
© tsstockphoto, 123RF
Die bisherigen Teile dieser Serie haben die vielfältigen Möglichkeiten der Indexierung von Fachartikeln mit dem Open-Source-Suchserver Datafari gezeigt. Nun hat der Solr Data Import Handler seinen Auftritt.
Verschiedene Varianten der Solr Update Handler halfen in den vorherigen Artikeln der Reihe dabei, mit dem Open-Source-Suchserver Datafari [1] ein Artikelarchiv einschlägiger IT-Publikationen nicht nur zum Thema Linux aufzubauen. Dabei wirkte sich die richtige Konfiguration der Dokumentenverarbeitung wesentlich auf die Qualität der Suchergebnisse und deren Präsentation aus.
Eine Google-artige Volltextsuche durchforstet nun Linux-Magazin und LinuxUser. Metadaten vervollständigen die indexierten Artikeltexte. Zu ihnen zählen der Magazinname, das Erscheinungsjahr, die Ausgabe und, soweit möglich, Seitenzahlen, erweiterte Titelangaben, Rubriken und Schlüsselwörter. Alle Konfigurationsdateien und Skripte warten auf dem Listing-Server [2].
Serie: Eigene Suchmaschine mit Datafari
Teil 1: Einführung in die Suchmaschine Datafari [5]
Teil 2: Volltextsuche durch Spracherkennung optimieren [6]
Teil 3: PDFs indizieren und Metadaten verbessern [7]
Reichlich Metadaten
Besonders treue Linux-Magazin-Leser besitzen womöglich nicht nur eine der Mega-Archiv-DVDs, sondern horten auch die jährlich erscheinenden Jahres-DVDs (wie sie für Abonnenten auch dieser Ausgabe beiliegt). Diese enthalten einen kompletten Jahrgang mit Indexdateien auf Jahres- und Monatsebene. Zudem bringen die DVDs seit 2003 eine Übersicht im HTML-Format mit. Letztere zeigt pro Artikel die Links auf HTML- und PDF-Versionen an und listet den Titel, die Dachzeile, die Rubrik, ein Schlagwort und die Seite im Heft auf.
