
© Olena Yakobchuk / 123RF.com
Apache ShardingSphere erweitert als leistungsfähige modulare Abstraktionsschicht Datenbanken wie MySQL oder PostgreSQL um Sharding und Skalierbarkeit in die Breite.
Datenbanken sind heute eine zentrale Komponente der meisten komplexen Setups. Frei nach dem Motto “ein spezielles Werkzeug für jede Aufgabe” hat es sich längst als Best Practice etabliert, die Verwaltung von Daten durch Datenbanken erledigen zu lassen, weil diese eben die Aufgabe am besten und effizientesten lösen. Die Veränderungen, die sich seit dem Aufkommen des Cloud-Computings, von Containern und dem Cloud-ready-Prinzip ergeben haben, erhöhten auch die Anforderungen an Datenbanken. In einer skalierbaren Umgebung muss sich auch die Datenbank skalieren lassen, mit einzelnen Instanzen von MySQL oder PostgreSQL ist es längst nicht mehr getan.
Ab Werk kommen DBMS mit etlichen Einschränkungen, die sie für den Betrieb in Cloud-Umgebungen eigentlich ungeeignet erscheinen lassen. Zwei Problemfelder sind offensichtlich: Zunächst gehen moderne Umgebungen heute davon aus, dass die darin laufenden Dienste implizit redundant sind. Üblicherweise stehen – das gilt besonders in Mikroarchitektur-Diensten – für jede Aufgabe beliebig viele Instanzen eines Diensts zur Verfügung, die einander überwachen und im Notfall die Aufgaben einer ausgefallenen Instanz nahtlos übernehmen. Wer schon einmal vor der Herausforderung stand, MySQL hochverfügbar zu machen, der weiß: Im Auslieferungszustand enthält MySQL keinerlei Funktionen für diese Aufgabe. Dasselbe gilt für PostgreSQL.
Das zweite Problemfeld ergibt sich aus der nötigen Skalierbarkeit. Monolithische Datenbanken der Vergangenheit wie MySQL oder PostgreSQL sind nicht darauf ausgelegt, nahtlos in die Breite zu skalieren. Es greift stattdessen das Prinzip, dass es stets genau eine zentrale Instanz des Diensts gibt, bei der sich höchstens die Kapazität des einzigen Servers erweitern lässt. Im Cloud-Kontext ist das vor allem deshalb ein Problem, weil es den beschriebenen Anforderungen an Cloud-ready-Anwendungen diametral entgegenläuft.
Neu ist diese Erkenntnis keineswegs, denn skalierbare Datenbanken sind in den vergangenen Jahren wie Pilze aus dem Boden geschossen und setzen zum Teil auf völlig neue architektonische Ansätze. Bei Yugabyte handelt es sich beispielsweise eigentlich um einen Key-Value-Store, der aber eine MySQL-Kompatibilitätsschicht bietet. Vitess dagegen nutzt im Hintergrund native MySQL-Datenbanken, fügt zwischen Anwender und DBMS aber eine Abstraktionsschicht ein, die sich um das Sharding und mithin um die Skalierbarkeit in die Breite kümmert.
Das Apache-Projekt schlägt mit seiner Software ShardingSphere [1] in eine ähnliche Kerbe, verspricht dabei aber einfaches Handling, nahtlose Erweiterbarkeit über Plugins und die Unterstützung der allermeisten gängigen Datenbanken. Grund genug, sich ShardingSphere genauer anzusehen.
Sharding
Zuvor schadet ein wenig Begriffskunde aber nicht, speziell im Hinblick auf den Begriff des Shardings. Vielen Administratoren dürften ihn noch aus der Urzeit der IT kennen, obgleich er sich damals auf einen völlig anderen technischen Sachverhalt bezog. Die Reise geht ganz weit zurück in die Vergangenheit, in eine Zeit, in der man die Kapazität von Festplatten noch in Gigabyte maß und nicht in Terabyte. Die Betreiber großer Mailserver hatten schon damals das Problem, dass ihnen der lokale Platz für Nachrichten regelmäßig ausging. Der Begriff Sharding meinte damals vor allem das Verteilen von Mailboxen der Nutzer auf verschiedene Maschinen, die nach außen weiterhin wie ein logischer Mailserver erschienen. Im Prinzip ist das Sharding bei ShardingSphere nichts anderes, nur dass es dabei eben um Datenbanken geht und nicht um E-Mails.
Im Datenbank-Kontext bedeutet Sharding, den Namespace einer Datenbank in logische Elemente zu teilen und diese auf verschiedene Datenbanken im Hintergrund zu verteilen. Beim DBMS-Sharding handelt es sich letztlich also nur um eine Abstraktionsebene, die nach außen eine einheitliche Ansicht ermöglicht und bei Zugriffen weiß, an welche der verfügbaren Instanzen sie die Anfrage eines Clients weiterleiten muss. Sharding erlaubt auf diese Weise zusätzliche Funktionen, etwa die Replikation einzelner Teile des Namespaces (oder auch der Shards) zwischen verschiedenen Datenbankinstanzen im Hintergrund. Auch Deduplikation, der parallele Read-only- oder Read-Write-Zugriff sowie Verschlüsselung während der Übertragung (“on-the-fly”) und beim Ablegen der Daten (“at rest”) lassen sich in der Abstraktionsschicht implementieren.
