
© Mikhail Kokhanchikov, 123RF
Die vier Testkandidaten helfen Webentwicklern dabei, HTML-Dokumente auf Standardkonformität hin zu prüfen. Die Saubermacher können aber nicht nur den Code validieren, sondern auch erlaubte, aber unerwünschte Elemente aufspüren und entfernen.
Früher war das Leben viel einfacher – Kompendien wie Self-HTML [1] deckten auf einer überschaubaren Seitenzahl so ziemlich alles ab, was das Webprogrammiererherz begehrte. Heute ist das Netz interaktiver und vielseitiger, aber auch komplizierter und gefährlicher. Das “eine HTML” gibt es schon lange nicht mehr, stattdessen existiert ein Vielzahl von Versionen [2]. HTML 4.01, XHTML und das aktuelle HTML 5 sind nur einige davon; hinzu kommen Varianten wie Strict oder Transitional, garniert durch CSS-Dateien in mehreren Spielarten.
Kurz vor dem 20. Geburtstag von HTML ist das Durcheinander dank neuer Versionen, Varianten und Elemente perfekt. Valide und sichere Dokumente zu erzeugen ist inzwischen alles andere als einfach. Contentmanagement-Systeme und Wysiwyg-HTML-Editoren helfen, dennoch bringt der prüfende Blick auf den Code meist Überflüssiges und echte Fehler zum Vorschein. Betreiber von Blogs und Foren stehen vor einem weiteren Problem: Oft sollen bestimmte Teile gar nicht erst im Quelltext auftauchen, beispielsweise um Bilder und interaktive Inhalte zu filtern.
Vier Tools helfen dabei, den eigenen Code zu prüfen und zu bereinigen. HTML Tidy [3] und der Total Validator [4] treten im Test als Vertreter der klassischen Validierungstools an. Der HTML Purifier [5] und das darauf aufbauende HTM Lawed [6] sind PHP-basierte Bibliotheken, die HTML-Code besonders für Foren und Blogs bereinigen.
HTML Tidy
Den Auftakt macht eines der bekanntesten Tools, das in vielen Kreisen neben dem offiziellen W3C-Validator [7] als Referenz gilt. Das unter der MIT-Lizenz veröffentlichte und mittlerweile als Sourceforge-Projekt entwickelte Programm ist als Stand-alone-Variante sowie als Bibliothek im Angebot. Letztere steht Software-Entwicklern bei, die ihre eigenen Anwendungen um eine HTML-Validierungsfunktion erweitern oder dem Original eine grafische Oberfläche spendieren möchten. HTML Tidy selbst arbeitet auf der Kommandozeile und bietet dazu sehr strukturierte und übersichtliche Aufrufoptionen.
Der Klassiker unter den Validatoren unterstützt alle gängigen HTML-Varianten bis einschließlich Version 4.01, XHTML und mit Einschränkungen auch XML. Das noch recht neue HTML 5 findet keine Beachtung (Abbildung 1), was nicht weiter verwundert, stammt doch die letzte Relase vom März 2009.
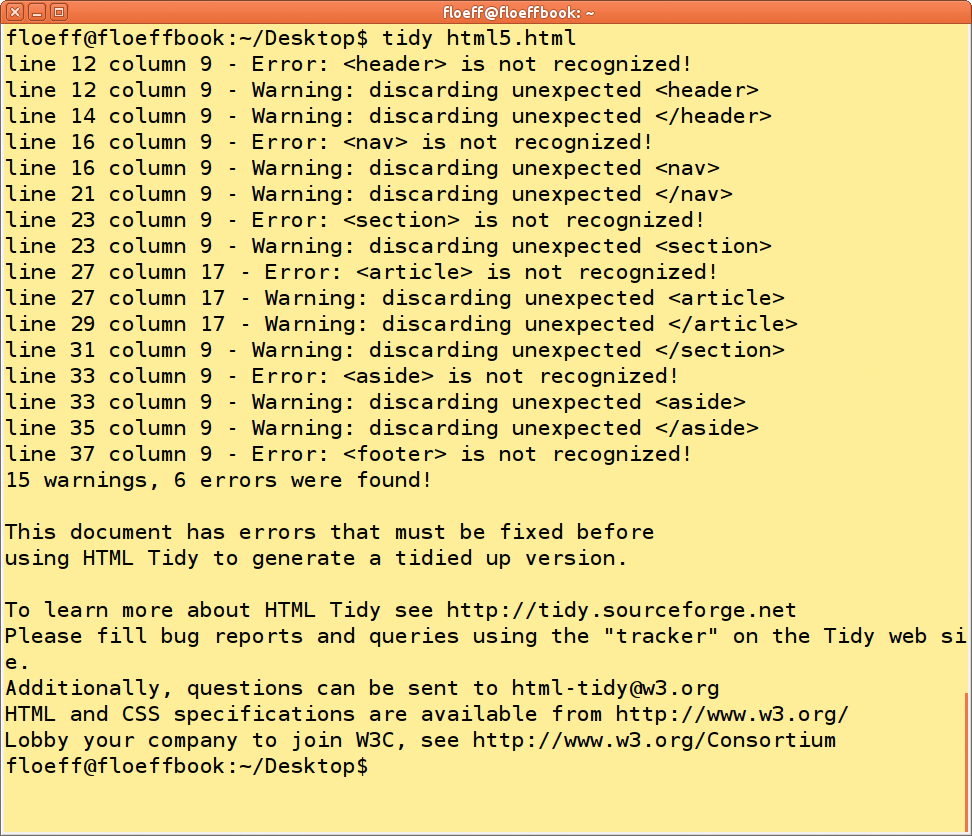
Abbildung 1: Das noch recht neue Format HTML 5 versteht HTML Tidy in der derzeitigen Programmversion noch nicht. Die neuen Tags erkennt es nicht und wirft entsprechend mit Fehlermeldungen um sich.
