
© bastian-dietz, photocase.com
Kommen Umlaute in Programmtexten oder Daten ins Spiel, ist der Perl-Programmierer gefragt. Denn ohne seine Mithilfe entstünde ein Kodierungskauderwelsch.
Am Anfang war die Ascii-Tabelle: 128 Zeichen, mit denen jedermann problemlos englische Texte schreiben konnte, zusammen mit den von der Schreibmaschine bekannten Sonderzeichen wie »%« oder »$« und natürlich auch mit den Kontrollzeichen wie Zeilenumbruch, Seitenvorschub oder Terminalklingel. Als dann später einige Europäer die in ihren Sprachen heimischen Sonderzeichen einbringen wollten, wurden die einfach in die nächsten 128 Zeichen gepresst. Alle 256 Zeichen ließen sich auf diese Weise von 0 bis 255 durchnummerieren und auf dem Computer mit 8 Bits (1 Byte) kodieren.
Der ISO-8859-Standard oder salopper: Latin-1 war damit geboren. Zuerst als ISO-8859-1, aber mit der Zeit kamen weitere Varianten hinzu. Die bislang letzte Version ist ISO-8859-15, die auch das Eurozeichen enthält. Übrigens verwenden die meisten gegenwärtig Dienst tuenden Webbrowser nicht den ISO-8859-1-Standard zur Dekodierung, selbst wenn es der Webserver verlangt. Stattdessen arbeiten sie nach dem Windows-1252-Standard, der noch einige zusätzliche Zeichen und wie ISO-8859-15 das Eurozeichen definiert.
Alle wollen mitspielen
Bald wollte die restliche Welt teilhaben und die Computer sollten auch ihre zum Teil voluminösen Zeichensätze darstellen. Dazu erfanden Normierungsgremien Kodierungsschemata für asiatische Schriften wie Shift-JIS und BIG5. Aber bald erwies sich das als eine Sackgasse und das Unicode Consortium erfand die gleichnamige Kodierung: eine riesige Tabelle, die alle gängigen Zeichen aller Weltsprachen enthält.
Ein Weg, die Unicode-Tabelle auf dem Computer effektiv darzustellen, ist der UTF-8-Standard. Denn hätten herkömmliche Ascii-Zeichen plötzlich durchgehend mit zwei oder gar vier Bytes kodiert werden müssen, wäre der Platzbedarf sprunghaft angestiegen. Um die Zeichen der alten Ascii-Tabelle weiterhin mit nur einem Byte darstellen zu können, ist die UTF-8-Tabelle so angelegt, dass die ersten 128 Zeichen genau der Ascii-Tabelle entsprechen.
Die zweite Hälfte der untersten 256 Zeichen besteht jedoch zum Teil aus speziellen Maskierungs-Codes, die anzeigen, dass nach ihnen noch eine definierte Anzahl weiterer Codes folgt, die zusammen das darzustellende Zeichen aus der Unicode-Tabelle eindeutig festlegen. Zum Beispiel ist der Umlaut ü in der ISO-8859-15-Tabelle unter der Nummer 252 (»0xFC«) abgelegt. Liegt also ein Text in ISO-8859-15 vor und ein Byte hat den Wert »0xFC«, dann ist klar: Dieses Zeichen ist ein ü.
A mit Welle
Die UTF-8-Kodierung hingegen stellt den Umlaut ü mit den beiden Bytes 195 und 188 (»0xC3« und »0xBC«) dar. Liegt ein Text in UTF-8 vor und der Computer stößt erst auf einen Bytewert von »0xC3« gefolgt von »0xBC«, ist hier ebenso klar: Dort steht der Buchstabe ü.
Ist jedoch die Kodierung eines Bytestroms nicht bekannt und der Computer findet ein Byte mit dem Wert »0xC3«, dann stellt sich die Frage: Ist dies das erste Byte eines westeuropäischen Umlauts im UTF-8-Format? Oder ist das Byte nach ISO-8859-15 zu interpretieren und stellt alleine bereits die vollständige Kodierung eines Zeichens dar?
Wird das einleitende Byte »0xC3« einer UTF-8-Sequenz fälschlicherweise nach ISO-8859-15 interpretiert, kommt ein Zeichen zum Vorschein, das leidgeplagte Programmierer, die zwischen den Kodierungswelten wandeln, bis zum Überdruss kennen: das A mit Welle.
