
Dieses Backup-System überrascht mit seinen inneren Werten: Mit präparierter Rescue-CD und einem Perl-Skript konserviert es den kompletten Festplatteninhalt von Clients via LAN auf einen Backupserver.
Was tun, wenn die Festplatte ausfällt? Schnellstens eine neue kaufen und das letzte Backup einspielen, selbstverständlich. Was aber, wenn mehrere Partitionen auf der Platte waren: Wie viel Platz war jeder zugeordnet? Welches Filesystem war dort installiert?
Die Wiederherstellung im Notfall (Desaster Recovery) fällt besonders leicht, wenn die Sicherung vollständige Partitionen umfasst, die man am Stück zurückspielen kann. Enthalten diese Partitionen aber beispielsweise das Root-Verzeichnis eines Linux-Systems oder läuft auf einem Laptop gar Windows, dann ist es nicht ohne weiteres möglich, im laufenden Betrieb geeignete Kopien zu ziehen.
Auf Sysresccd.org [2] gibt es allerdings eine Rescue-CD, die eine beliebige x86-Maschine mit einem Minimal-Linux bootet und wichtige Tools wie »partimage«, »sfdisk«, »fdisk«, »perl« und einen NFS-Client enthält. So kann das System anschließend Kontakt mit einem NFS-basierten Backupserver aufnehmen (Installation siehe unten) und sowohl das Partitionierungs-Layout als auch die Partitionen selbst sichern.
Notfall-CD als letzte Rettung
Natürlich möchte niemand umständliche Kommandos tippen, um ein Backup anzulegen. Nach dem Einlegen der CD in den zu sichernden Rechner sollte möglichst alles automatisch ablaufen. Deshalb beschreibt dieser Beitrag eine leicht angepasste Boot-CD, die nur kurz fragt, um welchen Rechner es sich handelt, und dann selbstständig alle Platten auf den Backupserver sichert.
Wie das Diagramm in Abbildung 1 zeigt, nimmt ein mit dieser CD gebooteter Rechner über das »autorun«-Skript sofort Kontakt mit dem Backupserver auf (im Beispiel unter der IP-Adresse 192.168.0.40). Ein zur Sysresc-CD hinzugefügtes »autorun«-Skript (Listing 1) initialisiert hierfür zunächst das Netzwerk und startet anschließend den NFS-Dienst mit seinen beiden Daemons »lockd« und »portmap«.
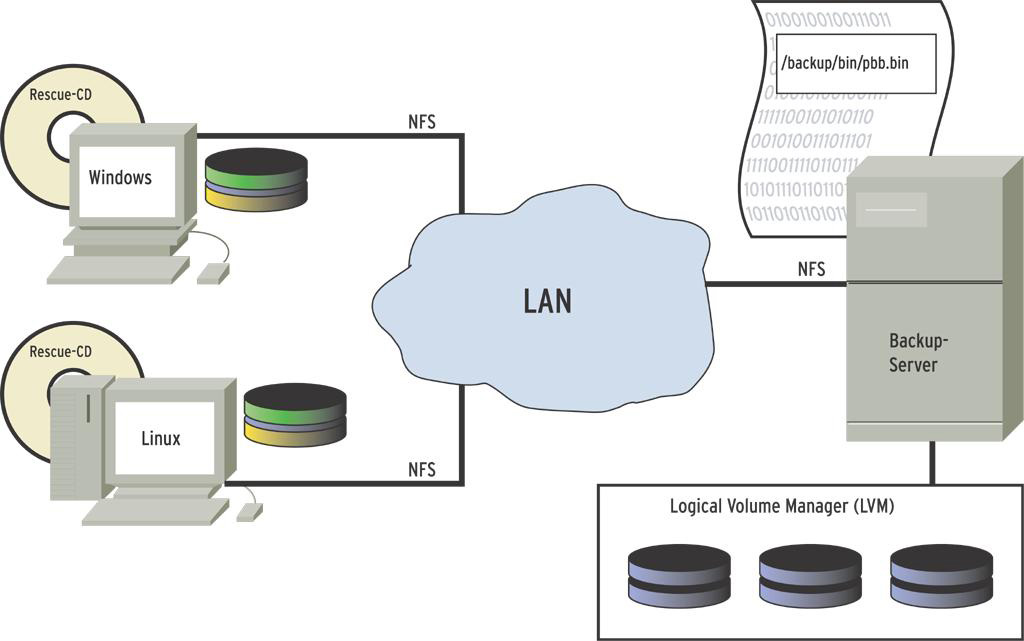
Abbildung 1: Die Rechner im lokalen Netz sichern ihre Partitionen mit Hilfe der gepatchten Sysresc-CD automatisch via LAN auf das LVM-Volume eines NFS-Servers.
