
Der Standard für Threads unter Linux ist heute die Native Posix Threads Library (NPTL). Die Bibliothek überzeugt durch große Kompatibilität zum Standard und hohe Performance. Dieser Artikel untersucht die neue Threading-Engine und zeigt, wie Benutzeranwendungen davon profitieren.
Vor Kernel 2.6 herrschte bei Threads unter Linux große Verwirrung, denn gleich mehrere Implementationen konkurrierten um den ersten Platz: Linuxthreads, Gnu Pth, NGPT (Next Generation Posix Threads) und NPTL (Native Posix Threads Library). Mittlerweile hat sich die NPTL von Ulrich Drepper und Ingo Molnar durchgesetzt[1].
Verwirrende IDs
Die neuen Threads setzen allerdings eine bessere Thread-Abstraktion im Kernel voraus. Ein Prozess wird nun als Thread-Gruppe abgebildet. Ein Thread entspricht einer Kernel-Task, ein Prozess einer Thread-Gruppe mit einem Thread-Gruppenführer. Einem Kernel-Thread entspricht ein Userspace-Thread, denn NPTL benutzt das 1:1-Scheduling-Modell, siehe Abbildung 1.
Die Struktur »task_t« enthält zwei Werte vom Typ »pid_t«: »pid« ist die Task-ID, »tgid« die Thread-Gruppen-ID. Bei Single-Thread-Prozessen besitzen die beiden IDs den gleichen Wert. Userspace-NPTL-Code bildet die TID auf die Posix-Thread-ID (Thread-Handle) ab. Tabelle 1 stellt alle Identifikatoren der NPTL- Threads gegenüber.
|
Tabelle 1: |
||||
|---|---|---|---|---|
|
User-Mode-IDs |
Typ |
Funktion (Bibliothek) |
Kernel-Mode-Äquivalente |
Typ |
|
Posix-Thread-ID |
»pthread_t« |
»pthread_create()« (NPTL) |
– |
– |
|
PID (Prozess-ID) |
»pid_t« |
»getpid()« (Glibc/Systemaufruf) |
»task_t:tgid« (Thread-Gruppen-ID) |
»pid_t« |
|
TID (Kernel-Thread-ID) |
»pid_t« |
»clone()«, »gettid()«, |
»task_t:pid« (Thread-ID) |
»pid_t« |
Im Kernel erzeugt der Systemaufruf »clone()« einen neuen Thread mit Thread-ID (TID) und »tgid« (PID). Ist beim Aufruf von »clone()« das »CLONE_ THREAD«-Flag gesetzt, wird der neue Thread einer Gruppe zugeordnet. Anwendungsprogrammierer benutzen statt des Systemaufrufs besser die Posix-Schnittstelle. Als ID stehen ihnen der Thread-Handle und die PID zur Verfügung, die TID ist ein privates Detail der Kernel-Implementierung. Für Neugierige gibt es trotzdem zwei TID-bezogene Systemaufrufe, die keine entsprechenden Glibc-Wrapper-Funktionen besitzen: »gettid()« gibt die TID zurück, »tkill()«, sendet dem Thread ein Signal.
Das C++-Programm in Listing 1 zeigt die verschiedenen IDs an. Der Haupt-Thread erzeugt zunächst mit »pthread_create()« einen Arbeits-Thread und wartet dann auf ihn. Optional versteht das Programm eine Kommandozeilenoption für eine Verzögerung in Sekunden. Damit hat man beim Testen Gelegenheit, »ps« auszuführen und die Ergebnisse zu vergleichen. Zur Übersetzung des Code siehe den Kasten “Kompilieren”.
|
Kompilieren |
|---|
|
Alle hier aufgeführten Programme lassen sich mit dem Befehl »make Programm LDFLAGS=-lpthread« übersetzen, wobei Programm durch den Namen der jeweiligen C++-Datei zu ersetzen ist. In der gedruckten Version fehlen der Übersichtlichkeit halber die Includes. Die vollständigen Listings sind auf dem Server des Linux-Magazins [3] zu finden. |
Die Ausgabe des kompilierten Programms sieht so aus:
# ./ids Main thread: PID=3775, pthread_t= 4143878816, TID=3775 Worker thread: PID=3775, pthread_t= 4143877040, TID=3776
Die beiden Threads besitzen die gleiche PID, die der »getpid()«-Systemaufruf zurückgibt. Der Haupt-Thread hat die gleichen PID- und TID-Werte, weil er Thread-Gruppenführer ist. Das Kommando »ps« zeigt den Prozess an und die einzelnen Threads mit der Option »-m«. TIDs werden vom generischen PID-Allokator erzeugt, der durch einen cleveren Algorithmus von Molnar deutlich schneller und mit konstanter Komplexität O(1) arbeitet.
