© Pei Ling Hoo, 123RF
Die Orient DB eignet sich als flexibles Backend zum Speichern und Abfragen von Graphenstrukturen. Doch welche Vorteile sind damit verbunden? Was kann eine NoSQL-Graph-DB besser als eine relationale Datenbank? Zeit für einen Blick auf die Details.
Lange Zeit galten relationale Datenbanken als Nonplusultra. Dafür musste deren Benutzer allerdings alle Datenmodelle in das Tabellenkonzept pressen. Das erwies sich in den letzten Jahren aber zunehmend als zu starr. Wo es zum Beispiel darum geht, die Beziehungen von Objekten untereinander zu speichern, ist mit Tabellen keine einfache und elegante Lösung möglich.
Datenbankkonzepte wie Dokument- und Graphdatenbanken etablierten sich als Alternative unter dem Schlagwort “Not Only SQL” (NoSQL). Ein Vertreter dieser Zunft ist die Orient DB, ein Datenbankserver, der sowohl als Dokument- wie als Graphdatenbank nutzbar ist.
Dieser Artikel demonstriert ein paar Möglichkeiten der Orient DB, die sich mit klassischen relationalen Datenbanken nicht umsetzen lassen. Das liegt an der vollkommen anderen Art und Weise, mit der die Datenbank ihre Daten ablegt. Abbildung 2 zeigt einen Vergleich: Relationale Datenbanken halten alle Daten in Tabellen, dort gibt es eine Spalte für jedes Attribut. Die Tabellen stellen zur Laufzeit ein starres Schema dar, zusätzliche Attribute erfordern entweder eine Anpassung der bestehenden Tabellen oder gar die Definition einer zusätzlichen Tabelle. Beides bringt einen Eingriff durch den Datenbankadministrator mit sich, gegebenenfalls sogar eine Migration der ganzen Datenbank.
Abbildung 2: Der Beispielgraph für die Abfragen bei drei Datenbankklassen.
Bei Dokumentdatenbanken liegen die Daten jedes Objekts in einem Dokument (XML, Json, …) vor. Jedes Dokument hat eine eindeutige ID, die die Datenbank benutzt, um es zu laden. Objektverknüpfungen stellen die Dokumente durch ID-Referenzen auf andere Dokumente dar. Zusätzliche Attribute lassen sich leicht in das Dokument einfügen.
Damit ist das Konzept zwar flexibler als die relationale Datenbank. Ein Nachteil ist allerdings, dass die Datenbank die Dokumente bei der Suche oder zur Verfolgung von Objektbeziehungen immer erst laden muss.
Graphdatenbanken beruhen auf zwei Basisobjekten: Den Knoten und den verbindenden Kanten. Beide können beliebige Attribute speichern, eine spezielle Deklaration ist meist nicht notwendig. Dadurch ergibt sich ein flexibles Datenmodell, das eine schnelle Traversierung über die Objekte möglich macht. Typische Anwendungsfälle sind alle Arten von sozialen Netzwerken (wer mit wem, wann und wo). Auch die Speicherung von Baugruppen-, Dokumenten- oder Projektstrukturen nutzt die flexible Abbildung von komplexen Abhängigkeiten und Querverweisen.
Die Orient DB implementiert zwei Konzepte: Die Basis bildet die Dokumentdatenbank, darüber ermöglicht ein Layer die Nutzung als Graphdatenbank.
Installation
Die Software steht auf der Webseite [1] fertig kompiliert als Tar-Archiv zur Verfügung. Nach dem Download entpackt der Admin das Archiv an einer beliebigen Stelle. Für die ersten Schritte lässt sich der Server ohne weitere Konfiguration mit dem Skript »bin/server.sh« starten. Beim ersten Hochfahren fragt die Datenbank nur ein Passwort für den Datenbank-Rootanwender ab.
Damit ist die Installation bereits abgeschlossen, für eine produktive Installation sollte der DBA die Datenbank allerdings mit SSL konfigurieren, da sonst die Daten und Passwörter im Klartext über das Netzwerk gehen.
