
© Mykhailo Shpenyk / 123RF.com
In Sachen Orchestrierung buhlen etliche Fertiglösungen um die Gunst der Nutzer. Doch die vorhandenen Bordmittel bieten bereits eine mögliche Lösung: Auch Ansible beherrscht den virtuosen Umgang mit AWS und Konsorten.
Ein zentraler Vorteil von Cloud-Computing-Umgebungen besteht darin, die dortigen Workloads per Orchestrierung zentral zu verwalten. Logisch: Wenn ohnehin alle Ressourcen der Zielplattform ohne Ausnahme virtuell existieren, spricht nichts dagegen, die gesamte virtuelle Umgebung in einer Textdatei zu beschreiben und die Cloud das Anlegen der Ressourcen erledigen zu lassen. Branchenprimus Amazon war das bei seiner AWS-Cloud früh klar: CloudFormation (Abbildung 1) heißt der dortige Dienst, der auf Zuruf nicht nur einzelne Ressourcen anlegt, sondern ganze virtuelle Setups. Azure und GCP – die anderen beiden Hyperscaler – haben längst reagiert und bieten ähnliche Funktionalität.
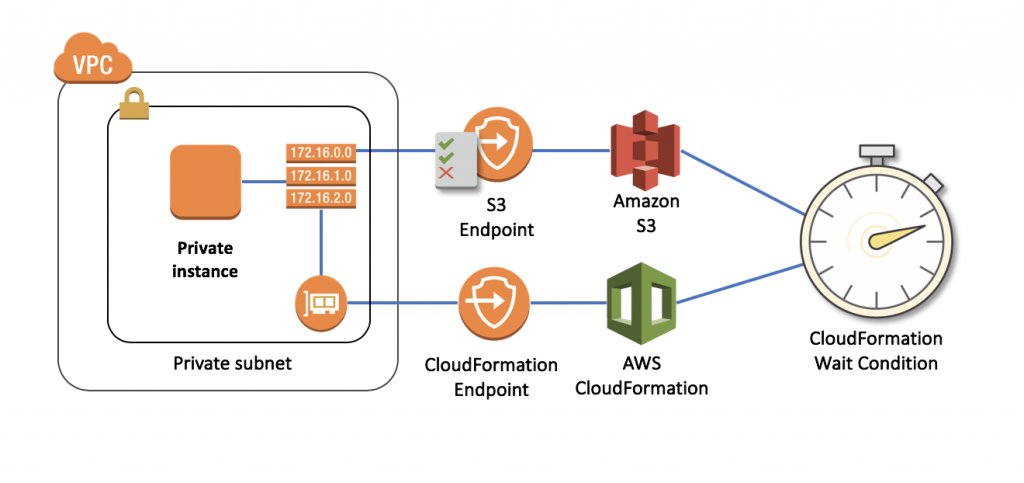
Abbildung 1: CloudFormation gilt als erste echte Orchestrierungslösung in Public Clouds und bietet viele Möglichkeiten, lässt sich zum großen Teil durch Ansible aber gut ersetzen. Quelle: Amazon
Obendrein ist Orchestrierung auch bei den Lösungen für private Clouds längst angekommen: OpenStack Heat (Abbildung 2) beherrscht neben dem eigenen Template-Format (Heat Orchestration Template, kurz HOT) sogar CloudFormation-Dateien bis zu einem bestimmten Grad. Und wer in die Container-Welt blickt, findet dort Kubernetes als autarken Orchestrierer für den Betrieb von Containern in Computing-Flotten. Klar ist: Das Prinzip Orchestrierung ist etabliert, und mit einem Abebben der Orchestrierungseuphorie ist kaum zu rechnen.
Abbildung 2: Das Prinzip der Orchestrierung hat von AWS schnell auf andere Lösungen übergegriffen, etwa auf OpenStack Heat, eine Art CloudFormation-Nachbau. Quelle: Open Metal
Etablierte Unternehmen wie Orchestrierer haben diesen Trend schon vor einiger Zeit erkannt und versuchen, ein Stück oder zumindest ein paar Krümel des großen Orchestrierungskuchens zu ergattern. Längst sprießen die Addons und Aufsätze für die Orchestrierungslösungen der Hyperscaler wie Pilze aus dem Boden. In bester Marketing-Manier kennen die Superlative dabei kaum Grenzen: Dank ihrer Werkzeuge sei Orchestrierung in der Cloud nicht nur effizienter als mit den Bordmitteln der Anbieter, sondern überhaupt erst sinnvoll zu implementieren, heißt es. Das gelte gerade dann, wenn hybride Setups mehrere Cloud-Umgebungen kombinieren und neben dem bloßen Anlegen und Starten von Ressourcen auch das Thema Verwaltung eine Rolle spielt.
