
© Anastasiia Yanishevska / 123RF.com
Rekurrente neuronale Netze ermöglichen das effiziente Verarbeiten sequenzieller Daten. Im Gegensatz zu gewöhnlichen Netzen enthalten sie einen Rückkopplungsmechanismus, sodass sich das Netz an vergangene Teile der Sequenz erinnert.
Neuronale Netze können komplexe Probleme des maschinellen Lernens lösen. Dabei kommen je nach Problemstellung verschiedene Architekturen zum Einsatz. Gilt es, visuelle oder andere hochdimensionale Daten zu verarbeiten, bieten sich beispielsweise Convolutional Neural Networks (CNNs [1]) an.
Zahlreiche Probleme des maschinellen Lernens müssen dagegen sequenzielle Daten verarbeiten, etwa bei der maschinellen Übersetzung von Texten. Hier besteht die Datensequenz aus verschiedenen Wörtern in einer Sprache, die auf Wörter in einer anderen Sprache abzubilden sind. Bei derartigen sequenziellen Daten hängen aktuelle Beobachtungen von früheren Beobachtungen ab, die Beobachtungen sind also nicht unabhängig voneinander. Das liegt daran, dass die Wörter in einem Text nicht zufällig aufeinanderfolgen, sondern durch Logik und Grammatik voneinander abhängen.
Traditionelle neuronale Netze behalten keine historischen Informationen und betrachten jede Beobachtung als unabhängig. Beim Übersetzen von Texten muss sich das Netz jedoch an vorhergehende Wörter erinnern. Eine stumpfe Wort-für-Wort-Übersetzung funktioniert nicht und führt zu unsinnigen Ergebnissen.
Zur Verarbeitung sequenzieller Daten wurden deshalb rekurrente neuronale Netze (RNN) entwickelt. Sie führen das Konzept des Gedächtnisses in neuronale Netze ein, indem sie die Abhängigkeit zwischen Datenpunkten berücksichtigen. Mit diesem Ansatz lassen sich RNNs darauf trainieren, Konzepte basierend auf dem Kontext zu behalten und wiederkehrende Muster zu erlernen.
Anwendungen
RNNs lassen sich für diverse Anwendungen einsetzen (Abbildung 1). Bei One-to-Many-RNNs gibt es eine Eingabe und viele damit verbundene Ausgaben. Eines der am häufigsten verwendeten Beispiele für diesen Typ ist die Bildbeschreibung, bei der das Netz anhand eines Bilds einen Satz mit mehreren Wörtern bildet. Als Eingabe fungiert dabei oft die Ausgabe eines CNNs, das das Bild analysiert hat. Das RNN transformiert das Resultat dann in eine Textausgabe.
Bei Many-to-One-RNNs erhält das Netz viele Eingaben, generiert jedoch nur eine Ausgabe. Diese Art von Netzen kommt bei Problemen wie der Sentimentanalyse zum Einsatz. Dabei übergibt man mehrere Wörter als Eingabe an das Netz, das dann den Gefühlsgehalt (Sentiment) des Texts voraussagt. Many-to-Many-RNNs erhalten mehrere Eingaben und liefern mehrere Ausgaben. Ein Beispiel dafür ist die Sprachübersetzung, die mehrere Wörter aus einer Sprache auf mehrere Wörter aus der zweiten Sprache abbildet.
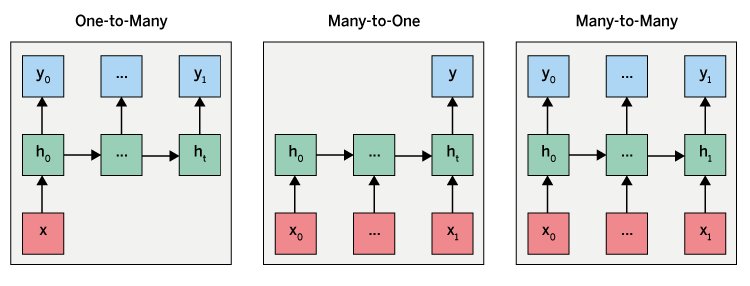
Abbildung 1: Der sequenzielle Eingabevektor ist als xt gekennzeichnet. Aus diesen Eingaben berechnet das RNN zunächst versteckte Zustandsvektoren ht und daraus dann die Ausgabevektoren yt. Die t-Variable gibt dabei immer den Zähler in der Sequenz an.
