
Pavel Parmenov, Fotolia
Nur wenige Tage nach Erscheinen des vorletzten Hefts gingen die Einsendungen im Stundentakt ein. Anhänger aller möglichen Sprachen wollten beweisen, dass sie besser programmieren können als es die Sprachpäpste im Linux-Magazin getan hatten. Die Auswertung zeigt: Das Volk irrt nicht.
Das Echo auf den Sprachvergleich aus Linux-Magazin 10/2008 [1] kann sich sehen lassen: Über 60 Programme in 13 Sprachen gingen in der Redaktion ein. Die Zahlen sind zwar nicht repräsentativ, geben aber dennoch einen Hinweis auf die Beliebtheit der Sprachen. Die populären Skriptsprachen Python und Perl sind auch im Testfeld am häufigsten vertreten (16 und 15 Einsendungen). Danach folgen neun Vorschläge in C++ und sieben in Ruby. Einige C++-Lösungen nutzten den Parser-Generator Flex zum Erzeugen des eigentlichen Quellcodes.
Gleichviele Beiträge gingen in Awk und Java ein (je vier) – weiter können Sprachkonzepte kaum auseinanderliegen. Ebenfalls in der Schlussgruppe finden sich C, C# und Pascal unter den klassischen Compilersprachen, Tcl als versprengter Vertreter der Skriptsprachen und schließlich noch Groovy, Haskell und Ocaml als Exemplare eher experimenteller und exotischer Sprachen. Gerade letztere verbuchte jedoch einen faustdicken Überraschungserfolg, denn die Ocaml-Lösung landete auf dem ersten Platz bei der Laufzeitmessung.
Aufgrund der großen Anzahl von Vorschlägen präsentiert dieser Artikel nur eine Auswahl, die die Redaktion nach Laufzeit, Kompaktheit des Codes und stilistischen Merkmalen getroffen hat.
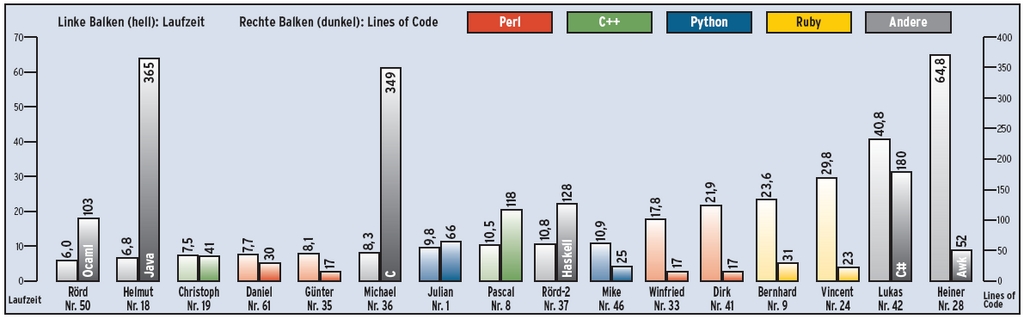
Abbildung 1: Sechzehn Finalisten haben die Sortieraufgabe auf sehr unterschiedliche Weise implementiert. Das Diagramm nennt die verwendete Sprache und zeigt die Laufzeit der jeweiligen Lösung in Sekunden sowie die Anzahl an Programmzeilen. Zu sortieren war eine 55 MByte große Datei mit rund einer Million Fußnoten.
Testumgebung
Die eingesendeten Lösungen inklusive einer kleinen Testumgebung, die alle Programme gegebenenfalls übersetzt und startet, stehen auf dem FTP-Server des Linux-Magazins zum Download bereit [2]. Bevor sie die diversen Programme in das Makefile für den Performancetest integrierte, untersuchte die Redaktion jedes Programm auf Funktionstüchtigkeit. Dazu ein kurzer Test-Input mit 8 MByte. Praktischerweise hatte Linux-Magazin-Leser Sebastian Mach einen Testgenerator geschrieben, der sich hierzu bestens eignete. Dieses Tool ist ebenfalls auf dem FTP-Server zu finden.
