
© destinacigdem, 123RF
Ceph hat sich als Lösung für verteilten Speicher längst etabliert, Kubernetes lässt die Herzen von Container-Fans höherschlagen. Wie Ceph und Kubernetes dank Rook unter einen Hut kommen, zeigt dieser Artikel.
Wer sich mit Cloud-Themen beschäftigt, lebt traditionell in Hypetanien: Kein Jahr, in dem sich nicht irgendeine disruptive Technik entfaltet und bestehende Traditionen wegfegt. Das haben auch die beiden Technologien gemein, um die es in diesem Artikel geht: Ceph übernahm quasi im Handstreich den Markt der Speicherlösungen und setzte damit Hersteller wie NetApp ganz erheblich unter Druck. Kubernetes (Abbildung 1) wirbelte parallel dazu den Markt der Virtualisierungslösungen durcheinander und nahm dabei nicht nur KVM & Co. Marktanteile ab, sondern auch Branchengrößen wie VMware.

Abbildung 1: Kubernetes ist mit weitem Abstand der beliebteste Container-Orchestrierer der Gegenwart und lässt sich dank Rook bestens mit Ceph kombinieren. Quelle: Kubernetes
Wie verzweifelt etablierte Hersteller sind, zeigt sich daran, dass NetApp mittlerweile mit einer eigenen Distribution von Kubernetes auf Kundenfang geht. Zwar hebt der Hersteller darin primär die Qualitäten der eigenen Software-Defined-Storage-Lösung hervor, doch dass NetApp überhaupt eine Software-Appliance auf den Markt bringt, die noch dazu nicht auf einem eigenen Produkt basiert, wäre noch vor ein paar Jahren unvorstellbar gewesen.
Wüten zwei disruptive Technologien wie Container einerseits und Ceph andererseits im selben Markt, dann bleibt es nicht aus, dass sie aufeinandertreffen. Das Werkzeug, das Ceph und Kubernetes unter einen Hut bringt, heißt Rook: Damit lässt sich innerhalb eines Clusters mit Kubernetes eine Ceph-Installation ausrollen. Das hat ganz erhebliche Vorteile verglichen mit einem Setup, bei dem Ceph “unterhalb” von Kubernetes liegt und dieses von Ceph nichts weiß.
Der wichtigste Vorzug liegt zweifellos darin, dass ein mittels Rook [1] in den Kubernetes-Workflow integriertes Ceph über dessen Werkzeuge ebenso gesteuert und kontrolliert werden kann wie alle anderen Kubernetes-Ressourcen. Kubernetes kennt Ceph samt dessen Topologie und kann sie bei Bedarf auch anpassen. Liegt Ceph stattdessen unterhalb von Kubernetes und reicht diesem nur persistente Volumes durch, fällt die Integration weg, und das Setup wirkt unrund.
Mit Rook durchstarten
Das Linux-Magazin hat Rook vor einiger Zeit bereits ausführlich vorgestellt [2] und sich mit seinen Vor- und Nachteilen beschäftigt. Seither hat sich einiges getan: Wer sich etwa mit OpenStack auseinandersetzt, bekommt Rook dort künftig in beinahe jedem Szenario automatisch. Die OpenStack-Anbieter gehen fast alle dazu über, ihre Distributionen auf Kubernetes umzustellen, und weil OpenStack fast immer ein Ceph im Schlepptau hat, muss auch daraus ein Ceph in Kubernetes werden.
Grund genug also, sich mit Rook einmal ganz praktisch zu beschäftigen: Wie startet man damit durch, wenn man keine fertige OpenStack-Distribution hat und auch nicht will? Wie funktioniert die händische Integration? Blieb der letzte Artikel zu Rook im Linux-Magazin eher theoretisch, geht es diesmal um die ganz konkrete Praxis.
Aller Anfang: Kubernetes
Damit der Admin sich mit Rook praktisch beschäftigen kann, braucht er zuerst ein lauffähiges Kubernetes. Das muss zwar nicht viele Anforderungen erfüllen, um fit für Rook zu sein, ein paar grundlegende Notwendigkeiten gibt es aber doch.
Dieser Artikel geht nicht davon aus, dass dem Admin schon ein laufendes Kubernetes zur Verfügung steht. So haben auch solche Admins die Chance, sich dem Thema zu nähern, die bisher wenig bis gar keine praktische Erfahrung mit Kubernetes sammeln konnten. Wie üblich gilt: Kubernetes aufsetzen ist nicht kompliziert. Gleich mehrere Werkzeuge treten mit dem Versprechen an, diese Aufgabe schnell und gut zu übernehmen.
