
© Andrey Bortnikov, 123RF
Donald Knuth entwickelte ab 1981 die Technik des Literate Programming für die Software-Entwicklung. Auch heutigen Programmierern kann die Methode nützlich sein.
Literate Programming [1] ist eine einfach anzuwendende Technik. Der größte Aufwand besteht in der mentalen Umgewöhnung auf die neue Arbeitsfolge “Erst dokumentieren, dann kodieren”. Dass die technische Dokumentation und der Code dabei in ein und demselben Primärdokument landen, erleichtert die Arbeit. Eine einfache Kombination aus Asciidoc, E-Web und Python reicht als Werkzeugausstattung beim Einstieg.
Konzept des Literate Programming
Im Literate Programming notiert der Programmierer von Anfang an seine Gedankengänge zur Gestaltung eines Programms in Freitext (Literate). So genannte Code-Snippets im Text erläutern dabei die Details etwa so, wie man das aus Fachbüchern kennt. Den Entstehungsprozess begleitet damit eine kontinuierlich mitgeführte Dokumentation in freier Rede. Diese mündet in einer technischen Dokumentation, die Entwicklungsentscheidungen und ihre Gründe leicht nachvollziehen lässt. Abbildung 1 illustriert dieses Grundprinzip.
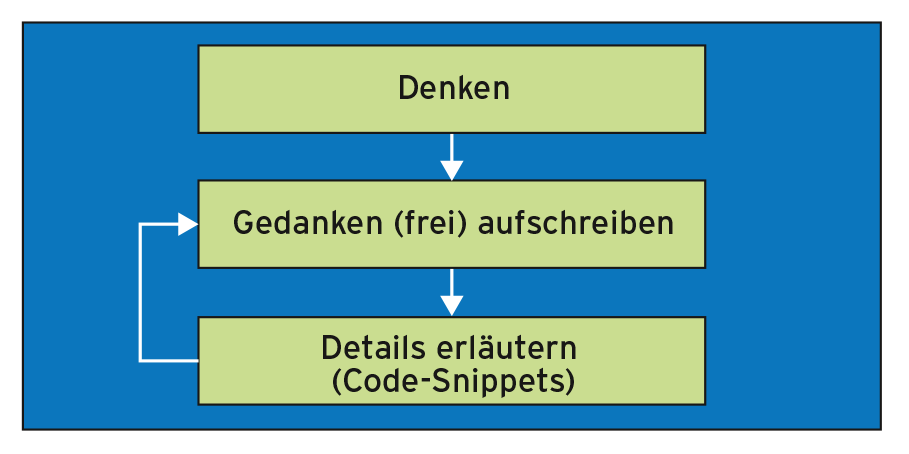
Abbildung 1: Das Grundprinzip des Literate Programming.
Die drei Komponenten “Denken, Aufschreiben, Details notieren” sind eng miteinander verzahnt. Der Programmierer denkt zwar während des Schreibens ständig über die Problemlösung nach http://2] Wichtig ist aber, die Abfolge durchzuhalten: erst Freitext, danach Code. Der Freitext beantwortet die Frage, welches konkrete Problem gerade zu lösen ist und warum gerade dieser Weg beschritten wurde. Der Code zeigt danach die konkrete Implementierung.
Manchmal tritt zu Anfang eine Schreibblockade beim Verfassen des Freitexts auf. Der Entwickler weiß genau, was er kodieren will, nur ein erklärender Text dazu fällt ihm nicht ein. In dieser Situation helfen die Leitfragen: “Welche alternativen Lösungsansätze gäbe es?” und “Warum löse ich diese Teilaufgabe so und nicht anders?” Oft stolpert der Programmierer bei diesen Leitfragen auch über Alternativen, die er vorher nicht beachtet hatte.
Der technische Trick dabei ist, die Code-Snippets nicht in irgendeiner Pseudosprache, sondern gleich in der Ziel-Programmiersprache zu notieren. Namen von Code-Snippets werden dabei in spitze Klammern geschrieben und mit einem Gleichheitszeichen vom eigentlichen Code abgesetzt – wie im Hello-World-Beispiel Listing 1, Zeile 9. Solche Namen lassen sich – wieder in spitzen Klammern – im Code-Abschnitt der folgenden Snippets referenzieren (ab Zeile 12).
Listing 1
Hello World!
01 Nötige Shebang-Zeile für die Shell 02 <shebang>= 03 #! /usr/bin/env python 04 <copyright>= 05 # 06 # This program is free to use for didactic purposes 07 # 08 Ausgabe von "Hello world!" 09 <print_content>= 10 print "hello world" 11 Gekapselt in einer Funktion 12 <content_function_def>= 13 def do_output(): 14 <print_content> 15 Startpunkt für den Zusammenbau des Programms 16 <*>= 17 <shebang> 18 <copyright> 19 <content_function_def> 20 do_output()
Knuth vergleicht eine fertige Software mit einem Gewebe, das aus Kettfäden und Schussfäden besteht. Die Kettfäden entsprechen dem Programmcode, aber die fertige Software ist ein Gewebe aus Dokumentation und Code.