Die Architektur
ShardingSphere als Lösung zu bezeichnen, ist eigentlich nicht ganz korrekt: Es besteht aus zwei Komponenten mit unterschiedlichen Feature-Sets, die sich zusätzlich per Plugin erweitern lassen. Die Ursache dafür ist historischer Natur, denn ihren Anfang nahm die ShardingSphere-Entwicklung zunächst in Form eines JDBC-Moduls (Abbildung 1).
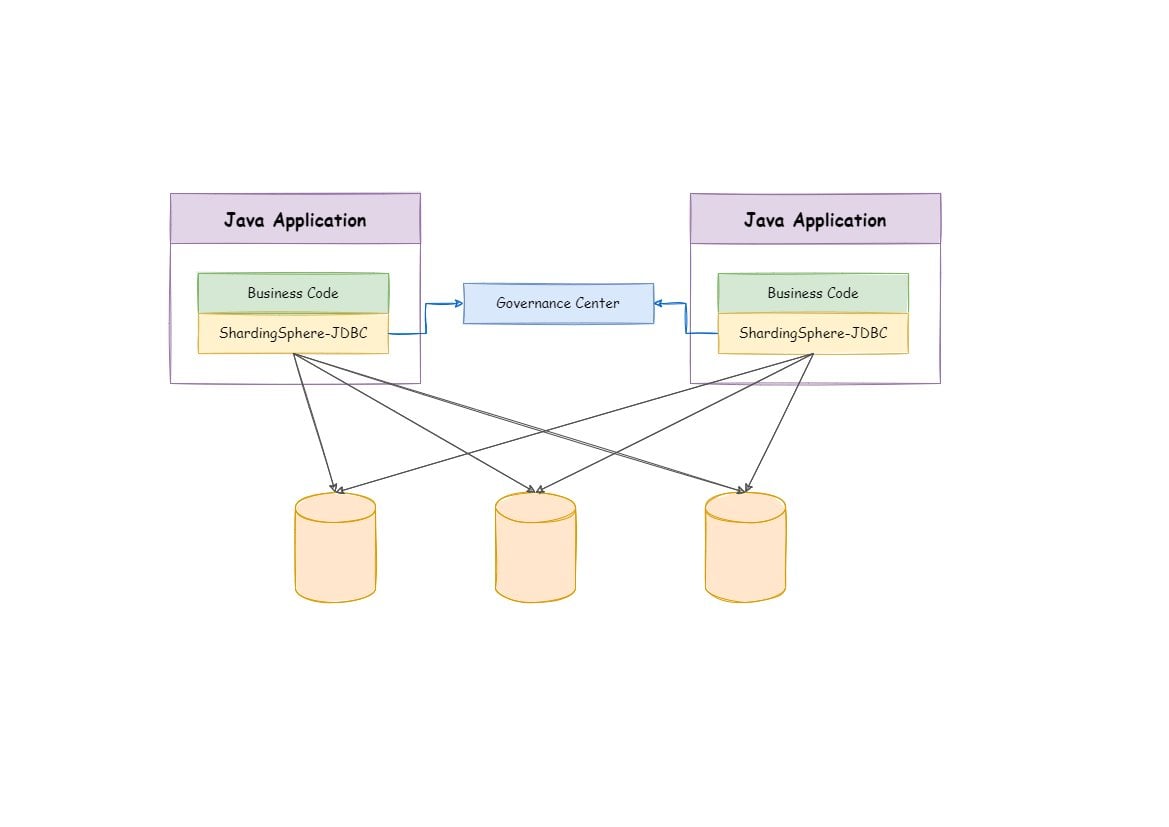
Abbildung 1: Von Haus aus ist ShardingSphere eigentlich eine JDBC-Anwendung und mithin für die Nutzung in Java-Umgebungen konzipiert. Für die Anwendungen und Clients ist es transparent. Quelle: ShardingSphere
Zur Erinnerung: JDBC steht für Java Database Connectivity und beschreibt eine Treiberumgebung für den Zugriff auf Datenbanken aus Java heraus. JDBC hat den großen Vorteil, dass es hochgradig modular ist und sich zudem verschiedene Module innerhalb der JDBC-Umgebung stapeln und mithin kombinieren lassen, indem man sie in Reihe schaltet. Die Keimzelle für ShardingSphere bestand in der Idee, für die am Markt seinerzeit dominanten Datenbanken wie MySQL oder PostgreSQL eine flexible Zwischenschicht zu konstruieren, die Sharding, Verschlüsselung, Redundanz und Verfügbarkeit liefert, ohne dafür an der Datenbank selbst große Umbauten vornehmen zu müssen. Stattdessen genügte es, in ShardingSphere einen Pool von Datenbank-Backends zu definieren und ShardingSphere selbst den Rest erledigen zu lassen. Dieses Einsatzszenario dürfte bis heute auch jenes sein, innerhalb dessen ShardingSphere am häufigsten zum Einsatz kommt.