Kubernetes ausrollen
Kubernetes ist nicht annähernd so komplex wie andere Cloud-Ansätze, etwa OpenStack. Das Deployment einer Kubernetes-All-in-one-Umgebung lässt sich etwa mit dem Werkzeug Kubeadm schnell erledigen. Das folgende Beispiel geht von fünf Servern aus, die eine Kubernetes-Instanz bilden.
Wer keine echte Hardware zur Hand hat, spielt das Beispiel alternativ in VMs durch. Jedoch sei darauf hingewiesen, dass Ceph die genutzten Festplatten oder SSDs später gehörig in Beschlag nimmt. Fünf VMs auf derselben SSD, die dann einen Kubernetes-Cluster mit Rook bilden, sind also vermutlich keine gute Idee, besonders dann, wenn man von besagter SSD auch noch längerfristig etwas haben möchte. Jedenfalls gilt, dass Ceph in jedem System mindestens eine komplett leere Festplatte braucht, die es später als Datensilo in Beschlag nehmen kann.
Kubeadm nutzen
Gegeben seien also fünf Server mit Ubuntu 18.04 LTS. Im ersten Schritt bestimmt der Admin einen dieser Server zum Kubernetes-Master. Für das Beispiel verzichtet das Setup auf jede Form klassischer Hochverfügbarkeit. In einem produktiven Setup würde der Admin das freilich anders handhaben, um im Falle eines Falles nicht den Kubernetes-Controller zu verlieren.
Wichtig: Auf dem Kubernetes-Master, der im Kubernetes-Jargon Control Plane Node heißt, müssen die Ports 6443, 2379 bis 2380, 10250, 10251 sowie 10252 von außen erreichbar sein. Ferner tut der Admin gut daran, auf allen Systemen den eventuell vorhandenen Swapspace zu deaktivieren, denn sonst funktioniert der Kubelet-Dienst auf den Zielsystemen nicht zuverlässig, der für die Kommunikation zwischen Control Plane und Zielsystem sorgt.
CRI-O installieren
Um Kubernetes betreiben zu können, brauchen die Systeme des Clusters eine Container-Runtime. Bisher war das wie selbstverständlich Docker, doch das hat bekanntlich nicht nur Freunde in der Community. Eine Alternative zu Docker bietet CRI-O, das Kubernetes mittlerweile offiziell unterstützt. Um es auf Ubuntu 18.04 nutzen zu können, führt der Admin die Befehle aus Listing 1 aus. Im ersten Schritt setzt er dabei mehrere Sysctl-Variablen, im zweiten geht es an die eigentliche Installation der CRI-O-Pakete.
Listing 1
CRI-O installieren
# modprobe overlay # modprobe br_netfilter [ ... benötigte Sysctl-Parameter ... ] # cat > /etc/sysctl.d/99-kubernetes-cri.conf <<EOF net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 EOF # sysctl --system [ ... Vorbedingungen ... ] # apt-get update # apt-get install software-properties-common # add-apt-repository ppa:projectatomic/ppa # apt-get update [ ... CRI-O installieren ... ] # apt-get install cri-o-1.13
Danach startet »systemctl start crio« die Runtime, die ab sofort für die Benutzung durch Kubernetes bereitsteht. Die Schritte muss der Admin auf allen Servern vornehmen, nicht nur auf der Control Plane oder den künftigen Kubelet-Servern.
Kubernetes ausrollen
Schließlich führt der Admin die Arbeitsschritte aus Listing 2 aus, um die Kubernetes-Pakete kubelet, kubeadm und kubectl auf seine Systeme zu bekommen.
Listing 2
Kubernetes installieren
# apt-get update && apt-get install -y apt-transport-https curl # curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF # apt-get update # apt-get install -y kubelet kubeadm kubectl # apt-mark hold kubelet kubeadm kubectl
Bis hierhin hat der Admin lediglich die Komponenten geholt, die er für Kubernetes benötigt. Einen laufenden Kubernetes-Cluster hingegen besitzt er noch nicht, denn den installiert Kubeadm ja erst. Auf dem Knoten, den der Admin zur Control Plane auserkoren hat, sorgt der folgende Befehl für das Setup der benötigten Komponenten:
# kubeadm init --pod-network-cidr=10.244.0.0/16
Der zusätzliche Parameter »–pod-network-cidr« wäre eigentlich nicht nötig, doch braucht ein per Kubeadm ausgerollter Kubernetes-Cluster zwingend ein mit dem CNI-Standard kompatibles Netzwerk-Plugin – doch dazu später mehr. Wichtig ist zunächst, dass die Ausgabe von »kubeadm init« mehrere Befehle enthält, die dem Admin das Leben erleichtern.
