
© Sergey Nivens, 123RF
Wenn in dynamischen Cloudumgebungen jeden Tag Dutzende Dienste und VMs neu entstehen und andere verschwinden, sorgt konventionelles Monitoring nicht für Betriebssicherheit, sondern für Fehlalarme.
Wohl zu Recht gilt die Cloud als eine der folgenschwersten Entwicklungen in der IT der vergangenen Jahre: Sie unterteilt die Industrie klar in zwei Gruppen, in die Anbieter und die Nutzer von Diensten. Jede Gruppe ist mit spezifischen Anforderungen konfrontiert.
Eine Anforderung betrifft das Thema Monitoring: Konventionelle Überwachung macht in einer Cloud weder die Anbieter der großen Plattformen noch deren Nutzer glücklich, denn die Besonderheit einer Cloud liegt ja gerade darin, die Ressourcen dynamisch anzubieten. Braucht der Anwender also im Moment viel Leistung, bucht er entsprechend viele VMs. Benötigt er später nur noch einen Teil dieser Ressourcen, gibt er die überflüssigen Kapazitäten in den Pool des Cloudanbieters zurück.
Jenen Pool muss der Anbieter indes sehr sorgfältig überwachen. Er muss zu jedem Zeitpunkt wissen, wie viele Ressourcen er Nutzern noch zur Verfügung stellen kann – und wann es an der Zeit ist, die Plattform in die Breite zu skalieren, indem er mehr Hardware nachrüstet.
Anderes Monitoring ist erforderlich
Sowohl aus Sicht der Anwender als auch aus der des Anbieters taugen für die Überwachung von Cloudplattformen klassische Monitoringansätze nur bedingt. Deren Sicht auf die Welt ist üblicherweise binär: Entweder arbeitet ein System oder ein Service wie gewünscht, sodass der entsprechende Eintrag im Monitoring grün ist. Oder eben nicht – dann ist der Eintrag rot, und es setzt sich eine Eskalationsspirale in Bewegung, die notfalls auch Admins aus dem Bett klingelt (Abbildung 1).
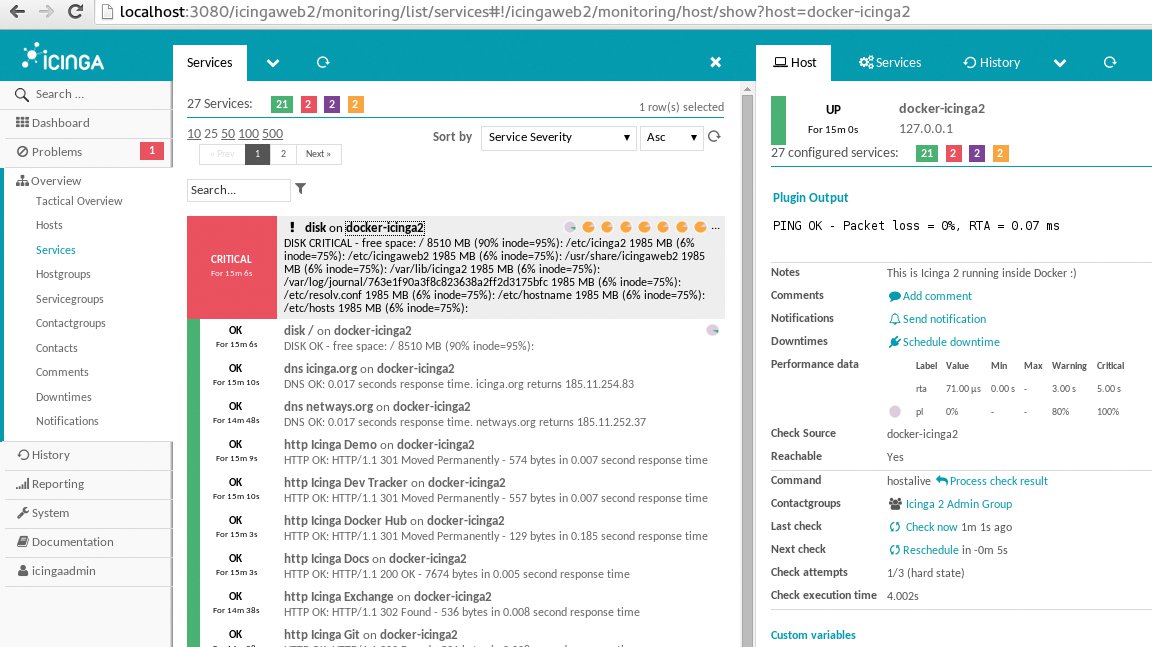
Abbildung 1: Klassische Monitoringsysteme unterscheiden zwischen “funktioniert” und “funktioniert nicht” auf Host- und Dienst-Ebene.
