MySQL ist ein schnelles Datenbanksystem. Wenn die Datenbankanwendung dennoch in der Praxis manchmal lahmt, sind die Ursachen meist suboptimales Datenbankdesign, ineffiziente Abfragen oder der Verzicht auf Indizierung. Diese Fehler sind aber vermeidbar.
MySQL ist ein Datenbankmanagement-Systen (DBMS), das zweifellos für betriebskritische Anwendungen konzipiert und entwickelt wurde, die Leistungsfähigkeit und Zuverlässigkeit dafür sind gegeben. Die Autoren von MySQL verzichteten dafür von vornherein lieber auf seltener genutzte Features, unter denen die Performance möglicherweise leiden könnte. MySQL[1] ist deshalb bis heute kein vollständiges DBMS, bewegt sich jedoch mit großen Schritten auf dieses Ziel zu.
Ab Version 4.0 gibt es neue Tabellentypen, die Transaktionen nach dem ACID-Prinzip[2] ermöglichen. In MySQL Server 4.0 legt das neue ».frm«-Dateiformat für Tabellendefinitionen intern bereits die Grundlage für neue Features, die in der Version 4.1 enthalten sind. Sie ist derzeit in einer Betaversion verfügbar. Dazu gehören unter anderem Subselects oder der Replikationsmechanismus. Für die nachfolgende Version 5.0 ist auch die Unterstützung von Stored Procedures, Triggers sowie referenzieller Integrität von Fremdschlüsseln (Foreign Keys) versprochen.
Trifft man in der Praxis auf langsame MySQL-Anwendungen, dann sind die Ursachen meist hausgemacht: ein schlechtes Datenbankdesign, ineffiziente Abfragen, Verzicht auf Indizierungen, eine schlechte Konfiguration oder unpassende Hardware-Ausstattung. Das alles ist vermeidbar. Die Performance-Optimierung sollte aber möglichst schon während der Entwicklung erfolgen und nicht erst als Nachbesserung am fertigen Produkt, denn je komplexer eine Anwendung ist, desto schwieriger wird die nachträgliche Optimierung.
Raum für Optimierungen
Bei MySQL-Datenbanken gibt es Optimierungsbedarf vor allem unter zwei Gesichtspunkten: Sind einzelne Queries zu langsam, ist fast immer ein suboptimales Design der Tabellen oder Queries die Ursache. Für Abhilfe sorgt in diesen Fällen: Ein Slow-Query-Log schreiben, langsame Queries identifizieren und mit »explain« analysieren. Wirkt jedoch die Datenbank als Ganzes lahm, liegt das meist an der Hardware oder an Versäumnissen bei der Installation.
Den Grundstein für gute Performance wird schon sehr früh gelegt, nämlich bereits beim Entwurf des Datenmodells auf Basis des Entity-Relationship-Modells (ERM)[2]. In der Praxis geht es dabei immer darum, einen Mittelweg zwischen strenger Normalisierung einerseits und schnellen, einfachen Modellen andererseits zu finden. Ein zu akademischer Ansatz führt im Allgemeinen zu einer hohen Anzahl von Tabellen und damit automatisch zu komplexen Abfragen, was die Datenbank deutlich verlangsamen kann.
Andererseits verhindert ein strenger Ansatz Redundanzen und damit die Gefahr von Inkonsistenz. Außerdem bleibt die Applikation besser anpassbar. Wenn Geschwindigkeitsprobleme auftreten, kann es sinnvoll sein, die Datenbank nachträglich zu denormalisieren. Aber erst nachdem die Ursachen gefunden und die möglichen Konsequenzen abgeschätzt wurden, lassen sich Rückschlüsse für die Wartung ziehen.
