
© Dmytro Panchenko, 123RF
Agile, Confluence und Gitlab sind im Devops-Kontext sehr beliebt und bilden oft das Fundament für agile Arbeit. Mit den richtigen Ansible-Playbooks lässt sich Ubuntu schnell zur agilen Arbeitszentrale machen.
Der Begriff Devops polarisiert – nicht zuletzt weil er mittlerweile fast so beliebig gebraucht daherkommt wie der Begriff Cloud. Admins sehen in ihm oft den Versuch, zusätzliche Arbeit auf sie abzuwälzen, und Entwickler beäugen die Kollegen vom Betriebssystem nicht selten argwöhnisch, wenn diese ihre Software in Betrieb nehmen.
Auf der Suche nach einer Begriffserklärung stößt man auf diverse Anleitungen, die sich stets auch mit agilem Arbeiten beschäftigen: Devops, so steht dort zu lesen, sei letztlich recht simpel. Admins übernehmen Workflows und verschiedene Prozesse von Entwicklern, um die Systeme unter ihren Fittichen effizienter zu verwalten.
Dass Devops und Agilität mehr als Schlagworte sind, merken Unternehmen spätestens beim Betrieb größerer Plattformen, etwa öffentlichen Clouds. Denn hier gelten mehrere Annahmen der klassischen Setups nicht mehr. Ein Setup mit zehn Knoten lässt sich möglicherweise noch händisch und ohne Automation verwalten – doch wenn mehrere Hundert Server oder noch mehr Teil der Installation sind, kommt man mit konventionellen Ansätzen nicht weiter.
Agiles Arbeiten ist nötig
Große Umgebungen wie Open Stack sind sowohl im Hinblick auf Entwicklung als auch auf Wartung eine echte Herausforderung. Sie bestehen aus einer großen Menge an Komponenten, die nicht alle demselben Releasezyklus folgen. Sie sind so mächtig, dass sie viele Aspekte umfassen, darunter Storage, Netz oder Benutzerverwaltung. Sie entwickeln sich kontinuierlich weiter, was auf einer produktiven Plattform die Notwendigkeit regelmäßiger Updates mit sich bringt – und die Notwendigkeit, neue Komponenten auszurollen, die zuvor gar nicht Teil des Betriebs waren.
Sie setzen auch so viele Rechner voraus, dass es schon ob der schieren Menge der verwalteten Systeme unmöglich ist, die Plattform händisch zu warten. Kurzum: Die Grundsätze agilen Arbeitens sind in einer großen Umgebung zwingende Voraussetzung dafür, dass die Plattform überhaupt gut funktioniert.
Wer eine solche Plattform betreibt, muss die Arbeit an ihr koordinieren. Dabei helfen Design-Dokumente den Entwicklern, den Leuten vom Betrieb und den Architekten neue Funktionen zu planen. Mit klassischem Issue Tracking lässt sich nachvollziehen, wer gerade an welcher Funktion oder an welchem Problem arbeitet. Das ist gerade bei verteilten Teams wichtig. Automatisierung ist hierfür eine zwingende Voraussetzung.
Solche Teams kombinieren ihre Automatisierungslösung meist mit einer klassischer Revisionsverwaltung. Ansible-Playbooks etwa lassen sich mit Git leicht und gut verwalten. Ist ein neues Feature entwickelt und getestet, genügt es, auf dem zentralen Ansible-Server das passende Repository auszuchecken und einen Run von Ansible zu starten, um die Änderung auszurollen.
Diese Art der Entwicklung macht zudem Continuous Integration (CI) leicht: Jeder Commit ins Git-Verzeichnis führt im Hintergrund dazu, dass Jenkins startet und verschiedene Tests auf den neuen Code loslässt. Eventuelle Fehler fallen so bereits beim Entwickeln auf und nicht erst Monate später, wenn die Änderung endlich im Rahmen eines großen Updates zum Einsatz kommt – wie es beim klassischen Wasserfall-Prinzip der Fall wäre.
Eine Frage der Werkzeuge
Wer einen agilen, Devops-artigen Workflow einrichten möchte, stellt sich am Anfang die Frage nach den dafür zu nutzenden Werkzeugen. Atlassian hat sich als Anbieter solcher Werkzeuge gut etabliert. Viele Anwender arbeiten zum Beispiel mit Confluence als Wiki, um gemeinsam an Design-Dokumenten zu arbeiten oder ihre Dokumentation zu verwalten.
