
Spätestens seit den 90er Jahren gehört objektorientiertes Programmieren zum flotten Alltag. Geht es um dauerhafte Speicherung, steigen Entwickler aber immer noch auf ein rostiges Dreirad um. Damit ist Schluss: Die Objektdatenbank Db4o konserviert mit wenigen Zeilen auch komplexe Objektstrukturen.
Im Kindergarten um die Ecke versucht einer der kleinen Wichte mit seinem Holzhämmerchen den runden Bauklotz durch das eckige Loch zu treiben. Nur einen Häuserblock weiter steht ein Programmierer vor dem gleichen Problem. Im Gegensatz zu seinem jüngeren Leidensgenossen versucht er jedoch ein Objekt in die Tabellen einer relationalen Datenbank zu pressen. Die Attribute sind noch recht schnell verstaut, die unterschiedlichen Referenzen und Vererbungshierarchien produzieren jedoch planmäßig ein nur schwer wartbares Tabellengeflecht.
Egal ob MySQL, Oracle oder DB2, keiner der etablierten Kameraden kann Objekte so richtig gut leiden. Java-Programmierer dürfen wenigstens zu der Krücke Hibernate [2] greifen, das Objekte nach einem manuell festgelegten Schema in eine Datenbank hämmert. Doch wehe dem, der schnell mal eben ein Refactoring durchführen möchte. Wie schön wäre doch eine spezialisierte Datenbank. So eine Art Container für Objekte, den man nur mit
ObjectContainer db=Db4o.openFile("adressdatenbank");
zu öffnen braucht, um dann irgendein zu speicherndes Objekt – beispielsweise »Kunde« – über eine entsprechende Methode dort hineinzuwerfen:
db.set(Kunde);
Die beiden Codezeilen gehören zur noch recht jungen Datenbank Db4o. Mehr ist tatsächlich nicht notwendig, um in ihr ein beliebiges Objekt dauerhaft zu konservieren. Db4o verzichtet komplett auf jegliche Tabellen und zählt damit zu den – noch recht seltenen – reinen Objektdatenbanken.
Zur Jahrtausendwende nahm Carl Rosenberger die Arbeiten an der “Database for Objects” auf. Die erste Version erschien 2001 und wurde vorwiegend an interessierte und testwillige Anwender abgegeben. Drei weitere Jahre vergingen, ehe die Software reif für die kommerzielle Vermarktung war. Eigens zu diesem Zweck wurde 2004 unter der Leitung von Christof Wittig die Firma Db4objects gegründet. Das Geld gaben drei alte Bekannte: Mark Leslie von Veritas, Vinod Khosla, Geschäftsführer bei Sun, und Jerry Fiddler von Wind River.
Noch im gleichen Jahr führte Db4objects ein zweigleisiges Lizenzmodell ein. Wer freie Software entwickelt, darf die Datenbank kostenlos unter den Bedingungen der GPL nutzen. Bei kommerziellen Anwendungen blutet jedoch der Geldbeutel. Obwohl Db4o im Vergleich zur etablierten Konkurrenz noch recht jung ist, kann es bereits einige prominente Nutzer vorweisen, darunter sind BMW, Boeing, Bosch und Intel.
Klein, aber oho!
Db4o arbeitet ACID-konform, unterstützt also die für Datenbanken grundlegenden Arbeitsprinzipien Atomarität (eine Transaktion wird ganz oder gar nicht ausgeführt), Konsistenz (Consistency, eine Transaktion hinterlässt einen konsistenten Zustand), Isolation (Transaktionen beeinflussen sich nicht gegenseitig) und Dauerhaftigkeit (Ergebnis der Transaktion bleibt dauerhaft gespeichert).
Wie bereits gezeigt, kann eine Db4o-Datenbank beliebige Objekte speichern. Der Programmierer muss sie nicht einmal von einer speziellen Persistenzklasse ableiten. Damit die Speicherung dennoch klappt, greift Db4o zu einem Trick: Über den Reflection-Mechanismus analysiert Db4o zunächst die Struktur des übergebenen Objekts und schiebt die dabei erbeuteten Informationen in seine Datenbank. Folglich benötigt man weder ein zuvor erstelltes Schema noch ein Mapping, wie es Hinernate verlangt. Umgekehrt bedeutet das aber auch, dass Db4o derzeit nur mit Java und Dotnet beziehungsweise Mono-Sprachen funktioniert. Alle nachfolgenden Beispiele verwenden Java, sind aber leicht auf C# übertragbar.