Insbesondere den Befehl »kubeadm join« am Ende der Ausgabe sollte der Admin sich notieren, denn damit fügt er später dem Cluster weitere Knoten hinzu. Ebenso wichtig sind aber auch die Schritte, in denen der Admin in seinem persönlichen Ordner einen Ordner namens ».kube/« anlegt und darin eine »admin.conf« deponiert, die es ihm sodann erlaubt, Kubectl & Co. aufzurufen, ohne Root zu sein. Den genannten Schritt führt der Admin idealerweise unmittelbar aus, nachdem Kubeadm ihn anzeigt.
Um das Thema Netz kommt der Admin bei Kubernetes nicht herum. Zwar gestaltet sich die Angelegenheit nicht annähernd so kompliziert wie bei OpenStack, wo ja gleich eine ganze SDN-Suite zu bändigen ist, aber ein Netzwerk-Plugin wird der Admin dennoch laden müssen – Container ohne Netz ergeben schließlich keinen Sinn.
Die sicher einfachste Variante dafür ist die Verwendung von Flannel, das allerdings noch ein paar zusätzliche Schritte erfordert. Auf allen Systemen führt der Admin den folgende Befehl aus, um IPv4-Traffic aus Bridges durch Iptables zu leiten:
# sysctl net.bridge.bridge-nf-call-iptables=1
Ferner müssen alle Server in der Lage sein, über die Ports 8285 und 8462 zu kommunizieren. Anschließend lässt sich Flannel auf der Control Plane einbinden, wofür der etwas sperrige Befehl aus Listing 3 zum Einsatz kommt. Der lädt die Flannel-Definitionen gleich in die laufende Kubernetes-Control-Plane, sodass sie zum Einsatz kommen kann.
Listing 3
Flannel einbinden
# kubectl apply -f https://raw.↩ githubusercontent.com/coreos/↩ flannel/2140ac876ef134e0ed5af15↩ c65e414cf26827915/Documentation/↩ kube-flannel.yml
Kubeletes hinzufügen
Im letzten Schritt nutzt der Admin den Befehl »kubeadm join«, den »kubeadm init« zuvor generiert hat. Er führt den Befehl auf allen Knoten des Setups außer der Control Plane aus. Kubernetes ist damit bereit für den Betrieb von Rook.
Dank verschiedener Vorbereitungen seitens der Rook-Entwickler lässt Rook sich ebenso leicht in Betrieb nehmen wie Kubernetes. Vorher ist es allerdings sinnvoll, noch einmal kurz auf die grundsätzliche Architektur eines Ceph-Clusters einzugehen. Die nötigen Container mit Rook auszurollen, ist kein Kunststück; zu wissen, was passiert, hingegen schon.
Wie Ceph funktioniert
Das Linux-Magazin hat bereits etliche Male ausführlich erläutert, wie Ceph im Grundsatz funktioniert (Abbildung 2). An dieser Stelle folgt deshalb nur eine ganz kurze Rekapitulation der wichtigsten Details, damit Art und Weise des Deployments von Rook im Gesamtzusammenhang verständlich sind.
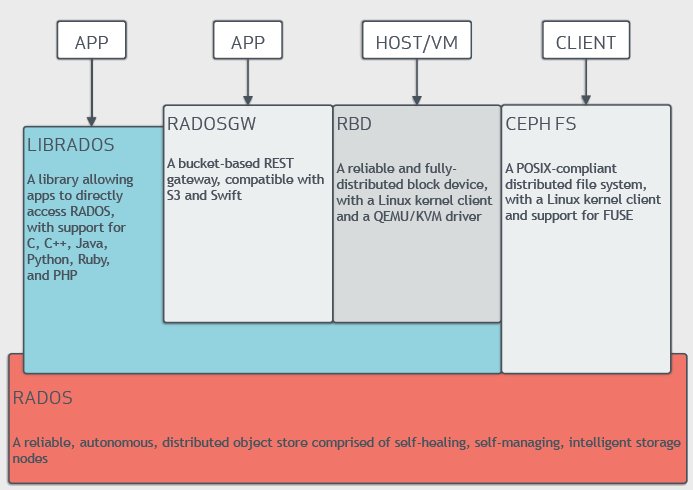
Abbildung 2: Ceph bietet verschiedene Schnittstellen an, darunter ein Block Device, eine REST-Schnittstelle und ein POSIX-Dateisystem. Quelle: Inktank
Ceph basiert auf dem Prinzip des Objektspeichers. Es behandelt daher jeden Inhalt, den ein User in Ceph hochlädt, als binäres Objekt. Solche Objekte haben den Vorteil, dass sie sich beliebig zertrennen, verteilen und wieder zusammensetzen lassen, sofern alles in der richtigen Reihenfolge passiert. Auf diese Weise umgehen Objektspeicher die Limitierungen klassischer Blockspeichergeräte, die stets untrennbar mit dem Datenträger verbunden sind, zu dem sie gehören.
