
© Yevhen Polishko / 123RF.com
Kubernetes ist aus dem IT-Alltag nicht mehr wegzudenken, kann allerdings schnell sehr komplex werden. eBPF verspricht Abhilfe, ist aber selbst komplex. Cilium macht seine revolutionären Möglichkeiten einfach zugänglich.
Anfang der 2010er-Jahre hatte Linux seinen Siegeszug in den Rechenzentren angetreten, es war abzusehen, dass es sich zum Standardbetriebssystem für Server entwickeln würde. Gleichzeitig zeichnete sich ein weiterer Trend in den Rechenzentren ab: Virtualisierung. Um mit der Entwicklung von virtualisierten Infrastrukturen Schritt zu halten, musste zwangsläufig auch das Netzwerk virtuell werden.
Als erster Schritt in Richtung virtualisierter Netzwerke entstanden Software-Defined-Network-Lösungen (SDN). 2011 wurde die Open Networking Foundation gegründet, um SDNs weiterzuverbreiten und zu standardisieren. Open vSwitch fand 2012 Eingang in den Kernel, im selben Jahr, in dem VMware den SDN-Pionier Nicira gekauft hatte. Die Entwicklung verlief rasant – zu rasant für den Linux Kernel. Netzwerktechnik erfordert hohe Performance, was für Linux bedeutet, dass sie Teil des Kernels sein muss. Codeänderungen am Kernel dauern oft viele Monate, und selbst nach einem Release kommen sie erst geraume Zeit später paketiert in den Distributionen an. Das erwies sich als zu langsam für die Anforderungen der sich schnell entwickelnden Netzwerktechnologien. Gleichzeitig kamen die ersten Container-Lösungen auf, die noch dynamischere Anforderungen an das Netzwerk stellten. Es brauchte einen neuen Weg.
eBPF revolutioniert Linux
Diesen neuen Weg fand Alexei Starovoitov: Er baute das bestehende, damals recht simple Kernel-Subsystem BPF aus, das in den 1990ern als einfacher Paketfilter entwickelt worden war. Tcpdump basierte lange darauf. Starovoitov erweiterte BPF um einige grundlegende Fähigkeiten und hob damit eBPF [1] aus der Taufe.
eBPF fungiert als eine Art Kernel-VM, in die man zur Laufzeit generische Programme laden und sie dort ausführen kann. Mit eBPF war es plötzlich möglich, die Arbeitsweise des Kernels ohne Neustart zu verändern und zu erweitern, eine revolutionäre Neuerung. Da eBPF-Code mit dem Kernel interagieren kann und in derselben Schicht arbeitet, lassen sich weitreichende Funktionen umsetzen, zum Beispiel ein detailliertes Monitoring, erhöhte Sicherheit oder ein sehr leistungsfähiges Netzwerk.
Mittlerweile ist eBPF im Markt angekommen. Es wird in einer Vielzahl von Projekten und Programmen eingesetzt; es gibt viele Unternehmen, die ihre Produkte darauf aufbauen. Seit Jahren unterstützt eine Stiftung [2] die Weiterentwicklung der Technik. Unter den Mitgliedern eBPF Foundation finden sich bekannte Namen aus dem Cloud- und Linux-Umfeld, darunter Meta, Google, Red Hat, Intel, Netflix, Datadog und auch Isovalent, dessen Übernahme Cisco Ende 2023 angekündigt hat. Wollen Sie mehr über die Geschichte von eBPF erfahren, sollten Sie sich auf Youtube die 30-minütige Videodokumentation ansehen, die den Hintergrund und die Anfänge von eBPF beleuchtet [3].
Zu den Programmen, die auf eBPF setzten, gehört auch Cilium. Es ermöglicht ein weitreichendes Monitoring, umfangreiche Sicherheitsoperationen und ein leistungsstarkes Netzwerk in Kubernetes. Bevor wir aber tiefer in Cilium einsteigen, werfen wir noch einen Blick auf die Details von eBPF, um zu sehen, warum es als so revolutionär gilt.
Eine kurze eBPF-Kunde
Wie erwähnt, handelt es sich bei eBPF um eine Technologie, die dazu dient, in einer Sandbox auf Kernel-Ebene Programme ablaufen zu lassen. Entscheidend ist dabei, dass die Programme aufgrund von Ereignissen aufgerufen werden, den Events. Diese Aufrufe triggern sogenannte Hooks, also bestimmte Punkte im Kernel. Das können beispielsweise bestimmte Funktionsaufrufe sein, der Start oder das Ende einer Funktion, wichtige Netzwerkereignisse und so weiter. Daneben lassen sich auch eigene Hooks definieren. Gibt es kein Ereignis, das ein eBPF-Programm aufruft, wird auch kein eBPF-Code ausgeführt. Code startet also nur dann, wenn es wirklich notwendig ist.
