
© besjunior, 123RF
Niemand kennt die kleinsten Details von 80 Prozent aller in PCs verbauten Prozessoren so gut wie Intel. Das legt den Verdacht nahe, dass die proprietäre Compilersuite des CPU-Herstellers das letzte Quäntchen Performance aus den Chips kitzeln kann. Das Linux-Magazin hat nachgemessen.
Cloud Computing mit seinen vielen Anwendern, das große Hin und Her bei Big Data sowie die gerade entstehenden Programme, die Daten aus dem IoT einsammeln und verknüpfen, lassen erahnen, was Software jetzt und künftig zu leisten hat. Entwickler solcher Lösungen müssen schauen, wie sie diese Anforderungen umsetzen können, oft müssen sie ihre Anwendungen in mehrere Threads aufteilen, oft sogar fit machen für den Lauf auf Firmen- und Netzwerk-übergreifenden Clustern.
Umfangreiche Entwicklungsumgebungen wie Eclipse oder Microsofts Visual Studio helfen den Programmieren lauffähigen und sicheren Code zu erstellen. Und dieser Code soll auch performant auf den Zielsystemen ablaufen. Aber nicht nur parallel ablaufender, effizienter Code trägt zur Verarbeitungsgeschwindigkeit bei, sondern auch die eingesetzte CPU. Was liegt also näher, als dass Prozessorhersteller ihre tiefen Kenntnisse der Prozessorarchitektur nutzen, um die Vorteile der eigenen CPUs in die Übersetzung des Codes in lauffähigen Programmcode einfließen zu lassen.
So versucht Chiphersteller Intel sich seit den 2000er Jahren durch die Entwicklung und den Vertrieb eines eigenen Compilers auch im Tools-Markt einen Namen zu machen. Das gelang auch, ein Linux-Magazin-Artikel im Jahr 2004 konnte auf mehreren Feldern Geschwindigkeitsvorteile feststellen [1]. Damals spielten dem ICC (Intel C/C++ Compiler) die automatische Vektorisierung und das Ausnutzen von Befehlssatz-Erweiterungen wie MMX oder SSE in die Karten (Tabelle 1).
| LM-Bench-Test | GCC 3.3.3 | ICC 8.0.055 | Leistungszuwachs |
|---|---|---|---|
| Datei lesen | 667353 | 641146 | +3,93 % |
| Datei lesen (Memmap) | 355139 | 332860 | +6,27 % |
| Datentransfer (Pipe) | 51251 | 46309 | +9,64 % |
| Datentransfer (TCP/IP-Socket) | 404764 | 404371 | +0,10 % |
| Datentransfer (Unix-Socket) | 61422 | 57660 | +6,12 % |
| IP-Verbindungslatenz (TCP/IP) | 8727 | 8719 | +0,09 % |
| Kontextwechsel | 166269 | 168229 | -1,18 % |
| Dateisystem (Erstellen/Löschen) | 618093 | 611237 | +1,11 % |
| Datei (Memmap/-unmap) | 77508 | 70242 | +9,37 % |
| Seitenfehler (Datei) | 1409 | 1351 | +4,12 % |
| IPC-Latenz (Pipe) | 31224 | 18243 | +41,57 % |
| Prozess-Erzeugung | 12832 | 12325 | +3,95 % |
| IPC-Latenz (Sun-RPC) | 169344 | 113342 | +33,07 % |
| Select (Datei/TCP-Verbindung) | 62676 | 60264 | +3,85 % |
| Signale (installieren/auslösen) | 53297 | 54053 | -1,42 % |
| Einfacher Systemcall | 30970 | 30466 | +1,63 % |
| IPC-Latenz (TCP/IP) | 62500 | 60700 | +2,88 % |
| IPC-Latenz (UDP/IP) | 58845 | 57982 | +1,47 % |
| IPC-Latenz (Unix-Socket) | 54854 | 47464 | +13,47 % |
Erfolge feiern dank Profile Guided Optimization
Als besonderer Trumpf gegenüber dem GCC erwies es sich, IPO (Interprocedural Optimization) mit der Profil-geleiteten ICC-Optimierung zu kombinieren. In einem dreistufigen Übersetzungsschema griff der ICC nämlich auf Informationen über den tatsächlichen Ausführungsfluss zurück, um Befehle umzuordnen und anderweitig zu optimieren.
