
© A. Reinkober, Pixelio.de
Wer seinem interaktiven Perl-Tool einen ebenso schicken wie praktischen History-Mechanismus mit Editierfunktion spendieren möchte, der braucht nur die GNU-Readline- und History-Libraries einzubinden und jeweils eine ihrer Funktionen zu nutzen .
Die GNU-Utilities »readline« und »history« gehören zu den Dinosauriern der IT, gleichwohl erweisen sie sich nach wie vor als überaus nützlich: Mit ihnen kann jedes Kommandozeilen-Programm ohne viel Eigeninitiative einen Mechanismus zum Editieren und Wiederholen von User-Eingaben anbieten.
Längliches SQL
Wer zum Beispiel im MySQL-Client »mysql« (Abbildung 1) eine längliche SQL-Abfrage eintippt, der weiß es sicherlich zu schätzen, dass er sie durch einen Druck auf die [Cursor-up]-Taste beim nächsten Eingabeprompt wieder hervorholen kann. Entweder, um sie dann nochmals abzusetzen, oder auch, um sie zu modifizieren. Diese Funktionen sind übrigens unabhängig von dem Kommando »e«, mit dem der MySQL-Client eine weitere Möglichkeit der Eingabekorrektur bietet. Wenn sich beispielsweise beim Eingeben einer langen Zeile herausstellt, dass das erste Wort einen Fehler enthält, dann fährt der User einfach mit dem Cursor zurück zum Zeilenanfang und berichtigt den Fehler dort, bevor er schließlich das Kommando abschickt.
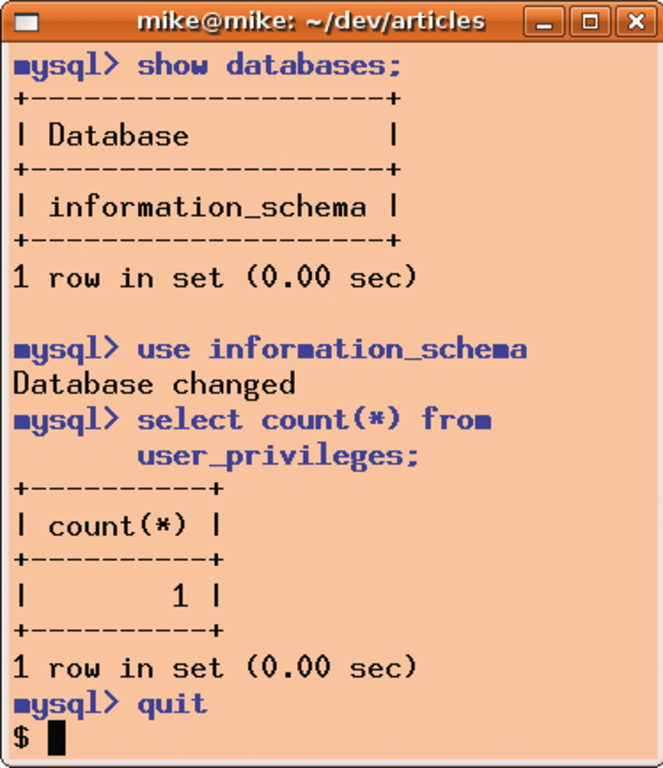
Abbildung 1: Eine Kommandozeilen-Session mit dem MySQL-Client »mysql«.
Wie ein Blick in den MySQL-Sourcecode verrät, implementiert die Datenbank den praktischen Mechanismus gar nicht selbst, sondern nutzt lediglich die C-Funktionen »readline()« und »add_history()« der GNU-Readline- und History-Libraries, um Benutzereingaben einzulesen und ausgewählte Kommandos zum später aufrufbaren History-Pool hinzuzufügen. GNU-typisch bringen die Befehle »info readline« und »info history« die vollständigen Manualseiten der Utilities im 70er-Jahre-Look ans Licht. Mit der [N]-Taste springt »info« zum nächsten Kapitel, mit [P] zurück zum zuletzt betrachteten und die [Tab]-Taste tastet sich innerhalb einer Seite zum nächsten verlinkten Aufzählungspunkt vor.