Jira kommt häufig als Issue Tracker hinzu, weil es neben Scrum und Kanban weitere Möglichkeiten bietet, um Aufgaben nicht nur zu verwalten, sondern auch zu visualisieren. Und wer seine Playbooks für Ansible nicht auf Github lagern möchte, greift nicht selten zu Gitlab: Damit lässt sich lokal ein zentrales Git-Repository aufbauen, das sich auch problemlos in die schon beschriebenen Continous-Integration- und Continous-Development-Konzepte integrieren lässt.
Allerdings: Wer mit einem jungfräulichen Ubuntu 16.04 anfängt und darauf Confluence, Jira und Gitlab ausrollen möchte, der hat noch einige Arbeit vor sich. Nicht wenige Unternehmen erledigen diesen Schritt – im krassen Widerspruch zum Automatisierungsprinzip – ganz ohne Automatisierung.
Das ist ein Problem, weil sich das Setup dann einerseits nur schwer warten lässt und es andererseits auch kaum möglich ist, nach einem Totalausfall schnell wieder zu funktionierenden Jira-, Confluence- und Gitlab-Instanzen mit eingespielten Backups zu kommen. Unterm Strich steht: Vielleicht gerade dann, wenn eine funktionierende agile Toolchain bitter nötig wäre, ist sie nicht verfügbar.
Ansible kommt zu Hilfe
Die gute Nachricht ist, dass sich Confluence, Jira und Gitlab problemlos mit Ansible automatisieren lassen. Im Netz finden sich für beinahe jede Kombination aus einer bestimmten Distribution und den Tools für agiles Arbeiten fertige Playbooks, die oft sogar aktuell sind.
So etwas lädt ein: Der Autor dieses Artikels sah sich kürzlich vor die Aufgabe gestellt, auf Basis von Ubuntu 16.04 eine agile Arbeitszentrale bauen zu müssen, die Instanzen von Confluence, Jira und Gitlab enthalten sollte. Das daraus entstandene Playbook ist die Grundlage für den folgenden Artikel.
Das Ziel bestand darin, auf einer jungfräulichen Instanz von Ubuntu 16.04 die drei Dienste automatisch durch den Aufruf nur eines einzelnen Ansible-Playbook vollständig zu installieren.
Vorbereitende Maßnahmen
Bevor die Arbeit mit dem eigentlichen Ansible-Playbook beginnt, ist ein wenig Vorarbeit nötig. Der Artikel geht im Folgenden davon aus, dass ein frisch installiertes System mit Ubuntu 16.04 LTS bereits existiert, etwa als virtuelle Maschine in einer öffentlichen Cloud. Ansible läuft im Beispiel auf demselben Host, der später auch Confluence, Jira und Gitlab hostet, also handelt es sich um ein so genanntes All-in-one-Setup (AiO).
Weil Ansible sich per SSH verbindet, dies idealerweise jedoch nicht als Systembenutzer Root tun sollte, ist ein gesonderter Benutzerzugang nötig. Das Beispiel geht davon aus, dass dieser Benutzer »ubuntu« heißt. Wer in einer Open-Stack-Cloud eine VM für Confluence & Co. startet und dazu ein offizielles Ubuntu-Cloudimage nutzt, findet diesen Benutzer bereits im Image vor und muss ihn nicht mehr anlegen.
Sinnvoll ist es zudem, dem Nutzer den Login per SSH-Schlüssel zu ermöglichen. Einerseits ist das sicherer als der Login per Passwort, andererseits muss der Admin nicht jedes Mal das Passwort des »ubuntu«-Nutzers eintippen, wenn er Ansible aufruft. Wie üblich genügt es, in der Datei ».ssh/authorized_keys« im Homeverzeichnis des Nutzers »ubuntu« den öffentlichen Teil des jeweiligen SSH-Schlüssels zu hinterlegen.
Besonders wichtig ist Ansible selbst. Gerade weil es sich um ein AiO-Setup handelt, müssen Ansible und Ansible Vault auf dem System vorhanden sein. Die Aufgabe meistert der Admin sinnvoll, indem er die passenden Pakete direkt aus den Ansible-Repositories für Ubuntu 16.04 installiert:
sudo apt-add-repository ppa:ansible/ansible sudo apt-get update sudo apt-get install ansible
Sind die drei Kommandos erfolgreich durchgelaufen, lässt sich durch das Kommando »ansible« prüfen, ob alles funktioniert hat: Es muss nun der Hilfetext von Ansible erscheinen.