Die Entwickler übersetzten das zu optimierende Programm mit aktivierter PGO-Instrumentalisierung (Profile Guided Optimization) und ließen es unter Realbedingungen eine Zeit lang laufen. Der Intel-Compiler erzeugte dabei so genannte PGO Segment Packets und zusätzlichen PGO-Code, der ein Profil des laufenden Programms enthielt und die PGO-Segmente zeitgesteuert in Dateien ablegte. In der dritten Phase, der Feedback Compilation, versorgt man den Compiler mit diesen Daten, der somit zielgerichtet übersetzen konnte. Mittlerweile beherrscht der GNU C-Compiler diese Techniken auch.
Diverse Produktlinien
Intel bietet seine Compiler den Entwicklern aktuell in zwei Produktlinien an. Das System Studio eignet sich laut Beschreibung insbesondere für die Entwicklung von kleineren IoT- sowie Embedded-Anwendungen. Intel Parallel Studio XE 2018 [2] hingegen richtet sich an Programmierer von Software mit vielen parallel ablaufenden Threads. Sein Einsatzgebiet liegt somit insbesondere bei Entwicklungen für einzelne Workstations, Workstation-Cluster oder verteilten Clusterumgebungen über Netzwerkgrenzen hinweg. In den drei Ausgaben Cluster Edition, Professional Edition sowie Composer Edition vertreibt die Prozessorschmiede ihr Parallel Studio.
Die drei Versionen unterscheiden sich hinsichtlich ihrer Bestandteile (Tabelle 2). So enthält die Composer Edition den C/C++-Compiler, einen Fortran-Compiler, eine (per separatem Download erhältliche) Python-Unterstützung sowie auf Intel-Prozessoren abgestimmte mathematische Bibliotheken. Zusätzliche Werkzeuge für die Leistungsprofilierung, zur optimierten Vektorisierung, zur Prototyp-Erstellung von Threads sowie Debugwerkzeuge für die Speichernutzung und Threadanalyse erweitern die Composer- zur Professional Edition.
| Edition | Composer | Professional | Cluster |
|---|---|---|---|
| Plattformen für kommerziellen Einsatz | Linux, Windows, Mac OS | Linux, Windows | Linux, Windows |
| 1 personengebundene Lizenz für Linux und 1 Jahr | ca. 700 US-Dollar | ca. 1600 US-Dollar | ca. 2950 US-Dollar |
| Kostenlos für | Studenten, Lehrkräfte (Mac OS) | Open-Source-Developer (Linux) | Studenten, Lehrkräfte (Linux, Windows) |
| C/C++, Fortran, Python, Mathlib | x | x | x |
| Vectorizing, Prototyping, Debugging | – | x | x |
| Skalierung, MPI, Diagnose | – | – | x |
Mehr oder minder massive Parallelisierung
Die Cluster Edition empfiehlt der Hersteller für massiv parallel rechnende Programme auf verteilten Systemen sowie für Workstation-Cluster. Die Edition unterstützt – ihrer Aufgabe folgend – den Message-Passing-Interface-Standard (MPI), bei dem mehrere identische Prozesse miteinander kommunizieren. Die Version enthält MPI-Bibliotheken, MPI-Analysewerkzeuge sowie Tools zur erweiterten Cluster-Diagnose.
Allen genannten Editionen gibt Intel die Fähigkeit zu Open MP (Open Multi-Processing, [3]) mit. Die seit 1997 von mehreren Hardware- und Compilerherstellern gemeinsam entwickelte Programmierschnittstelle für die Shared-Memory-Programmierung bei Multiprozessor-Computern parallelisiert Programme auf der Ebene von Schleifen, die sie in Threads separat ausführt.
Windows- und Linux-Nutzer wählen ihre bevorzugte Version unter allen drei Editionen aus. Mac-OS-Nutzern bleibt nur die Composer Edition, denn Werkzeuge für Apple-Cluster unter diesem Betriebssystem bietet Intel nicht an, und als Analysetool liefert Intel in der Mac-Version einzig den GNU Project Debugger.