HTML Tidy ist Bestandteil vieler Distributionen; Anwender installieren das entsprechende Paket aus den üblichen Repositories. Es punktet mit zahlreichen Funktionen, korrigiert mangelhafte Elemente nach Möglichkeit beziehungsweise ergänzt Fehlendes und gibt kurze Erläuterungen zu den kritisierten Codestellen. Eine farbliche Hervorhebung des Quelltextes findet auf der Shell nicht statt, aber die Ausgabe von Zeile und Spalte hilft bei der Orientierung.
Das Tool ist grundsätzlich auf lokale Dateien angewiesen und akzeptiert keine URLs als Quellen beim Aufruf. Es bietet viele Optionen, um den Quelltext zu optimieren und zu formatieren (»pretty print« , Abbildung 2). So rückt der Parameter »-i« automatisch ein, »-w« fügt Zeilenumbrüche hinzu und »-u« setzt alle Tags konsequent in Großbuchstaben. Auch beliebte Flüchtigkeitsfehler, etwa ungültige Quotezeichen (»-b« ), Backslashes (»–fix-backslash yes« ) und Sonderzeichen in URLs (»–fix-uri yes« ), korrigiert das Tool bis zu einem gewissen Grad.

Abbildung 2: HTML Tidy unterstützt Webentwickler bei der Formatierung des Quellcodes. Im Gegensatz zur Originaldatei (links) präsentiert sich die bearbeitete Datei (rechts) deutlich besser lesbar.
Darüber hinaus konvertiert es Dokumente in gängige Zeichensätze (zum Beispiel mit »-latin0« ) und entfernt proprietäre Elemente (»–drop-proprietary-attributes« ) sowie Kommentare (»–hide-comments yes« ). Auf Wunsch überführt HTML Tidy bestimmte HTML-Elemente in CSS-Tags (»-c« ).
Augen auf!
HTML Tidy untersucht mit »-access« die Barrierefreiheit der Dateien und fordert etwa »ALT« -Tags für Bilder ein. Grafiken dürfen zudem nicht nur aus Platzhaltern, Namen oder Größenangabe bestehen. Ähnliches gilt für eingebundene Applets oder Audiodateien. Das Tool beschwert sich auch über einen unzureichenden Farbkontrast zwischen Vorder- und Hintergrund und fehlende Noscript-Varianten in den Script-Sektionen. HTML Tidy hält Entwickler dazu an, auf indirekte Formatierung zu setzen (zum Beispiel Header-Auszeichnung statt großer Schriftart) und die Sprache des Dokuments zu kennzeichnen. Alle Kriterien samt Erklärungen und Testdateien finden Interessierte unter [8].
Fehlermeldungen schreibt das Tool mit »-f« und korrigierte Dokumente mit »-o« in separate Dateien. Alternativ landen sie direkt auf der Konsole. Einziger Wermutstropfen ist, dass die Anwender HTML Tidy nur eingeschränkt um eigene Tags erweitern dürfen, und dies auch nur für den Body der Dokumente. Den Header der Dateien fasst das Tool nicht an.
HTML-Dateien konvertiert es mit dem Parameter »-asxhtml« nach XHTML; in die umgekehrte Richtung führt die Option »-ashtml« . Anwender, die nicht jedes Mal einen Rattenschwanz von Aufrufoptionen übergeben möchten, speichern ihre Einstellungen in einer frei wählbaren Konfigurationsdatei. In dieser können etwa Einträge wie die folgenden stehen:
fix-backslash: yes fix-uri: yes hide-comments: yes accessibility-check: 0 show-warnings: yes
Die Webseite [9] listet alle Möglichkeiten mit Beispielen und den Standardwerten auf. Die Einrichtungsdatei übergeben Anwender anschließend über »-config« .