Schon kurz nach seiner Entstehung 2016 sorgte ShardingSphere für einiges Aufsehen. Bald entstanden Begehrlichkeiten, seine Funktionalität auch außerhalb von JDBC verwenden zu können. Das war die Geburtsstunde der zweiten ShardingSphere-Variante, die heute schlicht ShardingSphere Proxy heißt (Abbildung 2). Sie erledigt im Wesentlichen dasselbe wie die JDBC-Variante, kommt aber als eigenständiger Dienst daher. Im Hintergrund verwaltet ShardingSphere Proxy dabei ähnlich wie JDBC einen Pool von Verbindungen zu Datenbank-Backends, wobei es protokollkompatibel zu MySQL und PostgreSQL agiert. Datenbanken auf der Client-Seite verbinden sich mit dem Proxy statt direkt mit der Datenbank.
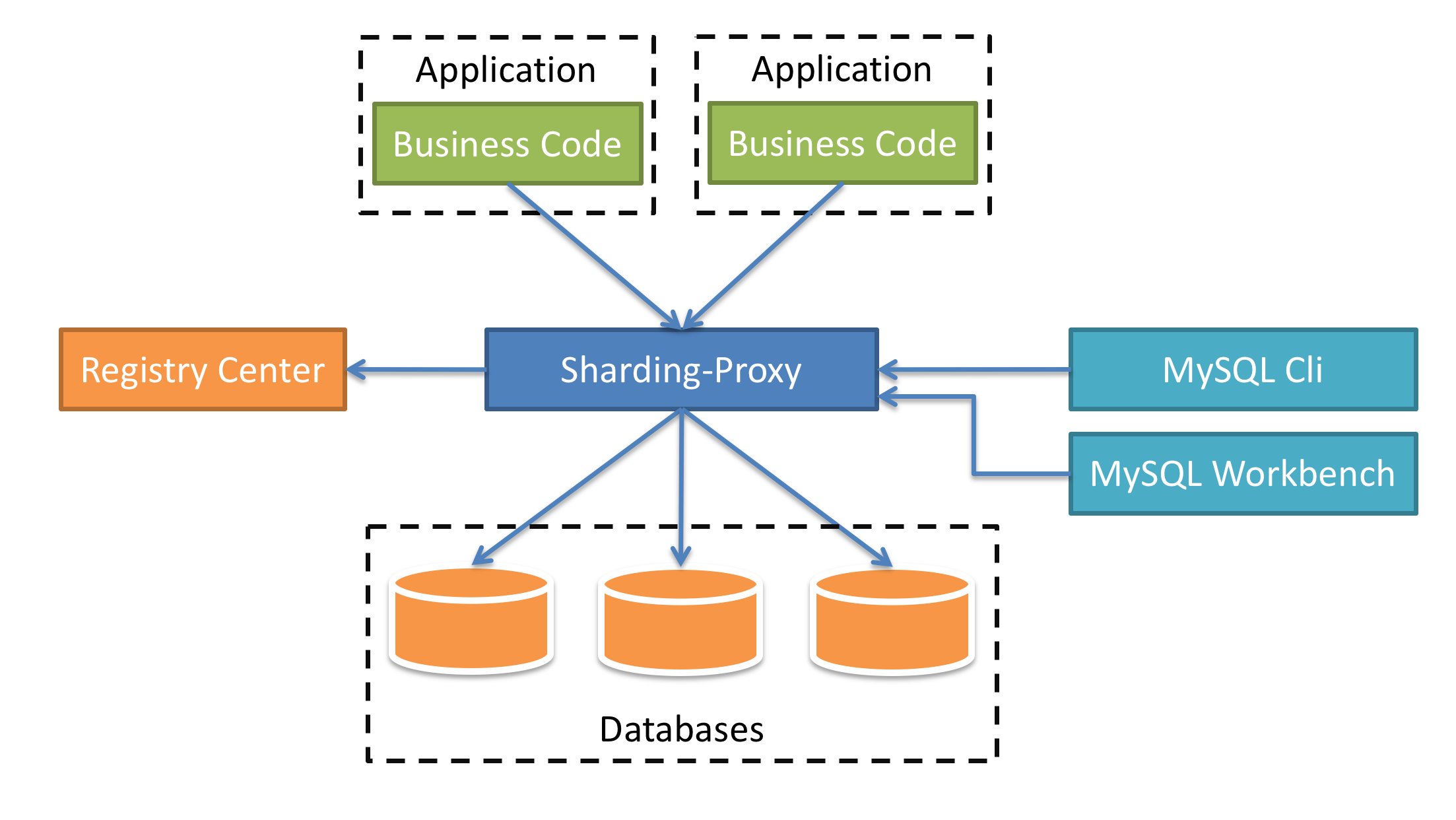
Abbildung 2: Der ShardingSphere Proxy liefert vergleichbare Funktionen wie die JDBC-Implementation, kommt aber ohne die Java-Schnittstelle aus und ist insofern generischer nutzbar. Quelle: ShardingSphere
Der Vorteil dabei: Indem ShardingSphere die Verbindung zwischen Client und Server steuert und kontrolliert, kann es allerlei praktische Funktionen implementieren, ohne dass Server oder Client dafür besonders vorbereitet sein müssten. Das ist eines der Hauptarchitekturprinzipien von ShardingSphere: Datenbank-Clients müssen durch den Dienst hindurch stets ohne Fehler mit einem DBMS in dessen SQL-Dialekt sprechen können, und zwar ohne besondere Anpassungen. Aus Sicht des Clients wie aus Sicht des Servers bleibt ShardingSphere also stets transparent.