Auch kostenlos zu beziehen
Außer den kommerziellen Editionen (Tabelle 2, auch nicht personengebundene Mehrplatz-Lizenzen für mehr als 20 000 Dollar sind erhältlich) bietet Intel kostenlose Lizenzen für Studenten, Lehrkräfte sowie Open-Source-Entwickler an. Umfassen die Editionen für Studenten und Lehrkräfte bei Verwendung auf Linux- und Windows-Systemen alle Komponenten der Cluster Edition und unter Mac OS die Bestandteile der Composer Edition, so entspricht die Version für Open-Source-Entwickler vom Umfang her der Professional Edition.
Gegenüber der Studenten- und Lehrkräfte-Version beschränkt sich die Edition für Open-Source-Entwickler auf eine Installation unter Linux – Programmierer für Mac-OS- oder Windows-Systeme bleiben außen vor. Für den Bezug der kostenlosen Suite muss der Open-Source-Entwickler nachweisen, dass sich sein betreutes Projekt an die Bestimmungen der Open Source Initiative hält ([4], [5]) und er dort aktiv mitarbeitet. Intel fordert zudem die Zustimmung zu den Non-Commercial-Vertragsbedingungen und -konditionen.
Nach Prüfung der Angaben erhält der Entwickler eine E-Mail mit einem Downloadlink zugesandt. Bis Mitte 2014 war Intel weniger pingelig beim Nachweis des nicht-kommerziellen Vorhabens. Zum Ausprobieren der Fähigkeiten der einzelnen Studio-XE-Varianten genügt jedoch bereits der Download der kommerziellen Free-Trial-Version. Die Tests in diesem Artikel gründen sich auf die Parallel Studio Cluster Edition 2018.
Systemvoraussetzungen
Sehr viele Linux-Distributionen besitzen die Voraussetzungen zur Installation von Parallel Studio XE. Intel führt auf seiner offiziellen Website verschiedene Ausgaben von Debian, Fedora, Red Hat, Suse sowie Ubuntu auf. Neben 2 GByte RAM schreibt Intel für die Cluster Edition mindestens 12 GByte freien Massenspeicher während des Installationsvorgangs vor, wobei die Cluster Edition nach der Installation rund 8,6 GByte belegt.
Die Software liefert Intel in einer TGZ-Datei aus. Löscht der Anwender das TGZ-Archiv zwischen Entpacken und Start der eigentlichen Installation nicht, erhöht das den notwendigen freien Plattenplatz auf mindestens 16,5 GByte. Der Installer selbst unternimmt keine Anstalten, um eigene Vorhaben und freie Kapazitäten ins Verhältnis zu setzen; verfügt das System nicht über genügend Platz, bricht der Kopiervorgang irgendwann während der Installation ab.
Eine zusätzliche Voraussetzung zum produktiven Einsatz des Compilers stellen die Kernelheader-Dateien für den aktuellen Kernel dar. Ubuntu beispielsweise lagert diese im Verzeichnis »/usr/src/linux-headers-XY/«.
Installation der Suite
Zum Installieren meldet sich der Anwender auf dem Desktop in einem Terminal an. Intel empfiehlt die Archivdatei in ein temporäres Verzeichnis zu speichern, vorzugshalber unterhalb von »/tmp/«. Der Anwender entpackt sie dort mit »tar -xvzf Datei.tgz«. Das oberste Verzeichnis des entpackten Archivs enthält das Skript »install_GUI.sh«.
Das startet der Admin per »sudo« oder nach dem Wechsel in den Administratormodus mit »sudo su«. Der sich nun auf dem Desktop entfaltende Installer führt durch den Installationsprozess. Da Ubuntu keine IA-32-Bibliotheken mehr mitbringt, wählt der Anwender in diesem Fall die Intel-Compiler-Unterstützung für diese Architektur im Installer ab (Abbildung 1). Der Prozess lädt während der Installation die notwendige Lizenzdatei von einem Intel-Server, was eine Verbindung zum Internet erfordert.