Schließlich ist es sinnvoll, dem Nutzer »ubuntu« das Ausführen aller Befehle per »sudo« ohne die vorherige Eingabe des Nutzerpassworts zu erlauben. Wenn das Playbook in einer Cloud-VM zum Einsatz kommt, ist das ab Werk bereits der Fall: Hier hat »ubuntu« gar kein Passwort, sodass passwortloses »sudo« zwangsläufig die Grundeinstellung ist.
Wer das Beispiel nicht in einer Cloud-VM nachspielt, erlaubt per »visudo« als Root der Gruppe »sudo« das Ausführen von Befehlen ohne Passwort und stellt nötigenfalls per »adduser ubuntu sudo« sicher, dass der Benutzer auch tatsächlich zur »sudo«-Gruppe gehört.
Ein letzter Schritt der Vorbereitung besteht darin, die benötigten Einträge in der DNS-Zone der Zieldomain anzulegen. Diese sollten vorhanden und bereits im DNS-System propagiert sein, bevor das Ausrollen von Confluence, Jira sowie Gitlab ansteht. Das Beispiel geht davon aus, dass die drei Dienste jeweils einen eigenen DNS-Eintrag und in weiterer Folge einen eigenen Virtualhost in Apache haben.
Das Ansible-Playbook auschecken
Danach lädt der Admin das AiO-Playbook für Ansible herunter. Hierzu ist es sinnvoll, das Paket »git« zu installieren, weil sich das Playbook dann direkt von Github auschecken lässt:
git clone https://github.com/madkiss/ansible-playbook-agile-aio
Wenn der Check-out funktioniert hat, findet sich in dem Ordner, in dem der Befehl ausgeführt worden ist, anschließend das Verzeichnis »ansible-playbook- agile-aio«. Es empfiehlt sich, in dieses zunächst einen Blick zu werfen: Der Ordner folgt den Ansible-Empfehlungen zur Verzeichnisstruktur [1].
So finden sich mehrere Playbooks, deren Dateiname auf ».yml« endet. Hinzu kommt die Datei »devops.hosts«, die Ansible als Inventory-File dient. Zusätzlich gibt es die Ordner »vars« und »roles«: In »vars« liegt eine Datei, die allgemeine Variablen für die einzelnen Playbooks definiert. Der Admin legt in diesem Ordner später eine weitere Datei namens »devops-secret.yml« an, in der verschiedene, per Ansible Vault verschlüsselte Passwörter des Setups hinterlegt sind. Der Ordner »roles« schließlich enthält die Rollen und indirekt die eigentlichen Playbooks, die die jeweiligen Dienste direkt auf dem Host ausrollen.
Eine Sonderstellung nimmt das Playbook »playbook.yml« ein: Es beinhaltet lediglich Verweise auf alle anderen Playbooks, sodass es dem Admin möglich ist, einfach »playbook.yml« per Ansible auszuführen und so alle benötigten Dienste auf einmal auszurollen (Abbildung 1).
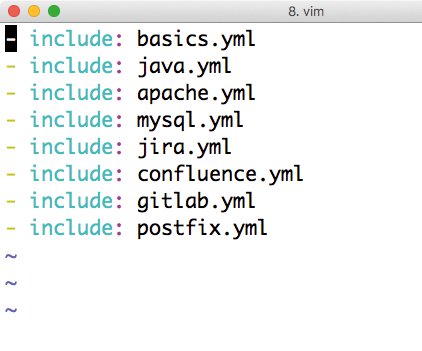
Abbildung 1: Die Datei »playbook.yml« ruft alle anderen Playbooks auf und dient als Wrapper für das gesamte Setup.
Der Artikel geht im weiteren Verlauf die einzelnen Playbooks durch, erklärt ihre Bedeutung und weist auch auf Stellen hin, an denen der Admin seine lokale Konfiguration anpassen muss.
Das Inventory konfigurieren
Bevor die Arbeit mit den verschiedenen Rollen des Playbook losgeht, legt der Admin eine passende Inventory-Datei für sein Setup an. Eine Vorlage ist im AiO-Playbook in Form der Datei »devops.hosts« bereits enthalten: Hier gibt es eine Gruppe namens »devops«, zu der ein einzelner Host gehört. In das erste Feld der Datei trägt der Admin den vollständigen Hostnamen des Servers ein, auf dem später das AiO-Setup läuft.
