
© blinkblink1 / 123RF.com
Convolutional Neural Networks kommen hauptsächlich bei der Objekterkennung zum Einsatz. Dort dienen diese faltenden neuronalen Netze unter anderem zur Bildklassifikation, Detektion und Segmentierung.
Convolutional Neural Networks (CNNs), also faltende neuronale Netze, werden in verschiedenen praktischen Szenarien eingesetzt, zum Beispiel in autonomen Fahrzeugen oder Sicherheitskamerasystemen. Man bevorzugt sie in bestimmten Anwendungen gegenüber normalen Multi-Layer-Perzeptron-Netzen, insbesondere bei Aufgaben, die mit dem Verarbeiten von Bildern oder anderen strukturierten Daten zu tun haben.
Ein wesentlicher Grund dafür liegt in ihrer Fähigkeit zur lokalen Mustererkennung durch mathematische Faltungsoperationen. Sie ermöglichen es dem Netz, räumliche Hierarchien von Merkmalen in den Daten zu erfassen, worauf es besonders bei der Bildverarbeitung ankommt. Ein weiterer Grund besteht darin, dass beispielsweise bei der Bildverarbeitung die direkte Eingabe aller Pixelinformationen in ein normales neuronales Netz zu einer sehr großen Anzahl trainierbarer Parameter im Netz führen würde. Das würde das Training drastisch ausbremsen. CNNs schaffen hier Abhilfe, indem sie sich nicht auf einzelne Pixel fokussieren, sondern auf Muster und Merkmale in den zu analysierenden Bildern.
Ein weiterer Vorteil von CNNs ist die Parameterfreigabe, bei der Gewichtsparameter für die Faltung über das gesamte Bild geteilt werden. Dadurch benötigen CNNs im Vergleich zu vollständig vernetzten neuronalen Netzen weniger Parameter, was die Trainingszeit verkürzt und Überanpassung minimiert. Die sogenannte translationale Invarianz macht CNNs robust gegenüber Verschiebungen in den Daten. Das bedeutet, dass ein bestimmtes Merkmal erkannt wird, unabhängig von seiner genauen Position im Bild (Abbildung 1).
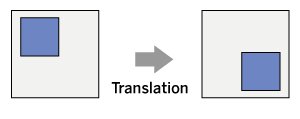
Abbildung 1: CNNs erkennen Merkmale unabhängig von ihrer Position und Lage im Bild.
Grundsätzlich eignen sich CNNs gut für das Verarbeiten mehrdimensionaler Daten. Das umfasst nicht nur Bilder, sondern auch andere mehrdimensionale Daten oder Probleme mit einer großen Menge Eingabedaten. So kommen CNNs beispielsweise auch bei Problemen der Spracherkennung zum Einsatz. Bei Bildern können CNNs mühelos mit mehreren Kanälen umgehen, beispielsweise den RGB-Farben, und durch tiefe Strukturen und komplexe Hierarchien von Merkmalen lernen. Viele der Eigenschaften und Vorteile von CNNs sind vom visuellen Kortex in biologischen Gehirnen inspiriert.
Grundsätzlicher Aufbau eines CNNs
Ein CNN besteht aus mehreren zentralen Komponenten, die zusammenarbeiten, um effektiv Merkmale aus Bilddaten zu extrahieren und komplexe Muster zu erlernen. Den schematischen Aufbau eines CNN sehen Sie in Abbildung 2. Die Eingabe ist hier ein Bild, das aus Pixeln besteht, von denen gewöhnlich jedes drei Werte umfasst (RGB). Zur Vereinfachung betrachten wir in den folgenden Beispielen lediglich Schwarz-Weiß-Bilder, deren Pixel lediglich die Werte 0 oder 1 annehmen können. Diese Pixelmatrix durchläuft in einem CNN dann verschiedene Schritte.
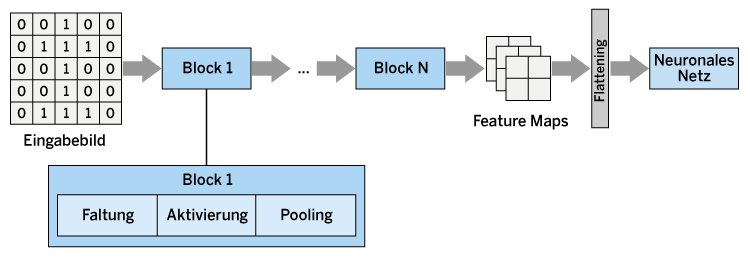
Abbildung 2: So sieht der schematische Aufbau eines CNNs aus.