Welches Tabellenformat für welchen Zweck
In MySQL kommen zahlreiche Tabellenformate für die verschiedensten Einsatzzwecke und Umstände zum Einsatz[3]. Man unterscheidet zwischen Transaktions-basierten (InnoDB, BDB, Gemini) und nicht Transaktions-basierten (MyISAM, ISAM, HEAP, MERGE) Formaten. InnoDB, Gemini und BDB sollten dann eingesetzt werden, wenn die Konsistenz der Datenbank auf keinen Fall gefährdet werden darf. Die Daten können nach einem Absturz von MySQL automatisch wiederhergestellt werden. Zugleich stellen Transaktionen sicher, dass nicht mehrere Anwender simultan Datensätze verändern, und sichern damit die Integrität der Datenbank.
Verknüpfte Tabellen verweisen nur auf tatsächlich existierende Datensätze und nicht ins Leere. Transaktions-sichere Tabellen sind aber langsamer als das am häufigsten verwendete MyISAM-Format. Noch schneller als diese sind Heap Tables, die vollständig im Speicher residieren, aber nach einem Absturz oder Reboot natürlich verschwunden sind und sich deshalb nur für eine temporäre Datenhaltung eigen.
Deklarieren der Datentypen
Ist das Tabellenformat festgelegt, müssen die Daten möglichst sinnvoll auf die Tabellen verteilt werden. Bei der Bestimmung von Zahlenwerten sollte man vorsichtig mit der Deklarierung umgehen. Oftmals ist der Wertebereich größer als erforderlich, was natürlich auch wieder zusätzlichen Speicher belegt. Abhilfe kann hier das Attribut »unsigned« schaffen, das jeweils nur den positiven Wertebereich wiedergibt.
Bei Zeichenketten ist »char« meist besser geeignet als »varchar«, da es in jedem Fall nur eine konstante Bytegröße für jeden Datensatz benötigt, egal wie viele Zeichen der Wert tatsächlich aufweist. Dadurch wird die Zugriffsgeschwindigkeit erheblich gesteigert.
Das Speichern binärer Daten innerhalb der Datenbank als Blob (Binary Large Object) beeinträchtigt die Performance sehr stark. Die einzige konservative Alternative besteht darin, die Daten (meist Dokumente, Bilder oder Multimedia-Elemente) in externen Dateien zu speichern und in der MySQL-Datenbank mit Links darauf zu verweisen. Wenn in einer Zeichenkettenspalte eine begrenzte Menge von Werten vorkommt, ist es möglicherweise auch sinnvoll, diese in »enum«-Spalten abzulegen.
Hilfestellung beim Deklarieren der Datentypen leistet »select fields from table procedure analyse()«. Sie liefert die minimalen und maximalen Werte sowie die Längen der Spalten zurück und ermittelt den optimalen Feldtyp.
Eine der einfachsten Maßnahmen zur Effizienzsteigerung ist die Indizierung von Daten. Ungefähr 90 Prozent der Performanceprobleme in MySQL-Anwendungen sind auf einen mangelhaften Einsatz von Indizes zurückzuführen. Der Index einer Datenbank gibt an, wo genau ein bestimmter Wert zu finden ist – wie der Index oder das Schlagwortverzeichnis eines Buches. Da jeder Index für ein bestimmtes Datenfeld aber den Datenbestand erhöht, ist es wichtig, hier durch entsprechendes Wissen eine optimale Balance zwischen Performance und Datenvolumen zu finden.
Indizierung bringt Speed
Bei einer einfachen Tabelle mit jeweils einem Feld für eine ID-Nummer und einem Namen bringt ein Index auf das Namensfeld bei 5000 Eintragen ein 60-mal schnelleres Ergebnis. Es existieren verschiedene Typen von Indices innerhalb von MySQL. Beim Primary Index dürfen Werte nur einmal vorkommen (unique) und die Spalte muss als »not null« definiert sein. Beim Unique Index entfällt diese Bedingung. Darüber hinaus gibt es noch den Fulltext Index, der für die Volltextsuche gedacht ist.
Die Indizierungen werden dann aktiv, wenn mit den Zeilen im »where«- Statement die jeweiligen Klauseln »like«, »between«, »min()«, »max()« oder »order by« zum Einsatz kommen. Indizierungen sollten für die Spalten erfolgen, in denen der Wert möglichst schnell zu finden sein soll, aber ebenso bei allen Fremdschlüsselspalten, die andere Tabellen referenzieren, oder wenn Zeilen aus anderen Tabellen durch einen Join abgefragt werden.