Um die Einsendungen zum Laufen zu bringen, musste die Redaktion gelegentlich minimale Änderungen vornehmen, etwa wenn ein Programm stur eine bestimmte Eingabedatei verwendete oder im Fußnoten-Trenner »@footnote:« ein Plural-S erwartete.
Wettkampfbedingungen
In der Endrunde musste jeder Vorschlag exakt den gleichen Input verarbeiten wie die Lösungen der Sprachgurus: Die Textdatei »sample5.txt« enthält rund eine Million Fußnoten in einer Datei von 55 MByte. Einige Einsender haben clevere Optimierungen vorgeschlagen und mitunter unterschiedliche Varianten der Sortierung implementiert.
Im Labor kamen jeweils die Voreinstellungen zum Einsatz. Eine Übersicht der 16 Finalisten zeigt Abbildung 1. Die Zeitachse (linker Balken) stellt die reale Laufzeit dar. Fast alle Lösungen benötigten rund 95 Prozent ihrer CPU-Zeit im Userland, um die Datenstrukturen zu verarbeiten, einzig die Varianten “Lukas” in C# und “Pascal” in C++ wichen von diesem Muster ab. Sie nutzen im Verhältnis mehr Kernelfunktionen.
Alle Programme erhielten praktisch einen eigenen Core für ihre Aufgabe auf einer Intel-L2400-CPU, die mit 1,66 GHz getaktet war und über 3,2 GByte Hauptspeicher verfügte. Der langsamste Vertreter beim letzten Test hatte rund 50 Sekunden für die Aufgabe benötigt, daher standen den Einsendungen zwei Minuten CPU-Zeit mittels »ulimit -t 120« zu. Nach 120 Sekunden brach der Kernel jedes Skript automatisch ab.
Die Länge des Programms – der zweite Balken in Abbildung 1 – maß das Makefile kurzerhand per »wc -l« und bezog dazu alle Code- und Header-Dateien inklusive aller Kommentare und Leerzeilen ein, schloss jedoch Hilfsdateien wie Makefiles oder Projektdefinitionen aus. Dieser Wert eignet sich somit nur bedingt für eine Wertung. Die folgenden manuellen Untersuchungen beziehen sich hingegen auf die reale Code-Menge.
Die Programme tragen den Vornamen ihrer Autoren, im Text ist jeweils eine Referenznummer angegeben, mit der sich die Lösungen auf dem FTP-Server lokalisieren lassen.
|
Listing 1: Perl: Günther |
|---|
01 #!/usr/bin/perl
02 use strict;
03
04 open(IN, @ARGV[0]) or
05 die "Cannot open file '@ARGV[0]': $!n";
06 undef $/; my $file = <IN>;
07 $file =~ /@footnote/g or
08 die 'Missing marker "@footnote".', "n";
10 (my $notecount, my @indexmap) = (0, ());
11 $indexmap[$1] = ++$notecount
12 while ($file =~ /[(d+)]/g);
13
14 (pos($file), my $from) = (0, 0);
15 while ($file =~ /[(d+)]/g) {
16 print substr($file, $from, pos($file) - $from - 2 - length($1)) . '[' . $indexmap[$1] . ']';
17 $from = pos($file);
18 }
19
20 print substr($file, $from);
|
|
Listing 2: Perl: Winfried (Nr. |
|---|
01 #!/usr/bin/perl
02
03 while ( <> ) {
04 $fn = 1 if /^@footnote:/;
05 if ( $fn ) {
06 (s/^[(d+)] (.*)//) &&
07 ($footer->{ $fn_hash->{ $1 } } =
08 sprintf "%s", $2) || print;
09 } else {
10 while ( s/^(.*?)[(d+)]//x ) {
11 printf "%s[%s]", $1, $fn_hash->{ $2 }
12 ||= ++$index;
13 }
14 print;
15 }
16 }
17
18 foreach ( sort keys %$footer ) {
19 printf "[%s] %sn", $_, $footer->{ $_ };
20 }
|
|
Listing 3: Perl: Dirk (Nr. |
|---|
01 #!/usr/bin/perl
02 while (my $line = <>) {
03 if($w) {
04 $line =~ /^[(d+)]s+(.*)$/;
05 $footnote[$index{$1}] = $2;
06 } else {
07 $w = 1 if $line =~ /^@footnotes/;
08 @hits = $line =~ /[(d+)]/g;
09 foreach my $hit (@hits) {
10 if (not defined $index{$hit}) {
11 $index{$hit} = ++$i };
12 $line =~ s/[$hit]/[$index{$hit}]/g;
13 }
14 print $line;
15 }
16 }
17 for my $i (1..$#footnote+1) {
18 printf("[%d] %sn", $i, $footnote[$i] ?