Dieses Prinzip reicht in Clouds nicht. Monitoring bedeutet hier auch, dass der Anbieter aus seinem Monitoringsystem regelmäßige Informationen über die Auslastung der Plattform erhält, um diese bei Bedarf zu erweitern. Anders als bei vielen klassischen Monitoringsystemen sollte das zudem leicht von der Hand gehen. Wer 200 Knoten installiert, möchte nicht stundenlang manuell die neuen Hosts in sein Monitoring einpflegen. Stattdessen ist irgendeine Art von automatischer Erkennung notwendig.
Noch radikaler ändern sich die Anforderungen ans Monitoring aus der Sicht des Nutzers: Der will nicht nur wissen, ob sein Dienst grundsätzlich noch zur Verfügung steht, sondern auch, wie hoch die anliegende Last aktuell ist. Ist der Punkt gekommen, an dem die existierenden Webserver-VMs auf dem letzten Loch pfeifen, startet die Cloudplattform im Idealfall zusätzliche VMs und integriert diese nahtlos in die bestehende virtuelle Umgebung. Sinkt die anliegende Last wieder, schaltet die Cloud im Idealfall nicht mehr benötigte VMs ab, damit dem Kunden keine unnötigen Kosten entstehen.
Hinzu kommt, dass der Ausfall einer einzelnen Komponente innerhalb einer virtuellen Cloudumgebung deren Funktion eigentlich nicht beeinträchtigen sollte. Ist das Setup richtig gebaut, überlebt es den Ausfall problemlos. Monitoring in der Cloud sollte folgerichtig nur dann Alarm schlagen, wenn ein echtes Problem aufgetreten ist, das die Funktionalität der Umgebung einschränkt. Dynamik ist auch hier das Stichwort.
Interessant ist vor diesem Hintergrund, dass Monitoring in Clouds sich auch noch in anderer Hinsicht unterscheidet: Wer Systeme nur überwachen möchte, baut das Monitoring als externe Komponente, unabhängig vom Setup selbst. In der Cloud hingegen sorgen die Ergebnisse von Monitoring-Operationen unmittelbar dafür, dass das Setup sich ändert, zum Beispiel durch neue VMs. Die klassische Sicht konventionellen Monitorings funktioniert in solchen Umgebungen also offenkundig nicht mehr, tatsächlich definieren Clouds den Begriff Monitoring zum Teil radikal um.
Wie gestaltet der Anbieter das Monitoring seiner Cloud so, dass es flexibel und dynamisch ist? Wie überwacht der Kunde seine Setups, sodass sie automatisch oder zumindest semi-automatisch in die Breite skalieren? Diesen Fragen geht der folgende Artikel nach. Im Fokus steht dabei Consul [1], das selbst Monitoringfunktionen mitbringt, sich aber auch hervorragend mit Lösungen wie Prometheus [2] koppeln lässt.
Was geht und was nicht
Zuerst ist eine eingehende Untersuchung dessen nötig, was sich in Sachen automatischer Skalierbarkeit überhaupt erreichen lässt. Die Anbieter von Clouds haben es hier leichter, denn Clouds skalieren in der Regel nur in die Breite, schrumpfen jedoch nicht mehr. Hat der Admin einen Knoten also einmal in sein Setup übernommen, geht er in der Regel davon aus, dass der Knoten dauerhaft im Setup verbleibt. Ist das aktive Monitoringsystem so konfiguriert, dass es beim Ausfall eines Systems Alarm schlägt, ist das in solchen Setups kein Problem, denn fast immer ist es aus Sicht des Anbieters ja ein Fehler, wenn ganze Server verschwinden.
Aus Sicht des Nutzers von Diensten innerhalb der Cloud kann es hingegen ein absolut legitimes Szenario sein, wenn virtuelle Maschinen verschwinden, die zuvor noch fester Teil des Setup waren. Eben dann nämlich, wenn die Cloud das Setup verkleinert, weil aktuell wenig Last anliegt. Schlägt das Monitoring in einem solchen Fall an, handelt es sich um einen waschechten Fehlalarm. Was für den Anbieter gilt, ist andererseits natürlich auch für den Cloudnutzer zutreffend. Fügt die Cloud in das bestehende System automatisch neue VMs ein, sollten diese im Idealfall automatisch auch in das vorhandene Monitoring aufgenommen werden.
