
©Olga Kolbakowa, 123RF
Jüngst hat Oracle mit der Group Replication eine Hochverfügbarkeitslösung für das allgegenwärtige MySQL vorgestellt, die mit wenig Aufwand einsetzbar ist.
Ein wichtiger Grund für den Erfolg von MySQL [1] war die schon im Jahr 2001 mit der Release 3.23 eingeführte asynchrone Replikation. Sie erlaubt das Aufsetzen von Replika-Instanzen (Slaves), die sich alle Datenänderungen vom Mastersystem holen. Muss MySQL Daten nur lesen, kann dies auf einem Slave passieren, um den Master zu entlasten.
Schnell haben viele diese Replikation auch genutzt, um bei Ausfall eines Master-Servers einen der Slaves zum Master zu befördern. In der Praxis erleiden Anwender hier aber häufig Datenverluste, weil aufgrund der asynchronen Übertragung der Änderungen der Slave noch nicht auf dem aktuellen Stand ist. Rückstände von wenigen Sekunden bis zu einigen Minuten sind möglich.
Seit Version 5.5 lässt sich mit MySQL eine semi-synchrone Replikation aufbauen. Dabei wartet der Master, bis eine Änderung auf einem der Slaves angekommen (nicht aber angewendet) ist. Das geht allerdings zu Lasten des Serverdurchsatzes bei mehreren gleichzeitigen Schreibzugriffen und wird unter anderem deshalb nur selten eingesetzt.
Hochverfügbar
Mit MySQL-Bordmitteln war also bisher echte Hochverfügbarkeit nicht zu erreichen. In der Community erfreute sich daher in den letzten Jahren der von der finnischen Firma Codership Oy unter der GPLv2 veröffentlichte Galera Cluster [2] wachsender Beliebtheit. Er setzt auf einen MySQL-Server auf und erlaubt – beim Einsatz von mindestens drei Servern – das Schreiben in jeden der Nodes.
Über ein Gruppenprotokoll stellt Galera sicher, dass eine Änderung auf allen Nodes ausgeführt werden kann. Geht das nicht, weil ein anderer User die gleichen Daten auf einem anderen Knoten gleichzeitig geändert hat, rollt MySQL die Transaktion zurück. Dann muss der Client den Fehler behandeln – etwa indem er die Queries noch einmal abschickt.
Sicherlich auch aufgrund der Popularität des Fremdprodukts hat Oracle nun reagiert und im September 2016 zusammen mit dem MySQL-Server 5.7.17 das Group-Replication-Plugin nach insgesamt acht Pre-Releases als stabile Release veröffentlicht. Bei der Group Replication handelt es sich um eine Shared-nothing-Architektur: Alle Nodes einer Gruppe halten alle Daten. Die Kommunikation zwischen den Nodes erfolgt mit dem Mencius-Protokoll [3] über eine Variante des Paxos-Algorithmus.
Das System erzeugt eine eindeutige Reihenfolge für alle Schreibzugriffe, sodass bei konkurrierenden Zugriffen auf die gleichen Daten immer ein Sieger feststeht. Ein neuer Node kann jederzeit zur Gruppe hinzukommen – alles was es dafür braucht, ist ein halbwegs aktuelles Backup von einem bestehenden Node. Die endgültige Synchronisation erledigt das Plugin dann mit Hilfe der klassischen MySQL-Binlogs von alleine.
Voraussetzungen
Für den Einsatz des Group-Replication-Plugins sind einige Voraussetzungen zu erfüllen. Da zur Entscheidungsfindung immer eine Mehrheit der Nodes nötig ist, müssen mindestens drei Nodes in einer Gruppe sein. Group Replication funktioniert ausschließlich mit Tabellen, die Inno DB als Storage Engine verwenden. Die alte MyISAM-Engine wird nicht unterstützt. Zudem ist es zwingend notwendig, dass jede Tabelle mit einem Primärschlüssel ausgestattet ist.
Es überrascht allerdings, dass es im Jahr 2017 keinen Support für IPv6 gibt. Zurzeit muss die Netzwerkkommunikation zwischen den replizierenden Knoten über IPv4 passieren – Besserung ist für eine der nächsten Releases aber versprochen. Außerdem schreibt Oracle dem Anwender ein schnelles Netzwerk ins Pflichtenheft. WAN-Verbindungen über Ozeane hinweg fallen damit als Einsatzgebiet der Group Replication vorerst flach.