Das folgende Beispiel zeigt das Verhalten desselben Programms mit Linuxthreads. Der Kasten “Rückwärtskompatibilität” erklärt, wie man Linuxthreads aktiviert:
# export LD_ASSUME_KERNEL=2.4.1 # getconf GNU_LIBPTHREAD_VERSION linuxthreads-0.10 # ./ids Main thread: PID=3824, pthread_t=16384, U TID=3824 Worker thread: PID=3826, pthread_t=16386, U TID=3826
Im Gegensatz zu den alten Linuxthreads benutzt NPTL keinen Manager-Thread, dessen Aufgaben hat der Kernel übernommen.
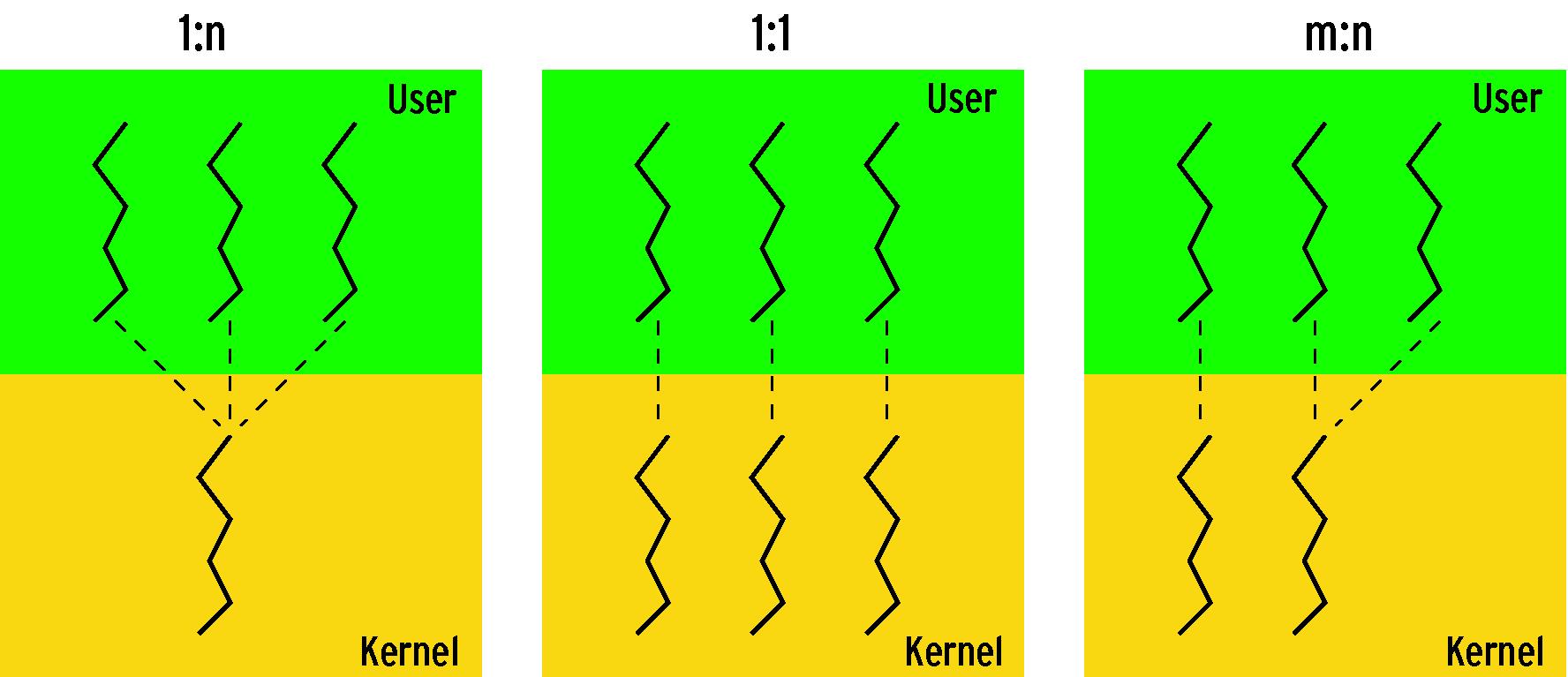
Abbildung 1: Drei Modelle ordnen Threads von User- und Kernelspace unterschiedlich zu. NPTL arbeitet nach dem 1:1-Modell.