19 $footnote[$i] : 'not defined')
20 if defined($footnote[$i]) or
21 defined($index{$i})
22 }
|
Kurz: Günther, Winfried, Dirk
Perl wird seiner Rolle als knappe Programmiersprache einmal mehr gerecht: Gleich drei Lösungen teilen sich den ersten Platz bei der Programmlänge. Die Programme “Günther” (Nr. 35), “Winfried” (Nr. 33) und “Dirk” (Nr. 41) benötigen nur 17 Zeilen Code für die Aufgabe (siehe Listings 1, 2 und 3, teilweise gekürzt).
Zudem bügelten die Perl-Freunde die Schmach, die einige in der langen Laufzeit der Expertenlösung sahen, wieder aus. Deren Autor Randal L. Schwartz hatte allerdings auch explizit den Auftrag erhalten, seine Lieblingssprache stilistisch vorzustellen, und nicht sein Programm auf Leistung zu trimmen. Das erledigten die drei Perl-Skripte im Testfeld, von denen das schnellste kaum ein Zehntel der Laufzeit der ersten Perl-Lösung benötigte. Alle drei verfolgen einen ähnlichen Ansatz und kommen mit einfachen Datenstrukturen aus. Der Ruf der Skriptsprache ist wieder hergestellt.
Schnell: Rörd, Helmut, Christoph
Die schnellsten Lösungen benutzen Compilersprachen – was niemanden überrascht. Verwundert hat aber doch, dass die Ocaml-Variante “Rörd” allen anderen den Rang ablief (Nr. 50, Listing 4). Die Sprache, die objektorientierte und funktionale Elemente vereint, hatte ihre Qualitäten schon bei mehreren Programmierwettbewerben bewiesen.
Auch auf C++ hatten einige in der Redaktion gewettet. Tatsächlich ist “Christoph” (Nr. 19, Listing 5) nur eine gute Sekunde langsamer als die Ocaml-Lösung. Das Programm nutzt neben der Bibliothek “Perl Compatible Regular Expression” nur reines C++ und schafft es damit auf Platz drei.
Für eine weitere Überraschung sorgte das Java-Programm “Helmut” (Nr. 18): Es war eine Spur schneller als die C++-Variante, benötigt dafür jedoch 365 Programmzeilen. Um das Ergebnis zu erreichen, wählte der Autor einen Mittelweg zwischen objektorientiertem Programmierstil und konkreter, datennaher Implementierung. So besteht sein Code aus fünf Klassen, darunter ein abstraktes Interface und zwei alternative Umsetzungen für die Sortierstrategie. Im Gegensatz zu vielen anderen Lösungen benutzt er jedoch keine Regular Expressions, um über den Text zu iterieren. Vielmehr lädt er Textstücke in Eingabebuffer und bearbeitet diese zeichenweise. Dabei hält er die Verwaltungsstrukturen einfach in einem Hash.