In einem ersten Schritt wird das Bild in Form von Blöcken verarbeitet. Jeder dieser Blöcke besteht aus drei Schritten: Faltung, Aktivierung und Pooling. Daraus resultieren eine Reihe von Merkmalskarten oder Feature Maps. Sie umfassen eine deutlich niedrigere Anzahl an Pixeln und enthalten Informationen über bestimmte Strukturen beziehungsweise Merkmale des Eingabebilds.
Die zentrale Idee von CNNs besteht darin, dass die Bildanalyse auf diesen Feature Maps basiert und nicht auf der vollen Pixelinformation des Bilds. Das ähnelt dem menschlichen Sehen: Betrachten wir ein Objekt oder Bild, ist nicht die genaue Position und Farbe eines jeden Bildpunkts relevant. Stattdessen versucht unser Gehirn bestimmte Muster zu extrahieren und basierend darauf dann zu unterscheiden, ob es sich beispielsweise um einen Hund oder eine Katze handelt. Genauso gehen CNNs vor. Die Aufgabe der Blöcke besteht darin, solche Merkmale aus dem Bild zu extrahieren und in den Feature Maps abzulegen. Für die weitere Bildanalyse werden dann nur noch diese Feature Maps herangezogen.
Hierzu werden die Feature Maps in einem nächsten Schritt nach Durchlaufen der Blöcke zu einem langen Vektor umgeformt, der dann als Eingabe für ein neuronales Netz zur Klassifikation dient. Das gibt wiederum einen Wahrscheinlichkeitsvektor zurück. Jeder Eintrag dieses Vektors gibt die Wahrscheinlichkeit an, welches Objekt auf dem Bild dargestellt ist. Das neuronale Netz am Ende bewerkstelligt also eine Klassifikationsaufgabe des überwachten Lernens anhand der gewonnenen Feature Maps. Entscheidend in diesem Prozess sind die zuvor durchlaufenen, von den Feature Maps erzeugten Blöcke. Die drei Schritte in jedem Block haben dabei spezifische Aufgaben.
Die Faltungsschichten bilden das Herzstück eines CNNs. Hier werden durch Faltungsoperationen des Bilds mit verschiedenen Filtern lokale Muster herausgearbeitet, wodurch anfängliche Feature Maps entstehen. Diese Schichten ermöglichen dem Netzwerk die Erfassung räumlicher Hierarchien von Merkmalen. Nach jeder Faltung wird dann zunächst eine nichtlineare Aktivierungsfunktion auf die Daten angewendet. Der letzte Schritt führt eine Pooling-Operation auf den aktivierten Feature Maps aus, um die Dimensionalität der Feature Maps zu reduzieren und die Beständigkeit gegenüber kleinen Verschiebungen zu fördern.
Mehrere dieser Blöcke verarbeiten das anfängliche Bild, bis schließlich die endgültigen Feature Maps an das neuronale Netz zur Klassifikation übergeben werden. Die zentralen Komponenten bei CNNs sind hier die Faltungsschichten, die dem CNN auch seinen Namen geben.
Faltung
Ein CNN soll sich bei der Erkennung von Bildern nicht auf jedes einzelne Pixel fokussieren, sondern stattdessen bestimmte Merkmale (Features) im Bild erkennen und herausfiltern. Dazu wendet das CNN eine mathematische Operation (die Faltung) mit verschiedenen Filtern (Kerneln) an:
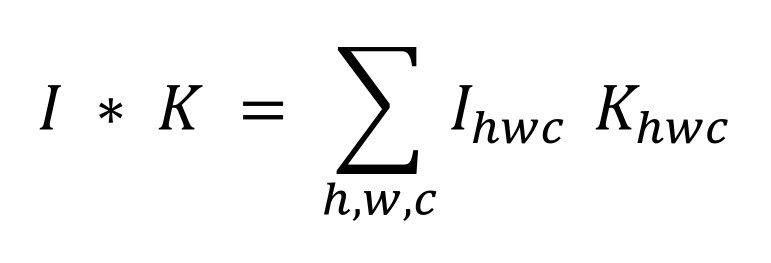
Ein Filter K ist ebenfalls eine Matrix, die im Rahmen der Faltung mit einem Teil des Bilds I multipliziert wird (h: Höhe, w: Breite, c: Farben): Filter können verschiedene Größen haben, müssen aber stets deutlich kleiner sein als das Bild selbst, da es sonst zu einer Unteranpassung kommt. Fällt der Filter (Kernel) hingegen zu klein aus, hat das System zu viele Parameter. Es kommt dadurch leicht zu einer Überanpassung, und das Training wird verlangsamt. Jeder Kernel filtert durch die Faltung ein bestimmtes Merkmal aus dem Bild heraus, was jeweils zu einer eigenen Feature Map führt.
