
© Anawat Sudchanham / 123RF.com
Beim verstärkenden Lernen optimiert ein Agent innerhalb einer Umgebung eine Strategie zum Lösen eines konkreten Problems selbstständig auf Basis von Belohnungen oder Strafe durch Versuch und Irrtum.
Verfahren des überwachten Lernens trainieren anhand von Daten leistungsfähige Modelle zur Lösung komplexer Aufgaben. Allerdings gibt es Probleme, bei denen das Lernen ausschließlich anhand von Daten keine guten Ergebnisse erzielt. Das kann verschiedene Gründe haben – beispielsweise, dass der Datenraum zu mächtig ist oder es sich um ein nicht deterministisches Problem handelt.
Der erste Fall tritt etwa ein, wenn ein Algorithmus lernen soll, wie er einen Rubik-Zauberwürfel von einer gegebenen Startposition aus in möglichst wenig Schritten löst. Hier gibt es zu viele Spielvarianten, sodass sich das Problem nicht durch überwachtes Lernen lösen lässt. Das zweite Problem ergibt sich beispielsweise beim Schachspielen. Hier kann das lernende System den Zug des Gegners nicht vorhersehen und ist damit nicht deterministisch. In solchen Fällen setzt man stattdessen verstärkendes Lernen ein.
Komponenten
Verstärkendes Lernen ist eine Art des maschinellen Lernens, bei dem ein Agent durch Interaktion mit einer Umgebung lernt, welche Aktionen er unter verschiedenen Bedingungen ausführen sollte, um ein bestimmtes Ziel zu erreichen. Im Gegensatz zu überwachtem Lernen, bei dem man den Agenten mit Daten trainiert, erhält er hier eine Rückmeldung auf seine Aktionen in Form einer Belohnung oder Bestrafung. Auf dieser Grundlage soll er dann eine optimale Strategie finden.
Abbildung 1 zeigt die wesentlichen Komponenten des verstärkenden Lernens mit den zentralen Akteuren Agent und Umgebung. Der Agent interagiert durch Aktionen mit der Umgebung, um ein bestimmtes Ziel zu erreichen. Dabei kann es sich um physische, virtuelle oder rein mathematische Umgebungen handeln. Beispiele wären unter anderem ein Roboter, der versucht, einen bestimmten Bewegungsablauf zu erlernen, oder ein Spiel, das der Agent gewinnen soll.
Im konkreten Fall aus Abbildung 1 soll der Agent lernen, Schach zu spielen. Die Umgebung stellt ihm Zustandsinformation zur Verfügung und bietet ihm die Möglichkeit, Aktionen auszuführen und Belohnungen zu erhalten. Zu einem bestimmten Zeitpunkt t registriert der Agent einen bestimmten Zustand, beispielsweise die Verteilung der Figuren auf dem Schachbrett. Auf dieser Grundlage entscheidet er sich der Agent für die nächste Aktion. Als Aktion bezeichnet man eine Handlung des Agenten, die er innerhalb der Umgebung ausführt und die zu einem neuen Zustand führt. Für gelungene Aktionen kann der Agent von der Umgebung Belohnungen erhalten.
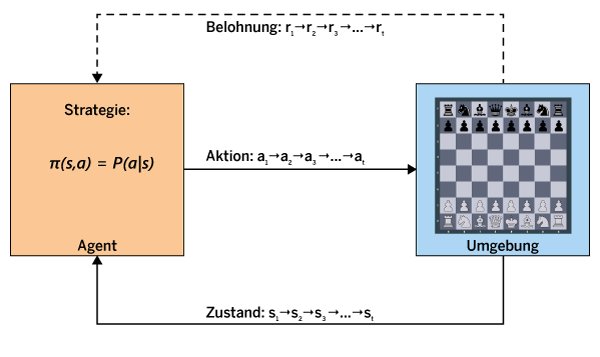
Abbildung 1: Ein Agent wirkt mit seinen Aktionen auf eine Umgebung ein, deren Zustände sich dadurch ändern. Gleichzeitig erhält er eine Rückmeldung in Form einer Belohnung, wenn die Zustandsänderung das Erreichen eines bestimmten Ziels befördert hat.
Die Belohnung erfolgt in Form einer numerischen Rückmeldung. Dabei ist wichtig, dass der Agent nicht für jede Aktion automatisch eine Belohnung erhält. Im Falle des Schachspiels könnte das System so aufgebaut sein, dass er im Extremfall nur eine Belohnung pro Spiel erhält – dann, wenn er gewonnen hat. Erhielte der Agent nach jeder Aktion eine Belohnung, würde es sich prinzipiell um ein Problem des überwachten Lernens handeln. Das ist aber beim verstärkenden Lernen gerade nicht der Fall.