Passend dazu tummeln sich am Markt mittlerweile etliche Lösungen, die gekonnt mit AWS, Azure und GCP hantieren und Templates mitbringen, um ganze virtuelle Setups in kürzester Zeit aus dem Boden zu stampfen. Oft aber bleibt bei der Nutzung dieser Werkzeuge ein fader Beigeschmack. Denn dezent verhalten sich die Tools der Anbieter meistens nicht. Stattdessen setzen sie voraus, dass der Administrator praktisch den gesamten eigenen Workflow auf Wohl und Wehe an die Vorgaben des jeweiligen Werkzeugs anpasst. Ein Schelm freilich, wer hier einen Lock-in-Effekt als Vater des Gedankens vermutet.
So oder so: Längst nicht jeder Administrator ist von der Idee begeistert, liebgewonnene Gewohnheiten und erlerntes Wissen über Bord zu werfen, um ein bestimmtes Automationswerkzeug verwenden zu können. Das umfasst übrigens ausdrücklich auch Terraform, das mittlerweile eine große Fangemeinde hat, aber auch viele wenig begeisterte Kritiker.
Alternative Ansible
Vielleicht muss der geneigte Admin aber auch gar nicht alles vergessen, was er weiß, um sein Glück bei der Orchestrierung von Clouds und Containern zu finden. Als Alternative stehen nämlich etliche Werkzeuge bereit, die viele Admins vermutlich sogar bereits einsetzen, und mittels derer sich Orchestrierung fast so umfassend erreichen lässt wie mit Spezialwerkzeugen.
Quasi die Speerspitze dieser Bewegung ist Ansible. Zwar ist das Tool den meisten Admins zumindest als Automatisierer bekannt, selbst wenn es in einem Unternehmen nicht unmittelbar zum Einsatz kommt. Dass Ansible mittlerweile aber den virtuosen Umgang mit den Hyperscalern ebenso gut beherrscht wie das Hantieren mit Ressourcen etwa in OpenStack wissen im Gegenzug nur wenige. Schade, denn so halsen sich viele Unternehmen externe Werkzeuge auf, obwohl sie eine leistungsfähigere Lösung möglicherweise bereits im Haus haben.
Dass Ansible sich für die Orchestrierung von Clouds eignet, ist dabei weder eine Überraschung noch eine tatsächliche Neuigkeit. Bereits vor dem Kauf durch Red Hat verstand das Werkzeug sich hervorragend mit AWS und Konsorten, und seither haben seine Entwickler die Fähigkeiten von Ansible zur Orchestrierung in Clouds noch ausgebaut. Technisch bringt Ansible ja ohnehin alles mit, was nötig ist. So versteht das Produkt sich als grundsätzlich idempotenter Automatisierer. Will heißen: Der Administrator beschreibt in Ansible einen Zustand, den ein Zielsystem haben soll. Läuft Ansible dann los und arbeitet seine Aufgaben ab, prüft es, ob der gewünschte Zustand auf dem Zielsystem bereits vorliegt. Falls das so ist, tut Ansible gar nichts. Ansonsten erzwingt Ansible die nötigen Änderungen.
Genau so funktioniert im Grunde aber auch Orchestrierung. Denn die tut auch nichts anderes, als den fertigen Zustand einer ganzen Umgebung zu beschreiben und über die von der jeweiligen Zielplattform bereitgestellten Dienste dafür zu sorgen, dass dieser Zustand erreicht wird. Der Vorteil für den Administrator liegt allerdings auf der Hand. Ansible-Rollen und -Playbooks gelten seit jeher als selbstdokumentierend. Gerade weil die Ansible-Entwickler in ihren YAML-Dateien eher einer Shell-Syntax folgen, als sich eine komplizierte deklarative Skriptsprache selbst auszudenken, genügt oft ein Blick, um die Ziele einer Ansible-Rolle oder eines Ansible-Playbooks nachzuvollziehen.
