. Ab dann war es leicht, zum Beispiel alle möglichen SSH-Keys einer Maschine vorauszuberechnen. Die dafür notwendigen Tools demonstriert [9].
Strategien für die Praxis
Sind trivialen Fälle wie beim Miniatur Wunderland abgehakt, wird klar: Das Hauptproblem fast aller digitaler Zufallszahlengeneratoren ist ihre Pseudozufälligkeit. Die Berechnung von Pseudozufallszahlen zu verstehen setzt eine Portion Neugier und mathematisches Interesse voraus. Man muss aber nicht Träger der Fields-Medaille sein, um zu kapieren, dass eine 148-Bit-Zufallszahl für eine Session-ID besser sein muss, als eine mit 64 Bit, die aus vorhersagbaren Werten kombiniert ist.
Beim verwendeten Seed lohnt es sich zu überlegen, woher die Zufallsdaten stammen. Folgt der Zufall einem Muster, dann wiegt der Generator seine Anwender in falscher Sicherheit. (Ein Beispiel aus einem Gebiet beleuchtet der Kasten “Kreditkartennummer erraten”.) Viele Kryptoalgorithmen erzeugen aber ihre Schlüssel mit Zufallszahlen. Sind die (in Teilen) vorhersagbar, lässt sich die Verschlüsselung leicht(er) knacken.
Für die Praxis heißt das: Wer seinen Zufallszahlengenerator sicher seeden will, der sollte auch echt zufällige Daten verwenden. Bevor man jedoch selbst versucht das Rad neu zu erfinden, lohnt sich das Beschäftigen mit »/dev/random« . Der erzeugt seine Zufallszahlen aus dem “Rauschen” des Systems und ist so nicht vorhersagbar. Außerdem gibt es nur so lange Daten, wie auch ausreichend Umgebungsrauschen vorhanden ist. Initialisiert man mit einem solchen Zufallswert einen kryptographisch sicheren Zufallszahlengenerator, ist es mit der Vorhersagbarkeit vorbei.
Außerdem lohnt es sich, auf bessere Zufallszahlenalgorithmen als LCG zurückzugreifen. Neben »lcg_rand()« bietet PHP die Funktionen »mt_rand()« , im Wesentlichen eine schnellere LCG-Implementation, und »rand()« , die sich auf den Zufallszahlengenerator des verwendeten C-Compilers stützt. (jk)
Kreditkartennummer erraten
Laut einer Google-Suche, also der landläufigen Meinung, lassen sich Kreditkartennummern nicht erraten. Diner’s Club vergibt 14-stellige Kartennummern, American Express 15-stellige und Visa und Mastercard nur noch 16-stellige. Damit ergeben sich 1014 bis 1016 Möglichkeiten für Kartennummern – theoretisch.
In der Praxis schränkt die Anatomie der Nummernvergabe den Wertebereich ein: Die erste Ziffer gibt den Schwerpunkt der Industriebranche an, der die Karte angehört. So sind Visa und Mastercard echte Banken und starten mit den Ziffern 4 und 5, während American Express aus der Reisebranche stammt und die 3 trägt.
Die ersten sechs Stellen einer Kreditkartennummer geben an, welche Bank die Karte ausgegeben hat. Zudem enthalten sie oft einen Hinweis auf die Kartenart. So lässt sich bei American Express an den ersten Ziffern ablesen, aus welcher Region die Karte stammt und welcher Kartenlevel assoziiert ist. Eine deutsche American Express beginnt mit 3750 [10], eine Platinum mit 37508. Bei Lufthansa sind in der Banknummer meinen Informationen zufolge der Status des Kunden und die Art der Karte (mit/ohne Businesspaket) kodiert.
Die darauf folgenden Positionen, mit Ausnahme der letzten, geben die bankinterne Kundennummer wieder. Eine Besonderheit konnte ich bei American Express beobachten: Dort markieren die Stellen 12 bis 14, ob es sich um die Partner- oder Hauptkarte handelt. Hauptkarten scheinen, sofern es Partnerkarten gibt, stets 300 als Wert zu haben. Partnerkarten tragen den Wert »10Fortlaufende_Nummer_der_Partnerkarte« . Andere Banken vergeben die interne Kundennummer offenbar auch nach einem Schema, das einfachste dürften aufsteigende Nummern sein.