Da eBPF-Programme mit vielen Kernel-Komponenten interagieren, braucht man Erfahrung in der Kernel-Entwicklung, um sie zu schreiben. Die Programme selbst liegen in Form von Bytecode vor. Programmiert werden sie oft in Pseudo-C-Code, den dann ein Compiler in Bytecode übersetzt. Beim Laden des Bytecodes in den Kernel vollzieht sich ein entscheidender Schritt in der eBPF-Kette: der Einsatz des Verifiers. Er überprüft das eBPF-Programm anhand verschiedener Kriterien, zum Beispiel ob das Programm auf jeden Fall endet, ob es auf Speicher außerhalb seiner Grenzen zugreifen will, ob die Komplexität finit ist (der Verifier prüft jeden Weg) und so weiter. Damit spielt der Verifier eine wichtige Rolle, denn ohne ihn wäre die Stabilität des Kernels mit jedem neuen eBPF-Programm gefährdet. Damit fungiert er als Garant für die Sicherheit von eBPF, schränkt gleichzeitig aber auch die Möglichkeiten von eBPF auf das zwingend Notwendige ein.
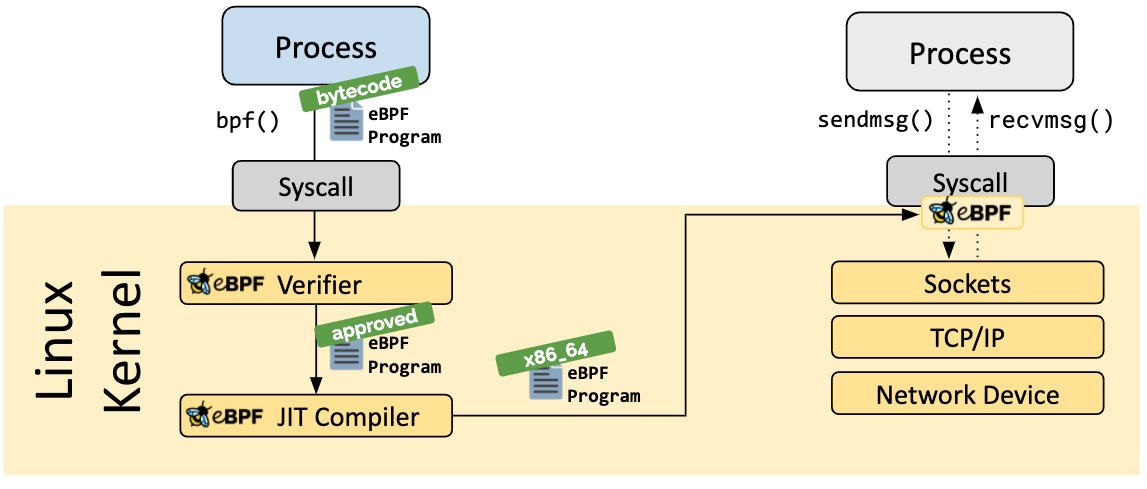
Abbildung 1: Dieses Diagramm zeigt, wie sich der Aufruf und die Verifizierung eines eBPF-Programms vollziehen. Quelle: https://ebpf.io, CC-BY-4.0
Ein weiteres wichtiges Feature von eBPF sind eBPF-Maps, Key-Value-Speicher im Kernel. Über sie können eBPF-Programme Daten untereinander austauschen, aber auch mit anderen Anwendungen, die zum Beispiel im Userspace laufen, also in der Nutzerschicht oberhalb des Kernels. Das ermöglicht einen umfassenden Daten- und Statusaustausch, selbst nachdem ein eBPF-Programm beendet ist. Außerdem lassen sich eBPF-Programme auf diesem Weg miteinander verketten, sodass sie sich gegenseitig aufrufen. Über die eBPF-Maps können Daten dabei zwischengespeichert und später weiterverarbeitet werden.
Wenn wir über eBPF und Netzwerke sprechen, muss früher oder später auch XDP zur Sprache kommen. Das Kürzel steht für Express Data Path, ein Framework für eBPF, das im Kernel eine zügige Verarbeitung von Netzwerkpaketen ermöglicht. Im Prinzip arbeitet XDP direkt mit dem Treiber der Netzwerkkarte zusammen und wird zum frühestmöglichen Zeitpunkt aufgerufen. Es kann das Paket direkt beim Eintreffen verarbeiten, noch bevor der Treiber irgendetwas anderes damit anstellt.
Das auf hohe Geschwindigkeit ausgelegte XDP lässt sich beispielsweise dazu nutzen, DDOS-Angriffen mit extrem hoher Effizienz zu begegnen, da ein XDP-Programm in der Lage ist, Pakete praktisch direkt auf der Netzwerkkarte zu verwerfen. Ebenso kann man damit Load Balancer schreiben, die Netzwerkpakete schon auf der Netzwerkkarte weiterschicken, auf der sie gerade erst angekommen sind. Ein gutes Beispiel dafür ist der von Facebook/Meta entwickelte Load Balancer Katran [4], der auf XDP aufbaut.
eBPF bietet also revolutionäre Möglichkeiten, direkt auf Kernel-Ebene flexibel Programme auszuführen. Allerdings ist es alles andere als trivial, solche Programme zu schreiben und sie dynamisch zu verwalten. Gerade der Einsatz von eBPF für die Netzwerkverwaltung unter Kubernetes erfordert jedoch eine Vielzahl an eBPF-Programmen.