Der Funktionsumfang von ShardingSphere weiß dabei durchaus zu überzeugen. Dreh- und Angelpunkt sämtlicher Features ist, wie beschrieben, das Aufteilen einer Datenbank in kleine logische Segmente, eben das Sharding. Dabei heben die Entwickler hervor, dass sie sowohl das Speichern von Daten als auch eventuelle Berechnungsaufgaben horizontal skalieren können. Oft ist bei einer Datenbank schließlich gar nicht das Problem, dass die einzelne Instanz zu wenig lokalen Platz hätte, sondern vielmehr, dass sie unter der Last eingehender Anfragen zusammenbricht, weil Ressourcen wie CPU und RAM endlich sind.
Das von ShardingSphere implementierte Sharding vermeidet das Problem, weil für die Berechnung von Queries im Hinblick auf einzelne logische Teile der Datenbank selbstredend jene Backends zuständig bleiben, die gerade den jeweiligen Shard halten. Greifen zwei große Queries also auf unterschiedliche Daten zu, werden diese von unterschiedlichen Backends abgewickelt und legen nicht die gesamte Datenbank lahm.
Verschlüsselung und mehr
Auch bei anderen Funktionen gibt ShardingSphere sich keine Blöße. So wirbt das Projekt damit, dass es signifikant schneller agiert als vergleichbare Lösungen der Konkurrenz. Das belegen die Entwickler sogar mit entsprechenden Benchmarks, beispielsweise im Rahmen der 38. ICDE-Konferenz der IEEE, bei der das Thema Data Engineering im Vordergrund stand. Hier legte das ShardingSphere-Team dar, wie es auf Basis seiner Lösung beinahe die native Performance der darunterliegenden Datenbanken erreicht. Der Performance-Overhead von ShardingSphere fällt also minimal aus.
Selbst bei der Verwendung des Proxys, der laut Entwicklern deutlich langsamer arbeitet als die JDBC-Option, liegt der Performance-Overhead mittlerweile bei unter 25 Prozent (Abbildung 3). Das darf durchaus als Besonderheit gelten: Die Entwickler von Vitess etwa geben für ihre Software an, dass die Performance im Vergleich zu einer nativen MySQL-Datenbank um bis zu 50 Prozent einbrechen kann. Das hat zum Teil allerdings etwas mit dem Thema Replikation zu tun, auf das der Artikel später noch im Detail eingeht.
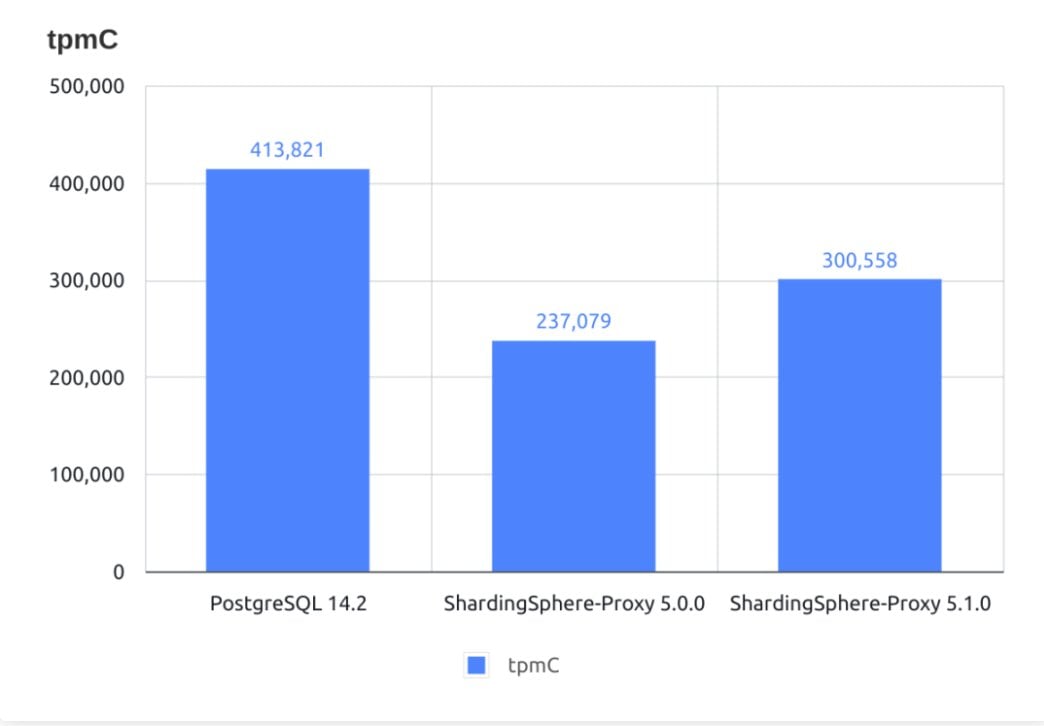
Abbildung 3: Selbst bei Verwendung von ShardingSphere Proxy, der langsameren der beiden Varianten, beträgt der Performance-Overhead bei PostgreSQL deutlich unter 25 Prozent. Quelle: ShardingSphere
Ebenfalls Bestandteil von ShardingSphere ist zudem eine Verschlüsselungsschicht, die sich in Form eines Plugins dynamisch aktivieren lässt. Sie sorgt insbesondere für das Verschlüsseln der Daten im Transit. Wer Verschlüsselung “at rest” benötigt, muss sich darum mittels einer der für MySQL oder PostgreSQL verfügbaren Lösungen selbst kümmern, so der lapidare Hinweis seitens der Entwickler.