In Abbildung 3 ist die mathematische Operation der Faltung anhand des beispielhaften Schwarz-Weiß-Bilds für einen bestimmten Kernel dargestellt. In einem ersten Schritt wird der Kernel in der oberen linken Ecke des Bilds platziert. Dann wird die Faltung in diesem Bildteil mithilfe des Kernels berechnet, indem man die Werte der Bildpunkte mit den Werten der Kernel-Matrix multipliziert und addiert. Der resultierende Wert fungiert dann als erster berechneter Wert der entstehenden Feature Map.
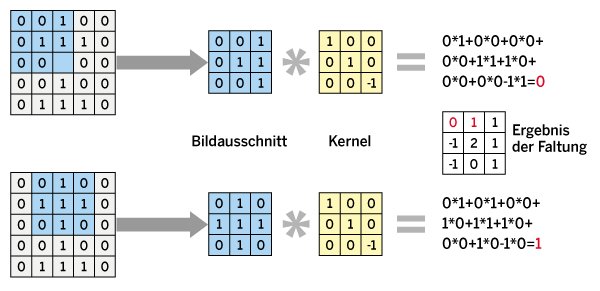
Abbildung 3: Veranschaulichung der Faltungsoperation in einem Schwarzweißbild.
Anschließend wird der Kernel ein Pixel nach rechts geschoben und abermals eine Faltung ausgeführt. So entsteht der Wert des zweiten Pixels der Feature Map. Danach wandert der Kernel immer weiter über das Bild, bis schließlich alle Faltungen berechnet sind. Das Ergebnis der Faltung ist dann eine Feature Map mit 3 x 3 Pixeln. Die genaue Größe dieser Feature Map hängt von der Größe des Kernels und zwei weiteren Parametern der Faltung ab: der Polsterung (Padding) und der Schrittweite (Stride).
Die Polsterung bezieht sich auf das Hinzufügen von zusätzlichen Pixeln oder Werten rund um das Eingabebild, bevor die Faltung berechnet wird. Das dient dazu, die Dimensionen der Feature Map nach der Faltung zu kontrollieren und sicherzustellen, dass die Faltung wichtige Informationen am Rand des Eingabebilds nicht vernachlässigt. Die Schrittweite bezeichnet die Distanz, um die sich der Kernel pro Schritt über das Eingabebild hinweg bewegt. Sie beeinflusst die räumliche Auflösung der Feature Map: Eine größere Schrittweite reduziert die Dimensionen der Ausgabe, eine kleinere führt zu einer feineren räumlichen Auflösung. Die Schrittweite beeinflusst somit direkt die Größe der Feature Map und kann die Effizienz des CNNs beeinflussen.
Die Faltung braucht nicht mit nur einem Filter ausgeführt zu werden. In der Praxis kommen verschiedene Kernel zum Einsatz, die jeweils verschiedene Merkmale aus dem Bild extrahieren. Durch das Hintereinanderschalten verschiedener Blöcke lassen sich so auch immer komplexere Merkmale aus dem ursprünglichen Bild herausfiltern. Bevor das Ergebnis der Faltungen an den nächsten Block weitergegeben wird, wendet das CNN aber noch eine Aktivierung und ein Pooling auf die Feature Map an.
Aktivierung und Pooling
Nach jedem Faltungsschritt folgt ein Aktivierungsschritt. Dazu wird auf jede einzelne Feature Map eine nicht lineare Aktivierungsfunktion angewandt. Meist handelt es sich hierbei um eine einfache ReLu-Funktion, max(0,x). Diesen Schritt demonstriert Abbildung 4 für das konkrete Beispiel. Die negativen Einträge in der Feature Map werden durch Anwendungen der ReLu-Funktion durch Nullen ersetzt. Die Aktivierung führt Nonlinearitäten in das Modell ein und ermöglicht es dem CNN, komplexere Zusammenhänge in den Daten zu erfassen.
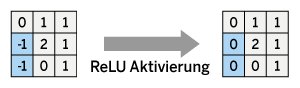
Abbildung 4: Die Aktivierung mithilfe einer ReLu-Funktion.