Glück für Anbieter, Pech für Nutzer
Aus Sicht der Cloudanbieter ist die gute Nachricht, dass mittlerweile eine ganze Reihe verschiedener Monitoringlösungen existieren, die das Erkennen von neuen Knoten automatisch ermöglichen – mittels Autodiscovery. Weit weniger rosig sieht es durch die Nutzerbrille aus, denn Monitoring für den Einsatz innerhalb von Clouds ist fast immer auf eine spezifische Plattform gemünzt und meist ein unmittelbarer Teil davon.
Beispiel Amazon: Hier sorgt ein eigener Dienst dafür, dass sich virtuelle Setups bei Bedarf ausdehnen und wieder zusammenziehen; unter dem Namen Autoscaling vermarktet der Anbieter entsprechende Funktionalität. Außerhalb von AWS lässt sich diese aber praktisch nicht nutzen. Das Setup ist speziell an AWS angepasst und ein impliziter Teil von Autoscaling.
Ähnliches gilt für andere Umgebungen, etwa Open Stack [3]. Dort besteht für das automatische Skalieren ein eigener Dienst namens Senlin [4], der es bis heute aber nur zu einer geringen Verbreitung gebracht hat. Wer sein Setup für Open Stack und Senlin baut, kann es in Nicht-Open-Stack-Umgebungen kaum sinnvoll einsetzen.
Zum Teil ist das prinzipbedingt: Skaliert eine Cloud ein Setup, muss ein bestehendes Monitoringsystem intensiv mit den APIs jener Cloud kommunizieren, um benötigte Informationen über den gewünschten Zustand der Komponenten zu erhalten. Nur so lässt sich herausfinden, ob der tatsächliche Zustand dem Zielzustand entspricht oder ob etwa VMs im Setup fehlen, die eigentlich aktiv sein sollten. Diese Aufgabe lässt sich viel besser abwickeln, wenn die beteiligten Komponenten Teil der Cloud selbst sind.
Schlaues Monitoring mit Consul
Den Anwendern, die Monitoring für Cloudumgebungen unabhängig von den in einer speziellen Installation vorhandenen Werkzeugen realisieren will, kommt Consul zur Hilfe. Ebenso lässt sich Consul auch auf nacktem Blech für umfassendes Monitoring nutzen, es handelt sich also um eine Art Wunderwaffe für moderne, flexible Umgebungen.
Dem einen oder anderen Admin ist Consul von Hashicorp möglicherweise schon begegnet. Das in Go verfasste Programm hatte der Hersteller schon 2014 vorgestellt, es war anfangs vorrangig für den Betrieb in Clouds gedacht. Dass sich Consul auch ganz hervorragend für verschiedene Aufgaben auf physischen Servern nutzen lässt, stellte sich erst im Lauf der Jahre sukzessive heraus.
Hashicorp selbst vermarktet Consul als Werkzeug für drei zentrale Aufgaben in verteilten Umgebungen:
- Service Discovery: Consul kann als zentrale Schnittstelle zwischen Servern und Clients agieren. Erstere melden sich als Dienst bei Consul an. Über alle bei ihm registrierten Dienste führt Consul eine Liste. Clients fragen genau jene Liste bei Bedarf ab und erfahren etwa, unter welcher Adresse aktuell ihr Server erreichbar ist.
- Health Checking: Consul überprüft selbstständig, ob die Server, die sich bei ihm angemeldet haben, tatsächlich noch funktionieren. So verhindert Consul, dass es etwa einem Client die Adresse einer MySQL-Datenbank nennt, die aktuell nicht aktiv ist.
- Key-Value-Speicher (KV): Consul unterhält auch eine Konfigurationsdatenbank nach dem Key-Value-Prinzip, in die Clients beliebige Einträge einfügen dürfen. Weil Consul ein Clusterdienst ist, von dem eine Instanz im Idealfall auf jedem System des Setup läuft, stehen sämtliche Informationen des Key-Value-Store zu jedem Zeitpunkt auf allen Systemen der Plattform zur Verfügung.
Mit Blick auf seine Architektur bietet Consul mehrere Vorteile: Natürlich enthält Consul einen Cluster-Konsens-Algorithmus, der automatisch ein Quorum implementiert und so Split-Brain-Situationen gar nicht erst entstehen lässt. Das ist besonders für den KV-Speicher wichtig.
Darüber hinaus ist Consul ausgesprochen leichtgewichtig. Das Programm kommt als Go-Binary auf das System, hat keine Abhängigkeiten im Gepäck und braucht lediglich eine Konfigurationsdatei. Damit lässt sich Consul auch auf betagteren Systemen problemlos nachinstallieren, auf denen etwa aktuelle Versionen von Python oder Ruby nicht verfügbar sind. Obendrein ist Consul in Sachen Ressourcenbedarf sehr genügsam.