Vaterschaftstest
Mit LWP-Threads gab es noch ein grundsätzliches Problem mit der Exec-Familie von Systemaufrufen: Wenn ein ande- rer als der Haupt-Thread eines Multi-Thread-Prozesses (MT-Prozesses) einen Prozess durch »fork()« und »exec…()« startet, erhält der Kindprozess als PPID (Parent Process ID) die Vater-Thread-PID. NPTL korrigiert dieses Fehlverhalten. In Listing 2 kreiert der Haupt-Thread einen Arbeits-Thread, der Mozilla startet. Die Ausgabe sieht unter Verwendung von NPTL so aus:
# ./spawn I'm main thread in the parent process: 19322 I'm forked process: 19324 from parent: 19322
Der Befehl »ps« zeigt zusätzlich die Mozilla-PID, die auch in der zweiten Meldung zu sehen ist.
Mit Linuxthreads ergibt sich ein anderes Resultat:
# export LD_ASSUME_KERNEL=2.4.1 # ./spawn I'm main thread in the parent process: 19337 I'm forked process: 19340 from parent: 19339
|
Rückwärtskompatibilität |
|---|
|
NPTL ist binärkompatibel zu Linuxthreads. Alle Anwendungen, die sich an den Posix-Standard halten, laufen weiterhin problemlos mit NPTL. Anwendungen, die weiterhin Linuxthreads benutzen möchten, haben folgenden Mechanismus zur Verfügung: Die bekannten Distributionen (Red Hat Linux 9.0, Suse Linux 9.1, Fedora Core 1, 2) liefern drei Versionen der »libpthread.so«:
In jedem der Verzeichnisse gibt es passende Runtime-Bibliotheken. Die OS-ABI-Versionen beziehen sich auf Red-Hat-Kernel. NPTL ist ab Kernel 2.5.36 verfügbar, Red Hat hat aber die nötigen Änderungen auf Version 2.4.20 rückportiert. Suse kommt ab Version 9.1 mit Kernel 2.6 und mit Glibc2.3/NPTL. Der dynamische Linker erfragt den Wert der Umgebungsvariablen »LD_ASSUME_KERNEL« und lädt die passende Bibliothek. Die Konfigurationsvariable »GNU_LIBPTHREAD_VERSION« zeigt die aktuelle Bibliotheksversion: # getconf GNU_LIBPTHREAD_VERSION NPTL 0.61 # export LD_ASSUME_KERNEL=2.4.1 # getconf GNU_LIBPTHREAD_VERSION linuxthreads-0.10 Dieselbe Information zeigt auch der folgende Befehl: `ldd Programm | grep libc.so.6 | cut -d' ' -f 3` | grep -i 'linuxthreads|nptl' Die NPTL-Bibliothek lässt sich sogar direkt ausführen: # /lib/tls/libpthread.so.0 NPTL 0.61 by Ulrich Drepper Copyright (C) 2003 Free Software Foundation, Inc ... |
|
Listing 1: |
|---|
01 void printThreadInfo(const char* pstrThread)
02 {
03 cout << pstrThread << ": PID=" << getpid() << ", pthread_t="
04 << pthread_self() << ", TID=" << syscall(__NR_gettid) << endl;
05 }
06
07 void* doWork(void* pArg)
08 {
09 printThreadInfo("Worker thread");
10 int nSeconds = *(int*)pArg;
11 sleep(nSeconds);
12 }
13
14 int main(int argc, char* const argv[])
15 {
16 printThreadInfo("Main thread");
17 int nSeconds = (argc > 1) ? atoi(argv[1]) : 0;
18 pthread_t hThread;
19 pthread_create(&hThread, 0, &doWork, (void*)&nSeconds);
20 pthread_join(hThread, 0);
21 return 0;
22 };
|
Hier ist die Haupt-Thread-PID 19337, die Arbeits-Thread-PID 19339 und die PID des Kindprozesses 19340. Die PPID des Kindprozesses ist 19339, weil ihn der Arbeits-Thread gestartet hat.