Das ist nicht nur eine schöne Navigationshilfe (Abbildung 1), sondern auch eine willkommene Metadatenquelle für die zusätzliche Dekoration der Artikel. Die lässt sich obendrein recht einfach über den XML-Parser von Xidel [3] und ein paar Zeilen XQuery erschließen. Je nach Jahrgang lautet der Dateiname »uebersicht.html« (bis 2010) oder »index_all.html« (ab 2011). Diese praktische Zugabe enthalten auch die Jahres-DVDs von LinuxUser ab Jahrgang 2014. So lässt sich derselbe Algorithmus für beide Magazine verwenden.
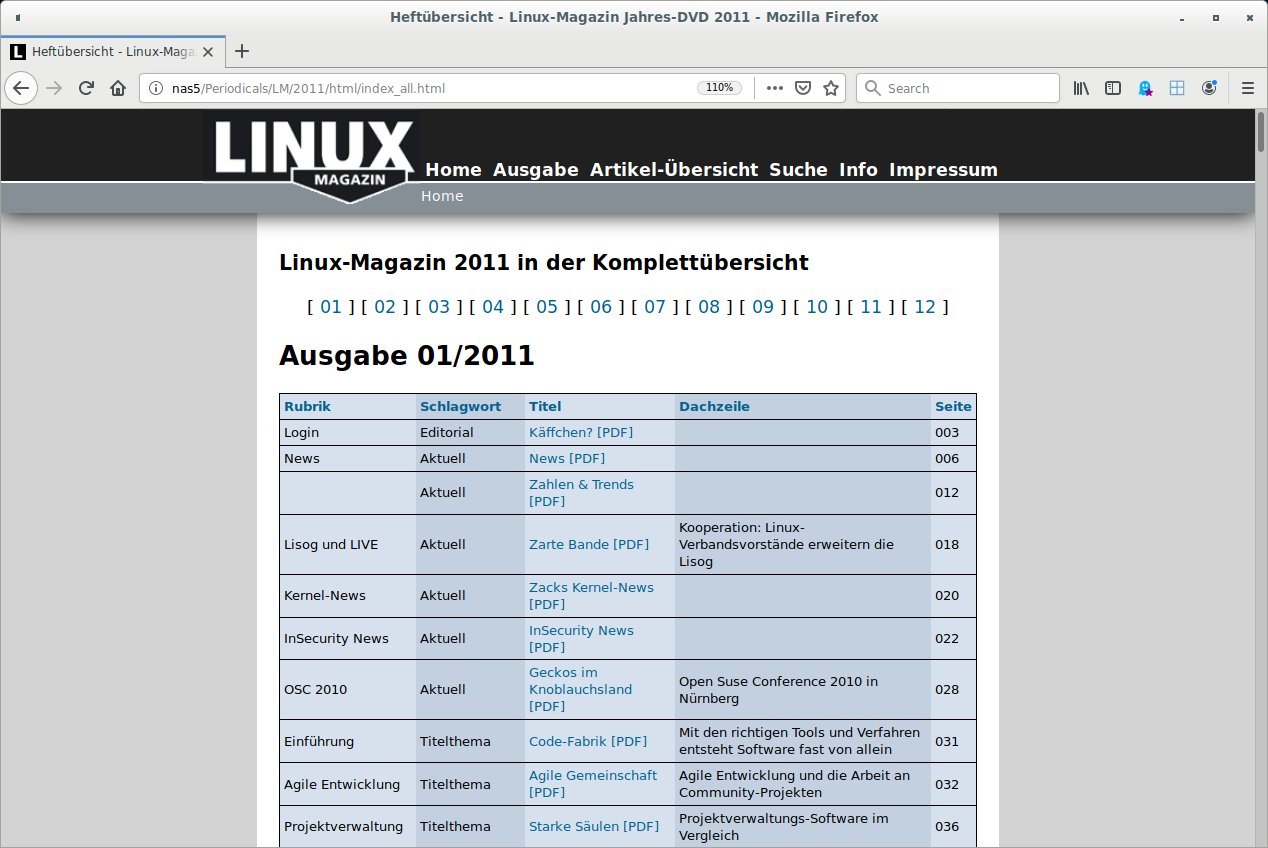
Abbildung 1: Die Heftübersicht auf der Jahres-DVD des Linux-Magazins.
Eine kleine Gemeinheit lauert allerdings im Hintergrund: Ab Linux-Magazin Jahrgang 2011 sind offensichtlich die Spalten für Rubrik und Schlagwort vertauscht. Die ältere Variante scheint korrekt zu sein, wobei sich jedoch über manche Begriffe durchaus streiten ließe. Auch die Tabellenstruktur hat sich im Laufe der Jahre etwas verändert.
Der dritte Teil der Artikelreihe stellte ein Verfahren für das englischsprachige Linux Magazine vor, um später ermittelte Metadaten mit bereits indexierten Artikeltexten zu verknüpfen. Dieses Vorgehen benötigte allerdings zwei getrennte Indexierungsläufe für die Artikeldateien und die Zusatzinformationen. Der Grund: Der Indexierungsprozess bezog die Informationen aus nur einer Datenquelle.
Wie sich das ändern lässt, zeigt der vorliegende Artikel, der den Fokus auf die Indexierung mit dem besonders flexiblen Solr Data Import Handler (DIH) legt. Zur Übersicht zeigt Abbildung 2 noch einmal die Grafik aus Teil 1 der Reihe.
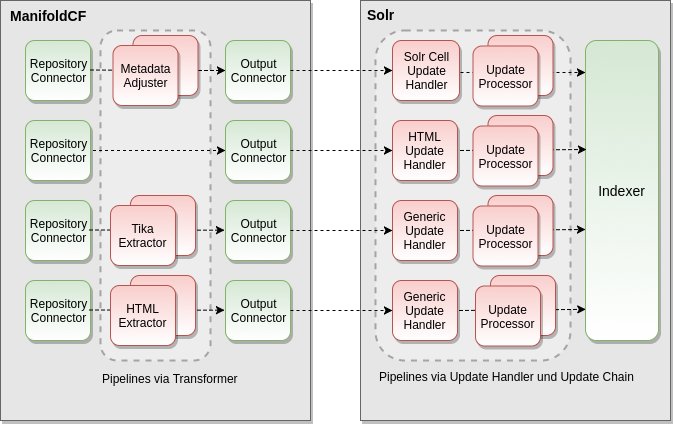
Abbildung 2: Eine Übersicht der möglichen Pipelines, um Texte in Datenquellen zu transformieren.
Data Import Handler
Der DIH unterstützt das Indexieren strukturierter Rohdaten. Die dürfen aus verschiedenen Datenquellen stammen, etwa aus Datenbanken, HTML-Ressourcen und lokalen Dateien. Der Import sieht dabei verschiedene Methoden vor, um die gewonnenen Daten zu transformieren. Dazu zählen wahlweise XSL, reguläre Ausdrücke und das Verarbeiten mit externen Skripten.