Der größte Vorteil von Consul besteht jedoch zweifellos darin, dass es ab Werk auf die Kooperation mit anderen Programmen ausgelegt ist. Mittels einer Restful-Schnittstelle lassen sich viele Informationen aus Consul beziehen. Als Bein in der alten Welt bietet Consul zudem die Option, Konfigurationsdateien auf Basis von Informationen etwa aus dem eigenen Service Directory zu generieren.
Tatsächlich lässt sich mit Consul also jene neue Art Monitoring realisieren, die in dynamischen Umgebungen nötig ist. Das sollen zwei Beispiele erläutern: Einerseits geht es um das Monitoring von Hardware, andererseits um das Monitoring dynamischer Umgebungen in der Cloud.
Konventionelles Monitoring
Beim Arbeiten mit echter Hardware ist eine der interessantesten Fragen, wie der Admin eine größere Anzahl neuer Server möglichst schnell ins bestehende Monitoringsystem integriert. Weil Clouds sehr dynamisch sind, wären 500 neue Server, die in Wochenfrist ins Setup integriert sein wollen, keine Besonderheit.
Klassische Ansätze wie Icinga oder Nagios halten dabei nur schwer Schritt. Bei ihnen muss der Admin etwa mit einer Automatisierungslösung wie Ansible oder Puppet nachhelfen. Consul nimmt ihm diese Arbeit ab, indem es die Funktionen der Software geschickt miteinander kombiniert.
Consul auf allen Systemen
Um Consul in physischen Setups einzusetzen, sollte der Admin den Dienst im ersten Schritt auf allen beteiligten Systemen ausrollen. Das erfolgt am besten mit Hilfe einer Automatisierungslösung wie Ansible. Consul kennt zwei unterschiedliche Betriebsmodi: jenen des Servers und den des Agent. Im Alltag unterscheiden sich die beiden Betriebsmodi vorrangig dadurch, dass die Server über das Quorum entscheiden und den Konsensalgorithmus ausführen, während die Agents sich bevorzugt um sich selbst kümmern. In Clouds findet sich fast immer eine Kategorie von Servern, die als Controller viele Dienste der Cloud betreiben – sie sind auch für die Rolle als Server in Consul wie geschaffen. Die normalen Compute-Knoten hingegen arbeiten nur als Agent.
Bereits das simple Ausrollen von Consul auf allen Systemen führt dazu, dass in Consul eine umfassende Datenbank aller verfügbarer Clusterknoten entsteht. Wie es von hier aus weitergeht, hängt auch mit den persönlichen Vorlieben des Admin zusammen. Die einfachste Variante besteht darin, Consul selbst prüfen zu lassen, ob bestimmte Dienste verfügbar sind oder nicht.
Variante 1: Consul für Service-Monitoring
Aus Sicht des Admin ist es nicht kompliziert, in Consul einen Dienst in die Dienstdatenbank zu integrieren. Ein simpler Befehl an das Consul-API ist ausreichend. Alternativ lassen sich Dienste direkt auf den Hosts in Form von Konfigurationsdateien für Consul hinterlegen. Möchte der Admin Consul etwa mitteilen, dass auf den Controllern auf Port 5000 Keystone läuft, also die Open Stack-Authentifizierungs-Komponente, reicht dieser Shellbefehl:
echo '{"service": {"name": "keystone", "tags": ["auth"], "port": 5000}}' | sudo tee /etc/consul.d/keystone.json
Anschließend genügt es, den Consul-Agent auf dem jeweiligen Host neu zu starten – schon kennt Consul für diesen Host den Keystone-Dienst. Clients können vorhandene Dienste des Verzeichnisses wahlweise via DNS-Anfrage oder via Restful-Request direkt bei Consul in Erfahrung bringen.
Will der Admin diese Konfiguration um Monitoring erweitern, hat er dafür mehrere Optionen: Zur Verfügung steht ein HTTP-basierter Check, ein Check, für den Consul beliebige externe Skripte aufruft, sowie ein klassischer Ping-Test, bei dem Consul überprüft, ob ein Dienst tatsächlich reagiert. Die Checks fügt der Admin wieder wahlweise per REST-Request oder mittels Json-Konfiguration auf dem jeweiligen System ein.
