
© everythingpossible, 123RF
Den Begriff P2P verbinden viele Nutzer unwillkürlich mit Bittorrent und dem (nicht immer legalen) Tausch von Dateien. Dabei lassen sich über Peer-to-Peer-Netzwerke auch Internetauftritte und andere Dienste anonym anbieten. Fünf darauf spezialisierte Netze treten in der Bitparade zu einem Vergleich an.
Fällt im World Wide Web ein Webserver aus, sind die entsprechenden Seiten nicht mehr erreichbar. Administratoren versuchen das durch redundante Systeme zu kompensieren, die jedoch wiederum einen hohen Wartungsaufwand erfordern. Zugleich fließen alle Daten meist unverschlüsselt über die Leitungen, selbst beim Einsatz einer SSL/TLS-Verschlüsselung identifizieren Dritte immer noch Absender und Empfänger.
Beide Nachteile wollen gleich mehrere Projekte mit hybriden und reinen Peer-to-Peer-Ansätzen (P2P) erschlagen, soll heißen: Ähnlich wie beim Datei-Austausch über Bittorrent liegen die Webseiten nicht mehr auf einem zentralen Server. Stattdessen bieten die im Netz hängenden Clients die Webseiten an.
Einige der Anbieter verteilen die Daten dabei auf mehrere Netzwerkknoten. Verschwindet ein Client aus dem Netz, sind die Daten noch vorhanden. Weil die Projekte den Traffic zudem durchgängig verschlüsseln, kann keiner der Teilnehmer die Kommunikation der anderen belauschen. Sowohl die Anbieter der Webseiten als auch die Nutzer bleiben also anonym.
Um P2P-Netzwerke wie Freenet [1], I2P [2], IPFS [3], Tor [4] und Zeronet [5] zu verwenden, müssen Anwender lediglich die von den Projekten bereitgestellte Clientsoftware auf ihrem Rechner installieren. Alle fünf Netzwerke stehen jedem Interessenten offen, sie bilden folglich keine abgeschotteten Darknets.
Alte Kamellen
Neben den vorgestellten P2P-Netzwerken gibt es noch weitere, deren Entwicklung jedoch größtenteils stagniert. Dazu gehört Gnunet, an dem Entwickler bereits seit dem Jahr 2001 arbeiten [26]. Das P2P-Netz diente ursprünglich zum “anonymen, Zensur-resistenten Filesharing”.
Mittlerweile sind weitere Dienste hinzugekommen. So kann der VPN-Service herkömmlichen IPv4- und IPv6-Verkehr über das Gnunet leiten und so beliebige Dienste über das P2P-Netzwerk anbieten. Das GNU Name System (GNS) ersetzt zudem das Domain Name System. Gnunet Conversation erlaubt sogar Telefongespräche, gewährleistet aber derzeit keine vollständige Anonymität. Die letzte Version 0.10.1 des Clients stammt vom April 2014.
Im Tiefschlaf befinden sich auch Osiris [27] und Netsukuku [28]. Die letzte stabile Version 0.15 von Osiris erschien im November 2011, die Arbeit an Version 1.0 stagniert seit Dezember 2014 in der Alphaphase. Von Netsukuku sollte 2010 eine komplette Neuentwicklung erscheinen, was bislang nicht passiert ist.
Nicht in den Vergleich geschafft hat es auch Retroshare [29]. Mit diesem P2P-Netz baut ein User eine verschlüsselte Verbindung zu einem oder mehreren Freunden auf. Diese können dann miteinander chatten, Videotelefonie betreiben, sich E-Mails schicken, Dateien austauschen und in Foren diskutieren. Retroshare garantiert keine Anonymität – wer seine IP-Adresse verschleiern will, muss die Kommunikation über Tor oder I2P leiten.
Die einzelnen Clients kommunizieren untereinander verschlüsselt, wobei jedes P2P-Netz seine eigenen Protokolle verwendet. Der Versand der Nachrichten erfolgt jedoch bei allen Kandidaten über das Internet und mit Hilfe der dort bewährten Protokolle. Die Clients stülpen somit dem vorhandenen Internet ein eigenes Netz mit eigenen URLs über und verwenden mitunter sogar einen eigenen Namensdienst. Die über das Netz verfügbaren Dateien, Websites und Dienste erhalten eindeutige IDs, die die Clients über kryptographische Verfahren erzeugen. Über diese ID fordern dann wiederum andere Clients die Daten an. In einigen der besprochenen P2P-Netze lassen sich zudem einmal veröffentlichte Webseiten nicht wieder zurückrufen beziehungsweise löschen.
Freenet
Die Geschichte des Freenet-Projekts reicht bis ins Jahr 1999 zurück [1]. Der irische Student Ian Clark entwickelte zunächst die Idee eines “verteilten anonymen Informationsspeicher- und Abrufsystems”, die er dann mit mehreren Helfern als Freenet umsetzte. Mittlerweile koordiniert das eigens zu diesem Zweck gegründete und spendenfinanzierte Unternehmen The Freenet Project Inc. die Entwicklung.
Über Freenet tauschen User Dateien aus, veröffentlichen aber auch komplette Websites. Letztere bezeichnet der Freenet-Sprech als Freesites. Damit niemand die Kommunikation der Teilnehmer verfolgt, leitet Freenet die verschlüsselten Pakete gleich über mehrere Rechnerknoten. Darüber hinaus weisen Benutzer ihren Client an, sich nur mit bekannten und vertrauenswürdigen Personen beziehungsweise Knoten zu verbinden. Die Freenet-Entwickler bezeichnen diese Betriebsart inkonsistent als Darknet-Mode oder High-Security-Modus.
Freenet liegt ein verteiltes Dateisystem zugrunde, zu dem jeder Nutzer etwas von seinem Festplattenplatz beisteuert. Technisch puffert der Freenet-Client in diesem so genannten Data Store einige der in Freenet angebotenen Dateien in verschlüsselter Form.
Welche Dateien wie lange im Data Store verbleiben, bestimmt allein der Freenet-Client. Der lag bei Redaktionsschluss in der Version 0.7.5 vor. Sein Code steht zu Teilen unter der GNU GPL und der Apache-Lizenz. Der Client selbst ist in Java geschrieben und setzt daher ein Java Runtime Environment (JRE) ab Version 1.6 voraus. Die Entwickler empfehlen die JRE von Oracle ab Version 1.7.
Die Installation des Clients erfolgt bevorzugt über den Java Web Start Installer [6], der aber ein im Browser installiertes Java-Plugin voraussetzt. Alternativ stellen die Entwickler unter [7] einen Installationsassistenten bereit, den Nutzer über »java -jar new_installer_offline.jar« starten. Der komplette Quellcode des Clients wartet auf Github [8].
Direkt nach Abschluss der Installation öffnet sich der Browser mit einem kleinen Assistenten (Abbildung 1). In ihm gibt der Nutzer unter anderem die Größe des Datenspeichers vor. Minimal möglich sind 512 Mebibyte, maximal 100 Gibibyte. Des Weiteren legt er die pro Monat maximal zu übertragende Datenmenge fest und limitiert die Bandbreite. So stellt er sicher, dass Freenet nicht dauerhaft seine Bandbreite blockiert.
