
© Gerti G., photocase.com.
Die einen lieben, die anderen hassen sie: die flexible, aber komplexe C++-Standardbibliothek STL. Entwickler des zweiten Lagers können ihren Quellcode nun fast umsonst parallelisieren. Den Werkzeugkasten dazu liefert OMPTL – vorausgesetzt der Compiler beherrscht den OpenMP-Standard.
Mittlerweile geht kaum noch ein PC über die Ladentheke, in dem nicht mindestens zwei Prozessorkerne schlagen. Die Kraft der zwei Herzen hat die Programmierlandschaft jedoch im Halbschlaf überrollt. Auf der einen Seite überschütten Intel und AMD selbst schon Privatkunden mit Quadcores (Abbildung 1), während am anderen Ufer die Software-Entwickler mit ihren linearen Sprachen und Konzepten winken.

Abbildung 1: Supercomputing-Power für den Desktop: Layout eines Vier-Kerne-Prozessors.
In mühsamer Kleinarbeit müssen daher die Programmierer parallele Aufgaben identifizieren, per Hand in eigene Threads und Prozesse auslagern und die Ergebnisse wieder aufwändig zusammenführen – vom anschließenden, teilweise hirnverdrehenden Debugging einmal ganz abgesehen.
Für Nutzer der C++-Standardbibliothek gibt es jedoch einen Lichtblick. Er hört auf den Namen OpenMP Multi-Threaded Template Library, kurz OMPTL. Diese kleine, aber pfiffige Bibliothek ersetzt einfach sämtliche Algorithmen sowie den numerischen Teil der C++-Standardbibliothek durch eigene parallelisierte Varianten. Der Programmierer muss lediglich ein paar Funktionsaufrufe leicht überarbeiten.
Stolperdraht
Bei so viel Komfort gibt es wie immer auch einen Haken. Im Fall der OMPTL liegt dieser beim Compiler: Die Bibliothek stützt sich vollständig auf den OpenMP-Standard ([1], [2]). Diese offene Spezifikation beschert C- und C++-Compilern neue Befehle, über die sich Codeblöcke recht einfach parallelelisieren lassen. Das klappt freilich nur, wenn der Übersetzer den OpenMP-Standard korrekt und vollständig beherrscht. Auf den Intel-Compiler trifft dies schon seit geraumer Zeit zu [3]. Leider darf die Linux-Version nur für private Zwecke kostenfrei genutzt werden.
Die beliebte GNU Compiler Collection kann erst in der brandneuen Version 4.2 mit OpenMP-Anweisungen umgehen. Wer nicht auf den Intel-Compiler ausweichen kann oder mag, muss folglich entweder den aktuellen G++ per Hand nachrüsten oder auf die allerneuesten Distributionen umsteigen. Bereits einsatzfertig haben ihn sowohl Ubuntu 7.10 als auch Open Suse 10.3 an Bord. Lediglich Red Hat hat für seine Community-Distribution Fedora die OpenMP-Funktionalität in ältere GCC-Versionen zurückportiert. Eine OpenMP-freie Variante der OMPTL-Bibliothek stellt der Kasten “Kleine Schwester” vor.
|
Kleine Schwester |
|---|
|
Auf der Homepage der OMPTL ist noch die Multi Processing Template Library, kurz MPTL, anzutreffen. Sie ist ähnlich gestrickt wie ihre großer Schwester, arbeitet aber intern mit herkömmlichen Posix-Threads statt OpenMP. Die Programmierung erfolgt analog zur OMPTL-Variante. Aus dem Code in Listing 1 beispielsweise würde in der MPTL-Variante: #include <vector>
#include <mptl.h>
#include <mptl_algo.h>
#include <mptl_qsort.h>
int main (int argc, char * const argv[])
{
mptl::setNumThreads(2);
std::vector<int> zahlen(100000);
mptl::sort(zahlen.begin(), zahlen.end());
return 0;
}
Im Gegensatz zur OMPTL-Bibliothek muss der Entwickler bei der MPTL zu Beginn seines Programms explizit angeben, auf wie viele Threads sich die Bearbeitung verteilen soll. Da die MPTL auf den Posix-Threads aufsetzt, muss er bei der Übersetzung eine passende Bibliothek hinzulinken, beispielsweise die »libpthread«: g++ -I/Pfad/MPTL/ -lpthread sortieren.cpp Die MPTL erreicht eine Parallelisierung der Standard-Algorithmen mit jedem beliebigen C++-Compiler, und das sogar ohne OpenMP-Support. Umso trauriger stimmt es daher, dass die bei Redaktionsschluss aktuelle Version schon fast ein Jahr auf dem Buckel hat. Es ist also zu vermuten, dass sie zugunsten ihrer großen Schwester langfristig in der Versenkung verschwinden soll – auch wenn das Ende der Bibliothek noch nicht offiziell verkündet ist. Den Sprung in die CVMLCPP hat sie jedenfalls nicht geschafft. |
Groß oder klein?