Für den beschriebenen Keystone-Prozess könnte das etwa so aussehen:
echo '{"service": {"name": "keystone", "tags": ["auth"], "port": 5000, "check": {"script": "curl localhost:5000 > /dev/null 2>&1", "interval": "10s"}}}' >/etc/consul.d/keystone.json
In der Annahme, dass Keystone auf »localhost:5000« lauscht, würde der beschriebene Check alle 10 Sekunden versuchen, die Keystone-Startseite per HTTP-Abfrage zu öffnen. Consul bietet ein eigenes Webinterface (Abbildung 2), in welchem die Ergebnisse der Monitoringabfragen aufgelistet sind. Es offeriert außerdem auch die Möglichkeit, Alarme zu definieren. Dann würde Consul eine Eskalation nach den festgelegten Regeln in Gang setzen, wobei es auch E-Mails versenden kann.
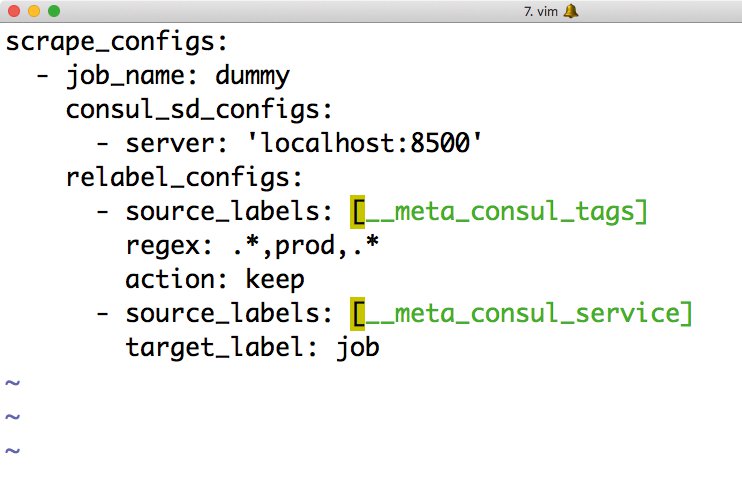
Abbildung 2: Consul bietet ein einfaches Dienstemonitoring, wer es jedoch mit echtem Blech zu tun hat, dem wird diese Detailtiefe kaum reichen.
Variante 2: Die Verbindung mit Prometheus & Co.
Ein großer Vorteil der beschriebenen Monitoringlösung allein mit Consul ist, dass sie ohne aufgeblähte Monitoringsysteme wie Icinga oder Prometheus daherkommt. Andererseits: Auf der Hardware-Ebene sind jene Systeme in der Regel ohnehin in irgendeiner Form vorhanden – meist waren sie schon vor Consul da. Da ist es durchaus sinnvoll, Consul nicht als Konkurrenz zum bestehenden Monitoring zu betrachten, sondern dieses mit Consul zu erweitern.
Prometheus etwa als Platzhirsch in Sachen Monitoring, Alerting und Trending könnte die Liste der zu überwachenden Hosts direkt aus Consul beziehen, weil dort immer die aktuelle Liste mit allen Hosts verfügbar ist. Zugleich bietet Prometheus mit seinen verschiedenen Exportern inzwischen ein viel granulareres Monitoring, als es mit Consul möglich wäre. Denn gerade bei Bare-Metal-Monitoring ist Consul oft nicht der Weisheit letzter Schluss: Wer etwa SMART-Meldungen seiner Speichergeräte überwachen möchte, erreicht das mit Consul nicht zuverlässig. Prometheus dagegen bietet einen SMART-Exporter an.
Dass die Kombination aus Prometheus und Consul attraktiv ist, das ist auch den Prometheus-Entwicklern klar: Tatsächlich kommt Prometheus mittlerweile ab Werk mit einer Schnittstelle, um an einen bestehenden Consul-Cluster anzudocken und dort die Liste der existierenden Host mitsamt deren Services zu beziehen (Abbildung 3).
