
© DavidQ, photocase.com
Webanwendungen bestehen üblicherweise aus einem Dreigespann von Interpreter-Sprache, Datenbank und Server – unter Linux meist in Form von LAMP (Linux, Apache, MySQL, PHP/Perl/Python). Dieser Artikel schildert, wie der Autor mit C++ ein leistungsfähigeres Konzept umgesetzt hat.
Die Frage drängt sich gelegentlich auf, wie es sein kann, dass viele selbst einfache Programme trotz aktueller Hardware so langsam sind? Seit 1982 der beliebte 8-Bit-Computer C-64 auf dem Markt erschien, sind 25 Jahre Mooresches Gesetz vergangen. Derzeit gehandelte Prozessoren sind sicherlich um den Faktor 50 000 schneller als die von damals. Bei der gefühlten Geschwindigkeit der Software stellt sich aber eher das Gefühl eines Rückschritts ein.
Die Klasse der Webanwendungen zum Beispiel: Ist es wirklich unumgänglich, dass ein Benutzer mehr als 20 Sekunden warten muss, um beispielsweise die Startseite von Ebay zu erhalten (bei DSL mit 6 MBit/s)? Auch Open-Source-Software ist von solchen Auswüchsen nicht verschont geblieben. Wenn E-Groupware – eine an sich sehr schöne Groupware-Lösung auf LAMP-Basis – den Eingangsordner einer Mailbox anzeigt (die ersten 20 Einträge), braucht sie dafür teilweise 10 Sekunden, obwohl der IMAP-Daemon auf demselben Server läuft. Das bedeutet für den dabei verwendeten AMD-Prozessor mindestens zehn Milliarden teils 64-bittige Rechenoperationen. Bei einer Ergebnisseite von 200 KByte sind das immerhin 50 000 CPU-Befehle pro Byte der fertigen HTML-Seite – auch wenn der Vergleich etwas hinkt.
C++ statt Skripte
Es ist ja verständlich, dass heute niemand mehr Software-Entwicklung in handoptimierter Maschinensprache bezahlen will. Aber mit einem aktuellen Compiler ist C++ fast genauso schnell. Wenn man jetzt noch auf das langwierige Speichern von Daten in einer SQL-Datenbank verzichtet und alle Daten einfach im Hauptspeicher hält, dann müsste es doch machbar sein, mit nicht allzu großem Aufwand eine sehr schnelle Webanwendung zu entwickeln.
Nach diesen Überlegungen und einem guten Maß an Neugier reifte ein konkretes Konzept für die Umsetzung der Idee “LAMP ohne AMP” (LOA), die dieser Artikel vorstellt. Praktisch ist die Idee in der Tauschzone-Site [1] umgesetzt, einer kostenlose Tauschplattform für Waren und Dienstleistungen, die seit Januar 2007 online ist und sich seitdem stetigen Zulaufs erfreut (Abbildung 1)
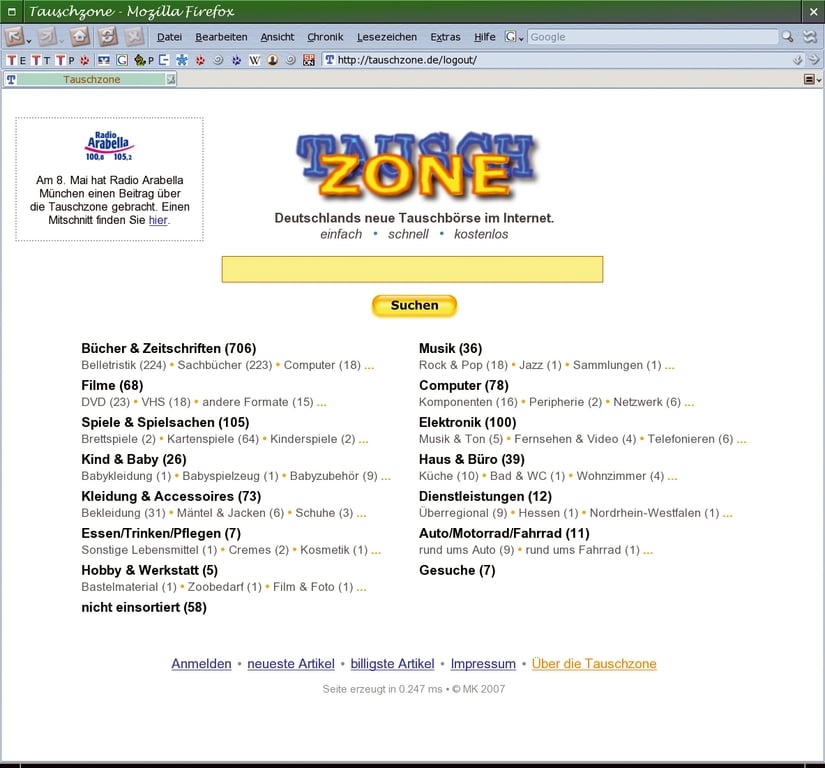
Abbildung 1: Bei der Tauschzone hat der Autor die hier vorgestellten Programmiertechniken angewandt.