Werden keine Indices verwendet, könnten die Daten genauso gut in eine Datei geschrieben werden, die dann sequenziell durchsucht wird. Indices helfen aber nicht immer, es kommt sehr auf den richtigen Einsatzzweck an. Wenn in unserem Beispiel der Zugriff auf alle 5000 Zeilen möglich sein soll, ist der Einsatz von Indices keineswegs schneller, da die sequenzielle Methode viel weniger Festplattenzugriffe benötigt. Außerdem belegen die Indexdateien sehr viel Speicherplatz und verlangsamen die Ausführung von »insert«- und »update«- Statements. Die Abfrage aller Datensätze von verknüpften Tabellen ist in der Praxis jedoch eher selten.
Ausgaben von »explain select« |
|
Abfragen effizienter gestalten
Die erste Maßnahme für eine Query-Optimierung sollte eine »explain select«-Abfrage sein, die den Engpass bei der Abfrage aufspürt. Um aus einzelnen Abfragen einer Datenbank ein möglichst schnelles und intelligentes Konstrukt zu erzeugen, besitzt jedes DBMS – also auch MySQL – einen Query Optimizer. Das damit optimierte Konstrukt benutzt MySQL anschließend für die weitere Arbeit. Man kann sich das wie eine Zwischenschicht zwischen einer Abfrage und dem eigentlichen Datensammelprozess vorstellen. Der Optimizer zeigt an, was die Datenbank nach allen Optimierungen tun wird.
In MySQL wird das optimierte SQL-Konstrukt durch ein dem »select«-Statement vorangestelltes »explain« ausgegeben. Es bietet somit die Chance, passende Indices zu setzen oder die Abfrage so zu verbessern, dass MySQL mehr oder bessere Indices verwenden kann.
Möglicherweise lässt das Ergebnis dieser Abfrage auch Rückschlüsse auf die Güte des Datenbankmodells zu, die Verbesserungen nahe legen, beispielsweise durch eine gezielte Denormalisierung. »explain select« gibt außerdem Informationen über die Verknüpfungen und darüber, welche Indices genutzt werden. Wenn es nicht jene sind, die man angelegt hat, sind sie für diese spezielle Abfrage überflüssig. Der Kasten “Ausgaben von »explain select« zeigt die Bedeutung der Spalten bei einer entsprechenden Analyse.
Abfragen-Analyse lohnt sich
Abbildung 1 zeigt einen typischen Ablauf bei einer Query-Analyse: Es sind aus der Tabelle »vehicle_type« jene Fahrzeugtypen aufzulisten, die zu der Fahrzeugmarke »vehicle_mark_id = 44« gehören. Der erste »explain select«-Durchlauf findet lediglich mit Primärindices statt. Das Ergebnis zeigt, dass zuerst ein Zugriff auf den Primärindex der Tabelle der Fahrzeugmarken erfolgt. Anschließend werden alle 1944 Datensätze aus der Tabelle »Fahrzeugtypen« sequenziell gelesen, ohne dabei auch nur einen einzigen Index zu verwenden.
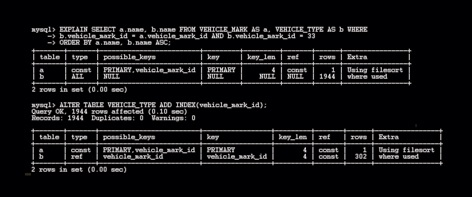
Abbildung 1: Der typische Ablauf einer Query-Analyse mit »explain select«.
Um das wenig erfreuliche Ergebnis zu optimieren, erhält der Fremdschlüssel (»vehicle_mark_id«) in der »Fahrzeugtypen«-Tabelle einen Index. Im Anschluss erfolgt noch einmal die identische Abfrage von oben. Es ist deutlich zu sehen, dass die Fremdschlüssel-Indizierung einiges bewirkt hat. Die »Fahrzeugtypen«-Tabelle wird nun optimal mit der »Fahrzeugmarken«-Tabelle über den Index verbunden und stellt auf diese Weise eine direkte Verbindung zu den Fahrzeugtypen her.