Total Validator Basic
In einer ähnlichen Liga spielt der zweite Testkandidat. Genau wie HTML Tidy spricht der Total Validator zwar auch nur Englisch, bietet dafür aber ein komfortables GUI. Dabei handelt es sich um eine betriebssystemunabhängige Java-Applikation, die unter einer proprietären Lizenz steht. Neben der getesteten kostenlosen Basic-Version gibt es eine kostenpflichtige Pro-Version, die mit 30 Euro zu Buche schlägt. Sie bietet einige zusätzliche Funktionen, etwa CSS-Validierung nach W3C-Standard, verschiedene Konfigurationsprofile, den Ausschluss einzelner Abschnitte einer Seite, die Überprüfung von 404-Fehlerseiten, ein Wörterbuch-Feature und den Test passwortgeschützter Seiten.
Zusätzlich gibt es ein unter der Mozilla Public License veröffentlichtes Firefox-Addon [10], das Webseiten direkt aus dem Browser heraus prüft. Das klappt mit lokalen Dateien und mit URLs, funktionierte im Test aber nicht ganz fehlerfrei. Beim Browserstart verschwand auf einmal die Extension, nur ein Profil-Reset und die anschließende Neuinstallation behoben das Problem. Der Bug tauchte auf einem zweiten Testgerät jedoch nicht auf, daher ist möglicherweise ein defektes Profil des Nutzers für diese Panne verantwortlich.
Auch ohne fertig gepackte Pakete geht die Installation auf gängigen Linux-Distributionen leicht von der Hand. Anwender laden die Java-Anwendung von [4] herunter, entpacken das Archiv und starten das Programm über den Befehl »java -jar totalvalidator.jar« . Alternativ übernimmt das die Firefox-Erweiterung, die vom Anwender vorher den korrekten Pfad zur Java-Datei wissen möchte (siehe Abbildung 3).
Abbildung 3: Das Firefox-Addon übernimmt auf Wunsch den Start der eigentlichen Anwendung. Dazu tragen Anwender den Pfad zum Binary ins Feld »Tool« ein.
Egal für welchen Weg sich der Entwickler entscheidet, in beiden Fällen erfolgt die Ausgabe der eigentlichen Validierung im Browser. Er zeigt eine Zusammenfassung der Kriterien und Testergebnisse an sowie zusätzlich eine Seite mit detaillierteren Informationen. Verschiedene Profile kennt die kostenlose Variante des Tools nicht. Anwender können lediglich die aktuelle Konfiguration im Einstellungsdialog speichern.
Kein kalter Kaffee
Am Funktionsumfang gibt es nichts auszusetzen. Der Total Validator unterstützt HTML in den Versionen 2.0 und 3.2, zudem die Versionen 4.0 und 4.01 – letztere jeweils in den Varianten Frameset, Transitional und Strict. Auch HTML 5 und XHTML sind im Angebot sowie eine Vielzahl weiterer Spielarten inklusive automatischer Formaterkennung, weshalb sich die fehlende Möglichkeit, eigene Tags zu ergänzen, verschmerzen lässt. Auch der zweite Testkandidat legt Wert auf Barrierefreiheit und richtet sich dabei wahlweise nach den “W3C Web Content Accessibility Guidelines” [11] oder den US-Regelungen nach Section 508 des Rehabilitation Act [12].
Total Validator konzentriert sich hauptsächlich darauf, Fehler zu finden, sie automatisch zu korrigieren ist nicht vorgesehen. Den Quelltext rückt das Tool zur besseren Lesbarkeit automatisch ein. Es nummeriert auch die Zeilen und hebt die Fehlerposition farbig hervor. Zudem unterscheidet es zwischen echten Fehlern und Warnungen und versieht die Ausgabe mit kurzen Erläuterungen (siehe Abbildung 4). Die Navigation zwischen den einzelnen Meldungen geschieht mit Hilfe von Links.