Die Routine »pthread_atfork()« registriert Funktionen, die das System unmittelbar vor und nach dem Systemaufruf »fork()« im Vater- und Kindprozess ausführt. Im Gegensatz zu Linuxthreads werden mit der NPTL diese Funktionen bei »vfork()« nicht ausgeführt.
Alle NPTL-Threads eines Prozesses dürfen gleichberechtigt auf den Kindprozess warten, wenn der Programmierer die »wait…()«-Systemaufrufe verwendet. Das geht mit Linuxthreads nicht. In Listing 3 forkt der Arbeits-Thread einen Prozess, auf den der Haupt-Thread wartet. Mit NPTL ist das Warten erfolgreich, bei Linuxthreads liefert die »waitpid()«-Funktion den Fehlercode »ECHILD«.
# ./wait waitpid successfull! # export LD_ASSUME_KERNEL=2.4.1 # ./wait waitpid failed: : No child processes
Eines der wichtigsten Designziele für NPTL war gute Skalierbarkeit. Die ersten Benchmarks zeigten sehr gute Ergebnisse. Entwickler Ingo Molnar erzeugte 100000 Threads in etwa 2 Sekunden – der gleiche Test mit Linuxthreads dauert 15 Minuten! Obwohl die meisten Anwendungen nur wenige Threads benutzen, gibt es auch solche, die Hunderte von Threads erzeugen: Serveranwendungen, die für jeden Request oder jede Verbindung einen Thread starten, oder virtuelle Maschinen mit Thread-Pools und asynchronen Frameworks. Damit das Betriebssystem mit der steigenden Anzahl von Threads gut skaliert, sollen Kernelroutinen möglichst konstante Komplexität besitzen.
|
Listing 2: |
|---|
01 void* doWork(void* pArg)
02 {
03 pid_t nChildPID = fork();
04 if (0 < nChildPID)
05 waitpid(nChildPID, 0, 0);
06 else if (0 == nChildPID)
07 {
08 cout << "I'm forked process: " << getpid() << " from parent: " << getppid() << endl;
09 execvp ("mozilla", 0);
10 exit(1);
11 }
12 return 0;
13 }
14
15 int main (int argc, char* const argv[])
16 {
17 cout << "I'm main thread in the parent process: " << getpid() << endl;
18 pthread_t hThread;
19 pthread_create(&hThread, 0, &doWork, 0);
20 pthread_join(hThread, 0);
21 return 0;
22 };
|
|
Listing 3: |
|---|
01 static pid_t nChildPID = 0;
02
03 void* doWork(void* pArg)
04 {
05 nChildPID = fork ();
06 if (0 == nChildPID)
07 {
08 exit(0);
09 }
10 return 0;
11 }
12
13 int main (int argc, char* const argv[])
14 {
15 pthread_t hThread;
16 pthread_create(&hThread, 0, &doWork, 0);
17 pthread_join(hThread, 0);
18 pid_t pid = -1;
19 if (0 >= (pid = waitpid(nChildPID, 0, 0)))
20 perror("waitpid failed: ");
21 else
22 {
23 assert(pid == nChildPID);
24 cout << "waitpid successfull!" << endl;
25 }
26
27 return 0;
28 };
|
|
Listing 4: |
|---|
01 void* doWork(void* pArg)
02 {
03 for (int i = 0; i < 4; ++i)
04 {
05 cout << "Worker thread doing the job!" << endl;
06 sleep(1);
07 }
08 return 0;
09 }
10
11 int main (int argc, char* const argv[])
12 {
13 pthread_t hThread;
14 pthread_create(&hThread, 0, &doWork, 0);
15 sleep(2);
16 cout << "Main thread sending SIGSTOP to worker thread!" << endl;
17 pthread_kill(hThread, SIGSTOP);
18
19 for (int i = 0; i < 2; ++i)
20 {
21 cout << "Main thread doing the job!" << endl;
22 sleep(1);
23 }
24
25 cout << "Main thread sending SIGCONT to worker thread!" << endl;
26 pthread_kill(hThread, SIGCONT);
27 pthread_join(hThread, 0);
28 return 0;
29 };
|
Flags für schnellere Threads
Um Threads schneller zu erzeugen und zu beenden, gibt es drei neue »clone()«-Flags: Das Flag »CLONE_SETTLS« erzeugt einen neuen Thread mit geladenem Thread-Register. Mit »CLONE_PARENT_SETTID« und »CLONE_CHILD_ CLEARTID« schreibt der Kernel die TID auf eine von der NPTL angegebene Adresse und löscht sie, nachdem der Thread sich beendet hat.