Für die direkte Nutzung stehen eine Webanwendung sowie die etwas spröde, aber mächtige Konsole zur Verfügung. Der Anwender startet sie mit »bin/console.sh« . Danach kann er sich mit »connect remote:localhost root Passwort« an der Datenbank anmelden. Während andere NoSQL-Datenbanken sich bei der Abfragesprache von relationalen Datenbanken abgrenzen, setzt die Orient DB soweit möglich auf SQL. Der Anwender muss also keine neue Sprache lernen, nur für die zusätzlich hinzukommenden Fähigkeiten braucht es extra Kommandos. In der Konsole gibt der Help-Befehl einen Überblick über verfügbare Kommandos, eine umfangreichere Doku steht im Orient-DB-Wiki [2] zur Verfügung.
Erste Schritte
Das erste Beispiel basiert auf Figuren und Büchern der Scheibenwelt-Serie des in diese Jahr verstorbenen genialen Terry Pratchett (Abbildung 1). Es kennt zwei Knotentypen »Person« und »Buch« , die über die beiden Kanten »Beziehung« und »Auftritt« verbunden sind. Knoten und Kanten haben unterschiedliche Attribute, die direkt oder als Liste beziehungsweise Map verwendbar sind.
Abbildung 1: Diese Beispieldatenbank erläutert die Beziehungen von Figuren der Scheibenwelt-Serie.
Das Listing 1 enthält auszugsweise die Konsolen-Kommandos, die der Anwender braucht, um den Graphen zu erstellen. In den ersten beiden Zeilen konnektiert er zunächst die Konsole mit dem Server und legt anschließend eine neue Datenbank mit dem Namen »discworld« an. Nach dem Anlegen verbindet sich die Konsole ganz automatisch mit der neuen Datenbank.
Listing 1
Datenbank anlegen
01 connect remote:localhost root password
02 create database remote:localhost/discworld root password plocal
03
04 create class Person extends V;
05 create property Person.geburtstag date;
06
07 create class Buch extends V;
08 create property Buch.uebersetzung embeddedmap;
09
10 create class Beziehung extends E;
11 create property Beziehung.von date;
12
13 create class Auftritt extends E;
14 create property Auftritt.kapitel embeddedlist integer
15
16 insert into Person (nachname, vorname, geburtstag) values ('Vimes', 'Samuel', '1962-04-03');
17 insert into Person (nachname, vorname, geburtstag) values ('Sybil', 'Ramkin', '1969-09-06');
18
19 insert into Buch (name, uebersetzung) values ('Guards ! Guards !', {'de':'Wachen ! Wachen !', 'fr' : 'Au Guet !'} );
20
21 create edge Beziehung from #11:0 to #11:1 set typ='Verheiratet', von='1993-01-01';
22
23 create edge Auftritt from #11:0 to #13:0 set kapitel={1,2,3,4,5,6};
Graphdatenbanken enthalten die Basistypen V (Knoten) und E (Kante). Auf ihrer Grundlage definiert das Listing die hier genutzten Typen. Ab Zeile 4 legt es die Klassen »Person« und »Buch« als Erweiterung des Basisknotens an und bestimmt ihre Attribute. In der Orient DB stehen die üblichen Primitive wie Integer, String oder Date zur Verfügung, es lassen sich wie ab Zeile 8 auch Listen, Sets oder Maps verwenden. Das Attribut »uebersetzung« in der Buch-Klasse enthält die Map »Sprache : Titel« , das Attribut »kapitel« nimmt die Kapitel auf, in denen eine Person auftritt. Relationale Datenbanken müssten hierfür eine zusätzliche Tabellen definieren.
Die Kantenklassen »Beziehung« und »Auftritt« definieren sich ähnlich wie Knotenklassen, nur ist die Basisklasse jetzt »E« statt »V« . Anders als bei relationalen Datenbanken muss man bei den Kanten nicht unterscheiden, ob sie eine 1:1-, 1:n- oder m:n-Beziehung repräsentieren. Jede Kante stellt eine 1:1-Beziehung zwischen zwei Knoten dar. Dafür darf es aber beliebig viele Kanten geben, die von einem Knoten ausgehen oder auf einen Knoten verweisen.