Keine Replikation
Solange man nur eine verteilte Datenbank anlegen will, lässt ShardingSphere allerdings einen zentralen Aspekt aus, den vergleichbare Lösungen mitabwickeln: jenen der Replikation. Wie eingangs beschrieben, ist das ein Faktor, um den Datenbanken sich beim Skalieren in die Breite üblicherweise mitkümmern. Einerseits ist das eine Anforderung, die der Markt an Cloud-Native- und Cloud-Ready-Anwendungen ganz einfach stellt, und andererseits liegt das Einziehen einer Hochverfügbarkeitsschicht auf der Hand, wenn man Sharding implementiert. Denn dann ist es ja aus Datenbanksicht durchaus möglich, einen Shard auf mehrere Backends zu kopieren, sodass jedes dieser Backends einspringen kann, falls ein anderes versagt.
Dabei klingt die Beschreibung an dieser Stelle trivialer, als ihre technische Umsetzung letztlich ist. Wer sich mit Replikation im Datenbankkontext beschäftigt, muss schließlich Garantien wie ACID einhalten und dabei besondere Vorsicht walten lassen. Obendrein ist das Thema Replikation nicht sehr beliebt, eben weil die Einhaltung entsprechender Konsistenzgarantien üblicherweise eine synchrone Replikation erzwingt. Die nagt wiederum an der Performance. Gut möglich also, dass die ShardingSphere-Leute bei aktivierter Replikation ihre sonst traumhaften Performance-Werte nicht mehr einhalten könnten.
Die Antwort auf das Thema Replikation verwundert dann aber doch etwas, denn ShardingSphere hat kurzerhand beschlossen, das Thema praktisch komplett auszulassen. Stattdessen heißt es in der Dokumentation lapidar, man solle die Replikation auf Ebene der Datenbank-Backends implementieren. Dann habe man HA-Funktionalität, ShardingSphere sei für deren Einhaltung aber nicht zuständig. Am Ende läuft das konzeptionell darauf hinaus, dass man zahllose HA-Cluster aus MySQL- oder PostgreSQL-Pärchen baut und diese ShardingSphere dann als Backends verfüttert. Wer allerdings schon einmal versucht hat, MySQL händisch hochverfügbar zu machen, hat es dabei zwangsläufig mit Tools wie Pacemaker oder DRBD zu tun bekommen. Gerade Pacemaker ist dabei in der Handhabung nicht nur äußerst komplex, sondern auch ganz sicher nicht hochverfügbar.
Dass ihre User-Story in Sachen Redundanz ein Loch hat, ist den ShardingSphere-Entwicklern durchaus klar. Im Netz finden sich etliche Anleitungen bezüglich der Frage, wie ein valides HA-Setup mit ShardingSphere aussehen kann. Einige Anleitungen beziehen sich allerdings auf Plugins für ShardingSphere, die es schon gar nicht mehr gibt, oder setzen auf Hosted-Lösungen, etwa DBaaS von AWS, um das Management der eigentlichen Datenbankinstanzen an den Anbieter abzuwälzen.
Eine valide Anwendergeschichte ist das freilich aber nur in Umgebungen, in denen entsprechende As-a-Service-Angebote überhaupt existieren. Gerade das bieten private Cloud-Umgebungen, etwa auf Basis von OpenStack, oft nicht. Dass ShardingSphere heute über eine piekfeine Integration in Kubernetes verfügt und sich sämtliche ShardingSphere-Dienste in kürzester Zeit als K8s-Dienst betreiben lassen, hilft da auch nicht weiter, weil die Integration für die Anwendung darunter quasi komplett fehlt.
Gerade im Hinblick auf den Proxy gilt im ShardingSphere-Kontext noch eine Besonderheit: In der Dokumentation verweisen die Entwickler regelmäßig auf einen Cluster Mode. Davon darf der Leser sich aber nicht täuschen lassen. Der Cluster Modus ist in ShardingSphere lediglich eine Betriebsart, um die verschiedenen Datenbankinstanzen im Hintergrund zu gruppieren. Die meisten Administratoren dürften mit dem Begriff Cluster hingegen eher Hochverfügbarkeit verbinden, aber eben die fehlt in ShardingSphere wie beschrieben komplett.
Was für’s Auge
Nicht unerwähnt bleiben soll an dieser Stelle die ShardingSphere-UI, die quasi im Vorbeigehen elementare Schwächen der Produktdokumentation und der Entwicklergemeinschaft von ShardingSphere aufdeckt.