Die Prüfsumme
Die letzte Zahl der Kreditkartennummer ist eine Prüfziffer, um Übertragungsfehler zu entdecken. Sie errechnet sich nach dem sehr einfachen Luhn-Algorithmus, der von rechts kommend jede zweite Stelle mit 2 multipliziert. Sollte das Ergebnis größer 9 sein, wird 9 subtrahiert. Aus diesen Ziffern und den verbleibenden Stellen entsteht die Summe. Ist sie durch 10 restlos teilbar, ist die Kartennummer gültig.
Durch die Gewichtung der benachbarten Stellen sind Zahlendreher sofort offensichtlich, die Sicherheit einer kryptographischen Prüfsumme ist jedoch nicht zu erreichen. Die Prüfsumme eignet sich für einen Schnellcheck, ob eine Kreditkartennummer gültig ist. Darum überrascht es nicht, dass es im Netz eine Vielzahl von Kreditkartengeneratoren gibt, die für diesen ersten Test plausible Nummern erzeugen.
Sternchen an verschiedenen Stellen
Onlineshops verkürzen eine Kreditkartennummer bei der Ausgabe, um den Klau der Kartendaten zu erschweren. Amazon gibt nur die letzten vier Stellen und den Typ der Karte aus, American Express nennt in Kunden-E-Mails und beim Onlinebanking die letzten fünf. Samsonite schreibt in die Bestellbestätigung die ersten vier und letzten beiden Ziffern. Bei Sixt finden sich die ersten vier und die letzten vier Stellen. Auf Tankbelegen sehe ich eigentlich alle weiteren Varianten. Einen Hochgenuss bereitete mir neulich ein Onlineshop, der alle – bis auf die letzte Stelle der Kartennummer – offen listet.
Aller Anfang ist leicht
In Kenntnis dieser Umstände kommen Angreifer wieder ein Stück weiter: Ist die letzte Ziffer bekannt, begrenzt sie den Wertevorrat aller anderen Stellen. Wäre nur eine Stelle unkenntlich, so lässt sich die sofort herleiten. Bei zwei versternten Stellen erwartet man 100 Ratemöglichkeiten, tatsächlich sind es nur neun. Beispiel American Express: Die Kartennummer hat 15 Stellen, die letzten fünf Stellen, verrät American Express freiwillig, lauten 71047. Die ersten vier sind auch bekannt: 3750. Damit bleiben noch sechs zu ratende Stellen.
Wer den Kartennutzer mal beobachtet hat, kennt die Farbe der Karte und damit deren Level. Alternativ lässt sich an der 104 erkennen, dass es sich um eine Partnerkarte handeln könnte – und es gibt nur wenige Kartenlevel, die vier Partnerkarten erlauben. Damit bleiben fünf offene Stellen. Statt der spontan zu erwartenden 100 000 Möglichkeiten gibt es hier nur 5904 gültige Kartennummern. Das lässt sich logisch herleiten oder auch empirisch bestimmen.
In einem Restaurant neulich tarnte der Beleg des Bezahlterminals gerade mal die letzten drei Stellen von American Express. Die viertletzte macht klar, dass es sich um eine Partnerkarte handelt. Damit sind die Werte der beiden vorletzten Stellen begrenzt. Die letzte Stelle errechnet sich nach Luhn. Damit sinken die Variationsmöglichkeiten von den sowieso schon mageren 103 auf eine (Partnerkarten sind durchnummeriert). Hier wird jeder Schuss ein Treffer.
Wer es selbst probieren möchte, findet in Listing 3 ein kleines Programm, das abhängig von den bekannten, also fixierten Stellen (»1« im Array »fixed« ) einer beliebigen Kartennummer alle möglichen gültigen Kartennummern mit der gleichen Prüfsumme ermittelt. Der Algorithmus ist bewusst simpel gestaltet und iteriert rekursiv durch alle Kombinationen.