Der Objektspeicher im Kern von Ceph heißt RADOS. Er kümmert sich implizit um das Thema Redundanz und multipliziert jede hochgeladene Information so oft, wie der Administrator das per Policy zuvor festgelegt hat. Obendrein verfügt RADOS über Selbstheilungskräfte: Fällt etwa eine einzelne Festplatte oder SSD aus, merkt RADOS das und legt nach einer konfigurierbaren Toleranzzeit neue Kopien der verlorengegangenen Objekte im Cluster an.
Unter der RADOS-Haube werkeln mindestens zwei Dienste: Die Object Storage Daemons (OSDs) sind die Speichersilos in Ceph. Es handelt sich um Blockgeräte, auf denen die Nutzdaten liegen. Hinzu kommen die Monitoring-Server, im Ceph-Jargon meist nur MONs genannt. Von diesen Wachhunden des Clusters müssen stets mehr als die Hälfte aktiv sein und funktionieren; auf diese Weise erlangt der Cluster sein Quorum.
Zerbricht ein Ceph-Cluster in mehrere Teile, weil etwa ein Switch ausfällt, bestünde ansonsten die Gefahr, dass es auf den einzelnen Partitionen des Clusters zu unkoordinierten Schreibvorgängen kommt. Ein solcher Split-Brain ist die totale Horrorvorstellung jedes Storage-Admins, denn er führt immer dazu, dass der Admin den gesamten Datenbestand des Clusters verwerfen muss. Danach kann er nur noch das letzte Backup einspielen.
Allerdings: Ceph-Cluster werden durch die Admins wegen ihrer schieren Größe meist gar nicht mehr komplett gesichert, sodass das Wiederherstellen aus dem Backup im Falle eines Falles auch problematisch wäre.
Sonderfall CephFS
Ab Werk bietet Ceph drei Frontends für den Zugriff durch Clients an. Das Ceph Block Device ermöglicht den Zugriff auf eine virtuelle Festplatte in Ceph (Image) so, als handele es sich um ein Blockgerät. Das geht wahlweise per Linux-Kernel-Modul RBD oder im Userland über die Librbd.
Variante 2 sieht den Zugriff per REST-Schnittstelle vor, ähnlich wie Amazons S3. Genau jenes Protokoll unterstützt die REST-Schnittstelle von Ceph, das Ceph Object Gateway, auch – neben dem OpenStack-Protokoll Swift. RBD und Ceph Object Gateway ist gemein, dass sie mit den OSDs und MONs in RADOS auskommen. Anders liegt die Sache bei Cephs POSIX-Dateisystem CephFS.
Hier wird in RADOS ein dritter Dienst benötigt, nämlich der Metadata-Server MDS. Er liest die in den Extended User Attributes der Objekte abgelegten POSIX-Metadaten aus und liefert sie in der Art eines Caches direkt an seine Clients aus.
Volle Kraft voraus
Um Rook (Abbildung 3) in Kubernetes auszurollen, sind also OSDs und die MONs nötig. Rook macht es dem Administrator hier einfach, denn dem Rook-Quelltext lassen sich die benötigten Ressourcendefinitionen in einer Standardkonfiguration entnehmen. Sie nutzen sogenannte CRDs, nämlich die Custom Resource Definitions in Kubernetes, um die lokalen Festplatten eines Systems ohne weiteres Zutun des Admins in OSDs zu verwandeln.