Die Datenstruktur abzubilden und die gewünschten Transformationen umzusetzen, gelingt im Gegensatz zur Definition der Prozessoren in der Solr Update Chain recht elegant und ohne unnötigen Ballast. Dennoch unterstützt DIH auch die bisher zur Transformation herangezogene Update Chain.
Der Data Import Handler besteht aus zwei JAR-Archiven (»solr-dataimporthandler-*.jar«), die in das Bibliotheksverzeichnis der Solr-Instanz (»FileShare/lib/solr/«) gehören. Allerdings liegen diese Archive der Datafari-Distribution erst ab Version 4.3 bei. Daher muss der Anwender eventuell zunächst die zu seiner Distribution passende Standalone-Variante von Solr herunterladen [4] und entpacken. Aus dem Archiv extrahiert er dann die gesuchten Dateien, die im Verzeichnis »dist/« liegen sollten.
Weiterhin benötigt der Admin die Definition des Update Request Handlers für den Import in die Solr-Konfiguration (»/update/dataimport/«). Diese Definition ergänzt er als weiteren Eintrag in der im ersten Teil beschriebenen Konfigurationsdatei »custom_request_handler.incl« (Listing 1). Das hat der Autor des Artikels bereits erledigt, das Ergebnis liegt auf dem unter [2] erwähnten Listing-Server. Die Handler-Adressen tauchen im jeweiligen MCF Output Connector unter dem Namen »DIH LM_de« und »DIH LU_de« auf. Weil die Update Chain nicht vom Magazintyp abhängt, ist sie für das Linux-Magazin und den LinuxUser identisch.
Listing 1
DIH-Deklaration in der custom_request_handlers.incl
<requestHandler name="/update/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">DIH-conf-lmde.xml</str>
<str name="update.chain">updchain_dih</str>
</lst>
</requestHandler>
Jahrgangsimport
Das bereits vorhandene Skript »upd_docs_lmen.sh« für die Artikel des Linux Magazine aus dem dritten Teil bildet mit wenigen Änderungen die Grundlage, um die Update-Anweisungen zu erzeugen. Es akzeptiert nun die tabellarischen Jahrgangsübersichten (»index_all.html« oder »uebersicht.html«) der Linux-Magazin-Ausgaben ab 2004 und der LinuxUser-Ausgaben ab 2014.
Das Skript (Listing 2) verwendet die Aufrufsyntax »add_docs.sh Index-URL«. Anders als zuvor generiert es nicht die Atomic-Update-Variante der Anweisungen, sondern die Solr-Standardsyntax für XML-Dokumente (Listing 3). Das Skript dient dazu, einen Jahrgang neu anzulegen.
Listing 2
Ausschnitt aus dem XQuery-Skript
[...]
let $rem := "dih"
let $year := replace(//title,"[^0-9]","")
let $pub := if ($year < "2007") then
substring-before(//title," ")
else if ($year < "2011") then
substring-before(substring-after(//title," « ")," ")
else
substring-before(substring-after(//title," - ")," ")
let $lh := 1
let $lp := 2
let $c := if ($year > "2010") then 2 else 1
let $h := if ($year > "2010") then 1 else 2
let $stbl := if ($year > "2010") then 0 else 4
let $srow := if ($year > "2010") then 1 else 2
for $t at $j in //table where $j > $stbl
let $issue := $j - $stbl
for $r at $i in $t/tr where $i > $srow
let $headline := functx:rtrim($r/td[4]/text())
let $href := $r/td[3]/a[$lh]/@href
let $pdf := if (ends-with($href, ".html"))
then $r/td[3]/a[$lp]/@href else $href
(: pdf page numbers are even more reliable :)
let $resource := functx:substring-after-last($pdf,"/")
let $section := $r/td[$c]/text()
let $title := $r/td[3]/a[1]/text()
let $subject := $r/td[$h]/text()
let $pageno := if (matches($resource,"^[0-9]{3}"))
then substring($resource,1,3) else $r/td[5]/text()
let $pagend := if (matches($resource,"^[0-9]{3}-[0-9]{3}"))
then substring($resource,5,3) else ""
let $section := if ($section = "TITELTHEMA") then "Titelthema" else
if ($section = "Titel") then "Titelthema" else
if ($section = "EDITORIAL") then "Editorial" else
if ($section = "Akuell") then "Aktuell" else
if ($section = "Aktuelles") then "Aktuell" else
if ($section = "Rubrik") then "Programmieren"
else $section
let $subject := if ($subject = concat("Zahlen","&","Trends")) then
concat("Zahlen ","&"," Trends") else $subject
let $link := resolve-uri($href)
where (doc-available($link))
return
<doc>{
<field name="id">{$link}</field>,
<field name="publication">{$pub}</field>,
<field name="title">{$title}</field>,
<field name="year">{$year}</field>,
<field name="issue">{$issue}</field>,
<field name="headline">{$headline}</field>,
<field name="section">{$section}</field>,
<field name="subject">{$subject}</field>,
<field name="pageno">{$pageno}</field>,
<field name="pagend">{$pagend}</field>,
<field name="comments">{$rem}</field>
}</doc>
Listing 3
Solr-Anweisungsdatei für ein Dokument
<add>
[...]