Ein Meister oder viele
Bei der Group Replication handelt es sich primär um eine Hochverfügbarkeitsfunktion. Ein Nebeneffekt sind höhere Kapazitäten für Lesezugriffe. Die Schreibkapazität erhöht sich nicht. Der Standard-Operationsmodus einer Gruppe ist der Single-Primary-Modus. Dabei bestimmt die Gruppe einen Node als Primary. Nur in diesen Node kann die Datenbank schreiben. Die übrigen stehen für Lese-Queries bereit und können die Rolle des Primary übernehmen, sollte der ausfallen.
Eine zweite Betriebsvariante heißt Multi-Primary, sie erlaubt das Schreiben auf jedem Node. Wer diesen Modus verwenden will, sollte sich ausgiebig mit dessen Einschränkungen beschäftigen [4]. Dringend ist darauf zu achten, dass es nicht zu konkurrierenden DDL-Queries (Data Definition Language) kommt. Gleichzeitige Änderungen der Struktur einer einzelnen Tabelle von mehreren Knoten aus können zum Datenverlust und zum Ausfall der gesamten Gruppe führen. Deshalb ist derzeit vom Einsatz des Multi-Primary-Modus abzuraten.
Limitierungen
Transaktions-Safepoints unterstützt MySQL nicht. Damit fällt auch das klassische Kommando »mysqldump« mit dem Parameter »–single-transaction« als Backupmethode aus. Deshalb ist entweder das von Oracle beim Kauf einer Enterprise-Lizenz erhältliche MySQL Enterprise Backup [5] oder das als freie Software erhältliche Percona Xtrabackup [6] als Backuplösung für die Group Replication zu verwenden. Ob der eigene Server Savepoints einsetzt, überprüft die in Listing 1 gezeigte Query.
Listing 1
Test auf Safepoints
01 mysql> SELECT COUNT_STAR FROM performance_schema.events_statements_summary_global_by_event_name WHERE event_name LIKE "%/savepoint"; 02 +------------+ 03 | COUNT_STAR | 04 +------------+ 05 | 1 | 06 +------------+ 07 1 row in set (0.00 sec)
In der Praxis
Die folgenden Abschnitte demonstrieren die Installation und Einrichtung der Group Replication. Der Admin im Beispiel startet mit drei Servern, auf denen MySQL 5.7.17 installiert ist und auf denen sich keine Daten befinden.
Die in Listing 2 beschriebenen Settings müssen auf allen Servern (in der Datei »/etc/my.cnf«) aktiv sein. Global Transaction-IDs sind eingeschaltet, das Binary-Logging ist aktiviert und alle Nodes, die zur Gruppe gehören, sind mit dem von der Group Replication verwendeten Port aufzulisten.
Listing 2
Konfigurationseinstellungen
01 gtid_mode = ON 02 enforce_gtid_consistency = ON 03 master_info_repository = TABLE 04 relay_log_info_repository = TABLE 05 binlog_checksum = NONE 06 log_slave_updates = ON 07 log_bin = binlog 08 binlog_format = ROW 09 transaction_write_set_extraction = XXHASH64 10 plugin-load = group_replication=group_replication.so 11 group_replication_group_name = "aaaaaaaa- aaaa-aaaa-aaaa-aaaaaaabcdef" 12 group_replication_start_on_boot = on 13 group_replication_group_seeds = "192.168.1.10: 24901,192.168.1.11:24901,192.168.1.12:24901" 14 group_replication_bootstrap_group = off
Außerdem gibt es noch einen Block von Einstellungen, die auf jedem der Nodes unterschiedlich sein müssen. Diese sind in Listing 3 aufgelistet und bestehen aus einer unterschiedlichen Server-ID, einem Port (für Clientverbindungen) und der lokalen Adresse inklusive Port für die Gruppenkommunikation. Da sich die Synchronisation der Nodes der MySQL-Binlog-Infrastruktur bedient, ist auch ein extra Replikations-User anzulegen (Listing 4).