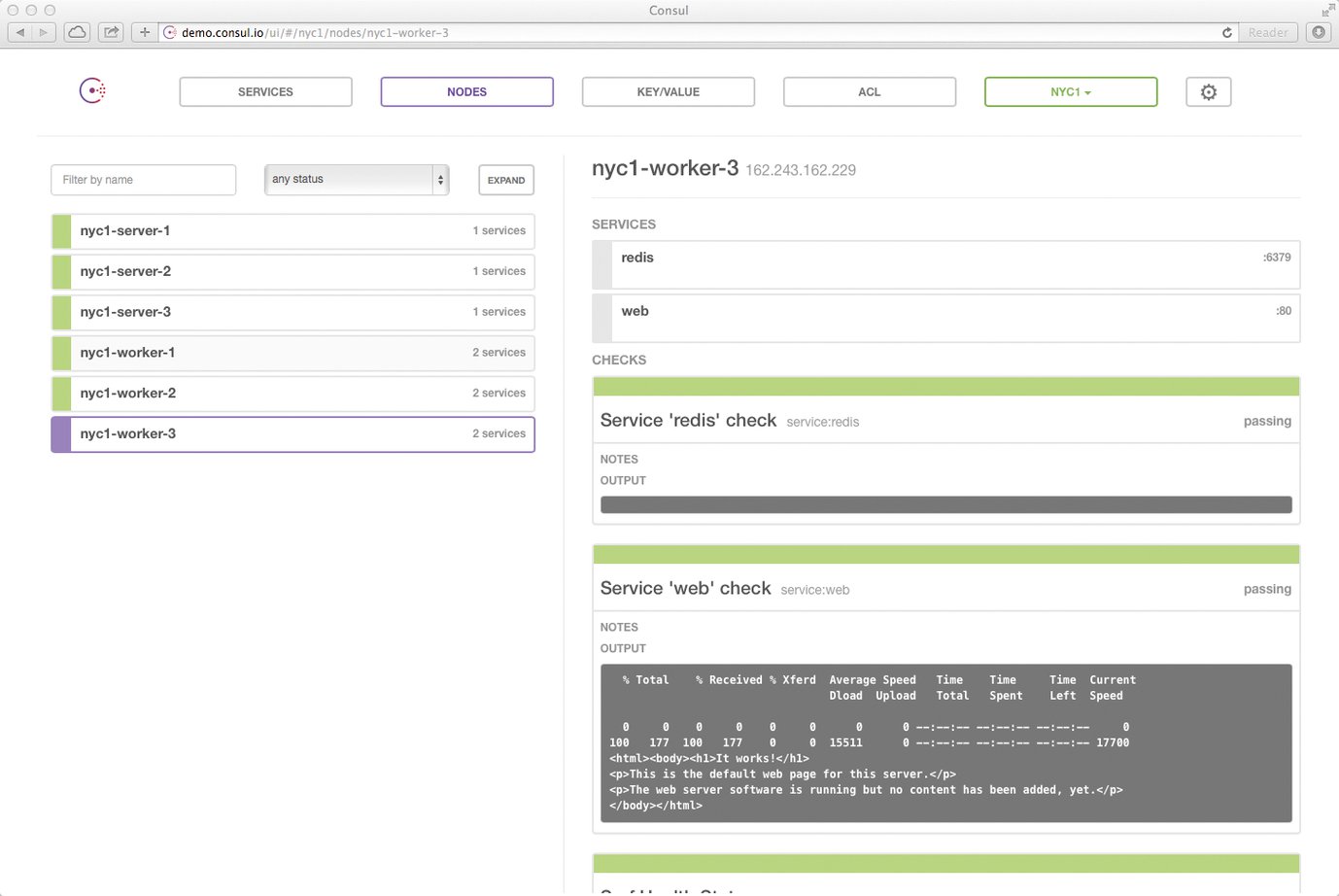
Abbildung 3: Prometheus kommt ab Werk mit einem Scraper, der nativ mit Consul reden kann.
Der Rest ist schnöde Praxis: Rollt der Admin zusammen mit Consul auf den betroffenen Hosts die Prometheus-Exporter aus, die Metriken sammeln sollen, und registriert diese als lokalen Dienst in Consul, bekommt Prometheus von Consul alle relevanten Daten und kann alle Exporter dort direkt abfragen.
Das Thema Alerting wickelt der Admin danach ausschließlich über Prometheus ab; kommen für einen Host etwa keine Ping-Metriken mehr herein, darf Prometheus Alarm schlagen (Abbildung 4). Die Kombination aus Automation, Consul und Prometheus erlaubt in diesem Szenario komplett automatisches Monitoring, denn wenn der Admin auf neuen Hosts automatisch Consul mit allen Exportern und den notwendigen Servicedefinitionen ausgerollt hat, ist der Host ein valides Monitoring-Ziel für Prometheus.

Abbildung 4: Der Alertmanager von Prometheus kümmert sich in diesem Gespann um die Alarmierung.
Wer statt Prometheus lieber ein klassischeres Monitoringsystem verwendet, sitzt auch nicht auf dem Trockenen: Mit Hilfe der Consul-Template-Funktion kann Consul auch Dateien im lokalen Dateisystem anlegen, die Details aus der Consul-Host- und Service-Datenbank enthalten. Details dazu finden sich etwa in der Anleitung unter [5]. So gelingt auch die Brücke zwischen Icinga, Zabbix oder anderen Monitoringsystemen und Consul.