Die Knotenerzeugung nutzt das klassische Insert-Statement, bei dem die Zielklasse und die Attributwerte anzugeben sind. Dass bei der Definition der »Person« die Attribute »nachname« und »vorname« nicht angegeben wurden, bestraft die Datenbank an dieser Stelle nicht mit einer Fehlermeldung, sie legt diese Attribute beim Einfügen dynamisch an.
Um Listen, Sets oder Maps zu füllen, akzeptiert die Orient DB eine Json-ähnliche Schreibweise (Zeile 18). Orient DB vergibt für jeden Knoten eine eindeutige Objekt-ID (zum Beispiel #11:3), die sich später zur Suche beziehungsweise zum Erzeugen der Kanten nutzen lässt.
Kanten sind mit dem neuen »create edge« -Statement zu erzeugen. Neben der ID des Start- und Zielobjekts können Kanten wie die Knoten beliebige Attribute tragen.
Fragestunde
Wenn das Datenmodell definiert und die ersten Daten eingefügt sind, geht es zur Suche in der Datenbank. Für die direkte Abfrage von Kanten und Knoten bietet sich das normale Select-Statement an, der Anwender kann dabei die typischen Vergleichsoperatoren wie »=« ,»>« oder »like« einsetzen. Das klappt auch bei eingebetteten Listen, Sets und Maps.
Zeile 3 in Listing 2 sucht das Buch, dessen deutscher Titel “Ab die Post” lautet. Der Mehrwert der Orient DB gegenüber einer relationale Datenbank ist das elegante Auswerten von Objektbeziehungen über eine oder mehrere Kanten hinweg. Basis dafür bilden die Out- und In-Attribute in den Knoten und Kanten. An der Ausgabe (Abbildung 3) sieht man, dass jedes Objekt automatisch definierte In- und Out-Attribute zur Speicherung der Objektbeziehungen enthält.
Listing 2
Beispiel-Selects
01 select from Person where nachname='Vimes';
02 select from Person where geburtstag > '1965-01-01';
03 select from Buch where uebersetzung["de"] ="Ab die Post";
04 select expand( both() ) from Person where vorname='Samuel';
05 select expand( in().out('Auftritt') ) from #11:2;
06 traverse any() from #11:0;
07 traverse out('Beziehung') from #11:1 while $depth < 10;
08 traverse any() from 11:0 while
09 ( @class='Beziehung' and von < '1871-01-01')
10 or von is null;
11 select name from (traverse any() from #11:0) where @class='Wohnort';
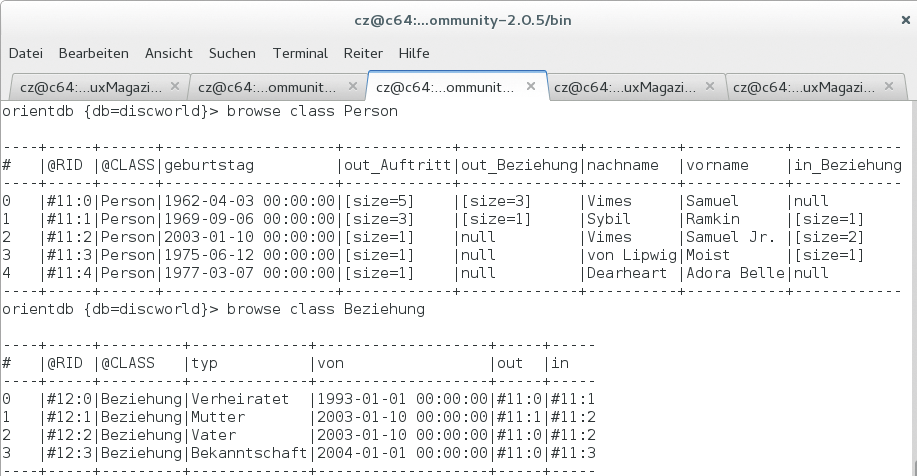
Abbildung 3: Mit der Konsole erhalten Anwender einen leichten Einstieg in die Welt der Orient DB.