Die Namen der Werkzeuge, die am Ende sowohl den Programmcode als auch die Dokumentation generieren, sind an diese Analogie angelehnt. Das Tool »tangle« extrahiert die Code-Snippets und führt sie automatisch zu einem Programmcode zusammen. Dazu benötigt Tangle einen Startpunkt. Er wird Root Node genannt und als »<*>« (Listing 1, Zeile 16) notiert. Zur Herstellung der Dokumentation dient das Werkzeug »weave« .
Aspekte des Literate Programming finden sich auch in anderen Sprachen. Auch Javadoc folgt etwa dem Prinzip, die Dokumentation und den Code in derselben Datei zusammenzuhalten.
Die qualitative Veränderung des Software-Entstehungsprozesses könnte man so beschreiben: Statt ein Programm zu basteln, erkläre ich die Funktionsweise des Programms und meine Entscheidungen für den gewählten Lösungsweg. Subjektiv ähnelt die Softwareherstellung nach Literate Programming eher dem Schreiben eines Artikels.
Werkzeuge
Zum Schreiben des Textes ist jeder beliebige Texteditor nutzbar. Als Weave-Werkzeug verwendete der Autor »asciidoc« , das den geschriebenen Text im Tex-, PDF- oder HTML-Format extrahieren kann. Das in Asciidoc http://3 enthaltene »a2x« erzeugt PDF-Ausgaben durch Konvertieren der Eingabe zu Docbook-XML, das dann nach einer Prüfung durch »xmllint« zu Latex-Code konvertiert und mit »pdf-latex« gesetzt wird.
Leider erfordert die Kombination Asciidoc/A2x unter Debian eine relativ große Installation (rund 500 MByte), weil eine komplette Tex-Distribution und Docbook-XML zu den Voraussetzungen gehören. Im Gegenzug besteht die Möglichkeit, beliebige Formatierungs-Backends einzusetzen, die Docbook-XML als Eingabe akzeptieren.
Als Tangle-Werkzeug kommt »etangle.py« aus dem E-Web-Projekt http://4 zum Einsatz. Es ist auf Asciidoc abgestimmt. Listing 2 demonstriert den Einsatz der Werkzeuge in Makefile-Syntax.
Listing 2
Makefile
01 # Auflistung aller mechanisch erzeugten Produkte 02 # 03 GENERATED=helloworld.html helloworld.pdf helloworld.py 04 05 # Erzeugung aller Produkte 06 # 07 all: $(GENERATED) 08 touch done 09 echo "all done" 10 11 # Erzeugung des Programm-Sourcecodes mit Etangle.py. Es filtert die 12 # Code-Schnipsel aus unserer Eingabe "helloworld.txt" heraus und 13 # löst die namentlichen Referenzen "<Name>=..." auf, sodass syntaktisch 14 # gültiger Python-Code entsteht. 15 # 16 helloworld.py: helloworld.txt 17 cat helloworld.txt | etangle.py > helloworld.py 18 chmod u+x helloworld.py 19 20 # Asciidoc erzeugt per default HTML-Output, wir wählen den Weg via 21 # Docbook-XML (Option "-dbook"), damit die HTML-Ausgabe und die 22 # PDF-Ausgabe sich so ähnlich wie möglich sehen. 23 # 24 helloworld.html: helloworld.txt 25 asciidoc -dbook helloworld.txt 26 27 # Erzeugung der PDF-Ausgabe mit A2x, Optionen ansonsten wie gehabt 28 # 29 helloworld.pdf: helloworld.txt 30 a2x -fpdf -dbook helloworld.txt 31 32 # Aufräumen - Löschen aller generierten Daten 33 # 34 clean: 35 rm -f $(GENERATED) done
Das Arbeiten nach dem Prinzip des Literate Programming wirkt freier, weil der Entwickler nicht ständig Syntax- und Laufzeitfehler korrigieren muss, während er noch über den geeigneten Lösungsweg nachdenkt. Diese Freiheit wird durch mentale Disziplin erkauft – erst erklären, dann kodieren! Entwicklungsfortschritte lassen zu Beginn etwas auf sich warten, stellen sich dann aber um so kontinuierlicher ein.
Fazit
Als ein riesengroßer Vorteil ergibt sich, dass bei Fertigstellung des Programms automatisch auch eine hochwertige und vollständige technische Dokumentation entstanden ist. Die Strafarbeit, nach einem Kodier-Marathon auch noch eine Dokumentation schreiben zu müssen, entfällt.
Leider ist die Integration von Literate-Techniken in IDEs mit eigener Codegenerierung nur schwer möglich. Größere Projekte müssen im Vorfeld also entscheiden, welche Technik dem Projekt in welchen Bereichen größere Vorteile bietet. Sowohl fortgeschrittene IDEs als auch Literate Programming erzeugen Quellcode-Dateien. Wer beide Techniken gleichzeitig für dieselbe Datei einsetzt, riskiert deshalb Unfälle. Eine Integration von Literate Programming in Toolchains, die unter eigener Kontrolle stehen, ist dagegen in der Regel jederzeit und problemlos möglich. (jcb)
Infos
- Knuth, Donald E., “Literate Programming”, 1992, ISBN 978-0-937073-80-3
- Literate Programming: https://de.wikipedia.org/wiki/Literate_programming
- Asciidoc: http://www.methods.co.nz/asciidoc/
- E-Web: http://sourceforge.net/projects/eweb