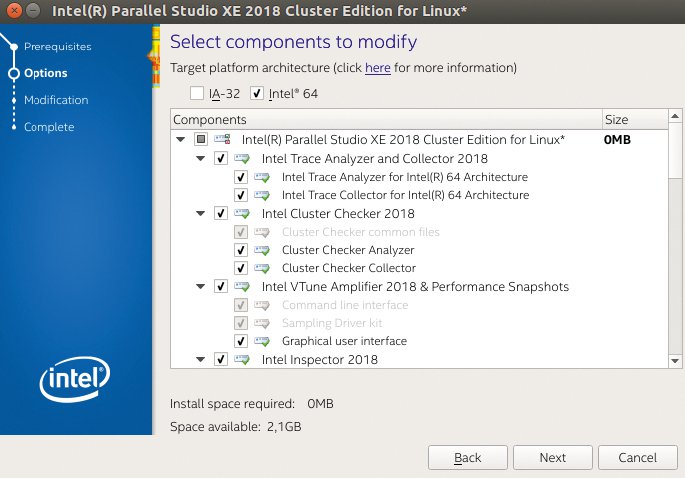
Abbildung 1: Wessen Distribution keine 32-Bit-Unterstützung hat, wählt im Installer diese Compiler-Version ab.
Nach erfolgreicher Installation versucht die Installationsroutine die “Getting started”-Seite aufzurufen. Dies schlug zumindest auf dem Referenzsystem fehl. Der Anwender findet das Dokument »getstart_clus_l.htm« bei Bedarf im Compiler-Installationsverzeichnis unterhalb von »documentation_2018/en/ps2018/«. Ungefähr 3,9 GByte verbleiben nach der eigentlichen Installation der Suite im temporären Verzeichnis; der Anwender darf die Daten ohne Bedenken löschen.
Erste Schritte
Vor dem produktiven Einsatz stellt der Anwender sein System auf den neuen Compiler ein. Das Skript, um die Umgebungsvariablen entsprechend zu setzen, befindet sich im »bin/«-Verzeichnis der Compiler-Installation. Der Aufruf erfolgt auf einem 64-Bit-System per »source compilervars.sh intel64«. Es bietet sich an, diesen Aufruf in die Datei ».bashrc« im Homeverzeichnis einzutragen, um nicht nach jedem Reboot das Skript manuell aufrufen zu müssen.
Der Anwender testet die grundsätzliche Funktionalität des Intel-Compilers am besten durch ein einfaches Programm. Das klassische “Hello World!” bietet sich hierzu an (Listing 1). Der Befehl »icc HelloWorld.c« generiert die Datei »a.out« im selben Verzeichnis. Ein Aufruf des Programms erzeugt die erwartete Meldung (Abbildung 2).
Listing 1
HelloWorld.c
01 #include <stdio.h>
02
03 main(void)
04 {
05 printf("Hello World!\n");
06 return 0;
07 }
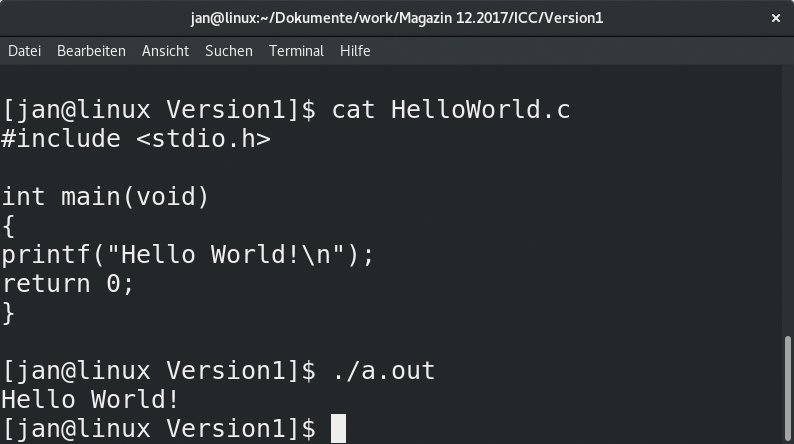
Abbildung 2: Zu erwarten: Nach der Kompilierung per ICC startet das Hello-World-Programm ohne Umstände.
Compiler bei der Arbeit
Für einen ersten Vergleich zwischen den beiden Konkurrenten GCC und ICC kann die Kernel-Kompilierung dienen, die jeden Compiler an seine Leistungsgrenze führt. Im Jahr 2004 hatte ein Linux-Magazin-Artikel [1] dies bereits mit dem damaligen ICC versucht. Letztlich gelang das Unterfangen, es waren dabei allerdings eine Menge Fallstricke aus dem Weg zu räumen und viel Kernelcode anzupassen. Mittlerweile ist der ICC ohne Vorarbeit dazu in der Lage.