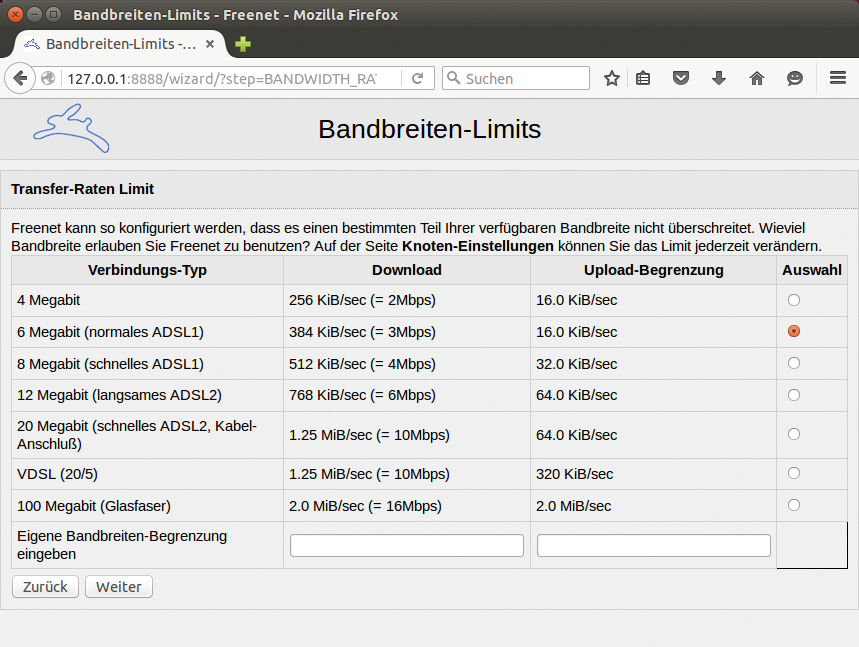
Abbildung 1: Die Installation des Freenet-Clients übernimmt dieser Assistent.
Der Freenet-Client läuft als Daemon im Hintergrund. Ihn trägt der Installationsassistent in die Startskripte ein. Die Aktivitäten des Daemon verzögern mitunter den Systemstart und auch das Herunterfahren des Rechners drastisch. Der Client bietet unter der URL »http://localhost:8888« eine Benutzeroberfläche an. Über sie laden User neue Dateien hoch und ändern die Client-seitigen Grundeinstellungen (Abbildung 2). Auf der Startseite der Weboberfläche finden sie zudem eine zurzeit noch experimentelle Suchmaschine vor, die Objekte im Freenet-Netzwerk aufspürt.
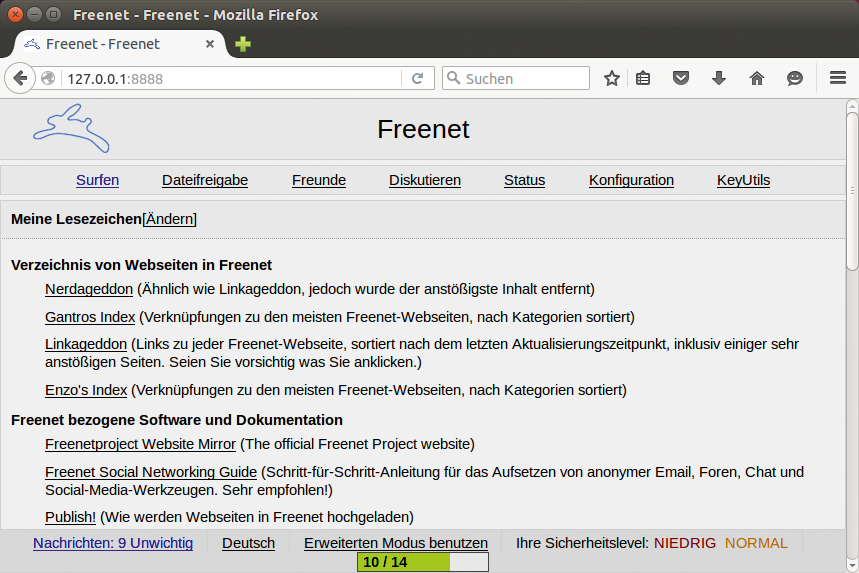
Abbildung 2: Die Weboberfläche des Freenet-Clients dient mit einer Linkliste als Einstiegspunkt in das Freenet-Netzwerk.
Im Freenet erhalten alle Daten eine ID, den so genannten Key. Möchten Nutzer Daten abrufen, hängen sie lediglich den zugehörigen Schlüssel an die URL »http://localhost:8888/« an. Freenet unterscheidet für die unterschiedlichen Daten beziehungsweise Dienste zwischen vier Keytypen. In jedem Fall ist das Ergebnis ein kryptisches Monster wie:
USK@0iU87PXyodL2nm6kCpmYntsteViIbMwlJE~wlqIVvZ0,nenxGvjXDElX5RIZxMvwSnOtRzUKJYjoXEDgkhY6Ljw,AQACAAE/freenetproject-mirror/243/
Etwas Abhilfe verschaffen die Keyword Signed Keys. Sie erlauben es Usern, benannte Seiten und Dateien nach dem Muster »KSK@eine_Datei.txt« in Freenet zu speichern. Da aber mehrere Nutzer den gleichen Namen für eine Datei verwenden dürfen, schützen diese Keys nicht vor Spamming und Hijacking.
Freenet bietet zudem Container an. Dabei handelt es sich um Archive aus mehreren Dateien, die maximal 2 MByte groß sein dürfen und meist eine Freesite enthalten. Mit ihnen lädt der Freenet-Client die komplette Website auf einmal und nicht in Einzelteilen.
Seiten bauen
Wer eigene Webseiten im Freenet anbieten möchte, greift auf das grafische Tool Jsite zurück (Abbildung 3). Der Autor muss lediglich ein neues Projekt anlegen, den Dateipfad zu den fertigen Webseiten auf der Festplatte angeben und die Datei mit der Startseite auswählen (in der Regel die »index.html« ). Jsite lädt dann die Website in das Freenet hoch und zeigt den Key an, über den die Website erreichbar ist. In PHP oder anderen Skriptsprachen geschriebene Webseiten ermöglicht Freenet nicht. Die Funktionen des Clients erweitert der Anwender über Plugins, bereits existierende rüsten unter anderem ein E-Mail-System, einen Microblogging-Dienst und ein Chatsystem nach.
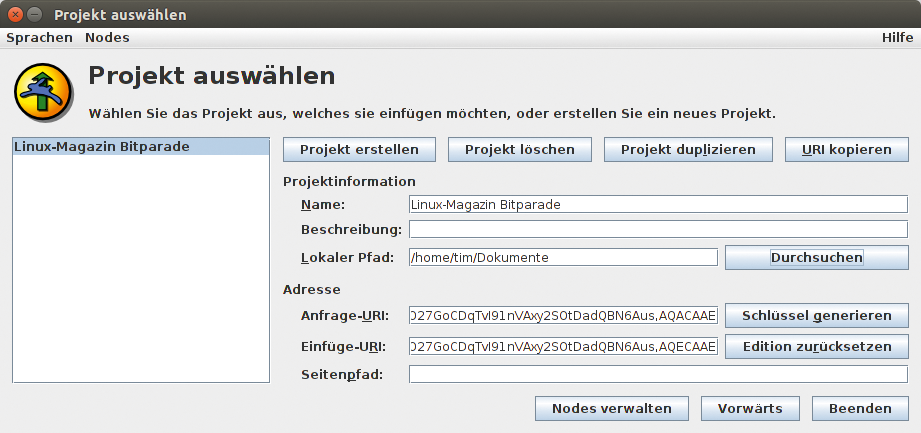
Abbildung 3: Mit dem Tool Jsite speisen Nutzer eigene Webseiten in das Freenet-Netzwerk.
