
© Elke Hanmann, Pixelio.de
Schauergeschichten vom Totalausfall eines Massenspeichers gehören ins Repertoire jedes Admins. Doch ist ein Datenverlust heutzutage tatsächlich wahrscheinlich, wo man überall redundante Plattenkonfigurationen einsetzt? Die überraschende Antwort lautet: Ja, heute eher denn je.
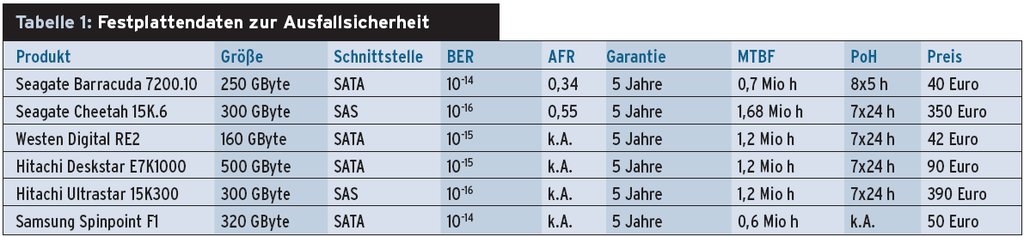
Beim Kauf von Festplatten hat der Kunde eine große Auswahl. Augenfällige Kenndaten sind Größe, Geschwindigkeit oder Preis. Mit der Ausfallsicherheit hat nichts davon zu tun. Wer dazu Details finden will, der muss das Datenblatt schon genauer studieren.
Die Hersteller geben meist die mittlere jährliche Fehlerrate (Annualized Failure Rate, AFR) und die Bit Error Rate (BER) an. Alternativ ist auch der Begriff MTBF (Mean Time Between Failure) zu finden. Die AFR bezeichnet jenen Anteil an Festplatten, die im Durchschnitt pro Jahr Ausfallerscheinungen zeigen. Das gilt natürlich nur für eine große Anzahl identischer Festplatten einer Produktionscharge. Die gleiche Information über die Zuverlässigkeit der gesamten Festplatte enthält die MTBF.
Beide Werte lassen sich auch ineinander umrechnen, wenn man berücksichtigt, dass die Hersteller zusätzlich angeben, wie lange die Disk pro Tag (oder Monat beziehungsweise Jahr) laufen darf (in Power on Hours, PoH):
![]()
Im Unterschied dazu gibt die Kennzahl BER an, nach durchschnittlich wie vielen gelesenen Bits die Festplatte einen Fehler meldet.
Alle Angaben von Herstellern gelten natürlich nur in der Garantiezeit, die ebenfalls aus dem Datenblatt abzulesen ist. Üblicherweise steigen die Fehlerraten nach der Garantiezeit dramatisch an. Der Suchmaschinen-Riese Google, der in seinen Rechenzentren viele Festplatten einsetzt und deshalb gute Statistiken von großen Chargen ermitteln kann, hat dazu Daten veröffentlicht [1].
Die Daten der Tabelle 1 betreffen willkürlich ausgewählte Festplattenmodelle. Gerade für Billigfestplatten lassen sich häufig keine Daten zur Zuverlässigkeit finden. Anhand der Bitfehlerrate kann man sich den Preisunterschied zwischen den verschiedenen Modellen einfach erklären. Die Werte für AFR und MTBF lassen sich nicht direkt entsprechend der obigen Formel umrechnen, denn hier haben die Hersteller noch eine zusätzliche Sicherheitsmarge einkalkuliert.
|
Tabelle 1: Festplattendaten zur |
|---|
|
|
Etwas Mathematik
Mit den Herstellerangaben ist die Zuverlässigkeit (oder anders ausgedrückt die Wahrscheinlichkeit eines Totalverlustes der Daten) relativ einfach zu berechnen. Wenn die AFR einer Festplatte 0,34 Prozent beträgt, ist das Risiko eines Ausfalls in der Garantiezeit von fünf Jahren 1-(1-0,34%)5 oder 1,68 Prozent – also nicht mehr zu vernachlässigen.