Nachdem Intel 2009 einen Rechtsstreit gegen AMD verloren hatte, optimieren die hauseigenen Compiler auch Code für fremde CPUs, sofern es sich um allgemein verbreitet Prozessorfeatures handelt. In der Dokumentation steht: “Intel garantiert nicht die Verfügbarkeit, Funktionalität oder Effizienz der Optimierung für Microprozessoren, die nicht von Intel stammen.”
Die Garantie fürs letzte Quäntchen Optimierung bekommt offenbar weiterhin nur, wer eine Intel-CPU vorzuweisen hat. Ein Auszug mittels »cat /proc/cpuinfo« bringt diesbezüglich Gewissheit, mit Intel-CPUs zeigt der Parameter »vendor_id« den Wert »GenuineIntel« an – so auch in der Testumgebung (siehe Kasten “So haben wir getestet”).
Die Zeit für einen Compilerlauf sind für den erzeugten Binärcode zwar belanglos, nicht aber für seinen Entwickler. Dessen Produktivität in umfangreichen Projekten insbesondere in der Testphase können lange Übersetzungszeiten sehr schmälern, und lange Wartezeiten führen stets auch zu Frustration.
Die in Tabelle 3 ermittelten Werte für die Kompilierungszeiten eines aktuellen 4.13.5-Kernels zeigen, dass der Buildprozess für einen mit dem ICC kompilierten Kernel fast doppelt so lange dauert wie bei einem mit dem GCC gebauten Kernelimage, und zwar unabhängig vom Einsatz der »-O2«- oder »-O3«-Optimierungen. Gleiches gilt für den Bau der Kernelmodule. Dabei unterscheidet sich diese Tendenz selbst dann nicht, wenn der Build auf einem System unter einem laufenden Ubuntu-Standardkernel oder mit einem durch den GCC oder durch den ICC kompilierten Kernel stattfindet.
| Kernel des Testsystems übersetzt mit | »gcc -O2« | »gcc -O3« | »icc -O3« |
|---|---|---|---|
| »make bzImage« | |||
| Per GCC | 16:35 min | 18:15 min | 18:15 min |
| Per ICC | 28:00 min | 28:01 min | 27:03 min |
| »make modules« | |||
| Per GCC | 01:03 min | 01:06 min | 01:07 min |
| Per ICC | 01:37 min | 02:44 min | 01:38 min |
So haben wir getestet
Die Installation der Cluster Edition erfolgte auf einem Ubuntu-Desktop-System (Version 17.04), das in einer virtuellen Maschine unter VMware Fusion lief. Während der Ermittlung der Kompilierungs- und Latenzzeiten liefen in der virtuellen Maschine und auf dem Host nur die Grunddienste und keine weiteren Prozesse. Der Host verfügte über 16 GByte RAM sowie eine Intel-i7-CPU mit Hyperthreading. Der virtuellen Maschine standen zwei Kerne und 4 GByte RAM zur Verfügung (Abbildung 3).
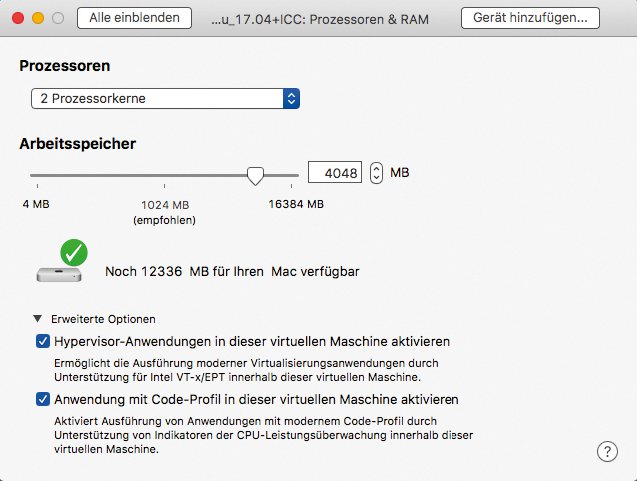
Abbildung 3: So war jede virtuelle Maschine für die Leistungstests konfiguriert.