So bewaffnet lädt sich der angehende Multicore-Programmierer von [4] das aktuelle Archiv herunter. Dessen Installation könnte nicht einfacher sein. Es genügt, den Inhalt in ein Verzeichnis eigener Wahl zu entpacken. Der alternative Weg führt über die CVMLCPP-Bibliothek ([5], Common Versatile Multi-purpose Library for C++). Sie erweitert die C++-Standardbibliothek um ein paar nützliche Funktionen.
Unter ihrem Dach wird mittlerweile auch die OMPTL weiterentwickelt, die sich innerhalb des CVMLCPP-Pakets im Unterverzeichnis »omptl« befindet. Dessen Inhalt ist wiederum mit dem Archiv auf der OMPTL-Homepage identisch – aber nur in der jeweils aktuellen Version. Nach der Installation der OMPTL-Bibliothek geht es daran, das eigene Programm algorithmisch zu parallelisieren.
Listing 1 zeigt in Anlehnung an [4] ein kleines Sortierbeispiel als Ausgangspunkt. Es legt zunächst einen »vector« mit 100 000 Elementen an, die es anschließend sortiert. Sowohl die Datenstruktur als auch der Algorithmus stammen aus der C++-Standardbibliothek. Um daraus eine parallele Version zu klöppeln, genügen zwei kleine Änderungen. Zunächst ersetzt der Programmierer den Header »algorithm« durch sein OMPTL-Gegenstück
#include <omptl/omptl_algorithm>
und verwendet anschließend den Sortieralgorithmus aus dem Namespace »omptl«:
omptl::sort(zahlen.begin(), zahlen.end());
Den vollständigen Programmcode zeigt Listing 2.
Mit Hilfe des Makros »_OPENMP« prüft der Compiler, ob die OpenMP-Unterstützung tatsächlich zur Verfügung steht. Im negativen Fall definiert der Quellcode das Symbol »OMPTL_OFF«, das wiederum die OMPTL-Funktionen dazu veranlasst, ihre parallele Verarbeitung abzuschalten. Das Ergebnis verhält sich wie ein herkömmlicher Aufruf der Standardbibliothek. Zudem ist der Quellcode mit einem C++-Compiler ohne OpenMP-Unterstützung übersetzbar.
Die Fallunterscheidung ist folglich immer dann sinnvoll, wenn man das Programm an andere Personen mit einem unbekannten Zielsystem weitergeben möchte. Selbstverständlich lässt sich »OMPTL_OFF« auch direkt dem Compiler mitgeben:
g++ -I/Pfad/omptl -DOMPTL_OFF sortieren.cpp
Den modifizierten Quellcode übersetzt ein Intel-Compiler mit:
icc -I/Pfad/omptl -openmp sortieren.cpp
GCC-4.2-Nutzer greifen zu dem folgenden Äquivalent:
g++ -I/Pfad/omptl -fopenmp sortieren.cpp
Nach dem Programmstart und der Erzeugung des Vektors verteilt die OMPTL die Sortieraufgabe auf mehrere OpenMP-Threads. Deren Anzahl hängt von der Anzahl der vorhandenen Prozessoren beziehungsweise der Prozessorkerne ab. Auf einem Core 2 Duo würde die Sortierung folglich auf genau zwei Threads aufgeteilt.
Falls nötig oder gewünscht, kann der Anwender über die zu OpenMP gehörende Umgebungsvariable »OMP_NUM_THREADS« beim Start des Programms eine bestimmte Thread-Anzahl erzwingen. Mehr Threads zu erzeugen, als Kerne vorhanden sind, führt allerdings eher zur Verlangsamung des parallelisierten Programms.