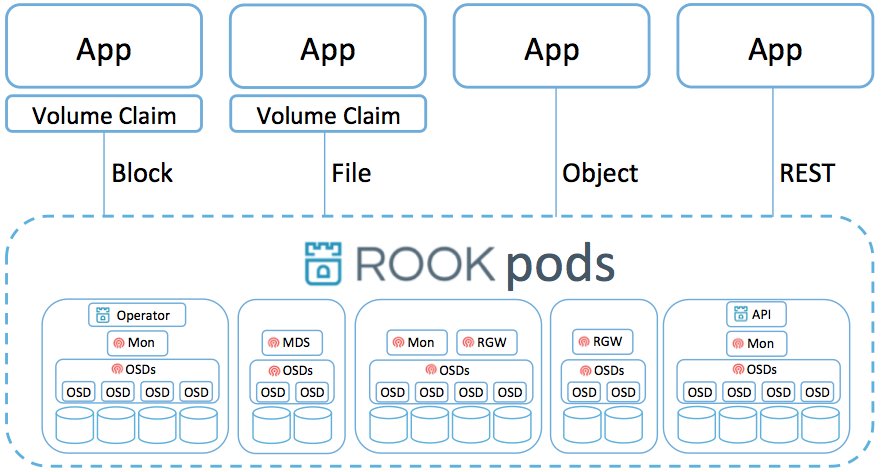
Abbildung 3: Rook liegt zwischen Ceph und Kubernetes und kümmert sich um dessen Verwaltung praktisch komplett automatisch. Quelle: Rook
Anders formuliert: Indem der Admin die vorgefertigten Rook-Definitionen aus dessen Git-Repository auf seine Kubernetes-Instanz anwendet, entsteht automatisch ein Rook-Cluster mit laufendem Ceph, der die unbenutzten Festplatten in den Zielsystemen nutzt.
Erfahrene Kubernetes-Admins haben nun vielleicht die Idee, den Paketmanager Helm zu nutzen, der in Kubernetes für das schnelle Ausrollen von Containern und Lösungen vorgesehen ist. Das scheitert aber daran, dass es von Rook für Helm nur den Operator paketiert gibt, den eigentlichen Cluster jedoch nicht. Der Administrator tut daher gut daran, zunächst das Git-Verzeichnis von Rook per Git lokal auszuchecken (Listing 4, Zeile 1).
Listing 4
Rook-Definitionen anwenden
# git clone https://github.com/rook/rook.git # cd rook/cluster/examples/kubernetes/ceph # kubectl create -f operator.yaml # kubectl get pods -n rook-ceph-system # kubectl create -f cluster.yaml
Im dabei neu entstandenen Unterordner »ceph/« (Zeile 2) existieren zwei Dateien von Bedeutung: »operator.yaml« und »cluster.yaml«. Mittels »kubectl« installiert der Admin zunächst den »operator«, der den Betrieb des Ceph-Clusters in Rook ermöglicht (Zeile 3). Mittels »kubectl get pods« lässt sich anschließend prüfen, ob das Ausrollen geklappt hat (Zeile 4): Die Pods sollten jeweils auf »Running« stehen. Dann folgt das Ausrollen des eigentlichen Rook-Clusters über die Datei »cluster.yaml« (Zeile 5).
Ein erneuter Blick sollte nun zeigen, dass auf allen Kubelet-Instanzen »rook-ceph-osd«-Pods für die dortigen lokalen Festplatten laufen. Auch »rook-ceph-mon«-Pods laufen, aber nicht auf jeder Kubelet-Instanz: Ab Werk beschränkt Rook die Zahl der »mon«-Pods auf 3, weil das als ausreichend gilt.
Rook und Kubernetes integrieren
Böse Stimmen behaupten, Cloud Computing sei in Wirklichkeit nur ein einziger, riesengroßer “layer cake”. Angesichts der Tatsache, dass Rook zwischen den Containern und Ceph eine zusätzliche Ebene einführt, ist das auch gar nicht so falsch – und um die Rook-Ceph-Installation in Kubernetes auch nutzen zu können, muss man sie erst noch in Kubernetes integrieren. Das geht unabhängig vom Speichertyp, den Ceph anbietet. Möchte man also CephFS für Storage verwenden, erfordert das andere Schritte, als wenn das Ceph Objekt Gateway zur Anwendung kommt.
Die klassische Art und Weise, Speicher zu konsumieren, sind und bleiben aber Blockgeräte, weshalb das Beispiel im nächsten Schritt von solchen ausgeht. Im Ordner, in dem der Admin sich nach dem Ausführen der obigen Schritte noch immer befindet, liegt eine Datei »storageclass.yaml«. In dieser ersetzt er die »1« bei »size: 1« durch eine »3« (Abbildung 4).