Die Dokumentation besteht aus einem spärlich gefüllten Wiki [9] und einer knappen Anleitung auf der Homepage [10], die aufgrund des schwarzen Hintergrunds schon nach kurzer Zeit die Augen tränen lässt. Eine weitere Seite [11] zeigt, wie der Nutzer bekannte Plugins einsetzt und verwendet, eine Linksammlung auf der Homepage verweist auf mehrere Whitepaper zu Freenet.
I2P
Das Netzwerk des Invisible Internet Project (I2P, [2]) soll in erster Linie eine anonyme Kommunikation garantieren. I2P gehört zu den besonders häufig genutzten P2P-Netzwerken. Die Clientsoftware steckt in vielen Sicherheitsdistributionen und liegt sogar für Android-Smartphones vor. Im August 2015 fand in Toronto mit der I2PCon erstmals eine eigene Konferenz rund um I2P statt [12]. Die Arbeiten an I2P begannen bereits 2003, ursprünglich war die Software eine Modifikation von Freenet.
Im Gegensatz zu IPFS oder Freenet speichert das I2P-Netz keine Dateien, sondern ermöglicht lediglich den verschlüsselten Versand von Datenpaketen zwischen den Clients. Andere Programme nutzen dies wiederum, um anonym miteinander zu kommunizieren beziehungsweise im I2P-Netz ihre Dienste anzubieten. Ein User könnte beispielsweise auf seinem Rechner einen Webserver starten und dann dessen Dienste über den I2P-Client im I2P-Netz anbieten. Jeder Kommunikationsendpunkt erhält dabei eine eigene ID, die ein kryptographisches Verfahren erzeugt und die als Empfangs- und Versandadresse dient. Im Beispiel würde folglich der laufende Webserver eine eigene ID erhalten.
Möchte ein Client eine Nachricht verschicken, sendet er diese zunächst über mehrere andere Rechner in Richtung Ziel. Diese Kette bezeichnen die I2P-Entwickler als Outbound Tunnel (Abbildung 4). Bevor die Nachricht beim Zielrechner ankommt, durchläuft sie ebenfalls eine Kette von Rechnern, den so genannten Inbound Tunnel.
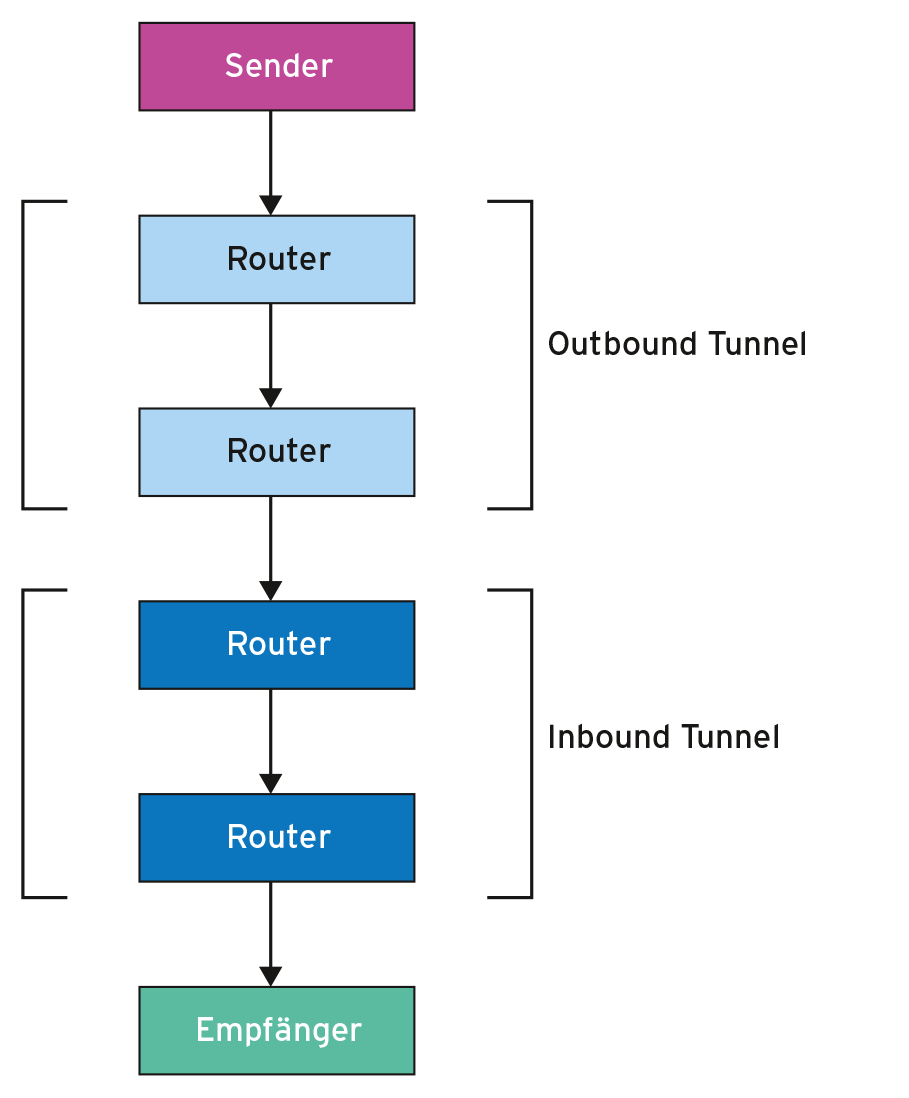
Abbildung 4: Im I2P-Netz wählt der Sender die Rechner für den Outbound Tunnel, der Empfänger die Rechner für den Inbound Tunnel. Dies soll eine anonyme Kommunikation ermöglichen.
Der Rückweg durch die Tunnel ist dabei jeweils ausgeschlossen. Jeden Knoten in diesen Ketten bezeichnet I2P als Router. Der eigentliche Transport der verschlüsselten Daten erfolgt via IP-Protokoll.
Anstelle des aus dem Internet bekannten DNS-Systems setzen die I2P-Entwickler auf verteilte Adressbücher: Zunächst besitzt jeder Anwender auf seinem lokalen System ein eigenes Adressbuch, in dem er jedem Endpunkt beliebige Namen zuordnen kann. Zusätzlich darf der User die Adressbücher von anderen, als vertrauenswürdig eingestuften Quellen importieren.
Wollen Anwendungen Daten über I2P verschicken, müssen sie entsprechend programmiert sein. Die I2P-Entwickler stellen dazu eine passende Java- sowie eine einfache C-Bibliothek bereit. Eine Python- und Perl-Anbindung ist derzeit in Arbeit. Programme, die ihre Daten per UDP austauschen, lassen sich recht einfach für den Einsatz mit I2P umrüsten: Möchte die Anwendung Daten an ein bestimmtes Ziel senden, muss sie in der Regel I2P lediglich dessen kryptographische ID nennen. I2P verschlüsselt diese dann und stellt sie zu.
Die I2P-Entwickler bieten zudem eine Streaming-Bibliothek an, mit der Anwendungen ähnlich wie über TCP miteinander kommunizieren. Insbesondere bringt die Bibliothek eine Congestion Control mit [13] und stellt so sicher, dass Pakete auch wirklich ihr Ziel erreichen.