Datenhaltung
Der erste und wichtigste Schritt bei LOA ist, sich möglichst genau über die Daten Gedanken zu machen, um die es gehen soll. Immerhin muss das Programm ja alle Daten quasi von Hand im Hauptspeicher verwalten, und zwar in Form von C++-Objekten. Listing 1 zeigt ein Beispiel für den fiktiven Datensatz eines Tauschzone-Artikels mit einer eindeutigen ID, einem Titel, einer Beschreibung, einem Preis in der Tauschwährung und einem Anbieter.
|
Listing 1: Artikeldatensatz, |
|---|
01 class Article
02 {
03 unsigned _id;
04 string _title;
05 string _description;
06 unsigned _price;
07 User *_owner; // direkter Zeiger auf Besitzer
08
09 public:
10 // Konstruktor
11 Article(unsigned id, char *title, char *descr,
12 unsigned price, User *owner);
13
14 // Zugriffsfunktionen (hier gekürzt)
15 char *title() { return _title.c_str(); };
16 setTitle(char *t) { _title = t; };
17
18 // Persistenz: Binärdarstellung in Datei schreiben
19 streamToFile(int fd);
20 };
|
|
Listing 2: Datensatz |
|---|
01 // Datentypen von Indizes:
02
03 std::map<id, Article *> _articlesById;
04 std::set<Article, less_than_cheap> _articlesByPrice;
05
06 Engine::createArticle(char *title, char *descr,
07 unsigned price, User *owner)
08 {
09 unsigned id = nextArticleId();
10 Article *art = new Article(id, title, descr, price, owner);
11
12 // ID-Index einfügen
13 _articlesByID.insert(make_pair(id, art));
14
15 // Index für billigste Artikel pflegen
16 _articlesByPrice.insert(art);
17 }
|
Wichtig dabei ist, sich Gedanken darüber zu machen, wie man die richtigen Datensätze schnell finden kann. Sind mehrere Millionen Datensätze eines Typs linear zu durchsuchen, um den gewünschten Satz zu finden, dann ist die wertvolle Rechenzeit schnell verschwendet. Daher muss jeder Zugriff über eine Indexstruktur gehen, die ein schnelles Auffinden des gewünschten Datensatzes ermöglicht. Dabei braucht jede Art des Zugriffs eine eigene Struktur.
Die Tauschzone verwaltet zunächst einmal Benutzerdaten. Jeden Benutzer speichert sie als C++-Objekt, das Datenfelder für Anmeldename, Passwort, E-MailAdresse und andere Angaben besitzt. Wenn nun ein Surfer in der Anmeldemaske Name und Passwort eingibt, muss die Software aus allen Benutzern den richtigen Datensatz anhand des Anmeldenamens finden. Damit dies effizient geschieht, können die Benutzer zum Beispiel in einem binären Suchbaum gespeichert sein, der den Anmeldenamen als Schlüssel verwendet.