Container-Netzwerke
Kubernetes dient dem Management von Anwendungen, die in Containern beziehungsweise Gruppen von Containern verpackt sind, sogenannten Pods. Damit diese Anwendungen ihren Zweck erfüllen können, benötigen sie üblicherweise Daten, die sie oft auch weitergeben. Diese Datenströme bedienen sich eines Netzwerks, um von A nach B fließen zu können. Kubernetes selbst implementiert jedoch keine Netzwerkfunktionen, sondern überlässt das Plugins, die die CNI-Spezifikation (Container Network Interface) erfüllen. Wenn die Container-Runtime einen Pod baut, beauftragt sie das CNI-Plugin, eine entsprechende Netzwerkumgebung zu erstellen, also eine virtuelle Netzwerkschnittstelle samt der nötigen Regeln, um den Datenverkehr passend zu routen.
Die meisten CNI-Plugins weisen jedoch dieselben Schwächen auf: IP-Adressen und Iptables. IP-Adressen werden zum Problem, weil sie in Container-Umgebungen nicht mehr so statisch sind wie früher. Vor dem weitreichenden Einsatz von Containern waren IP-Adressen eines der wesentlichen Merkmale, um die Identität einer Applikation zu bestimmen. Kam ein Datenstrom von der IP-Adresse 1.2.3.4, dann war klar, welcher Server oder welche VM dahinterstand, und damit auch welche Anwendung.
Container jedoch verwenden üblicherweise lokale, dynamisch vergebene IP-Adressen. Außerdem können mehrere Container zu einer Anwendung gehören, eine 1:1-Zuweisung lässt sich nicht mehr treffen. Oft laufen viele unterschiedliche Container auf einem Knoten. IP-Adressen kommen und gehen gerade auch im Fall von automatischen Down- oder Upscalings. Damit können CNIs noch umgehen, weil entsprechende Logik verbaut wurde. Traditionelle Monitoring- oder Sicherheitssysteme sind jedoch spätestens dann überfordert, wenn sie sich auf IP-Adressen in Kubernetes verlassen. Wie aber kann man sonst die Identität der Anwendungen sicher beschreiben?
In eine andere Kerbe schlägt das Problem Iptables. Besteht ein Kubernetes-Cluster aus mehreren Nodes, auf denen viele Anwendungen laufen, kommen eine ganze Menge IP-Adressen und Regeln zusammen. Iptables geht sie sequenziell durch: Es prüft jedes übertragene Paket gegen eine Liste von Regeln, eine nach der anderen. Die benötigte Zeit steigt dadurch linear mit der Zahl dieser Regeln. Außerdem muss Iptables die Liste aller Regeln jedes Mal neu laden, wenn eine neue Regel hinzukommt, was bei vielen Regeln lange dauert und den Ablauf verzögert. Dadurch steigen Leistungseinbußen und Latenzen mit der Zahl der Regeln erheblich (Abbildung 2). Noch schlimmer wird es beim Kube-Proxy, der die Zahl der Regeln schnell exponentiell wachsen lässt [5].
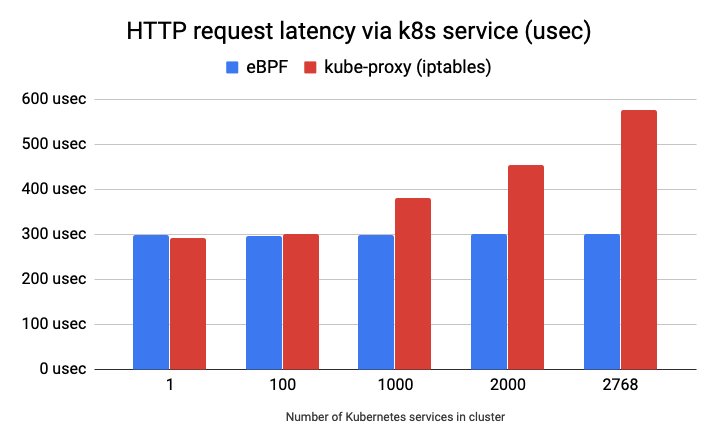
Abbildung 2: Ohne eBPF steigt die Latenz mit der Anzahl der Services im Cluster erheblich an, mit bleibt sie annähernd gleich. Quelle: The Cilium Authors, https://cilium.org
Daraus ergibt sich die Notwendigkeit eines effizienten Regelsystems für das K8s-Netzwerk. Hier springt eBPF in die Bresche, mit dessen Hilfe man Hash-Tables nutzen kann, um die Zieladressen zu ermitteln. Aus der Tatsache, dass dabei der Rechenaufwand selbst bei steigender Regelanzahl nahezu identisch bleibt, resultiert ein drastischer Effizienzgewinn.
Es gibt noch einen weiteren Vorteil von eBPF: Es vermag einen anderen, wesentlich sinnvolleren Identifier zu bieten. eBPF versteht die Namespaces, in denen Container erstellt werden, und kann auf dieser Ebene operieren. Daher lassen sich Kommunikationsbeziehungen und Regeln einrichten, die sich an Namespaces orientieren. Das ermöglicht eine wesentlich bessere Beschreibung von Containern und auch von zusammenfassenden Services.
In Kubernetes-Umgebungen spielt es für die Sicherheit einer Anwendung keine Rolle, wo sie ist, sondern wer sie ist. Um einer komplexen K8s-Umgebung gerecht zu werden, muss das CNI in Kubernetes also auf eBPF basieren. Das bringt uns zu Cilium.