Zum Knuddeln
Db4o besteht aus einer einzigen kleinen ».jar«- beziehungsweise ».dll«-Datei. In gerade mal 700 KByte enthält sie die komplette Datenbank-Engine, die sich sogar noch auf bis zu zirka 400 KByte abspecken lässt. Das Leichtgewicht fühlt sich somit auch in Embedded Devices oder mobilen Geräten wohl.
Nach dem Download des aktuellen Db4o-Archivs unter [1] kopiert man die zur jeweiligen Sprachversion passende Bibliothek aus dem »lib«-Verzeichnis in das eigene Projektverzeichnis. Bei einem Java-5-Projekt wäre beispielsweise »db4o-6.0-java5.jar« der richtige Partner. Damit ist die Installation bereits erledigt und Db4o ist einsatzbereit. Im eigenen Programm sind nur noch die benötigten Packages beziehungsweise Namespaces zu importieren – und schon darf man beliebige Objekte eintuppern. Listing 1 zeigt noch einmal ein vollständiges Beispiel für das Speichern zweier Kunden in einer Adressdatenbank.
Die zentrale Anlaufstelle ist das »com.D4o«-Objekt (siehe Kasten “Extensions”). Es enthält verschiedene statische Methoden, die beispielsweise eine neue Datenbank produzieren oder eine existierende konfigurieren. In den meisten Fällen fordert ein Programmierer von ihr lediglich einen »ObjectContainer« an, der die Datenbank selbst und die Zugriffe darauf kapselt.
|
Extensions |
|---|
|
Die Db4o-Programmierschnittstelle besteht eigentlich aus zwei Teilen. Alle Kernfunktionen, die auch in Zukunft unverändert bleiben, liegen im »com.db4o«-Package. Dazu gehören beispielsweise das zentrale »Db4o«-Objekt oder der »ObjectContainer«. Neue oder wenig benutzte Funktionen packen die Entwickler in das »com.db4o.ext«-Paket. Darin befindet sich beispielsweise der »ExtObjectContainer«, der gegenüber seinem »ObjectContainer«-Kollegen ein paar Funktionen mehr auf Lager hat. Pfiffigerweise ist ein »ObjectContainer« auch immer gleichzeitig ein »ExtObjectContainer«. Um an einen »ExtObjectContainer« zu gelangen, genügt entweder ein simples Cast oder der Aufruf der »ObjectContainer.ext()«-Methode. Diese Zweiteilung hat gleich mehrere Vorteile: Einsteiger werden nicht mit unnötigem Ballast bombardiert, die zusätzlichen Funktionen dürfen für eine abgespeckte Db4o-Variante wegfallen und – last but not least – können die Entwickler relativ gefahrlos neue Funktionen anbieten, ohne gleich das Db4o-Kern-API ändern zu müssen. Umgekehrt bedeutet Letzteres aber auch, dass sich alle im »ext«-Namensraum verstauten Funktionen mit jeder neuen Db4o-Version ändern können. Ein prominentes Beispiel liefert das Replication-API. |
Jede Db4o-Datenbank besteht aus einer einzigen Datei, die meist die Endung ».yap« führt, selbst im Client-Server-Modus. Im Beispiel aus Listing 1 heißt sie »adressendatenbank.yap«. In ihr landen alle per »db.set()« gespeicherten Objekte. Das Erstellen eines »ObjectContainer«-Objekts startet gleichzeitig eine Transaktion, die erst ein »db.commit()« explizit abschließt. Gleiches übernimmt »db.close()«, das zusätzlich noch den gesamten Container zusperrt. »db.rollback()« nimmt die jeweils letzte Transaktion zurück.