Sobald die Threads ihre Berechnungen beendet haben, führt die OMPTL deren Ergebnisse automatisch wieder zu einem sortierten Vektor zusammen. Nach außen hin bleibt dies alles vollkommen transparent, der Programmierer kann anschließend direkt mit dem fertig sortierten Vektor weiterarbeiten.
|
Listing 1: Quicksort mit |
|---|
01 #include <vector>
02 #include <algorithm>
03
04 int main (int argc, char * const argv[])
05 {
06 std::vector<int> zahlen(100000);
07 std::sort(zahlen.begin(), zahlen.end());
08 return 0;
09 }
|
|
Listing 2: Mit OMPTL |
|---|
01 #include <vector>
02
03 #ifndef _OPENMP
04 #define OMPTL_OFF
05 #endif
06
07 #include <omptl/omptl_algorithm>
08
09 int main (int argc, char * const argv[])
10 {
11 std::vector<int> zahlen(100000);
12 omptl::sort(zahlen.begin(), zahlen.end());
13 return 0;
14 }
|
Unter der Haube
Wie ein Blick in das »omptl«-Verzeichnis verrät, besteht die gesamte Bibliothek aus einer Handvoll Headerdateien. Tatsächlich ist die OMPTL nur ein Wrapper, der sich zwischen Programm und Standardbibliothek setzt. Abbildung 2 verdeutlicht dieses Zusammenhang noch einmal grafisch.
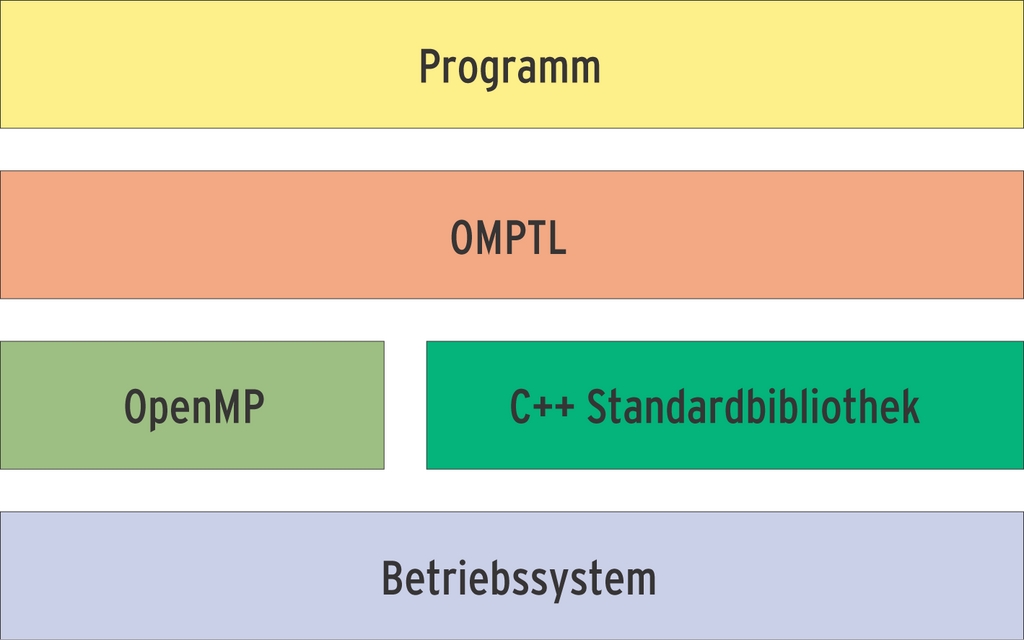
Abbildung 2: Die OMPTL-Bibliothek zur Parallelisierung in C++ ist zwischen Programm und den Standardbibliotheken angesiedelt.
Mit Hilfe der Iteratoren zerhackt die OMPTL den Wertebereich zunächst in mehrere Teilstücke. Für jedes von ihnen ruft sie anschließend die passende Funktion der Standardbibliothek auf, deren Ausführung sie wiederum in eigene OpenMP-Threads kapselt.
Die Funktionen der Standardbibliothek werden somit gar nicht selbst parallelisiert, sondern nur mehrfach für kleinere Datenpakete aufgerufen. Da sowohl die Container als auch die eigentlichen Algorithmen unangetastet bleiben, darf der Programmierer jede beliebige Implementierung der Standardbibliothek verwenden und diese sogar ohne erneute Übersetzung des Programms austauschen.
Laufzeit messen mit OpenMP
Nach dem Einbau von OMPTL-Konstrukten ins eigene Programm möchte jeder Entwickler natürlich gerne wissen, wie viel schneller das nun parallelisierte Programm überhaupt läuft. Dabei hilft ihm die OpenMP-Funktion zur Zeitmessung:
double aktuelle_zeit = omp_get_Uwtime();
Die Funktion liefert den Wert einer ständig im Hintergrund laufenden Stoppuhr. Bevor OMPTL mit den eigentlichen Berechnungen startet, sichert der Programmierer den aktuellen Wert auf die gezeigte Art und Weise. Sobald das Ergebnis vorliegt, ermittelt der folgende Code die verstrichene Zeit in Millisekunden:
std::cout<<"Berechnungsdauer: "<< (1000 * (omp_get_wtime() - aktuelle_zeit)) <<" msn";
Wer die so ermittelten Ausführungszeiten von paralleler und herkömmlicher Variante miteinander vergleicht, dürfte in vielen Fällen von dem Resultat enttäuscht sein, häufig scheint die parallele Ausführung sogar langsamer zu sein.