Wer im Select-Statement die »out()« -Funktion nutzt, erhält alle von dem Knoten ausgehenden Kanten, mit der »in()« -Funktion entsprechend die auf einen Knoten zeigenden Kanten und mit »both()« Kanten beider Richtungen. In Kombination mit der »expand()« -Funktion bekommt man die mit den gefundenen Kanten verbundenen Knoten.
Beziehungsfragen
Mit diesen Abfragen lassen sich typische Beziehungsfragen wie “Wer kennt diese Person?” oder “Wovon ist diese Tätigkeit abhängig?” leicht klären. Das Statement in Zeile 6 findet damit alle Personen und Bücher, die über eine Kante mit »#11:0« verknüpft sind. Darüber hinaus lassen sich explizit die gewünschten Kantentypen und -richtungen angeben und sogar zu einer Pfadbeschreibung verknüpfen. Das Statement in Zeile 5 verfolgt so alle Verknüpfungen, die auf »#11:2« verweisen, gegen ihre Richtung und geht bei den gefundenen Objekten dann den Verknüpfungen des Typs »Auftritt« nach. Damit erhält man die Bücher, in denen Personen auftreten, die Samuel Jr. kennen. Ein bekannter Anwendungsfall ist bei Versandhändlern die Anzeige von Artikeln, die Kunden des aktuell betrachteten Artikels auch gekauft haben.
Bei der Verwendung von »in()« , »out()« und »both()« sind die zu betrachtenden Pfade Teil der Anfrage, der Fragende bekommt immer nur einen Teilbereich um das Startobjekt als Ergebnis. Ähnlich wichtig ist das rekursive Ablaufen, um alle verknüpften Knoten und Kanten zu erhalten. Hierfür steht in Orient DB das »traverse« -Statement bereit, das Angaben zu den zu verfolgenden Kanten und zu den Bedingungen auf den traversierten Knoten und Kanten benötigt.
Die Abfrage ab Zeile 8 verfolgt dank »any()« alle Kanten, damit liefert sie ausgehend von »#11:0« den gesamten Graph inklusive des Startobjekts. Für mehr Kontrolle lässt sich mit »while« eine Bedingung angeben, die bei jedem Übergang Knoten/Kante oder Kante/Knoten überprüft. Im einfachsten Fall dient das der Einschränkung der Suchtiefe. Darüber hinaus kann man auch auf die Attribute der gerade betrachteten Knoten und Kanten zugreifen und sie zur Klassifizierung oder Gültigkeitseinschränkung nutzen.
Im Beispiel haben die Beziehungen einen Typ und einen Startzeitpunkt, es lassen sich aber auch Ressourcenzuordnung bei Projekten oder die Zuordnung von Bauteilen zu bestimmte Fertigungslosen so abbilden. Zeile 5 ermittelt nur noch die Mitglieder einer Familie. Dazu prüft die While-Bedingung beim Traversieren, ob es sich um Beziehungskanten mit einer familiären Beziehung handelt oder um Knoten vom Typ »Person« .
Wie bei einer relationalen Datenbank ist es möglich, Statements zu verschachteln. Zeile 8 bis 10 zeigen dies mit einer Kombination von Select- und Traverse-Statements. Dabei ermittelt »traverse« die gewünschten Objekte, »select« wirkt als Filter, um nur noch die Namen der gefundenen Bücher auszugeben.
Solche Kombinationen gestatten effiziente Abfragen. Doch durch die elegante Abfragesprache gerät der Benutzer schnell in Versuchung, erst mal zu viele Objekte anzufassen und sie später durch ein weiteres »select« auf den eigentlichen Suchbereich einzugrenzen.
Das kann bei großen Graphen jedoch fatale Folgen haben, gerade beim Traverse-Statement sollte der Anwender die Menge der durchlaufenen Objekte durch Einschränkung der Kanten oder in der While-Bedingung reduzieren. Schon bei dem kleinen Beispiel reduziert sich die Laufzeit um gut ein Drittel, bei größeren Graphen natürlich um noch mehr. Ansonsten helfen bei der Orient DB die übliche Methoden der Optimierung wie Indizes auf häufig gesuchte Attribute und das Profile-Kommando, um Queries zu untersuchen.