|
Listing 1: Autorun |
|---|
01 #!/bin/sh 02 # Sysresccd autorun script 03 IP=192.168.0.40 04 05 # Start network 06 /etc/init.d/net.eth0 start 07 /etc/init.d/nfs start 08 09 # Mount directory via NFS 10 mkdir /mnt/backup 11 mount $IP:/backup /mnt/backup || 12 (echo "Mount failed ($IP down?)"; 13 exit 1) 14 15 # Run backup script over NFS 16 /mnt/backup/bin/pbb.bin 17 18 # Close NFS 19 umount /mnt/backup |
Danach mountet es das Verzeichnis »/backup« des Backupservers unter »/mnt/backup« auf dem zu sichernden Client. Dort steht dann das zu einem Binary kompilierte Perl-Skript »bin/pbb.bin« (Partition Based Backup) bereit. Das Skript »autorun« ruft es über NFS auf und lässt es auf dem Client ablaufen.
Das Skript präsentiert nach dem Start ein einfaches Textmenü mit den nummerierten Rechnernamen der konfigurierten Clients. Sobald der Anwender einen Eintrag auswählt, startet das Backup. Steht hingegen eine Restaurierung an, bricht der Benutzer einfach mit [Ctrl]+[C] ab und operiert weiter in der Root-Shell, in der er danach landet.
Listing 2 zeigt den Sourcecode des Backup-Skripts. Die Funktion »ask()« bietet voreingestellte Rechnernamen aus einer Liste an und »sfdisk« klappert sodann alle sichtbaren IDE-Festplatten auf seinem Client ab. Anschließend sichert das Tool deren Partionstabellen auf den Backupserver. Außerdem kopiert es den Master Boot Record der ersten Platte »/dev/hda« dorthin. Die gesicherten Daten liegen danach im Verzeichnis »/backup/data/Rechner« unter dem anfangs ausgewählten Rechnernamen auf dem Backupserver.
|
Listing 2: |
|---|
01 #!/usr/bin/perl -w
02 use strict;
03 use Pod::Usage;
04 use Sysadm::Install qw(:all);
05 use Log::Log4perl qw(:easy);
06 use Log::Log4perl::Appender::Screen;
07
08 Log::Log4perl->easy_init($DEBUG);
09
10 my $MDIR = "/mnt/backup/data";
11 my %ptypes = map { $_ => 1 }
12 qw(83 7);
13 my @machnames = qw(desktop1
14 desktop2 laptop1);
15 my %machnames = map { $_ => 1 } @machnames;
16
17 my $mname = pick "Box", @machnames, 1;
18
19 my %drive_done;
20
21 my $bdir = "$MDIR/$mname";
22 my $oldbdir = "$MDIR/$mname.old";
23
24 # Move old backup aside
25 if(-d $oldbdir) {
26 LOGDIE "$oldbdir already exists";
27 }
28 mv $bdir, $oldbdir if -d $bdir;
29 mkd $bdir unless -d $bdir;
30
31 # Save the master boot record
32 # of the first IDE disk
33 tap qw(dd if=/dev/hda),
34 "of=$bdir/hda.mbr",
35 qw(count=1 bs=512);
36
37 my $sf = `sfdisk -d`;
38
39 while($sf =~ /^(.*Id=s*(w+).*)/mg) {
40 my($line, $id) = ($1, $2);
41
42 next unless exists $ptypes{$id};
43
44 my($path) = split ' ', $line, 2;
45 (my $dev = $path) =~ s#.*/##;
46 (my $drive = $dev) =~ s/d//g;
47
48 # Save partition drive's table
49 if(!$drive_done{$drive}++) {
50 sysrun "sfdisk -d /dev/$drive " .