Eine Schwierigkeit bei Problemen des verstärkenden Lernens besteht darin, dass man nicht jeder Aktion direkt eine konkrete Belohnung zuordnen kann. Im Fall des Schachspiels ließe sich die Häufigkeit der Belohnungen allerdings erhöhen, indem zum Beispiel ein versierter menschlicher Schachspieler die Aktionen (Züge) des Agenten beurteilt und ihm mitteilt, ob der Zug gut oder schlecht war. Mit einer erhöhten Frequenz brauchbarer Belohnungen gibt es schnellere Lernfortschritte.
Ziel des Agenten ist es, die kumulative Belohnung im Lauf des Lernprozesses zu maximieren. Das führt zum Erlernen einer optimalen Strategie, also einer Folge von Aktionen abhängig vom aktuellen Zustand, die schließlich auf möglichst kurzem Weg zu einem Zielzustand führt. Die zentrale Idee beim verstärkenden Lernen besteht darin, dem Agenten nicht explizit zu zeigen, welche Aktion in welcher Situation die beste ist. Stattdessen erhält er infolge der Interaktion mit seiner Umwelt lediglich gelegentlich eine Belohnung, die auch negativ sein kann.
Strategie
Alle Aktionen des Systems erzeugen beim verstärkenden Lernen ein Tripel, das aus Zustand, Aktion und Belohnung besteht. Allerdings kann der Wert der Belohnung oft auch null sein. Das entspricht inhaltlich keiner Belohnung, auch wenn dafür formell ein Wert übergeben wird. Mathematisch versucht der Agent, auf der Grundlage dieser Tripel-Sequenz die optimale Strategie abzuleiten.
Ziel der Strategie ist es, ausgehend von einem bestimmten Zustand die nächste Aktion optimal auszuwählen, also so, dass die kumulative Belohnung innerhalb der Aktionssequenz maximiert wird. Wichtig dabei: Bei der Strategie handelt es sich nicht um eine feste Funktion, die einen Zustand eindeutig einer Aktion zuordnet, sondern um eine bedingte Wahrscheinlichkeitsverteilung. Sie ordnet je nach Zustand verschiedenen Aktionen Wahrscheinlichkeiten zu, aus denen der Agent dann auswählt. Der Grund für diese probabilistische Vorgehensweise liegt in der ebenfalls probabilistischen statt deterministischen Umgebung.
Im Beispiel des Schachspiels kann der Agent beispielsweise nicht davon ausgehen, dass bestimmte Aktionen (Züge) festgelegte Reaktionen des Gegners hervorrufen. Die Strategie gibt dem Agenten deshalb nur eine Wahrscheinlichkeitsverteilung für seine nächste Aktion vor, die er basierend auf dem aktuellen Zustand ausführen sollte. Ausgehend von einer anfänglichen Strategie erzeugt das System die Tripel-Sequenz bestehend aus Zuständen, Aktionen und Belohnungen. Die Strategie wird dann während des Trainings weiter verbessert.
Markov-Entscheidungsprozesse
Die Strategie Ï€(a,s) in Abbildung 1 nimmt an, dass die Wahrscheinlichkeitsverteilung für die nächste Aktion a lediglich vom letzten Zustand s abhängt. Allerdings ist dieser Zustand nur das Ende der bisherigen Sequenz von Zuständen. Hier stellt sich die Frage, warum die Wahrscheinlichkeitsverteilung nicht die gesamte Sequenz der bisherigen Zustände berücksichtigt.
Diese Annahme ist dadurch gerechtfertigt, dass sich viele Probleme des verstärkenden Lernens als sogenannte Markov-Entscheidungsprozesse interpretieren lassen. Ein Markov-Entscheidungsprozess ist ein mathematisches Modell für die Wahrscheinlichkeit des Ergebnisses beim Ãœbergang von einem Zustand in einen nächsten [1]. Der Agent bewegt sich dazu durch eine Menge von Zuständen S, indem er aus einer Menge von Aktionen A wählt. Welchen Zustand der Agent erreicht, ist nicht deterministisch. Die Wahrscheinlichkeiten hängen jedoch nur von der gewählten Aktion und dem aktuellen Zustand ab, nicht von den weiter zurückliegenden Zuständen. Das ist die entscheidende Eigenschaft eines Markov-Prozesses. Näherungsweise kann man das Wetter als Markov-Prozess betrachten, da die Wahrscheinlichkeit für dessen zukünftigen Zustand nur vom aktuellen Wetter abhängt und nicht davon, wie das Wetter in der länger zurückliegenden Vergangenheit war.