In einem letzten Schritt wird dann ein Pooling auf die zuvor aktivierte Feature Map angewendet. Dieser wesentliche Schritt dient dazu, die Dimensionalität der Feature Maps weiter zu reduzieren und gleichzeitig die wichtigsten Merkmale des Bilds zu bewahren. Die Dimensionsreduktion vermindert die Anzahl der Parameter im CNN und erhöht die Trainingseffizienz. Gleichzeitig werden entscheidende Informationen beibehalten, um relevante Merkmale zu extrahieren.
Ein weiterer Vorteil des Poolings besteht darin, dass es zur Erzeugung von Translationsinvarianz beiträgt. Das bedeutet, dass die erkannten Merkmale nicht stark von kleinen Verschiebungen in den Eingabedaten beeinflusst werden. Pooling trägt auch zur Verhinderung von Überanpassung bei, indem es räumliche Abstraktion fördert und das Modell weniger anfällig für spezifische Details in den Trainingsdaten macht. Das verbessert die Generalisierungsfähigkeit des Netzwerks auf nicht gesehene Daten.
Wie bei der Faltung schieben CNNs auch beim Pooling eine Fensterfunktion über die Daten. Innerhalb des Fensters werden dann die dortigen Pixelwerte zusammengefasst. Dabei kommen verschiedene Pooling-Methoden zum Einsatz. Am verbreitetsten ist das sogenannte Max-Pooling (Abbildung 5, links). Dabei zieht man das Maximum der Pixelwerte heran, um eine neue, niedrigdimensionale Feature Map zu generieren. Das Mean-Pooling (Abbildung 5, rechts) schreibt stattdessen den Mittelwert der Pixelwerte in die neue Feature Map. Ebenso sind auch weitere Pooling-Verfahren wie die Bildung des Medians möglich. In allen Fällen entsteht so ein deutlich kleineres Bild, das die wichtigsten Merkmale der Feature Map enthält.
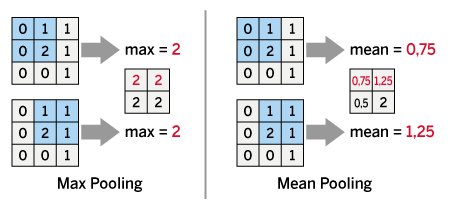
Abbildung 5: Das Pooling mit verschiedenen Methoden (Max-Pooling links, Mean-Pooling rechts).
Flattening
Faltung, Aktivierung und Pooling werden für verschiedene Kernel in den Blöcken hintereinander durchlaufen. Dadurch entsteht am Ende ein Satz von Feature Maps, den dann das darauffolgende neuronale Netzwerk zur Klassifikation erhält. Zuvor steht allerdings noch ein Flattening der Feature Maps an.
Flattening bezieht sich in CNNs auf den Prozess, der die mehrdimensionalen Feature Maps in eine eindimensionale Vektorform umwandelt. Dies geschieht, um die Ausgabe der letzten Faltung-Aktivierung-Pooling-Schicht in ein Format zu bringen, das das folgende neuronale Netz verarbeiten kann. Typischerweise wandelt diese letzte Schicht die Feature Maps in einen Vektor um, indem sie alle ihre Werte nacheinander anordnet.
Dieser Schritt gibt also die räumliche Struktur der Feature Maps auf und ordnet sie stattdessen flach hintereinander an – daher auch der Name des Prozesses. In Python-basierten Deep-Learning-Frameworks wie Tensorflow oder PyTorch verwendet man in der Regel die Funktionen »flatten()« oder »reshape()«, um diesen Schritt zu implementieren.
Architektur, Training, Regularisierung
Zur Spezifikation einer CNN-Architektur dienen unter anderem die Anzahl der Faltungs- beziehungsweise Pooling-Schichten oder die Zahl der Schichten des neuronalen Netzes. Auch Parameter wie Padding und Stride gilt es festzulegen. Daneben ist zu bestimmen, wie die Initialisierung der Kernel der verschiedenen Schichten und der Gewichte des neuronalen Netzes erfolgt. Insgesamt entsteht so eine recht große Zahl möglicher Architekturen, wobei es vom konkreten Problem abhängt, wann genau welche Architektur zum Einsatz kommt.