Komplette Abfragen der Art »select * from table« sind zwar nur selten erforderlich, aber trotzdem häufig anzutreffen. Sie sind stilistisch nicht gerade elegant und beanspruchen viel Speicher. Der »select«-Befehl ist zudem für einen Außenstehenden schwer zu durchschauen, da eine solche Abfrage keinen Aufschluss darüber gibt, welche Spalten wirklich benötigt werden.

Abbildung 2: Tabellenanalyse in MySQL mit »analyse table«.
Weitere Optimierungstipps
Bei jeder Abfrage ist also sorgfältig darauf zu achten, unnötige Dateizugriffe zu minimieren und Indices nur dann einzusetzen, wenn es darum geht, einzelne Werte schneller zu finden. Es ist zudem empfehlenswert, die »where«-Bedingung so einfach wie möglich zu halten und auf Rechenoperationen in der Abfrage zu verzichten, da MySQL keine konstanten Ausdrücke optimieren kann.
Eine weitere nützliche Methode ist die intensive Überprüfung der Logfiles. Falls MySQL mit dem Parameter »–log-slow-queries[=file_name]« gestartet wurde, protokolliert »mysqld« alle SQL-Queries, die länger für die Ausführung benötigten als den über über »long_query_time« in Sekunden definierten Zeitraum. Außerdem existiert im MySQL-Datenverzeichnis das »hostname.err«-Logfile, das Informationen über Crashes oder Probleme aufzeichnet.
Falls große Teile einer Tabelle gelöscht oder viele Änderungen durchgeführt wurden, kann der Einsatz von »optimize table« bei MyISAM- und BDB-Tabellen helfen, um den unbenutzten Platz freizugeben und den Defragmentierungs- Vorgang zu starten. »analyze table« gibt Aufschluss über die Schlüsselverteilung und darüber, in welcher Reihenfolge Tabellen verknüpft werden. Bei der Tabellenverwaltung und bei der Reparatur nach einem Absturz kann das Dienstprogramm »myisamcheck« Tabellen prüfen, reparieren oder optimieren.
Server-Tuning
Die Optimierung von MySQL Server führt zwar nicht zu großen Performance-Sprüngen, trotzdem wirken sich einige Parameter direkt auf die Anfrageverarbeitung und Verarbeitungsgeschwindigkeit aus. Die Modifizierungen sind unter anderem über die Konfigurationsdatei »my.cnf« möglich.
Hier sind insbesondere die Parameter für das Query-Caching interessant. »cache _limit_size« etwa legt fest, bis zu welcher maximalen Aufzeichnungsgröße gecacht werden soll. »query_cache_size« legt die Speichergröße für den Cache fest. Hat »query_cache_type« den Wert »1«, wird grundsätzlich jede Query gecacht, bei »2« nur Queries der Form »select sql_query_cache«.
Bei den Speichereinstellungen legt »key_ buffer_size« die Größe des Buffers für Index-Blöcke fest. Ein größerer Wert macht durchaus einen Performance-Gewinn bei der Handhabung von Indices (Lese- und mehrfache Schreibzugriffe) möglich. »table_cache« legt die Anzahl der gleichzeitig geöffneten Dateien für alle Threads fest. »tmp_table_size« sollte möglichst groß sein, wenn viele komplexe »group by«-Abfragen erforderlich sind. So entstehen weniger temporäre MyISAM-Tabellen.
Aber schon die Kompilierung von MySQL hat Auswirkungen auf die Performance. Durch das Linken mit statischen Libraries ist man gut elf Prozent schneller als mit dynamischen. Auch ein plattformspezifischer Compiler zum Übersetzen kann Vorteile bringen. Mit ihm kompiliert man MySQL am besten ohne Framepointer und verwendet nur die wirklich nötigen Charsets.