Aus diesem Grund sind schon lange redundante Festplattenarrays (Raid) im Einsatz. Sie schreiben im einfachsten Fall (Raid 1) alle Daten auf zwei Platten. Falls eine Festplatte ausfällt, finden sich alle Daten noch auf der anderen. Natürlich muss der Administrator die defekte Festplatte schnell austauschen und den Raid-Verbund wieder herstellen. Fällt nämlich während der Reparaturzeit eine weitere Festplatte aus, ohne dass Ersatz eingebaut und die Synchronisation der Daten beendet ist, dann droht der Totalausfall. Damit hängt die Wahrscheinlichkeit für den Verlust von Daten stark von der mittleren Wiederherstellungszeit (Mean Time to Repair, MTTR) ab.
Steht ein Hotspare zur Verfügung, hängt die MTTR allein von der Geschwindigkeit des Datentransfers ab und liegt bei maximal ein paar Stunden. Falls der Administrator aber erst Ersatz kaufen, einbauen und die Wiederherstellung anstoßen muss, kann der Prozess Tage dauern.
So lässt sich die Wahrscheinlichkeit für den Totalausfall eines einfachen Raid-1-Spiegels innerhalb von fünf Jahren abschätzen, indem man die Zeit für die Wiederherstellung des Array nach einem Ausfall beispielsweise mit einem Tag veranschlagt. Die Wahrscheinlichkeit für den Ausfall einer Festplatte innerhalb von fünf Jahren beträgt 1,68 Prozent (siehe oben). Die Wahrscheinlichkeit, dass auch die zweite Platte noch in der Reparaturzeit ausfällt, beträgt 1 Tag/(5 Jahre) = 5,48*10-4.
Multipliziert man alle Wahrscheinlichkeiten ergibt sich: 1,68%*1,68%*5,46*10-4 = 1,55*10-7. Das entspricht einer Chance von 1:6465000, und die ist ungefähr zehnmal häufiger als ein Sechser im Lotto. Wem das immer noch zu risikoreich ist, der verwendet eine Festplatte im Standby-Betrieb und reduziert so die Zeit bis zur Wiederherstellung des Spiegels.
Platz versus Sicherheit
Bei Festplattenspiegeln ist nicht mehr die MTBF als statistische Kenngröße üblich, sondern die Mean Time to Data Loss (MTTDL). Wie Chen et.al. [2] zeigen, lässt sich die MTTDL für verschiedene Systeme herleiten. Zwar lässt sich beim Lesen von einem Spiegel neben der Sicherheit auch Geschwindigkeit gewinnen, doch dafür sind (inklusive Hotspare) drei Festplatten erforderlich, um die einfache Nettokapazität zu erhalten. Das ist eine ziemliche Verschwendung von Plattenplatz. Deshalb gibt es als weitere Variante Raid 5. Neben einer Anzahl Festplatten, die die Daten des Dateisystems aufnehmen, speichert Raid 5 zusätzlich auf einer Festplatte noch die aus den Daten errechnete Parität.
Falls eine Disk ausfällt, lassen sich ihre Daten mit Hilfe der Paritätsdaten wieder rekonstruieren. Wenn das Array aus n Festplatten besteht, dann beträgt die Nettokapazität n-1 Festplatten. Liegt noch eine Platte als Standby bereit, verringert sich die Nettokapazität auf n-2.
Aber auch Raid 5 hat einen Nachteil: Der Preis für den Platzgewinn sind ein erhöhter Rechenaufwand und mehr Schreib-.operationen. Bei jedem Schreiben ist die Parity des betroffenen Streifens neu zu berechnen und zusätzlich zu speichern. Trotzdem bleibt Raid 5 für viele Anwendungen ein guter Kompromiss.