Auf dem Papier ist die ShardingSphere-UI ein auf Vue.js basierendes grafisches Interface für den Datenbankverteiler (Abbildung 4). Es ermöglicht einerseits administrative Aufgaben wie das Festlegen der ShardingSphere-Konfigurationsparameter. Andererseits soll es aber auch dabei helfen, die Struktur der aktuell in ShardingSphere hinterlegten Daten zu verstehen, ihre Verteilung zu erkennen und die augenblicklich genutzten Backends zu analysieren.
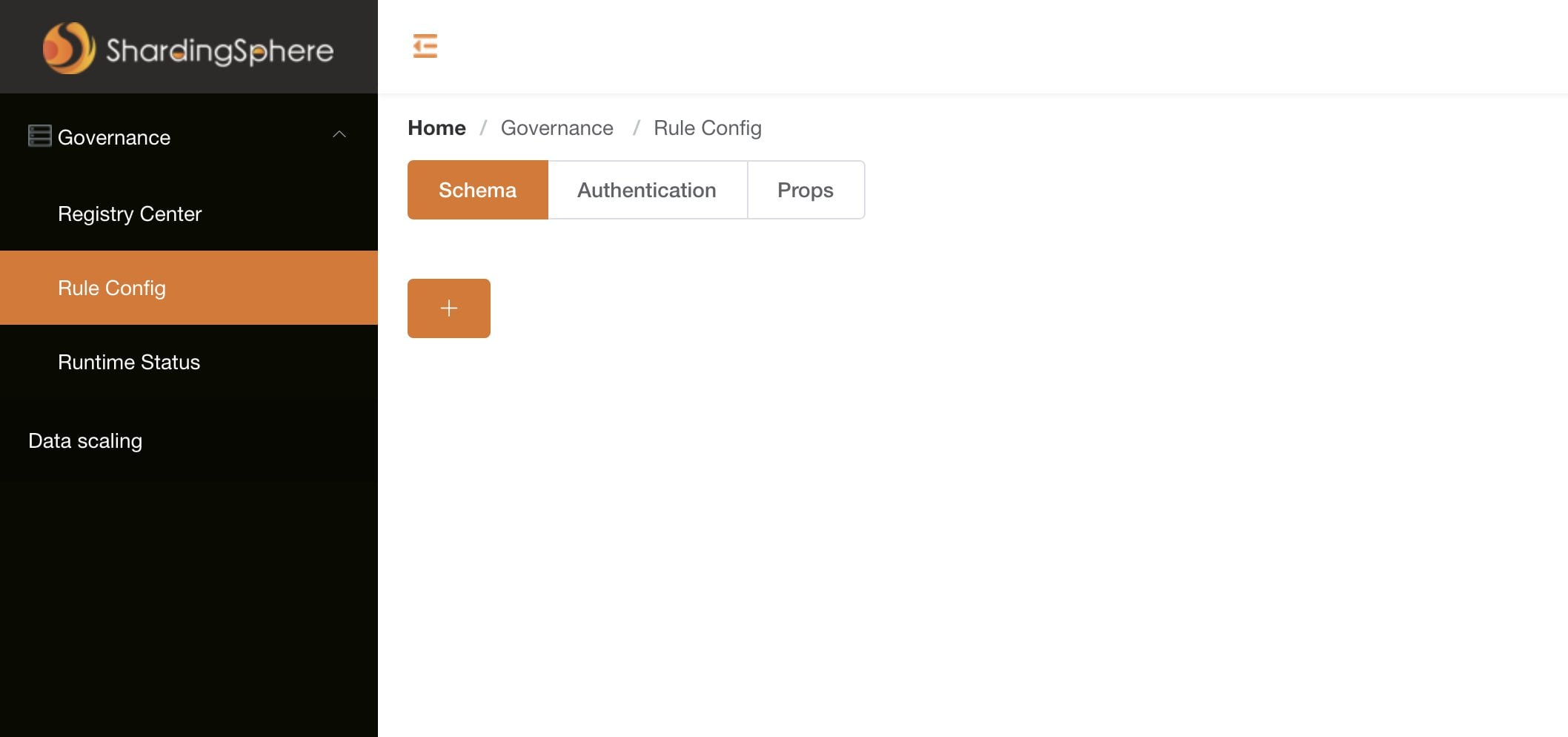
Abbildung 4: Die ShardingSphere-UI soll das Verständnis der hinterlegten Daten und die Cluster-Funktionalität deutlich erleichtern, ist aber merklich unterdokumentiert. Quelle: ShardingSphere
Dumm nur, dass die ShardingSphere-Dokumentation über UI kaum ein Wort verliert und das Git-Repository zwar den Code enthält, zusammen damit allerdings nur ein paar dürre Zeilen zur Installation. Den Rest darf der Administrator sich quasi allein zusammenreimen. Das ist insbesondere im Hinblick auf den Teil nicht ganz trivial, der die Verbindung des UIs mit einer laufenden ShardingSphere-Instanz oder einem laufenden ShardingSphere-Cluster beschreibt. Denn wer mit der Lösung noch keine Erfahrung hat, versteht im schlechtesten Fall die Konfigurationssyntax nicht und experimentiert stundenlang herum.