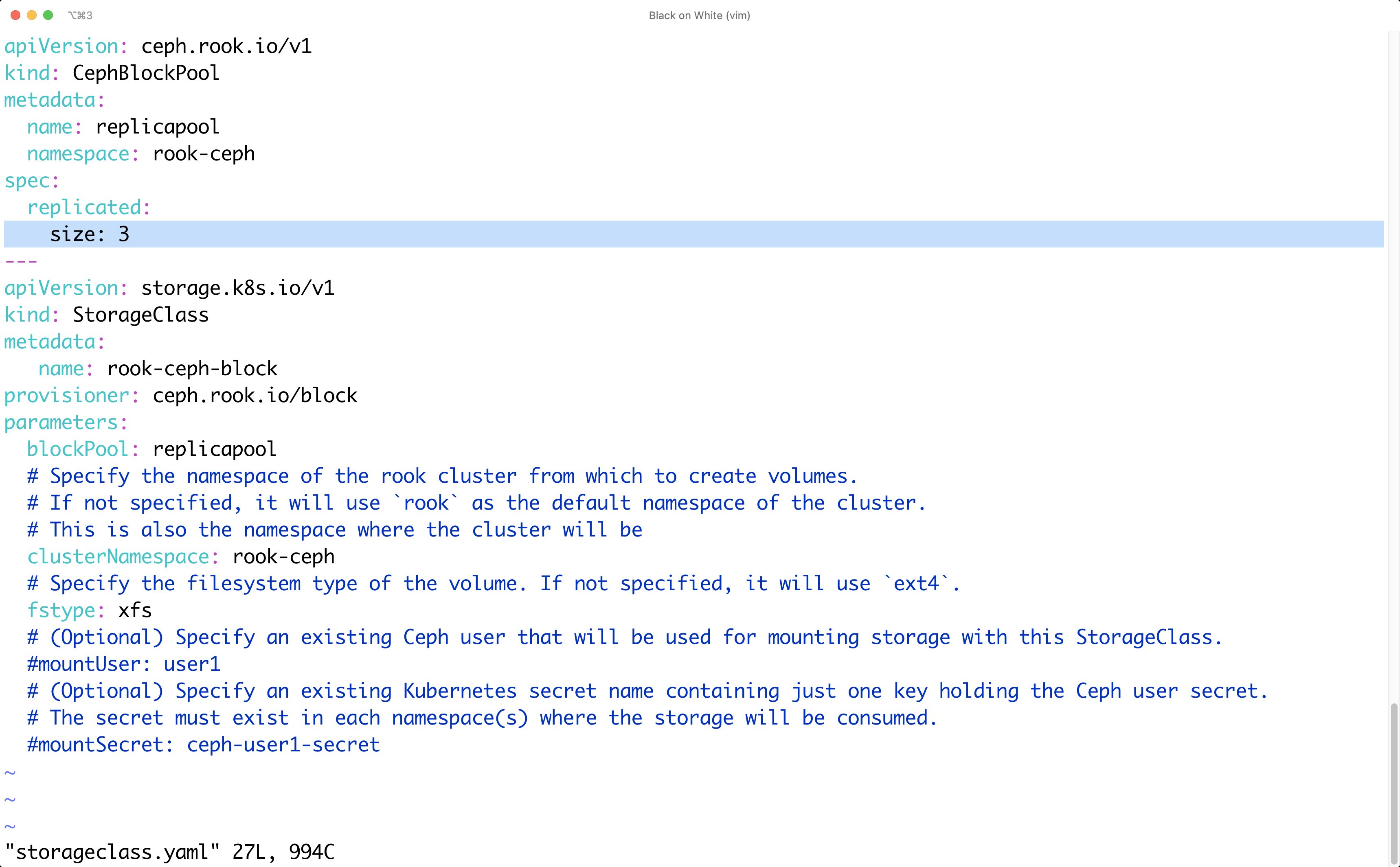
Abbildung 4: Wer eine Storage-Klasse für das Ceph Object Gateway anlegt, sollte im produktiven Einsatz die »size« auf »3« setzen.
Auf dem Umweg über Kubectl legt der Admin im nächsten Schritt einen Pool in Ceph an. Im Ceph-Jargon sind Pools so etwas wie Namensschilder für binäre Objekte, die der internen Organisation des Clusters dienen. Grundsätzlich funktioniert Ceph wie beschrieben auf Basis binärer Objekte, die jedoch sogenannten Placement Groups zugewiesen sind. Binäre Objekte, die zur selben Placement Group gehören, liegen auf denselben OSDs.
Jede Placement Group gehört zu einem Pool, und auf Pool-Ebene legt der Size-Parameter fest, wie oft jede einzelne Placement Group repliziert werden soll. Faktisch bestimmt der Admin über »size« also das Replikationslevel – »1« wäre hier unzureichend. Es bleibt schleierhaft, wieso die Rook-Entwickler den Standard»3« nicht einfach übernehmen.
Egal: Sobald die Datei angepasst ist, geht es mit »kubectl create -f storageclass.yaml« weiter. Ein »kubectl get sc -a« zeigt danach die neue Storage-Klasse »rook-block« an. Über sie hat der Admin ab sofort die Möglichkeit, sich aus dem laufenden Ceph-Cluster heraus ein Ceph Block Device zu organisieren. Das klappt per Persistent Volume Claim, wofür das Listing 5 ein entsprechendes Beispiel enthält.