Wir beschreiben im Folgenden, wie sich mit Ansible Ressourcen bei den drei großen Hyperscalern und in einer privaten OpenStack-Umgebung manipulieren und verändern lassen. Dabei kommen übrigens die Orchestrierungsdienste der Zielplattformen gar nicht notwendigerweise zur Anwendung. Denn sogar deren Funktionalität lässt sich durch Ansible zum Teil ersetzen. Ohnehin sprechen in den meisten Clouds die Orchestrierungsdienste im Hintergrund mit den einzelnen API-Komponenten, allerdings in der richtigen Reihenfolge im Hinblick auf die zu erstellenden Ressourcen. Genau das kann Ansible auch, wenn auch mit etwas weniger Komfort.
Ein Beispiel verdeutlicht das schnell: Bestimmt der Admin beispielsweise in einer Datei für CloudFormation, dass eine virtuelle Instanz mit einem VPC – also einem virtuellen Netz – zu starten ist, muss er auch dieses Netz explizit definieren, falls er kein bereits vorhandenes Netz wiederverwendet. CloudFormation sorgt jedoch automatisch dafür, dass das Netz immer angelegt ist, bevor es die auf das Netz zugreifende virtuelle Instanz startet.
Im Ansible-Playbook hingegen muss der Admin regelmäßig zumindest sicherstellen, dass das Anlegen der gewünschten Ressourcen in der richtigen Folge geschieht. Denn anderenfalls wäre das Ergebnis eine schnöde Fehlermeldung. Das tut der Sache insgesamt aber keinen Abbruch – denn das Hirnschmalz, das in die richtige Reihenfolge beim Erstellen der Ressourcen fließt, würde sonst in das Erlernen des Syntax fließen, die der jeweilige Orchestrierer vorgibt. Schlimmstenfalls stünde gar das Erlernen eines völlig neuen Werkzeugs an, mit der Gefahr, dass es sich letztlich als Windei herausstellt.
Ansible und AWS
Quasi in der Natur der Sache liegt, dass die Unterstützung für Ressourcen in AWS bei Ansible mit einigem Abstand die vollständigste ist. Einerseits war AWS die erste Plattform überhaupt, die richtige Traktion am Markt erlangen konnte. Andererseits hat AWS bis heute die größte Anwenderbasis, sodass die Ansible-Entwickler mit den entsprechenden Features die größte Zielgruppe unter ihren Nutzern bedienen. Das Modul für die Interaktion mit AWS stammt dabei unmittelbar von den Ansible-Entwicklern selbst und kann sich in Sachen Leistungsumfang durchaus sehen lassen.
Wichtig ist dabei aus Sicht des Administrators die Frage, wie AWS-spezifische Funktionen sich aus Rollen und Playbooks heraus unmittelbar aufrufen lassen. Hier folgt Ansible seinem bekannten Schema und stellt den eigentlichen Funktionsnamen sprechende Bezeichnungen voran, gefolgt von einem Unterstrich (»_«). Wer beispielsweise ein VPC, also ein virtuelles Cloud-Netz, aus Ansible heraus anlegen möchte, benutzt dafür die Ansible-Funktion »ec2_vpc_net«. Hier liegt sogar ein Spezialfall vor, denn Ansible sieht VPC als eine Unterfunktion von EC2 (Elastic Compute) an und setzt deshalb gleich zwei Präfixe vor den eigentlichen Befehl (»net«). Etwas offensichtlicher liegt die Sache etwa bei der Funktion »rds_cluster«, die Datenbank-Cluster in Amazon RDS anlegt.
Die Beschreibung des AWS-Moduls in der Ansible-Dokumentation listet die zur Verfügung stehenden Optionen auf. Die haben es in Summe durchaus in sich. Mittels etlicher Funktionen für den Objektspeicher S3 etwa lassen sich darin Verzeichnisse (Buckets, Präfix »s3_object«) und Objekte verändern. Für Amazon AWS EC2 steht gleich ein ganzer Haufen von Modulen zur Verfügung. Mit ihnen kann man virtuelle Instanzen anlegen (Abbildung 3), sie mit persistentem Speicher versorgen, mit Metadaten und SSH-Schlüsseln ausstatten oder aus spezifischen fertigen Betriebssystemabbildern heraus starten. Auch Snapshots bestehender EC2-Volumes lassen sich anlegen, löschen oder verwalten. Hinzu kommen Funktionen für den globalen DNS-Dienst Route 53, für AWS Lambda sowie für AWS Backup. Wer die automatische Skalierung von EC2 nutzt, bestimmt deren Parameter über die beiden Module »autoscaling_group« und »autoscaling_group_info«.