Hinter »ansible_host« gehört die IP-Adresse des Zielsystems. Die Variablen »ansible_port« sowie »ansible_python _interpreter« bleiben idealerweise unverändert: Sie veranlassen Python dazu, sich auf dem Standard-SSH-Port 22 mit dem Host zu verbinden und beim Aufruf von Befehlen auf dem Zielsystem die Version Python 3 zu verwenden.
Ob das Einrichten der »devops.hosts« funktioniert hat, kontrolliert der Admin im Anschluss per »ping«-Befehl:
ansible devops -i devops.hosts -m ping
Verläuft das Ausführen des Befehls erfolgreich, ist Ansible bereit für den Einsatz.
Passwörter festlegen
Noch bevor die Arbeit mit den eigentlichen Ansible-Rollen losgeht, ist es geboten, deren benötigte Passwörter zu konfigurieren. Naturgemäß rollen sich beim Admin die Fußnägel hoch, wenn er Passwörter unchiffriert in Textdateien ablegen soll, die später möglicherweise in einem firmeninternen Git-Repository offen einsehbar sind.
Ansible bietet hier jedoch eine Alternative: Per Vault kann es geheime Information verschlüsselt auf der Platte ablegen. Der Admin übergibt beim Aufruf von »ansible-playbook« dann lediglich noch zwei weitere Parameter, sodass Ansible nach dem Vault-Passwort fragt und die Dateien dann während seiner Arbeit vollautomatisch entschlüsselt.
Vault funktioniert gut, aber mit einer kleinen Einschränkung: Wenn mehrere Inhalte in verschiedenen Dateien zu verschlüsseln sind, müssen alle Vault-Dateien mit exakt demselben Passwort geschützt sein. Das ist in diesem Beispiel der Fall: Die Rolle, die auf dem Zielsystem das SSL-Zertifikat ausrollt, speichert den SSL-Schlüssel, der zum Zertifikat gehört, ebenfalls als Vault-Datei ab. Der Admin sollte sich das für den ersten Vault-Container genutzte Passwort also merken, weil er es später für den SSL-Key-Tresor ebenfalls benötigt.
Zunächst kommt Vault jedoch zum Einsatz, um im Ordner »vars« innerhalb des AiO-Playbook eine Datei namens »devops-secret.yml« anzulegen. Das erledigt der folgende Befehl:
ansible-vault create devops-secret.yml
Nach der Eingabe eines frei wählbaren Passworts öffnet sich der Editor, der in der Variablen »$EDITOR« hinterlegt ist. Die Datei sollte letztlich drei Zeilen enthalten:
apache2_vhosts_pass: "secret" mysql_root_pass: "secret" apache2_vhosts_hash_salt: "secret"
»secret« ist dabei freilich durch ein sinnvolles Passwort zu ersetzen. Ist die Datei entsprechend eingerichtet, genügt es, sie zu speichern und den Editor zu schließen. Möchte der Admin den Inhalt der Datei später sehen oder ändern, helfen die Befehle »ansible-vault view devops-secret.yml« (Abbildung 2) oder »ansible-vault edit devops-secret.yml«.

Abbildung 2: Mit Ansible Vault speichert der Admin vertrauliche Daten in einer verschlüsselten Datei auf der Platte – statt im Klartext.
Grundlegende Konfiguration
Das vorliegende Ansible-Playbook basiert im Wesentlichen auf der Arbeit von drei Entwicklern: Der größte Teil der genutzten Rollen entstammt der Feder von Wong Hoi Sing Edison (»hswong3i«), der die gesamte Installation von Jira und Confluence in Ansible abgebildet hat. Seine Rollen sind mit geringfügigen Anpassungen das Rückgrat des AiO-Playbook. Denn sie decken nicht nur Jira und Confluence ab, sondern ermöglichen es auch, diverse Basisparameter des Systems idempotent zu konfigurieren.