Auf Wunsch schleust das Tool I2PTunnel normalen TCP-Verkehr durch das I2P-Netz. Damit lässt sich bestehende Software weiterverwenden. Beispielsweise kann ein User einen normalen Webserver auf seinem Rechner starten und dann mit I2PTunnel diesen Webserver im I2P-Netz verfügbar machen. Ergänzend bringt I2P mit Eeproxy einen HTTP-Proxy mit, über den User mit einem Browser die Dienste im I2P-Netz abrufen. Will ein Anwender viele Dienste gleichzeitig nutzen, muss er für jeden einen Tunnel aufbauen. Das kostet zusätzliche Ressourcen. Der Proxy verhindert auch nicht, dass der Browser Informationen über seinen Benutzer und das Betriebssystem mitsendet.
I2P-Anwendungen
Mittlerweile existieren auch explizit für I2P entwickelte Anwendungen. Der I2P-Messenger erlaubt sichere und anonyme Chats über das I2P-Netz. Andere Programme helfen beim Filesharing, dem Austausch von E-Mails und dem Aufbau von Blogs. Der Webserver Eepsite [14] bietet Seiten direkt über das I2P-Netz an, während sich mit Tahoe-LAFS [15] ein verteilter Datenspeicher beziehungsweise eine Cloud im I2P-Netz aufbauen lässt. Die Alltagstauglichkeit der einzelnen Programme schwankt jedoch stark.
Die I2P-Entwickler stellen auf ihren Projektseiten ein Paket bereit, das den I2P-Router, die I2P-Bibliotheken und ausgewählte Anwendungen enthält. Die Komponenten stehen unter verschiedenen Open-Source-Lizenzen, die Kernbestandteile sind durchweg Public Domain – jeder darf mit dem Quellcode anstellen, was er möchte.
Für Ubuntu, Mint, Debian und Knoppix stehen fertige Pakete bereit, alle anderen Linux-Anwender greifen zum angebotenen Installationsassistenten. Voraussetzung für den Einsatz ist eine JRE ab Version 1.6, die Entwickler empfehlen jedoch mindestens Java 7. Der Quellcode lagert auf Github [16]. Die Software lag zum Redaktionsschluss in der stabilen Version 0.9.24 vor, Aktualisierungen erscheinen im Schnitt alle sechs bis zehn Wochen mit kleineren Neuerungen oder Änderungen.
Anwender starten zunächst den I2P-Router »i2prouter« , der als Daemon läuft und die Datenpakete mit anderen I2P-Routern im Netz austauscht. Auf seine Dienste greifen anschließend die Bibliotheken zurück, auf denen wiederum die Anwendungen aufbauen. Unter der URL »http://localhost:7657« bietet der Router auch eine Weboberfläche an (Abbildung 5). Dort dürfen User in die Konfiguration eingreifen und geben unter anderem die maximal nutzbare Bandbreite vor. Die zahlreichen von I2P eingesetzten Ports listet die Dokumentation auf [17].
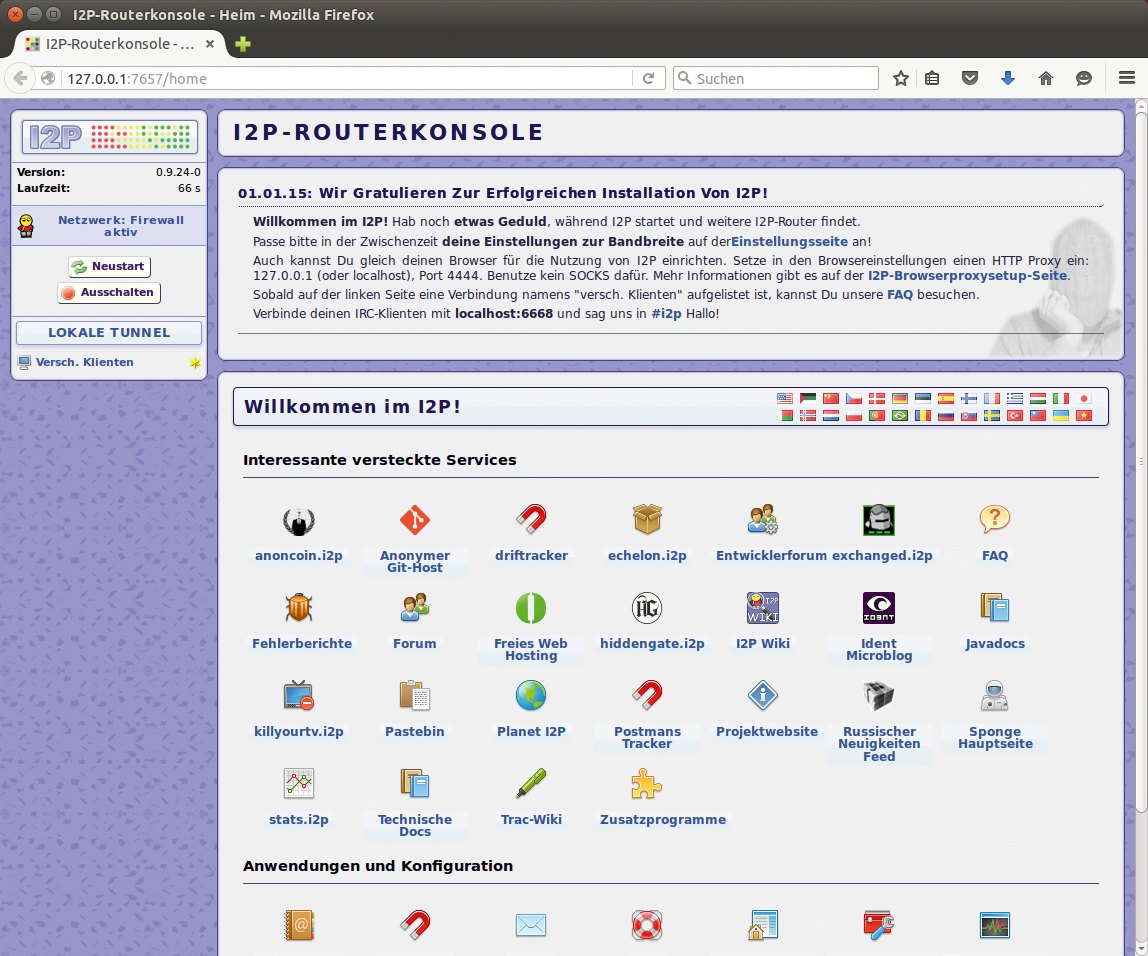
Abbildung 5: Die Weboberfläche des I2P-Clients bietet bereits zahlreiche Links auf Dienste im I2P-Netz.
Zum Paket gehört auch ein Adressbuch, das einige wichtige Webseiten und Dienste mit lesbaren Adressen versieht. So findet sich etwa unter [18] das I2P-Forum. Damit der Browser diese Adressen im I2P-Netz ansteuern kann, muss der User in den Browser-Einstellungen manuell den I2P-Proxy eintragen, der unter der IP-Adresse »127.0.0.1« an Port »4444« wartet.
Dank des vorkonfigurierten Clients stellen Anwender schnell ihre eigene Internetseite im I2P-Netz bereit. Sie müssen nur ihre Webseiten in einem vorgegebenen Unterverzeichnis verstauen und einen passenden Tunnel darauf aktivieren. Eine Jetty-Instanz liefert die Webseite dann aus und lauscht auf Port »7658« . Die I2P-Router lassen sich über Plugins erweitern. Die Dokumentation beschränkt sich auf eine allgemeine Onlinehilfe auf der I2P-Homepage.