Consul in der Cloud
Noch besser spielt Consul seine diversen Stärken aus, wenn es als Bestandteil von virtuellen Maschinen in der Cloud zum Einsatz kommt. Denn für diesen Use Case ist es ursprünglich entwickelt worden. Wie bereits erwähnt gelten in virtuellen Setups andere Maßstäbe im Hinblick auf Monitoring als bei nacktem Blech. Hier steht stets die Verfügbarkeit eines bestimmten Dienstes hin zur Außenwelt im Fokus, und die Verzahnung von Consul etwa mit in die Cloud integrierten Load Balancern ist das Primärziel des Administrators. Mehrere Beispiele machen das deutlich.
Zunächst spielt natürlich die automatische Erkennung von Diensten, die in Consul zum Lieferumfang gehört, eine hervorgehobene Rolle. Baut der Admin sein virtuelles Setup so, dass etwa die IP-Adresse der nutzbaren Datenbank stets in Consul hinterlegt ist, kann er seine Clients automatisch mit dieser IP reden lassen.
Das DNS-Backend von Consul spielt seine Stärken hier voll aus: Die einzelnen VMs innerhalb der Cloud nutzen dann Consul als primären Dienst für DNS-Abfragen, sodass der Admin als Zielhost für alle Datenbank-Queries einfach den Wert hinterlegt, hinter dem sich in Consul die benötigte Datenbank verbirgt.
Zumindest beim Aufbau einer virtuellen Umgebung bedeutet das allerdings Mehrarbeit: Am Anfang muss der Admin das Setup einmal durchdenken und dann zum Beispiel beim Erstellen eines Template für die Orchestrierungslösung der Cloud entsprechend umsetzen.
Dazu gehört es auch, den Datenbankdienst in Consul gleich von Anfang an mit entsprechenden Servicechecks zu versehen und die Datenbank im Hintergrund so zu bauen, dass mehrere Frontends zur Verfügung stehen – beispielsweise per Galera und Maria DB.
Consul mit externen Diensten verzahnen
Wer seine virtuelle Umgebung auf Basis von Consul perfekt hochverfügbar gemacht und gegen Ausfälle abgesichert hat, hat ein Problem aber noch immer nicht gelöst: Jenes der nahtlosen Skalierbarkeit. Auch das ist nicht unmöglich, bedingt an verschiedenen Stellen aber möglicherweise ein Umdenken.
Viele Clouds bieten Load Balancing as a Service (kurz LBaaS) an. Das ist einerseits praktisch, weil sich der Cloudarchitekt selbst nicht mehr um den Load Balancer kümmern muss, sondern die Cloud diesen komplett automatisch provisioniert und zur Verfügung stellt. Andererseits ist bei einem solchen Setup aber üblicherweise auch das System des Load Balancers vor den Augen des Nutzers versteckt und lässt sich nur per API konfigurieren, obwohl es sich im Hintergrund in der Regel auch nur um eine ganz normale Linux-VM handelt.
Wer Consul nutzen möchte, um ein automatisch skalierbares und überwachtes Setup zu bauen, geht hier sinnvollerweise den etwas mühsameren Weg und baut sich seinen Load Balancer als separate VM beispielsweise auf Basis von HAproxy selbst. Der Teil, der bei entsprechend hoher Systemlast automatisch neue VMs startet, liegt dabei weiterhin bei der Cloud.
Doch wenn die neu gestarteten VMs etwa mit den zusätzlichen Webfrontends automatisch Teil des Consul-Clusters werden, dann lässt sich – wie etwa [6] ausführlich beschreibt – HAproxy mittels der Consul-Template-Funktion so bauen, dass es neue VMs automatisch in den Load Balancer übernimmt.
Der große Vorteil einer solchen Lösung liegt nun klar auf der Hand, denn ein Setup nach diesem Prinzip lässt sich in praktisch jeder beliebigen Cloud verwenden, weil es nicht auf Cloud-spezifische Funktionen angewiesen ist.
Fazit
Im Cloudzeitalter funktioniert Monitoring anders als mit konventionellen Systemen – zumindest mit Blick auf die VMs. Beim Blech verändert sich nicht so viel: Hier will der Admin noch immer wissen, wenn einzelne Server ausfallen, um schnell Gegenmaßnahmen zu ergreifen. Die Kombination aus Consul, Prometheus und Grafana bietet dafür ideale Voraussetzungen (Abbildung 5). In der virtuellen Umgebung hingegen rückt die Verfügbarkeit von Diensten viel stärker in den Vordergrund als jene einzelner Systeme.