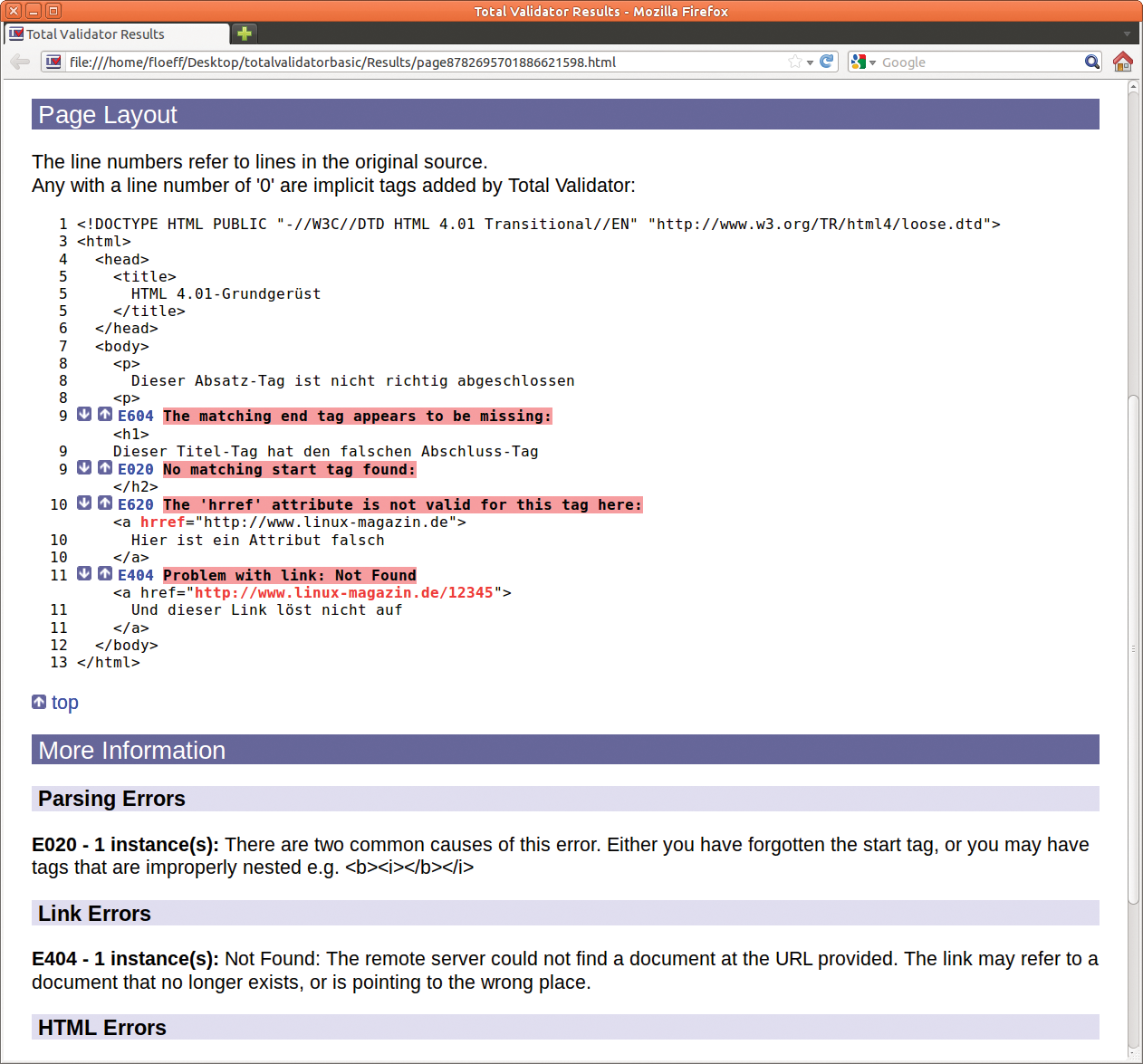
Abbildung 4: Der Total Validator erkennt auch ungültige Links. Das Tool hebt Fehler deutlich hervor und versieht sie sogar mit Erklärungen für den Webentwickler.
Gut gefallen hat den Testern zudem der integrierte Linkchecker, der auch in der kostenfreien Basic-Version des Programms zur Verfügung steht. Das Feature durchforstet die HTML-Seiten nach veralteten oder nicht erreichbaren Verknüpfungen und erspart dem Programmierer diese doch recht mühsame Klickaufgabe. Eine Rechtschreibprüfung für Deutsch, Englisch, Französisch, Italienisch und Spanisch rundet das Bild ab.
HTML Purifier
Die nächsten beiden Kandidaten sind PHP-Bibliotheken. Der englischsprachige HTML Purifier ist unter der LGPL lizenziert und beherrscht die Standards XHTML 1.0 und HTML 4.01, jeweils in den Varianten Transitional und Strict, sowie XHTML 1.1. Die Library ist primär zum Einbinden in eigene PHP-Skripte gedacht. So würde Listing 1 beispielsweise das Dokument automatisch mit Paragraphen versehen. Für erste Tests enthält die Webseite ein Beispielformular, in dem Anwender einige Optionen direkt per Copy&Paste ausprobieren können (siehe Abbildung 5).
Listing 1
HTML Purifier im Einsatz
01 <?php
02 require_once('HTMLPurifier.standalone.php');
03 $input='Dieser Text ist ohne p-Tags erstellt
04
05 HTML Purifier baut diese aber ein,
06 damit das Dokument gut aussieht.