IPFS
Wie der Name andeutet, ist das Interplanetary File System (IPFS, [3]) im Kern ein verteiltes Dateisystem. Über dies sollen die Nutzer in erster Linie Hypermedia-Inhalte und somit Websites anbieten. Maßgeblich entwickelt das Dateisystem die amerikanische Firma Protocol Labs, die jedoch alle Interessierten zur Mitarbeit einlädt. Das Protokoll und die Clientsoftware befinden sich derzeit in einer frühen Entwicklungsphase. Zum Redaktionsschluss aktuell war der IPFS-Client 0.4.0, der einer MIT-Lizenz untersteht und komplett in Go programmiert ist. Sein Quellcode findet sich auf Github [19], fertige Pakete für 32- und 64-Bit-Systeme stellen die Entwickler unter [3] bereit. Zur Inbetriebnahme müssen Nutzer lediglich das entsprechende Archiv herunterladen, entpacken und das Programm »ipfs« in den Standardsuchpfad einbinden. Alternativ wartet unter [20] ein Docker-Container mit einem vorkonfigurierten IPFS.
Bevor ein Anwender mit »ipfs« auf das verteilte Dateisystem zugreift, muss er mit »ipfs init« ein lokales Repository für IPFS einrichten. Dessen Daten landen gewöhnlich unter »~/.ipfs« . Bei der Initialisierung erzeugt »ipfs« zudem eine ID, die den Client eindeutig identifiziert. Anschließend lassen sich mit »ipfs« Dateien oder gleich ganze Verzeichnisse veröffentlichen (»ipfs add Datei.txt« ). Jede Datei und jedes Verzeichnis erhält dabei einen eindeutigen Hashwert, über den andere sie künftig ansprechen beziehungsweise herunterladen.
Der »ipfs« -Client lässt sich auch als Daemon starten. In diesem Fall verbindet er sich automatisch mit den nächstgelegenen IPFS-Clients beziehungsweise Peers und erhält die Verbindungen aufrecht. Der laufende Daemon bietet zugleich auf Port »8080« einen Webserver an. Über ihn rufen Anwender mit ihrem Browser ein Objekt aus dem IFPS-Netz ab. Dazu steuern sie nur die URL »https://localhost:8080/ABC« an, wobei »ABC« für den Hash des gewünschten Objekts steht.
Unter der Adresse »http://localhost:5001/webui« wartet zudem eine Webseite, die Informationen unter anderem über den eigenen Knoten und die gerade verbundenen Peers liefert (Abbildung 6). Über sie lädt der Anwender zudem schnell neue Dateien hoch beziehungsweise ruft diese ab. Mit Hilfe der Fuse-Technik mountet er das IFPS zudem wie ein normales Dateisystem. Auf diesem Weg ermöglichen die IPFS-Entwickler den Zugriff auf einzelne Objekte, ohne dass die User den »ifps« -Client brauchen. Dazu ruft der Anwender in seinem Browser die URL »https://ipfs.io/ipfs/ABC« auf, wobei »ABC« für den Hashwert des entsprechenden Objekts steht.
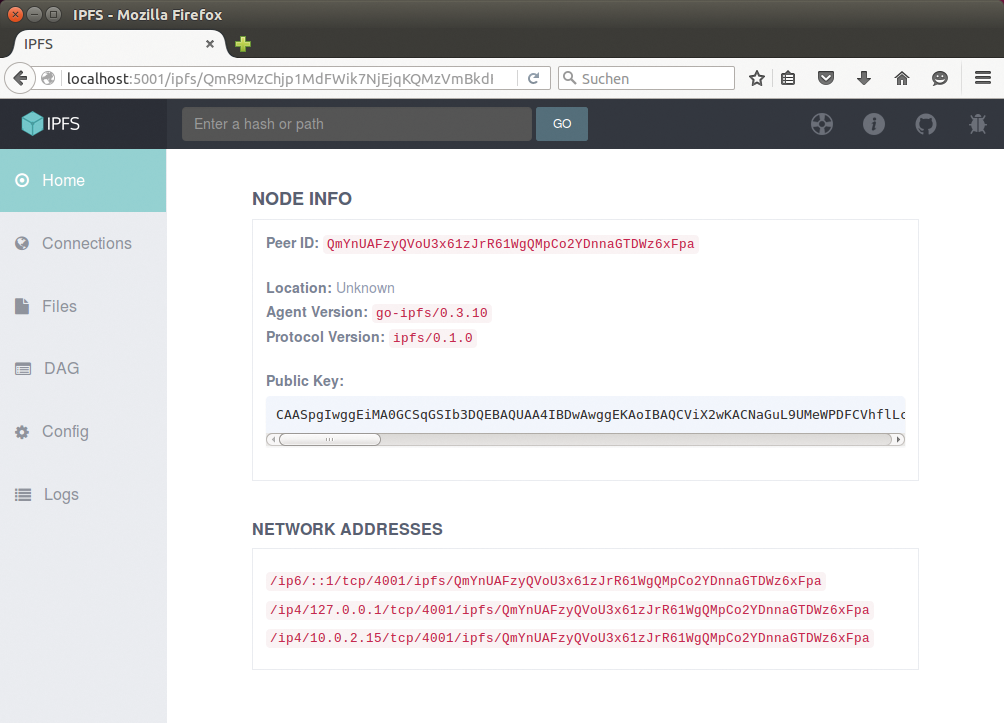
Abbildung 6: Die Weboberfläche des IPFS-Clients erlaubt unter anderem einen Einblick in die gerade aufgebauten Verbindungen. Zudem lassen sich hier Dateien hochladen.
IPFS bietet kein DNS-System, Anwender müssen Objekte derzeit folglich immer über die kryptischen Hashwerte ansprechen. Allerdings lassen sich auch normale DNS-Server einspannen. Die IPFS-URL landet dabei im TXT-Record, den wiederum das Kommandozeilentool »ipfs« abfragt – das genaue Verfahren beschreibt die Ausgabe von »ipfs dns –help« . Die Dokumentation beschränkt sich auf einige Tutorials und eine karge Kommandozeilenreferenz [21]. Die technischen Hintergründe von IPFS liefert ein Whitepaper unter [3], das sich allerdings noch im Entwurfsstadium befindet.
Tor
Das kurz nach der Jahrtausendwende entstandene Tor-Netzwerk [4] dient wesentlich dazu, die Identität eines Internetnutzers zu verschleiern, etwa in Ländern mit starker Internetüberwachung. Sein PC verbindet sich nicht direkt mit dem Webserver, sondern das Tor-Netzwerk leitet den Verkehr zuvor über mehrere andere Rechner im Internet. Dazu betreiben Freiwillige spezielle Server, die Tor-Nodes oder (Tor-)Relays. Erst der letzte Relay in der Kette, der Exit-Relay (oder Exit-Node), übergibt die Anfrage des Nutzers stellvertretend an den Webserver. Der Tor-Client und die Relays übertragen die Nachrichten mehrfach verschlüsselt. So kann niemand die Kommunikation abhören und zurückverfolgen (Abbildung 7). Folglich nutzen die User bestehende Dienste im Internet anonym.