Funktionsweise
Das Gedächtnis eines RNNs erzeugt eine Rückkopplungsschleife – der Hauptunterschied zwischen einem RNN und einem traditionellen neuronalen Netz. Die Rückkopplungsschleife ermöglicht es, Informationen innerhalb einer einzelnen Schicht weiterzugeben. Im Gegensatz dazu propagieren vorwärts gerichtete neuronale Netzwerke wie CNNs die Informationen immer nur von der Eingabe in Richtung auf die Ausgabe. RNNs stellt man meist wie in Abbildung 2 auf kompakte Weise dar.
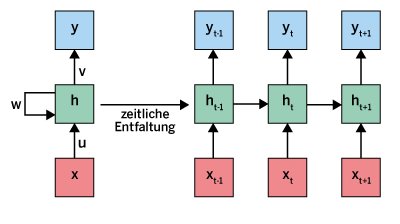
Abbildung 2: Die Schleife in der Abbildung symbolisiert die Rückkopplung. Rechts sieht man die zeitliche Entfaltung dieses RNNs für drei Schritte einer Sequenz.
Die Berechnung des versteckten Zustandsvektors ht erfolgt in einem RNN gemäß folgender Formel:
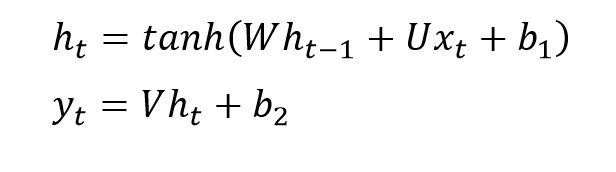
Die Matrix W beschreibt dabei den Übergang vom versteckten Zustandsvektor ht-1 (Zeit: t-1) zum versteckten Zustandsvektor ht (Zeit: t). Die Matrix U beschreibt dagegen den Übergang vom Eingabevektor xt zum versteckten Zustandsvektor ht. Der eigentliche Ausgabevektor wird schließlich mithilfe der Matrix V berechnet, die den Übergang vom versteckten Zustandsvektor zum Ausgabevektor beschreibt. Die Vektoren b1 und b2 enthalten die Bias-Werte für die Berechnung des versteckten Zustandsvektors und des Ausgabevektors.
Die Aktivierungsfunktion ist hier als hyperbolische Tangensfunktion (tanh) implementiert. Stattdessen könnte auch eine ReLU- (Rectified Linear Unit) oder Sigmoid-Funktion zum Einsatz kommen [2]. Die Matrix W gewährleistet in dieser RNN-Architektur die Rückkopplung, indem sie den vorherigen versteckten Zustandsvektor ht-1 an den aktuellen versteckten Zustandsvektor ht koppelt.
Eine weitere gebräuchliche Darstellung eines RNNs sehen Sie in Abbildung 3. Sie zeigt schematisch die zentrale Berechnung des neuen Zustandsvektors in einer Zelle des RNNs, basierend auf dem Eingabevektor und dem alten Zustandsvektor. Eine solche kompakte Darstellung der Operationen in einer RNN-Zelle ist insbesondere für komplexere RNN-Architekturen nützlich.