Die Implementierung eines solchen Baums bietet die Bibliothek STL (Standard Template Library) in Form der Klassen »set« oder »map«. Bei 100 000 Benutzern sind bei einer linearen Suche im Schnitt 50 000 Vergleiche notwendig. Bei Verwendung eines Binärbaums, der ausreichend balanciert ist, genügen maximal log2 100 000, also 17 Vergleiche.
Doppelte Buchführung
Bei der Registrierung eines neuen Benutzers gibt dieser seine E-Mail-Adresse an. Eine weitere Suche nach der Adresse prüft, ob sie nicht bereits von einem anderen Konto verwendet wird. Deswegen ist ein weiterer Suchbaum erforderlich. Um die Benutzerdaten nicht doppelt zu speichern, führt dieser Baum nur einen Zeiger auf das eigentliche Benutzerobjekt. Dieses Verfahren verwendet man auch bei SQL-Datenbanken und spricht vom Primärindex und den Sekundärindizes. Nur dass die Suchbäume dort auf der Festplatte und nicht im Hauptspeicher abgelegt sind.
Natürlich bedeutet es etwas Programmierarbeit, alle benötigten Indizes zu pflegen. Das betrifft nicht nur das Anlegen und Löschen von Datensätzen. Auch beim Ändern von Werten, zu denen es einen Index gibt, muss die Webanwendung diesen aktualisieren. Ändert ein Benutzer seine E-Mail-Adresse, muss der Eintrag vor der Änderung aus dem Mailindex entfernt und danach mit dem neuen Wert wieder eingefügt werden.
Wer suchet …
Listing 2 zeigt ab Zeile 6 die Funktion »createArticle()« der Klasse »Engine«, die einen Tauschartikel anlegt. Im Beispiel pflegt sie zwei Indizes, und zwar »_articlesByID« für das Finden eines Artikels nach der ID (Zeile 13) sowie »_articlesByPrice« für das schnelle Finden der billigsten Artikel (Zeile 16).
Zwischen den verschiedenen Datensatztypen gibt es Beziehungen. So hat jeder Artikel einen Eigentümer »owner«. Relationale Datenbanken bilden Beziehungen eines Datensatzes zu einem anderen über den Primärschlüssel. Bei den Tauschzone-Benutzern wäre das der Anmeldename. Bei LOA gibt es aber immer noch als zweite Möglichkeit das Speichern eines direkten C++-Zeigers auf den Datensatz. Dieser braucht nur wenig Speicherplatz und kommt vor allem ohne Index aus. Der gesuchte Datensatz ist gewissermaßen nur einen CPU-Befehl weit entfernt.
Beim Einsatz einer SQL-Datenbank müsste diese erst eine Anfrage der Art »SELECT * FROM user WHERE nick= \’mathi\’« ausführen, inklusive SQL-Parser, Datenübertragungen, Konvertierungen und vielem mehr. In Listing 1 findet sich mit »_owner« ein direkter Zeiger vom Artikel auf den Benutzer.
Datenpersistenz
An dieser Stelle drängt sich der Einwand auf, dass trotzdem die Daten irgendwie persistent auf der Platte liegen sollen. Auch wenn Linux noch so stabil läuft und die Hardware sicher vor Ausfällen wäre – spätestens bei einem Software-Update ist ein Neustart notwendig.
Die Datenspeicherung ist ein wichtiger Teil von LOA, sozusagen das Filetstück. Das an sich einfache Konzept hat erstaunliche Vorteile, wie später zu sehen sein wird. Die Idee: Da Lesezugriffe grundsätzlich aus dem Hauptspeicher bedient werden, müssen die Daten auf der Festplatte nicht für schnelles Lesen optimiert sein. Daher kann LOA alle Daten einfach sequenziell in eine Datei schreiben, die Persistenzdatei.