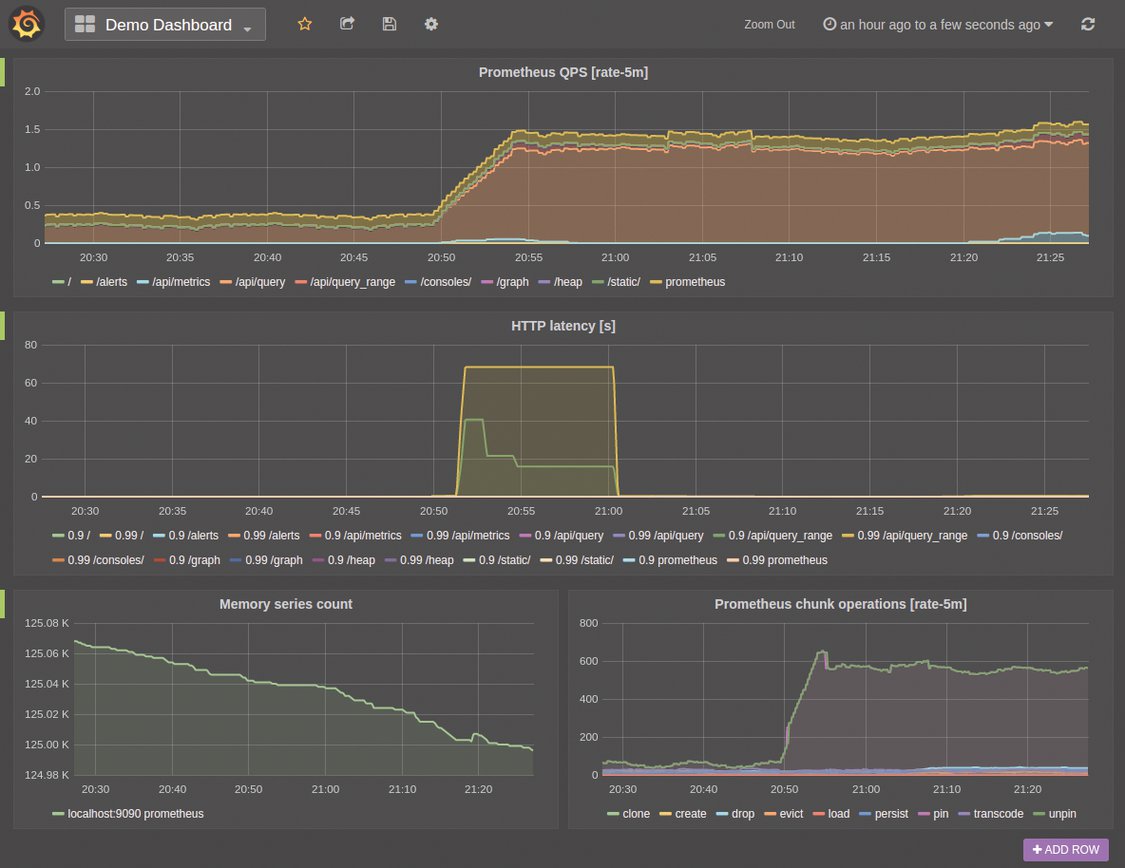
Abbildung 5: Alle in Consul eingetragenen Dienste lassen sich bequem und automatisch mit Prometheus überwachen. Die visuelle Darstellung der Performancedaten übernimmt dann Grafana. In gewohnter Weise lassen sich so Dashboards gestalten.
Consul eignet sich für beide Szenarien gut: Im Rechenzentrum ermöglicht es das automatisierte Überwachen riesiger Verbünde von Systemen bei überschaubarem Aufwand. In virtuellen Umgebungen bildet Consul das Bindeglied zwischen den virtuellen Maschinen, die Dienste betreiben, und den Nutzern, die auf jene Dienste zugreifen. Dort erlaubt es dem Admin auch Setups, die sich in beliebigen Umgebungen ausführen lassen.
Infos
- Consul: https://www.consul.io
- Prometheus: https://prometheus.io
- Open Stack: https://www.openstack.org
- Open Stack Senlin: https://wiki.openstack.org/wiki/Senlin
- Die Template-Funktion von Consul: https://github.com/hashicorp/consul-template/tree/master/examples
- Consul und HAproxy: https://icicimov.github.io/blog/devops/HAProxy-dynamic-backends-with-Consul-and-Consul-Template-in-AWS/