Listing 4
Replikations-User
01 CREATE USER IF NOT EXISTS rpl@'%' IDENTIFIED BY 'Rplpass1!'; 02 GRANT REPLICATION SLAVE ON *.* TO rpl@'%'; 03 CHANGE MASTER TO MASTER_USER='rpl', MASTER_PASSWORD= 'Rplpass1!' FOR CHANNEL 'group_replication_recovery';
Listing 3
Knotenspezifische Einstellungen
01 server-id=10001 02 port = 3306 03 group_replication_local_address = "127.0.0.1:24901"
Danach startet der Admin die Group Replication auf dem ersten Node. Da der sich noch nicht mit anderen Nodes verbinden kann, begibt er sich vor dem eigentlichen Start zunächst in den Bootstrap-Modus:
SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF;
Auch wenn alle verwendeten Server leer sind, muss der Admin als Nächstes den Datenbestand des ersten Servers mit Hilfe eines Dump auf die anderen übertragen – sonst machen die globalen Transaction-IDs der zusätzlichen Systeme das Aufbauen der Replikation unnötig schwer. Dazu wird ein Dump auf dem ersten Server erstellt:
mysqldump -uroot -p -A --triggers --routines --events > /tmp/instanz1.sql
Diesen Dump kopiert der Admin auf die anderen Nodes und importiert ihn dort:
mysql -uroot -p --init-command="RESET MASTER" < /tmp/instanz1.sql
Nun muss der MySQL-Dienst auf dem jeweiligen Node nur noch einmal neu gestartet werden. Damit sind alle Voraussetzungen erfüllt, um die Group Replication auch auf den anderen Nodes zu starten (Listing 5).
Listing 5
Start der Group Replication
01 CHANGE MASTER TO MASTER_USER='rpl', MASTER_PASSWORD='Rplpass1!' FOR CHANNEL 'group_replication_recovery'; 02 START GROUP_REPLICATION;
Die Group Replication läuft jetzt. Schreib-Queries sind bereits auf dem ersten Knoten erlaubt.
Im Betrieb
Fällt der Knoten aus, wählt das System automatisch einen neuen Knoten zum Primary und erlaubt dort die Schreibzugriffe. Wenn sich der ausgefallene Knoten später zurückmeldet, holt er die in der Zwischenzeit aufgelaufenen Änderungen von einem der anderen Knoten.
Zurzeit gibt es hier noch einen Fallstrick: Schlägt der Kontaktaufbau aus irgendeinem Grund fehl (beispielsweise wegen eines Netzwerkausfalls), dann arbeitet der Server von nun an als Single-System und nimmt als solches auch wieder Schreib-Queries an. Das sorgt dann augenblicklich dafür, dass der Cluster diesen Node nicht mehr aufnehmen kann, ohne ihn komplett frisch mit einem Backup von einem der anderen Nodes zu befüllen. Hier gibt es noch eindeutiges Verbesserungspotenzial, was den Betrieb der Lösung angeht. Als erste stabile Release macht die Group Replication allerdings schon einen sehr guten Eindruck.
Query-Verteilung
Die Group Replication löst nicht das Problem, wie die Queries von der Anwendung zu den Clusterknoten kommen. Gerade beim Single-Primary-Modus ist hier zusätzliche Intelligenz notwendig, da ja auch die Information, welcher Knoten nun gerade beschrieben werden kann, irgendwo hinterlegt sein muss. Es gibt aktuell vier verbreitete Softwarelösungen für das Problem.
Bei allen vier handelt es sich um Proxy-Systeme, die die Verbindungen von der Anwendung annehmen und an ein passendes System weiterleiten. Die Lösungen sind im Kasten “Query-Verteilung” aufgelistet. ProxySQL scheint auf dem noch sehr kleinen Markt die verbreitetste Lösung zu sein. Idealerweise installiert man die Verteilungslösung auf jedem Anwendungsserver und nicht zentral an einer Stelle im Netzwerk. Bis auf Maxscale sind alle Lösungen freie Software.
Query-Verteilung
ProxySQL [7]: Feature-reicher Layer-7-Proxy, der Schreib- und Lese-Queries trennen und an separate Server schicken kann, Beispielkonfiguration unter [8].
Haproxy [9]: Klassischer Layer-4-Proxy, Beispielkonnfiguration unter [10].
MySQL Router [11]: Routinglösung im Rahmen des Oracle-Inno-DB-Clusters.
Maria DB Maxscale [12]: Layer-7-Proxy-Lösung aus dem Hause Maria DB.
Und Galera?
Der bisherige Platzhirsch bei virtuell-synchroner Replikation im MySQL-Lager ist die finnische Firma Codership Oy mit ihrem Galera-Cluster. Bei Galera handelt es sich um eine unter der GPLv2 veröffentlichte Erweiterung für MySQL. Galera handhabt die Replikation in einer zusätzlichen Schicht, die auf dem MySQL-Kern aufsetzt. Anders als bei der Group Replication wird nicht das Binlog zum Handling vergangener Transaktionen genutzt, sondern mit dem Gcache ein eigenes File, das als Ringbuffer dient.