Manager für eBPF Programme
Schon das Schreiben eigener eBPF-Programme ist nicht gerade einfach. Viele kleine eBPF-Programme in einem dynamischen Umfeld wie Kubernetes zu managen, macht noch wesentlich mehr Schwierigkeiten. Hier kommt Cilium [6] ins Spiel: Es erstellt, lädt und verwaltet die notwendigen eBPF-Programme dynamisch. Das bleibt für die Nutzer völlig transparent. Auf diesem Weg kann man die revolutionären Fähigkeiten von eBPF nutzen, ohne selbst ein Kernel-Entwickler zu sein.
Cilium schafft als CNI die notwendigen Netzwerkschnittstellen und leitet die Pakete effizient von A nach B. Das beschränkt sich nicht auf die Kommunikation innerhalb des Clusters: Cilium kann auch mehrere K8s-Cluster zusammenschließen und mithilfe von Cluster Mesh die Dienste übergreifend zur Verfügung stellen. Außerdem steht ein Kubernetes-Cluster selten allein im leeren Raum: Oft müssen die Anwendungen, die darauf laufen, mit weiterer IT außerhalb des Clusters kommunizieren. Cilium ermöglicht das Anbinden an klassische Netzwerke mithilfe von BGP, das es nativ spricht. Obendrein unterstützt es IPv4, IPv6 und den IPv4/IPv6-Mischbetrieb. Dazu gehört auch NAT zwischen IPv4 und IPv6, sodass man zum Beispiel einen IPv6-Kubernetes-Cluster in einer IPv4-Umgebung betreiben kann.
Darüber hinaus lassen sich durch Cilium Regeln definieren, um Kommunikationsbeziehungen zu erlauben oder zu verbieten, sogenannte Network Policies. Im Prinzip erlaubt Kubernetes ohne solche Regeln erst einmal alles. Das kann man sich wie eine Stadt vorstellen, in der alle – vom Auto über das Fahrrad bis zum Fußgänger – wild durcheinander wuseln. Die Network Policies bringen Ordnung in das Chaos, und K8s-Admins können mit ihrer Hilfe kontrollieren, welcher Pod mit welchem Dienst kommunizieren darf.
Cilium versteht sowohl die generellen Kubernetes-Network-Policies als auch die Cilium-Network-Policies. Die normalen Network Policies ermöglichen eine Kontrolle auf Layer 3 und 4 der OSI-Schicht, während die Network Policies von Cilium auch den Layer 7 mitabdecken, also zum Beispiel HTTP-Pfade. Das setzt eBPF übrigens nicht direkt um, sondern bedient sich dazu eines minimierten Envoy-Proxys. Außerdem kann man in Cilium nicht nur nach Pods oder Namespaces filtern, sondern auch auf Basis von DNS-Namen, Diensten, Endpoints und mehr.