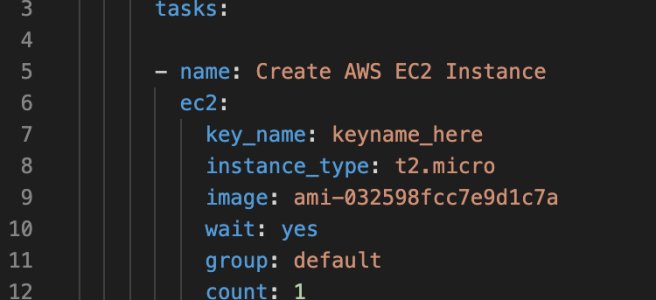
Abbildung 3: EC2-Instanzen aus Ansible heraus anzulegen, ist ein sehr einfaches Unterfangen. Wie bei anderen Ansible-Ressourcen gibt der Administrator lediglich die Parameter an, Ansible erledigt den Rest. Quelle: GeekTechStuff
Interessant ist für passionierte Ansible-Administratoren auch, wie die Ansteuerung der Dienste aus Amazon heraus funktioniert. Die Syntax entspricht durchaus der Art und Weise, wie Ansible auch an anderen Stellen funktioniert. Der Admin ruft in einer Rolle oder einem Playbook also ein Modul auf und legt mittels der Aufrufparameter die Details fest. Beim Anlegen eines VPCs über das entsprechende »ec2«-Modul wäre das beispielsweise der Name des Netzwerks so wie der zu nutzende Adressraum für IP-Adressen. Unter der Haube wandelt Ansible sämtliche angegebenen Parameter dann in einen oder mehrere AWS-API-Aufrufe um und schickt sie in der angegebenen Reihenfolge direkt an die entsprechenden Amazon-Dienste. Damit der Ablauf funktioniert, muss der Administrator freilich noch einen Satz Login-Daten für AWS angeben. Dasselbe gilt aber genauso für Azure und GCP. Ohne Credentials bleibt der Zugriff auf die AWS-Dienste eines Accounts so oder so vollständig verwehrt.
Ein beinahe lustiges Detail: Ansible hat auch ein »cloudformation«- sowie ein »cloudformation_info«-Modul. Das klingt doppelt gemoppelt, ist es aber nicht. Mittels des erstgenannten Moduls lassen sich Stacks in CloudFormation anlegen. Das setzt allerdings voraus, dass der gewünschte virtuelle Stack in Form eines Templates vorliegt, das CloudFormation lesen und interpretieren kann. Das zweite der beiden CloudFormation-Module gibt Informationen über einen laufenden Stack samt sämtlicher Vitalwerte aus. Wer nicht auf CloudFormation verzichten will, etwa weil es bereits ein fertiges Template für den vorgesehenen Einsatzzweck gibt, kann also zumindest über Ansible dafür sorgen, dass der gewünschte Stack in AWS auch wirklich existiert und dass er bestimmten Anforderungen genügt.
Inventar inklusive
Aus der Gegenrichtung in Sachen Systemadministration kommend hat AWS übrigens noch ein weiteres sehr praktisches Modul in AWS an Bord. Es hilft dem Administrator nicht dabei, Workloads in AWS zu verwalten, sondern bereits existierende Workloads mittels Ansible sinnvoll zu automatisieren.
Wer also einen Schwarm von EC2-Instanzen für die eigenen Dienste betreibt, kann direkt über die EC2-API die darin verwendeten IP-Adressen und ihre Host-Namen laut Cloud-API herausfinden. Einer Verbindung mit den Instanzen per SSH im jeweiligen VPC steht dann nichts mehr im Weg. Hat man ein paarmal mit der Funktion gearbeitet, kommt Freude über die einfache und doch umfassende Weise auf, in der dieses Feature implementiert ist: Auf Zuruf lassen sich die vom EC2-Inventar-Plugin ausgegebenen Hosts nach spezifischen Parametern filtern oder anhand einer Blacklist aussieben.
Hier leisten die Ansible-Entwickler einmal mehr Erstaunliches: Die Möglichkeit, gängige Automatisierer auf Basis des lokalen Inventars einzusetzen, bewerben andere Hersteller mit großem Tamtam und lassen sie sich gut bezahlen.