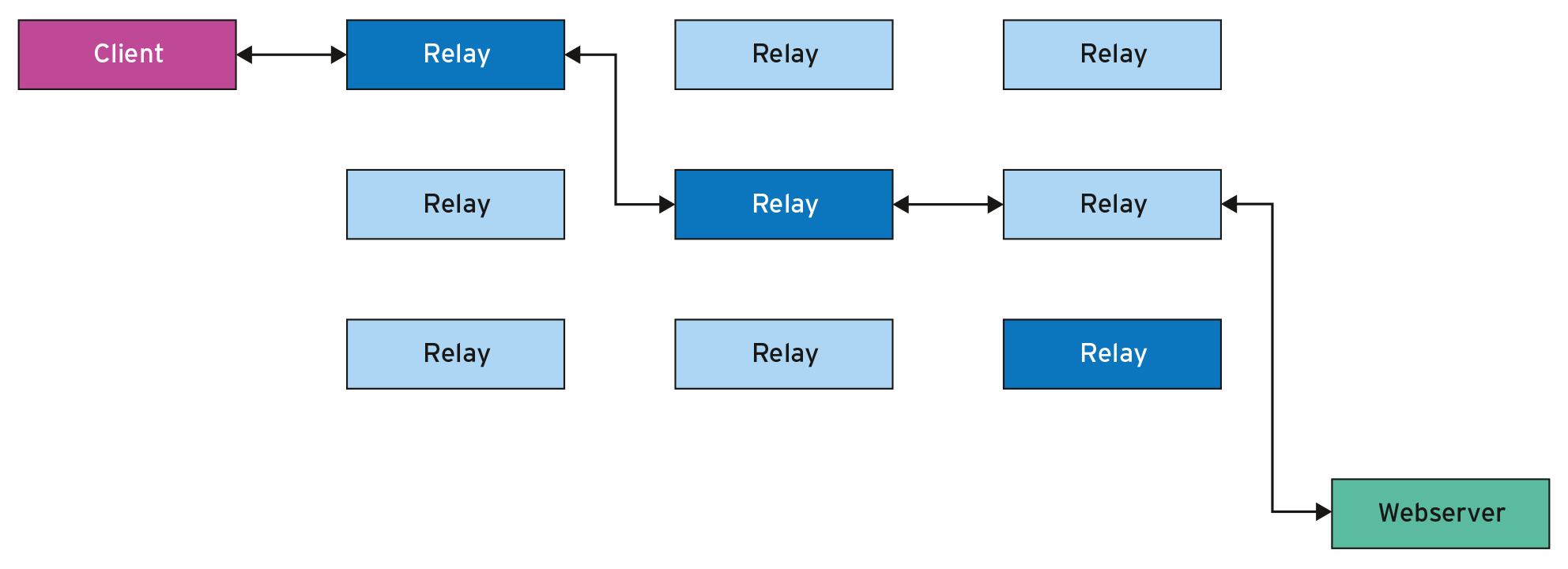
Abbildung 7: Bei Tor durchläuft eine Anfrage mindestens drei zufällig ausgewählte Knoten und ver- und entschlüsselt die Pakete dabei.
Ein weniger bekanntes Feature sind die Hidden Services: Sie erlauben es jedermann, Webseiten und Dienste anonym im Tor-Netz anzubieten. Nutzer dieser Dienste erfahren weder ihre IP-Adresse noch den wahren Standort.
Um einen Dienst über das Tor-Netzwerk zu erreichen, muss dieser zunächst in dem Netzwerk seine Existenz ankündigen. Das erfolgt nach einem recht komplizierten Muster: Zunächst erzeugt der Tor-Client ein Schlüsselpaar, das den Dienst ab sofort identifiziert. Anschließend verbindet er sich mit einigen zufällig ausgewählten Relays, den so genannten Introduction Points. Den öffentlichen Schlüssel hinterlegt der Client zusammen mit Informationen über die Introduction Points in einer verteilten Hashtabelle, die als eine Art Verzeichnisdienst fungiert. Andere Tor-Clients erreichen den Dienst anschließend unter der URL »dienst.onion« , wobei »dienst« für einen 16 Zeichen langen Namen steht, den ein Hashverfahren aus dem öffentlichen Schlüssel des Dienstes bildet. Der Vorteil: Dank der automatisch erzeugten Domainnamen prüfen alle Beteiligten jederzeit, ob sie tatsächlich mit dem korrekten Dienst sprechen.
Möchte ein Client einen Hidden Service nutzen, verbindet er sich mit einem zufällig ausgewählten Tor-Relay und fordert ihn auf, als so genannter Rendezvous Point zu dienen (Abbildung 8). Anschließend bittet der Client einen der Introduction Points, eine Nachricht an den Dienst zu senden. Diese Nachricht enthält unter anderem einen Hinweis auf den Rendezvous Point. Der Tor-Client auf dem Rechner mit dem Dienst verbindet sich mit dem Rendezvous Point, über den dann wiederum beide Parteien miteinander kommunizieren. Das ganze Verfahren sorgt zwar für Anonymität, die zahlreichen involvierten Rechner bremsen jedoch die Geschwindigkeit.
Abbildung 8: Das Tor-Projekt kündigt die Hidden Services über ein komplexes Verfahren mit mehreren Beteiligten im Tor-Netzwerk an.
Wer einen Hidden Service anbieten möchte, muss zunächst einen Dienst einrichten. Das kann ein beliebiger Internetdienst sein, etwa ein Apache-Webserver. Des Weiteren muss er den Tor-Client konfigurieren und starten. Zum Redaktionsschluss lag der Client in der Version 0.2.7.6 vor. Auf ihrer Homepage bieten die Tor-Entwickler in erster Linie den Tor-Browser an, der mit einem vorkonfigurierten Tor-Client kommt.
Der Client selbst verbirgt sich etwas hinter dem Link »View All Downloads« . Er steckt allerdings auch in den Repositories aller größeren Distributionen und unterliegt einer BSD-Lizenz [22]. Der in C programmierte Client muss in der Lage sein, sich mindestens mit den Ports »80« und »443« zu verbinden.
Tor selbst startet als Daemon »tor« , den Anwendungen wiederum als Proxy an Port »9050« nutzen. Der Einsatz als Relay erfordert zudem eine kleine Änderung der Konfigurationsdatei »torrc« , bei Ubuntu liegt sie zum Beispiel im Verzeichnis »/etc/tor« .
Um einen Dienst im Tor-Netz zu veröffentlichen, bearbeitet der Tor-Benutzer nach dem Einrichten des Clients die Konfigurationsdatei »torrc« . Er ergänzt sie im Abschnitt für die Hidden Services um zwei Zeilen:
HiddenServiceDir /var/tor/hiddenservice/ HiddenServicePort 80 127.0.0.1:8080
Im Verzeichnis hinter »HiddenServiceDir« legt Tor dann einige Daten über den versteckten Dienst ab. Dazu gehört unter anderem eine Datei, welche die ».onion« -URL des Service verrät.
Hinter »HiddenServicePort« steht außerdem ein Port, den die Nutzer des Hidden Service verwenden, den Webserver im Beispiel erreichen sie über Port »80« . Anschließend folgt die IP-Adresse nebst Port, an die der Tor-Client später alle Anfragen weiterleitet. Im obigen Beispiel läuft der Webserver unter »127.0.0.1:8080« und leitet nach einem Neustart des Tor-Clients automatisch alle weiteren notwendigen Schritte ein.