Das ermöglicht performante Verwaltung von Userspace-Speicherblöcken, die NPTL als Thread-Stacks benutzt. NPTL implementiert einen Stack-Cache, der die freigegebenen Stacks recycelt und dadurch teure Speicherallokierung vermeidet. Der neue Systemaufruf »exit_ group()« beendet schnell und korrekt einen Multithreading-Prozess.
Abbildung 2 zeigt die Ergebnisse eines Benchmarks mit Linuxthreads, Win32- und NPTL-Threads. Er spiegelt die Gesamtperformance aller Beteiligten wider: des Kernels beim Erzeugen oder Beenden der Threads, der Thread-Bibliothek, der Synchronisationsmechanismen und des Schedulers. Optionale Argumente sind die Anzahl der Threads (in Zweierpotenzen) und die Stackgröße. Jeder Thread startet zwei Nachfolger-Threads und wartet auf sie. Die Threads-Pyramide endet, wenn die angegebene Anzahl der Threads erreicht ist.
In allen Fällen geht NPTL als klarer Sieger hervor, obwohl der Stack-Cache nicht einmal aktiviert wird, denn alle Threads haben etwa die gleiche Lebensdauer. NPTL ist in allen Bereichen schneller als die Win32-Threads, besonders bei mehr als 2048 Threads, dann ist NPTL bis zum Faktor 4,5 schneller.
|
Mehr Threads |
|---|
|
Wer die Tests mit vielen Threads ausführen möchte, muss die folgenden zwei Variablen auf höhere Werte setzen: echo 100000 > /proc/sys/kernel/pid_max echo 100000 > /proc/sys/kernel/threads-max Die maximale Stackgröße lässt sich mit dem Bash-Befehl »ulimit -s Stackgröße in KByte« einstellen. |
Der Benchmark lief unter Fedora Core 2 und Windows XP SP 2 auf einem Athlon XP 2000+ mit 256 MByte RAM. Auf beiden Plattformen kamen zur Zeitmessung hochauflösende CPU-Timer zum Einsatz. Weitere Details sind in der Datei »readme« und im Quellcode des Unterverzeichnisses »perf« zu finden.
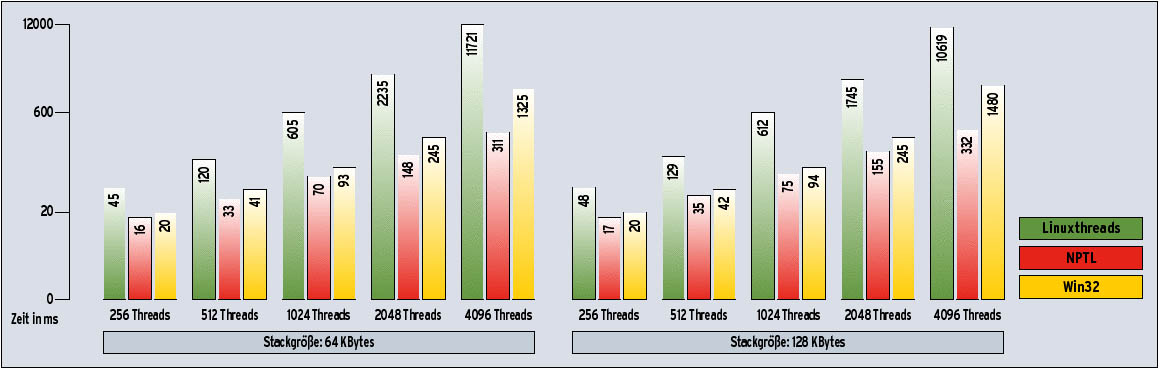
Abbildung 2: Das Diagramm zeigt die Ergebnisse des Benchmark für drei Thread-Typen. Die logarithmische Darstellung übertreibt Unterschiede bei wenigen Threads. Die Differenz zwischen dem größten und dem kleinsten Wert sieht deshalb geringer aus, als sie ist. NPTL ist in allen Fällen schneller als Linuxthreads und Win32.