Azure
Zwar ist AWS wie beschrieben weiter Branchenprimus, doch hat Microsoft mit Azure in den vergangenen Jahren ordentlich aufgeholt und beansprucht heute ein großes Stück des Cloud-Kuchens für sich. Dass das impliziert, auch in Lösungen wie Ansible prominent vertreten und gut integriert zu sein, liegt auf der Hand. Und tatsächlich ist es Microsoft selbst, das in Sachen Ansible-Integration mit Azure gut und viel liefert.
Die Dokumentation der Azure-Module [1] verdeutlicht das eindrucksvoll: Hier ist das Who’s Who der wichtigsten Azure-Ressourcen vollständig versammelt. Anders als bei AWS haben sämtliche Ansible-Module für Azure den Vornamen »azure_rm«, da sie bei Azure direkt an der Resource Management API andocken. Entsprechend eignet sich das Modul »azure_rm_virtualnetwork«, um virtuelle Netze in der eigenen Azure-Umgebung zu verwalten.
Dass Azure anders als AWS für Ressourcen keine Projektnamen verwendet, ist dabei Fluch und Segen zugleich. Einerseits wissen alle AWS-Entwickler und Admins sofort, was mit EC2 bei Amazon gemeint ist. Wäre hier stattdessen von Virtual Instances die Rede, wären die meisten AWS-Administratoren wohl erst einmal verwirrt. Andererseits machen die Namen bei Azure es durch ihre sprechende Eigenschaft leicht zu verstehen, worum es geht. Das klappt sogar dann, wenn man die Diktion des Anbieters nicht kennt oder zumindest nicht verwendet. Beispielsweise legt »azure_rm_mysql« eine von Azure selbst verwaltete MySQL-Instanz in Azure an. Dass der Name des Moduls exakt dessen Funktion entspricht, schließt Missverständnisse von vorneherein aus.
Funktional geben die Azure-Module sich im Alltag übrigens fast exakt so wie jene für AWS. Auch hier lassen sich die benötigten Parameter für den Aufruf einzelner API-Befehle im Azure RM als Parameter für einen Funktionsaufruf in Azure übergeben. Das bedeutet freilich auch, dass sich mit Ansible hybride Workloads in verschiedenen öffentlichen Clouds problemlos betreiben lassen. Wer also virtuelle Instanzen aus denselben Playbooks heraus sowohl in AWS als auch in Azure anlegen möchte, kann das in Ansible mit Bordmitteln erledigen, ganz ohne komplizierte und teure Zusatzsoftware.
Stellt sich schließlich noch die Frage nach einem Inventory-Plugin, um Ansible automatisiert auf alle oder eine Gruppe von Ressourcen in Azure vorhandenen VMs loszulassen. Hier gibt Azure sich aber erneut keine Blöße und liefert ein entsprechendes Plugin für das Inventar aus.
Übrigens: Sowohl für AWS [2] als auch für Azure [3] stehen Guides für neue Anwender zur Verfügung. Diese helfen laut ihren Autoren Newbies dabei, in die Verwaltung von Ressourcen in Azure oder AWS mit Ansible hineinzufinden.
GCP
Wie knapp das Rennen der Hyperscaler um die Gunst der Nutzer ist, lässt sich an der Integration in Ansible ganz gut ablesen. AWS hatte eingangs zwar die mit Abstand beste Integration in den Automatisierer, Azure zog allerdings bald nach. Klar, dass der Suchmaschinenriese Google mit dem eigenen Cloud-Angebot da nicht nachstehen möchte und selbst ordentlich zur Entwicklung der GCP-Module für Ansible beigetragen hat.
Im Ergebnis findet sich dort viel, das schon in den Modulen für Azure oder AWS vorhanden ist. Wer eine virtuelle Instanz aus Ansible heraus in GCP anlegen will, wird dabei also ebenso wenig Probleme haben wie beim Anlegen eines virtuellen Netzwerks oder dem Anlegen einer gemanagten Datenbankinstanz. Firewalls, IAM sowie Routen in den anliegenden Netzwerken lassen sich ebenso problemlos bewerkstelligen wie Checks in Googles eigenem Monitoring für die gegebenen Ressourcen. Insgesamt ist die Integration aller wichtigen GCP-Ressourcen in die gleichnamigen Module gegeben und funktioniert gut.