Für jeden Datensatztyp definiert der Entwickler ein binäres Format. Bei jeder Neuanlage oder Änderung eines Datensatzes, hängt er ihn in Binärform hinten an die Persistenzdatei an. Beim Löschen platziert er einfach einen Löschvermerk dahinter. Den prinzipiellen Aufbau des im Tauschzone-Projekt verwendeten Binärformats zeigt der Kasten “Binär gespeichert”.
|
Binär |
|---|
|
Abbildung 2 zeigt den Aufbau des in der Tauschzone verwendeten Binärformats. Folgende vier Chunk-Typen sind definiert:
Für jeden Datensatztyp (Benutzer, Artikel) und für jedes Feld des Satzes gibt es einen Unterchunk-Typ, zum Beispiel »AC_ID« für die Artikel-ID und »UC_EMAIL« für die E-Mail-Adresse eines Benutzers. Die Strings sind so aufzufüllen, dass alle Chunks an 4-Byte-Grenzen ausgerichtet sind. Abbildung 3 zeigt die Datenstruktur bei der Änderung des Titels von Artikel Nummer 4711.  Abbildung 2: Das Binärformat der Tauschzone. 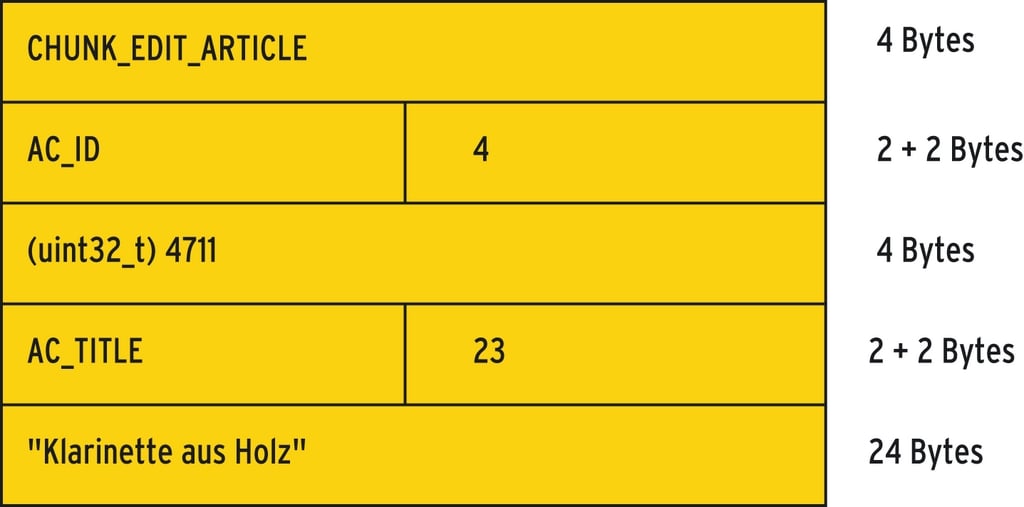 Abbildung 3: Datenstruktur beim Ändern des Titels von Artikel 4711. |
Damit die Datei nicht unentwegt wächst, ist regelmäßig ein Bereinigen von veralteten und gelöschten Datensätzen nötig. Dazu legt das Programm einfach eine neue Persistenzdatei an und schreibt alle Datensätze einmal komplett heraus. Bei einem Neustart liest es die Persistenzdatei von Anfang an sequenziell ein und baut alle Datensätze im Hauptspeicher auf. Dabei werden auch in der Datei vorhandene Änderungen und Löschungen nachvollzogen. Die Hauptspeicher-Datenbank macht sozusagen im Eiltempo die komplette Änderungsgeschichte seit der letzten Bereinigung durch.
Replikation und Onlinesicherung geschenkt
Dies mag zunächst nach einer sehr langwierigen Operation aussehen. Da LOA aber mit Binärformaten arbeitet und eine sehr effiziente Verwaltung der Daten im Speicher verwendet, liegen die Zeiten selbst bei GBytes an Daten lediglich im Bereich von einigen Minuten. Die Tauschzone speichert in 4 GByte etwa eine Million Artikel.