|
Listing 4: Ocaml: Rörd (Nr. |
|---|
01 let sep_line = "@footnote:"
02 let ref_regexp = Str.regexp "\[\([0-9]+\)\]"
03
04 let ref_of_int n="[" ^ string_of_int n ^ "]"
05
06 let output_endline c s = output_string c s; output_char c 'n'
07
08 exception End_of_body
09
10 (* read body from inc, substitute references from table refs. If not in refs, evaluate unknown_ref; print to outc *)
11 let process_body inc outc refs unknown_ref =
12 let sub_ref l _ =
13 let old_n = int_of_string (Str.matched_group 1 l) in
14 try ref_of_int (Hashtbl.find refs old_n)
15 with Not_found -> unknown_ref old_n
16 in
17 try
18 while true do
19 let l = input_line inc in
20 if l = sep_line then raise End_of_body;
21 output_endline outc
22 (Str.global_substitute ref_regexp (sub_ref l) l)
23 done
24 with End_of_body -> output_endline outc sep_line
25
26 (* read foots from inc, process lines *)
27 let process_foots inc process_foot malformed_foot =
28 try
29 while true do
30 let l = input_line inc in
31 if Str.string_match ref_regexp l 0 then
32 process_foot l (int_of_string (Str.matched_group 1 l))
33 else malformed_foot l
34 done
35 with End_of_file -> ()
36
37 (* insert a new reference for old_n into refs and return the new n *)
38 let insert_ref refs old_n =
39 let n = Hashtbl.length refs + 1 in
40 Hashtbl.add refs old_n n;
41 n
42
43 (* reorder foots by appearance in body *)
44 let renumber_by_body inc outc =
45 let refs = Hashtbl.create 1000000 in
46 let new_ref old_n = ref_of_int (insert_ref refs old_n) in
47 process_body inc outc refs new_ref;
48 let foots = Array.make (Hashtbl.length refs) None in
49 let add_foot l old_n =
50 try
51 let n = Hashtbl.find refs old_n in
52 foots.(n-1) <- Some (Str. string_after l (Str.match_end ()))
53 with
54 Not_found -> prerr_endline ("unreferenced footnote: " ^ l)
55 and prerr_malformed l = prerr_endline ("malformed footnote: " ^ l) in
56 process_foots inc add_foot prerr_malformed;
57 for i = 1 to Array.length foots do
58 output_string outc (ref_of_int (i));
59 match foots.(i-1) with
60 None -> output_endline outc "Missing"
61 | Some l -> output_endline outc l
62 done
63
64 (* renumber references by original order *)
65 let renumber_by_foots inc outc =
66 while input_line inc<>sep_line do () done;
67 let refs = Hashtbl.create 1000000 in
68 let add_foot_ref _ old_n =
69 if not (Hashtbl.mem refs old_n) then ignore (insert_ref refs old_n)
70 in
71 process_foots inc add_foot_ref ignore;
72 seek_in inc 0;
73 process_body inc outc refs (function _ -> "[?]");
74 let print_foot l old_n =
75 let n = Hashtbl.find refs old_n in
76 output_string outc (ref_of_int n);
77 output_endline outc (Str.string_after l (Str.match_end ()))
78 in
79 process_foots inc print_foot (output_endline outc)
80
81 (* renumber footnote references *)
82 let renumber by_foots =
83 if by_foots then renumber_by_foots else renumber_by_body
84
85 (* process options and input files *)
86 let main () =
87 if Array.length Sys.argv > 1 then
88 let by_foots = ref false in
89 let do_file f =
90 let c = open_in f in
91 (try renumber !by_foots c stdout with e -> close_in c; raise e);
92 close_in c
93 in
94 Arg.parse [("-f", Arg.Set by_foots,
95 "Renumber by original order")]
96 do_file "Usage: footnotes [OPT] [file]"
97 else renumber_by_body stdin stdout;;
98 main ()
|
|
Listing 5: C++: Christoph (Nr. |
|---|
01 #include <fstream>
02 #include <iostream>
03 #include <pcrecpp.h>
04 #include <tr1/unordered_map>
05
06 pcrecpp::RE re_ref("^\[(\d+)\]");
07 pcrecpp::RE re_txt("(.*?)\[(\d+)\]");
08
09 void process(char const * filename) {
10 std::ifstream file(filename);
11 std::string line;
12 while (getline(file, line) and
13 line != "@footnote:");
14 std::tr1::unordered_map<int, int> dict;
15 int counter = 1;
16 while (getline(file, line)) {
17 int number = -1;
18 if (re_ref.PartialMatch(line, &number))
19 dict[number] = counter++;
20 }
21
22 file.clear(); file.seekg(0);
23 while (getline(file, line)) {
24 pcrecpp::StringPiece input(line);
25 pcrecpp::StringPiece prefix;
26 int ref;
27 while (re_txt.