Da verwundert es nicht weiter, dass auch für GCP ein Inventarmodul zur Verfügung steht, mit dem sich Inventarisierungslisten für die Bearbeitung durch Ansible dynamisch erstellen lassen. Für die verschiedenen GCP-Module sowie für die Inventarisierungsschnittstelle gilt dabei in Sachen Nutzung dasselbe wie schon bei Azure oder AWS. Zunächst ruft der Administrator in einem Playbook oder einer Rolle das jeweilige Modul auf, dann gibt er die für den Aufruf nötigen Parameter an. Wie bei Azure oder AWS wird auch bei GCP die Ansible-Dokumentation ein ständiger Begleiter des Administrators sein, wenn er eine Ansible-Integration für GCP baut. Im Kopf behalten lassen sich die zahlreichen Parameter bei Ansible für GCP ebenso wenig wie jene der Konkurrenz.
Praktisch sämtliche Parameter, die bei den jeweiligen API-Aufrufen im Body der HTTP-Nachricht kodiert sein können, unterstützt Ansible sowohl bei GCP als auch bei Azure und AWS. Wer vorher nicht wusste, welche der drei Lösungen er gern einsetzen möchte, ist also auch nach dem Abwägen der Ansible-Integration nicht schlauer: Die ist für alle drei Hyperscaler auf vergleichbar exzellentem Niveau und gut in der Lage, externe Werkzeuge zu ersetzen oder überflüssig zu machen. Die Einsteiger-Handbücher beweisen das ebenso, denn es gibt selbstredend auch ein Handbuch für Neueinsteiger in Sachen GCP und Ansible.
Ab vom Schuss: OpenStack
Vor ein paar Jahren war OpenStack eine massiv gehypte Lösung für private Cloud-Umgebungen. Weil sich im Laufe der Jahre viele – auch große – Unternehmen an OpenStack versucht und verhoben haben, ist das öffentliche Tamtam um OpenStack zwischenzeitlich aber weitgehend verebbt. Erst in jüngster Vergangenheit interessieren Unternehmen sich wieder zunehmend für die Umgebung: Anders als bei den Hyperscalern ermöglicht OpenStack echte Kontrolle über die eigenen Daten und zahlt mithin auch auf das Thema der digitalen Souveränität ein, das derzeit in aller Munde ist. Zudem finden sich in freier Wildbahn durchaus OpenStack-Umgebungen, etwa die Open Telekom Cloud, die zumindest die APIs der OpenStack-Dienste unterstützt.
Da wundert es nicht, dass aus der Community heraus auch ein paar Ansible-Module für OpenStack und dessen Steuerung entstanden sind. “Ein paar” ist hier deutlich wörtlicher zu nehmen als bei AWS & Co., denn verglichen mit der Vielzahl der Module für die Steuerung der Hyperscaler bleibt die Liste der Module für Ansible und OpenStack sehr übersichtlich. Die wichtigsten Aufgaben lassen sich trotzdem erledigen.
Die stets mit dem Präfix »os_« versehenen Funktionen ermöglichen das Anlegen und Bearbeiten virtueller Netze, Speichergeräte und Instanzen (Abbildung 4). Auch Load Balancer in OpenStack Octavia kann man aus Ansible heraus als Ressource anlegen. SSH-Schlüsselpaare lassen sich in der Steuerung der Virtualisierung Nova ebenso konfigurieren wie Security Groups, die den Zugriff von außen auf virtuelle Instanzen regeln. Zusätzlich steht ein Inventory-Modul zur Verfügung, das Instanzen aus OpenStack Nova sowie aus OpenStack Ironic für die Verarbeitung in Ansible ausgibt.