Die MTBF für ein Raid-5-Array aus n Festplatten berechnet [2] folgendermaßen:
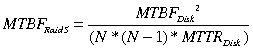
Somit betrüge die MTBF für ein System aus zehn guten Festplatten 76100 Jahre (MTBFDisk=1,2*106). Das ist natürlich ein rein theoretischer Wert, der keine Bedienfehler und abhängige Fehler in Produktionschargen oder Produktzyklen berücksichtigt und nur für den Fall gilt, dass der Admin defekte Platten im Raid sofort ersetzt. Ein sicheres Backup und langfristige Datensicherheit bleiben also weiterhin ein Thema.
Neue Probleme
Die Technik von Raid 5 war lange Zeit das Lieblingskind vieler Administratoren. Allerdings berücksichtigt die Rechnung oben nicht alle möglichen Fehlerquellen, die zum Datenverlust führen können. Die zweite Kennziffer in der Tabelle 1 ist die Bitfehlerrate. Sie besagt, dass die Festplatte nach einer bestimmten Anzahl gelesener Bits zurückmeldet: Ich kann den Block nicht mehr lesen.
Bisher spielte dieser Fehler keine wesentliche Rolle, da er durchschnittlich nur alle 1015 Bits oder umgerechnet alle 125 TByte auftritt. Selbst Platten, bei denen der Fehler zehnmal häufiger zu beobachten ist, waren bisher noch kein großes Problem. Das aber ändert sich nun mit ständig wachsenden Festplattengrößen.
Folgendes Beispiel verdeutlicht das: Ein Administrator beschließt, zehn Festplatten mit jeweils 1 TByte zu kaufen. Daraus baut er ein Raid-5-Array mit 9 TByte. Die Wahrscheinlichkeit, dass innerhalb der ersten fünf Jahre keine einzige Festplatte ausfällt beträgt nur ((1-0.0034)10)5 = 84,3 Prozent. Das Risiko für einen Ausfall ist also 15,6 Prozent.
Der Admin hofft dieses Risiko mit dem Raid-5-Ansatz zu beherrschen, da das System ja die ausgefallene Festplatte einfach aus der Parity-Information wiederherstellen kann. Bei der Wiederherstellung muss es aber alle Daten aller Festplatten inklusive der Parity-Informationen lesen, also die kompletten 9 TByte.
Falls der Chef des Administrators nun nur die billigen Festplatten mit einer Bitfehlerrate von BER = 10-14 genehmigt hat, gibt es möglicherweise ein Problem. Die Anzahl der Bits, die zu lesen sind, beträgt M = 8 Bits/Byte * 9 TByte = 7,2*1013 Bit. Die Wahrscheinlichkeit, dass alle diese Bits ohne Fehler lesbar sind, beträgt (1-BER)M. Im vorliegenden Beispiel wären das 48,7 Prozent. Oder anders gesagt: Mit hoher Wahrscheinlichkeit (51,3 Prozent) lässt sich mindestens ein Block nicht wieder herstellen.
Keine schöne Situation für den Administrator. Bei besseren Festplatten (BER = 10-15) beträgt die Chance für den Verlust eines Sektors immerhin noch 7 Prozent. Und das Problem verschärft sich exponentiell mit steigender Festplattenkapazität, da die Hersteller die Zuverlässigkeit ihrer Produkte nicht im selben Maße steigern können.
Als Alternativen bleiben nur andere Raid-Konzepte. Wenn pDisk die Wahrscheinlichkeit ist, die komplette Festplatte ohne Fehler auszulesen, dann ist laut [2]:
Abbildung 1: Funktion von Raid 6 als Schema: Im Gegensatz zu Raid 5 wird zu jedem Stripe eine zusätzliche Paritätsinformation gebildet und auf einer separaten Festplatte abgelegt.
Die gleiche Rechnung wie im obigen Beispiel zu Raid 5 ergibt hier bei der 1-TByte-Festplatte (BER = 10-15) mit pDisk = 0,992 eine MTTDL von nur noch 178 Jahren oder anders ausgedrückt, eine Chance von 0,56 Prozent pro Jahr, doch Daten zu verlieren.