So einfach das Speicherkonzept auf den ersten Blick wirken mag, so vielfältig sind die Vorteile, die sich aus dieser Lösung ergeben:
- Die Persistenz kostet kaum CPU-Zeit – und auch das nur
bei Änderungen. Das Schreiben der Daten auf Platte kann zudem
asynchron geschehen. Somit blockiert es nicht den
Hauptprozess. - Im laufenden Betrieb lässt sich jederzeit ein Snapshot der
Daten anlegen. Dazu verwendet man die gleiche Funktion wie beim
Bereinigen. Der Snapshot kann auf einem anderen System sofort
gestartet werden (zum Beispiel zu Testzwecken). - Der LOA-Server kann parallel in zwei Dateien oder sogar
TCP-Kanäle schreiben. Auf diese Art erledigt die Tauschzone
online über SSH kontinuierlich ihr Backup. - Wenn ein LOA-Server seine Daten über TCP schreibt, kann
ein zweiter Server sie kontinuierlich einlesen und in seine
Datenbank einpflegen. Verhindert man bei diesem Schreibzugriffe,
entsteht ein Online-Replikat, das stets mit dem ersten Server
identisch ist. Es kann entweder zur Lastverteilung dienen oder bei
einem Ausfall des ersten Servers diesen ersetzen (Abbildung
4).
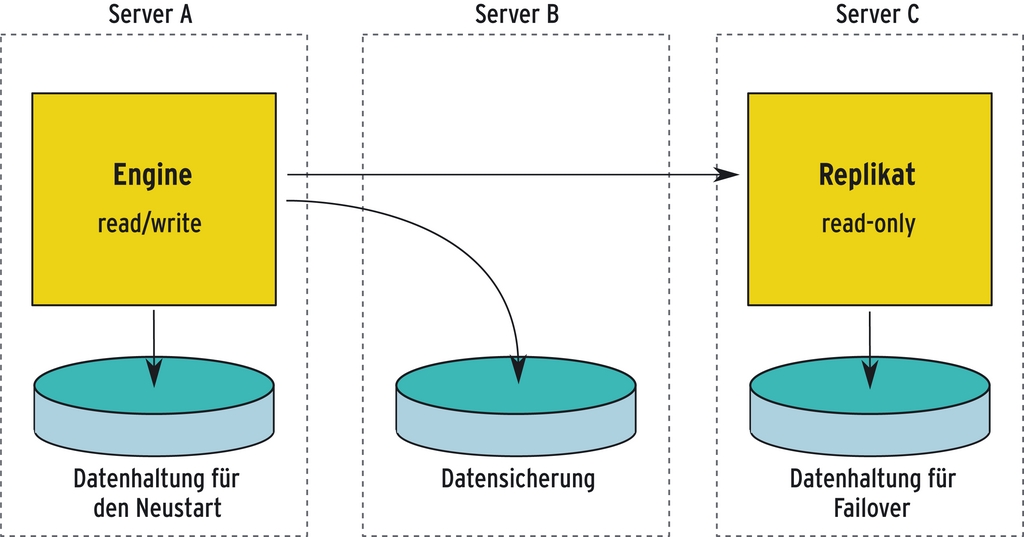
Abbildung 4: Mögliches Schema für die Replikation der im Speicher gehaltenen Daten.
Gerade die beiden letzten Punkte beschreiben Funktionen, die bei relationalen Datenbanken viel Geld und Administrationsaufwand kosten.
HTTP-Server weg
Nachdem aus LAMP nun das M und das P verschwunden sind, muss konsequenterweise noch das A folgen, nämlich der HTTP-Server Apache. Bei LOA ist er ein Bestandteil des Serverprozesses. Dessen Implementierung für die Tauschzone ist überraschend schlank ausgefallen, obwohl alle wichtigen Komponenten vorhanden sind.