Dieses in Abbildung 1 gezeigte Zeichen kommt zwar nach [2] in der portugiesischen, vietnamesischen und der kaschubischen Schrift vor. Wer jedoch normalerweise nicht in diesen Gefilden operiert, aber ein A mit Welle erblickt, arbeitet wahrscheinlich mit einem in UTF-8 kodierten Text, der irrtümlich nach ISO-8859-15 interpretiert wurde.

Abbildung 1: In einem auf ISO-8859-15 eingestellten Terminal funktioniert die Ausgabe in Latin1, die Ausgaben nach UTF-8 ergeben Kaschubisch.
Terminal muss mitspielen
Ein Terminal, das die Textausgabe eines Programms auf den Bildschirm bringt, muss ebenfalls wissen, wie der vom Programm ausgesandte Bytestrom zu interpretieren ist, und dann die für die Anzeige geeigneten Zeichen finden. Um ein X-Terminal mit UTF-8-Unterstützung zu starten, empfiehlt es sich, »xterm« mit den Optionen »-u8 +lc« aufzurufen. Die Option »-u8« schaltet UTF-8 an, »+lc« schaltet die Interpretation von Umgebungsvariablen wie »LANG« ab, damit diese Einstellung nicht dazwischenfunken kann.
Um im anderen Fall ein Terminal im ISO-8859-15-Modus zu öffnen, ruft die folgende Codezeile »xterm« extra mit der gesetzten Environment-Variablen »LANG« auf:
LANG=en_US.ISO-8859-15 xterm
Die Abbildungen 1 und 2 zeigen die Ausgabe zweier Perl-Skripte in einem ISO-Terminal sowie in einem UTF-8-Terminal. Ein einzelnes Byte mit dem Wert »0xFC« interpretiert das rote ISO-Terminal korrekt als »ü«. Aus der UTF-8-Sequenz »0xC3BC« hingegen macht es ein A mit aufgesetzter Tilde und der ISO-Darstellung des Code »0xBC«, dem Zeichen für »1/4«. Das grüne UTF-8-Terminal in Abbildung 2 zeigt ein einzelnes Byte mit dem Wert »0xFC« hingegen nicht an. Erwartungsgemäß wird die UTF-8-Sequenz »0xC3BC« korrekt zu einem »ü« dekodiert.

Abbildung 2: In einem auf UTF-8 eingestellten Terminal funktioniert die Ausgabe in UTF-8, aber in ISO-8859-15 kodierte Zeichen bleiben unsichtbar.
Latein als Normalfall
Gibt man nichts explizit vor, interpretiert Perl den Sourcecode eines Skripts einschließlich aller Strings, regulärer Ausdrücke, Variablen- und Funktionsnamen nach dem Standard ISO-8859-1. Wer den Code in Listing 1 mit einem Editor eintippt, der auf ISO-8859-1 eingestellt ist, findet das ü im Programmtext als »0xFC« vor, wie sich leicht mit dem Utility »hexdump« feststellen lässt (siehe Abbildung 3).
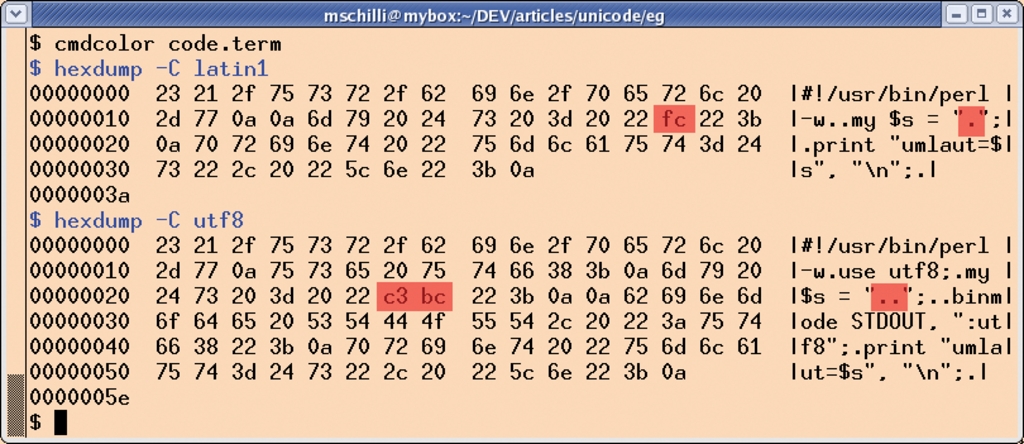
Abbildung 3: In einem in ISO-8859 geschriebenen Perl-Skript wird das Zeichen ü im Sourcecode als »0xFC« kodiert. Ist der Sourcecode in UTF-8 kodiert, erscheint das ü hingegen als Bytesequenz »0xC3BC«.