51 ">$MDIR/$mname/$drive.pt";
52 }
53
54 # Save partition
55 sysrun "partimage -b -d -z1 -o save" .
56 " /dev/$dev $bdir/$dev.img.gz";
57 }
58
59 # Remove old backup
60 rmf $oldbdir if -d $oldbdir;
61
62 =head1 NAME
63
64 pbb - Partition Based Backup
65
66 =head1 SYNOPSIS
67
68 pbb
69
70 =head1 DESCRIPTION
71
72 Scans all IDE hard drives, and backs
73 them up by partition.
|
Nur Wertvolles sichern
Beim Sichern von Partitionen fällt auf, dass diese oft nicht vollständig gefüllt sind. Wer nur die Rohdaten per »dd if=/dev/hda1 of=backup.img« abzieht, erzeugt am Ende ein unnötig großes Image »backup.img«. Das nützliche Tool »partimage« hingegen kennt die Struktur bekannter Dateisysteme wie Ext 2, Ext 3 oder des unter Windows gängigen NTFS (siehe Artikel in diesem Heft). Es bietet eine nützliche Fortschrittsanzeige, speichert nur relevante Daten und komprimiert diese außerdem noch.
Damit kann es ohne weiteres vorkommen, dass aus einer nur spärlich gefüllten 30 GByte großen Root-Partition eine Backup-Datei resultiert, die lediglich ein paar hundert MByte belegt.
Das Kommando »partimage -b -d -z1 -o save /dev/hda1 / Pfad/hda1.img.gz« ruft »partimage« im Batch Mode (»-b«) auf, damit es sich nach getaner Arbeit automatisch beendet. Die Option »-d« legt fest, dass das Tool dem Benutzer keinen Kommentar für die Beschreibung der entstehenden Imagedatei abverlangt. Mit »-o« überschreibt es rücksichtslos eventuell bestehende Imagedateien und »-z1« bestimmt, dass es die Komprimierung mit »gzip« durchführt. Dabei spaltet »partimage« die entstehende Backupdatei zur leichteren Handhabung in je 2 GByte große Teile, die es fortlaufend nummeriert.
Partitionen selektieren
Das durch den User »root« gestartete Shellkommando »sfdisk -d /dev/hda« liest die Partitionierungstabelle der ersten IDE-Festplatte und gibt sie dann so aus, dass ein späterer Aufruf von »sfdisk« sie anstandslos restaurieren kann (Abbildung 3).
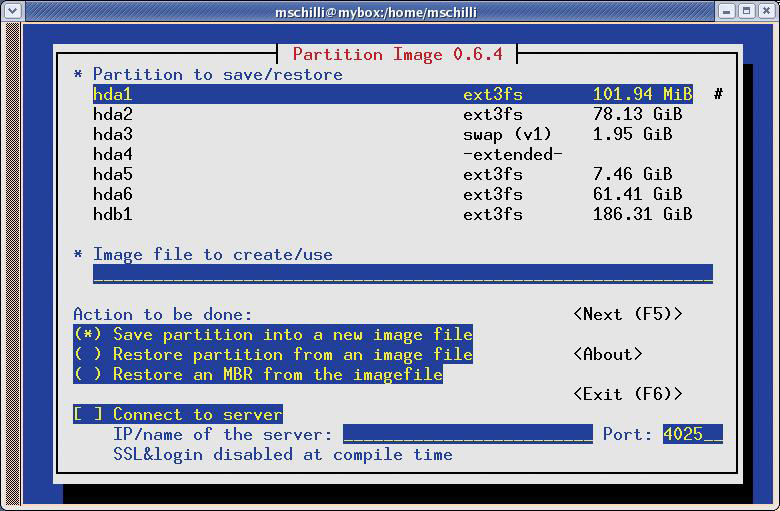
Abbildung 2: Das Tool »partimage« archiviert die Daten roher Festplattenpartitionen und restauriert sie im Bedarfsfall auch wieder.