Listing 5
Persistent Volume Claim für Kubernetes
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: lm-example-volume-claim
spec:
storageClassName: rook-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
In einer Pod-Definition referenziert der Admin dann nur noch auf den Storage-Claim »lm-example-volume-claim«, und schon steht ihm das Volume lokal zur Verfügung.
CephFS nutzen
Im selben Verzeichnis findet sich auch eine Datei namens »filesystem.yaml «. Die braucht der Admin, wenn er zusätzlich zum Ceph Block Device auch CephFS aktivieren möchte; die Einrichtung verläuft analog zu jener des Ceph Block Devices. Im ersten Schritt gilt es, in »filesystem.yaml« wieder die Werte des »size«-Parameters zu korrigieren, die sowohl beim »dataPool« als auch beim »metadataPool« auf »3« stehen sollten (Abbildung 5).
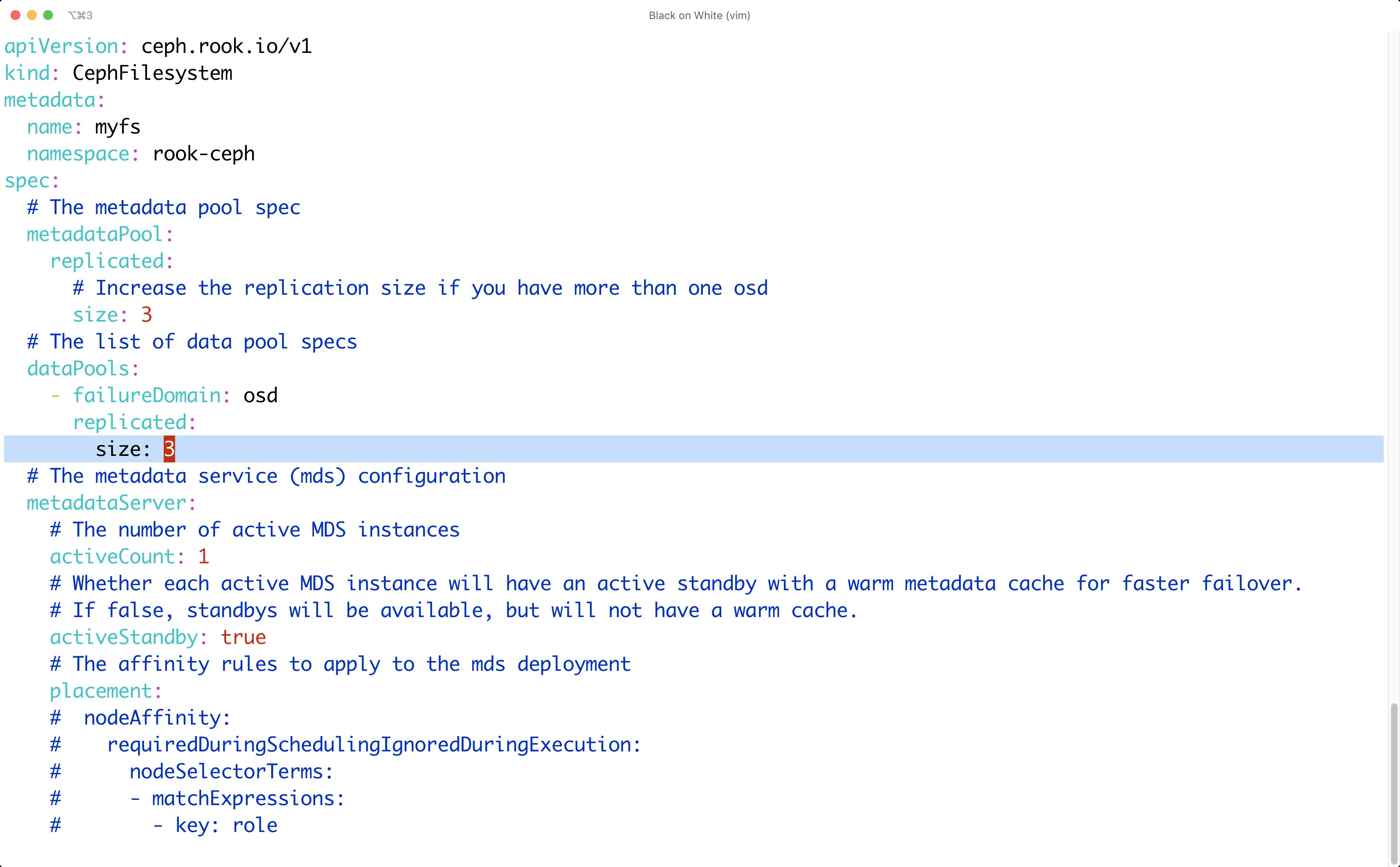
Abbildung 5: Auch beim Anlegen der Storage-Klasse für CephFS gilt, dass die in der Beispieldatei genutzte »size« von »1« für die Produktion nicht genügt.