07
08 Und hier folgt noch ein Absatz.
09 ';
10 $config=HTMLPurifier_Config::createDefault();
11 $config->set('AutoFormat.AutoParagraph', true);
12 $purifier=new HTMLPurifier($config);
13 $output=$purifier->purify($input);
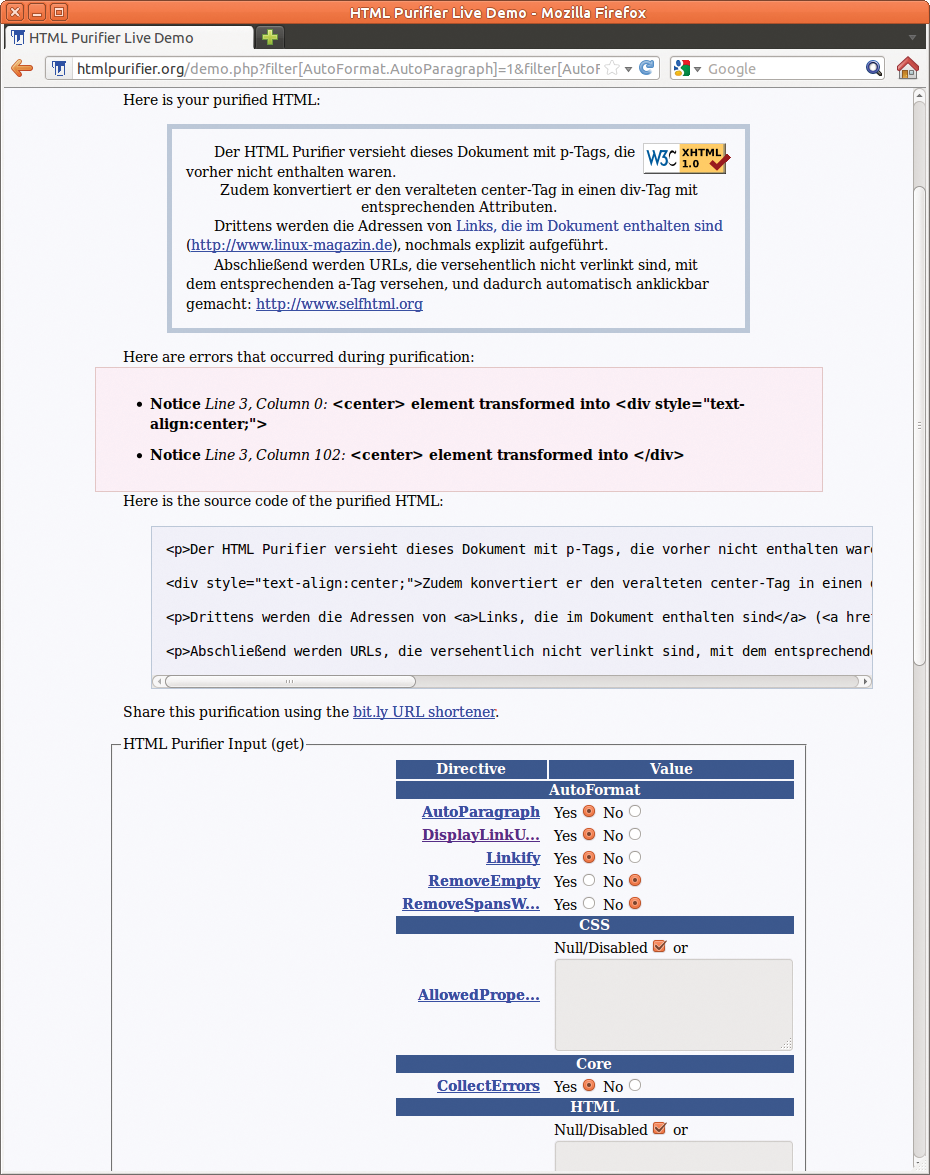
Abbildung 5: Vor dem Einsatz von HTML Purifier in eigenen Skripten können sich Webentwickler in der Online-Demo von dessen Fähigkeiten überzeugen.
Bei diesem Testkandidaten stehen genau wie beim folgenden die Blogs und Foren ganz oben auf der Liste der möglichen Einsatzgebiete. Die eigentliche Validierung des Quellcodes ist eher zweitrangig, das Erzeugen von sicherem und übersichtlichen Code steht im Vordergrund. Zwar entfernt auch dieses Tidy-Modul ungültige, alte oder im gewählten Dokumentstandard nicht mehr unterstützte Tags (»HTML.TidyLevel« ) und erläutert sie auf Wunsch samt genauer Positionsangabe (»Core.CollectErrors« ), die Funktion ist aber als experimentell gekennzeichnet und funktionierte beim Test mit eigenen PHP-Skripten nicht.
Barrierefreiheit ist ein Fremdwort für den HTML Purifier, und die Bibliothek verifiziert auch keine Header. Der Fokus liegt stattdessen auf dem Seiteninhalt, den sie um möglicherweise schadhafte Elemente zu bereinigen versucht, um potenzielle Sicherheitslücken zu schließen. Dazu gehören etwa »Object« , »Iframe« oder »Embed« .