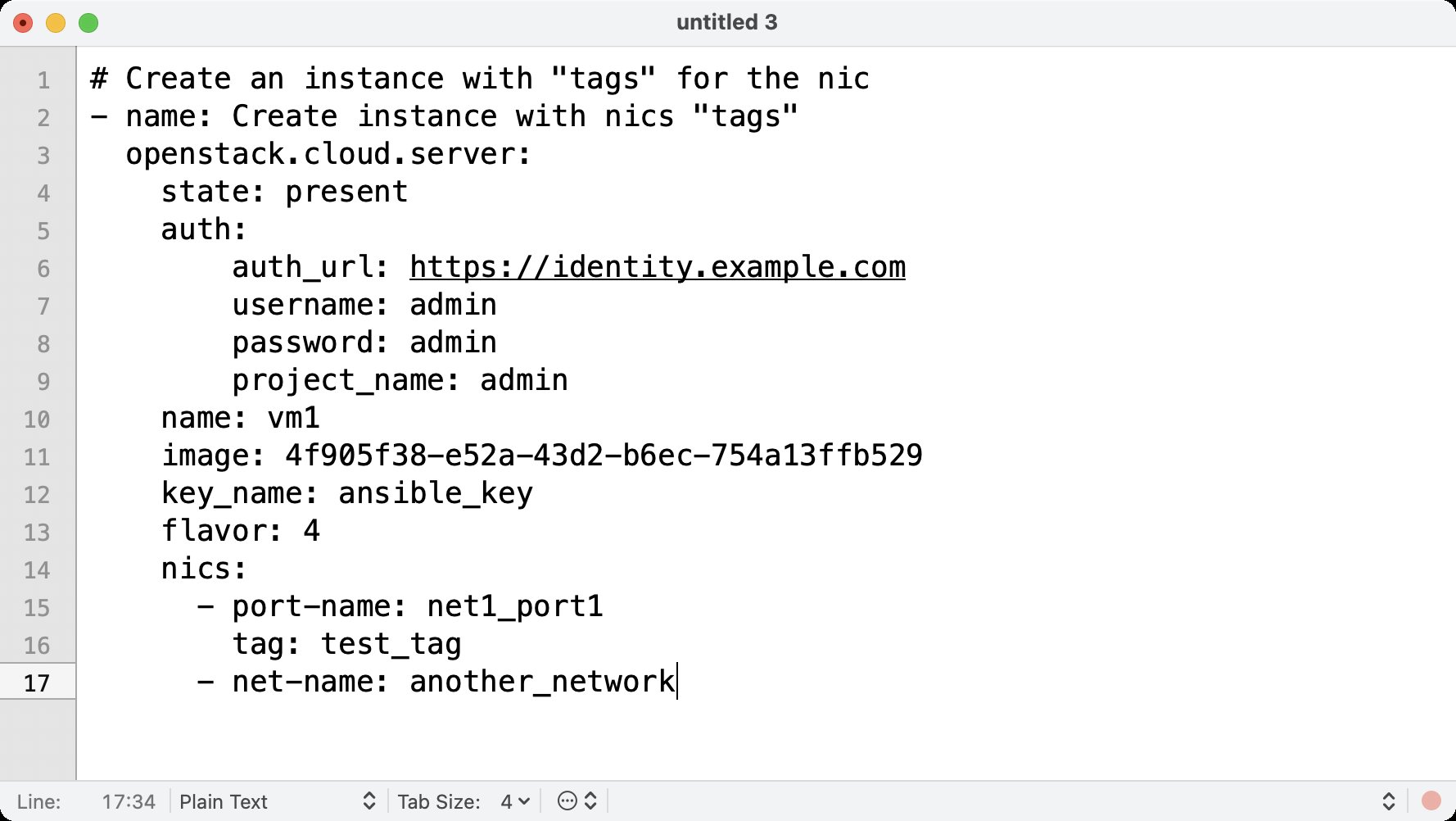
Abbildung 4: OpenStack unterstützt Ansible in Sachen Orchestrierung ebenfalls, hier beispielsweise beim Anlegen einer virtuellen Instanz.
In Sachen Parametrisierung tun die Module für OpenStack exakt dasselbe wie die anderen im Artikel vorgestellten Pendants: Über Parameter gesteuert, geben sie die entsprechenden Befehle in für OpenStack verständlichen API-Befehlen an die jeweiligen Dienste einer Plattform weiter.
Sonderfall Kubernetes
Ansible versteht sich übrigens nicht nur auf den perfekten Umgang mit den großen Cloud-Plattformen. Wie eingangs beschrieben, spielt auch Kubernetes im Cloud-ready-Zirkus der Gegenwart eine große Rolle. Anders als bei Cloud-Plattformen besteht hier aus Sicht des Administrators der große Vorteil, dass es sich bei der Kubernetes-API um eine Standard-API handelt, die grundsätzlich bei jeder K8s-Instanz identisch ausfällt. Dabei spielt es keine Rolle, ob die Instanz auf AWS, Azure, GCP oder im Rahmen eines anderen Setups läuft.