Das »basic«-Playbook macht sich viele Rollen von Edison zunutze: Neben einer grundlegenden Apt-Konfiguration rollt es auch Konfigurationsdateien für den Hostnamen und die zu nutzenden Locales aus. Es stellt die Zeitzone des Systems zudem auf »UTC« und rollt NTP aus, um eine zuverlässige Quelle für die Uhrzeit zu erhalten. Obendrein installiert es eine grundlegende IPtables-Konfiguration, die auf den privilegierten Ports bis 1024 nur 22 für SSH öffnet. Andere Ansible-Rollen erweitern die Firewall-Konfiguration später – falls nötig.
Dass er sich per Ansible erfolgreich mit dem Zielsystem verbinden kann, hat der Admin im Schritt zuvor bereits überprüft. Nun testet er durch den Aufruf des »basics«-Playbook, ob das Ausführen von Ansible-Playbooks auch wirklich funktioniert:
ansible-playbook -i devops.hosts -e @vars/devops.yml -e @vars/devops-secret.yml --ask-vault-pass basics.yml
Das Abarbeiten des Kommandos kann etwas Zeit in Anspruch nehmen, denn Ansible installiert beim Ausführen der Rollen in »basics.yml« viele Pakete auf dem künftigen Agile-Host. Läuft das Playbook ohne Fehler durch, meldet Ansible dies am Ende und gibt »0« als Rückgabewert aus. Damit ist die grundlegende Systemkonfiguration bereits abgeschlossen, weiter geht es mit den spezifischen Rollen für Confluence, Jira und Gitlab.
Viele Voraussetzungen
Ein Faktor, den viele Admins oft übersehen, wenn sie Confluence, Jira & Co. händisch installieren, sind die diversen Voraussetzungen, die die Werkzeuge erwarten. Jira und Confluence etwa benötigen Java und MySQL sowie den MySQL-Java-Connector. Gitlab setzt in der Omnibus-Edition auf PostgreSQL, installiert es aber immerhin selbst.
Auch das Thema SSL spielt eine Rolle: Die drei Dienste laufen in der Regel auf demselben Host und nutzen möglicherweise dieselbe IP, sollen aber natürlich HTTPS auf Port 443 anbieten. Dieses Setup lässt sich jedoch nur über einen Webserver mit verschiedenen virtuellen Hosts lösen, der gleichzeitig als SSL-Terminator dient. Confluence, Jira und Gitlab mit allen Abhängigkeiten und der benötigten Konfiguration zu Fuß aufzusetzen, artet deshalb nicht selten in eine langwierige Arbeit aus.
Das vorliegende AiO-Playbook kümmert sich um die Abhängigkeiten und ist auch darauf ausgelegt, Apache als terminierenden SSL-Proxy einzurichten. Jira, Confluence und Gitlab konfigurieren jeweils ihre eigenen virtuellen Hosts über die Apache-Vhost-Rolle, die ebenfalls Wong Hoi Sing Edison geschrieben hat.
Um die Voraussetzungen für die drei Dienste zu schaffen, ruft der Admin nach dem erfolgreichen Ausrollen des »basics«-Playbook nacheinander die Playbooks »java.yml«, »apache.yml« und »mysql.yml« analog zu dem Befehl beim »basics«-Playbook auf. Im Anschluss laufen auf dem AiO-Host bereits Apache, MySQL und Java für Confluence, und Jira ist installiert. Danach geht es ans Eingemachte, also an das Deployment der gewünschten Dienste.
SSL-Zertifikate an den Start bringen
Auch eine fertige Ansible-Rolle für Jira steuert Edison bei, doch gibt es – anders als bei den bisherigen Playbooks – einen zusätzlichen Schritt: Im AiO-Playbook enthält die Datei »jira.yml« mehrere Platzhalter, die Admins sinnvollerweise durch tatsächliche Werte ersetzen. Das gilt besonders für die Parameter »apache2_vhosts_server_name« bei der Rolle »hswong3i.jira« sowie für »apache2_vhosts_server_name« bei der Rolle »hswong3i.apache2_vhosts« (Abbildung 3).