Wie die wenigen Beispiele demonstrieren, ermöglicht die Orient DB sowohl eine kompakte Beschreibung des Datenmodells als auch – durch das erweiterte Select- und das neue Traverse-Statement – eine elegante Abfrage von Objektbeziehungen. Relationale Datenbanken erfordern mehr Aufwand: Für die Listen- beziehungsweise Map-Attribute wäre dort jeweils eine eigene Tabelle notwendig. Und auch die Traversierung ist wesentlich aufwändiger: Rekursive Abstiege stehen dort nicht datenbankübergreifend zur Verfügung, sind unleserlich und in der Regel auch langsam.
Schnittstellen
Für eigene Anwendungen auf Basis der Orient DB stehen etliche Schnittstellen bereit. Erster Kandidat ist natürlich Java, womit die Datenbank selbst implementiert ist. Mit Hilfe des Client-API ist es möglich, den Server aus einem beliebigen Programm anzusprechen. Es zeigt auch die gute Performance der Orient DB: Das Anlegen einer Baumstruktur mit jeweils 8000 Knoten und Kanten in einer Transaktion dauert auf einem kleinem Webserver (Core I3, 4 GByte RAM) unter 5 Sekunden, das rekursive Ablaufen ist in 1/3 Sekunde erledigt.
Auch jenseits der Java-Welt ist der Zugriff auf Orient DB kein Problem, native Treiber stehen für Skriptsprachen wie Python, PHP und Perl bereit, der C- und C#-Treiber erschließt diese Sprachfamilien. Zudem bietet der Orient DB Server eine HTTP-Schnittstellen. Durch »GET-« und »POST« -Requests ist der Server ähnlich wie auf der Konsole zu nutzen. Listing 3 enthält eine Abfolge von URLs, mit der ein Benutzer sich mit dem Server verbindet, Informationen über den Server und die »Person« -Klasse abfragt und dann nach Objekten sucht. Die Ergebnisse kommen als Json zurück, Updates gehen im gleichen Format an den Server.
Listing 3
HTTP-Interface
01 http://localhost:2480/connect/discworld 02 http://localhost:2480/database/discworld 03 http://localhost:2480/class/discworld/Person 04 http://localhost:2480/query/discworld/sql/select from Person where nachname='Vimes' 05 http://localhost:2480/disconnect
Die HTTP-Schnittstelle ermöglicht die Nutzung aus beliebigen Programmiersprachen, vor allem direkt aus dem Javascript-Code einer Webseite. Darüber lässt sich die Skriptsprache dank des in Java vorhandenen Javascript-Interpreters auch zur Programmierung von Datenbankfunktionen nutzen, die dann direkt im Datenbankserver ablaufen.
Fazit
Dieser Artikel zeigt die Möglichkeiten von Orient DB nur ansatzweise. Aber schon das kleine Beispiel lässt das flexible Datenmodell und die elegante Abfrage erkennen. Da die Abfragesprache in der Regel auf dem bekannten SQL beruht, sind die Einstiegshürden niedrig. Die weiteren Features der Orient DB wie Transaktionssicherheit, Verwaltung von Zugriffsrechten, verteilte Datenbanken oder direkte Datenübernahme aus relationalen Datenbanken seien hier nur erwähnt. Datenbanken mit Milliarden von Einträgen und GBytes an Speicherplatz sind in produktiver Nutzung.
Dank der liberalen Apache-Lizenz ist die Orient DB auch für kommerzielle Applikationen nutzbar. Bei Bedarf bietet die hinter der Entwicklung stehende Firma Orient Technologies kommerziellen Support an. Neben der Weiterentwicklung an der Datenbank selbst fließt das Geld auch in die frei verfügbare Dokumentation. Sie hat sich im Laufe der letzten beiden Jahre von nahezu unbrauchbar zu dem jetzigen, ganz passablen Zustand entwickelt. Damit ist der größte Kritikpunkt ausgeräumt. Heute kann man den Server auf alle Fälle als ein Highlight der jungen NoSQL-Welt einstufen.
Infos
- Orient DB: http://www.orientechnologies.com
- Orient-DB-Wiki: http://www.orientechnologies.com/docs/last/