28 Consume(&input,&prefix,&ref))
29 std::cout << prefix << "[" <<
30 (dict[ref] ? dict[ref] : ref) << "]";
31 std::cout << input << "n";
32 }
33 }
34
35 int main(int argc, char **argv) {
36 std::ios::sync_with_stdio(false);
37 for (int i = 1; i != argc; ++i)
38 process(argv[i]);
39 }
|
Elegant: Vincent, Bernhard, Rörd-2
Diesmal konnte sich auch Ruby beweisen – für diese Sprache fand sich im ersten Artikel kein Experte. Die zwei Einsendungen “Vincent” (Nr. 24) und “Bernhard” (Nr. 9) gleichen sich in Codelänge und Laufzeit. Beide errangen zwar keine Spitzenplätze, hielten aber gut mit. Insofern bestätigte Ruby seinen Ruf als hoffnungsvoller Newcomer, der sich noch nicht eindeutig gegen die etablierten Platzhirsche durchsetzt. Besonders eindrucksvoll ist die Kompaktheit des Codes, ohne in kryptische Abkürzungen à la Perl abzugleiten. Von allen Kommentaren befreit, wäre “Vincent” gar nur 14 Zeilen lang (siehe Listing 6).
Vom Autor des schnellsten Programms stammt auch die funktionale Einsendung “Rörd-2”. Sie ist in Haskell verfasst. Der Code zeigt, dass sich fast alle Probleme in jeder Sprache lösen lassen, aber dass das nicht immer die allerbeste Wahl sein muss. Das Lambda-Kalkül ist für die vorgegebene Sysadmin-Aufgabe wohl unnötig und die 128 Zeilen Code lassen den Code-Reviewer erst einmal suchen. Der kompilierte Code läuft zwar schnell, erreicht aber nicht die Spitzengruppe.
|
Listing 6: Ruby: Vincent (Nr. |
|---|
01 #!/usr/bin/ruby -W0
02 # Autor: Vincent Landgraf
03 index, footnodes = {}, {}
04 body, trailer = open(ARGV[0], 'r') { |f| f.read }.split('@footnote:')
05 body.scan(/[d+]/).uniq.each { |r| index[r] = index.size + 1 }
06 trailer.scan(/^([d+])s+(.*)$/) do
07 raise "Error: Node #{$1} not defined" if index[$1].nil?
08 footnodes[index[$1]] = $2
09 end
10 puts body.gsub!(/([d+])/) { '[' + index[$1].to_s + ']' }
11 puts '@footnote:'
12 footnodes.keys.sort.each { |k| puts '[' + k.to_s + '] '
+ footnodes[k] }
|
Skriptsprachen: Mike, Julian, Heiner, Daniel
Etliche Leser trieb es um, dass Python in den Prominenten-Lösungen scheiterte. So auch Einsender “Julian” (Nr. 1), dessen Lösung Python bei der Laufzeit zu einem Platz in der ersten Hälfte des Testfelds verhilft. Die Einsendung von “Mike” (Nr. 46, Listing 7) läuft nur zehn Prozent länger, schafft das aber mit weniger als der Hälfte der Codezeilen. Beide Lösungen beweisen, dass die Sprache Python mit der 55 MByte langen Testdatei gut zurechtkommt.
|
Listing 7: Python: Mike (Nr. |
|---|
01 #! /usr/bin/env python
02 # Autor: Mike Mueller
03
04 import re
05 import sys
06
07 RE_NUMBER = re.compile(r"[(d+)]")
08
09 def process(file_name):
10 "Process all data."
11 data = open(file_name).read()
12 split_text = data.split("@footnote:")
13 footnote_numbers = RE_NUMBER findall(split_text[1])
14 pairs = zip(footnote_numbers, range(1, len(footnote_numbers) + 1))
15 number_dict = dict((number, counter) for number, counter in pairs)
16 def callback(match):
17 "Replace all old with new numbers."