Einen guten Einblick in die verschiedenen Möglichkeiten von Cilium- und Kubernetes-Network-Policies gibt der interaktive Policy Editor auf http://editor.networkpolicy.io (Abbildung 3). Er bietet die Möglichkeit, sich Regeln zusammenzuklicken, und stellt das Resultat sowohl als Kubernetes- als auch als Cilium-Network-Policy dar. Die Regeln kann man herunterladen und in existierenden Kubernetes-Instanzen verwenden.
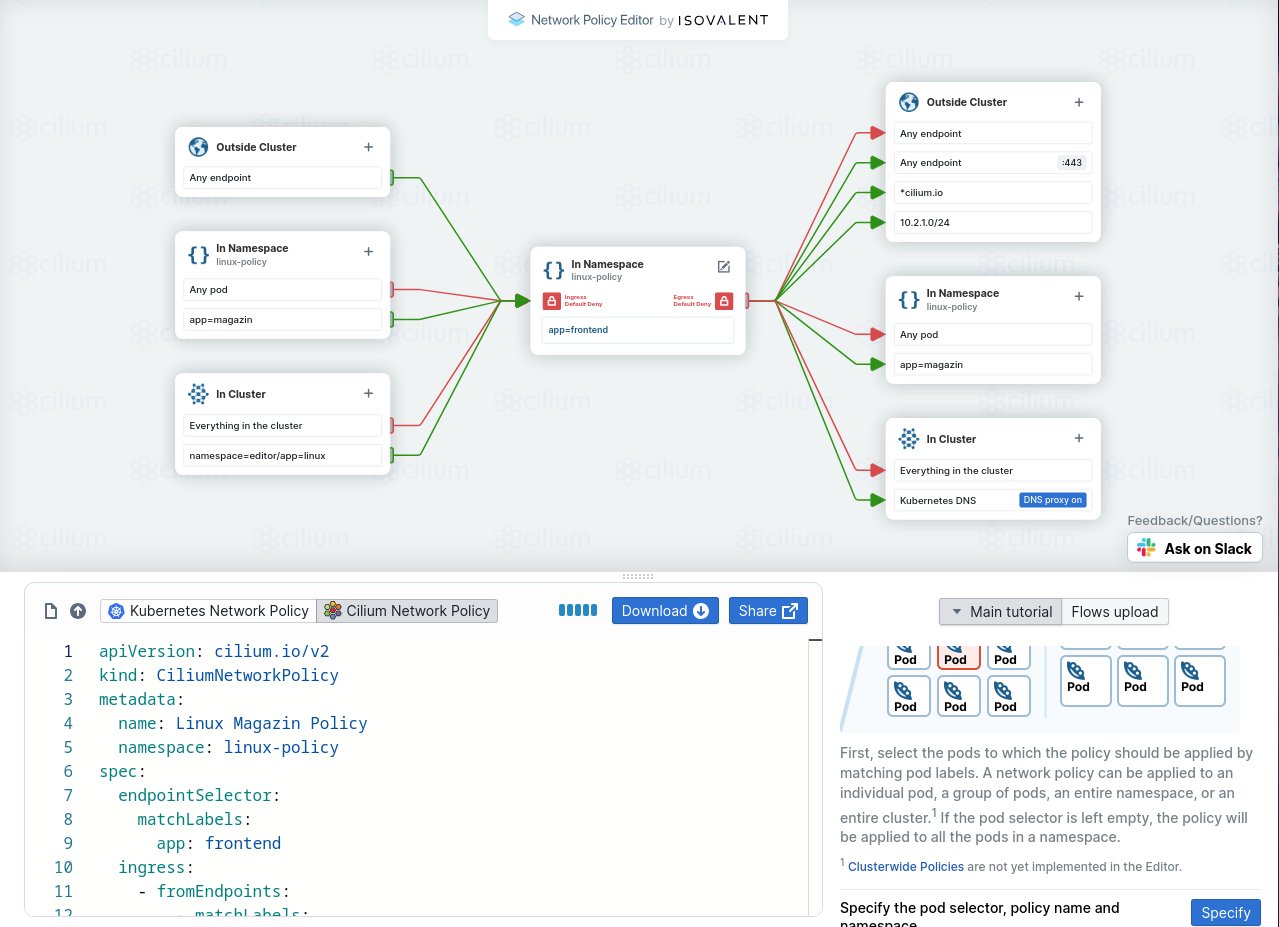
Abbildung 3: Der interaktive Policy-Editor, der im Internet zugänglich ist. Quelle: The Cilium Authors, https://cilium.org
Einen Sonderfall des Netzwerkverkehrs stellt es dar, wenn Daten von außen in den Cluster kommen oder ihn dorthin verlassen. Cilium unterstützt die Kubernetes Ingress Resource und damit TLS Termination, Load Balancing und HTTP auf Layer 7. Zusätzlich beherrscht Cilium die neuere Spezifikation Gateway API, die Ingress um den Layer 4 erweitert, neben HTTP weitere Protokolle bietet und erweiterte Funktionen wie A/B-Testing und Canary Rollouts mitbringt. Ausgehenden Datenverkehr verwaltet Cilium gleichfalls: Über die Funktion Egress Gateway lässt sich zum Beispiel sicherstellen, dass ein bestimmter Endpunkt außerhalb des Clusters immer mit derselben Source-IP angesprochen wird. Das vereinfacht die Integration in Umgebungen mit IP-basierten Firewalls erheblich.
Cilium als CNI hat sich mittlerweile fest im Markt etabliert. Es ist ein Graduated Project der Cloud Native Foundation (CNCF), das einzige CNI mit diesem Status. Auch die großen Cloud-Provider setzen auf Cilium, darunter Azure CNI Powered by Cilium, AWS EKS und EKS-A und die Google GKE Dataplane v2. Daneben verwenden immer mehr Firmen Cilium. Die entsprechende Adopters-Seite [7] verlinkt eine Vielzahl von Erfahrungsberichten; im Bereich Netzwerk finden sich auch Reports von Firmen aus dem deutschsprachigen Raum wie DB Schenker oder Hetzner.
Cilium Hubble
Cilium kann den Netzwerkverkehr auf Layer 7 filtern, da es den Datenstrom wie etwa HTTP-Verkehr nativ versteht. Das wiederum ermöglicht, die Erkenntnisse über den Netzwerkverkehr für das Monitoring zu nutzen.
Cilium kann beispielsweise nicht nur sicherstellen, dass Datenverkehr nur mit »*.cilium.io« stattfindet, es kann auch zählen, wie oft Verbindungen dorthin aufgebaut werden. Generell besitzt es die Fähigkeit, Kommunikationsbeziehungen darzustellen und bis auf die Ebene von DNS-Namen und HTTP-Pfaden aufzuschlüsseln. Dafür nutzt es die nach dem bekannten Weltraumteleskop benannte Komponente Hubble (Abbildung 4). Dabei handelt es sich in erster Instanz um eine Benutzerschnittstelle, die einen Einblick in die Beziehungen der Dienste und den Datenverkehr zwischen ihnen ermöglicht.