Vor diesem Hintergrund verwundert es nicht, dass Ansible auch für den Umgang mit Kubernetes fit ist (Abbildung 5), und zwar auf mehreren Ebenen: Mittels seiner K8s-Plugins kann Ansible beispielsweise Services in Kubernetes verwalten, Ressourcen einspielen oder laufende Ressourcen ändern. Hinzu kommt ein Plugin für Kubectl, mit dessen Hilfe sich aus Ansible heraus Befehle so absetzen lassen, als hantierte der Administrator selbst auf der Kommandozeile im Cluster. Wer außerdem Container mittels Ansible verwalten möchte, findet das »k8s.inventory«-Plugin. Es gibt mit etlichen Filtermöglichkeiten laufende Container aus und ermöglicht so den Zugriff auf einzelne oder alle laufenden Container und Pods.
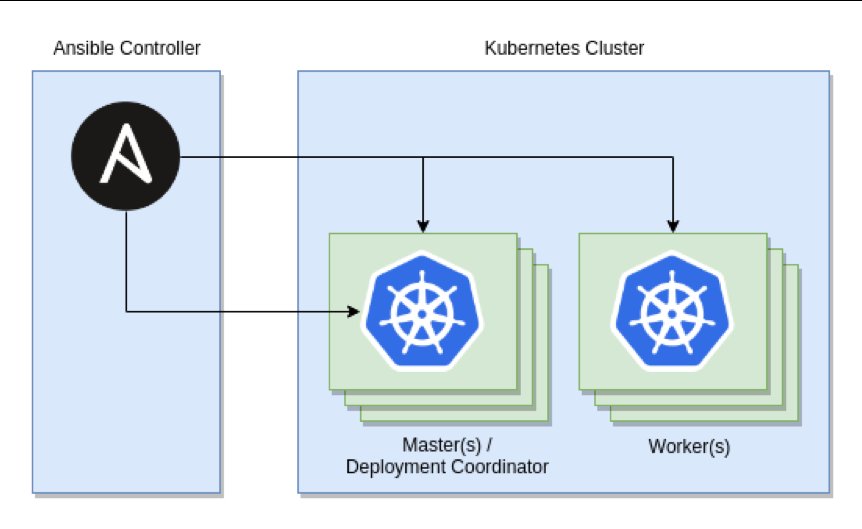
Abbildung 5: Auch Kubernetes und Ansible lassen sich gut verheiraten, wobei man aufpassen muss, nicht Orchestrierer auf Orchestrierer zu stapeln. Instanzen in Kubernetes lassen sich mit Ansible aber hervorragend administrieren. Quelle: Ansible
Fazit
Es erfordert keine Spezialwerkzeuge, Ressourcen in den großen Umgebungen zentral, reproduzierbar und idempotent zu verwalten. Wer Ansible bereits einsetzt, findet dort eine große Funktionsvielfalt vor. Das gilt sowohl im Hinblick auf Hyperscaler und private Clouds als auch auf Kubernetes. Die Bordmittel brauchen sich vor den speziellen Tools für diesen Einsatzbereich keineswegs zu verstecken.
Manche Aspekte der alltäglichen Arbeit mit orchestrierten Workloads fallen in Ansible möglicherweise etwas weniger komfortabel aus. So fehlt etwa ein Wizard, wie manche kommerzielle Lösungen ihn mitbringen, um virtuelle Setups von Grund auf zu designen. Im Gegenzug muss der Administrator sich aber auch nicht an ein spezifisches Programm und seine Marotten gewöhnen. Zudem entfällt der Lernaufwand, den viele Speziallösungen voraussetzen. Der daraus resultierende Zeitgewinn dürfte schwerer wiegen als die wenigen Punkte, die mit Ansible aufwendiger zu erledigen sind als mit einer Speziallösung. (jcb)
Infos
- AWS-Modul für Ansible: https://docs.ansible.com/ansible/latest/collections/amazon/aws/index.html
- AWS-Guide für den Ansible-Einstieg: https://docs.ansible.com/ansible/latest/collections/amazon/aws/docsite/guide_aws.html#ansible-collections-amazon-aws-docsite-aws-intro
- Azure-Guide für den Ansible-Einstieg: https://docs.ansible.com/ansible/latest/scenario_guides/guide_azure.html