Das Tor-Netzwerk verwendet allerdings ausschließlich TCP-Verbindungen. Auch eine automatische Ende-zu-Ende-Verschlüsselung fehlt. Gibt der Browser unablässig Informationen über sich und seinen Standort preis, erfährt dies nach wie vor der Webserver am anderen Ende der Kette. Plaudert umgekehrt der als Hidden Service laufende Webserver zahlreiche Daten aus, erfährt auch ein Nutzer möglicherweise den Standort.
Zeronet
Gerade mal etwas über ein Jahr alt ist das Zeronet (Abbildung 9, [5]), das primär als Plattform für Webseiten herhält. Die Zeronet-Clients kommunizieren verschlüsselt über das Bittorrent-Netzwerk miteinander. Daraus wiederum folgt, dass die IP-Adressen der Nutzer weiterhin sichtbar bleiben. Die Zeronet-Entwickler empfehlen daher, den Verkehr noch einmal über das Tor-Netzwerk zu leiten. Der Zeronet-Client unterstützt Tor von Haus aus, einschließlich der ».onion« -Adressen und Hidden Services.
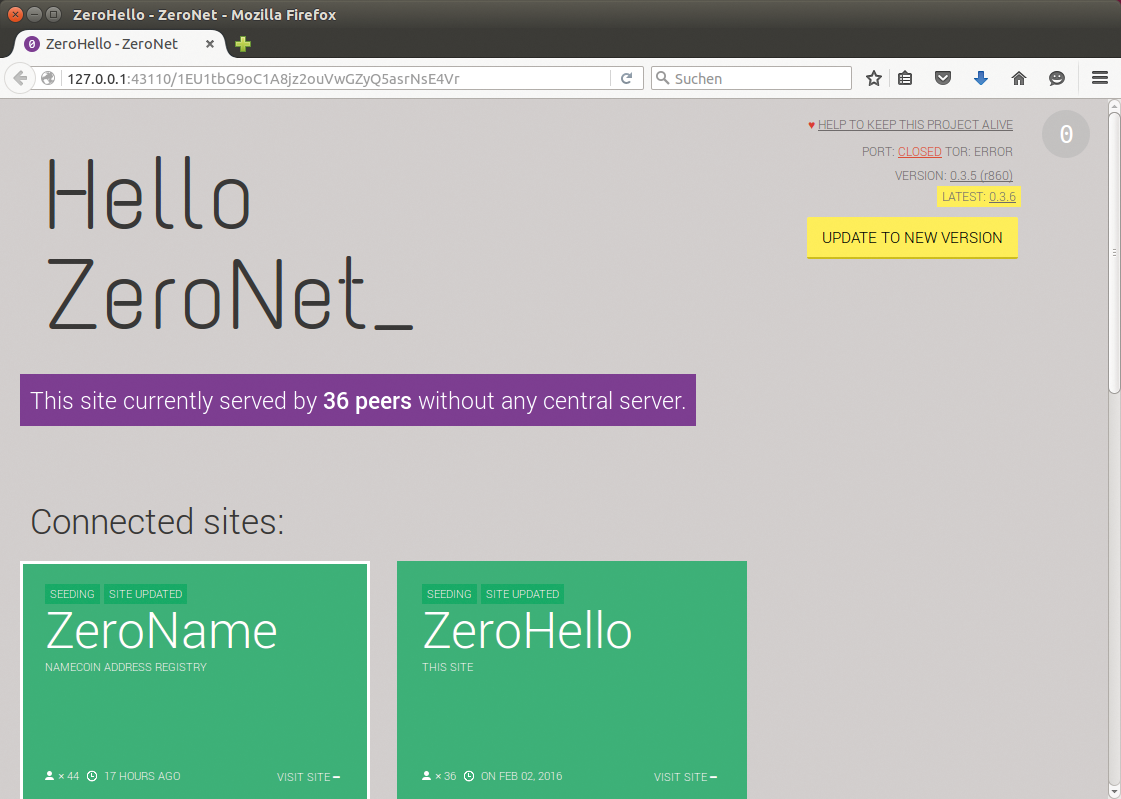
Abbildung 9: Die Weboberfläche von Zeronet sieht zwar recht karg aus, bietet aber bereits Links zu einigen wichtigen Seiten im Zeronet-Netzwerk.
Jede Website erhält eine eindeutige ID, über die andere Zeronet-Nutzer sie abrufen. Für die veröffentlichten Websites lassen sich Domains mit der Endung ».bit« einrichten. Zeronet verwendet dabei nicht das klassische Domain Name System, sondern eine auf Namecoin [23] basierende Alternative. Ähnlich wie bei der Kryptowährung Bitcoin landen dabei die Namen in einer verteilten Blockchain (Abbildung 10). Die Zeronet-Entwickler versprechen, dass die Clients Änderungen an einer Webseite in Echtzeit aktualisieren, Nutzer sehen folglich keine veralteten Inhalte.
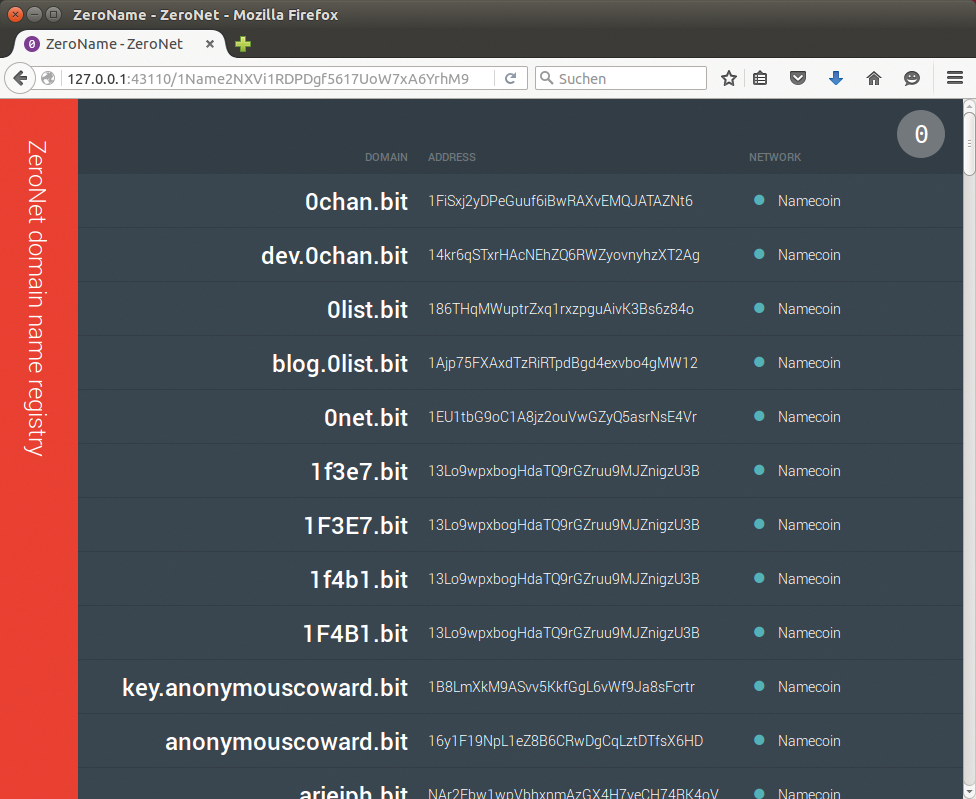
Abbildung 10: Die Adressen im Zeronet stammen aus einer Blockchain.