|
Listing 1: Speichern eines |
|---|
01 package adressbeispiel;
02 import com.db4o.*;
03 import com.db4o.config.*;
04 import com.db4o.query.*;
05
06 class Kunde
07 {
08 private String name;
09 private String adresse;
10 private int kundennummer;
11
12 public Person(String name, String adresse, int kundennummer){
13 this.anrede = name;
14 this.name = adresse;
15 this.kundennummer = kundennummer;
16 }
17
18 public String getName() { return name; }
19 public void setName(String name) { this.name = name; }
20 public String getAdresse() { return adresse; }
21 public int getKundennummer() { return kundennummer; }
22 public void print() {System.out.println(name + adresse + kundennummer);}
23 }
24
25 public class Adressbeispiel {
26 public static void main(String[] args){
27 ObjectContainer db = Db4o.openFile("adressdatenbank.yap");
28 try{
29 Kunde herrbert = new Kunde("Herr Bert", "Hinkburg", 56321);
30 Kunde frauenbart = new Person ("Frau Enbart", "Neustadt", 98217);
31 db.set(herrbert);
32 db.set(frauenbart);
33 }
34 finally{
35 db.close();
36 }
37
38 }
39 }
|
Das per »db.set()« übergebene Objekt landet nicht nur mit Haut und Haaren in der Datenbank, Db4o greift sich auch gleich noch sämtliche an ihm hängenden, respektive alle von ihm referenzierten weiteren Objekte (Persistence by Reachability). Zyklen und anderen Assoziationssalat löst die Datenbank dabei selbstständig auf. Damit stellt sich aber die Frage, wie man an das so verstaute Material wieder herankommt. Der angestaubte Abfrage-Großvater SQL ist auf relationale Datenbanken geeicht und funktioniert somit in diesem Fall nicht. Folglich muss eine neue Abfragesprache her. Db4o kennt davon sogar drei – mit jeweils eigenen Vor- und Nachteilen.
Query by Example (QBE)
Bei der einfachsten Methode erstellt der Programmierer ein Beispielobjekt und weist Db4o an, alle Objekte aus der Datenbank zu fischen, die so aussehen wie diese Vorlage. Um beispielsweise aus dem Adressenbestand alle Kunden aus »Hinkburg« zu erhalten, erstellt er zunächst ein passendes Objekt:
Kunde vorlage = new Kunde(null, "Hinkburg", 0);
Der erste und der letzte Parameter (Name und Kundennummer) stehen auf ihren Standardwerten – in Java sind Integer-Werte standardmäßig »0«, Strings hingegen »null«. Damit weiß Db4o, dass es diese Attribute bei der Suche ignorieren soll und nur der Ortsname »Hinkburg« von Interesse ist. Dieses präparierte Beispielobjekt wandert nun in Db4o:
ObjectSet ergebnisse = db.get(vorlage);
Diese Suchanfrage liefert alle in der Datenbank gespeicherten Objekte, die vom Typ »Kunde« sind und deren Attribut »adresse« den Wert »Hinkburg« enthält. Eine entsprechende SQL-Abfrage wäre »SELECT * FROM Kunde WHERE adresse = \’Hinkburg\’«. Die Ergebnisse landen in einer Liste, die sich anschließend per While-Schleife durchlaufen lässt:
while(ergebnisse.hasNext()) {
((Kunde)(ergebnisse.next())).print();
}
Diese als Query by Example bezeichnete Abfragemethode ist kurz und unkompliziert, leider aber auch extrem unflexibel. So sind beispielsweise keine komplexen Verknüpfungen mit logischen Operatoren möglich, ein “Suche alle Kunden, die in Hinkburg UND Neustadt wohnen” lässt sich also nicht ausdrücken. Darüber hinaus ist eine Suche nach Standardwerten unmöglich: “Alle Personen mit der Kundennummer 0” bleibt in den Untiefen der Datenbank ebenso verschollen wie “Menschen ohne Adresse”.