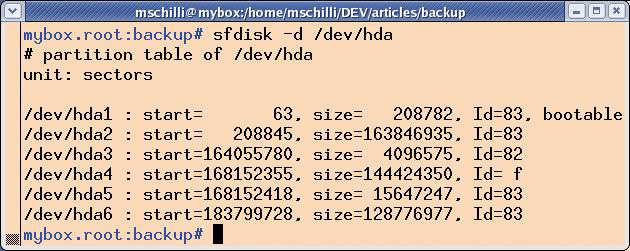
Abbildung 3: Das Kommando »sfdisk« gibt die Partitionierungsdaten einer Festplatte übersichtlich auf der Textkonsole aus.
Um zu sehen, welche Festplatten überhaupt auf dem zu sichernden System installiert sind, hilft »pbb« der Aufruf von »sfdisk -l«, der alle Partitionen aller gefundenen Platten auflistet. Das Backupskript durchsucht sie und führt für alle im »@ptypes«-Array enthaltenen Partitionstypen ein Backup durch (Abbildung 4). Die Zeilen 12 und 42 in Listing 2 legen fest, dass »pbb« nur die Typen 7 (HPFS/NTFS) und 83 (Linux) beachtet. So fallen nicht sicherungswürdige Swap-Partitionen elegant unter den Tisch.
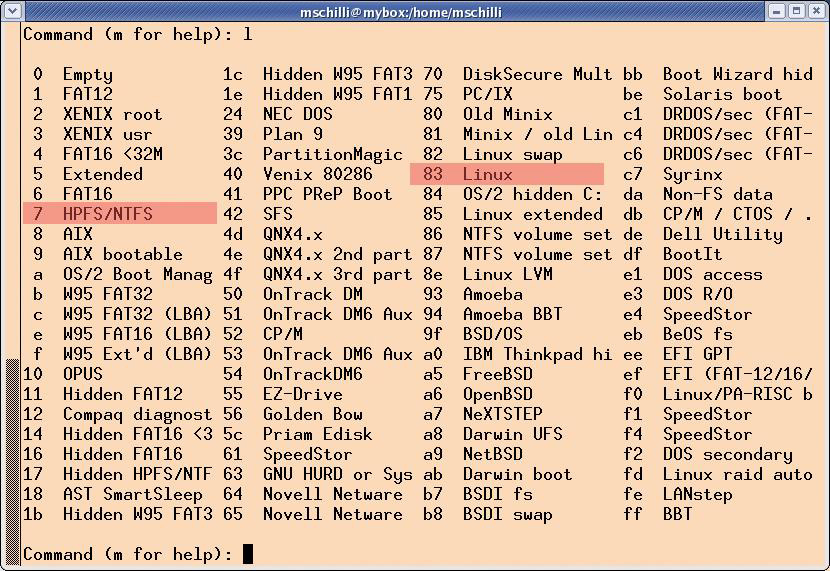
Abbildung 4: Das Kommando »l« im Programm »fdisk« gibt alle bekannten Partitionstypen aus. Das im Artikel vorgestellte Backupskript fasst nur die hier rot hinterlegten Typen an.
Wer andere Partitionstypen sichern möchte (W95 FAT 32 hat zum Beispiel das Kürzel »c«), braucht nur Zeile 12 im Listing anzupassen. Zwar ist laut »partimage« der Support für NTFS noch experimentell, die Tests des Autors funktionierten allerdings tadellos.
Bevor das Skript ein neues Backup anlegt, schiebt es zunächst das alte Backupverzeichnis mit der Endung ».old« zur Seite. Schließlich soll es bereitstehen, falls das neue Backup schief geht oder die Platte ausgerechnet während der Sicherung den Geist aufgibt. Existiert jedoch schon ein ».old«-Verzeichnis, liegt etwas im Argen und der User muss einschreiten, nachdem »pbb« mit einem Fehler abgebrochen hat (Zeile 26).
Das skript »pbb« durchforstet die Ausgabe von »sfdisk -l« nach dem Muster »Id=«, das den Typ jeder gefundenen Partition enthält (beispielsweise »83« oder »c«). Am Zeilenanfang steht dann der Device-Pfad (etwa »/dev/hda1«), und daraus leitet »pbb« den Plattenpfad ab (»/dev/hda«). Für SCSI-Disks funktioniert das freilich nicht, das Skript lässt sich aber leicht erweitern.