Der Zeronet-Client ist in Python geschrieben und untersteht der GPLv2. Der Quellcode liegt auf Github [24]. Zum Redaktionsschluss meldete sich der Client in Version 0.3.5. Diese setzte Python 2.7 sowie die Python-Module Msgpack, Greenlet und Gevent voraus. Alle Komponenten bieten die größeren Distributionen in ihren Repositories an.
Zur Inbetriebnahme laden Anwender lediglich die aktuelle Zeronet-Version von Github herunter und rufen den Befehl »python zeronet.py« auf.
Der Zeronet-Client startet als Dienst, der sich automatisch die passenden Ports per UPnP öffnet. Zudem stellt er unter der URL »http://localhost:43110« eine Weboberfläche bereit. Für Admins bieten die Zeronet-Entwickler ein Vagrant-Image und einen Docker-Container mit jeweils vorinstalliertem Client an.
Wer eine neue Webseite publizieren möchte, muss diese zunächst bei einem deaktivierten Client über das Kommando »python zeronet.py siteCreate« anmelden. Der Client generiert dabei ein Schlüsselpaar und eine lange und kryptische Site-Adresse. Die Webseite erreichen User über die URL »http://localhost:43110/abcdef« , wobei »abcdef« für die Site-Adresse steht.
Die eigentliche Webseite lagert im Unterverzeichnis »data/abcdef« . Dort passt der Betreiber sie nach Herzenslust an, muss sie aber noch via »python zeronet.py siteSign xyz« signieren und per »python zeronet.py sitePublish xyz« publizieren. Dabei steht »xyz« für den privaten Schlüssel, den der Client beim Anmelden der Seite erzeugt hat.
Wie Nutzer eine einfacher lesbare ».bit« -Domain registrieren, verrät die karge, aber immerhin vollständige Onlinedokumentation [25]. Zeronet unterstützt derzeit keine Skriptsprachen wie PHP oder Ruby. Wer dynamische Webseiten anbieten möchte, muss daher auf ein von Zeronet angebotenes API namens Zeroframe zurückgreifen. Ansprechen lässt sich das nur per Javascript oder Coffeescript. Daten speichert eine in Zeroframe eingebaute Datenbank.
Fazit
Über alle vorgestellten P2P-Netze können Anwender Inhalte auch anonym veröffentlichen. Jedes Projekt verfolgt dabei seinen eigenen Ansatz. Gemein ist ihnen lediglich, dass sie verschlüsselt über das Internet kommunizieren und der Verkehr teils über mehrere private Rechner läuft. Dies wiederum hat zur Folge, dass sich die Ladezeiten und Latenzen bei allen Netzen spürbar in die Länge ziehen. Mehrere Sekunden für den Abruf einer einfachen statischen Seite sind keine Seltenheit. Schnell sind vor allem Netze mit vielen Teilnehmern, was bislang nur auf Tor und I2P zutrifft. Dort ist der User jedoch selbst für die Dienste verantwortlich. Fallen sie aus, ist auch seine Webseite nicht mehr erreichbar.
Die anderen P2P-Netze wiederum schränken den User ein, indem sie keine dynamischen Websites erlauben. Aufgrund dieser Nachteile kann zum aktuellen Zeitpunkt keines der P2P-Netze eine ernsthafte Konkurrenz zum herkömmlichen Internet darstellen.
Tabelle 1
P2P-Netze im Überblick
|
P2P-Netz |
Freenet |
I2P |
IPFS |
Tor Hidden Services |
Zeronet |
|---|---|---|---|---|---|
|
Homepage |
|||||
|
Lizenz des Clients |
GNU GPL und Apache License |
Public Domain |
MIT License |
BSD-Lizenz |
GPLv2 |
|
Version |
0.7.5 |
0.9.24 |
0.4.0 |
0.2.7.6 |
0.3.5 |
|
Programmiersprache |
Java |
Java |
Go |
C |
Python |
|
Verbindung nur mit manuell ausgewählten Clients |
ja |
nein |
nein |
nein |
nein |
|
Client läuft als Daemon |
ja |
ja |
auf Wunsch |
ja |
ja |
|
Benötigt Client-Rootrechte |
nein |
nein |
nein |
nein |
nein |
|
Lässt sich Bandbreite begrenzen |
ja |
ja |
nein |
ja |
nein |
|
Bedienung |
Weboberfläche |
Weboberfläche |
Kommandozeile |
Kommandozeile |
Weboberfläche |
|
Plugins |
ja |
ja |
nein |
nein |
nein |
|
Services |
|||||
|
Dateien |
ja |
ja, mit entsprechender Software |
ja |
ja, mit entsprechender Software |
ja |
|
Websites |
ja |
ja, mit entsprechender Software |
ja |
ja, mit entsprechender Software |
ja |
|
Dynamische Websites |
nein |
ja, mit entsprechender Software |
nein |
ja, mit entsprechender Software |
ja, eingeschränkt |
|
|
per Plugin |
ja, mit entsprechender Software |
nein |
ja, mit entsprechender Software |
nein |
|
Blog |
per Plugin |
ja, mit entsprechender Software |
nein |
ja, mit entsprechender Software |
nein |
|
Chat |
per Plugin |
ja, mit entsprechender Software |
nein |
ja, mit entsprechender Software |
nein |
|
Nameservice |
eigenes, über spezielle Keys |
Adressbücher |
nein |
Distributed Hash-Table mit automatisch erzeugten URLs |
Namecoin-Verfahren |
|
Suche im Netz möglich |
ja, experimentell |
nein |
nein |
nein |
nein |
Infos
- Freenet: https://freenetproject.org
- I2P: https://geti2p.net
- IPFS: https://ipfs.io
- Tor: https://www.torproject.org
- Zeronet: http://zeronet.io
- Freenet Java Web Start Installer: https://freenetproject.org/assets/jnlp/freenet.jnlp
- Freenet Installer: https://freenetproject.org/assets/jnlp/freenet_installer.jar
- Freenet-Quellcode: https://github.com/freenet/fred
- Freenet-Wiki: https://wiki.freenetproject.org
- Freenet-Doku: https://freenetproject.org/documentation.html#documentation-intro
- “The newcomer’s guide to anonymous communication on Freenet”: http://freesocial.draketo.de
- I2PCon: https://geti2p.net/en/about/i2pcon/2015
- Congestion Control: https://tools.ietf.org/html/rfc896
- Eepsite: http://eepsite.com
- Tahoe-LAFS: https://tahoe-lafs.org
- I2P-Quellcode: https://github.com/i2p/i2p.i2p
- Von I2P verwendete Ports: https://geti2p.net/en/docs/ports
- I2P-Forumadresse: http://forum.i2p
- IPFS-Quellcode: https://github.com/ipfs/go-ipfs
- IPFS Docker Container: https://hub.docker.com/r/jbenet/go-ipfs/
- IPFS-Dokumentation: http://ipfs.io/docs/
- Tor Lizenz: https://gitweb.torproject.org/tor.git/plain/LICENSE
- Namecoin: https://de.wikipedia.org/wiki/Namecoin
- Zeronet-Quellcode: https://github.com/HelloZeroNet/ZeroNet
- Zeronet-Dokumentation: https://zeronet.readthedocs.org/en/latest/
- Gnunet: https://gnunet.org
- Osiris: http://www.osiris-sps.org
- Netsukuku: http://netsukuku.freaknet.org
- Retroshare: http://retroshare.sourceforge.net