Abbildung 1: Funktion von Raid 6 als Schema: Im Gegensatz zu Raid 5 wird zu jedem Stripe eine zusätzliche Paritätsinformation gebildet und auf einer separaten Festplatte abgelegt.
Raid 6 und anderes
Wenn eine Parity-Disk nicht mehr ausreicht, um die notwendige Datensicherheit zu gewährleisten, ist ein Ausweg, auch die Parity-Informationen redundant zu halten. Die einfachste Variante heißt Raid 6. Zusätzlich zur einfachen Paritätsinformation berechnet Raid 6 eine zweite und legt sie auf einer weiteren Festplatte ab. So dürfen zwei Festplatten gleichzeitig ausfallen oder bei Ausfall einer Festplatte darf ein Sektor bei der Wiederherstellung defekt sein – trotzdem sind alle Daten rekonstruierbar. Der Nachteil der redundanten Parity-Informationen ist der Performanceverlust, der mit der doppelten Berechnung einhergeht.
Unter Linux mit dem Raid-Modul des Kernels gibt es aber keine Alternative. Nur große Hersteller bieten hier Lösungen an, die Datensicherheit mit Performance vereinen. Als Beispiel seien hier das Raid-Z- und das Raid-Z2-Verfahren vorgestellt, die in Suns ZFS zum Einsatz kommen. Eine alternative Technik von Net-app heißt Raid DP.
Das große Problem bei Raid 5 und 6 ist, dass sie bei jedem Schreiben die Parity-Information des ganzen Streifens neu berechnen. In ZFS ist das Raid nahtlos ins Filesystem integriert. Deshalb kann ZFS die Größe eines Streifens zur Berechnung des Raid immer an die aktuelle Datengröße anpassen und muss keine starren Größen verwenden. ZFS schreibt also bei jedem Datensatz eine eigene Paritätsinformation, egal ob ein Datenblock von 512 Byte oder eine Datei von 128 KByte auf die vorhandenen Festplatten zu verteilen ist. Die maximale Größe der Daten zur Berechnung der Parität passt sich an die Anzahl der tatsächlich vorhandenen Festplatten an.
Näheres zur Technik hinter Raid Z zeigt [3]. Durch die Verwendung einer dynamischen Größe entfällt die Notwendigkeit, die komplette Parity neu zu berechnen, sobald sich nur ein Datenblock ändert. Mit Raid Z2 setzt Sun noch eins drauf und verwendet einfach einen zweiten Algorithmus zum Berechnen der zweiten Parität. Er gewährleistet, dass alle Daten auch bei Ausfall zweier Festplatten rekonstruierbar bleiben. Eine genaue Erklärung findet sich unter [4].
Die MTTDL berechnet sich in Arrays mit einer doppelten Parity zu:
![]()
Im obigen Beispiel ergibt das 76103 Jahre, also fast das gleiche Ergebnis wie für einfaches Raid 5. Mit diesem Ausblick können die Administratoren dem weiteren Anwachsen des Speicherbedarfs gelassen entgegen sehen. (jcb)
|
Infos |
|---|
|
[1] E. Pinheiro, W.-D. Weber and L. A. Barroso, “Failure Trends in a Large Disk Drive Population”: Proceedings on the 5th USENIX Conference on File and Storage Technologies, 2007 [2] Peter M. Chen et. al., “Raid: High-Performance, Reliable Secondary Storage”: ACM Computer Surverys, Vol 26 No 2, 1994 [3] Raid Z: [http://blogs.sun.com/bonwick/entry/raid_z] [4] Double Parity: [http://blogs.sun.com/ahl/entry/double_parity_raid_z] |
|
Der Autor |
|---|
|
Dr. Michael Schwartzkopff arbeitet als Berater bei der Firma Multinet Services GmbH. Mit dem Linux-Virus ist er seit dem ersten Kontakt 1994 über eine Yggdrasil-Distribution infiziert. |