Signalverarbeitung
Kernel 2.6 implementiert die Posix-konforme, prozessbezogene Signalbearbeitung. Damit beheben die Entwickler ein Problem mit dem »SIGSTOP«-Signal, wie Listing 4 demonstriert: Der Haupt-Thread kreiert einen Arbeits-Thread und sendet ihm das Signal. Mit NPTL werden die beiden Threads angehalten, was korrekte Jobverwaltung in der Shell ermöglicht sowie den MT-Prozess im Debugger anzuhalten.
Der Signal-Handler eines Prozesses kann in jedem Thread ausgeführt werden, der nicht das Signal blockiert. In Listing 5 registriert der Haupt-Thread einen Signal-Handler für »SIGUSR1« und erzeugt danach einen Arbeits-Thread, der sich gleich schlafen legt. Der Haupt-Thread blockiert das »SIGUSR1«-Signal und sendet es danach an den Prozess. Mit NPTL wird der Signal-Handler im Kontext des Arbeits-Thread ausgeführt, bei Linux- threads beendet sich das Programm, ohne das Signal zu bearbeiten.
|
Listing 5: |
|---|
01 void handler (int nSignalNo)
02 {
03 cout << "Signal SIGUSR1 received by thread: " << pthread_self() << endl;
04 }
05
06 void* doWork(void* pArg)
07 {
08 cout << "Worker thread (" << pthread_self() << ") doing the job!" << endl;
09 sleep(5);
10 return 0;
11 }
12
13 int main (int argc, char* const argv[])
14 {
15 struct sigaction sa;
16 memset (&sa, 0, sizeof (sa));
17 sa.sa_handler = &handler;
18 sigaction (SIGUSR1, &sa, 0);
19 pthread_t hThread;
20 pthread_create(&hThread, 0, &doWork, 0);
21
22 sigset_t signal_mask;
23 sigemptyset (&signal_mask);
24 sigaddset (&signal_mask, SIGUSR1);
25 pthread_sigmask (SIG_BLOCK, &signal_mask, 0);
26 cout << "Main thread (" << pthread_self() << ") sending SIGUSR1 to the process!" << endl;
27 kill(getpid(), SIGUSR1);
28 pthread_join(hThread, 0);
29
30 return 0;
31 };
|
|
Listing 6: |
|---|
01 class T
02 {
03 public:
04 T(const char* pstrThread): m_strThread(pstrThread) {}
05 ~T() {cout << m_strThread << " : destructor called!" << endl;}
06 private:
07 string m_strThread;
08 };
09
10 void* doWork(void* pArg)
11 {
12 T t("First thread");
13 pthread_setcanceltype (PTHREAD_CANCEL_ASYNCHRONOUS, 0);
14 sleep(10);
15 return 0;
16 }
17
18 void* doWork2(void* pArg)
19 {
20 T t("Second thread");
21 pthread_exit(0);
22 return 0;
23 }
24
25 void* doWork3(void* pArg)
26 {
27 try
28 {
29 T t("Third thread");
30 pthread_setcanceltype (PTHREAD_CANCEL_ASYNCHRONOUS, 0);
31 sleep(10);
32 }
33 catch(...)
34 {
35 cout << "Exception handler called!" << endl;
36 throw;
37 }
38 return 0;
39 }
40
41 int main(int argc, char* const argv[])
42 {
43 // create the three worker threads, cancel first and third, join them and exit
44 ...
45 return 0;
46 };
|
C++-Integration
NPTL bringt wichtige Verbesserungen für C++ mit. Abbrechen und Beenden eines Thread durch »pthread_cancel()« und »pthread_exit()« ähneln semantisch einer C++-Exception. Die Funktionen lösen lokale C++-Destruktoren und »catch()«-Exception-Handler aus.