Sag’s mit PHP
Die Dokumentation auf der Webseite des Projekts empfiehlt, keine anderen Zeichensätze als UTF-8 einzusetzen. Die recht ausführliche Anleitung enthält außerdem detaillierte Beschreibungen der einzelnen Konfigurationsdirektiven und erläutert, welche Sprachelemente HTML Purifier unterstützt. Webentwickler finden hier auch Tipps, wie sie trotz strenger Filterregeln Filme aus Videoportalen wie Youtube einbinden und wie der URL-Filter funktioniert. Es ist darüber hinaus möglich, die Bibliothek um eigene Elemente zu erweitern.
Anhand zahlreicher Konfigurationsdirektiven legen Anwender in einer Black- und Whitelist fest, was im Code erlaubt sein soll und was nicht. Auch den Inhalt einzelner Elemente dürfen sie festlegen. So geben sie beispielsweise grünes Licht für Attribute wie Class (»Attr.AllowedClasses« ) und Rel (»Attr.AllowedRel« ), für Frame-Targets (»Attr.AllowedFrameTargets« ) und Kommentare (»HTML.AllowedComments« ). Auch die verlinkten Protokolle (»URI.AllowedSchemes« ), die Maximalgröße von Bildern (»HTML.MaxImgLength« ) und ein automatisches Alt-Tag dürfen sie vorgeben.
Für einen einfachen Einstieg empfiehlt es sich, alle externen eingebundenen Objekte (»URI.DisableExternalResources« ) oder Links zu externen Seiten zu deaktivieren (»URI.DisableExternal« ). Die Dokumentation liefert etliche Beispiele mit, wie Anwender detaillierte Listen erstellen. Der folgende Konfigurationseintrag erlaubt beispielsweise nur die Elemente »h1« , »h2« , »p« und »br« :
$config->set('HTML.Allowed', 'h1,h2,p,br');
Auch Einstellungen zum Escapen sind vorhanden (zum Beispiel »Core.EscapeNonASCIICharacters« ). Die Anweisung »AutoFormat.RemoveEmpty« gliedert automatisch und entfernt überflüssigen Code wie etwa »<a></a>« . Selbst eine Direktive, die Flash-Inhalten das Umschalten in den Vollbildmodus verbietet, ist vorhanden (»HTML.FlashAllowFullScreen« ). Gut gefallen im Test hat auch, dass HTML Purifier Funktionen zum Überprüfen von CSS-Elementen enthält. Das geht bis zur Definition erlaubter Schriftarten (»CSS.AllowedFonts« ). Insgesamt macht das Tool einen runden Eindruck und hält, was die gute Dokumentation verspricht.
HTM Lawed
Den vierten Kandidaten beschreiben seine Entwickler als Alternative zum HTML Purifier. Auch das LGPL-lizenzierte HTM Lawed ist eine PHP-Bibliothek, deren primäre Aufgabe darin besteht, Code für Blogs oder Foren zu optimieren. Neben der Korrektur ungültiger Elemente liegt der Schwerpunkt auf dem Herausfiltern unerwünschter Inhalte. Das Tool entfernt ebenfalls gezielt Designelemente und sichert Seiten gegen mögliche Sicherheitslücken ab.
Zusätzlich bringt die Library Funktionen mit, um den Quelltext zu optimieren (»Beautify and Compact« ) und Codeelemente einzurücken. Den Anwender unterstützt dabei ein rudimentäres Syntax Highlighting. Zur Validierung kompletter Seiten eignet sich das Tool indes nicht, da es lediglich den Body der Dokumente untersucht und der Header sowie Frameset-Definitionen außen vor bleiben. Auch weitergehende Erläuterungen für den Anwender und Positionsangaben von Fehlern sind nicht vorhanden. Barrierefreiheit beachtet HTM Lawed ebenfalls nicht. Die Bibliothek kennt HTML 4, XHTML und XML, nicht jedoch das neue HTML 5.
Listing 2 zeigt schrittweise, wie Webentwickler die PHP-Bibliothek einbinden. Das Beispiel nimmt den Text aus »$input« (also dem Link zur Mailadresse) und ersetzt im »href« -Tag das At-Zeichen durch »kringelchen« . So wird aus »<a href=”mailto:floeff@googlemail.com”>« also »<a href=”mailto:floeff%20kringelchen%20googlemail.com”>« . Das Ganze landet in der Variablen »$output« . Für Testläufe und um kurze Seiten händisch per Copy&Paste zu bearbeiten, enthält das Paket das einfache Webformular »htmLawedTest.php« (Abbildung 6). Per Mausklick und in einfachen Textfeldern definieren Anwender die Optionen für das Tool, nach einem Klick auf »Process« startet HTM Lawed seine Arbeit.