Listing 2 hingegen ist mit dem bekannten Editor »vim« und der Einstellung »set encoding=utf-8« erzeugt. Die rot markierten Stellen im Hexdump von Abbildung 3 zeigen, dass der Editor den Umlaut im String des Programmcode in diesem Fall tatsächlich mit 2 Bytes kodiert, nämlich mit den beiden Werten »0xC3« und »0xBC«.
|
Listing 1: |
|---|
01 #!/usr/bin/perl -w 02 use strict; 03 my $s = "ü"; 04 print "umlaut=$s", "\n"; |
|
Listing 2: |
|---|
01 #!/usr/bin/perl -w 02 03 use strict; 04 use utf8; 05 my $s = "ü"; 06 07 binmode STDOUT, ":utf8"; 08 print "umlaut=$s", "\n"; |
Disziplin auf ganzer Linie
Zweitens setzt Listing 2 die Line Discipline der Standardausgabe mit »binmode(STDOUT, “:utf8”)« in den UTF-8-Modus. Dies bewirkt, dass Perl Unicode-Strings im UTF-8-Format über die Standardausgabe ausgibt. So erhält das Terminal die von ihm erwarteten UTF-8-Daten und stellt sie auch ordnungsgemäß dar. Fehlt hingegen der »binmode«-Aufruf, dann versucht Perl den ausgegebenen String nach Latin-1 umzuwandeln. Auf einem ISO-8859-1-Terminal ist das sogar sinnvoll, doch auf einem UTF-8-Terminal ist das natürlich genau die falsche Strategie.
Es geht sogar komplett schief, wenn das Unicode-Zeichen nicht in Latin-1 umzuwandeln ist, wie zum Beispiel das japanische Katakana-Zeichen me mit der Unicode-Nummer »30E1«. In diesem Fall erscheint die Warnung »Wide character in print«. Eine mit »binmode(STDOUT, “:utf8”)« eingestellte Line-Discpline auf dem ausgebenden Filehandle sorgt dafür, dass Perl keinerlei Anstalten dafür macht, den Unicode-String umzuwandeln, sondern ihn roh als UTF-8 ausgibt. Nutzt jemand ein UTF-8-Terminal, ist das genau die richtige Strategie.
Nachgeblättert
Die Manualseite »man iso-8859-1« zeigt die Kodierung nach dem Latin-1-Standard an. Dort findet sich unter der oktalen Nummer 374 der Hex-Eintrag »FC« mit dem Zeichen »LATIN SMALL LETTER U WITH DIAERESIS«, also dem Umlaut ü. Um hingegen die Unicode-Tabelle aufzublättern, eignet sich die Datei »unicore/UnicodeData.txt«, die sich unterhalb des »lib«-Verzeichnisses der Perldistribution befindet (normalerweise »ls /usr/lib/perl5/5.8.x«). Dort findet sich unter der Nummer »00FC« ebenfalls ein Eintrag »LATIN SMALL LETTER U WITH DIAERESIS«.
Dem aufmerksamen Leser wird beim Studieren der Abbildung 4 auffallen, dass die Ordnungsnummer des kleinen ü in der Unicode-Tabelle exakt dem Eintrag des kleinen ü in der ISO-8859-1-Tabelle entspricht: Es ist beide Male »FC« (»FC« in ISO-8859-1 und »00FC« in Unicode), da die Ersteller der Unicode-Tabelle sich bei den untersten 256 Bytes am ISO-8859-1-Standard orientierten.