Im Listing 6 erzeugt der Haupt-Thread drei Threads nacheinander. Der erste Thread legt eine Klasseninstanz vom Typ »T« an und wird danach vom Haupt-Thread asynchron abgebrochen. Der zweite Thread beendet sich selbst, der dritte verfügt über einen »catch()«-Exception-Händler und wird ebenfalls abgebrochen:
# ./cleanup First thread : destructor called! Second thread : destructor called! Third thread : destructor called! Exception handler called!
Es ist nicht mehr notwendig, im C++-Code die Cleanup-Händler mit »pthread _cleanup_push()« zu registrieren.
|
Listing 7a: |
|---|
01 int main (int argc, char* const argv[])
02 {
03 size_t nSize = 4*1024;
04 int fd = open("/tmp/pmutex", O_CREAT | O_TRUNC | O_RDWR);
05 ftruncate(fd, nSize);
06 void* pMem = mmap (NULL, nSize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
07 pthread_mutex_t* pMutex = (pthread_mutex_t *)pMem;
08
09 pthread_mutexattr_t a;
10 pthread_mutexattr_init (&a);
11 pthread_mutexattr_setpshared (&a, PTHREAD_PROCESS_SHARED);
12 pthread_mutex_init (pMutex, &a);
13 pthread_mutexattr_destroy(&a);
14
15 pthread_mutex_lock(pMutex);
16 cout << "Process 1 locked the mutex ..." << endl;
17
18 pid_t nChildPid = fork();
19 if (0 == nChildPid)
20 {
21 execvp("./process2", 0);
22 exit(1);
23 }
24
25 sleep (5);
26 pthread_mutex_unlock(pMutex);
27 cout << "Process 1 released the mutex!" << endl;
28 waitpid(nChildPid, 0, 0);
29 cout << "Process 1 exiting ..." << endl;
30 close(fd);
31 return 0;
32 }
|
|
Listing 7b: |
|---|
01 int main (int argc, char* const argv[])
02 {
03 int fd = open("/tmp/pmutex", O_RDWR);
04 void* pMem = mmap (NULL, 4*1024, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
05 pthread_mutex_t* pMutex = (pthread_mutex_t*)pMem;
06
07 cout << "Process 2 waiting for the mutex ..." << endl;
08 pthread_mutex_lock (pMutex);
09 cout << "Process 2 got the mutex ..." << endl;
10 pthread_mutex_unlock(pMutex);
11 cout << "Process 2 released mutex. Exiting ..." << endl;
12 close(fd);
13 return 0;
14 }
|
Synchronisationsprimitive
Eventuelle Zugriffskonflikte auf geteilte Ressourcen verhindern Posix-Synchronisationsprimitive: Mutex, Read-Write-Lock, Bedingungsvariable, Semaphor, Barriere und Spinlock.
Linuxthreads benutzte zur Synchronisation Signale, was zu vielen Problemen führte. Kernel 2.5.7 führte einen neuen Mechanismus ein, den Futex (Fast Userspace Mutex). Er besteht aus einem 4 Byte großen Integer-Flag an einer bestimmten Adresse und einer zugehörigen Warteschlange. Die Adresse darf sich im Shared-Memory-Bereich befinden, womit Futexe mehreren Prozessen zugänglich sind. Das schafft die Basis für die Implementierung der Interprozessvariante von allen Synchronisationsprimitiven (Option »_POSIX_THREAD_ PROCESS_SHARED«).
Ein Thread kann den freien Futex ohne Kernel-Intervention setzen (Fast-Path). Ist der Futex schon gesetzt, legt sich der Thread schlafen. Er wird vom Kernel erst wieder durch eine »FUTEX_WAKE«- oder »FUTEX_CMP_REQUEUE«-Aktion, einen Interrupt oder einen abgelaufenen Timeout geweckt.
Mehrere Threads können gleichzeitig auf einen Futex warten – dank der Futex-Warteschlange. Mit diesem flexiblen Basismechanismus lassen sich alle anderen Synchronisationsprimitive effizient implementieren. Anwendungsprogrammierer dürfen Futexe direkt in ihrem Code benutzen.
Die Listings 7a und 7b zeigen einen Interprozess-Mutex im Einsatz. Der erste Prozess (7a) legt den Mutex in einer, in seinem Adressraum eingeblendeten Datei an, setzt ihn und startet dann den Prozess im Listing 7b. Der zweite Prozess blendet dieselbe Datei in seinen Adressraum ein, nimmt die Mutex-Referenz und versucht den Mutex zu setzen. Er muss aber warten, bis der erste Prozess den Mutex freigibt.