Native Queries
Warum formuliert man eine Datenbankabfrage nicht einfach direkt in der sowieso schon verwendeten Programmiersprache? Das fragten sich auch die Db4o-Entwickler und bauten kurzerhand die so genannten Native Queries ein. Die dahintersteckende Idee ist auch als Safe Query Objects bekannt [3]. Um beispielsweise herauszufinden, ob eine Person in »Hinkburg« wohnt, genügt es in Java oder C#, einfach das entsprechende Attribut zu prüfen:
if(einkunde.getAdresse() == "Hinkburg")
return true;
Damit Db4o mit einer solchen Formulierung etwas anfangen kann, muss der Programmierer sie noch in eine Methode namens »match()« verpacken, die wiederum zur Klasse »Predicate« gehört. Wie so etwas aussieht, zeigt Listing 2. Das Beispiel einer Native Query gilt für Java bis Version 1.4, Java 5 verwendet dafür Generics.
|
Listing 2: Native Query mit Java |
|---|
01 List kundenaushinkburg = db.query(new Predicate() {
02 public boolean match(Kunde einkunde) {
03 if(einkunde.getAdresse() == "Hinkburg") return true;
04 else return false;
05 }
06 });
|
Damit ist die Suchanfrage bereits komplett. Db4o kramt nun in der Datenbank nach Objekten vom Typ »Kunde«. Immer wenn es einen entsprechenden Kandidaten entdeckt hat, ruft es die »match()«-Methode auf. Sie teilt Db4o wiederum mit, ob es sich tatsächlich um eines der gesuchten Objekte handelt. Da »match()« eine herkömmliche Funktion ist, eignet sie sich zur Kombination mit allen Java- beziehungsweise C#-Sprachelementen. Auch Und-Verknüpfungen sind damit kein Problem mehr, wie Listing 3 beweist. Diese Abfrage liefert alle Kunden aus Neustadt, deren Kundennummer kleiner als 6000 ist.
|
Listing 3: Eine komplexere |
|---|
01 List kundenaushinkburg = db.query(new Predicate() {
02 public boolean match(Kunde einkunde) {
03 return (einkunde.getAdresse() == "Neustadt" && einkunde.getKundennummer()<6000);
04 }
05 });
|
Ob der Code der Abfrage syntaktisch korrekt ist, prüft der Java- oder C#-Compiler bei jedem Übersetzungsvorgang automatisch mit – was mit eingebetteten SQL-Statements nicht klappt. Wenn die eingesetzte Entwicklungsumgebung (IDE) Vorlagen unterstützt, lässt sich das Grundgerüst solcher Abfragen per Knopfdruck in den Quellcode einfügen.
Was für den Programmierer so leicht aussieht, bedeutet allerdings für Db4o unter der Haube Schwerstarbeit. Theoretisch müsste die Datenbank jedes gefundene Objekt zunächst instanziieren und anschließend durch die »match()«-Funktion pressen. Dies kostet jedoch Zeit und Hauptspeicher. Aus diesem Grund analysiert Db4o den Inhalt der »match()«-Funktion und versucht den darin enthaltenen Code in eine so genannte SODA-Anfrage zu übersetzen.
Blubberblasen
SODA bezeichnet in diesem Fall kein Getränk, sondern die dritte von Db4o unterstützte Abfragesprache. Das Akronym steht für Simple Object Database Access. Im Vergleich mit den Native Queries bedeuten sie etwas mehr Schreibarbeit. Dafür erlaubt sie einen feingranularen Zugriff auf die Abfrage, die Db4o auch noch relativ fix ausführt. Die Db4o-Entwickler bezeichnen SODA daher auch als ihr Low Level Query API.
Um per SODA an alle Kunden heranzukommen, die in »Hinkburg« wohnen, ist zunächst ein neues Query-Objekt nötig:
Query query = db.query();
Es repräsentiert eine Datenbankabfrage, die in diesem Zustand noch alle Objekte aus der Datenbank zurückliefern würde. Folglich muss die Ergebnismenge etwas schrumpfen beziehungsweise sich auf die gewünschten Objekte beschränken. Im Beispiel interessieren nur alle Kunde-Objekte:
query.constrain(Kunde.class);
Wenn die Suche anschließend mit der Anweisung
ObjectSet ergebnisse=query.execute();
beginnt, liefert Db4o alle gespeicherten Personen-Objekte aus der Adressdatenbank zurück. Um nur alle Kunden aus »Hinkburg« zu erhalten, ist eine weitere Einschränkung der Adresse fällig:
query.descend("adresse").constrain("Hinkburg");
Dieser Befehl hangelt sich zunächst zu dem Attribut mit dem Namen »adresse« durch und gibt ihm die Einschränkung »Hinkburg«. Abbildung 1 zeigt einen solchen Graphen, in dem jeder Knoten eine Einschränkung erhält. Die Funktion »descent()« durchläuft dann den Graphen. Auch komplexe Abfragen sind mit dieser etwas gewöhnungsbedürftigen Notation möglich. Listing 4 liefert beispielsweise den Kunden aus »Neustadt« mit der Kundennummer »56321«.