Fatalerweise ist die Dokumentation der Benutzeroberfläche zudem nicht der einzige Teil der ShardingSphere-Doku, der einfach vollständig fehlt. Immer wieder stößt man bei der Lektüre auf Stellen, die man nur versteht, wenn man bereits mit dem JDBC gearbeitet oder schon Vorerfahrung mit dem Proxy gesammelt hat. Ungeachtet etlicher Quickstart Guides haben Einsteiger es bei ShardingSphere alles andere als leicht, denn die Guides sind regelmäßig nur Links auf Github-Verzeichnisse mit Beispielcode, verteilt auf eine Vielzahl von Dateien. Wie man von blanken Systemen hin zu einer laufenden ShardingSphere-Instanz kommt, verraten diese Dokumente gerade nicht.
Und die Konkurrenz?
Wie beschrieben, ist ShardingSphere eine umfangreiche Lösung, um Datenbanken in die Gegenwart zu hieven und sie um Cloud-ready-Fähigkeiten sowie Skalierbarkeit zu erweitern. Wie aber schlägt das Werkzeug sich im Hinblick auf seine Konkurrenz? Die Frage lässt sich gar nicht so leicht beantworten, eben weil sich im Marktsegment, das ShardingSphere anspricht, mittlerweile eine Vielzahl komplexer Lösungen tummeln. Deren Fundamente unterscheiden sich von denen von ShardingSphere zum Teil allerdings erheblich.
Noch am ehesten mit ShardingSphere vergleichbar ist das schon genannte Vitess [2]: Es implementiert ein eigenes Sharding spezifisch für MySQL und setzt dabei auf eine vergleichbare Komponentenstruktur. Es implementiert ebenfalls keinen eigenen Speicher, sondern greift auf MySQL-Instanzen im Backend zurück. Über die verteilt es seinen eigenen logischen Datenbank-Namespace. Anders als ShardingSphere spezialisiert Vitess sich aber wie gesagt auf MySQL. Die in ShardingSphere ebenfalls enthaltene Unterstützung beispielsweise für PostgreSQL fehlt ihm vollständig.
Die bieten andere Lösungen wie etwa Yugabyte [3]. Das operiert unter der Haube als klassischer Key-Value-Store, exponiert seine Strukturen zur Außenwelt hin jedoch über eine eigens für diesen Zweck geschaffene PostgreSQL-Kompatibilitätsschicht. Das führt im Zweifelsfall dazu, dass eine Anwendung auf die Nase fällt, wenn sie ein PostgreSQL-Feature nutzen will, das der Nachbau von Yugabyte nicht beherrscht. ShardingSphere geht hier cleverer vor, weil es im Hintergrund echte PostgreSQL- oder MySQL-Datenbanken nutzt. Wer auf der Suche nach einer Lösung für verteilte Datenbanken per Aufsatz ist, sollte ShardingSphere entsprechend in seine Evaluation einschließen.
Allerdings hat ShardingSphere bei der Planung der Lösung nicht gleich auch das Thema implizite Hochverfügbarkeit abgedeckt. Hier ist die Konkurrenz deutlich weiter: Vitess beispielsweise kann die einzelnen Shards eines Knotens auf andere Knoten replizieren und diese im laufenden Betrieb jeweils auch nahtlos gegeneinander austauschen. Ähnliches gilt für die Key-Value-Datenbank, die das Herz von Yugabyte bildet.
Blick in die Zukunft
Die ShardingSphere-Entwickler betrachten ihre Arbeit noch lange nicht als abgeschlossen und werkeln bereits an einer dritten Darreichungsform ihres Produkts: ShardingSphere Sidecar (Abbildung 5). Wer im Container- und K8s-Umfeld unterwegs ist, ahnt bereits, worauf das hinausläuft: Sidecar soll ShardingSphere-Funktionen bieten, dabei aber als Cloud-nativer Dienst daherkommen und sich nahtlos in Container-Flotten integrieren.