Etwas Mathematik
Mit mehr Energie lässt sich erkennen, dass aufgrund der Struktur der Prüfsumme bestimmte Permutationen über einen Treffer auch Treffer sein müssen. Die Nummern darf ein weiterer Durchlauf ausblenden. Außerdem lassen sich zwei benachbarte Ziffern tauschen, wenn man sie geeignet verdoppelt oder halbiert. Mathematisch handelt es sich eigentlich um ein (stark) unterbestimmtes, nicht homogenes lineares Gleichungssystem. Darum lassen sich aus einer Lösung weitere direkt herleiten.
Die Konsequenz
Gelingt es einem Angreifer, über mehrere Shops, Belege oder E-Mails verschiedene Teile einer Kreditkartennummer zu ermitteln, reduziert er so die Anzahl der möglichen Varianten. Kennt er zudem den Kartentyp (siehe oben), schränkt das den Wertevorrat weiter ein. Besonders effektiv sind die Akzeptanzstellen, die die letzte Ziffer, die Prüfziffer, nicht ausblenden, was für fast alle Onlineshops gilt.
Die beste Lösung wäre, wenn alle Shops die Prüfziffern “versternen” würden. Angreifern macht es zudem das Leben schwer, wenn Zahlen aus dem mittleren Bereich, also nach der sechsten Ziffer, getarnt bleiben. Für weiter vorne stehende Ziffern lohnt der Aufwand nicht, die sind sowieso leicht ermittelbar.
Für einige Karten konnte ich schon Informationen zum Aufbau ermitteln, doch ist das nur ein überschaubarer Vorrat. Um weiter zu recherchieren, würde ich mich freuen, wenn an dem Thema Interessierte mir von eigenen Erkenntnissen berichten. Insbesondere interessieren mich bankinterne BIN-Konstruktionen analog zu den Beispielen Lufthansa und American Express sowie Besonderheiten innerhalb der Kundennummer, wie bei Amex-Partnerkarten.
Listing 3
Kartennummer raten
01 #!/bin/perl
02 @cc = (3,7,5,0,8,1,2,3,4,5,7,1,0,0,7);
03 @fixed = (1,1,1,1,1,1,0,0,0,0,1,1,1,1,1);
04
05 sub test_rekursiv
06 { my ($stelle, @ccnum) = @_;
07 my ($val, $pos, $summe);
08 if ($stelle < $#ccnum)
09 { if ($fixed[$stelle] == 1)
10 { test_rekursiv($stelle + 1, @ccnum);
11 }
12 else
13 { for ($val = 0; $val < 9; $val++)
14 { $ccnum[$stelle]=$val;
15 test_rekursiv($stelle +1, @ccnum);
16 }
17 }
18 }
19 else
20 { for ($summe=0, $pos=0; $pos <= $#ccnum; $pos++)
21 { $summe+= (($pos % 2) == 0) ? $ccnum[$pos] : (($ccnum[$pos]*2>9) ? $ccnum[$pos]*2-9 : $ccnum[$pos]*2);
22 }
23 if (($summe % 10) == 0 )
24 { print "Gueltige Nr: @ccnum\n";
25 }
26 }
27 }
28
29 test_rekursiv(0, @cc);
Infos
- Miniatur Wunderland: http://www.miniatur-wunderland.de
- Seite von Samy Kamkar: http://www.samy.pl
- Samy Kamkar, “Phpwn: Attacking sessions and pseudo-random numbers in PHP”: Blackhat US 2010
- Firebug: http://www.getfirebug.com
- Phpwn, “Attack on PHP sessions and random numbers”: Http://samy.pl/phpwn/
- GCC-Patch “Use urandom to get random seed”: http://gcc.gnu.org/ml/gcc-patches/2011-09/msg01769.html
- Amit Klein, Open BSD DNS Cache Poisoning: http://www.trusteer.com/sites/default/files/OpenBSD_DNS_Cache_Poisoning_and_Multiple_OS_Predictable_IP_ID_Vulnerability.pdf
- Debian-Sicherheitsankündigung für Open SSL: http://www.debian.org/security/2008/dsa-1571
- Debian-Open-SSL-Lücke: http://digitaloffense.net/tools/debian-openssl/
- Bank-Identifikationsnummern: http://en.wikipedia.org/wiki/List_of_Bank_Identification_Numbers