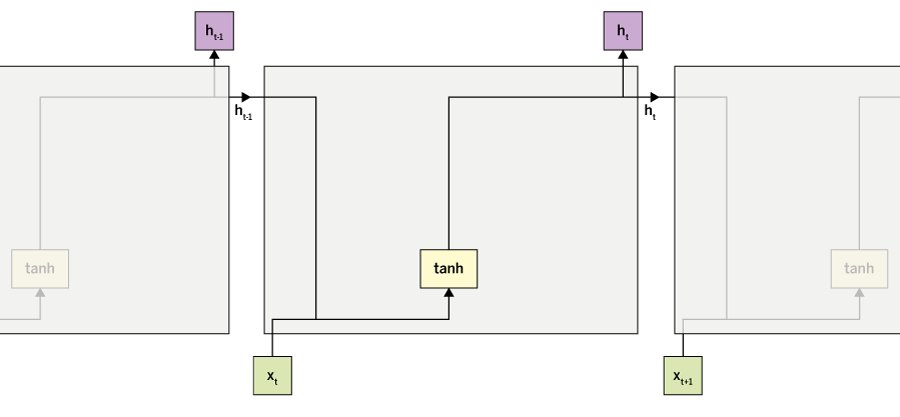
Abbildung 3: Eine schematische Darstellung der Berechnung des Zustandsvektors basierend auf dem Eingabevektor und dem vorherigen Zustandsvektor.
Das Training erfolgt bei RNNs genauso wie bei anderen neuronalen Netzen durch Fehlerrückführung (Backpropagation). Allerdings nimmt hier die Sequenz die Backpropagation vor (Backpropagation Through Time, BPTT). Bei BPTT wird der am Ende einer Sequenz auftretende Fehler rückwärts durch das Netzwerk propagiert, wobei der Algorithmus die Gewichte entsprechend anpasst, um die Verlustfunktion des Netzes weiter zu minimieren.
BPTT läuft wie folgt ab: Zunächst aktiviert man das Netz durch Vorwärtspropagation, um Vorhersagen für jeden Zeitschritt in der Sequenz zu machen. Anschließend wird der Fehler über die Zeit rückwärts propagiert, um die Beiträge jedes Gewichts zur Verlustfunktion zu berechnen. Diese dabei auftretenden partiellen Ableitungen dienen kumuliert zur Aktualisierung der Gewichte, typischerweise unter Verwendung eines Optimierungsalgorithmus wie des Gradientenverfahrens.
Die Propagierung der Gradienten kann bei RNNs allerdings zu Problemen führen, wenn die Gradienten im Verlauf des Prozesses exponentiell schrumpfen. Dieses sogenannte Problem der verschwindenden Gradienten führt dazu, dass sich das RNN keine längeren Sequenzen merken kann. Ähnliche Probleme treten auch bei sehr tiefen Netzen des Deep Learnings auf, wo dann der Trainingsprozess stagniert. Insbesondere bei langen Sequenzen können die Gradienten zu den frühen Zeitpunkten der Sequenz stark abnehmen, sodass das RNN kritische Dinge vergisst.
Long Short-Term Memory
Dieses Problem lässt sich lösen, indem das RNN entscheidet, welche Informationen relevant genug sind, um sie im Gedächtnis zu behalten. Einen solchen Ansatz verfolgt die Architektur des Long Short-Term Memory (LSTM).
LSTM-Netze wurden speziell entwickelt, um das Gradientenproblem zu umgehen und eine effektive Modellierung von langen Sequenzen zu ermöglichen. Durch ihre komplexe interne Zellstruktur mit speziellen Steuer-Gates können LSTM-Zellen relevante Informationen über lange Zeitintervalle hinweg speichern und aktualisieren, während sie gleichzeitig das Verschwinden von Gradienten vermeiden. Dadurch haben sich LSTM-Netze als äußerst nützlich in verschiedenen Anwendungsgebieten erwiesen, unter anderem in Sprachverarbeitung, Zeitreihenanalyse und maschinellem Übersetzen.