Der HTTP-Server (Klasse »HTTPServer«) hört auf TCP-Port 80 und verteilt Anfragen (also durch »accept(2)« erhaltene Verbindungssockets) an einen Pool von Threads der Klasse »ClientConnection«. Jeder wartet, bis er vom Server die nächste Verbindung zugeteilt bekommt, holt dann geduldig die HTTP-Anfrage vom Browser auf der anderen Seite des Netzes und bereitet sie in Form eines Objekts vom Typ »HTTPRequest« auf. Der Pseudocode aus Listing 3 skizziert die Implementierung.
|
Listing 3: |
|---|
01 // Hauptschleife von Webserver
02 HTTPServer::serve()
03 {
04 // Threads für die Verbindungen erzeugen
05 for (int i=0; i<NUM_THREADS; i++) {
06 createClientThread();
07 }
08
09 int s = openTCPSocket(80); // auf Port 80 hören
10 int client;
11 while (true)
12 {
13 // Systemcall accept() wartet auf nächste Clientverbindung
14 client = accept(s);
15 // Filedescriptor in Warteschlange stopfen
16 pushConnection(client);
17 }
18 }
19
20
21 // Hauptschleife von Thread
22 ClientConnection::run()
23 {
24 while (!should_terminate)
25 {
26 // nächste Clientverbindung aus Warteschlange holen
27 // (blockiert, solange Warteschlange leer ist)
28 int fd = server->getConnection();
29
30 // HTTP Header von Socket lesen und parsen
31 HTTPRequest request(fd);
32
33 // HTML Objekt erzeugen zum Speichern des Ergebnisses
34 HTML html;
35
36 // Seite von Engine berechnen lassen
37 engine->processRequest(request, html);
38
39 // Ergebnis an Client zurückschreiben
40 writeHTTPHeader(request, fd);
41 write(fd, html.buffer(), html.length();
42
43 // Verbindung zum Client schließen
44 close(fd);
45 }
46 }
|
Nach dem Empfangen kann die Engine den Request bearbeiten. Sie ist gewissermaßen Datenbank und Seitengenerator in einem. Sie generiert HTML-Code in Form eines Objekts vom Typ »HTML«, das einen Puffer für die Aufnahme des HTML-Code kapselt. Ist die Engine fertig, kann der Thread das Ergebnis in einem Rutsch an den Browser zurücksenden. Damit es keine Probleme mit der Datenkonsistenz gibt, darf allerdings immer nur ein Thread gleichzeitig die Engine benutzen.
Schneller als SQL
Listing 4 zeigt, wie die Engine anhand von Bestandteilen der URL in verschiedene Funktionen verzweigt, die jeweils eine Art Seite generieren. Das Beispiel der Artikelseite (Funktion »pageArticle«) demonstriert, wie sich der Artikel anhand seiner ID im Index »articleById« auffinden lässt. Danach stehen alle Daten des Artikels direkt über das Objekt »art« zur Verfügung.
|
Listing 4: Seitengenerierung |
|---|
01 Engine::processRequest(HTTPRequest &request, HTML &html)
02 {
03 // Dafür sorgen, dass nur ein Thread die Engine
04 // betritt (hier mit pthread-Mechanismen gelöst)
05 pthread_mutex_lock(&_mutex);
06
07 // Kein Verzeichnis -> index.html
08 if (request.numDirs() == 0)
09 pageIndex(request, html);
10
11 // 1. Pfadkomponente unterscheidet Art der Seite
12 else if (!strcmp(request.dir(0), "art"))
13 pageArticle(request, html); // Artikelseite
14
15 else if (!strcmp(request.dir(0), "search"))
16 pageSearch(request, html); // Suchabfrage
17
18 else
19 pageUnknown(request, html); // Unbekannte Seite
20
21 // Zugang zur Engine wieder freigeben
22 pthread_mutex_unlock(&_mutex);
23 }
24
25
26 // Artikelseite, exemplarisch
27 Engine::pageArticle(HTTPRequest &request, HTML &html)
28 {
29 // Artikelnummer ist 2. Pfadkomponente, z.B. /art/1829/
30 int artid = atoi(request.dir(1));
31
32 // Finde Artikel in Suchindex
33 Article *art = articleById(artid);
34 if (art) {
35 // HTML-Kopf mit Seitentitel erzeugen
36 html.addPageHeader(art->title()); // Titel des Artikels
37
38 // Inhalt der Seite anhand der Daten aus dem Objekt art
39 html.add("Beschreibung: %s<br>n", art->description());
40 html.add("Anbieter: %s<br>n", art->owner->fullname());
41
42 // Seitenfuss und HTML-Abschlusscode
43 html.addPageFooter();
44 }
45 else // Artikel nicht gefunden
46 pageUnknown(request, html);
47 }
|
Das ist nicht nur einfacher und übersichtlicher als bei der Programmierung mit einer SQL-Datenbank, sondern auch um Größenordnungen schneller. Tabelle 1 beweist mit den verwendeten C++-Klassen die überschaubare Komplexität der HTTP-Implementierung.