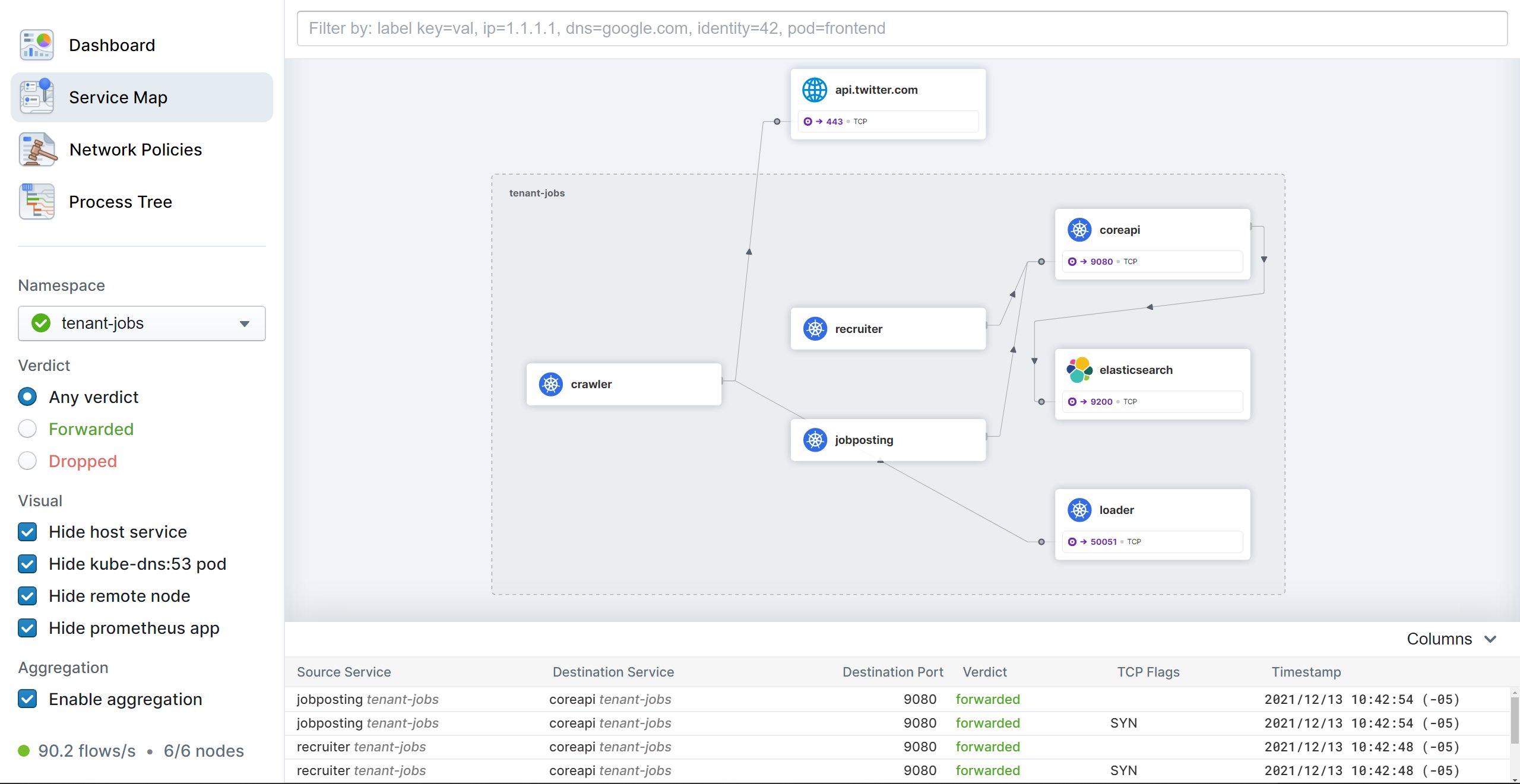
Abbildung 4: Cilium untersucht Datenströme im Netzwerk mittels der Komponente Hubble. Quelle: Isovalent, https://isovalent.com
Hubble stellt in einer Service Map die Beziehung der Dienste untereinander dar und zeigt auf Knopfdruck den relevanten Datenstrom dazu an. Hubble hilft dabei, Fragen zu beantworten wie:
- Welche Dienste kommunizieren miteinander und wie oft?
- Von welchem Service hängt ein anderer ab?
- Gibt es Probleme im Netzwerkverkehr? Wenn ja, wo sind Verbindungen blockiert, wo werden Pakete gedroppt? Auf welchem Layer ist die Verbindung gestört?
- Bei welchen Diensten wurden Verbindungen aufgrund von bestehenden Regeln geblockt?
- Wie hoch ist die Rate von 4xx- oder 5xx-Return-Codes?
Damit ist Hubble für das Troubleshooting von bestehenden Anwendungen im alltäglichen Betrieb von unschätzbarem Wert. ClickHouse hat dies in einem Erfahrungsbericht [8] folgendermaßen zusammengefasst: “I used Hubble to debug [the issues], to see network flows, how things are going, where it’s blocked, because we had problems with traffic forwarding and it wasn’t clear. What is that? Is it a network policy or something else? When we initially installed Cilium, we didn’t enable Hubble, but now we have it installed in every cluster because it is so useful for debugging.”
Aber auch das Monitoring profitiert erheblich von Hubble: Relevante Metriken lassen sich nach Grafana exportieren und dort anzeigen. Typisch sind Graphen zu Anzahl und Verhältnis von HTTP-Return-Codes, Drop Reasons, HTTP-Latenzen und DNS-Errors. Dabei muss man nicht zwingend das grafische Interface nutzen, Hubble bietet eine ebenso mächtige Kommandozeilenschnittstelle an.