Sogar nach einem Neustart des MySQL-Clients ist die History-Information der letzten Session noch abrufbar. Das Geheimnis: Wie Abbildung 2 zeigt, legt der verwendete GNU-History-Mechanismus die Information in der Datei »~/.mysql_history« ab. Das letzte Kommando »quit« erscheint nicht in der History-Datei, da MySQL nur nutzbringende Kommandos speichert und bei »quit« noch vor dem Aufruf von »add_history()« merkt, dass es hier nichts Aufhebenswertes gibt, und die Bearbeitung abbricht.

Abbildung 2: In der Datei »~/.mysql_history« liegen die eingegebenen Kommandozeilen für später aufgerufene Sessions abrufbereit.
Perl schottet ab
Perl bietet verwöhnten Skriptprogrammierern eine komfortable Schnittstelle zu den GNU-Libraries an. Das Perl-Modul Term::ReadLine::Gnu vom CPAN kommuniziert hierfür mit dem C-Layer der ebenfalls installierten GNU-Libraries und präsentiert sich dem Perl-Programmierer als objektorientierte Schicht. Das Modul Term::ReadLine liegt Perl-Distributionen von Anfang an bei, es bietet allerdings nur eingeschränkte Funktionen. Erst durch die Installation von Term::ReadLine::Gnu vom CPAN ist Term::ReadLine voll funktionsfähig.
Listing 1 erzeugt ein Objekt der Klasse Term::ReadLine und ruft dessen Methode »readline()« auf. Die wiederum fordert den User dann mit dem ihr überreichten String (»input>«) zur Eingabe eines Kommandos auf. Enthält das eingegebene Kommando verwertbare Zeichen, ist es sinnvoll, es mit »add_history()« in den Zeilenspeicher zu übernehmen, um es später mit den Cursortasten wieder hervorkramen zu können.
|
Listing 1: |
|---|
01 #!/usr/local/bin/perl -w
02 use strict;
03
04 use Term::ReadLine;
05 my $term = Term::ReadLine->new("myapp");
06
07 while (1) {
08 my $input = $term->readline("input>");
09 last unless defined $input;
10 print "Input was '$input'n";
11
12 if($input =~ /S/) {
13 $term->addhistory($input);
14 }
15 }
|
Das Beispiellisting macht es sich einfach und akzeptiert alles außer Leerzeichen als verwertbar, natürlich sind aber auch raffiniertere Prüfungen vorstellbar. Weitere Informationen zur Terminal-Programmierung unter Perl finden sich in den Manualseiten der beiden CPAN-Module sowie – allerdings eher spärlich – in der Perl-Literatur, zum Beispiel in [2].
Ungenießbarer Zeichensalat im Debugger
Auch der eingebaute Perl-Debugger verfügt über einen History-Mechanismus, damit der User nicht ewig die gleichen Kommandos eintippen muss. Kommt allerdings nach dem Druck auf eine Cursortaste nur Zeichensalat zum Vorschein, zum Beispiel
perl -d test.pl DB<1> $ ^[[A,
dann ist dies ein sicheres Zeichen dafür, dass das Opfer vergessen hat, den Perl-Wrapper der GNU-Readline-Library mit
cpan> install Term::ReadLine::Gnu
vom CPAN zu installieren. Perls Debugger überprüft nämlich beim Programmstart, ob das »Gnu«-Modul tatsächlich verfügbar ist, und stellt bei dessen Fehlen eine zwar funktionale, aber deutlich eingeschränkte Tippumgebung ohne History-Funktionen bereit.
Ohne manuellen Eingriff erfolgt die Cursor-Navigation mittels Emacs-Kommandos, was für Vi-Liebhaber befremdlich wirken mag. Bekanntlich hat sich schon so mancher beim Tippen der komplizierten Emacs-Tastenkombinationen den Handwurzelknochen gebrochen. Mit der Option
set editing-mode vi
in der Datei »~/.inputrc« im Homeverzeichnis lässt sich dies aber ganz leicht vermeiden, denn damit springt Readline automatisch in den Vi-Modus.