Für jeden Kompilierungsvorgang erhielt die zuständige »Makefile«-Datei im Wurzelverzeichnis des Kernels 4.13.5 für die unterschiedlichen Testszenarien entsprechende Modifikationen. Diese betrafen bei Kompilierung eines ICC-Kernels die Variablen »HOSTCC«, »HOSTCXX«, »HOSTCFLAGS«, »HOSTCXXFLAGS« sowie »CC«. Versuche einer Code-Optimierung unter Einsatz der »-O3«-Option bedingten eine entsprechende Änderung des Flag »-O2«. Die »Makefile«-Dateien in den Kernel-Unterverzeichnissen änderten sich bei dieser Gelegenheit nicht.
Mit »make mrproper« löschten die Tester die bei früheren Kompilationen entstandenen Binaries. Die notwendige ».config«-Datei erzeugte anschließend der Befehl »make defconfig«. Eine zusätzliche Installation des »libncurses5-dev«-Pakets auf dem Linux-Gast ermöglichte es, »make menuconfig« auszuführen, um notwendige weiterer Kernelmodule zu berücksichtigen. Die Ergänzung der Konfiguration beschränkte sich jedoch auf Module, um virtuelle SCSI-Festplatten einzubinden.
Die Zeiten der Kernelkompilierung ermittelte »time make bzImage« oder ein entsprechender »time make modules«-Befehl.
Antwortverhalten des Kernels messen
Die Suche nach einem freien Benchmark, der die Performance des erzeugten Binärcodes vergleichend beurteilen kann, führte die Tester zu Open Benchmarking [6]. Die dort propagierten Leistungstests laufen innerhalb der Phoronix Test Suite [7] ab. Ubuntu hält diese Suite im Repository vor, sodass der Admin sie leicht per Paketmanager installieren kann.
Der Befehl »phoronix-test-suite list-tests« zeigt eine Liste möglicher Tests, die mit Cyclictest auch einen Benchmark zur Messung von Latenzen enthält. Latenz bezeichnet allgemein die zeitliche Verzögerung zwischen dem Auslösen eines Prozesses und dessen Auswirkung beziehungsweise dem von ihm verursachten Effekt. Die Latenz ist also ein Maß für die (möglichst gering zu haltende) Wartezeit.
Der Cyclictest misst Latenzen von Linux-Kerneln sehr präzise, weshalb ihn die Tester zum Vergleich verschiedener Kernel und somit auch der beiden Compiler heranzogen. Mittels »phoronix-test-suite install cyclictest« installierten sie zunächst den Test. Der Befehl »phoronix-test-suite run cyclictest« startete einen Benchmarklauf (Abbildung 4). Der Mittelwert eines jeden der 24 durchgeführten Testläufe gründet sich auf jeweils sechs Durchläufe. Insgesamt 24*6=144 Einzelwerte flossen so in die Ergebnisse ein. Rückschlüsse auf die Kompilierzeiten und Binärcode-Latenzen der ICC-Suite unter Windows oder Mac OS lassen diese Ergebnissen aber nicht zu.
Abbildung 4: Beispiel der Cyclictest-Latenzmessung unter einem mit dem ICC kompilierten Kernel 4.13.5.
Die Auswahl des jeweiligen Kernels erfolgte vor dem Bootvorgang im Grub-Menü. Zur Anzeige des Bootmenüs versahen die Tester in der Datei »/etc/default/grub« die Zeilen »GRUB_HIDDEN_TIMEOUT=0« sowie »GRUB_HIDDEN_TIMEOUT_QUIET=true« am Zeilenanfang mit einem Kommentarzeichen (»#«). Danach führte der Befehl »update-grub« die Konfigurationsänderungen im System durch.
Performance des erzeugten Codes messen
Nach Erzeugung der GCC- und ICC-Kernelimages ist ein Benchmark das beste Mittel, um die mit dem jeweiligen Compiler erreichbare Systemperformance zu beurteilen. Aussagekräftiger, als Datendurchsätze zu messen, ist beim Kernel, dessen Antwortverhalten mit dem Benchmark Cyclictest zu quantifizieren (siehe Kasten “So haben wir getestet”).