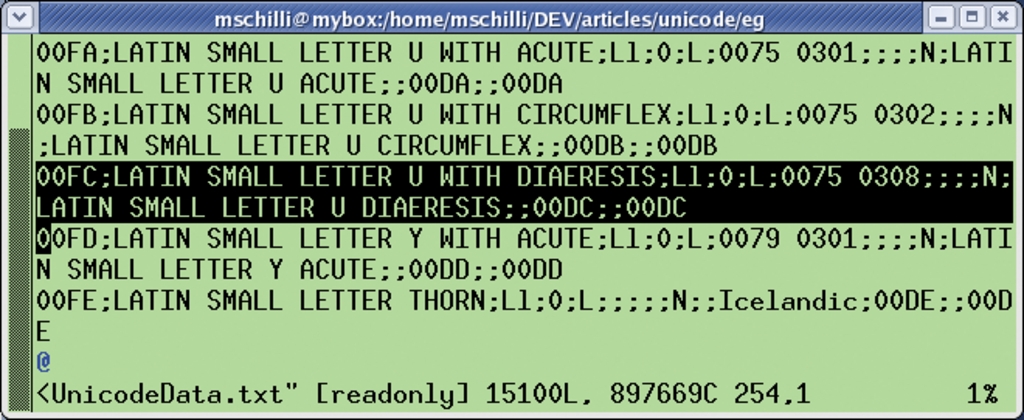
Abbildung 4: Diese Zeilen bilden den Eintrag für ü in Perls Unicode-Tabelle.
Zu beachten ist allerdings, dass die Unicode-Nummer nicht der UTF-8-Kodierung des Zeichens entspricht. So hat das ü, also das Unicode-Zeichen mit der Nummer »00FC«, die UTF-8-Kodierung »C3BC«. Wie bereits erwähnt ist UTF-8 nur ein effizientes Verfahren, die Unicode-Tabelle zu kodieren.
Keyboard ohne Umlaute
Wer kein Keyboard mit Umlauten besitzt – wie der Schreiber dieser Zeilen im fernen San Francisco -, kann sich ein ü in einem String auch über dessen Unicode-Nummer
my $s = "\x{00FC}";
eintippen. Alternativ bieten Editoren Tastenkombinationen an. Im populären Editor Vim lautet die Tastenfolge für ein kleines ü im Input-Modus [Ctrl]+[k] und danach [u] und [:]. Es ist zu beachten, dass Vim dafür mit »set encoding=utf-8« auf UTF-8 eingestellt sein muss.
Rein und raus
Liest ein Perl-Programm Daten ein oder gibt sie aus, muss der Programmierer festlegen in welchem Format die Daten vorliegen oder auszugeben sind. Um Zeilen einer als UTF-8 vorliegenden Textdatei einzulesen, kann er das genutzte Filehandle »FILE« entweder mit dem oben gezeigten »binmode«-Trick auf »:utf8« ummünzen oder die Line-Discipline gleich dem dreiparametrigen »open«-Befehl mitgeben: »open FILE, “<:utf8”, “datei.txt” …«.
Liest das Programm anschließend eine Dateizeile mit »FILE« ein und weist das Ergebnis einem Skalar zu, ist sichergestellt, dass der String ein Unicode-String ist und dass sich Perl seine interne Notiz von dieser Tatsache macht. Ohne die Line-Discipline würde Perl die Eingabe als ISO-8859-1 interpretieren und die rohen Bytes in herkömmliche String-Skalare stopfen.
Analoges gilt für die Ausgabe. »>:utf8« beziehungsweise »>>:utf8« als zweiter Parameter für »open« setzt die Line-Discipline der Ausgabe in den UTF-8-Modus und ein folgendes »print FILE $string« wird den UTF-8-kodierten String unmodifiziert ausgeben. Alternativ lässt sich auch hier das Filehandle mit dem »binmode«-Trick ummünzen.
Die letzte Hülle fällt
Listing 3 zeigt, wie Perl Unicode-Strings intern verwaltet. Wegen des gesetzten Pragma »use utf8« erkennt und verwaltet es den String »ü« (per Vim in UTF-8 eingetippt) als Unicode-String. Hierzu setzt Perl ein internes Flag, das sich mit dem Modul Encode abfragen (»is_utf8()«) und manipulieren (»_utf8_off()«) lässt. Die Ausgabe von »peek« in Abbildung 5 zeigt, dass der UTF-8-String tatsächlich die Länge 1 aufweist.