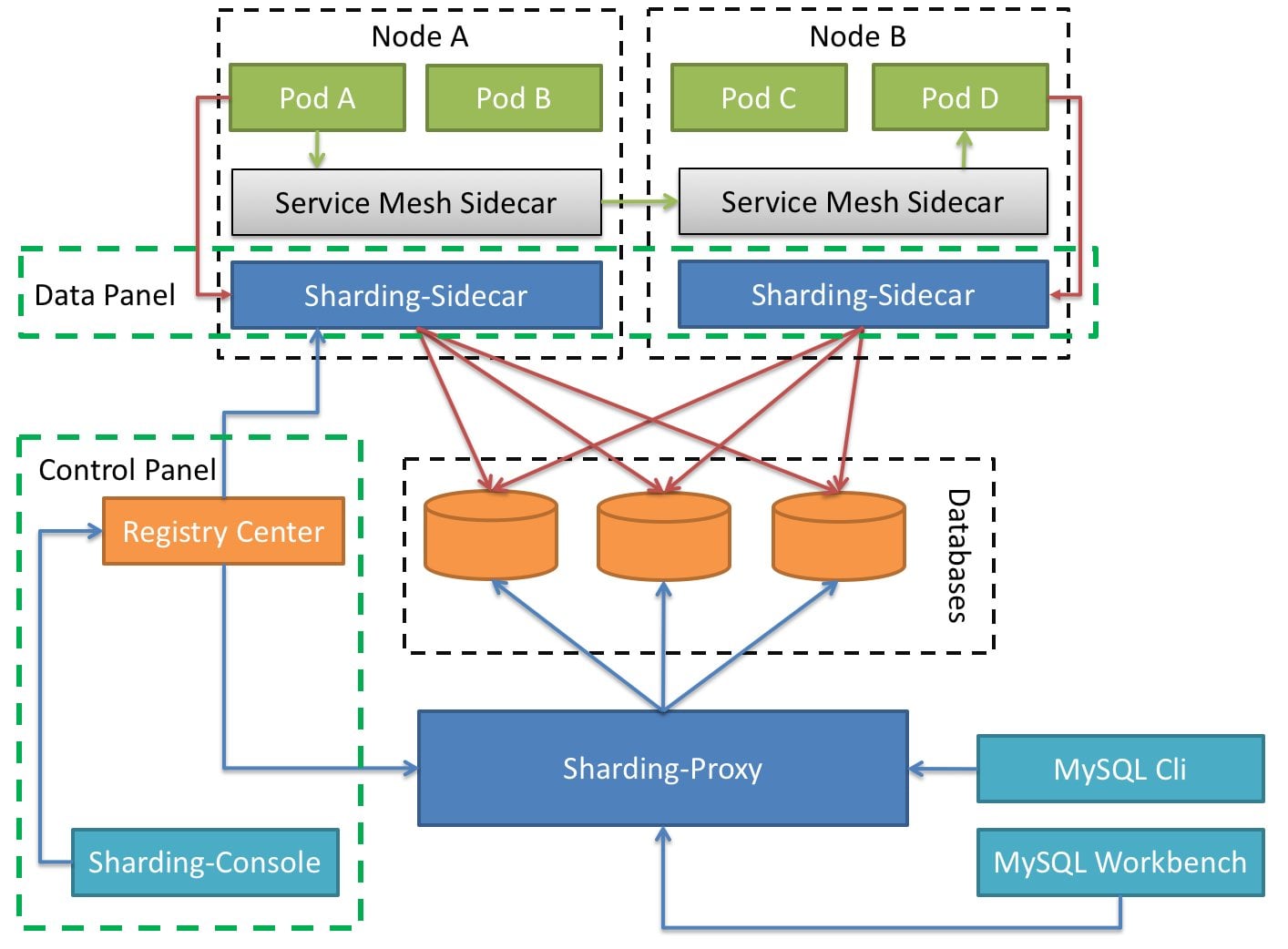
Abbildung 5: Zum JDBC-Treiber und dem Proxy soll sich absehbar das für den Betrieb der Lösung in Clouds optimierte ShardingSphere Sidecar gesellen. Eine produktionsreife Version lag zu Redaktionsschluss allerdings noch nicht vor. Quelle: ShardingSphere
Dabei werkelt Sidecar in enger Kooperation mit dem Proxy: Auch der wird in einem Sidecar-Setup nach ShardingSphere-Lesart nämlich weiter benötigt. Dank einer integrierten Mesh-Funktionalität kommunizieren die einzelnen Anwendungen dann aber nicht mehr direkt mit dem Sharding-Proxy, sondern mit einer lokalen Instanz von Sharding Mesh Sidecar. Die laufenden Mesh-Sidecars wiederum leiten die eigentlichen Daten an die Sharding-Sidecars von ShardingSphere weiter, die schließlich mit den Datenbank-Backends kommunizieren.
Derzeit ist ShardingSphere Sidecar noch nicht für den produktiven Einsatz freigegeben, Administratoren müssen sich mit Alternativen behelfen. Diese könnten etwa aus der Kombination des Proxy-Servers von ShardingSphere mit einem Mesh wie Istio bestehen.
Fazit
ShardingSphere ist ein umfassendes und mächtiges Werkzeug, um Datenbanken konventioneller Art in die skalierbare IT der Gegenwart zu hieven. Anders als die Konkurrenz etwa von Yugabyte versucht es dabei nicht, das Rad neu zu erfinden: Durch ShardingSphere hindurch reden Anwendungen also mit einem echten MySQL statt mit einer Übersetzerschicht.
Es fällt jedoch auf, dass die einzelnen Komponenten von ShardingSphere nicht vollständig Feature-kompatibel zueinander sind. Dass die JDBC-Implementierung der Erstling war, macht sich beispielsweise dadurch bemerkbar, dass sie bis heute die meisten Features bietet. Das degradiert den ShardingSphere-Proxy aber nicht zu einer Komponente zweiter Klasse. Aus Sicht des Entwicklers oder Administrators gilt es im Falle eines Falles aber, sorgsam zwischen den Varianten zu wählen. Steht ohnehin JDBC im Rahmen eines Projekts zur Verfügung, bietet sich diese Option jedenfalls an.
So oder so gilt: Wer sich nicht nur mit fertigen Boxed-Lösungen für skalierbare Datenbanken beschäftigen möchte, sollte neben Vitess, das für MySQL einen ähnlichen Ansatz verfolgt, auch ShardingSphere auf der Liste der zu evaluierenden Lösungen haben. (jcb)
Infos
- Apache ShardingSphere: https://shardingsphere.apache.org
- Vitess: https://vitess.io
- Yugabyte: https://www.yugabyte.com