Die durchaus überraschenden Ergebnisse zeigt Abbildung 5 grafisch, Tabelle 4 listet noch einmal die genauen Werte. Sie verdeutlichen, dass tendenziell GCC-kompilierte Kernel geringere Latenzzeiten zeigen als mit dem ICC übersetzte – in den meisten Fällen um 20 Prozent oder weniger.
| Kernel | Ubuntu original | 4.13.5 | 4.13.5 | 4.13.5 |
|---|---|---|---|---|
| Übersetzt mit | »gcc -O2« | »gcc -O2« | »gcc -O3« | »icc -O3« |
| Testlauf 1 | 760 ms | 826 ms | 1091 ms | 1062 ms |
| Testlauf 2 | 788 ms | 845 ms | 802 ms | 1005 ms |
| Testlauf 3 | 803 ms | 801 ms | 1014 ms | 1148 ms |
| Testlauf 4 | 788 ms | 804 ms | 1121 ms | 1187 ms |
| Testlauf 5 | 740 ms | 1091 ms | 875 ms | 1138 ms |
| Testlauf 6 | 1021 ms | 866 ms | 903 ms | 1119 ms |
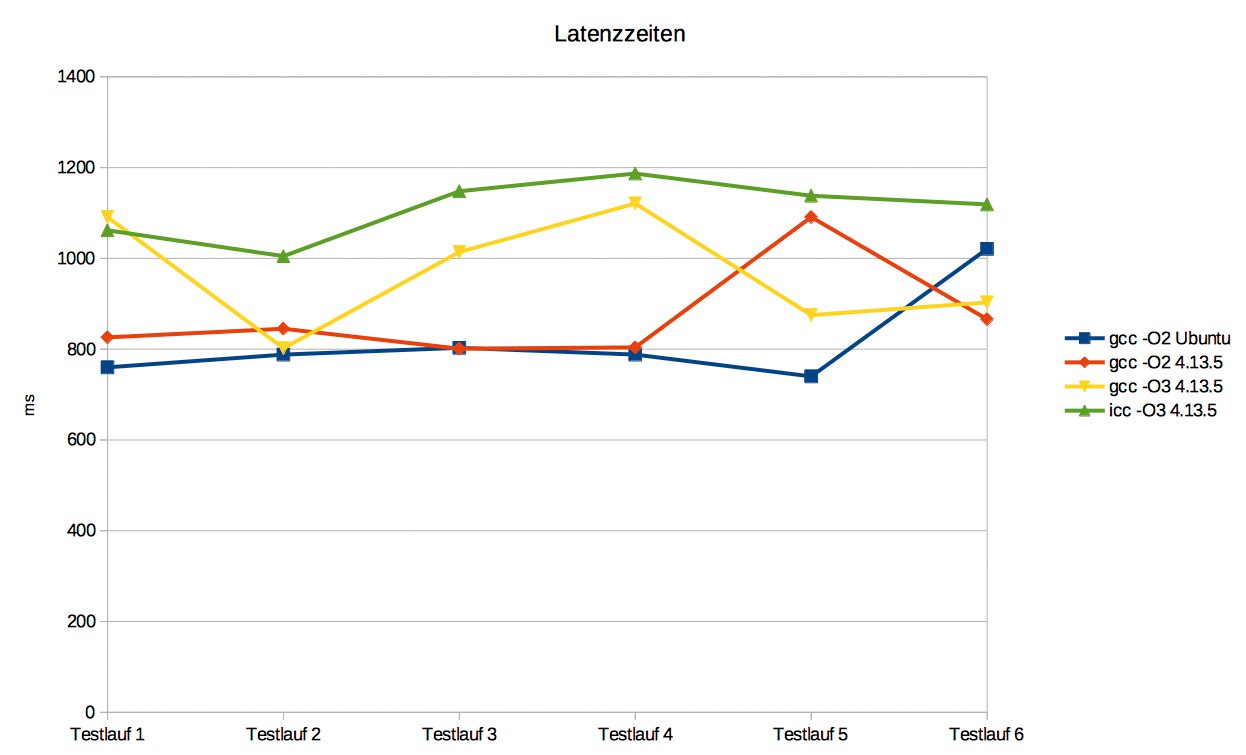
Abbildung 5: Ergebnisse der Latenzmessung über sechs Testläufe. Die Zeiten auf der y-Achse sind in Millisekunden aufgetragen. Die ermittelten ICC-Werte liegen signifikant über den Werten bei Verwendung des GCC.