|
Listing 3: |
|---|
01 #!/usr/bin/perl -w
02 use strict;
03 use utf8;
04 use Data::Hexdumper;
05 use Encode qw(_utf8_off is_utf8);
06
07 my $s = "ü";
08
09 if( is_utf8($s) ) {
10 print "UTF-8 flag is 'on'.\n";
11 }
12
13 print "Len: ", length($s), "\n";
14 _utf8_off($s);
15 print "Len: ", length($s), "\n";
16
17 print hexdump(data => $s), "\n";
|
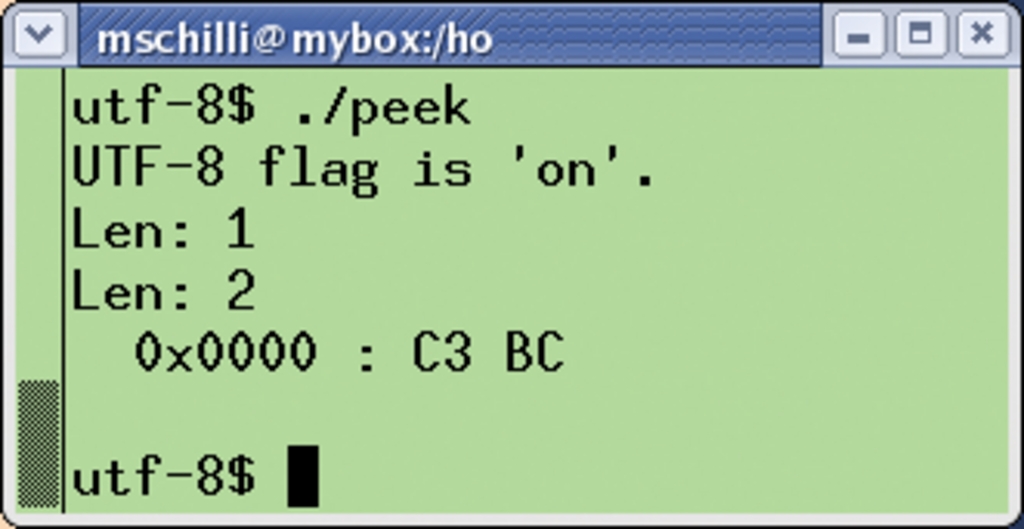
Abbildung 5: In einem Unicode-String hat ein Multi-Byte-Zeichen tatsächlich die Länge 1. Wird dem String die Unicode-Eigenschaft entzogen, interpretiert Perl ihn Byte für Byte.
Wenn jemand das Flag mit »_utf8_off()« löscht, ist der String plötzlich zwei Zeichen lang. Die Ausgabe mit dem CPAN-Modul Data::Hexdumper zeigt, dass der String intern als »0xC3BC« gespeichert wird, und das ist – Trommelwirbel – tatsächlich UTF-8.
Sagt ISO-8859-1, meint Windows-1252
Listing 4 zeigt, wie ein CGI-Skript dem Browser nach ISO-8859-1 kodierten Text verspricht und dann ein Eurozeichen mit dem Code 0x80 schickt, der dem Windows-1252-Standard entspricht. Wie aus der Abbildung 6 ersichtlich, gibt sich der Browser jedoch kulant und zeigt das Eurozeichen tatsächlich an. Hätte das Serverskript stattdessen im vorauseilenden Header ISO-8859-15 signalisiert, stünde ein schwarzes Fragezeichen statt des Euro auf der vom Browser dargestellten Seite. In der ISO-8859-15-Tabelle hat der Euro nämlich den Code 0xA4. Sobald sich der CGI-Code dahingehend verändert, zeigt der Browser das Eurozeichen wieder korrekt an.
|
Listing 4: |
|---|
01 #!/usr/bin/perl -w 02 use strict; 03 use CGI qw(:all); 04 05 print header( 06 -type => 'text/html', 07 -charset => 'iso-8859-1'); 08 09 print "The Euro sign is ", 10 chr(0x80), ".\n"; |
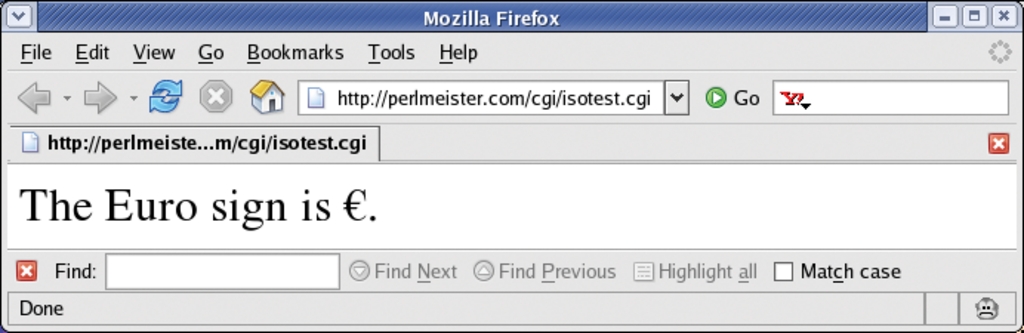
Abbildung 6: Der Browser zeigt das Eurozeichen korrekt an, obwohl ihm der Seitenquelltext nicht wie versprochen ISO-8859-1-kodiert, sondern im Windows-1252-Standard übermittelt wurde.