Thread-lokaler Speicher (TLS) enthält Daten, von denen es je eine Instanz per Thread gibt. Die meisten Plattformen stellen dafür so genannten Thread-Register zur Verfügung. Auf IA-32 und x86-64 war die TLS-Implementierung früher etwas problematisch. Sie benutzte die LDT-Strukturen (Local Descriptor Table), was die maximale Anzahl der Threads per Prozess auf 8192 beschränkte.
|
Änderungen in |
|---|
|
Das virtuelle Proc-Dateisystem hat in Kernel 2.6 einige Änderungen erfahren. Jeder Prozess besitzt außer dem Verzeichnis »/proc/pid« nun ein Unterverzeichnis »task« für die Thread-Einträge. Die Datei »/proc/pid/stat« zeigt im 20. Feld die Anzahl der Threads, die auch im neuen Threads-Feld von »/proc/pid/status« steht. Thread-Einträge unterscheiden sich nicht von Single-Prozess-Einträgen. In der Ausgabe von »/proc/pid/task/tid/stat« steht jedoch die TID am erster Stelle, während die Vater-Task-TID als viertes Feld erscheint. Die Datei »/proc/pid/task/tid/status« zeigt in den »Tgid«-, »Pid«- und »PPid«-Feldern die Werte der PID, TID und PTID. Die maximale Anzahl der PIDs ist auf vier Millionen gesetzt, »/proc« kann bis zu 64 K Einträge haben. Der Autor empfiehlt sein QT-basiertes Prozess-Monitoring-Tool[2], um Prozess- und Thread-Infos zu analysieren. |
Thread-Speicher
Ingo Molnar implementierte im Kernel 2.5.28 einen neuen Mechanismus für Thread-lokalen Speicher. Der Kernel besitzt eine GDT-Struktur (Global Descriptor Table), in der der neue Systemaufruf »set_thread_area()« für jeden Thread Einträge anlegt. NPTL benutzt das Flag »CLONE_SETTLS«, um den GDT-Eintrag gleich beim Kreieren des Thread einrichten zu lassen.
Die Posix-Funktionen »pthread_getspecific()« und »pthread_setspecific()« reservieren dynamisch Thread-lokale Variablen über Key-Value-Paare. Für eine einfache Variable ist dieser Verwaltungs-Overhead zu groß. Auch die Benutzung der Funktionen in dynamisch geladenen Modulen ist problematisch. Die GCC-Familie bietet für beide Fälle die Extension »__thread«, die eine Variable als Thread-lokal deklariert. Ein Beispiel ist die C-Runtime-Variable »errno«.
Nichts ist perfekt
Die Designziele der NPTL sind erreicht, trotzdem gibt es noch Anlass zur Kritik. NPTL implementiert den Thread-Handle als einen Zeiger auf den zugehörigen Thread-Deskriptor. Der Handle hat daher große Werte, was die Übersicht erschwert. Außerdem verwendet der Stack-Cache den Handle wieder. Das verwirrt, wenn man zwei nacheinander kreierte Threads mit dem gleichen Handle debuggt. Zweites Problem sind die Ressourcen des MT-Prozesses. Standardmäßig sollen sie von allen Threads geteilt werden. Beim aktuellen Kernel können aber zwei Threads verschiedene UIDs oder verschiedene Ressourcen-Limits haben. Betroffen sind die Systemaufrufe »getuid()«, »setuid()«, »getgid()«, »setsid()«, »nice()«, »getrlimit()« und »setrlimit()«. (ofr)
|
Infos |
|---|
|
[1] Ulrich Dreppers Homepage: [http://people.redhat.com/drepper] [2] Prozess-Monitoring-Tool Pscan: [http://forge.novell.com/modules/xfmod/project/?pscan] [3] Vollständige Listings zum Artikel: [https://www.linux-magazin.de/Service/Listings/2005/01/NPTL/]. |
|
Der Autor |
|---|
|
Aleksandar Colovic arbeitet als Senior-Software-Entwickler bei der Evosoft GmbH. Seine Interessen sind Betriebssysteme, Komponenten-Frameworks und Middleware-Technologien. |