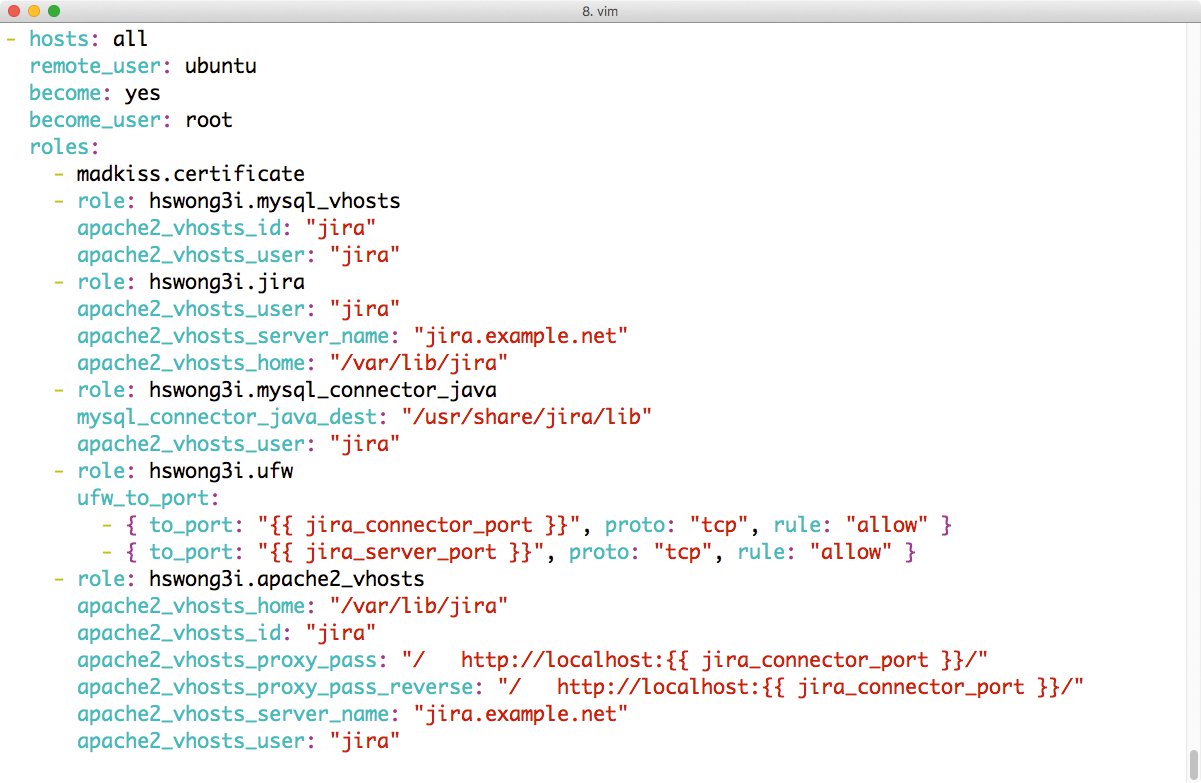
Abbildung 3: Die Jira- und Confluence-Rollen enthalten diverse Einträge, die der Admin vor dem Ausführen an die lokalen Begebenheiten anpassen sollte.
Außerdem fällt auf, dass »jira.yml« eine Rolle namens »madkiss.certificate« aufruft: Das ist eine rudimentäre Rolle aus der Feder des Autors dieses Artikels, die das SSL-Zertifikat, den passenden SSL-Schlüssel sowie ein SSL-CA- oder SSL-Intermediate-Zertifikat an die richtige Stelle im System packt. Bevor der Admin »jira.yml« ausrollen kann, stattet er diese Rolle mit den benötigten Dateien aus und konfiguriert sie.
Die Rolle »madkiss.certificate« geht grundsätzlich von drei Dateien aus, die nötig sind: »key.pem.enc« ist eine Ansible-Vault-Datei und enthält den SSL-Schlüssel für das Zertifikat, »certificate.pem« ist das Zertifikat selbst, und »intermediate.pem« enthält eventuell benötigte Zertifikate, die nötig sind, um zwischen den CA-Zertifikaten in den Browsern und dem jeweiligen Zertifikat eines Anbieters einen direkten Vertrauenspfad herzustellen. Weil die meisten CAs mittlerweile mit Sub-Signing-Keys arbeiten, ist das notwendig.
Die drei Dateien gehören in den Ordner »roles/madkiss.certificate/files« im AiO-Playbook. Mittels »ansible-vault create key.pem.enc« legt der Admin wie schon beschrieben die Schlüsseldatei an; dabei achtet er darauf, das gleiche Passwort wie zuvor beim Anlegen von »devops-secret.yml« zu verwenden. Die beiden anderen Dateien legt er einfach im Klartext am selben Ort ab.