Des Weiteren muss man noch eine Verlustfunktion sowie Optimierer für das Training auswählen. Die Verlustfunktion soll die Diskrepanz zwischen den Vorhersagen des Modells und den tatsächlichen Labels quantifizieren. Ein Optimierer wird gewählt, um die Gewichte des Modells iterativ zu aktualisieren und den Verlust zu minimieren. Anschließend kann das Training anhand der Trainingsdaten beginnen. Das Modell wird mit ihnen trainiert, indem es vorwärts durch das Netzwerk propagiert, den Verlust berechnet und dann rückwärts (Backpropagation) die Gradienten durch das Netzwerk zurückführt. Die Optimierungsmethode dient dazu, die Gewichte zu aktualisieren. Dieser Prozess wird für mehrere Epochen wiederholt. Wichtig ist, während des Trainings nicht nur die Gewichte des neuronalen Netzes zu trainieren, sondern auch die Filter der Faltungsschichten. Das CNN lernt damit die optimalen Filter zur Extraktion der wichtigsten Bildmerkmale.
CNNs sind anfällig für Überanpassung, weil sie dazu neigen, sich zu stark auf die spezifischen Merkmale und Muster des Trainingsdatensatzes einzustellen. Diese Überanpassung kann dazu führen, dass das Modell Schwierigkeiten hat, sich auf neue, nicht gesehene Daten einzustellen. Um dieser Herausforderung entgegenzuwirken, kommen Techniken wie Dropout und Data Augmentation zum Einsatz.
Beim Dropout handelt es sich um eine Regularisierungstechnik, bei der man während des Trainings zufällig eine festgelegte Anzahl von Neuronen des Netzes deaktiviert. Das verhindert, dass das Netzwerk zu stark von bestimmten Neuronen abhängig wird, und verringert somit die Gefahr der Überanpassung. Dropout fördert die Robustheit des Modells, indem es erzwingt, dass verschiedene Neuronen im Netzwerk gemeinsam lernen und nicht übermäßig spezialisierte Gewichtungen entwickeln.
Data Augmentation hingegen umfasst eine künstliche Erweiterung des Trainingsdatensatzes durch Anwendung verschiedener Transformationen auf die vorhandenen Daten. Durch Rotationen, Verschiebungen, Spiegelungen und andere Transformationen der Trainingsbilder erzeugt man vielfältigere Variationen der Trainingsdaten. Das hilft dem CNN, eine breitere Palette von Merkmalen zu lernen, und reduziert die Tendenz, sich zu stark auf spezifische Merkmale zu fokussieren. Die resultierende Vielfalt an trainierten Mustern trägt dazu bei, dass das Modell besser bei unterschiedlichen Eingabedaten generalisieren kann.
Insgesamt unterstützen Dropout und Data Augmentation die Entwicklung von robusten CNN-Modellen, indem sie Überanpassung reduzieren und die Fähigkeit des Modells verbessern, sich neuen Daten anzupassen. Diese Techniken tragen dazu bei, die allgemeine Leistungsfähigkeit von CNNs in verschiedenen Anwendungsdomänen zu steigern.
Fazit
Convolutional Neural Networks haben in den letzten Jahrzehnten einen entscheidenden Beitrag zur Fortentwicklung der maschinellen Bildverarbeitung geleistet und sind heute in verschiedenen Anwendungsgebieten unverzichtbar. Insbesondere ihre Fähigkeit zur Bilderkennung hat zahlreiche innovative Lösungen ermöglicht.
Durch die Identifikation komplexer Muster und Merkmale vermögen CNNs in Bereichen wie der Gesichts- und Objekterkennung sowie der Szenenklassifizierung beeindruckende Leistungen zu erbringen. Das wiederum hat zu Fortschritten in der Sicherheitsbranche, der Automobilindustrie oder im Gesundheitswesen geführt. Ein weiteres bedeutendes Anwendungsgebiet stellt die Entwicklung autonomer Fahrzeuge dar. Hier spielen CNNs eine zentrale Rolle bei der Echtzeitverarbeitung von Straßenbildern, der Identifikation von Fahrspuren und der Erkennung von Hindernissen.
Die medizinische Bildgebung profitiert ebenfalls erheblich von CNNs, vornehmlich bei der Analyse von Röntgenbildern, MRT-Scans und CT-Aufnahmen. Die Technologie ermöglicht eine frühzeitige Erkennung von Krankheiten und verbessert die diagnostische Genauigkeit. Daneben haben sich CNNs auch im Bereich der Sprachverarbeitung etabliert, wo sie zur automatischen Übersetzung, Sentimentanalyse und Textklassifikation dienen. Insgesamt zeigen moderne CNNs eine beeindruckende Fähigkeit zur Extraktion und Verarbeitung von Merkmalen in komplexen Daten. (jcb)