Listing 2
HTM-Lawed-Beispiel
01 <?php
02 include('htmLawed.php');
03 $input='<a href="mailto:floeff@googlemail.com">Dieser Text verlinkt auf eine Mailadresse</a>';
04 $config=array('anti_mail_spam'=>' kringelchen ');
05 $output=htmLawed($input,$config);
06 ?>
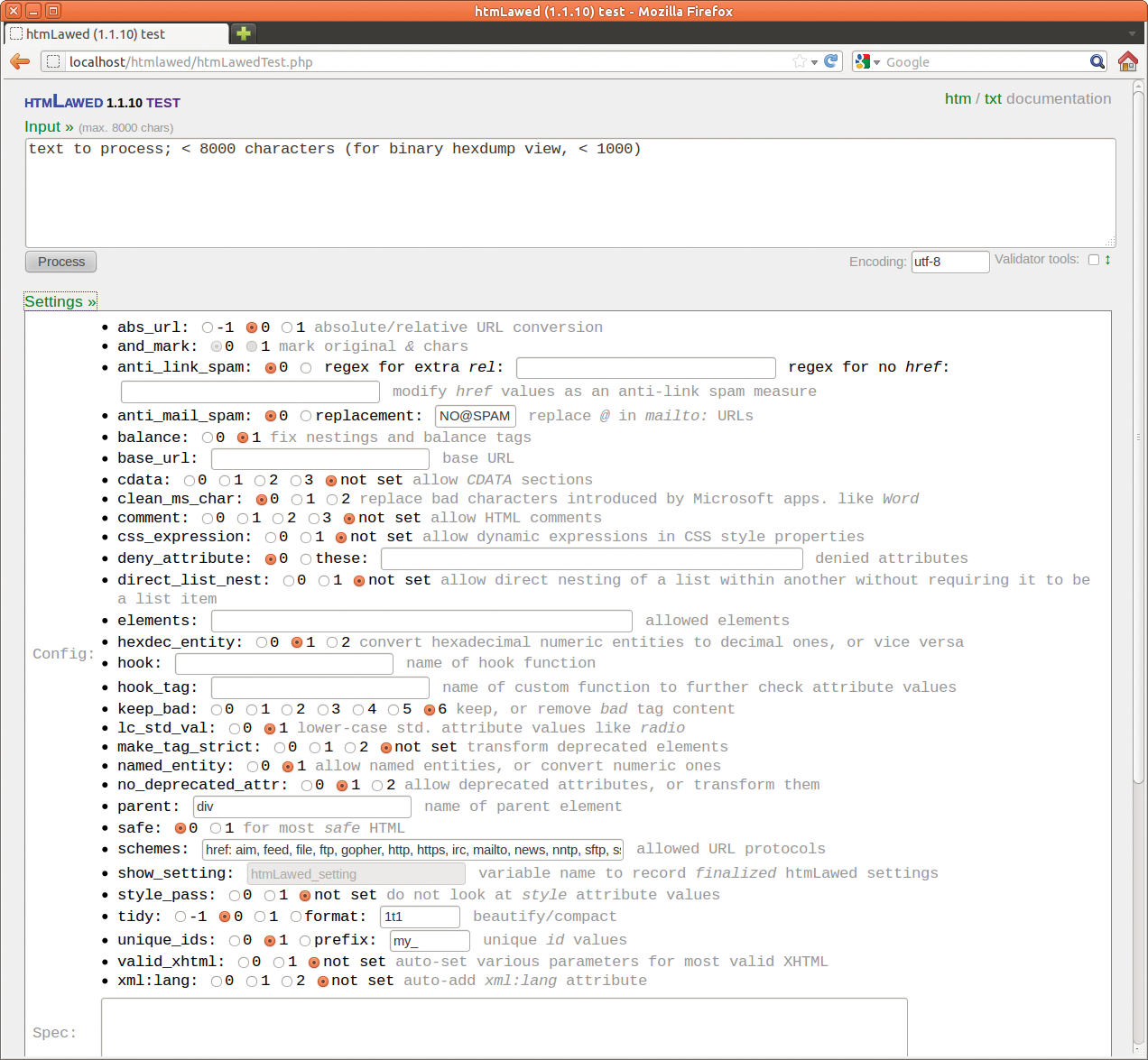
Abbildung 6: HTM Lawed bietet neben der PHP-Bibliothek auch eine einfache Browseranwendung. Hier setzen Anwender viele Optionen per Mausklick und geben ihren Quellcode per Copy&Paste ein.
Die Stärken liegen vor allem in der umfangreichen Dokumentation und in seiner Flexibilität. Anwender passen es ganz genau an eigene Bedürfnisse an und können zum Beispiel in Black- und Whitelists festlegen, welche Elemente erlaubt beziehungsweise verboten sind und welche Werte bestimmte Attribute annehmen dürfen, was vor allem beim Filtern von böswilligem Code praktisch ist.
En détail
Die Anweisung »deny_attribute=>’title’« verbietet beispielsweise lediglich das gleichnamige Attribut, die Direktive »deny_attribute=>’* -title’« hingegen lässt alle Attribute außer »title« zu. Elemente wie beispielsweise »onMouseOver« und »onClick« oder Links entfernt dagegen die Direktive »deny_attribute=>’on*,href’« . HTM Lawed korrigiert zudem häufige Fehler, etwa fehlende Abschluss-Tags oder nicht gesetzte Attribute. Alte Elemente, die nicht dem gewählten Standard entsprechen, korrigiert oder ersetzt die Bibliothek – wenn möglich. Gleiches gilt für überflüssige Kommentare.