Danach erstellt der Admin per »kubectl create -f filesystem.yaml« die Custom Resource Definition für den CephFS-Dienst. Dass nun Pods mit der MDS-Komponente von Ceph laufen, beweist anschließend ein Blick auf die Ausgabe folgenden Befehls:
# kubectl -n rook-ceph get ↩ pod -l app=rook-ceph-mds
Anschließend lässt sich CephFS wie das Block Device auch in eine eigene Storage-Klasse mappen, die dann wie gewohnt als Ressource für Kubernetes dient.
Sehen, was los ist
Wer die Arbeit mit Ceph gewohnt ist, der weiß: Es gibt diverse Werkzeuge, die dem Admin Einblick in einen laufenden Ceph-Cluster geben. Auf die muss er auch bei Rook nicht verzichten. Allerdings gilt es, einen Pod eigens für diese Werkzeuge zu starten, nämlich die Rook-Toolbox. Für die gibt es in den Rook-Beispielen ebenfalls eine CRD-Definition, die den Start der Toolbox sehr leicht von der Hand gehen lässt (Listing 6, erste Zeile). Danach verbindet der Admin sich auf der Kommandozeile mit Rook (zweite Zeile).
Listing 6
Rook-Toolbox nutzen
# kubectl create -f toolbox.yaml
# kubectl -n rook-ceph exec -it ↩
$(kubectl -n rook-ceph get pod-l ↩
"app=rook-ceph-tools" -o jsonpath↩
='{.items[0].metadata.name}') bash
Hier stehen nun die gewohnten Ceph-Kommandos zur Verfügung. Mittels »ceph status« prüft der Admin den Status des Clusters; »ceph osd status« zeigt, wie es den OSDs aktuell geht. Per »ceph df« schaut der Admin nach, wieviel Platz er noch im Cluster hat. Dieser Teil des Setups ist insofern nicht Rook-spezifisch, sondern generisch.
Ein Wort zum Container Storage Interface
Kubernetes verändert sich unverändert schnell – auch, weil viele Standards rund um Container-Lösungen gerade erst entstehen oder für notwendig erachtet werden. Seit einiger Zeit gibt es etwa mit CSI (Container Storage Interface) einen Standard für Storage-Plugins in Containern. Das CSI ist in Kubernetes mittlerweile durchgehend implementiert, doch viele User verwenden es schlicht noch nicht.
Die gute Nachricht: CSI spielt problemlos mit Rook zusammen. So liegt den Rook-Beispielen auch eine »operator-with-csi.yaml« bei, die der Admin verwenden kann, um Rook statt per zuvor erwähnter »operator.yaml« gleich mit CSI-Anbindung auszurollen. Im Ordner »ceph/csi/«in den Beispielen finden sich für das Ceph Block Device und CephFS CSI-kompatible Varianten anstelle der hier benutzten Nicht-CSI-Spielarten. Die sollte sich genauer ansehen, wer einen neuen Kubernetes-Cluster mit Rook ausrollt.
Fazit
Rook in Kubernetes bietet eine schnelle und einfache Möglichkeit, Ceph in Betrieb zu nehmen und für Container-Workloads zu nutzen. Anders als OpenStack ist Kubernetes nicht mandantenfähig, sodass der Ansatz “ein großes Ceph für alle” deutlich schwieriger zu implementieren ist als bei OpenStack. Aus diesem Grund neigen Admins dazu, viele einzelne Kubernetes-Instanzen auszurollen statt einer großen. Genau dafür eignet sich Rook hervorragend, denn es nimmt dem Admin einen Gutteil der Arbeit ab: die Pflege des Ceph-Clusters.
Mittlerweile liegt Rook in der Version 1.0 vor und gilt als reif für den Einsatz in produktiven Umgebungen. Obendrein ist es nun ein offizielles Projekt der CNCF – man darf also davon ausgehen, dass in Zukunft noch viele praktische Features hinzukommen werden. (jcb/jlu)
Infos
-
Rook: https://rook.io
-
Kubernetes mit Rook: Martin Loschwitz, “Containerspeicher”, LM 09/2018, S. 58, https://www.linux-magazin.de/ausgaben/2018/09/rook/