Cilium Tetragon
Mit der zunehmenden Nutzung von Kubernetes für Business-kritische Anwendungen rücken die Aspekte Sicherheit und Compliance immer stärker in den Fokus. Kann Cilium auch bei ISO 27000 und beim Grundschutz helfen?
Cilium geht diese Themen von zwei Seiten an. Einerseits unterstützen die schon beschriebenen Möglichkeiten von Cilium direkt beim Absichern von Systemen: Detaillierte Network Policies helfen, Dienste abzusichern und eine Zero-Trust Policy zu etablieren. Hubble übernimmt die Verifizierung und prüft kontinuierlich, ob die Compliance im alltäglichen Betrieb eingehalten wird. Zudem kann Cilium den Netzwerkverkehr mit Wireguard oder IPsec verschlüsseln. So lässt sich die Vertraulichkeit der Daten sicherstellen, wenn die Netzwerke mit anderen zusammen genutzt werden oder etwa gar nicht unter der Kontrolle eines bestimmten Nutzers stehen. Beide Lösungen haben ihre Vor- und Nachteile: Wireguard bietet ein automatisches Key-Management, während IPsec in Tests bessere Latenzen und bessere CPU-Effizienz zeigt.
Andererseits greift Cilium das Thema Sicherheit mit der Komponente Tetragon auf [9]. Tetragon (Abbildung 5) setzt ebenfalls auf eBPF, zielt im Unterschied zu Cilium jedoch nicht auf den Datenverkehr zwischen den Knoten ab, sondern auf den Knoten selbst. Wo Cilium Einblick in die volle Breite des Clusters ermöglicht, geht Tetragon in die Tiefe und macht die Tiefen des Kernels des jeweiligen Knotens transparent. Es überwacht dort die System Calls, die Namespaces und so weiter. Damit kann Tetragon ein komplettes Bild davon zeichnen, was auf einem Knoten alles passiert.
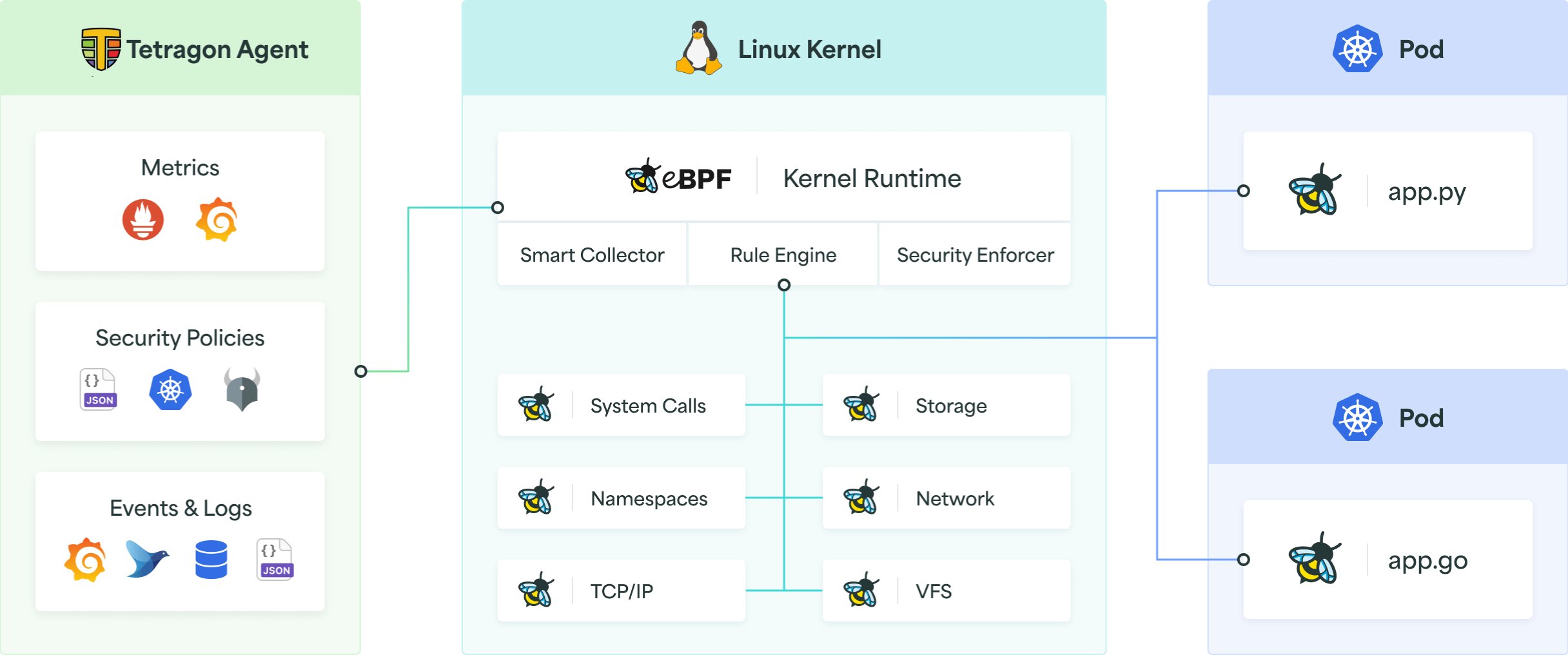
Abbildung 5: Tetragon liefert eine Übersicht, was auf einem Knoten im Detail passiert. Quelle: The Tetragon Authors, https://tetragon.io
Eine Einsatzmöglichkeit besteht zum Beispiel darin, Container daraufhin zu überwachen, ob nach längerer Laufzeit noch neue Prozesse starten. Da Container immutabel sind, weist das oft auf einen möglichen Einbruch hin. Github verwendet Tetragon, um Netzwerkverkehr einzelnen Prozessen auf dem Host zuzuweisen und dadurch ein tieferes Verständnis davon zu gewinnen, welche Anwendung in einem Cluster bestimmten Datenverkehr verursacht. Tetragon bietet dabei nicht nur Einblicke, sondern kann auch Events blockieren. So lassen sich beispielsweise verdächtige Zugriffe auf Systemdateien wie »/etc/shadow« unterbinden.