Bei einem LSTM ersetzt eine Speicherzelle den versteckte Layer der standardmäßigen RNNs (Abbildung 4). Sie verwendet drei Steuer-Gates, um zu kontrollieren, ob die aktuelle Zelle vergessen werden kann (Forget Gate f), ob ihre Eingabe gelesen werden muss (Input Gate i) oder ob der neue Zellenwert ausgegeben werden soll (Output Gate o). Hat das Gate den Wert 1, behält LSTM den Zellenwert der entsprechenden Schicht bei. Bei einem Wert von 0 wird der Zellenwert auf null reduziert.
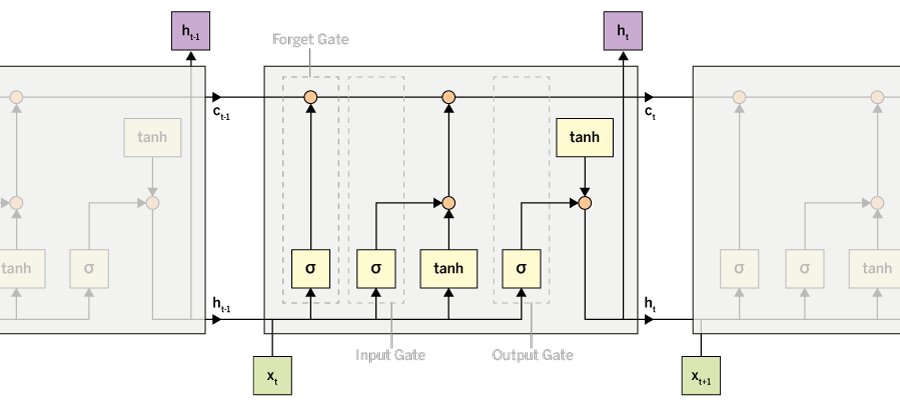
Abbildung 4: Beim Long Short-Term Memory ersetzt eine Speicherzelle den versteckten Layer.
Die Definitionen aller Gates, die Zellaktualisierung und die Ausgabe zum Zeitpunkt t bestimmen sich bei einem LSTM nach folgender Formel:
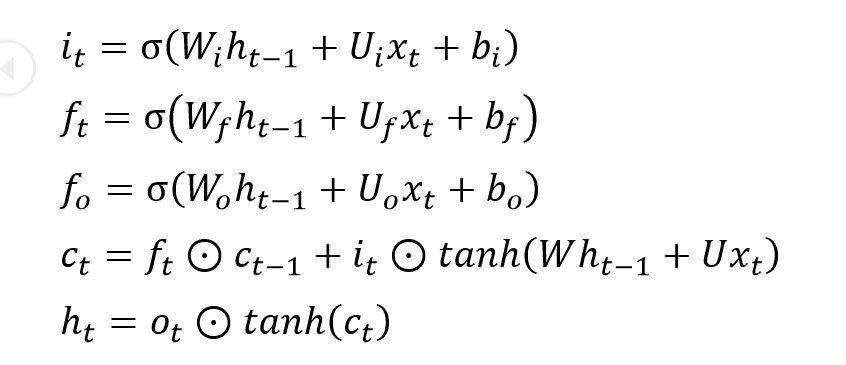
Das Zeichen mit dem Punkt in einem Kreis steht hier für eine elementweise Multiplikation von Vektoren. Bei den Variablen mit dem Subskript i handelt es sich um die Parameter des Input-Gates. Entsprechend sind Variablen mit Subskript f und o Parameter der Forget- und Output-Gates. Die Gates verwenden Sigmoid-Aktivierungsfunktionen, da sie Werte zwischen 0 und 1 liefern müssen.
Die gesamte Architektur des Long Short-Term Memory (LSTM) und insbesondere der Speicherzellen ermöglicht es dem Netz, relevante Informationen über lange Zeiträume hinweg zu speichern und zu aktualisieren. Dagegen ermöglichen die Steuer-Gates die Kontrolle über das Vergessen, Lesen und Ausgeben von Informationen. Dadurch eignen sich LSTM-Netzwerke besonders gut dazu, langfristige Abhängigkeiten in Sequenzdaten zu modellieren.