|
Tabelle 1: |
|---|
|
|

Die Ernte
Um zu beurteilen, ob die gemachten Anstrengungen wirklich der Mühe wert waren, hat der Autor in die Klasse »ClientConnection« eine Zeitmessung integriert, um die Dauer für die Generierung der Antwortseiten zu protokollieren. Die Zeit für den Datentransfer bleibt unberücksichtigt, da sie von der Netzwerkverbindung zum Client bestimmt ist.
Unglaublich
Ein erster Versuch mit der C-Funktion »ftime(3)« ließ den Autor zunächst an einen Programmierfehler glauben: Die gemessene Zeit war meist 0, manchmal 1 (also 1 Millisekunde). Erst eine Messung mit »gettimeofday(2)«, die in Mikrosekunden auflöst, brachte die volle Wahrheit zu Tage.
Das Ergebnis kann jedermann auf »www.tauschzone.de« live bestaunen. Jede Seite gibt zu diesem Zweck am Seitenende die Generierungszeit aus. Bei einfachen Seiten liegt sie deutlich unter 100 Mikrosekunden. Sehr komplexe Seiten genehmigen sich etwa 400 Mikrosekunden. Der Schnitt liegt bei rund 250 Mikrosekunden. Das bedeutet eine Rate von 4000 Seiten pro Sekunde! Und das auf einem preisgünstigen, zwei Jahre alten Mietserver.
Um das Verhalten auch bei großen Datenmengen zu untersuchen, hat der Autor eine Testfunktion geschrieben, die in der Tauschzone zufällige Artikel einstellt. Selbst bei etlichen hunderttausend Artikeln war keine nennenswerte Verlangsamung festzustellen. Das lässt ahnen, welches Potenzial sich erschließt, wenn man noch weitere Optimierungsmöglichkeiten ausschöpft, zum Beispiel einen besser optimierenden Compiler, effizientere Datenstrukturen als die der STL oder die oben skizzierte Lastverteilung auf mehrere Server.
Wenn die Voraussetzungen für LOA gegeben sind (überschaubare Menge an Datentypen, ausreichend RAM, um alle Daten im Hauptspeicher zu halten), lassen sich mit dieser Methode sensationell kurze Antwortzeiten und hohe Durchsätze erzielen.
Aufwändiger, dafür schneller
Der Mehraufwand steckt in der sorgfältigen Anlage der Datenstrukturen und der Speicherung im Binärformat sowie einem rudimentären HTTP-Server. Im Gegenzug erspart LOA die Anbindung an eine Datenbank und den damit verbundenen Programmieraufwand, da die Daten direkt in C++-Variablen zur Verfügung stehen.
Die Datenpersistenz nach Stream-Art ermöglicht kontinuierliche Datensicherung und Online-Replikation nebenbei. Und nicht zuletzt: Die Unabhängigkeit von fremder Software macht die eigene Anwendung immun gegen Fehler anderer und Versionsunterschiede. (ofr)
|
Infos |
|---|
|
[1] Tauschzone-Site: [http://www.tauschzone.de] |
|
Der Autor: |
|---|
|
Mathias Kettner war früher Entwickler bei Suse und ist seit 2000 selbstständiger Linux-Berater und -Dozent. |