Overhead
Schuld an diesem Widerspruch ist der erhöhte Aufwand bei einer Parallelisierung. So müssen OMPTL und OpenMP zunächst die Daten passend auf mehrere Threads verteilen und deren Ergebnisse anschließend wieder sinnvoll zusammenführen. Die entstehende zusätzliche Arbeit frisst recht häufig den erzielten Zeitgewinn auf. Ob sich eine Parallelisierung tatsächlich lohnt, hängt maßgeblich von den vorliegenden Daten und dem zu verwendenden Algorithmus ab. Als Faustregel gilt: Eine Parallelisierung rentiert sich nur, wenn man erstens mit großen Datenmengen hantiert und zweitens die darauf ausgeführten Berechnungen auch wirklich einen essenziellen Teil des späteren Programms ausmachen.
|
Alternative |
|---|
|
Neben dem im Artikel erwähnten OpenMP gibt es für C/C++-Entwickler noch weitere Alternativen zur Parallelprogrammierung. Ähnlich wie OMPTL richtet sich die Intel-Entwicklung Threading Building Blocks (TBB) an C++-Programmierer [6]. Auf Templates basierend ergänzt die Bibliothek das Funktionsrepertoire der Standard-C++-Library STL. Für einige komplexe Datentypen der STL bringen die TBB auch Thread-sichere Pendants mit. Seit dem im Linux-Magazin erschienenen Artikel [7] zu diesem Thema hat sich bei der TBB-Bibliothek einiges getan. So steht sie mittlerweile unter einer Open-Source-Lizenz jedermann frei zur Verfügung. Die kommende Version wird weitere Neuerungen bringen. So möchten die Entwickler neue Thread-sichere Containerklassen implementieren und vorhandene beschleunigen. Die Implementierung von Task-to-Thread-Affinität soll außerdem dafür sorgen, dass die Cache-Lokalität von Daten bei parallelen Programmen erhalten bleibt. Andernfalls würden die durch zwischen den Kernen wechselnde Threads gewonnenen Performance-Vorteile wieder verschenkt. (Oliver Frommel) |
Fazit
Die OMPTL bietet einen schnellen und unkomplizierten Einstieg in die parallele Programmierung mit C++. Dank der transparenten Arbeitsweise muss sich der Entwickler keine Gedanken mehr über die Aufteilung des Algorithmus und der Zusammenführung der Berechnungsergebnisse machen, vorausgesetzt die betroffenen Container bringen eigene Iteratoren mit.
Wer zur OMPTL greifen möchte, sollte sich vorher aber gut überlegen, ob die parallele Verarbeitung tatsächlich Vorteile bringt. Hier sind entsprechende Laufzeittests unentbehrlich. Verschärfend kommt noch hinzu, dass die OMPTL gegenwärtig noch nicht alle Algorithmen aus der Standardbibliothek unterstützt und bei einigen von ihnen auch gar keine Parallelisierung möglich sein wird. Immerhin ist die OMPTL dank LGPL-Lizenz mit kommerzieller Software verträglich. (ofr)
|
Infos |
|---|
|
[1] OpenMP: [http://www.openmp.org] [2] Michael Hebenstreit, “Parallelisieren mit OpenMP” Linux-Magazin 05/07, S. 42 [3] Intel-C++-Compiler für Linux [http://www3.intel.com/cd/software/products/asmo-na/eng/compilers/clin/277618.htm] [4] OMPTL-Bibliothek: [http://sip.unige.ch/omptl] [5] CVMLCPP-Bibliothek: [http://sip.unige.ch/cvmlcpp] [6] TBB-Homepage: [http://threadingbuildingblocks.org] [7] Mario Deilmann, Thomas Willhalm, “Intel Threading Building Blocks. Ein Template-basiertes Programmiermodell für Multicore”: Linux-Magazin 05/07, S 48 |
|
Der Autor |
|---|
|
Tim Schürmann ist selbstständiger Diplom-Informatiker und derzeit hauptsächlich als freier Autor unterwegs. Zu seinen Büchern gesellen sich zahlreiche Artikel, die in Zeitschriften und auf Internetseiten in mehreren Ländern veröffentlicht wurden. |