Ernüchterung
Die aktuell ermittelten Werte der Kompilierungs- und Latenzzeiten transportieren eine schlechte Nachricht für Entwickler, die nach einer einfachen Lösung für einen Performance-Schub suchen und deswegen auf den Intel-eigenen Compiler setzen (wollen).
Denn für die Kernelimages gilt das Geschwindigkeits-Versprechen von Intel nicht mehr, die Bootzeiten zwischen mit dem GCC und mit dem ICC kompilierten Kerneln sind praktisch gleich. Allenfalls lassen sich durch angepasste Compilerflags in den Makefiles der Kernel-Unterverzeichnisse die Kompilierzeiten verkürzen, da die umfangreichen Warnmeldungen während des Buildprozesses unterbleiben.
In Sachen Optionen warnt die offizielle Dokumentation sowieso vor Blauäugigkeit: “Der Intel C++ Compiler unterstützt viele von den Compileroptionen …” – die Einschränkung “viele” ist ernst zu nehmen. Ein Projekt einfach durch Austausch des Compilers in den Makefiles portieren zu wollen, gelingt selten.
In die Bewertung der Messwerte sollte zudem einfließen, dass Optimierungen im Betriebssystem selbst schwere Kost sind: Bei den Wechseln vom Benutzer- in den Kernelmodus sichert die CPU nämlich nur ihre allgemeinen Register, aber nicht die der Prozessorerweiterungen. Das macht es schwer, im Kernel parallelisierbaren SIMD-Code (Single Instruction Multiple Data) zu verankern. Software im Userspace unterliegt dieser Einschränkung nicht. Wie in [8] aufgezeigt, wartet der ICC in anderen Fällen (Datenbankzugriffe unter Gentoo Linux) durchaus mit einem Performance-Schub auf.
Fazit
Dass Konkurrenz das Geschäft zum Wohle der Kunden belebt, gilt für Compiler allemal. Schon allein deshalb war und ist es gut, dass Intel sein Produkt am Markt hält, auch wenn die Absicht des PC-Prozessor-Quasimonopolisten wohl eher die ist, die eigenen CPUs über optimierten Code attraktiv zu halten. Und dass der ICC ein Jahrzehnt lang messbar schnellere Binaries produziert hat als der GCC und andere, war für diese Alternativen ein guter Ansporn.
An dieser Stelle löst sich wohl auch das Rätsel um das schlechte Abschneiden des Intel-Compilers gegenüber dem GCC auf: Nicht Intels Produkt ist schlechter geworden, sondern der freie Compiler ist heute besser denn je. Insbesondere hantiert er heute mit der PGO-Instrumentalisierung (Profile Guided Optimization), die vor Jahren noch ein Alleinstellungsmerkmal des ICC war.
Nun ist es an Intel, sich wieder einen Vorsprung herauszuarbeiten. Ein erster Ansatzpunkt sollten die Übersetzungszeiten sein, denn auch für vielbeschäftigte Entwickler gilt: Zeit ist Geld.
Infos
- Ingo A. Kubbilun, “Linux-Kernel mit dem Intel-Compiler übersetzen”: Linux-Magazin 07/04, S. 34, https://www.linux-magazin.de/Ausgaben/2004/07/Aufgedreht-Kernel-Tuning
- Intel Parallel Studio XE: https://software.intel.com/en-us/parallel-studio-xe
- Open MP: http://www.openmp.org
- Open Source Initiative: https://opensource.org
- The Open Source Definition: https://opensource.org/osd
- Open Benchmarking: https://openbenchmarking.org
- Phoronix Test Suite: http://www.phoronix-test-suite.com
- Kay Königsmann, “Gentoo-Software optimiert übersetzen”: Linux-Magazin 06/11, S. 42, https://www.linux-magazin.de/Ausgaben/2011/06/ICC-fuer-Gentoo