Konkret bedeutet die Markov-Annahme für das Problem des verstärkenden Lernens, dass die Wahrscheinlichkeit, einen Zustand s1 von einem Zustand s aus zu erreichen, nur von diesem Zustand und der Aktion a abhängt, aber nicht von den vorherigen Zuständen. Dadurch kann man die Suche nach der optimalen Strategie auf die Menge der sogenannten stationären Strategien beschränken. Eine Strategie bezeichnet man als stationär, wenn die von ihr zurückgegebene Wahrscheinlichkeitsverteilung für Aktionen nur vom zuletzt besuchten Zustand abhängt.
Beim Markov-Entscheidungsprozess als Modell für die Umgebung sind die Wahrscheinlichkeiten für den Zustandsübergang von s nach s’**P(s,a,s’) und die Belohnungsfunktion R(s,a,s’) bekannt. Damit liegt ein konkretes mathematisches Modell für das verstärkende Lernen vor, das es erlaubt, eine optimale Strategie für den Agenten zu finden. Hier spricht man deshalb auch von modellbasiertem verstärkenden Lernen.
Optimierungsproblem
Das Auffinden der optimalen Strategie ist die Kernaufgabe des verstärkenden Lernens. Wie so oft im Bereich des maschinellen Lernens gilt es, dazu ein konkretes Optimierungsproblem zu lösen, um die Strategie zu finden. Dazu muss man jeder Strategie zunächst eine Bewertung zuordnen, auf der aufbauend sich dann ein Optimierungsverfahren formulieren lässt. Zur Bewertung der Strategie bei Markov-Entscheidungsprozessen lässt sich eine Zustands-Wert-Funktion nutzen, die eine Strategie (a,s) ausgehend vom aktuellen Zustand s aus bewertet:
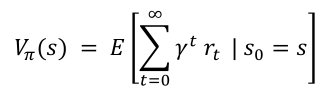
Diese Funktion berechnet die voraussichtliche Gesamtbelohnung des Agenten als Erwartungswert der Summe aller folgenden Belohnungen, wenn der Agent sich gerade im Zustand s befindet und der Strategie Ï€(a,s) folgt. Weil es dabei um den gegenwärtigen Wert einer zukünftigen Summe geht, benutzt man dafür häufig einen Terminus aus der Finanzmathematik und spricht von einer diskontierten Summe [2]. Der Diskontierungsfaktor γ liegt zwischen 0 und 1. Er gewichtet Belohnungen in der fernen Zukunft schwächer.
Die Zustands-Wert-Funktion beschreibt also die Gesamtbelohnung, die der Agent zu erwarten hat, wenn er im Zustand s startet und Aktionen ausführt, die der Strategie Ï€(a,s) folgen. Die Berechnung des Erwartungswerts kann man beim modellbasierten verstärkenden Lernen mithilfe der bekannten Modellgrößen P(s,a,s’) und R(s,a,s’) vornehmen. Damit lässt sich auch die Zustands-Wert-Funktion für eine vom Zustand s ausgehende optimale Strategie bestimmen. Die Zustands-Wert-Funktion für die optimale Strategie erfüllt eine rekursive Gleichung, die Bellman-Gleichung [3]:
![]()
Basierend auf einem gegebenen V(s) kann man dann auch die optimale Strategie bestimmen, die zum vorteilhaftesten Wert der Zustands-Wert-Funktion ausgehend vom Zustand s führt:
![]()
Die optimale Strategie lässt sich also bestimmen, sobald man V(s) für alle Zustände s kennt. Für Probleme mit einem kleinen Zustandsraum wie Tic-Tac-Toe kann man basierend auf der Bellman-Gleichung Iterationsverfahren anwenden, um zunächst V(s) und dann die optimale Strategie als Lösung des Optimierungsproblems zu bestimmen.
Methoden des verstärkenden Lernens
Markov-Entscheidungsprozesse sind ein nützliches Modell für Probleme des verstärkenden Lernens. Liegt ein Markov-Entscheidungsprozess mit gegebenem P(s,a,s’) und R(s,a,s’) vor, lässt sich das Problem iterativ lösen. Allerdings kennt man in der Praxis oft nicht alle Informationen und insbesondere nicht P(s,a,s’) und R(s,a,s’). Zur Lösung derartiger Probleme gibt es eine Vielzahl verschiedener Methoden des modellfreien verstärkenden Lernens.