Der Rest funktioniert automatisch: »madkiss.certificate« legt die drei Dateien in der Standardkonfiguration in »/etc/ssl« ab, die anderen Rollen sind mittels Default-Werten so konfiguriert, dass sie Zertifikat, Intermediate-Zertifikat und Key an denselben Stellen suchen (Abbildung 4).
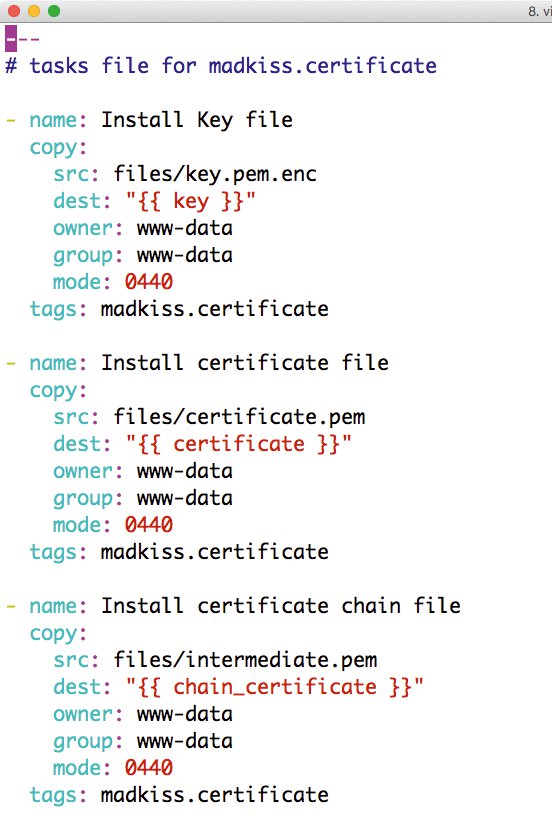
Abbildung 4: Die »madkiss.certificate«-Rolle installiert auf dem Zielsystem SSL-Zertifikate samt Schlüssel.
Postfix als Voraussetzung für die anderen Dienste
Confluence, Jira und Gitlab eint eine Eigenschaft: Sie kommunizieren viel per Mail mit den registrierten Nutzern. Ohne funktionierendes Mail-Setup klappt schon das Hinzufügen von Nutzeraccounts nicht, weil die initialen Daten der Nutzerzugänge bei allen Diensten per Mail in Umlauf kommen.
Das Playbook enthält deshalb eine »postfix.yml«. Die konfiguriert Postfix auf dem Zielhost grundlegend und erlaubt auch das Senden per E-Mail über ein Mailrelay. In »postfix.yml« nimmt der Admin die entsprechende Konfiguration vor und rollt das Playbook danach mit dem »ansible-playbook«-Kommando aus. Die Postfix-Rolle im Playbook stammt übrigens zur Abwechslung mal nicht von Edison, sondern von dem niederländischen Provider Oefenweb.
Übrigens: Das Postfix-Playbook konfiguriert Postfix so, dass es danach als Relay-Host für lokale Dienste funktioniert. Damit lassen sich Gitlab, Jira und Confluence mit »127.0.0.1« als Mailserver konfigurieren. Authentifizierung setzt der Dienst nicht voraus, wohl aber, dass der Mailserver von außen über die üblichen SMTP-Ports nicht erreichbar ist – eine Firewall also den Zugriff verhindert.
Jira und Confluence
Wenn die drei Dateien für »madkiss.certificate« platziert sind und der Admin in »jira.yml« die passenden Parameter hinterlegt hat, erfolgt wieder der bekannte »ansible-playbook«-Aufruf von oben, doch dieses Mal mit »jira.yml« als Ziel. Das kann wieder dauern. Das Playbook lädt die Jira-Software, rollte sie aus, hinterlegt für den Dienst in MySQL einen Benutzer und konfiguriert Apache.
Wenn das Jira-Setup geklappt hat, erfolgt analog der Confluence-Rollout: In »confluence.yml« ersetzt der Admin analog zu »jira.yml« die Werte für »apache2_vhosts_server_name« und »apache2_vhosts_server_name« und ruft danach erneut »ansible-playbook« auf.