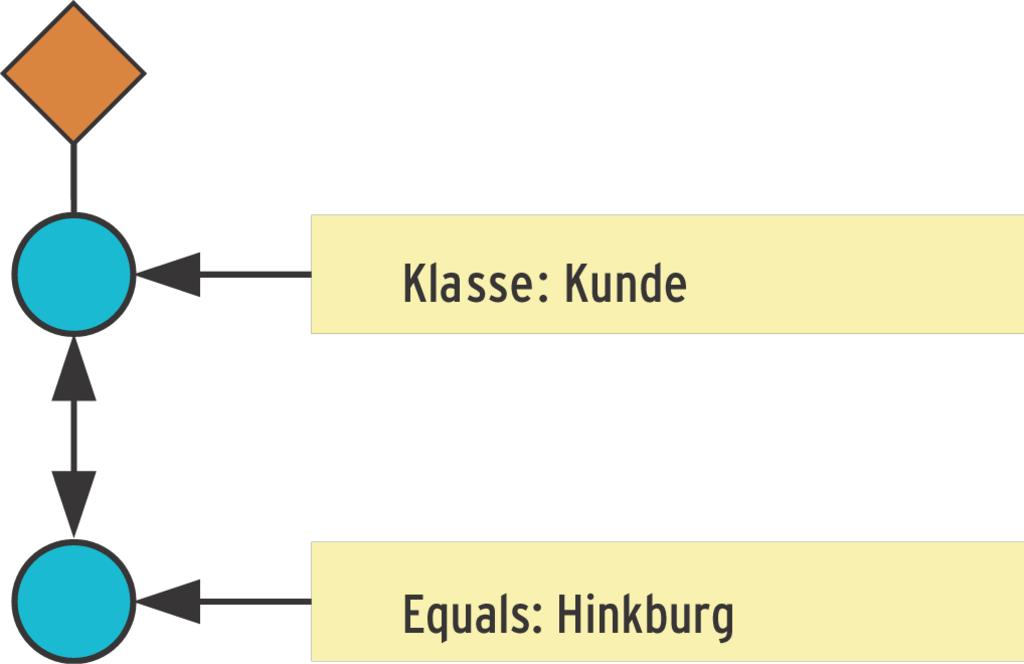
Abbildung 1: Graph einer SODA-Abfrage, bei der die Knoten Suchbedingungen festlegen.
|
Listing 4: Komplexe |
|---|
01 Query query=db.query();
02 query.constrain(Kunde.class);
03 Constraint constr=query.descend("adresse").constrain("Neustadt");
04 query.descend("kundennummer").constrain(new Integer(56321)).and(constr);
05 ObjectSet ergebnisse=query.execute();
|
Neben »and()« bietet SODA alle üblichen und noch viele weitere nützliche Operatoren. Eine vollständige Referenz steht unter [4] bereit. Da umfangreiche Abfragen in recht komplexe Gebilde ausarten können, wird der Anwender in der Praxis hauptsächlich auf Query by Example oder Native Queries zurückgreifen. Die Nutzung des SODA-API bietet sich vor allem dann an, wenn Abfragen dynamisch zu erzeugen sind. Dabei ist jedoch stets zu beachten, dass es keinen verbindlichen Standard gibt, im Gegenteil: Als offenes Sourceforge-Projekt sieht sich SODA noch munteren Änderungen unterworfen [4].