Nach einem erfolgreichen Backup entkoppelt sich das gesicherte System in »autorun« mit »umount« wieder vom NFS-Server, um sicherzustellen, dass die Backupdaten vor dem Herunterfahren des Rechners intakt auf der anderen Seite angekommen sind.
Ernstfall
Tritt der Ernstfall ein und eine neu gekaufte und installierte Platte muss das jüngste Backup erhalten, bootet der Besitzer das zu restaurierende System wiederum mit der Rescue-CD und spielt anschließend die gesicherte Partitionstabelle auf der neuen Platte ein: »sfdisk /mnt/backup/data/Rechner/hda.pt«.
Handelt es sich, wie im Beispiel, um die Festplatte mit dem Master Boot Record, der in den ersten 512 Bytes gespeichert ist und für den Bootvorgang gebraucht wird, dann kommt dieser mit »dd if=/mnt/backup/data/Rechner/hda.mbr of= /dev/hda« wieder zurück auf die zu restaurierende erste IDE-Festplatte »hda«. Um die Daten einer Partition wiederherzustellen, startet man »partimage« am besten von der Kommandozeile, wählt im GUI »Restore a partition from an image file« und gibt den Pfad zum gesicherten Image mit »/mnt/backup/data/Rechner/hda.img.gz.000« an. Die folgenden Teile sucht »partimage« sich dann im gleichen Verzeichnis zusammen.
Auf der Rescue-CD ist zwar eine Perl-Installation enthalten, aber leider fehlen CPAN-Module, die das Skript »pbb« braucht, etwa Sysadm::Install oder Log::Log4perl. Doch dank des schon einmal in [4] vorgestellten PAR (Perl Archive Toolkit) ist es leicht, aus dem Skript auf einem vollständig mit allen notwendigen CPAN-Modulen installierten und kompatiblen Linux-Rechner einfach ein Binärpaket »pbb.bin« zu schnüren, das sowohl das Skript, als auch alle verwendeten Module (und obendrein einen Perl-Interpreter) enthält.
An den Haaren aus dem Sumpf
Zu beachten ist allerdings, dass das System, auf dem das Binärpaket geschnürt wird, mit einer Version der Libc läuft, die kleiner oder gleich 2.3.2 ist. Das mit der Sysresc-CD gebootete System läuft nämlich damit, und wer das Perl-Bündel mit einer jüngeren Version erzeugt, kann sich sehr leicht Kompatibilitätsprobleme einhandeln.
Der Aufruf des PAR-Compilers mit »pp -o ppb.bin ppb« macht aus dem Perl-Skript »pbb« das Executable »pbb.bin«, wenn auf dem ausführenden System das Paket »PAR« vom CPAN installiert ist. »Log::Log4perl::Appender::Screen« zieht »pbb« übrigens extra herein, da »pp« es sonst vergäße. Log4perl benutzt es zur Laufzeit, aber »pp« ermittelt die Abhängigkeiten zur Compile-Zeit.
Backupserver installieren
Als Backupserver hat der Autor einen alten PC mit einigen alten 120-GByte-Platten und einer neuen 400-GByte-Platte zusammengeklopft. Als Operationssystem kam Debians Sarge-Release zum Einsatz – keine Gimmicks, nur ein einfaches und stabiles System, das sich mit »apt-get« leicht aktualisieren lässt.
Um einen großen zusammenhängenden Speicherbereich zu erhalten, verbindet der Logical Volume Manager (LVM) die Einzelpartitionen der Festplatten. Zum Einrichten einer Partition der Festplatte (zum Beispiel »/dev/hdc1«) für den Gebrauch mit LVM ist »pvcreate /dev/hdc1« zuständig. So erzeugte Physical Volumes fasst anschließend eine Volume Group zusammen, die wiederum einem Logical Volume zugeordnet ist:
vgcreate giantvg /dev/hdc1 ... lvcreate -L 600G -n giantlv giantvg
Dieser Aufruf erzeugt ein 600 GByte großes virtuelles Device, das unter »/dev/giantvg/giantlv« verfügbar ist. Mit »mkfs.ext3« lässt sich dort ein Ext-3-Dateisystem installieren, das anschließend mit »mount /dev/giantlv/giantvg /backup« problemlos zu mounten ist.