18 return '[%s]' % number_dict.get(match.group(1), 'Footnote %s not found' % match.group(1))
19 print RE_NUMBER.sub(callback, data),
20
21 if __name__ == '__main__':
22 process(sys.argv[1])
|
Die Aufgabe der Fußnotensortierung war eigentlich dem Unix-Urgestein Awk wie auf den Leib geschrieben. Einige Leser, darunter “Heiner” (Nr. 28), haben sie dann auch mit diesem klassischen Allzwecktool gelöst. Listing 8 zeigt den Awk-Aufruf, den Heiner im Original in ein kurzes Shellskript eingebettet hat. Bei der Performance kann die Lösung allerdings nicht mit den modernen Skriptsprachen mithalten und landet abgeschlagen auf dem letzten Platz. Die Awk-Lösung gleicht dies auch nicht durch besonders kurzen Code aus.
|
Listing 8: Awk: Heiner (Nr. |
|---|
01 awk '
02 function renumrefs(line, createmap, result) {
03 result = ""
04 while (match(line, /[[0-9][0-9]*]/) > 0) {
05 oldnum = substr(line, RSTART+1, RLENGTH-2) + 0
06 if (!(oldnum in map) && createmap) {
07 map[oldnum + 0] = ++lastnum
08 }
09 newnum = map[oldnum]
10
11 result = result substr(line, 1, RSTART) newnum "]"
12 line = substr(line, RSTART + RLENGTH)
13 }
14 result = result line
15 return result
16 }
17 $0 == "@footnote:" { mode = "list"; next }
18 $0 !~ /[[0-9][0-9]*]/ { print; next }
19 {
20 if (mode != "list") {
21 print renumrefs($0, 1)
22 } else {
23 notetext[newnum + 0] = renumrefs($0, 0)
24 }
25 }
26 END {
27 for (i = 1; i <= lastnum; i++) { print notetext[i] }
28 }
29 ' "$@"
|
Perl, in mancher Hinsicht Erbe von Awk, wirkt im Vergleich wesentlich frischer: Die Einsendung von “Daniel” (Nr. 61) verpasste mit dem vierten Platz bei der Laufzeit nur knapp das Siegertreppchen und ist in der Kategorie Skriptsprachen sogar ungeschlagen. Mit 30 Zeilen ist der Code allerdings fast doppelt so lang wie die kürzesten Perl-Lösungen.
Kompiliert: Michael, Pascal, Lukas
Auch die systemnahe Sprache C sollte im Wettbewerb nicht fehlen – das dachte sich Leser “Michael” (Nr. 36) und fütterte den Compiler gleich mit 349 Zeilen Quellcode. Bei seiner Implementierung, in der reguläre Ausdrücke einen guten Teil der Laufzeit ausmachen, scheint sich C allerdings nicht so richtig in seinem Element zu befinden. Bei der Laufzeit reicht es gerade mal für einen Platz im vorderen Mittelfeld. Da nimmt schon der Perl-Interpreter in zwei Fällen mehr Fahrt auf. Auch die C++-Lösung von “Pascal” (Nr. 8) landet, obwohl sie einen Compiler bemüht, bei der Laufzeit nur auf einem mittleren Rang.
Eine politische Sonderrolle bekleidet C#. Schöpfer der Sprache ist ausgerechnet Microsoft und der Linux-Port basiert auf dem Engagement von Novell. Die Sprache erntet dennoch viel Lob für ihre konstruktive Mischung aus C++- und Java-Features, siehe dazu den Artikel ab Seite 102. Einsender “Lukas” (Nr. 42) widmete sich in seiner Lösung dieser Sprache.
Dass C# konsequent objektorientiert ist, demonstriert Zeile 9 in Listing 9: Ein regulärer Ausdruck entsteht als neues Objekt mit dem Aufruf »new«. Die Methode »PrintFootNotes()« ab Zeile 18 demonstriert ein einfaches Error-Handling. Schnell und kurz ist die vorliegenden C#-Lösung allerdings nicht – das Listing zeigt nur einen kleinen Code-Auszug.
|
Listing 9: C#: Lukas (Nr. |
|---|
01 public class Footnotesorter
02 {
03 [...]
04 string _strFilename = String.Empty;
05 Dictionary<int, Footnote> _dictHashToFootnote = new Dictionary<int, Footnote>();
06 /* Footnote values will be cached for printing the right order on the bottom */
07 Dictionary<int, string> _dictIndexToValue = new Dictionary<int, string>();
08 /* Regular Expression for finding footnotes */
09 Regex _Regex = new Regex(@"[(d+)]", RegexOptions.Compiled);
10
11 [...]