Ein Problem unvollständiger Informationen ist, dass sich bei fehlendem P(s,a,s’) und R(s,a,s’) die V(s) nicht ohne Weiteres bestimmen lässt. Das macht es unmöglich, daraus eine optimale Strategie abzuleiten, wie das bei einem modellbasierten Problem mit bekanntem P(s,a,s’) und R(s,a,s’) der Fall wäre. Eine in diesem Fall oft angewandte Methode ist das zeitliche Differenzlernen. Dahinter steckt die Idee, V(s) zunächst zu raten und dann langsam iterativ zu verbessern.
Dazu überprüft der Agent nach jeder Aktion, wie sich die ihm über V(s) versprochene erwartete Belohnung im Vergleich zur direkt erhaltenen Belohnung und der nun in Aussicht stehenden erwarteten Belohnung verhält. Dementsprechend passt er die V(s) des eben verlassenen Zustands geringfügig entsprechend an. Der Agent betrachtet also verschiedene Zeitpunkte in der Lernsequenz. Die Strategie wird dann basierend auf den gefundenen V(s)-Werten ebenfalls iterativ verändert. So lässt sich V(s) sukzessive lernen und später daraus dann eine Strategie ableiten.
Daneben gibt es auch Verfahren, bei denen man die Strategie nicht explizit aktualisieren muss. So wird beim Q-Lernen beispielsweise die Strategie implizit mitgelernt. Dazu optimiert man statt der Zustands-Wert-Funktion eine Aktions-Wert-Funktion Q(s,a), die vom aktuellen Zustand s und der nächsten Aktion a abhängt. Als Gesamtbelohnung ergibt sich hier der Belohnungswert, den der Agent zu erwarten hat, wenn er im Zustand s startet, die Aktion a ausführt und von dort an optimal handelt. Auch beim Q-Lernen kann man auf das zeitliche Differenzlernen zurückgreifen, um die optimale Strategie zu finden.
Das Q-Lernen gehört zur Klasse der wertebasierten Verfahren des verstärkenden Lernens. Diese Methoden konzentrieren sich darauf, den Wert von Aktionen und Zuständen zu schätzen, um daraus eine optimale Strategie abzuleiten. Daneben gibt es auch strategiebasierte Verfahren (Abbildung 2). Sie zielen darauf ab, direkt eine optimale Strategie zu erlernen, statt den Wert von Aktionen und Zuständen erst zu schätzen.
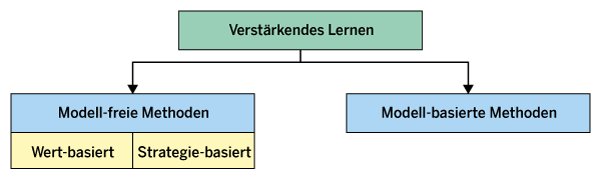
Abbildung 2: Die verschiedenen Methoden des verstärkenden Lernens in der Ãœbersicht.
Fazit
Verstärkendes Lernen stellt eine mächtige Methode des maschinellen Lernens dar, wenn rein datenbasierte Ansätze des überwachten Lernens aufgrund der Komplexität des Problems scheitern. Die Modelle des verstärkenden Lernens versuchen, das Trial-and-Error-Lernverhalten in der Natur nachzubilden und bedienen sich zur mathematischen Modellierung des Markov-Entscheidungsprozesses.
Verstärkendes Lernen kann auch ein Bewertungsmodell verwenden, das auf menschlicher Interaktion basiert. Dann erfolgt verstärkendes Lernen durch menschlich beeinflusste Rückkopplung. Dieses Verfahren kommt beispielsweise beim Trainieren von GPT-3.5 zum Einsatz, um das Alignment-Problem zu lösen: Generative Modelle wie ChatGPT erzeugen in ihren ursprünglichen Versionen voreingenommene, beleidigende oder schädliche Inhalte. In GPT-3.5 konnten die Entwickler das durch verstärkendes Lernen mit menschlichen Interaktionen minimieren. (jcb/jlu)
Infos
- Hidden Markov Model: https://de.wikipedia.org/wiki/Hidden_Markov_Model
- Diskontierung: https://de.wikipedia.org/wiki/Abzinsung_und_Aufzinsung
- Bellman Equation: https://en.wikipedia.org/wiki/Bellman_equation