Die bei einer Suchanfrage zurückgelieferten Objekte sind grundsätzlich vollständig instanziiert. Wenn ein Kunde eine Referenz auf seine Bestellung enthält, würde Db4o nicht nur die gesuchte Person, sondern auch gleich noch das von ihr referenzierte Bestell-Objekt zurückliefern. Diese Automatik hat jedoch ihre Grenzen. Beispielsweise dann, wenn sie Objekte in der Datenbank aktualisieren oder aus ihr löschen muss. Das Update eines einfachen Objekts in der Datenbank übernimmt »set()«:
herrbert.setName("Herr Appeldorn");
db.set(herrbert);
Db4o erkennt selbstständig, dass das Objekt bereits in der Datenbank liegt und also nur noch aktualisiert werden muss. Um es komplett aus der Datenbank zu werfen, spürt man es zunächst auf und schickt es dann per »delete()«-Befehl ins Nirwana:
ObjectSet ergebnisse=db.get(new Kunde("Herr Bert",null, 0));
Kunde herrbert=(Kunde)ergebnisse.next();
db.delete(herrbert);
Wenn nun ein Kunde mit einer Bestellung verbunden ist, stellt sich für Db4o die Frage, ob es genau jene Bestellung ebenfalls aktualisieren beziehungsweise löschen muss. In diesem einfachen Beispiel lässt sich die Frage noch recht schnell klären. In der Praxis herrschen gewöhnlich jedoch weitaus komplexere Beziehungen. Im Fall einer Aktualisierung müsste Db4o unter Umständen zunächst eine riesige Menge von Objekten instanziieren, denn schließlich hängt an dem Objekt ein Objekt, an dem ein Objekt hängt.
Objekt-Hierarchien
Wie tief soll Db4o also in die Objekt-Hierarchie hinabsteigen? Da die Datenbank diese Frage nicht mehr selbst lösen kann, überlässt sie die Entscheidung dem Programmierer. Die Anzahl der Hierarchie-Ebenen, die Db4o berücksichtigt, heißt dabei Update Depth. Der Ausdruck
Db4o.configure().objectClass("Kunde").cascadeOnUpdate(true);
weist Db4o an, bei einem »Kunde«-Objekt grundsätzlich allen Referenzen bis zum bitteren Ende zu folgen, also so tief wie möglich in die Objekt-Hierarchie hinabzusteigen. Die passende Konfigurationsanweisung für den Löschvorgang lautet analog:
Db4o.configure().objectClass("Kunde").cascadeOnDelete(true);
Damit verschwindet auch die an dem zu löschenden Personeneintrag hängende Bestellung aus der Datenbank. Um ihre Wirkung zu entfalten, muss der Programmierer die Konfigurationsbefehle übrigens immer vor dem Öffnen eines Containers absetzen.
Das Problem mit den Hierarchien taucht noch an einer anderen Stelle auf. Dies lässt sich am einfachsten mit einer verketteten Liste wie der aus Listing 5 demonstrieren. Eine Bestellung verweist einfach über »next« auf die nächste Bestellung. Der Kunde braucht dann nur noch eine Referenz auf das erste Element in der Bestellkette.
|
Listing 5: Verkettete |
|---|
01 class Bestellung{
02 private String produkt;
03 private Bestellung next;
04 public Bestellung getNext() {
05 return next;
06 }
07 ...
08 }
09
10 class Kunde {
11 ...
12 private Bestellung erstebestellung;
13 public Bestellung getErstebestellung() {
14 return erstebestellung;
15 }
16 ...
17 }
|
Suchtiefe festlegen
Wer einen Kunden aus der Datenbank holt und seinen Bestellungen folgt, erhält immer nur genau die ersten fünf Bestellungen (Listing 6). Theoretisch könnte Db4o zwar die gesamte Liste erstellen und zurückliefern. Im schlechtesten Fall – beispielsweise bei einer sehr langen Liste – würden dann aber alle Objekte aus der Datenbank instanziiert und den Hauptspeicher fluten. Also folgt Db4o standardmäßig nur fünf Referenzen in die Tiefe. Alle anderen sind dann automatisch »null«.
|
Listing 6: Bestellungen |
|---|
01 ObjectSet ergebnisse=db.get(Kunde.class);
02 Kunde einkunde=(Kunde)ergebnisse.next();
03 Bestellung eintrag=einkunde.getErstebestellung();
04 while(eintrag!=null) {
05 System.out.println(eintrag);
06 eintrag=eintrag.getNext();
07 }
|
Wer tiefer hinabsteigen will, muss explizit das hinter einer Referenz stehende Objekt mit
while(eintrag != null) {
db.activate(eintrag,1);
System.out.println(eintrag);
eintrag = eintrag.getNext();
}
aktivieren oder die so genannte Activation Depth erhöhen. Das kann der Programmierer beispielsweise über folgende Anweisung erledigen:
Db4o.configure().objectClass(Bestellung.class).cascadeOnActivate(true);
Damit steigt Db4o die gesamte Hierarchie hinab.