<doc>
<field name="id">[...]/LM/2011/html/01/064-066_knoppix/064-066_knoppix.html</field>
<field name="publication">Linux-Magazin</field>
<field name="title">Zehn gewinnt</field>
<field name="year">2011</field>
<field name="issue">1</field>
<field name="headline">Zum Geburtstag: Knoppix 6.4</field>
<field name="section">Software</field>
<field name="keywords">Knoppix</field>
<field name="pageno">064</field>
<field name="pagend">066</field>
<field name="comments">dih</field>
</doc>
[...]
</add>
Kommen die Jahres-DVDs und die Mega-Archiv-DVD parallel zum Einsatz, besteht allerdings die Gefahr von Überlappungen. Identische Artikel warten dann unter zwei verschiedenen URLs im Index, denn die Suche behandelt sie wie zwei unterschiedliche Dokumente. Daher ergänzen reguläre Ausdrücke die Listen der URLs, die der Crawler auslassen soll (MCF Admin UI | List all Jobs | Edit | Exclusions), um betroffene Jahrgänge auszuschließen (etwa ».*/2010/.*«).
Zunächst prüft das Skript, ob die verlinkten Dokumente tatsächlich auf dem Webserver existieren. Die Implementierung basiert im Wesentlichen auf dem Tool Xidel und steckt in zwei XQuery-Skripten für Linux-Magazin und LinuxUser. Die zuständigen MCF-Jobs »DIH LM_de« und »DIH LU_de« erwarten die Dateien unter den vorkonfigurierten Pfaden »/var/datafari/docs/lmde/« beziehungsweise »/var/datafari/docs/lude/«. Führt der Admin das Skript aus, schreibt es eine XML-Datei pro Jahrgang ins aktuelle Verzeichnis. Die Dateien müssen dabei für den User datafari lesbar sein.
Die Ausgaben des Linux-Magazins der Jahres-DVD 2003 fallen aus der Reihe: Zwar existiert eine passend strukturierte Indexdatei, aber die Artikel gibt es nur als PDFs. Die Textextraktion via Solr Cell böte sich an, ist aber hier nicht optimal. Der HTML-Handler der Datafari-Entwickler liefert mit den HTML-Artikeln der Mega-Archiv-DVD bessere Ergebnisse. Der nachfolgende Ansatz betrifft deshalb die Jahresscheiben ab 2004.
Nach wie vor führt MCF die Indexierungsjobs aus. Es benötigt dazu wieder ein Repository-Connector-Objekt des Typs »Filesystem« mit dem konfigurierten Ablageverzeichnis für Update-Anweisungen. Zudem braucht es ein passendes Output-Connector-Objekt. Da DIH keine konkurrierenden Aufträge unterstützt, begrenzt der Admin die Anzahl der konfigurierten MCF-Verbindungen des Output-Connector-Objekts auf eine einzige (MCF Admin UI | Outputs | List Output Connections | Edit | Throttling).
Eine parallele Verarbeitung wäre unberechenbar, falls beim Import mehrerer Jahrgänge auch mehr als eine Anweisungsdatei existieren würde. Weil MCF nur indirekt beteiligt ist, verliert der Archivar mit dem Verfahren auch einen Teil der Kontrolle über die Frequenz, in der Solr die Dokumente vom Webserver abruft. Nur der Zugriff auf das lokale Dateisystem lässt sich per Throttling regulieren.
DIH bringt eine eigene Konfiguration mit, die als Parameter in der Request-Handler-Deklaration von »solrconfig.xml« steckt. Beim Experimentieren mit DIH tappen Unbekümmerte schnell in eine Falle, wenn sie die Solr-Dokumentation nicht sorgfältig lesen: DIH kann vor dem Import eine »Delete«-Suchanfrage gegen den Index absetzen. Dummerweise löscht der Data Import Handler dabei aber standardmäßig und gnadenlos den gesamten Index.