Fällt allerdings erst während des Tippens auf, dass Readline sich nicht im gewünschten Editormodus befindet, schaltet die Tastenkombination [Meta]+[Strg]+[J] um. Die sieht zwar Emacs-verdächtig aus, doch auch der Vi-Modus versteht sie und schaltet daraufhin in den Emacs-Modus. Verfügt das Keyboard über keine [Meta]-Taste, kann man hierfür auch erst die [Esc]-Taste kurz antippen und dann [Strg]+[J] drücken.
Statt [Strg]+[B], um den Cursor ein Zeichen nach links zu rücken, tippt der Vi-Freund dann [Esc], um in den Command-Modus zu gelangen, und anschließend einfach so oft [H], bis der Cursor an der gewünschten Stelle weiter links steht. Mit [I] geht es dann wieder zurück in den Insert-Modus.
Wir schreiben Geschichte
In einer History, die Dutzende von Kommandos umfasst, kommt der User sicherlich schneller zum Ziel, wenn er nach bestimmten Einträgen sucht, statt seitenweise unpassende Kommandos durchzublättern. Im Vi-Modus schaltet die [Esc]-Taste zunächst in den Command-Modus, in dem dann ein Querstrich, gefolgt von Teilen des gesuchten Texteintrags und der [Return]-Taste, eine Liste von Treffern zurückgibt, durch die die Taste [N] (Next) vorwärts und die Taste [P] (Previous) rückwärts blättert.
Erscheint der gewünschte History-Eintrag, schickt die [Return]-Taste ihn ab, doch auch weitere Editiervorgänge sind mit gängigen Vi-Kommandos möglich. Im Emacs-Modus sucht [Strg]+[R] rückwärts und zeigt in diesem aktiven Suchmodus zu teilweise eingegebenen Zeichenketten jeweils passende Treffer an (Abbildungen 3 und 4).

Abbildung 3: Im Emacs-Suchmodus holt Readline auf den Buchstaben »o« hin das letzte passende Kommando hervor …

Abbildung 4: … und tippt der User weiter (»ow«), findet der Mechanismus ein weiter zurückliegendes Kommando.
Zwangsweise eingewickelt
Programmen, die ohne Readline-Funktionen programmiert sind und denen deswegen die Fähigkeit zum Merken und Editieren von Eingabezeilen völlig abgeht, bringt der Wrapper »rlwrap« [3] die notwendigen Tricks bei. Listing 2 zeigt ein einfaches Perl-Skript, das mit dem Perl-typischen Konstrukt »<STDIN>« dreimal von der Standardeingabe eine Benutzereingabe entgegennimmt und diese anschließend ausgibt.
|
Listing 2: |
|---|
01 #!/usr/local/bin/perl -w
02 use strict;
03
04 $| = 1;
05 for(1..3) {
06 print "Input> ";
07 my $in = <STDIN>;
08 chomp $in;
09 print "You said '$in'n";
10 }
|
In Abbildung 5 ist zu sehen, wie der Benutzer auf die [Cursor-up]-Taste drückt, um den letzen Eintrag erneut aufzurufen, aber auf Unverständnis stößt und nichts als einen aus »^[[A« bestehenden Zeichensalat erntet. In der Abbildung 6 hingegen wirft der Anwender das unveränderte Skript mit dem Wrapper »rlwrap« an und, siehe da, ein Tastendruck auf [Cursor-up] in der dritten Eingabezeile zaubert die in der zweiten Eingabezeile getippten Daten wieder hervor. Die Daten bestehen sogar über den Aufruf des Skripts hinaus weiter.

Abbildung 5: Ohne Readline-Unterstützung bringt die Cursortaste keine alten Einträge hervor, sondern Zeichensalat.

Abbildung 6: Der Wrapper »rlwrap« bringt dem unveränderten Programm Readline-Unterstützung und holt den letzten Eintrag noch einmal hervor.
Wer neugierig im Homeverzeichnis schnüffelt, findet sie in der Datei ».wrapper-test_history« wieder. Zauberei? Nein, »rlwrap« überlädt lediglich mit »LD_PRELOAD« die Eingabefunktionen des ursprünglichen Programms und ersetzt sie durch Wrapper, die mit GNUs Readline- und History-Libraries ticken.