Zu jedem Zeitpunkt t empfängt ein LSTM einen Eingabevektor xt, den versteckten Zustandsvektor ht-1 sowie den Zellzustandsvektor ct-1, der im vorherigen Moment (t-1) bestimmt wurde. Das Forget-Gate entscheidet basierend auf den Vektoren xt und ht-1, welche Informationen aus dem Zellzustandsvektor ct-1 zur Zeit t-1 entfernt werden sollen. Dazu bestimmt es einen Selektorvektor ft. Den multipliziert es dann elementweise mit dem als Eingabe von der LSTM-Einheit empfangenen Zellzustandsvektor ct-1. An einer Stelle, an der der Selektorvektor den Wert null hat, wird also die Information, die sich an derselben Stelle im Zellzustand befindet, vollständig entfernt. An einer Stelle, an der der Selektorvektor den Wert eins hat, bleibt die Information unverändert, die sich an derselben Stelle im Zellzustand befindet.
Nach dem Entfernen einiger Informationen aus dem empfangenen Zellzustandsvektor ct-1 wird ein neuer Zustandsvektor ct bestimmt. Dazu bestimmt das Input-Gate basierend auf xt und ht-1 einen neuen Selektorvektor it, den es dann mit einem Kandidatenvektor multipliziert. Den Kandidatenvektor bestimmt das Gate basierend auf xt und ht-1 und normalisiert ihn durch eine hyperbolische Tangensfunktion (tanh). Die Tanh-Funktion stellt sicher, dass alle Werte des Kandidatenvektors zwischen -1 und 1 liegen, was für die Normalisierung der dem Zellzustandsvektor hinzuzufügenden Informationen sorgt.
Die elementweise Multiplikation des Selektor- und des Kandidatenvektors löscht erneut an jeder Nullstelle des Selektorvektors die korrespondierenden Informationen des Kandidatenvektors. An einer Stelle, an der der Selektorvektor den Wert eins hat, bleiben die entsprechenden Informationen aus dem Kandidatenvektor dagegen unverändert. Das Ergebnis der Multiplikation wird zu dem gefilterten Zellzustandsvektor addiert, was dem Zellzustandsvektor ct neue Informationen hinzufügt.
Das Output-Gate bestimmt schließlich den Wert des versteckten Zustands ht, den das LSTM zum Zeitpunkt t ausgibt und im nächsten Moment (t+1) als Eingabe wieder empfängt. Das Erzeugen dieses versteckten Zustands ht funktioniert ebenfalls mit einer Multiplikation zwischen einem Selektor- und einem Kandidatenvektor. Der Kandidatenvektor wird in diesem Fall durch Anwenden der Tanh-Funktion auf den Zellzustandsvektor ct berechnet. Dieser Schritt normalisiert abermals die Werte des Zellzustandsvektors auf den Bereich von -1 bis 1. Das ermöglicht es, die Stabilität des Netzwerks über den Lauf der Zeit zu kontrollieren.
Mit dieser recht komplexen Architektur gelingt es dem LSTM-RNN, das Problem der verschwindenden Gradienten von gewöhnlichen RNNs zu umgehen und keinen Gedächtnisverlust zu erleiden. LSTM stellt damit eine der am weitesten verbreiteten RNN-Architekturen dar.
Neben den LSTM-RNNs wurden noch weitere RNN-Architekturen entwickelt, beispielsweise die Gate Recurrent Unit (GRU). Ein Hauptunterschied zwischen LSTM und GRU liegt in der jeweiligen Komplexität und Struktur. Die GRU-Architektur ist eine vereinfachte LSTM-Version mit weniger Gate-Mechanismen. Ein weiterer Unterschied liegt in der Berechnungseffizienz und Parameteranzahl.