|
Unter falscher |
|---|
|
Datenbanken klassifiziert man nach der Art, wie sie ihre gespeicherten Daten strukturieren und in Relation zueinander setzen. Die bekannten relationalen Datenbanken arbeiten mit Tabellen, während die Objektdatenbanken ganze Datenobjekte verdauen. Zwischen den beiden Extremen gibt es noch Mischformen, beispielsweise die objektrelationalen Datenbanken. Sie nehmen Objekte zwar entgegen, pressen sie aber intern wieder in eine Tabellenform. Hierzu zählen beispielsweise Hibernate und die meisten Datenbanken, die den Standard JDO einhalten [6], zum Beispiel Apache JPOX vor Version 1.2 [7] oder Speedo [8], aber auch die von Oracle&Co. angebotenen Wrapper. Einige Datenbankhersteller verwenden gerne den etwas schwammigen Begriff der objektorientierten Datenbank, hinter der sich meist jedoch nur eine objektrelationale Datenbank verbirgt. Reine und auch noch kostenlose Objektdatenbanken muss man immer noch mit der Lupe suchen. Für Python existiert beispielsweise ZODB [9], deren Objekte der Anwender jedoch alle von einer Persistenzklasse ableiten muss. Der brauchbare Rest, beispielsweise Versant [10], stammt aus kommerziellen Softwarehäusern. |
Server-Modus
Bisher fand Db4o lediglich als eingebettete Datenbank Verwendung. Einen eigenständigen Server liefert der Hersteller nicht aus, doch lässt sich Db4o in einen Server-Modus versetzen. Dazu ist nur ein passendes Server-Objekt zu erstellen:
ObjectServer server=Db4o.openServer("adressdatenbank", Port);
Ab sofort lauscht der Server am TCP-Port Port auf eingehende Anfragen. Per
server.grantAccess(Benutzer, Passwort);
schränkt man den Zugriff noch auf den Benutzer mit seinem Passwort ein. Die Client-Anwendung erzeugt wie gewohnt einen Container, der diesmal jedoch keine Datei öffnet, sondern den (auf Localhost laufenden) Server anspricht:
ObjectContainer client=Db4o.openClient("localhost", Port, User, Passwort);
Ab hier funktioniert der »client« wie ein normaler Container.
Synchron
Die Adressdatenbank auf einem Notebook oder dem mobilen Pocket-PC verlangt regelmäßig einen Abgleich mit ihrem Pendant am Arbeitsplatz. Das gleiche Phänomen kennen Datenbankentwickler als Replikation. Ist ein Objekt aus der Datenbank A auch in der Datenbank B zu finden, müssen Änderungen an einem Objekt immer auch in der jeweils anderen Datenbank auftauchen. Eine derartige Replikation erlaubt Db4o seit Version 5.
Nur kurze Zeit nach der Veröffentlichung haben die Entwickler die Funktionen zur Replikation jedoch schon wieder aus Db4o entfernt. Heute stecken sie in einem separat erhältlichen Zusatzmodul namens Db4o Replication System, kurz DRS [5]. Die noch im Kern verbliebenen Replikations-Funktionen sind als veraltet gekennzeichnet und sollten nicht mehr verwendet werden. Die Installation des DRS-Pakets funktioniert wie bei Db4o.