Service Mesh
Beim Thema Kubernetes und Netzwerk darf das Service Mesh nicht fehlen. Hier bieten Linkerd, Istio und Kong etablierte Lösungen – wie steht Cilium dazu? Immerhin stellt es Funktionen wie das Filtern auf Protokollebene zur Verfügung, die man normalerweise eher einem Service Mesh zurechnet. Und genau das ist der Ansatz von Cilium.
Cilium bietet diverse Funktionen eines Service Mesh an. Die sind entweder direkt in eBPF implementiert (wie TCP-Filterung) oder in einem minimierten Envoy-Proxy (wie das protokollnative Filtern), von dem aber einer je Node genügt statt einer je Container. Üblicherweise starten die bekannten Service-Mesh-Lösungen zu jedem Container einen weiteren Service-Mesh-Container, was Overhead und Komplexität schnell in die Höhe treibt. Bei Cilium ist das nicht notwendig.
Dieser Ansatz hat neben der geringeren Komplexität weitere Vorteile. Dazu gehören ein geringerer Overhead durch fehlende Sidecars sowie eine flache Lernkurve, da keine Service-Mesh-spezifischen Objekte gelernt werden müssen – das Cilium-Service-Mesh nutzt bereits vorhandene Methoden. Der vermutlich entscheidende Vorteil aber besteht darin, dass man die benötigten Service-Mesh-Funktionen nach und nach anschalten kann, wie es gerade passt. Statt mit viel Aufwand und einem großen Paukenschlag ein komplettes Service Mesh zu evaluieren, zu testen, das Team darauf anzulernen und es in Test und Produktion einzuführen, lassen sich mit Cilium Mesh die benötigten Features im laufenden Betrieb anschalten, wenn sie gerade benötigt werden. Dieser Ansatz vereinfacht das Einbringen von Service-Mesh-Funktionen erheblich. Oft benötigen Teams nicht alle Funktionen eines Service Mesh, sondern nur einen kleinen, aber entscheidenden Teil. Für solche Fälle bietet ein natives Service Mesh, wie es Cilium implementiert, einen unschätzbaren Vorteil.
Es scheint, dass andere Projekte dem von Cilium eingeschlagenen Weg folgen: Sie übertragen mehr und mehr Funktionen in die darunterliegende Netzwerk-Schicht oder setzen gleich auf Cilium auf. Möglicherweise wird nicht das Service Mesh das Kubernetes-Netzwerk der Zukunft, sondern geht mit der Zeit schlicht in der darunterliegenden Netzwerkschicht und den Proxies auf. Zu wünschen wäre es jedenfalls.
Fazit
Kubernetes ist gekommen, um zu bleiben, und verwaltet unsere Container. Das bringt aber eigene Herausforderungen mit sich, gerade im Bereich der Netzwerke, der Überwachung und der Sicherheit. Hier schafft das revolutionäre eBPF Abhilfe. Auf ihm baut Cilium auf, das die Möglichkeiten von eBPF handhabbar macht. Es ermöglicht ein umfassendes Management der Netzwerke innerhalb von Kubernetes sowie an den Schnittstellen zur umgebenden IT. Die Komponenten Tetragon und Hubble erweitern es um vielfältige Funktionen im Bereich Monitoring und Sicherheit.
Wenn wir mit diesem Artikel Interesse an dem Thema wecken konnten, empfehlen wir Ihnen einen Besuch der Cilium Labs [10]. Dort finden sich zahlreiche, direkt aus dem Browser zu startende interaktive Programme, um Cilium und alle zugehörigen Komponenten auszuprobieren und besser kennenzulernen. (jcb)
Infos
- eBPF: https://ebpf.io
- eBPF Foundation: https://ebpf.foundation
- eBPF-Documentary: https://www.youtube.com/watch?v=Wb_vD3XZYOA
- Katran: https://github.com/facebookincubator/katran
- Kube-Proxy: https://isovalent.com/blog/post/why-replace-iptables-with-ebpf
- Cilium: https://cilium.io
- Adopters: https://cilium.io/adopters
- Erfahrungsbericht von ClickHouse: https://www.cncf.io/case-studies/clickhouse
- Tetragon: https://tetragon.io
- Cilium Labs: https://cilium.io/labs