Galera setzt auf MySQL auf, implementiert die Kollisionserkennung und Verteilung der Write-Sets aber selbst. Im Unterschied zu Oracles Lösung greift es nicht auf den Baukasten von schon im Server integrierten Replikationsfeatures zurück. Galera ist aber schon mehrere Jahre an vielen Stellen produktiv im Einsatz und hier der Group Replication noch voraus.
Ausblick
Oracle hat mit der Veröffentlichung der Group Replication auch eine groben Einblick in die eigene Roadmap (Abbildung 1) gegeben. Die Group Replication ist der wichtigste Bestandteil des MySQL-Inno-DB-Clusters, einem Produkt, das zusätzlich noch die MySQL-Shell für eine vereinfachte Einrichtung und Administration eines Clusters sowie den MySQL-Router zur automatischen Verteilung von Queries beinhaltet. Der Inno-DB-Cluster ist als Preview verfügbar [13]. In den folgenden Evolutionsschritten der MySQL-Plattform will sich Oracle um Read-Scaleout (über zusätzliche asynchrone Read-only-Slaves) und Write-Scaleout (über Sharding) kümmern.
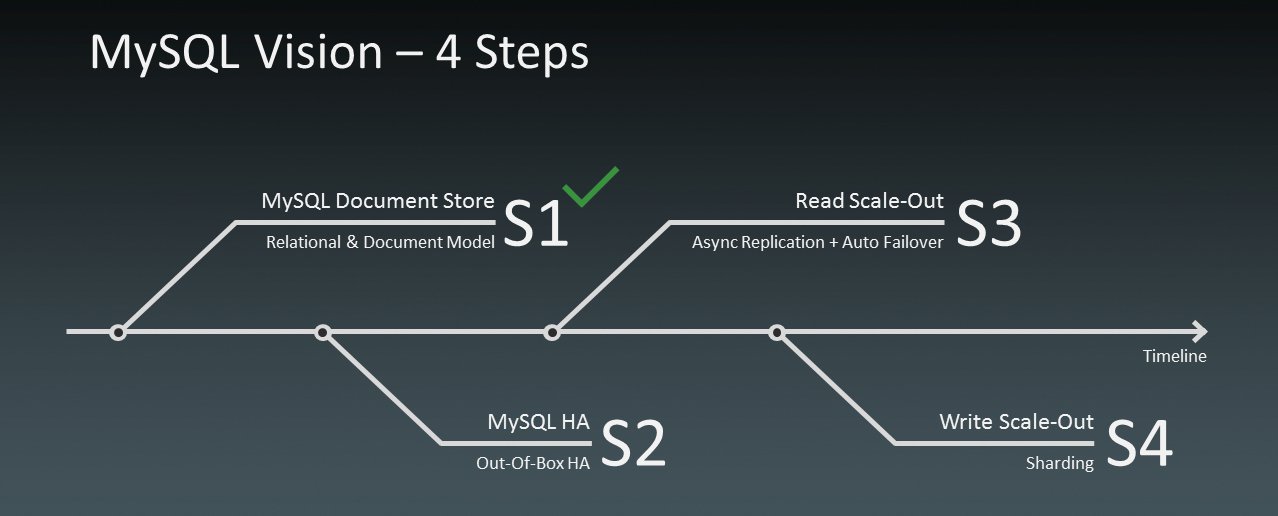
Abbildung 1: Oracles Pläne für die MySQL-Zukunft.
Infos
-
MySQL: https://www.mysql.de
-
Galera Cluster: http://galeracluster.com/products
-
Menicus-Protokoll: http://sysnet.ucsd.edu/~yamao/pub/mencius-osdi.pdf
-
Multi-Primary-Modus: http://lefred.be/content/mysql-group-replication-single-primary-or-multi-primary
-
MySQL Enterprise Backup: https://www.mysql.com/products/enterprise/backup.html
-
Percona Xtrabackup: https://www.percona.com/doc/percona-xtrabackup/2.3
-
ProxySQL: http://www.proxysql.com
-
ProxySQL: http://lefred.be/content/ha-with-mysql-group-replication-and-proxysql
-
Haproxy: http://www.haproxy.org
-
Group Replication als HA-Lösung: http://lefred.be/content/mysql-group-replication-as-ha-solution
-
MySQL Router: https://dev.mysql.com/downloads/router
-
Maria DB Maxscale: https://mariadb.com/products/mariadb-maxscale
-
Inno DB Cluster: https://labs.mysql.com