Dem steuern besonnene Anwender entgegen, indem sie den Parameter »preImportDeleteQuery« in der Konfiguration nutzen oder das Löschen mit dem Request-Parameter »clean=false« gleich komplett unterbinden. Request-Parameter lassen sich bequem im Output-Connector-Objekt definieren (Abbildung 3). Listing 4 zeigt die gemeinsame DIH-Konfigurationsdatei »DIH-conf-lmde.xml« für Linux-Magazin und LinuxUser.
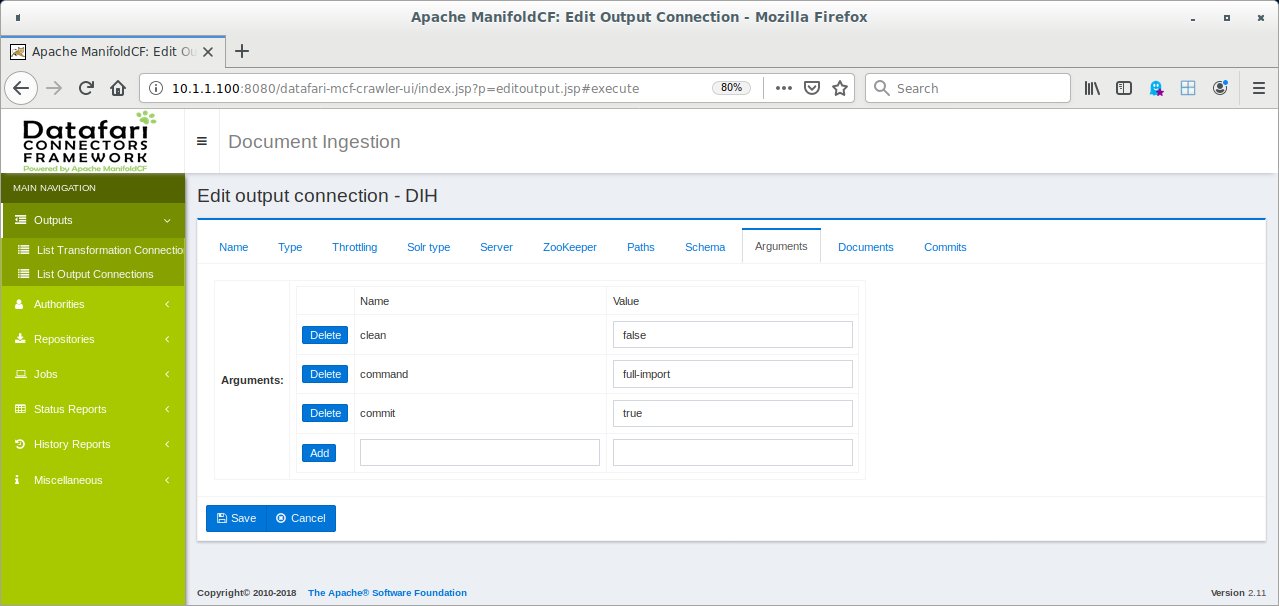
Abbildung 3: Nutzer dürfen Request Parameter im Output-Connector-Objekt festlegen.
Listing 4
DIH-Konfiguration DIH-conf-lmde.xml
<dataConfig>
<dataSource name="index"
type="ContentStreamDataSource"/>
<dataSource name="attachment"
type="BinURLDataSource"/>
<dataSource name="field"
type="FieldReaderDataSource"/>
<document>
<entity name="doc"
processor="XPathEntityProcessor"
dataSource="index? stream="true"
useSolrAddSchema="true">
<entity name="article"
processor="TikaEntityProcessor"
dataSource="attachment" url="http://$doc.id"
format="xml" htmlMapper="identity"
onError="skip">
<field column="text"/>
<field column="description"
name="description" meta="true"/>
<entity name="content"
processor="XPathEntityProcessor"
dataSource="field" dataField="article.text"
forEach="/html/body">
<field column="component_1"
xpath="/html/body/body/p"/>
<field column="component_2"
xpath="/html/body/body/p/table/tr/td/p"/>
<field column="component_3"
xpath="/html/body//h3"/>
<field column="component_4"
xpath="/html/body//h2"/>
</entity>
</entity>
</entity>
</document>
</dataConfig>
Document Processing Pipeline
Die DIH-Konfigurationsdatei deklariert die drei Datenquellen »index«, »attachment« und »field«. Die logische Dokumentenstruktur bilden »doc«, »article« und »content«.