Nicht so nachsichtig
Perls Webclient-Bibliothek LWP gibt sich allerdings nicht so kulant. Den Serverteil zeigt Listing 5, das den Text ordnungsgemäß als UTF-8 schickt und auch den Header der Antwort richtig setzt. Das Eurozeichen im String wird hier durch seine Unicode-Ordnungsnummer »x{20AC}« angegeben.
|
Listing 5: |
|---|
01 #!/usr/bin/perl -w
02 use strict;
03 use CGI qw(:all);
04
05 print header(
06 -type => 'text/html',
07 -charset => 'utf-8');
08
09 binmode STDOUT, ":utf8";
10 print "The Euro sign is ",
11 "\x{20AC}.\n";
|
Auf der Client-Seite einer Webapplikation gibt es ebenfalls eine Reihe von Dingen zu beachten, wenn der vom Server kommende Webseitentext in UTF-8 kodiert ist. Ziel der Maßnahmen ist es, das Dokument mit der LWP-Bibliothek vom Webserver zu holen und den Inhalt im Erfolgsfall in einem Unicode-String in Perl abzulegen. Listing 5 zeigt das dafür erforderliche Verfahren.
Wegen eines offenen Bugs in der LWP-Bibliothek (genauer HTML::HeadParser) wirft Perl bei zurückkommendem UTF-8 die unschöne Warnung »Parsing of undecoded UTF-8 will give garbage when decoding entities« aus, was sich nach Angaben in [4] aber durch die Option »parse_head => 0« im Konstruktoraufruf des User Agent vermeiden lässt.
Sonderbehandlung
Damit Perl den zurückkommenden UTF-8-Text in einem Unicode-String ablegt, extrahiert Listing 6 den Seitentext nicht mit der sonst üblichen Methode »content()« aus dem HTTP::Response-Objekt, sondern benutzt stattdessen »decoded_content()«. Die zweite Methode konsultiert im Unterschied zur ersten für die Dekodierung das vom Webserver im Header mitgeschickte »charset«-Feld. Achtet schließlich der Client auch noch auf die Line-Discipline für »STDOUT«, dann steht der ordnungsgemäßen Ausgabe auf einem Terminal im UTF-8-Modus nichts mehr im Wege.
|
Listing 6: |
|---|
01 #!/usr/bin/perl -w
02 use strict;
03 use LWP::UserAgent;
04
05 my $ua = LWP::UserAgent->new(
06 parse_head => 0
07 );
08
09 my $resp = $ua->get(
10 "http://perlmeister.com/cgi/isotest.cgi");
11
12 if($resp->is_success()) {
13 my $text = $resp->decoded_content();
14 binmode STDOUT, ":utf8";
15 print "$text\n";
16 }
|
Historisch bedingt ist also das Wandeln zwischen mehreren Kodierungswelten keine ganz einfache Sache. Wer die Verfügbarkeit seiner Software jedoch nicht künstlich auf die Hälfte des Marktes beschränken will, sollte seine Internationalisierungsstrategie anpassen. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2006/07/Perl] [2] “The Mystery of the Double-Encoded UTF8”: [http://blog.360.yahoo.com/blog-8_S91Lc7dKj4rz8iueEaVlexawc_ZFVpd4JK?p=16] [3] Windows-1252: [http://en.wikipedia.org/wiki/Windows-1252] [4] Offener LWP-Bug bei UTF-8-kodierten Webseiten: [http://www.mail-archive.com/libwww@perl.org/msg06330.html] |
|
Der Autor |
|---|
|
|