NFS nachrüsten
Die Root-Partition des Debian-Systems landet mit 10 GByte Größe auf der ersten 120-GByte-Platte des Testsystems, den verbleibenden Platz von 110 GByte schlägt eine LVM-Definition elegant dem großen Datenbereich für Backup-Zwecke zu. Der NFS-Server ist nicht in der Grundinstallation enthalten, der Aufruf »apt-get install nfs-kernel-server nfs-common portmap« zieht ihn elegant vom Netz und installiert ihn.
Damit die Rechner im lokalen Netz auf das Verzeichnis »/backup« lesend und schreibend zugreifen dürfen, ist noch der Eintrag »/backup 192.168.0.*(rw,sync)« im File »/etc/exports« erforderlich, wobei die IP-Adresse natürlich anzupassen ist. Das Kommando »exportfs -a« propagiert die Änderung.
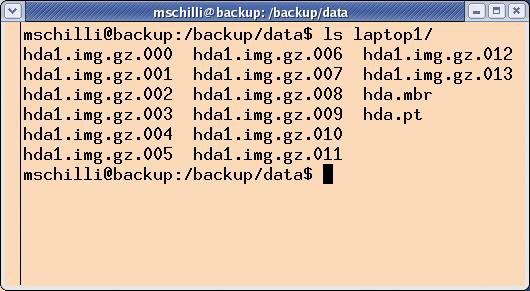
Abbildung 5: Die gesicherten Daten eines Laptops mit einer Festplatte sammelt ein Verzeichnis auf dem Backupserver.
Weil die von Sysresccd.org erhältliche Rescue-CD den Rechner bootet und dann die nach dem Booten sichtbaren Programme in einer so genannten »cloop« einschließt, müssen beim Patchen einige vorgeschriebene Schritte gemäß der Anleitung auf [2] eingehalten werden.
Notfall-CD patchen
Das Shellskript in Listing 3 holt die Datei »autorun« aus dem »bin«-Verzeichnis des gemounteten Backupservers und kopiert sie ins Root-Verzeichnis der neuen CD. Das Kommando »mkcd« muss der Anwender auf einem mit der Sysresc-CD gebooteten System aufrufen, damit es die aktive Rescue-CD zunächst in ein temporäres Verzeichnis kopiert, dann »autorun« hinzufügt und anschließend mit einem ebenfalls von der CD stammenden Skript eine modifizierte ISO-Datei erzeugt. Die legt es im Root-Verzeichnis des Backupservers ab, anschließend lässt sie sich dort mit »cdrecord dev=/dev/cdrom speed=4 sysresccd-new.iso« auf eine neue CD brennen. Wer zwei Laufwerke eingestöpselt hat, kann dies auch mit einem einzelnen Rechner bewerkstelligen.
|
Listing 3: |
|---|
01 CUST=/usr/sbin/sysresccd-custom 02 MNT=/mnt/backup 03 OUT=/mnt/custom 04 05 cd $MNT 06 07 dd if=/dev/zero of=fsimage bs=1M count=1000 08 mke2fs -F -q -N 50000 fsimage 09 mount -t ext2 -o loop fsimage $OUT 10 11 $CUST extract 12 $CUST cloop 300 20000 13 14 cp $MNT/bin/autorun $OUT/customcd/isoroot 15 16 $CUST setkmap speakup 17 $CUST isogen my_srcd 18 19 cp $OUT/customcd/isofile/sysresccd-new.iso /mnt/backup |
Kontakt zum Server
Vor dem Brennen der CD und dem Einsatz des Skripts sind die IP-Adresse des Backupservers in »autorun« sowie die Rechnernamen in »pbb« anzupassen und schließlich »pbb« zu kompilieren. Wer möchte, kann das Skript noch mit zusätzlichen Funktionen zur Datenrestaurierung erweitern und so gerüstet dem nächsten Festplattencrash gelassen entgegensehen. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2006/11/Perl] [2] Download für die Rescue-CD von Sysresccd: [http://sysresccd.org] [3] Dokumentation zu Partimage: [http://partimage.org] [4] Michael Schilli, “Gepackte Koffer”: [https://www.linux-magazin.de/Artikel/ausgabe/2004/09/perl/perl.html] |
|
Der Autor |
|---|
|
|