Der Inhalt der Indexdatei (»index«) gelangt als Datenstrom zu einem »XPathEntityProcessor«, der Update-Anweisungen in Solr-Syntax direkt zu lesen vermag. Das Feld »id« speichert die URL der Artikeldatei (»attachment«), deren Inhalt der »TikaEntityProcessor« dann feldweise (»field«) in Text mit UTF-8-Kodierung sowie die restlichen Metadaten zerlegt. Dazu gehört auch der Meta-Parameter (»<meta name=”description” […] />«). Das Feld »text« enthält den Text im XHTML-Format, das ein »FieldEntityProcessor« liest, während zu guter Letzt ein weiterer »XPathEntityProcessor« die wesentlichen Textbestandteile voneinander separiert.
Die in DIH eingebaute Tika-Implementierung ähnelt der in Solr Cell. Sie gestattet es, praktisch alle gängigen Formate zu verarbeiten. Deren XHTML-Ausgabeformat eignet sich für das Weiterverarbeiten des extrahierten Texts mithilfe von XPath-Anweisungen. Allerdings bleiben im Verlauf der Textextraktion nur wenige HTML-Tags erhalten. Immerhin besteht die Möglichkeit, etwas mehr Struktur aus dem Original-HTML zu übernehmen, indem der Admin den Parameter »htmlWrapper=”identity”« setzt. Einem nachgelagerten »XPathEntityProcessor« bieten sich folglich bessere Filtermöglichkeiten.
Der Artikeltext befindet sich in verschiedenen Teilen des ursprünglichen HTML-Dokuments. Die XPath-Anweisungen extrahieren deshalb den Haupttext (»/body«), Text aus Tabellen sowie eingestreute Überschriften. Daraus bildet die Update Chain zunächst zusammen mit dem Feld »description« ein einzelnes, skalares Textfeld »content«. Dank kosmetischer Ausbesserungsarbeiten in der Update-Kette enthält das Ergebnis am Ende keine Zeilenschaltungen, Tabs oder mehrfachen Leerzeichen mehr.