Die eigentliche Replikation einer Datenbank läuft genauso schnell ab. Zunächst muss ein Objekt in allen Datenbanken wiedererkannt werden. Das erreicht Db4o durch Zuweisung einer eindeutigen Nummer, der Unique Universal ID. Deren automatische Berechnung ist, da sie Zeit kostet, abgeschaltet, bei Bedarf muss der Programmierer sie per Hand aktivieren:
Db4o.configure().generateUUIDs(ConfigScope.GLOBALLY);
Gleiches gilt für die Versionsnummern, an denen Db4o Änderungen erkennt:
Db4o.configure().generateVersionNumbers(ConfigScope.GLOBALLY);
Dann sind noch zwei Datenbanken einzurichten:
ObjectContainer adressdatenbankA = Db4o.openFile("adressenA.yap");
ObjectContainer adressdatenbankB = Db4o.openFile("adressenB.yap");
Hier sollen die Objekte aus »adressdatenbankA« in der Datenbank »adressdatenbankB« landen. Dies erfährt das DRS über ein passendes Replication-Objekt:
ReplicationSession replication = Replication.begin(adressdatenbankA, adressdatenbankB);
Dieses Objekt führt auch gleich die Replikation durch. Damit fehlt nur noch die Information, welche Objekte aus der »adressdatenbankA« in die »adressdatenbankB« wandern sollen. Am besten nur jene, die sich seit dem letzten Abgleich verändert haben:
ObjectSet changed = replication.providerA().objectsChangedSinceLastReplication();
Über die auf diese Weise erhaltene Ergebnismenge iteriert die folgende Schleife und stopft dabei jedes gefundene Objekt in die »adressdatenbankB«:
while (changed.hasNext())
replication.replicate(changed.next());
Ein darauf folgendes »replication.commit()« sorgt für einen ordnungsgemäßen Abschluss.
Die Replikation geschieht auf Wunsch sogar in eine relationale Datenbank. Im Hintergrund zieht Db4o dazu Hibernate heran, das die von Db4o angelieferten Objekte wieder in die gewohnte Tabellenform presst.
Besser als SQL
Db4o macht süchtig. In 90 Prozent der Fälle genügen bereits neun oder zehn Db4o-Funktionen. Dank Native Queries muss zudem niemand eine spezielle Abfragesprache lernen. Zudem macht Db4o sogar Refactorings häufig ohne Anpassungen mit: Neue oder erweiterte Objekte versucht es automatisch auf bereits in der Datenbank gespeicherte abzubilden. Sollte der »Kunde« beispielsweise nachträglich das Attribut »telefon« erhalten, klappen trotzdem noch Suchanfragen an die Datenbank. In den zurückgelieferten Objekten lässt Db4o das neue Feld einfach leer. Auf eine ähnliche Weise geht die kleine Datenbank auch mit Vererbung um.
Nur Administratoren müssen umdenken: Da Db4o nur eingebettet funktioniert, gibt es weder einen eigenen Server noch eine schmucke Administrationsoberfläche. Hier ist der Programmierer für alles alleine verantwortlich. Immerhin gibt es seit Neuestem den »ObjectManager« (Abbildung 2), mit dem der Admin wenigstens einen kleinen Einblick in eine bestehende Db4o-Datenbank erhält. Ein paar Hinweise zu alternativen Objektdatenbanken gibt der Kasten “Unter falscher Flagge”. (ofr)

Abbildung 2: Der »ObjectManager« bietet einen ersten, schnellen Einblick in eine Datenbank.
|
Infos |
|---|
|
[1] Objektdatenbank Db4o: [http://www.db4o.com] [2] Persistenzframework Hibernate: [http://www.hibernate.org] [3] William R. Cook, Siddhartha Rai, “Safe Query Objects, Statically Typed Objects as Remotely Executable Queries”: [http://www.cs.utexas.edu/~wcook/papers/SafeQuery05/SafeQueryFinal.pdf] [4] SODA-Abfragen: [http://sodaquery.sourceforge.net] [5] Db4o Developer Community: [http://developer.db4o.com] [6] Java Data Objects: [http://java.sun.com/javaee/technologies/jdo] [7] Apache JPOX: [http://www.jpox.org] [8] Speedo: [http://speedo.objectweb.org] [9] Zope ZODB: [http://wiki.zope.org/ZODB] [10] Versant: [http://www.versant.com/de_DE] |
|
Der Autor |
|---|
|
Tim Schürmann ist selbstständiger Diplom-Informatiker und derzeit als freier Autor unterwegs. Zu seinen Büchern gesellen sich zahlreiche Artikel, die in Zeitschriften und auf Internetseiten in mehreren Ländern veröffentlicht wurden. |