Tools einrichten
Wichtig nach dem Rollout von Confluence und Jira ist, dass der Admin sich nach dem »ansible-playbook«-Aufruf sofort per HTTPS mit den installierten Diensten verbindet. Beide begrüßen ihn zunächst mit dem Konfigurationsassistenten. Weil erst dieser Assistent das Admin-Passwort einrichtet, steht die Seite also so lange für jedermann ohne Passwort offen. Nutzt man Confluence und Jira zusammen, ist es sinnvoll, die Benutzerdatenbank nur in Jira zu führen und Confluence an Jira anzubinden (Abbildung 5). Während des initialen Setups fragen Confluence und Jira übrigens auch nach der Lizenz, die dafür idealerweise griffbereit vorliegt.
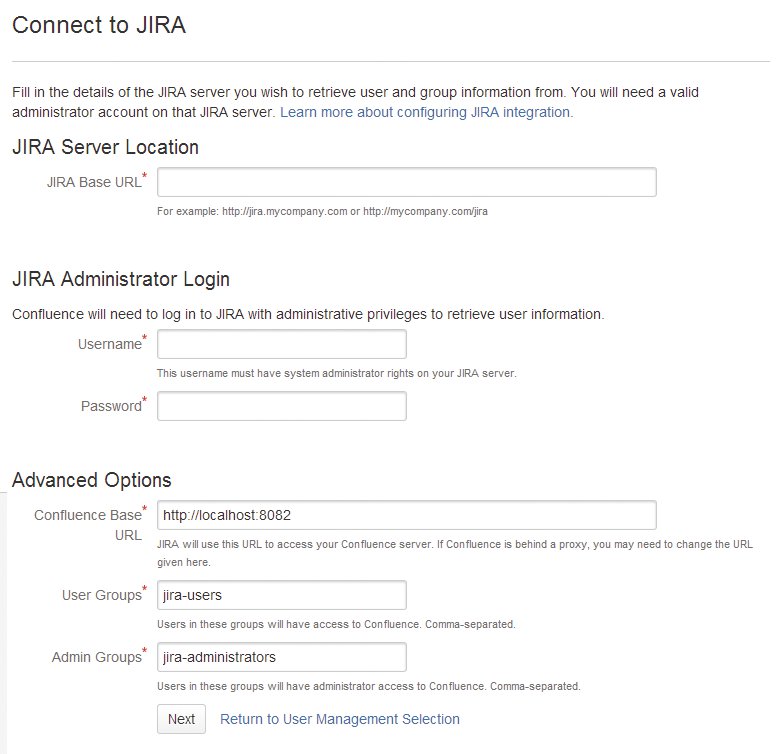
Abbildung 5: Beim initialen Setup lässt sich Confluence so einrichten, dass es Jira als Quelle für Nutzerdaten verwendet.
Damit ist die agile Arbeitszentrale fast fertig: Es fehlt bloß noch Gitlab. Ein eigenes Playbook (»gitlab.yml«) rollt es aus; auch hier sollte der Admin zuvor aber noch verschiedene Werte anpassen. Das betrifft besonders die Mail-Konfiguration, die Gitlab später nutzen soll, sowie die üblichen Einträge für die Steuerung der Apache-Vhost-Konfiguration.
Schließlich rollt ein letzter Aufruf von »ansible-playbook« noch die Omnibus-Edition von Gitlab aus. Auch Gitlab kommt übrigens mit einem eigenen Konfigurationsdialog daher, den der Admin ebenfalls direkt nach dem Deployment abschließen sollte.
Sinnvolles Arbeiten
Das vorgestellte Setup aus Confluence, Jira und Gitlab birgt aus Sicht des Admin gleich mehrere Vorteile in sich. Zunächst ist es idempotent: Der Admin kann also die einzelnen Playbooks oder »playbook.yml« jederzeit wieder aufrufen, um das Standardsetup wiederherzustellen. Änderungen am Setup sollte der Admin entsprechend zunächst in Ansible umsetzen und anschließend ausrollen.
Hinzu kommt, dass sich die drei Dienste auch untereinander gut verstehen: Wie erwähnt kann Jira als Nutzerdatenbank für Confluence dienen. Wer möchte, kann Gitlab und Jira miteinander verbinden, sodass Gitlab-Commits zu Log-Einträgen in Jira-Issues führen. Und Jira-Tickets lassen sich unmittelbar in Confluence-Seiten referenzieren. Für verteilte Teams, die zusammen agil arbeiten wollen, sind alle diese Funktionen ausgesprochen nützlich.
Infos
- Verzeichnisstruktur für Ansible: http://docs.ansible.com/ansible/latest/playbooks_best_practices.html#directory-layout