Eine Merkwürdigkeit des Tika-Prozessors bedarf jedoch besonderer Beachtung: Aus unbekannten und hier nicht weiter untersuchten Gründen verdoppelt die Tika-Ausgabe das »body«-Tag zu »<body><body>«. Die XPath-Anweisungen berücksichtigen diesen Umstand.
Eine Besonderheit ergibt sich beim Lesen der XML-Anweisungen direkt aus dem Dateisystem und dem indirekten, für MCF nicht sichtbaren Zugriff auf die Artikeldatei auf dem Webserver. Startet der Admin den MCF-Job ohne Modifikation der XML-Dateien mehrfach, findet keine Neuindexierung statt, denn aus Sicht von MCF hat sich die Datenbasis nicht geändert.
In der Entwicklungsphase muss der Nutzer MCF daher immer wieder etwas unter die Arme greifen. Ein »touch« auf die XML-Dateien aktualisiert deren Zeitstempel und ebnet den Weg für eine Reindexierung. Alternativ schiebt der Anwender die Reindexierung über das MCF-Admin-UI und Outputs | List Output Connectors | View an, beziehungsweise erzwingt das Löschen der gespeicherten dynamischen Jobdaten für einen bestimmten Job.
Insgesamt profitiert das Suchergebnis nicht unerheblich von den als neue Facetten zusätzlich präsentierten Dachzeilen, Seitenzahlen, Rubriken und Schlagwörtern (Abbildung 4). Zudem verläuft der Indexierungsprozess im Vergleich zu den anderen Varianten blitzschnell.
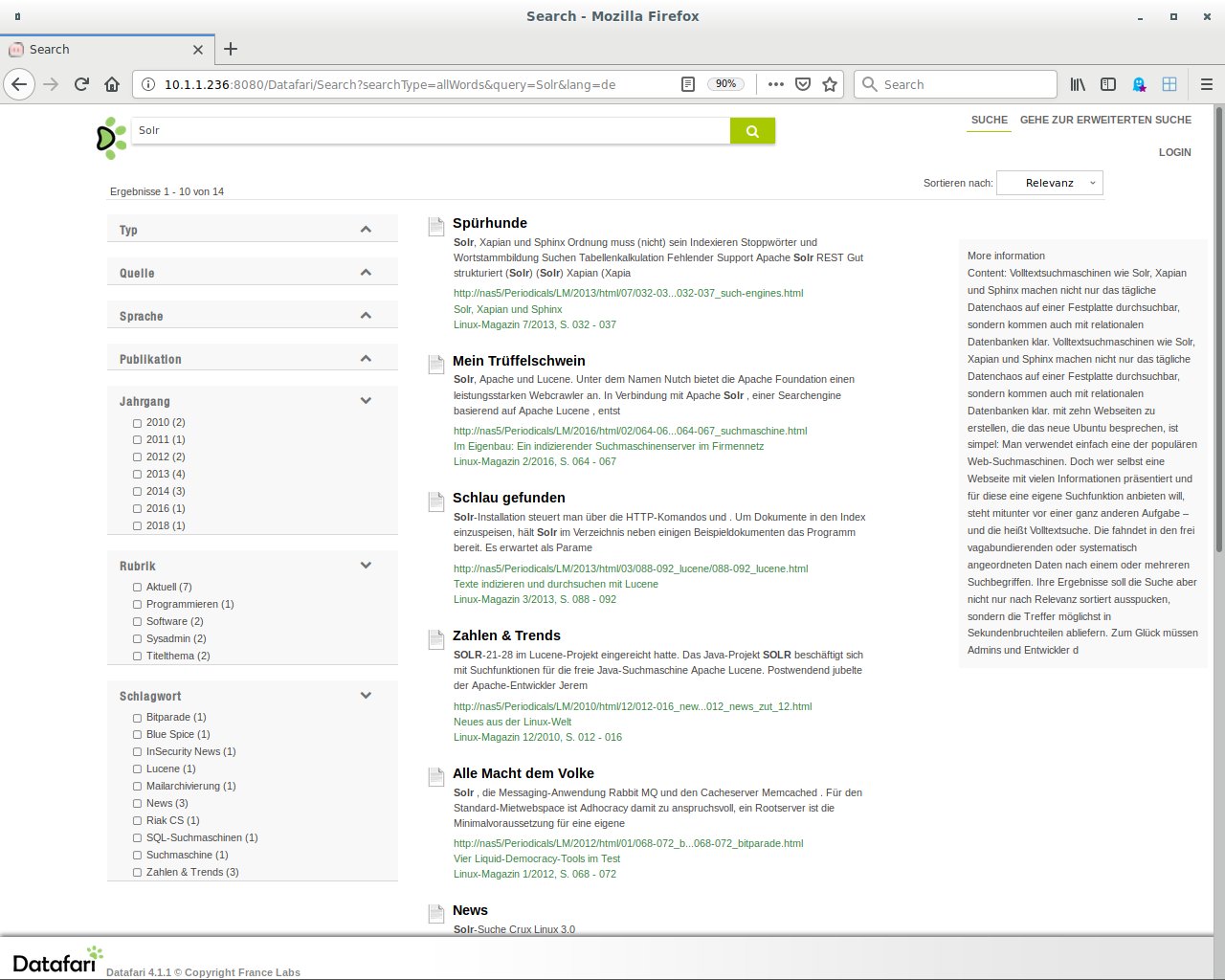
Abbildung 4: Die Suchergebnisse wurden um weitere Facetten ergänzt.
Ausbeute
Der Inhalt des Archivs kann sich am Ende mit etwa 150 000 Einzelartikeln durchaus sehen lassen und bietet die Grundlage für vielfältige Recherchen. Die Jobstatus-Ansicht (Abbildung 5) zeigt die Anzahl der indexierten Dokumente im PDF- oder HTML-Format sowie die Verarbeitungszeit pro Job.
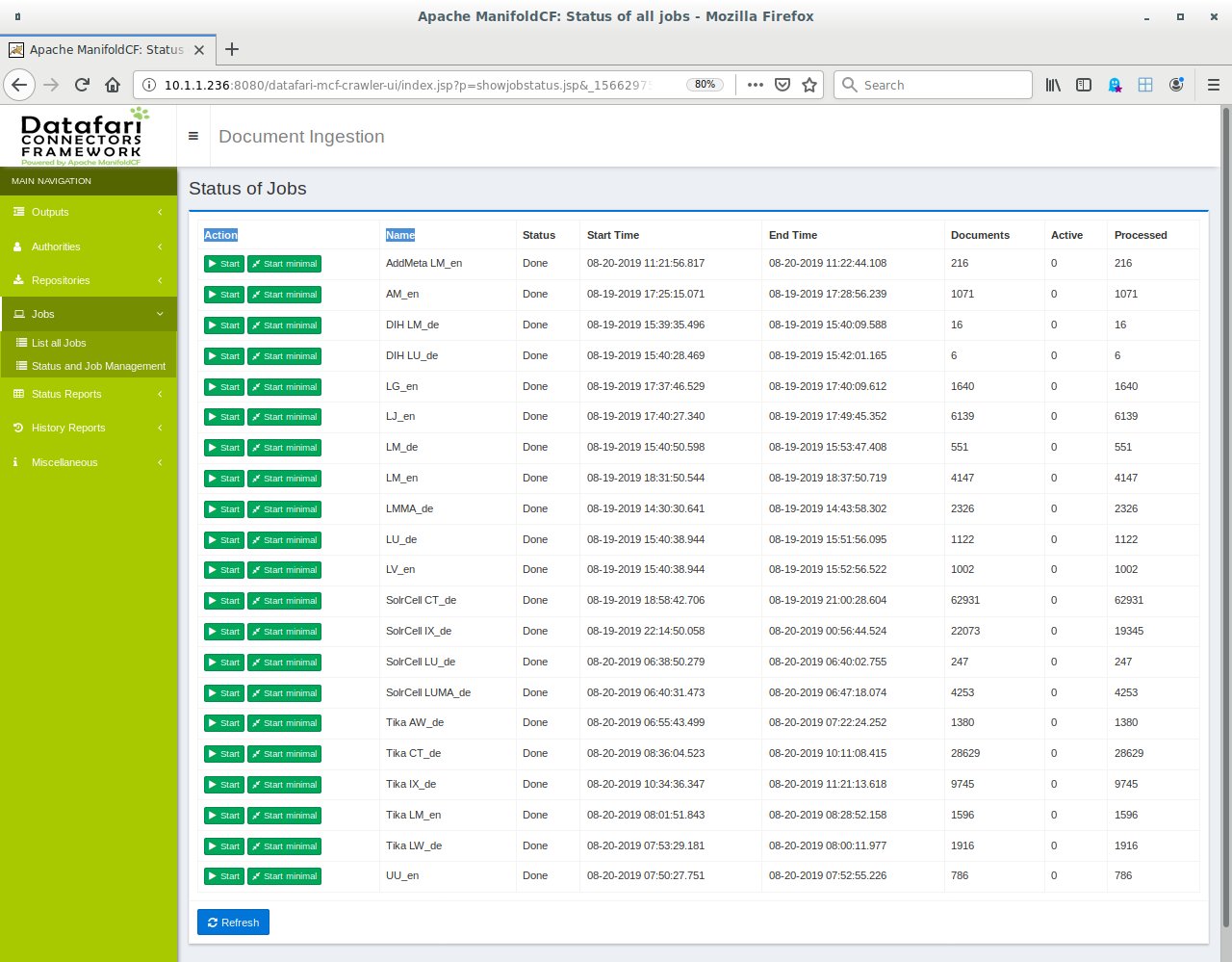
Abbildung 5: Die Jobstatus-Liste zeigt die erledigten Jobs an.