12 MatchEvaluator me = new MatchEvaluator(MatchReplace);
13 /* Each match calls the MatchReplace function and replaces with its returnvalue */
14 s = _Regex.Replace(s, me);
15 Console.WriteLine(s);
16 [...]
17 /* Simply print all the Footnotes at the bottom in the right order*/
18 private void PrintFootnoteNotes()
19 {
20 for(int i = 1; i < _dictIndexToValue.Count + 1; i++)
21 {
22 try
23 {
24 Console.WriteLine("[" + i + "] " + _dictIndexToValue[i]);
25 }
26 catch(KeyNotFoundException ex){Console.WriteLine(ex.Message + ": " + i);}
27 }
28 }
29 }
30 }
|
Vielfältiges Ökosystem
Wenn Artenvielfalt ein Zeichen für ein gesundes Ökosystem ist, erfreuen sich Programmiersprachen bester Gesundheit. Dass die Leser die stark auf den Sysadmin-Alltag abgestimmte Aufgabe mit so vielen grundverschiedenen Sprachen lösen würden, hatte die Redaktion eingangs nicht erwartet. Besonders beeindruckend waren Einsendungen in Sprachen, die man in diesem Kontext nicht erwartet, etwa Ocaml oder Haskell. Auch das gute Abschneiden von Java überraschte.
Als weiteres Ergebnis bleibt, dass nicht so sehr die gewählte Sprache, sondern in erster Linie das Geschick des Entwicklers der Faktor ist, der über die Geschwindigkeit und die Übersichtlichkeit eines Programms entscheidet. Auch der Lösungsalgorithmus per se ist bei der gestellten Aufgabe nicht das alleinentscheidende Kriterium, dazu war die Aufgabenstellung zu einfach. Vielmehr ist die clevere Wahl von geschickten Datenrepräsentationen und den richtigen Programmbibliotheken für Geschwindigkeit und Speicherverbrauch ausschlaggebend. Kompetente Programmarchitekten bleiben also nach wie vor gefragt.
|
63 Einsendungen in 13 |
|---|
|
Sortiert nach Häufigkeit der Programmiersprachen haben folgende Leser Lösungsvorschläge an die Redaktion gesendet: Python: Mike Müller, Jörg Lehmann, Andreas Lang-Nevyjel, Günter Jantzen, Julian Andres Klode, Klaus Bremer, Markus Korn, Richard Hacker, Aaron Digulla, Robert Hunger, Uli Fouquet, Stefan Schwarzer, Jens Kadenbach, Marc Rintsch, Adi J. Sieker; Perl: Dirk Jäger, Winfried Angele, Guenter Burgstaller, Daniel Pfeiffer, Jens E. Wunderwald, Horst-W. Radners, Daniel Pfeiffer, Simon Bertrang, Uwe Kerstan, Andreas Romeyke, Thomas Birnthaler, David Raab; C++: Joke de Buhr, Enrico Thierbach, Christoph Bartoschek, Marc Wäckerlin, Pascal Hofmann, Sebastian Redl, Christoph Buchetmann, Sebastian Mach; Ruby: Vincent Landgraf, Urs Meyer, Bernhard Reiter, Jörg Lehmann, Ronald Sacher, Knut Franke; Java: Kai Triebel, Oliver Siegmar, Werner Wetjen, Helmut Juskewycz; Awk: Heiner Steven, Marc Wäckerlin, Andreas Bruckmeier, Daniel Werner; Tcl: Holger Jakobs, Michael Schlenker, Gerhard Reithofer; Ocaml: Rörd Hinrichsen, Andreas Romeyke; C: Michael Heide; C#: Lukas Elsner; Groovy: Tobias Käfer; Haskell: Rörd Hinrichsen; Pascal: Stefan Hille. |
|
Infos |
|---|
|
[1] Nils Magnus, Peter Kreußel: “Babylon zu fünft”, Linux-Magazin 10/08, S. 30 [2] Alle Listings und eine Buildumgebung zu diesem Artikel: [ftp://linux-magazin.de/pub/listings/magazin/2008/12/sprachen] |