Aufgrund ihrer Einfachheit haben GRUs weniger Parameter und sind daher schneller trainierbar als LSTMs. Das macht sie insbesondere attraktiv für Anwendungen, bei denen Geschwindigkeit eine wichtige Rolle spielt. Allerdings haben LSTMs aufgrund ihrer zusätzlichen Gating-Mechanismen oft eine bessere Fähigkeit, langfristige Abhängigkeiten zu modellieren und zu erfassen. Das kann sie besonders effektiv machen, wenn es gilt, komplexe Sequenzmuster zu erkennen.
Insgesamt stellen GRUs wie LSTMs leistungsfähige Werkzeuge für die Modellierung sequenzieller Daten dar. Die Wahl zwischen ihnen hängt oft von den spezifischen Anforderungen der Anwendung sowie von Kompromissen zwischen Geschwindigkeit und Modellkomplexität ab.
Fazit
RNNs und insbesondere LSTMs/GRUs haben in vielen Bereichen der künstlichen Intelligenz bahnbrechende Erfolge erzielt. In der Sprachverarbeitung kommen sie für Übersetzungen, Textgenerierung und Spracherkennung zum Einsatz. In der Bildverarbeitung helfen sie bei der Analyse von Videosequenzen und der Objekterkennung. Auch in der medizinischen Forschung und Finanzanalyse spielen sie eine wichtige Rolle.
Daneben gibt es noch einige weitere verbreitete RNN-Architekturen. Dazu zählen die bidirektionalen RNNs, die Informationen sowohl vorwärtsgerichtet als auch rückwärtsgerichtet verarbeiten. Dazu verwenden sie zwei separate Schichten von Neuronen: eine, die eine Sequenz vorwärtsgerichteter Daten durchläuft, und eine andere, die eine Sequenz rückwärtsgerichteter Daten durchläuft. Durch diese Dualität können sie Kontextinformationen sowohl aus der Vergangenheit als auch aus der Zukunft berücksichtigen. Das ist besonders nützlich, um die Bedeutung von Wörtern oder Zeichen in einer Sequenz besser zu verstehen.
In den letzten Jahren wurden RNNs teilweise von der Transformer-Technologie abgelöst. Als Transformer bezeichnet man fortschrittliche neuronale Netzwerke zur Verarbeitung natürlicher Sprache. Im Gegensatz zu traditionellen RNNs nutzen sie Aufmerksamkeitsmechanismen, um lange Sequenzen effizient zu verarbeiten. Dadurch können sie komplexe Zusammenhänge in Texten besser erfassen und übertreffen bei vielen Aufgaben der Sprachverarbeitung RNNs. Dennoch finden sich RNNs nach wie vor in bestimmten Anwendungen, insbesondere, wenn es gilt, zeitliche Abhängigkeiten zu modellieren. Transformer kommen beispielsweise bei den aktuellen Large-Language-Modellen von OpenAI und zahlreichen anderen Produkten zum Einsatz.
In letzter Zeit haben die LSTM-Entwickler mehrfach Vorträge über eine neue LSTM-Variante namens xLSTM [3] gehalten. Diese neue Autoregressionsarchitektur zielt darauf ab, die Effizienz gegenüber den derzeit verwendeten Transformer-Architekturen zu verbessern. Im Gegensatz zu den rechenintensiven Transformern soll xLSTM schneller sein, weniger Speicher benötigen und eine bessere Laufzeitskalierung bieten. Es bleibt abzuwarten, ob diese in Europa entwickelte Technologie die dominierende Transformer-Technik ablösen wird. ((jcb)/(jlu))
Infos
- KI-Serie (8): Mark Vogelsberger, “Kunst des Faltens”, LM 04/2024, S. 72, https://www.lm-online.de/50596
- KI-Serie (7): Mark Vogelsberger, “Nachgemachte Neuronen”, LM 03/2024, S. 70, https://www.lm-online.de/50486
- “xLSTM – I am almost exploding”: https://www.youtube.com/watch?v=hwIt7ezy6t8