Die drei Jobs »DIH LM_de«, »DIH LU_de« und »AddMeta LM_en« lesen XML-Dateien mit den Links der Artikeldateien. Die geringe Anzahl der ausgewiesenen Dokumente täuscht daher: Sie steht für die Anzahl gefundener Jahrgänge im Repository.
Fazit
Während die Textextraktion und das Filtern eher vom Format der Artikeldateien abhängen (HTML oder PDF) und schnörkellos verlaufen, gestaltet sich das Gewinnen von Metadaten unter Umständen kompliziert. In erster Linie bestimmt dabei die Quelle der Zusatzinformationen den bestmöglichen Ansatz. Liefert die Artikeldatei alle nötigen Informationen, steht der Weg frei für gängige Standardverfahren über Solr Cell oder den Datafari-eigenen HTML-Handler.
PDFs muss der Archivar nur dann besonders vorbereiten, wenn sie mehr als einen Artikel enthalten. In diesem Fall kommt er um einen Zwischenschritt nicht herum: das Splitten der PDF in Einzelartikel [7]. PDFs bieten aber die meist willkommene Eigenschaft, Zusatzinformationen in der Datei selbst unterzubringen.
Je nach Gegebenheit ergänzt der Admin die gewünschten Metadaten pragmatisch mit einem zweiten, nachträglichen Indexierungslauf oder wählt gleich eine Methode, die mehrere Quellen parallel auswertet. Hierfür bietet der Data Import Handler nicht nur wegen der prägnanten Beschreibung der Transformationsregeln die besten Voraussetzungen. (kki)
Infos
-
Datafari: https://www.datafari.com/en
-
Alle Dateien zum Artikel: http://www.linux-magazin.de/static/listings/magazin/2020/02/datafari/
-
Apache-Solr-Downloads: http://archive.apache.org/dist/lucene/solr
-
Datafari (Teil 1): Michael Brandenburg, “Suchtrupp”, LM 11/2019, S. 62, https://www.linux-magazin.de/43403
-
Datafari (Teil 2): Michael Brandenburg, “Suchauftrag”, LM 12/2019, S. 64, https://www.linux-magazin.de/43520
-
Datafari (Teil 3): Michael Brandenburg, “Suchgeschick”, LM 01/2020, S. 54, https://www.linux-magazin.de/43529