Readline bietet nicht nur eine Editierfunktion, sondern komplettiert darüber hinaus nach einem Druck auf die [Tab]-Taste auch unvollständige Eingaben. Ähnlich wie mit dem in [4] kürzlich an dieser Stelle vorgestellten Bash-Komplettiermechanismus kann der Anwender auch diese Funktion individuell anpassen.
Kompliziertes Readline
Listing 2 zeigt exemplarisch einen einfachen Kommando-Interpreter, der im Beispiel aber nur die Befehle »install«, »remove« und »quit« versteht. Das API der Kommando-Ergänzung der Readline-Library ist ein wenig komplizierter, denn unter dem Eintrag »completion_entry_function« erwartet sie einen Callback, den Readline dann mehrmals aufruft, wenn der User nur einmal [Tab] drückt, und zwar so lange, bis alle Vorschläge vorliegen.
Readline legt dem Aufruf des Callback jeweils zwei Parameter bei: »$count« und »$word«. Der Parameter »$word« ist das zu ergänzende Wort, also der String, an dessen Ende der Cursor stand, als der User [Tab] drückte. »$count« ist beim ersten Aufruf »0« und wird bei folgenden Aufrufen hochgezählt.
Die Callback-Funktion initialisiert sich also, wenn »$count« den Wert »0« führt, und liefert dann bei jedem weiteren Aufruf, bei dem »$count« ungleich null ist, einen Wert aus einer Liste möglicher Ergänzungen zurück. Ein Rückgabewert von »undef« signalisiert hingegen, dass die Liste abgearbeitet ist.
Falls zu einem angefangenen Wort nur eine Ergänzung in Frage kommt, liefert die Callback-Funktion beim Aufruf mit »$count« gleich »0« das Ergebnis zurück und im darauf folgenden Aufruf mit »$count« gleich »1« den Wert »undef«. Zum Glück für den Programmierer hat Term::ReadLine::Gnu für einfache Fälle schon eine Callback-Funktion vorbereitet, die unter dem Eintrag »list_completion_function« unter der Referenz »$attribs« verfügbar ist. Diese Funktion komplettiert all jene Wörter, die sie in einem speziellen Array unter dem Hasheintrag »completion_word« vorfindet.
Statt erst eine Callback-Funktion schreiben zu müssen, legt der Programmierer dank dieser Hilfestellung also nur eine Liste komplettierbarer Schlüsselwörter im Hasheintrag »completion_word« ab. Dann setzt er den Wert von »completion_entry_function« so, dass er auf die unter dem Schlüssel »list_completion_function« liegende Funktionsreferenz verweist. Damit ist alles erledigt.
|
Listing 3: |
|---|
01 #!/usr/local/bin/perl -w
02 use strict;
03
04 use Term::ReadLine;
05 my $term = Term::ReadLine->new('myapp');
06 my $attribs = $term->Attribs;
07 $attribs->{completion_entry_function} =
08 $attribs->{list_completion_function};
09
10 $attribs->{completion_word} =
11 [qw(install remove quit)];
12
13 while(1) {
14 my $cmd = $term->readline("myapp> ");
15 last if $cmd =~ /^quit/i;
|
Fragt das Skript in Listing 3 in dieser Situation mit »myapp>« nach einem Kommando und der User gibt daraufhin [I]+[Tab]« ein, dann vervollständigt Readline dies zu dem Kommando »install«. Und schont spart sich der Benutzer wieder sechs Anschläge. (jcb)
|
Infos |
|---|
|
[1] Alle Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2010/06/Perl] [2] Peter Wainwright, “Pro Perl”: Apress Verlag, 2005, S. 551 [3] Der Wrapper »rlwrap«: [http://utopia.knoware.nl/~hlub/rlwrap/man.html] [4] Michael Schilli, “Stets zu Diensten”: Linux-Magazin 04/2010, S. 122[https://www.linux-magazin.de/Heft-Abo/Ausgaben/2010/04/Stets-zu-Diensten] |
|
Der Autor |
|---|
|
Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. Er hat die Bücher “Goto Perl 5” (deutsch) und “Perl Power” (englisch) für Addison-Wesley geschrieben und ist unter [mschilli@perlmeister.com] zu erreichen. |