Läuft der MySQL-Server unter hoher Belastung, wird zudem die Hardware-Ausstattung wichtig. Bei der Auswahl der Festplatte ist SCSI der IDE-Variante vorzuziehen und darauf zu achten, dass die Festplatte eine möglichst kurze Zugriffszeit aufweist. Ein RAID-System (Hard- oder Software) ist für diesen Einsatz ebenfalls zu empfehlen. Je mehr Speicher, desto besser für den Query-Cache und das Vermeiden von Swapping.
Nicht zuletzt ist auch die Wahl des Betriebssystems maßgeblich für die Geschwindigkeit der Lese- und Schreibzugriffe. Darf man der Quelle von MySQL AB Glauben schenken, so liegt bei identischer Hardware Linux beim Lesen mit 245 Sekunden gegenüber Windows ohne MyODBC (360 Sekunden) klar vorn. Beim Schreiben ist der Unterschied noch deutlicher, hier ist Linux mit 198 Sekunden) erheblich schneller als Windows mit 345 Sekunden.
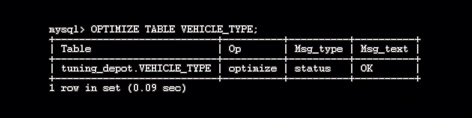
Abbildung 3: Tabellen-Optimierung mit »optimize table«.
Performance dank Replikation
Auch die Möglichkeiten der Replikation bei neueren MySQL-Versionen lassen sich zur Performancesteigerung heranziehen. Dieser Mechanismus erlaubt es, alle Anfragen der Clients an den jeweiligen Master-Server weiterzuleiten, der die auszuführenden Datenänderungen in eine Datei namens »Binary Log« schreibt. Der untergeordnete Slave-Server wiederholt diese Operationen und befindet sich auf dem gleichen Stand wie der Master-Server und besitzt somit ein aktuelles Backup. Sollte der Master-Server ausfallen, übernimmt der Slave dessen Aufgaben.
Auch bei der Lastenverteilung und Skalierung bringt der Replikations-Mechanismus Vorteile, da eine beliebige Anzahl von Slave-Servern im Verbund ständig auf dem Stand des Master-Servers ist. Der Master wird damit entlastet, die ankommenden Anfragen verteilen sich auf die Slaves. Um Load und Swap zu überprüfen, bietet sich neben dem bekannten Linux-Tool »top« das MySQL-Monitoring-Tool »my_top«[6] an.
Mit seiner Hilfe lassen sich wichtige Daten analysieren: Queries pro Sekunde, Idle zu Active Threads, Cache-Hitrate, übertragene Daten (Bytes) und Slow Queries. Auch der Befehl »show status« liefert nützliche Daten zur Performance-Analyse. Neben den Statusvariablen des Servers lassen sich aus den Statusmeldungen Informationen über die aktuelle Beschaffenheit der Datenbank in Erfahrung bringen. (uwo)
Infos |
|
[1] Offizielle Webseite von MySQL: [http://www.mysql.com/] [2] Bernhard Röhrig, “Daten-Bastelstube – Entwurf von Datenmodellen”: Linux- Magazin 04/01, S. 32 [3] Michael Kofler, ” Ganz oder gar nicht – Transaktionen in MySQL”: Linux-Magazin 08/01 [4] Connolly, Begg, Strachan: “Datenbanksysteme”, Addison Wesley, ISBN 3827320135 [5] Heuer, Saake: “Datenbanken. Konzepte und Sprachen”, mitp, ISBN 3826606191 [6] MySQL Monitoring Tool: [http://jeremy.zawodny.com/mysql/mytop/] |
Der Autor |
|
Andre Gildemeister ist selbstständiger Software-Entwickler [www.inocreation.com] und befasst sich verstärkt mit der Software-Entwicklung im Web-basierten Umfeld und dessen Technologien. Außerdem ist er als freier Autor für verschiedene Online- und Print-Magazine rund um PHP und Web-Technologien aktiv tätig. |