Die Library kommt mit fertigen Konfigurationsdirektiven wie etwa »safe=>1« . Diese aktiviert eine sinnvolle Vorauswahl von Tags, die das Tool filtern soll, darunter Skripte und externe Objekte, sodass Webentwickler nicht zwingend eine eigene Liste erstellen müssen. Was vom Code übrig bleibt, kann HTM Lawed zudem ordentlich verpacken und achtet dabei auf entsprechendes Quoting und Escaping. Über »hexdec_entity=>2« konvertiert es dabei sogar HTML-Entities in Dezimal- oder Hexadezimalschreibweise.
Überzeugend sind auch die Antispam-Maßnahmen für Mailadressen. Neben der schon gezeigten Funktion aus Listing 2 bietet HTM Lawed an, mittels »”anti_link_spam” = array(‘`.`’, ”);« für einzelne oder alle Links das »nofollow« -Attribut zu setzen. Es sorgt dafür, dass Suchmaschinen den Verknüpfungen nicht folgen, und erschwert so genannten Link-Spammern damit das Leben. Darüber hinaus gibt es die Möglichkeit, absolute Links in relative umzuwandeln und umgekehrt. Anwender verbieten auch bestimmte Protokolle. So lässt »schemes=>’href: https’« beispielsweise nur die Verknüpfung zu SSL-Hosts zu.
Die Bibliothek konvertiert keine Zeichensätze und sieht auch keine Anordnung von Attributen oder deren genaue Syntaxprüfung vor. Ebenso wenig entfernt sie unnützen Code wie etwa nicht benötigte Tags. Die Entwickler begründen die Entscheidung in der Dokumentation damit, dass dies weder die Anzeige im Browser beeinflusse noch Sicherheitslücken öffne. In der Voreinstellung unterscheidet das Tool bereits zwischen sicheren und unsicheren Elementen.
Wer diesen sinnvoll gewählten Standard anpassen möchte, kann eigene Ergänzungen vornehmen, indem er nach dem Durchlauf eigene Routinen aufruft. Dazu kann HTM Lawed seine Ergebnisse an eine selbst geschriebene PHP-Funktion übergeben.
Hand in Hand
Ein Tool, sie zu knechten, sie alle zu finden – das suchen Webentwickler vergeblich. Keiner der Testkandidaten erfüllt alle Wünsche und meistert alle Aufgaben. HTML Tidy und der Total Validator konzentrieren sich ganz aufs Validieren, HTML Purifier und HTM Lawed auf Sicherheit und Sauberkeit im Code. Total Validator hat in der ersten Paarung leicht die Nase vorn, bietet das Tool doch HTML-5-Support und mehr Komfort mit seinem GUI. Punktabzug gibt es nur für ein paar fehlende Funktionen in der kostenlosen Basic-Variante – ein Problem, das Anwender mit 30 Euro aus der Welt schaffen.
Im direkten Vergleich zwischen HTML Purifier und HTM Lawed offenbaren sich unterschiedliche Features. Anwender sollten je nach Einsatzzweck entscheiden, welcher Bibliothek sie den Vorzug geben. Beide sind äußerst gut dokumentiert und zeigen in Beispielen auf ihren Webseiten, was sie können.
Sauberen Code schreiben bleibt auch mit Hilfsmitteln eine Herausforderung, und je komplexer das Quellmaterial ist, umso wahrscheinlicher übersieht ein Tidy-Tool etwas oder kennzeichnet ein eigentlich gültiges Konstrukt als falsch. Im Zweifel empfiehlt sich eine Kooperation mehrerer Werkzeuge, um bestmögliche Ergebnisse zu erzielen.
Infos
- Self-HTML: http://de.selfhtml.org
- Wikipedia-Übersicht zu HTML: http://de.wikipedia.org/wiki/HTML
- HTML Tidy: http://tidy.sourceforge.net
- Total Validator: http://www.totalvalidator.com
- HTML Purifier: http://htmlpurifier.org
- HTM Lawed: http://www.bioinformatics.org/phplabware/internal_utilities/htmLawed
- W3C-Validator: http://validator.w3.org
- HTML Tidy, Barrierefreiheit: http://www.aprompt.ca/Tidy/accessibilitychecks.html
- HTML-Tidy-Konfigurationsoptionen: http://tidy.sourceforge.net/docs/quickref.html
- Total Validator für Firefox: https://addons.mozilla.org/firefox/addon/total-validator
- Barrierefreiheits-Richtlinien nach WCAG: http://www.w3.org/WAI/intro/wcag#is
- Rehabilitation Act, Abschnitt 508: http://www.section508.gov





